
更新 :模型的裁剪量化(新需求)
why?最近发现尽管yolov3-tiny网络已经足够小了,但实际上对于我们新niao来说把这个网络放到vu3p的板子上实现的难度还是有点大。
1、网络大主要包括两个方面:input图片大小(416*416*3)和网络的weight参数数量(8.7M个)
2、在一个我们在硬件使用16bit的二进制数表示一个数据,这无疑会增大数据的体量
怎么裁剪?(尽量不会导致硬件同学大改动已做好的模块(就是说还是使用传统卷积池化激活))
参考:https://github.com/coldlarry/YOLOv3-complete-pruning
鉴于目前硬件大部分已经设计有了雏形,大的更改不太现实,比如稀疏化剪枝 。
尝试:将512 -1024的卷积以及旁边的卷积层通道数直接减半:
最后一层的输出通道数75通道
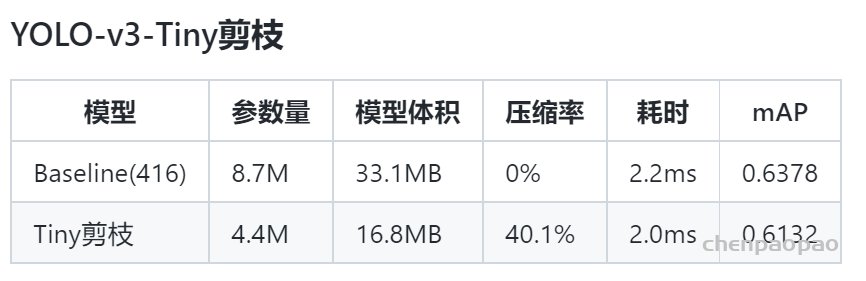
结果:
AP略降、参数量:减少3.5M个(效果还凑合)

接下来尝试:
1、把卷积层 —> 1*1conv + 3*3 dconv
resize: 对输入大小 416 –> 320(效果下降很厉害)
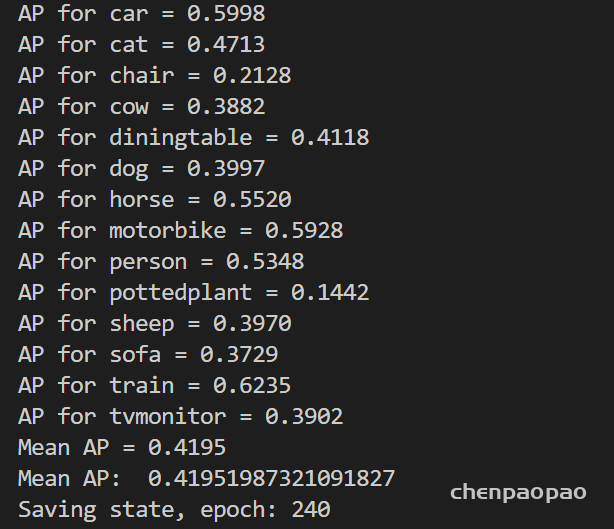
2、在 尝试:将512 -1024的卷积以及旁边的卷积层通道数直接减半,之后对输入大小 416 –> 384(正在做,设置为384的话最后最小的特征图是12*12这样方便硬件实现) AP:0.47—>0.43


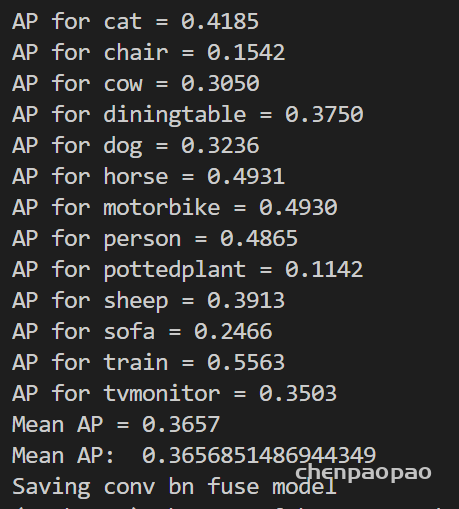
可以看到:直接修改会导致效果 下降很厉害:通过不断地调参:
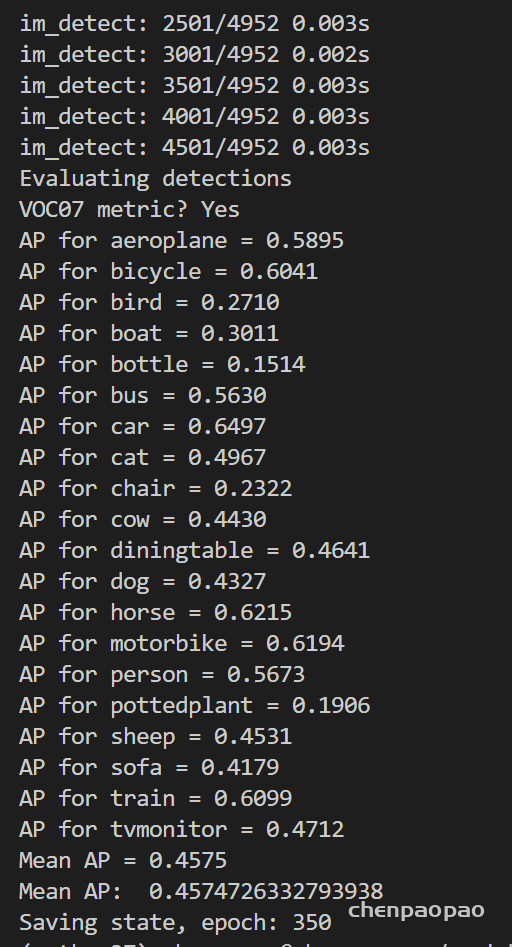

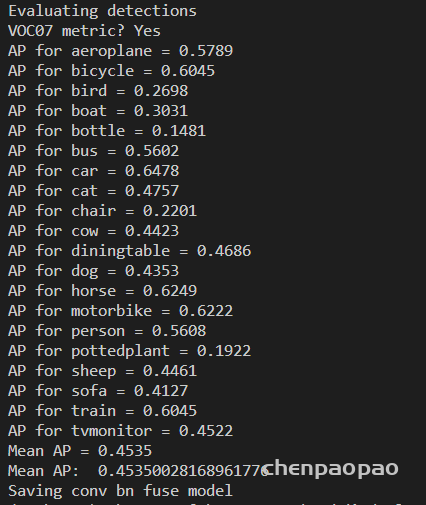
下一步:微调(微调完 实际上就可以数据分析、提取参数、量化到7bit+8bit、写入bin文件,然后提供给硬件同学了)
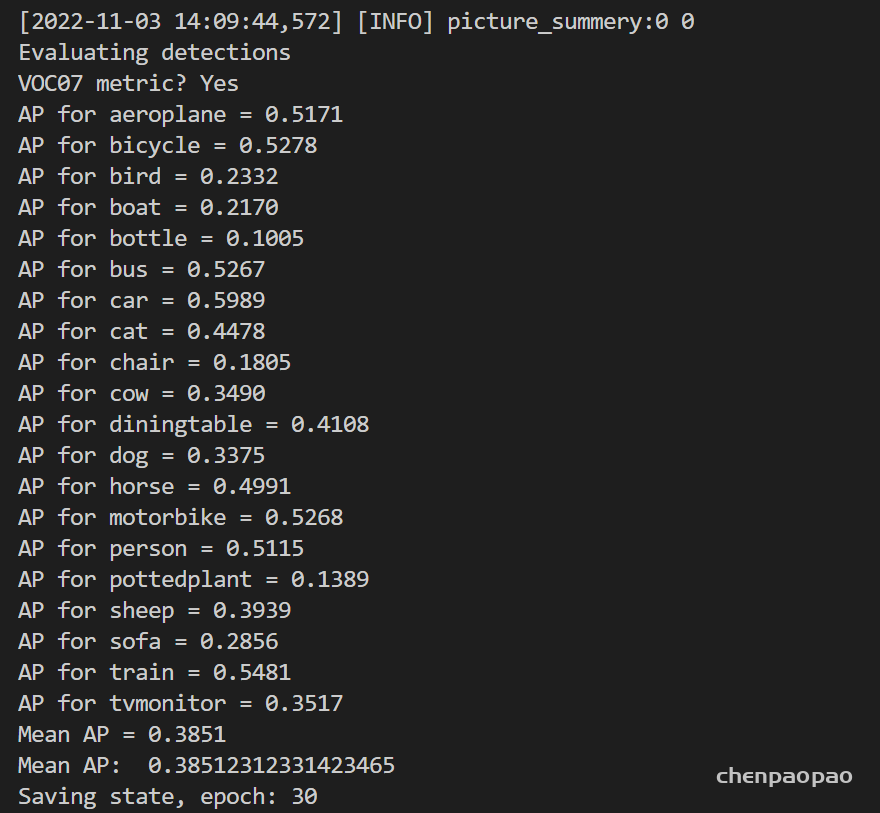
这里因为bn融合后的ap基本没有改变,所以用在进行量化了。
微调完:进行量化(不再使用最开始的量化方法,损失有点大)
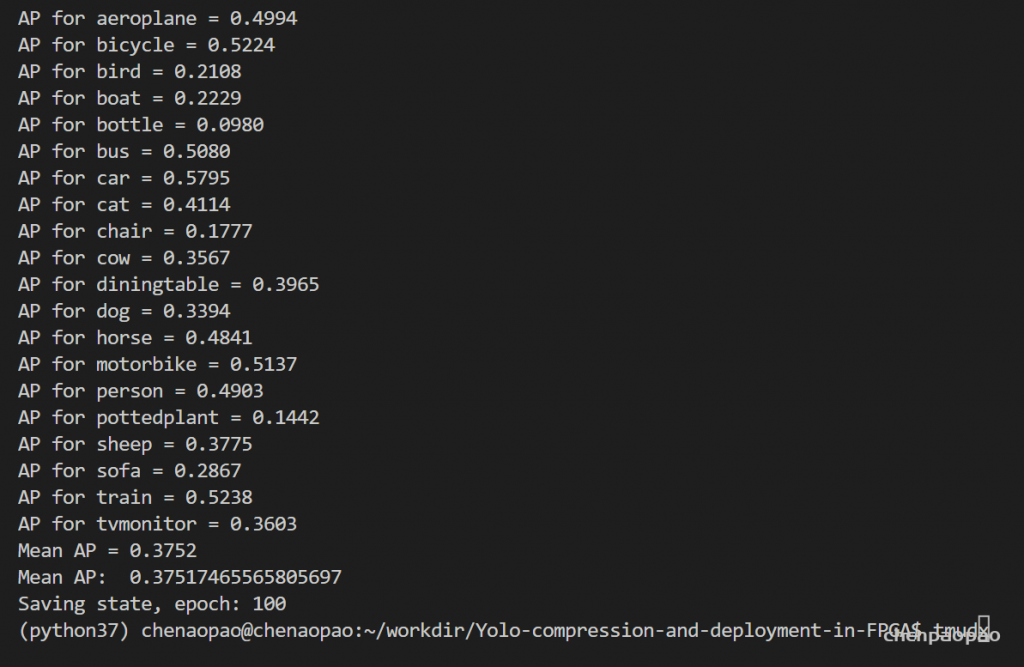

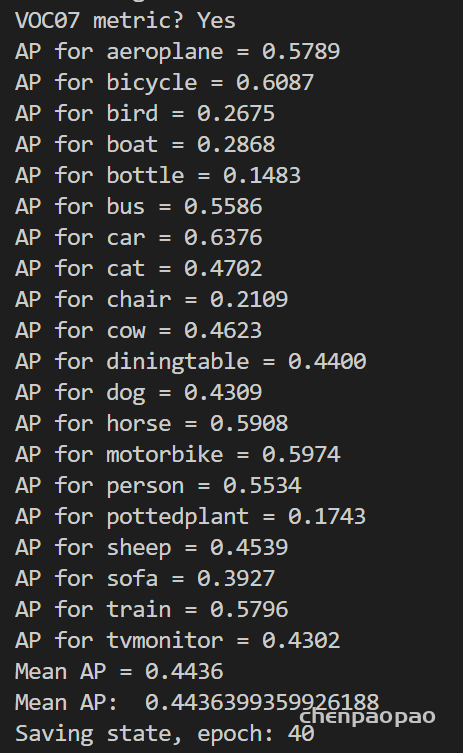
量化报的警告:
# 最新版本
def quantize_tensor(activation,integer_precision=7, fraction_precision=8,channel_level=False):
_max = activation.abs().max()
if _max > 2**integer_precision:
print("data is too big, overflows!!!")
one = torch.ones_like(activation)*(2**integer_precision- 1/(2**fraction_precision))
_activation = torch.where(activation > 2**integer_precision ,one, activation)
_activation = torch.where(_activation < -2**integer_precision ,one*-1, _activation)
else:
_activation = activation
# 0.00390625 表示的最大精度
_int = _activation.trunc() #整数部分
_frac = _activation.frac() #小数部分
new_tensor =_int + (_frac//2**(-fraction_precision))*(2**(-fraction_precision))
return new_tensor, 1use torch.div(a, b, rounding_mode=’trunc’), or for actual floor division, use torch.div(a, b, rounding_mode=’floor’)
把权重写入bin/text文件中
2、FPGA硬件同学最终希望的目标 是把权重参数降到3M一下,这样可以直接把权重放在uram /bram,这样不需要从ddr读取权重数据(会很大程度减轻硬件同学的工作量)——————所以需要软件同学尽最大可能的压缩!!!!
待做:1、搭建每一层的python仿真程序,供硬件做参考 2、原来的torch训练,需要 将最新的模型和输入进行一系列的微调、量化、以及最后提取各层参数,写入bin文件 3、torch训练过程的量化过程:进行优化(16bit) 4、尝试使用repconv(yolov6来替代 yolov3中的卷积层)
3、torch训练过程的量化过程:进行优化(16bit) :
修改 原始代码:
class AveragedRangeTracker_v1(nn.Module):
def __init__(self, momentum=0.1):
super().__init__()
self.momentum = momentum
self.register_buffer('scale', torch.zeros(1))
self.register_buffer('first_a', torch.zeros(1))
def quantize_activation(self, activation, integer_precision=7, fraction_precision=8, rescale=True,
quantization=False, freeze = False):
if(quantization == False):
return activation
# 实际上这部分的内容就是在训练过程中把输入---》约束到bitwidth=8所能表示的范围,并替换掉
# 实际的输入。
with torch.no_grad():
_max = activation.abs().max()
if _max > 2**integer_precision:
print("data is too big, overflows!!!")
one = torch.ones_like(activation)*(2**integer_precision- 1/(2**fraction_precision))
_activation = torch.where(activation > 2**integer_precision ,one, activation)
_activation = torch.where(_activation < -2**integer_precision ,one*-1, _activation)
else:
_activation = activation
quantized_a = (_activation//2**(-fraction_precision))*(2**(-fraction_precision))
quantized_a.requires_grad = True
return quantized_adef quantize_tensor_v1(activation,integer_precision=7, fraction_precision=8,channel_level=False):
_max = activation.abs().max()
if _max > 2**integer_precision:
print("data is too big, overflows!!!")
one = torch.ones_like(activation)*(2**integer_precision- 1/(2**fraction_precision))
_activation = torch.where(activation > 2**integer_precision ,one, activation)
_activation = torch.where(_activation < -2**integer_precision ,one*-1, _activation)
else:
_activation = activation
new_tensor = (_activation//2**(-fraction_precision))*(2**(-fraction_precision))
return new_tensor, 1def quantize_tensor_b_v1(activation,integer_precision=7, fraction_precision=8,channel_level=False):
_max = activation.abs().max()
if _max > 2**integer_precision:
print("data is too big, overflows!!!")
one = torch.ones_like(activation)*(2**integer_precision- 1/(2**fraction_precision))
_activation = torch.where(activation > 2**integer_precision ,one, activation)
_activation = torch.where(_activation < -2**integer_precision ,one*-1, _activation)
else:
_activation = activation
new_tensor = (_activation//2**(-fraction_precision))*(2**(-fraction_precision))
return new_tensor, 1repvggcode:https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py
repconv(yolov6来替代 yolov3中的卷积层) :
# This func derives the equivalent kernel and bias in a DIFFERENTIABLE way.
# You can get the equivalent kernel and bias at any time and do whatever you want,
# for example, apply some penalties or constraints during training, just like you do to the other models.
# May be useful for quantization or pruning.
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1,1,1,1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
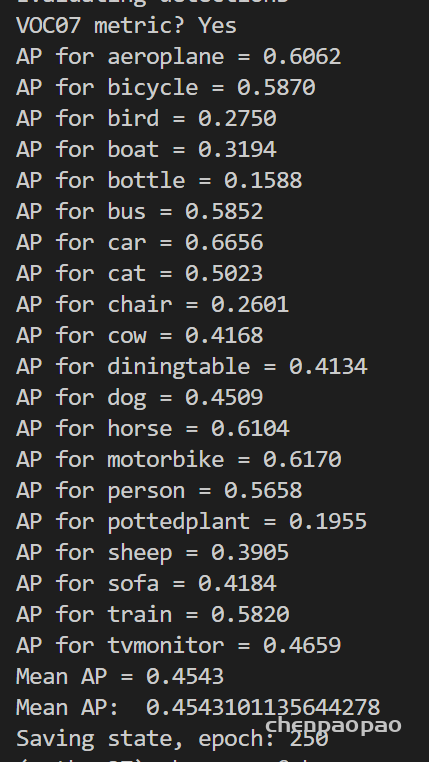
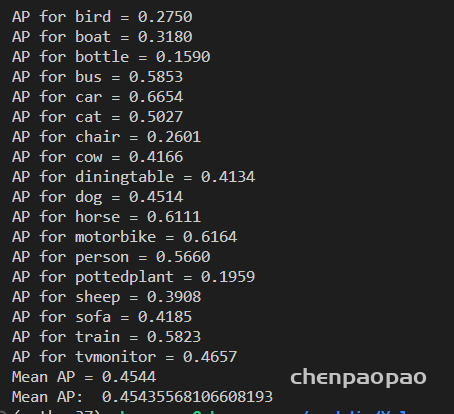
量化:
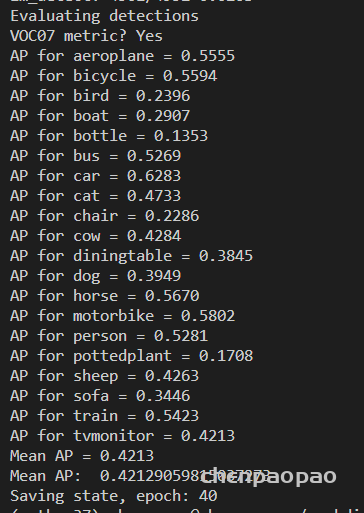
rep_small_v1:
class Conv2d_v1(nn.Module):
"""
模块说明:conv2d+bn+激活函数,
在训练完以后,进行deploy_model = repvgg_model_convert(train_model, save_path='RepVGG-A0-deploy.pth')之前,设置train_model.eval(),然后在转换就可以了
实现bn+conv融合
if deploy == true: 返回融合后的模型
"""
def __init__(self, in_channels, out_channels, kernel_size=3, padding=1, stride=1, dilation=1, leakyReLU=True,groups=1,deploy=False,padding_mode="zeros"):
super(Conv2d_v1, self).__init__()
self.nonlinearity = nn.LeakyReLU(0.125, inplace=True) if leakyReLU else nn.ReLU(inplace=True)
self.deploy = deploy
if self.deploy:
self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=True, padding_mode=padding_mode)
else:
self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, groups=groups)
def forward(self, inputs):
if hasattr(self, 'rbr_reparam'):
# print("rbr_reparam:")
return self.nonlinearity(self.rbr_reparam(inputs))
return self.nonlinearity(self.rbr_dense(inputs))
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def switch_to_deploy(self):
if hasattr(self, 'rbr_reparam'):
return
kernel, bias = self._fuse_bn_tensor(self.rbr_dense)
self.rbr_reparam = nn.Conv2d(in_channels=self.rbr_dense.conv.in_channels, out_channels=self.rbr_dense.conv.out_channels,
kernel_size=self.rbr_dense.conv.kernel_size, stride=self.rbr_dense.conv.stride,
padding=self.rbr_dense.conv.padding, dilation=self.rbr_dense.conv.dilation, groups=self.rbr_dense.conv.groups, bias=True)
self.rbr_reparam.weight.data = kernel
self.rbr_reparam.bias.data = bias
self.__delattr__('rbr_dense')
if hasattr(self, 'rbr_identity'):
self.__delattr__('rbr_identity')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
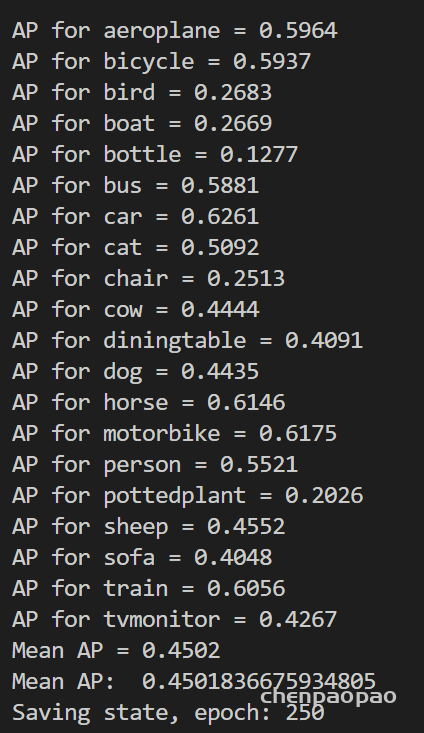
self.deploy = True最新:使用最近邻插值替代双线性插值算法
C_5_up = F.interpolate(C_5_1, scale_factor=2.0, mode=’nearest’)
如何bn和conv:
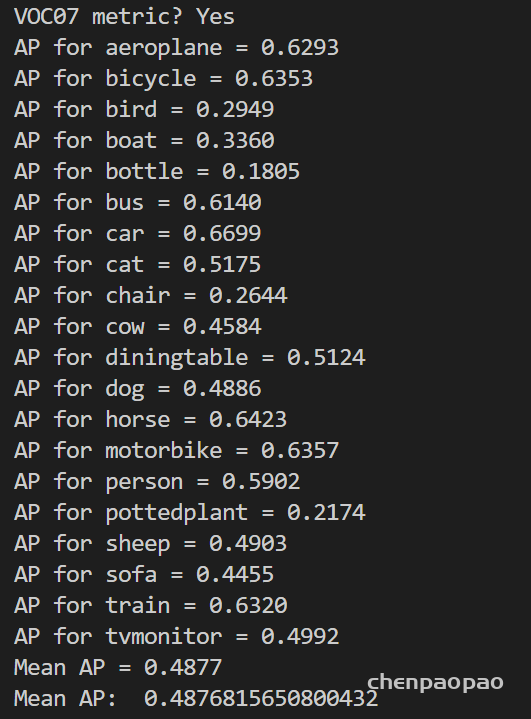
待做:1 看看repvgg是如何实现的(论文+代码 ) 2、yolov6的代码,是怎么部署到工业化的 2、目前效果提升不明显,尝试知识蒸馏 or 数据增强(参考yolov5/v6)
1、数据增强:参考yolovx(待做)
参考博客:https://blog.csdn.net/qq_39237205/article/details/125730988
https://www.codeleading.com/article/80135054649/
https://my.oschina.net/u/4580321/blog/4358486
YOLOV5会进行三种数据增强:缩放,色彩空间调整和马赛克增强。其中马赛克增强是通过将四张图像进行随机缩放、随机裁剪、随机分布方式进行拼接,小目标的检测效果得到提升。
在网络的输入端,Yolox主要采用了Mosaic、Mixup两种数据增强方法。通过随机缩放、随机裁剪、随机排布的方式进行拼接,对于小目标的检测效果提升,还是很不错的。而且在Yolov4、Yolov5算法中,也得到了广泛的应用。是一种非常有效的增强方式。MixUp是在Mosaic基础上,增加的一种额外的增强策略。
2、知识蒸馏 (待做)
参考文献 https://blog.csdn.net/qq_39523365/article/details/118525815
知识蒸馏(Knowledge Distilling)是模型压缩的一种方法,是指利用已经训练的一个较复杂的Teacher模型,指导一个较轻量的Student模型训练,从而在减小模型大小和计算资源的同时,尽量保持原Teacher模型的准确率的方法。即用一个复杂网络(teacher network)学到的东西去辅助训练一个简单网络(student network)。