中兴捧月大赛 :https://zte.hina.com/zte/index
图像去噪赛题背景图像去噪是机器视觉领域重要任务,图像去噪模块在安防,自动驾驶,传感,医学影像,消费电子等领域都是重要的前端图像处理模块。消费级电子产品(例如手机)出于成本考虑,在低照度和高ISO条件下,噪声对成像质量的降级更加严重。对于传统图像处理算法,常见去噪算法包含双边(bilateral)滤波,NLM (non local mean)滤波,BM3D,多帧(3D)降噪方案等多种方案,产品实现上需要兼顾性能和复杂度。
AI可进一步提升图像主客观质量在学术和工业界得到了广泛认证。对于手机产品,AI正快速补充和替代传统手机ISP(Image signal processing)中的痛点难点,例如可进行AI-based去噪,动态范围增强,超分辨,超级夜景,甚至AI ISP等。
提交说明
1. 参赛者需要根据举办方提供的10张noisy图片提交相应10张denoise图片存放至文件夹“data”下,命名方式为denoise0.dng至denoise9.dng,注意上传denoise RAW图值域为[black_level, white_level] = [1024,16383],可参照baseline代码;
2. 参赛者需要提交模型文件和参数文件至文件夹“algorithm/models/”下,模型文件命名方式为network.py,参数文件命名pytorch对应model.pth,tensorflow对应model.h5。模型参数文件大小限制为50M;
3. 若使用非AI方法,算法文件提交至以上相同路径,文件命名为alg.py;
4. 参赛者需要提交文档报告阐述所使用方法,文档存放在algorithm二级目录下;
5. data和algorithm按照二级目录结构进行放置,将二级目录放置于命名为result的一级目录内,将一级目录result压缩成.zip格式上传;

赛题简介本次题目围绕手机图片RAW域去噪问题,参赛者算法方案使用基于AI或传统图像处理算法均可。
比赛目标是提升举办方提供给参赛者10张noisy图片的PSNR和SSIM指标。为了方便参赛者轻松上手流程,举办方为参赛者提供baseline代码示例,以及training dataset(200张图片)以帮助参赛者更好地提升算法性能。根据参赛者所提交算法的原创性,额外有5% bonus分数浮动。
比赛排名 55/1159

项目参考 论文: Simple Baselines for Image Restoration
参考:Simple Baselines for Image Restoration
单位:旷视
代码:https://github.com/megvii-research/NAFNet
论文:https://arxiv.org/abs/2204.0467
项目介绍:
一、网络结构:
1.1使用类Unet结构:
如下图,Unet 网络结构是对称的,形似英文字母 U 所以被称为 Unet。通过拼接的方式将不同层次的特征进行通道拼接。其中网络中主要使用了NAFBlock块。U-Net和FCN非常的相似,U-Net比FCN稍晚提出来,但都发表在2015年,和FCN相比,U-Net的第一个特点是完全对称,也就是左边和右边是很类似的,而FCN的decoder相对简单,只用了一个deconvolution(反卷积)的操作,之后并没有跟上卷积结构。第二个区别就是skip connection,FCN用的是加操作(summation),U-Net用的是叠操作(concatenation)。这些都是细节,重点是它们的结构用了一个比较经典的思路,也就是编码和解码(encoder-decoder),早在2006年就被Hinton大神提出来发表在了nature上.
当时这个结构提出的主要作用并不是分割,而是压缩图像和去噪声。输入是一幅图,经过下采样的编码,得到一串比原先图像更小的特征,相当于压缩,然后再经过一个解码,理想状况就是能还原到原来的图像。这样的话我们存一幅图的时候就只需要存一个特征和一个解码器即可。这个想法我个人认为是很漂亮了。同理,这个思路也可以用在原图像去噪,做法就是在训练的阶段在原图人为的加上噪声,然后放到这个编码解码器中,目标是可以还原得到原图。
后来把这个思路被用在了图像分割的问题上,也就是现在我们看到的U-Net结构,在它被提出的三年中,有很多很多的论文去讲如何改进U-Net或者FCN,不过这个分割网络的本质的拓扑结构是没有改动的。举例来说,ICCV上凯明大神提出的Mask RCNN. 相当于一个检测,分类,分割的集大成者,我们仔细去看它的分割部分,其实使用的也就是这个简单的FCN结构。说明了这种“U形”的编码解码结构确实非常的简洁,并且最关键的一点是好用。
采用Unet的好处我感觉是:网络层越深得到的特征图,有着更大的视野域,浅层卷积关注纹理特征,深层网络关注本质的那种特征,所以深层浅层特征都是有格子的意义的;另外一点是通过反卷积得到的更大的尺寸的特征图的边缘,是缺少信息的,毕竟每一次下采样提炼特征的同时,也必然会损失一些边缘特征,而失去的特征并不能从上采样中找回,因此通过特征的拼接,来实现边缘特征的一个找回。
最后,将网络输出和input做加和,这样实际上是用网络做噪声的预测,想比直接输出图像,输出噪声的实际效果好,个人认为,如果输出的是图像,那么即使用unet结构,在进行conv、layernormal过程中还会造成图像的细节特征损失,对于生成的图像细节方面会差一些。总之,我认为直接预测图像的task会比预测噪声的难度大。
下图1是本次设计的图像去噪网络结构:
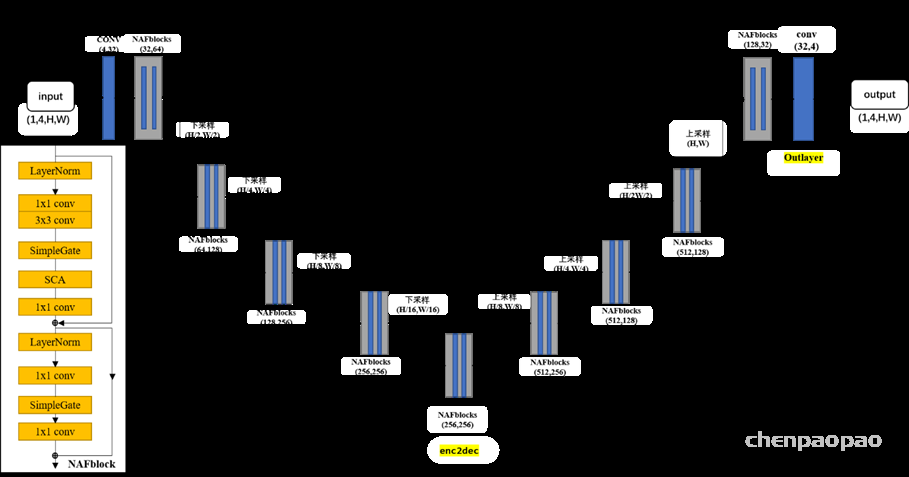
Figure 1 NFnet网络结构
二、NAFBlock块
(使用论文Simple Baselines for Image Restoration中的NAFBlock模块)
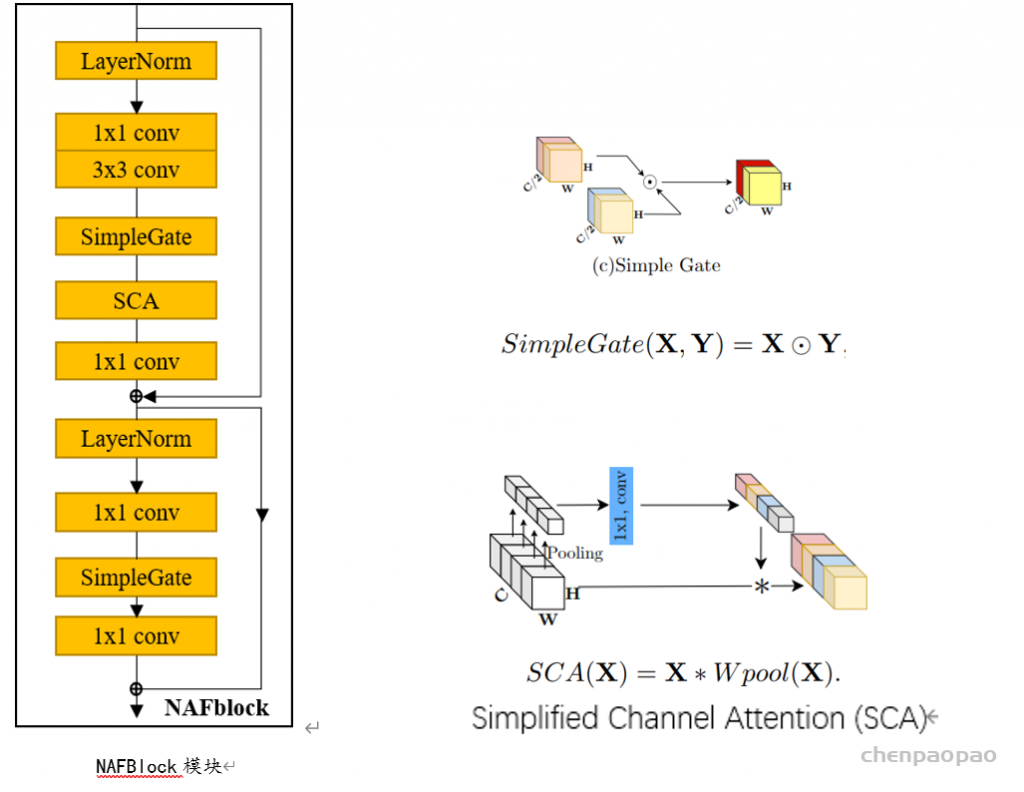
NAFBlock结构介绍:
- Normalization:Layer Normalization
- 加速训练(可以使用更大的learning rate)
- 防止exploding/vanishing gradients.
- 减小参数的initialization对训练的影响
- 提高训练效果
- layerNorm关注整幅图,也没有超过单张的范围,LN将每个训练样本都归一化到了相同的分布上,某种意义上避免了平滑
对于Normalization,文章采用了Transformer里被通常采用的LayerNorm,并通过实验发现其能提点。其实传统意义上,除了早期的方法,底层视觉一般是不太会增加归一化层,认为其会降点而且让图像模糊,我个人理解这可能和BatchNorm的特性有关,一方面BatchNorm本身训练测试阶段由于统计量不同,就会导致领域不适应问题。另外不同于high-level task倾向于寻找一致性表示,底层视觉的任务与之相反,往往是倾向于学习图片特定性以增强细节的恢复效果(比如之前有人通过捕获图像分布(正态分布)的sigma以增强边缘区域的效果),batchNorm由于是batch内做attention,其实很容易将其他图片的信息引入,忽略了恢复图像的特定信息,导致性能下降。所以之前底层视觉里面用的比较多的norm是instance Norm(比较多的是在风格迁移,图像恢复这边有HI-Net就是用IN),因为只关注同一个图片同一channel内的信息,所以某种意义上避免了平滑,layerNorm关注整幅图,也没有超过单张的范围,所以能够work还是蛮make sense的。
归一化技术在high-level任务中已被广泛应用,但在low-level任务中应用极少。但是,依托于Transformer,LN得到了越来越多的应用。基于该事实,我们猜想:LN可能是达成SOTA复原器的关键,故在上述模块中添加了LN(见上面图示)。LN的引入使得训练更平滑,甚至可以将学习率放大10倍。更大的学习率可以带来显著性能提升。
在Transformer中,数据过Attention层和FFN层后,都会经过一个Add & Norm处理。其中,Add为residule block(残差模块),数据在这里进行residule connection(残差连接)。而Norm即为Normalization(标准化)模块。Transformer中采用的是Layer Normalization(层标准化)方式。
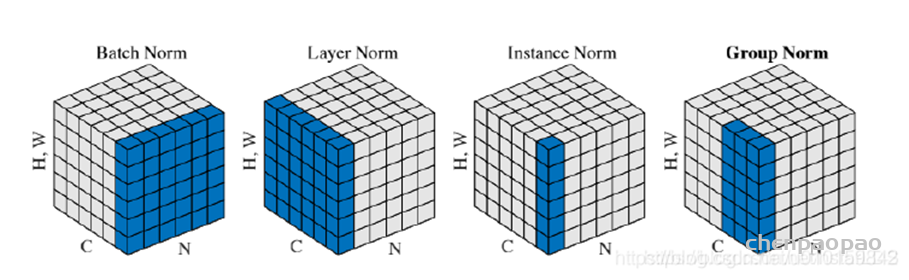
在图片视频分类等特征提取网络中大多数情况BN效果优于IN,在生成式类任务中的网络IN优于BN。
BN适用于判别模型中,比如图片分类模型。因为BN注重对每个batch进行归一化,从而保证数据分布的一致性,而判别模型的结果正是取决于数据整体分布。但是BN对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布;
IN适用于生成模型中,比如图片风格迁移。因为图片生成的结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,在风格迁移中使用Instance Normalization不仅可以加速模型收敛,并且可以保持每个图像实例之间的独立。
- Activation:simple gate 引入非线性
(对特征进行了channel-split,分成两个C/2个通道的特征,并相乘)
尽管ReLU是最常用的激活函数,现有SOTA方案中采用GELU进行代替。由于GELU可以保持降噪性能相当且大幅提升去模糊性能,故我们采用GELU替代ReLU,但作者认为 GELU太复杂:因此提出了简化版的GELU。
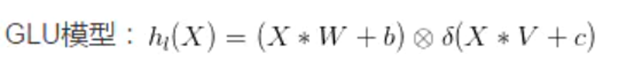

作者也是从High-Level Task 找到的灵感,将现在大火的GLU和GELU引入并做了简化。 文章先给出了GLU的数学形式:,之后文章认为GELU是GLU的一种特殊情况(这个可以看原文,比较直观),于是只关注于GLU本身。虽然GLU可以提升模型效果,但是也会增加计算量,于是作者为降低计算量,所以对GLU进行了简化。GLU的计算量主要来自于sigmoid和映射函数(上图)。因为GLU本身是具备非线性这一性质的(我个人理解是(元素积)element-wise multiplication引入的),所以文章删除了sigmoid。为了减少计算量,映射函数更是直接删除,同时对特征进行了channel-split,分成两个C/2个通道的特征,并相乘,具体是上面的图。 由于这个简化的simple gate引入了非线性,所以常用的ReLU自然也不需要再加入到网络中了,这也就是为什么这篇文章提出的方法叫做 Nonlinear Activation Free Network (NAFNet)。
补充:channel-split 思想来自Channel-Wise Convolutions
【ChannelNets: Compact and Efficient Convolutional Neural Networks via Channel-Wise Convolutions:论文提出channel-wise卷积的概念,将输入输出的维度连接进行稀疏化而非全连接,区别于分组卷积的严格分组,让卷积在channel维度上进行滑动,能够更好地保留channel间的信息交流。基于channel-wise卷积的思想,论文进一步提出了channel-wise深度可分离卷积,并基于该结构替换网络最后的全连接层+全局池化的操作,搭建了ChannelNets。Channel-wise卷积的核心在于输入和输出连接的稀疏化,每个输出仅与部分输入相连,概念上区别于分组卷积,没有对输入进行严格的区分,而是以一定的stride去采样多个相关输入进行输出(在channel维度滑动),能够降少参数量以及保证channel间一定程度的信息流。】
GELU与GLU的实现可以发现:GELU是GLU的一种特例。我们从另一个角度猜想:GLU可视作一种广义激活函数,它是可以用于替代非线性激活函数。提出了一种简化版GLU变种(见上图):直接将特征沿通道维度分成两部分并相乘。
- Simplified Channel Attention
注意力机制可以说是近年来最火热的研究领域之一,其有效性得到了充分的验证
通过保留通道注意力的两个重要作用(全局信息聚合、通道信息交互),我们提出了如上图的简化版通道注意力。
对于attention,上述的simple Gate操作虽然可以有效减少计算量,但是作者认为channel-wise的操作(导致channel间的信息阻隔)丢失了channel之间的信息,所以在后面的attention上,作者使用了简化的channel attention,减少计算量的同时引入channel的交互,这个看图就可以直接明白。这个其实对我个人有点启发,因为从swin到restormer(用于高分辨率图像恢复的高效Transformer),多少能隐隐的感受到,其实tranformer的全局attention可能没有想象的那么重要,swin里切成window-based仍然可以保持很好的效果,restormer里面干脆放弃了spatial的MSA(多头self注意力)而使用深度卷积和传统的spatial attention(空间注意力),有可能CA对恢复任务更重要一些(有待证明)。
4、1*1卷积
1×1卷积实际上是对每个像素点,在不同的channels上进行线性组合(信息整合),且保留了图片的原有平面结构,调控depth,从而完成升维或降维的功能。
最后,有了上述的基本改进,并将上面的模块组合在了一起。
其他说明:
1、参考论文:
Simple Baselines for Image Restoration,是目前去噪效果比较好的网络。
Github代码实现:https://github.com/megvii-research/NAFNet
2、损失函数:
使用L1损失、mse损失(Fourier_loss)、
psnrloss【参考https://github.com/megvii-research/NAFNet中提供的psnrloss】、以及相邻像素损失
L1损失:用来预测generate和real 之间的像素级别误差
MSE损失(Fourier_loss):计算generate和real的fft变换后的频域信息。
参考论文:Fouier Space Losses for Efficient Perceptual Image Super-Resolution,在改论文中利用transformer实现图像去雨,提出了Fourier Space Losses,单张图像超分方法在重构高分辨率图像时缺失高频细节。这通常通过有监督的训练来执行,其中使用已知核对真实图像 y 进行下采样,例如 bicubic,得到LR输入图像x。虽然这种方法能够在某种应用中尽可能恢复频率信息,但高频信息却难以恢复,容易出现模糊情况。近几年,许多研究者使用GAN,用于学习高频空间的分布。丢失了频谱空间的高频信息。因此,文章提出了一种用于频域的损失函数。首先,将真实图像和生成图像经过Hann window预处理。接着,计算傅里叶频域损失函数,包括L1范数度量的频谱差异,以及相位角差异
对generate和real进行fft变换,时域变换到频域
参考代码:https://github.com/zzksdu/fourierSpaceLoss/blob/master/Fourier_loss.py
Psnrloss:参考NAFnet。
相邻像素损失:
使用L1loss,比较相邻行之间的像素loss:
Step1:
对gt:求相邻行像素的l1损失,记为 gloss。
Step2:
对denoise求相邻行像素的l1损失,记为 dloss。
Step3:对gloss和dloss求L1损失。
【因为图像在进行预处理时候进行了行列交织,所以再求此损失时候,需要先对图像进行复原,再求相邻像素损失】

3、优化函数 SGD or Adam
SGD虽然训练时间更长,容易陷入鞍点,但是在好的初始化和学习率调度方案的情况下,结果更可靠。SGD现在后期调优时还是经常使用到,但SGD的问题是前期收敛速度慢。SGD前期收敛慢的原因: SGD在更新参数时对各个维度上梯度的放缩是一致的,并且在训练数据分布极不均衡时训练效果很差。而因为收敛慢的问题应运而生的自适应优化算法Adam、AdaGrad、RMSprop 等,但这些自适应的优化算法泛化能力可能比非自适应方法更差,虽然可以在训练初始阶段展现出快速的收敛速度,但其在测试集上的表现却会很快陷入停滞,并最终被 SGD 超过。 实际上,在自然语言处理和计算机视觉方面的一些最新的工作中SGD(或动量)被选为优化器,其中这些实例中SGD 确实比自适应方法表现更好。
主流认为:Adam等自适应学习率算法对于稀疏数据具有优势,且收敛速度很快;但精调参数的SGD(+Momentum)往往能够取得更好的最终结果。
Improving Generalization Performance by Switching from Adam to SGD 提出了Adam+SGD 组合策略。前期用Adam,享受Adam快速收敛的优势;后期切换到SGD,慢慢寻找最优解。这一方法以前也被研究者们用到,不过主要是根据经验来选择切换的时机和切换后的学习率。这篇文章把这一切换过程傻瓜化,给出了切换SGD的时机选择方法,以及学习率的计算方法,效果看起来也不错。
torch.optim.lr_scheduler.StepLR:这是比较常用的等间隔动态调整方法,该方法的原理为:每隔step_size个epoch就对每一参数组的学习率按gamma参数进行一次衰减。
3、训练结果:
Batch Size=1,梯度变来变去,非常不准确,网络很难收敛。
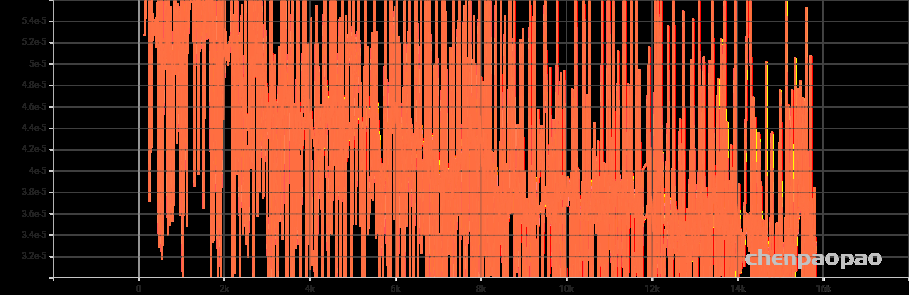
Figure 1 loss损失函数值
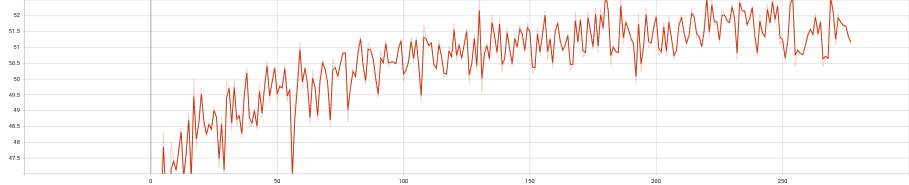
Figure 2 训练过程中的psnr测试值
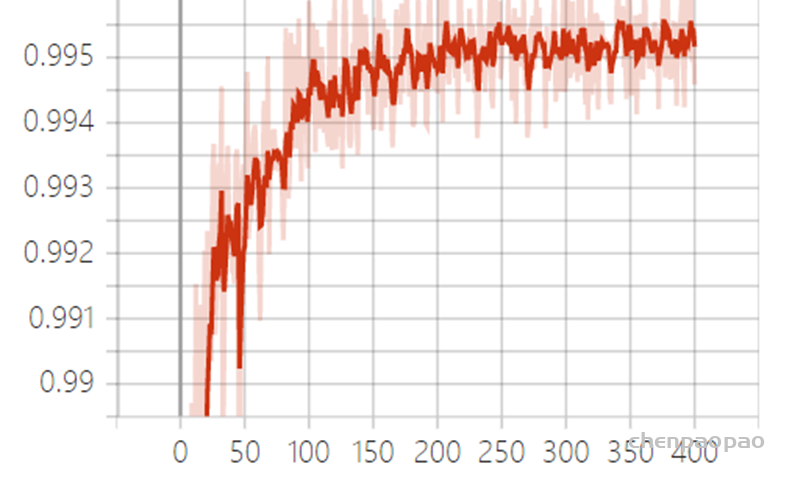
Figure 3 训练过程SSIM 测试值
4、数据集处理
对数据进行加噪处理、数据随机翻转等预处理。
因为显存有限,所以将img(4,1736,2312)裁剪为 1736/4, 2312/4的大小送入网络中进行训练。在进行验证/生成去噪图片时,同样裁剪噪声图片分批送入网络,注意,裁剪需要多裁剪20个tensor,然后拼接成完整图片并写入文件,这样拼接成的图片不会有分割线 。
[加噪处理效果不好,我使用的噪声正则项是torch正态分布,原本任务就是去噪,raw域噪声的分布应该跟正态分布不贴合,增加噪声后可能会导致模型效果变差。
数据翻转:这里需要注意label和noise应该使用相同的seed。
因为显存有限,需要裁剪图像,这里我认为如果只是简单的裁剪图像,会导致裁剪前后的相邻像素信息损失,因此我借鉴了unet:Overlap-tile 重叠切片的思想,同时,在生成test图像时候,也要对其进行拼接。]

5、使用加载模型:
from network import NFnet3
net = NFnet3()
net.load_state_dict(torch.load(modelpath))
6、test数据集去噪结果:




去噪结果思考:
对于噪声比较小的图像,去噪效果比较好,而且不会破坏原有图像的结构,但对于噪声特别大的图像:纹理效果不是很好,一些细节处理的不太好。
此外,我认为,如果输入裁剪后的图像能在大一些,效果应该会好一些。或者现在小的图像进行预训练,在使用大图像进行微调,会好一些。

参考论文:
[1] Chen L, Chu X, Zhang X, et al. Simple Baselines for Image Restoration[J]. arXiv preprint arXiv:2204.04676, 2022.
[2] Huang H, Lin L, Tong R, et al. Unet 3+: A full-scale connected unet for medical image segmentation[C]//ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020: 1055-1059.
[3] Wang Y, Huang H, Xu Q, et al. Practical deep raw image denoising on mobile devices[C]//European Conference on Computer Vision. Springer, Cham, 2020: 1-16.
[4] Ba, J.L., Kiros, J.R., Hinton, G.E.: Layer normalization. arXiv preprintarXiv:1607.06450 (2016)
[5] Chen, H., Wang, Y., Guo, T., Xu, C., Deng, Y., Liu, Z., Ma, S., Xu, C., Xu, C., Gao,W.: Pre-trained image processing transformer. In: Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition. pp. 12299–12310 (2021)
[6] Cheng, S., Wang, Y., Huang, H., Liu, D., Fan, H., Liu, S.: Nbnet: Noise basis learning for image denoising with subspace projection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4896–4906 (2021)
[7] Language Modeling with Gated Convolutional Networks
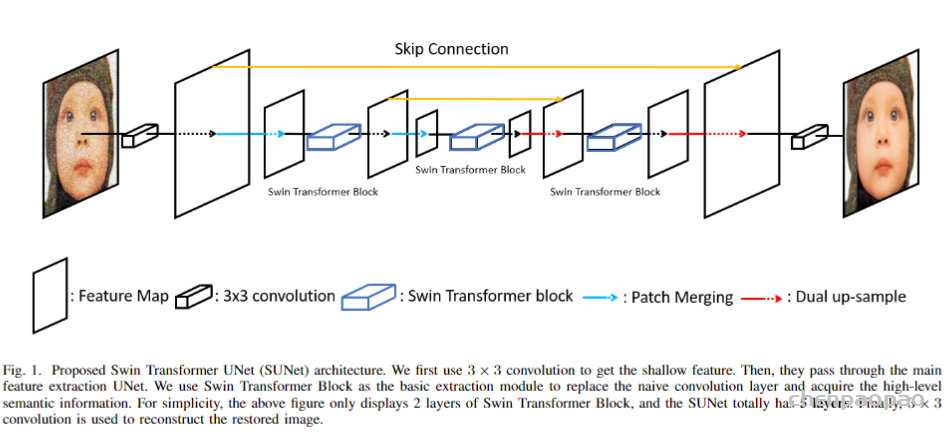
更新:最近Swin Transformer的提出,就有人利用该结构和unet,实现了图像去噪:
SUNet: Swin Transformer UNet for Image Denoising
https://arxiv.org/abs/2202.14009