
GitHub: https://github.com/facebookresearch/mae
PAPER: https://arxiv.org/abs/2111.06377
Abstract
恺明提出一种用于计算机视觉的可扩展自监督学习方案Masked AutoEncoders(MAE)。所提MAE极为简单:对输入图像的随机块进行mask并对遗失像素进行重建。它基于以下两个核心设计:
- 我们设计了一种非对称编解码架构,其中解码器仅作用于可见块(无需mask信息),而解码器则通过隐表达与mask信息进行原始图像重建;
- 我们发现对输入图像进行高比例mask(比如75%)可以产生一项重要且有意义的自监督任务。
上述两种设计促使我们可以更高效的训练大模型:我们加速训练达3x甚至更多,同时提升模型精度。所提方案使得所得高精度模型具有很好的泛化性能:仅需ImageNet-1K,ViT-Huge取得了87.8%的top1精度 。下游任务的迁移取得了优于监督训练的性能,证实了所提方案的可扩展能力。
极致精简版
用下面几句话来简单说明下这篇文章:
- 恺明出品,必属精品!MAE延续了其一贯的研究风格:简单且实用;
- MAE兴起于去噪自编码,但兴盛于NLP的BERT。那么是什么导致了MAE在CV与NLP中表现的差异呢?这是本文的出发点。
- 角度一:CV与NLP的架构不同。CV中常采用卷积这种具有”规则性“的操作,直到近期ViT才打破了架构差异;
- 角度二:信息密度不同。语言是人发明的,具有高语义与信息稠密性;而图像则是自然信号具有重度空间冗余:遗失块可以通过近邻块重建且无需任何全局性理解。为克服这种差异,我们采用了一种简单的策略:高比例随机块掩码,大幅降低冗余。
- 角度三:自编码器的解码器在重建方面的作用不同。在视觉任务方面,解码器进行像素重建,具有更低语义信息;而在NLP中,解码器预测遗失的词,包含丰富的语义信息。
- 基于上述三点分析,作者提出了一种非常简单的用于视觉表达学习的掩码自编码器MAE。
- MAE采用了非对称的编解码器架构,编码器仅作用于可见图像块(即输入图像块中一定比例进行丢弃,丢弃比例高达75%)并生成隐式表达,解码器则以掩码token以及隐式表达作为输入并对遗失块进行重建。
- 搭配MAE的ViT-H取得了ImageNet-1K数据集上的新记录:87.8%;同时,经由MAE预训练的模型具有非常好的泛化性能。
Method
所提MAE是一种非常简单的自编码器方案:基于给定部分观测信息对原始信号进行重建 。类似于其他自编码器,所提MAE包含一个将观测信号映射为隐式表达的编码器,一个用于将隐式表达重建为原始信号的解码器。与经典自编码器不同之处在于:我们采用了非对称设计,这使得编码器仅依赖于部分观测信息(无需掩码token信息),而轻量解码器则接与所得隐式表达与掩码token进行原始信号重建(可参见下图)。
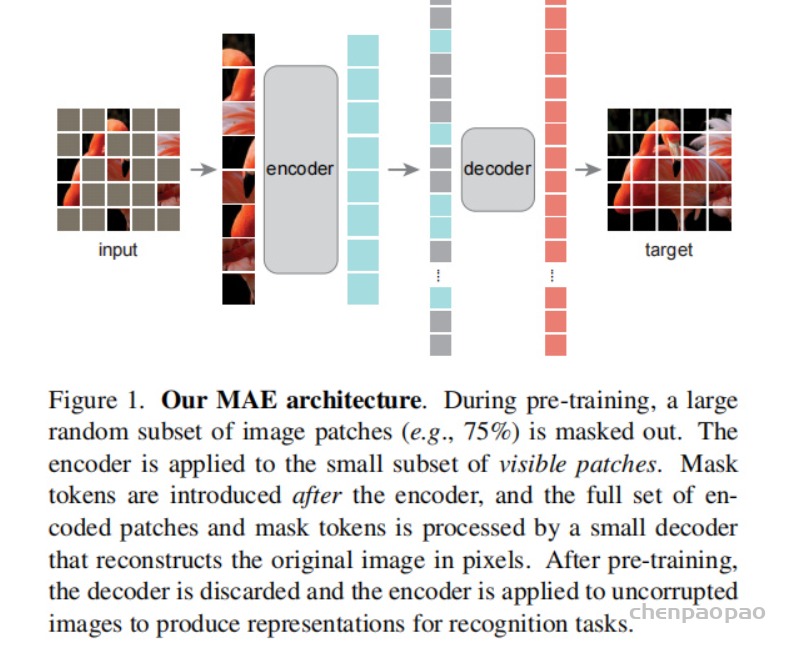
Masking 参考ViT,我们将输入图像拆分为非重叠块,然后采样一部分块并移除其余块(即Mask)。我们的采样策略非常简单:服从均匀分布的无重复随机采样 。我们将该采样策略称之为“随机采样”。具有高掩码比例的随机采样可以极大程度消除冗余,进而构建一个不会轻易的被近邻块推理解决的任务 (可参考下面图示)。而均匀分布则避免了潜在的中心偏置问题。

MAE Encoder MAE中的编码器是一种ViT,但仅作用于可见的未被Mask的块。类似于标准ViT,该编码器通过线性投影于位置嵌入对块进行编码,然后通过一系列Transformer模块进行处理。然而,由于该编解码仅在较小子集块(比如25%)进行处理,且未用到掩码Token信息。这就使得我们可以训练一个非常大的编码器 。
MAE Decoder MAE解码器的输入包含:(1) 编码器的输出;(2) 掩码token。正如Figure1所示,每个掩码Token共享的可学习向量,它用于指示待预测遗失块。此时,我们对所有token添加位置嵌入信息。解码器同样包含一系列Transformer模块。
注:MAE解码器仅在预训练阶段用于图像重建,编码器则用来生成用于识别的图像表达 。因此,解码器的设计可以独立于编码设计,具有高度的灵活性。在实验过程中,我们采用了窄而浅的极小解码器,比如默认解码器中每个token的计算量小于编码器的10% 。通过这种非对称设计,token的全集仅被轻量解码器处理,大幅减少了预训练时间。
Reconstruction target 该MAE通过预测每个掩码块的像素值进行原始信息重建 。解码器的最后一层为线性投影,其输出通道数等于每个块的像素数量。编码器的输出将通过reshape构建重建图像。损失函数则采用了MSE,注:类似于BERT仅在掩码块计算损失。
我们同时还研究了一个变种:其重建目标为每个掩码块的规范化像素值 。具体来说,我们计算每个块的均值与标准差并用于对该块进行归一化,最后采用归一化的像素作为重建目标提升表达能力。
Simple implementation MAE预训练极为高效,更重要的是:它不需要任何特定的稀疏操作。实现过程可描述如下:
- 首先,我们通过线性投影与位置嵌入对每个输入块生成token;
- 然后,我们随机置换(random shuffle)token序列并根据掩码比例移除最后一部分token;
- 其次,完成编码后,我们在编码块中插入掩码token并反置换(unshuffle)得到全序列token以便于与target进行对齐;
- 最后,我们将解码器作用于上述全序列token。
正如上所述:MAE无需稀疏操作。此外,shuffle与unshuffle操作非常快,引入的计算量可以忽略。