论文地址:https://arxiv.org/abs/2201.03545
github: https://github.com/facebookresearch/ConvNeXt
class Block(nn.Module):
r""" ConvNeXt Block. There are two equivalent implementations:
(1) DwConv -> LayerNorm (channels_first) -> 1x1 Conv -> GELU -> 1x1 Conv; all in (N, C, H, W)
(2) DwConv -> Permute to (N, H, W, C); LayerNorm (channels_last) -> Linear -> GELU -> Linear; Permute back
We use (2) as we find it slightly faster in PyTorch
Args:
dim (int): Number of input channels.
drop_path (float): Stochastic depth rate. Default: 0.0
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
"""
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv
self.norm = LayerNorm(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layers
self.act = nn.GELU()
self.pwconv2 = nn.Linear(4 * dim, dim)
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x
2020年以来,ViT一直是研究热点。ViT在图片分类上的性能超过卷积网络的性能,后续发展而来的各种变体将ViT发扬光大(如Swin-T,CSwin-T等),值得一提的是Swin-T中的滑窗操作类似于卷积操作,降低了运算复杂度,使得ViT可以被用做其他视觉任务的骨干网络,ViT变得更火了。本文探究卷积网络到底输在了哪里,卷积网络的极限在哪里。在本文中,作者逐渐向ResNet中增加结构(或使用trick)来提升卷积模型性能,最终将ImageNet top-1刷到了87.8%。作者认为本文所提出的网络结构是新一代(2020年代)的卷积网络(ConvNeXt),因此将文章命名为“2020年代的卷积网络”。
方法
训练方法
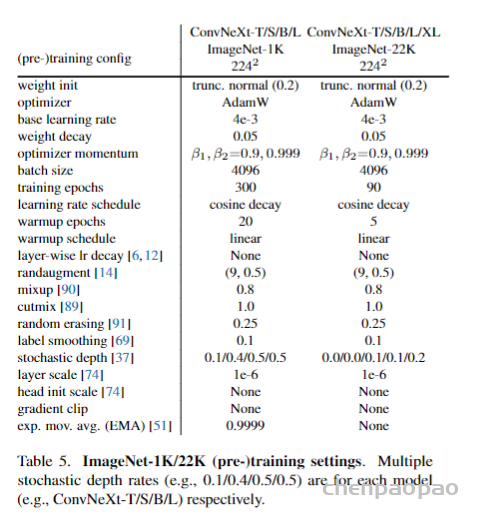
作者首先将ViT的训练技巧,包括lr scheduler、数据增强方法、优化器超参等应用于ResNet-50,并将训练轮数由90扩大到300,结果分类准确率由76.1%上升到78.8%。具体训练config如下:
宏观设计
作者借鉴了Swin-T的两个设计:
- 每阶段的计算量
- 对输入图片下采样方法
对于第一点类似Swin-T四个阶段1:1:9:1的计算量,作者将ResNet-50每个阶段block数调整为3,3,9,3(原来为3,4,6,3),增加第三阶段计算量,准确率由78.8%提升至79.4%。
对于第二点Swin-T融合压缩2 2的区域,作者则使用4 4步长为4的卷积对输入图片进行下采样,这样每次卷积操作的感受野不重叠,准确率由79.4%提升至79.5%。
类ResNeXt设计
depthwise conv中的逐channel卷积操作和self-attention中的加权求和很类似,因此作者采用depthwise conv替换普通卷积。参照ResNeXt,作者将通道数增加到96,准确率提升至80.5%,FLOPs相应增大到了5.3G。相比之下原始的ResNet-50 FLOPs为4G,运算量增大很多。
Inverted Bottleneck
在depthwise conv的基础上借鉴MobileNet的inverted bottleneck设计,将block由下图(a)变为(b)。因为depthwise不会使channel之间的信息交互,因此一般depthwise conv之后都会接1 1
C的pointwise conv。这一顿操作下来准确率只涨了0.1%到80.6%。在后文说明的大模型上涨点多一点。
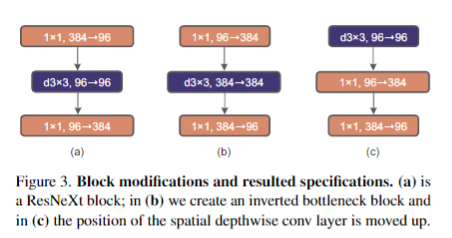
增大卷积kernel
作者认为更大的感受野是ViT性能更好的可能原因之一,作者尝试增大卷积的kernel,使模型获得更大的感受野。首先在pointwise conv的使用上,作者为了获得更大的感受野,将depthwise conv提前到1 1 conv之前,之后用384个1 1 96的conv将模型宽度提升4倍,在用96个1 1 96的conv恢复模型宽度。反映在上图中就是由(b)变为(c)。由于33的conv数量减少,模型FLOPs由5.3G减少到4G,相应地性能暂时下降到79.9%。
然后作者尝试增大depthwise conv的卷积核大小,证明77大小的卷积核效果达到最佳。
其他乱七八糟的尝试
借鉴最初的Transformer设计,作者将ReLU替换为GELU;ViT的K/Q/V计算中都没有用到激活函数和归一化层,于是作者也删除了大量的激活函数和归一化层,仅在1 1卷积之间使用激活函数,仅在7 7卷积和1 1 卷积之间使用归一化层,同时将BN升级为LN。最终block结构确定如下:
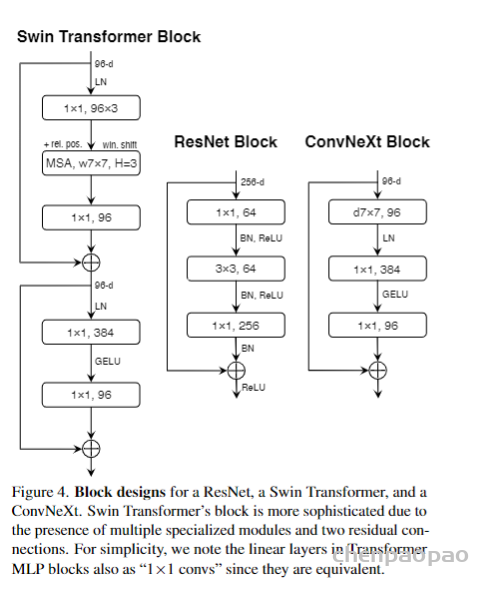
最后仿照Swin-T,作者将下采样层单独分离出来,单独使用2 2卷积层进行下采样。为保证收敛,在下采样后加上Layer Norm归一化。最终加强版ResNet-50准确率82.0%(FLOPs 4.5G)。
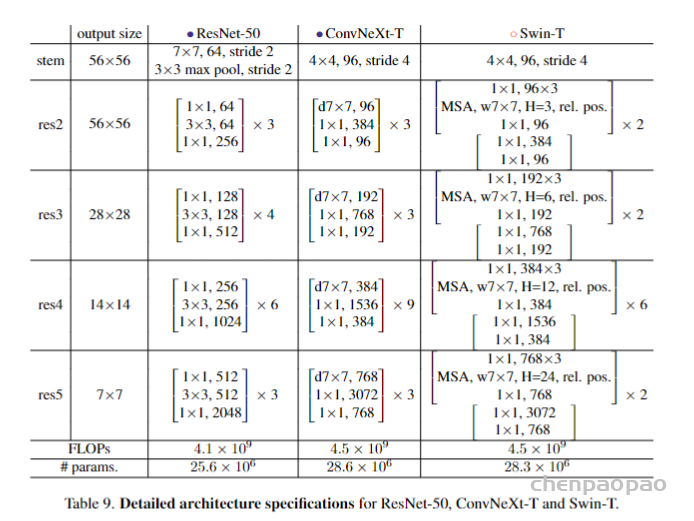
总的来说ResNet-50、本文模型和Swin-T结构差别如下: