
前言 通常convolution和self-attention被认为是表征学习的两个有力且相互对等的不用方法。在本文中,作者发掘了两者之间的潜在关系,两者的大部分计算实际上是相通的。
作者将K x K 的传统卷积分解为k方个1 x 1的卷积,然后将self-attention模块中queries、 keys等解释为多个1 x 1的卷积,然后计算注意力权重和聚合值。
该模型在图像识别和down streamtasks取得了优异的结果。
论文题目:On the Integration of Self-Attention and Convolution
论文链接:https://openaccess.thecvf.com/content/CVPR2022/papers/Pan_On_the_Integration_of_Self-Attention_and_Convolution_CVPR_2022_paper.pdf
源代码:https://github.com/LeapLabTHU/ACmix https://gitee.com/mindspore/models.
卷积神经网络与自注意力在图像识别、语义分割等方面取得了飞速的发展。随着transformers的出现,attention-based的方法取得了更加优异的性能。尽管两种方法都取得了成功,但是两者遵循不同的设计思路。前者在特征图中共享权重,后者通过动态计算像素间的相似度函数从而能够捕获不同区域的特征进而获得更多的特征。
在一些工作中,研究人员仅使用self-attention来独立地构建视觉任务模型,这一做法的有效性在一些任务中得到了验证,其完全可以代替卷积操作。Vision Transformer表明只要给定足够的数据,就可以获得优异的结果,这一做法在点云分割等其他视觉任务上也取得了不错的效果。Hu等人提出自适应确定聚合的方法;Wang等人通过引入非局部块来增加感受野来比较全局像素之间的相似性;Conformer将transformer与独立的CNN结合来整合两个特征。
早期的工作从几个不同的角度探索了convolution和self-attention的组合,CBAM等证明self-attention可以作为convolution的增强;SAN等提出self-attention可以代替传统的convolution;AA-ResNet等在设计独立架构方面存在局限性。现有的方法仍将自注意力和卷积视为不同的部分,因此它们之间的关系并未得到充分利用。
本文主要贡献
1、揭示了self-attention和convolution之间的潜在关系,为了解两个模块间的关联和设计新的learning paradigms提供了新的视角。
2、self-attention和convolution的组合使得两者的功能得到整合,经验及实验证明混合模型的性能始终优于纯卷积或者自注意力模型。
方法
1、将self-attention和convolution关联起来
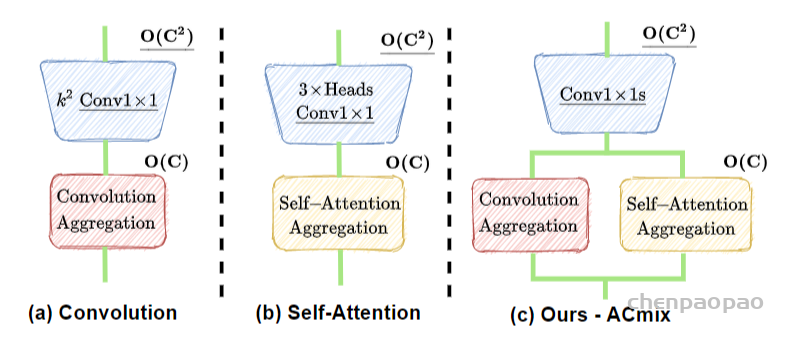
标准卷积可以分为两个部分,第一个阶段为一个特征学习模块,通过执行1 x 1的卷积共享相同的操作将特征投影到更深的空间,第二阶段对应于特征聚合的过程。作为结论,分析表明卷积和自注意力在通过1 x 1的卷积投影输入特征图实际上共享相同的操作,聚合操作是轻量级的,并不需要获取额外的学习参数。卷积和自注意力的示意图如下图所示。
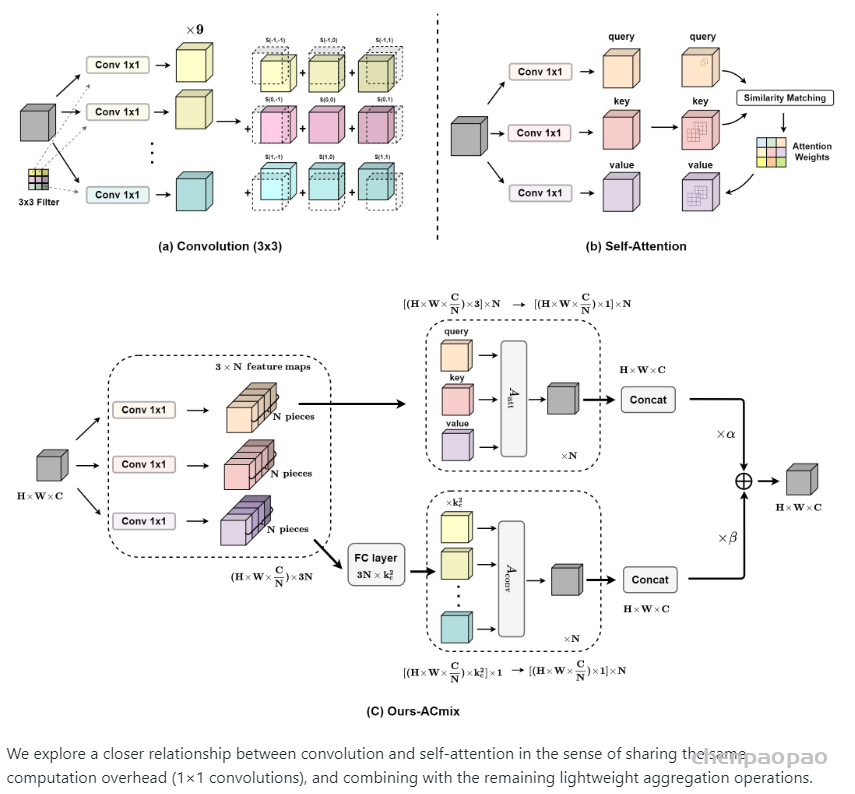
2、将self-attention和convolution进行整合
作者根据上述的分析提出ACmix模型,如下图所示:
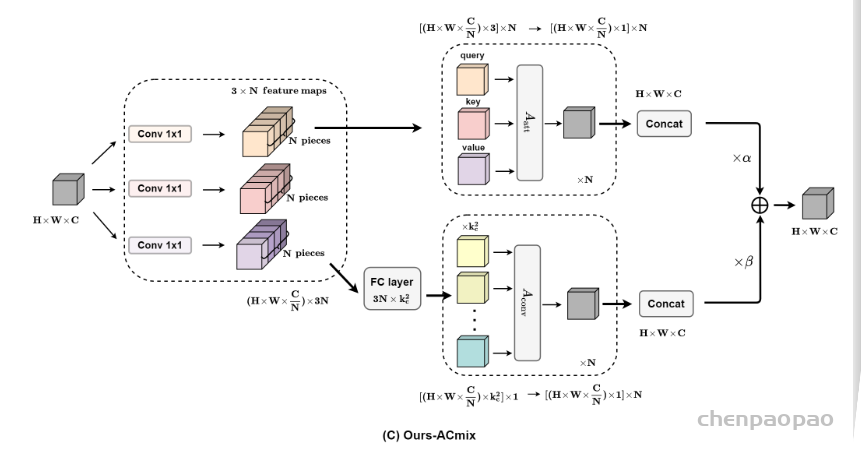
ACmix模型分为两个阶段,在阶段一,输入特征由三个1 x 1的卷积操作并被reshape成N块,由此获得丰富的3 x N的特征图;在阶段二,对于self-attention,作者将中间特征收集到N组中,每组包含三个部分特征,其中每个1 x 1卷积对应一个。通过移动和聚合生成的特征(用以下公式表达),并像传统方法一样从本地感受野中收集信息。

3、对Shift和Summation进行改进
中间特征遵循传统的卷积模块中的Shift和Summation操作,尽管这些操作在理论上是轻量级的,但是难以矢量化实现,这会极大影响计算的实际效率。作者采用了固定内核的深度卷积来解决这一问题,如下图所示。
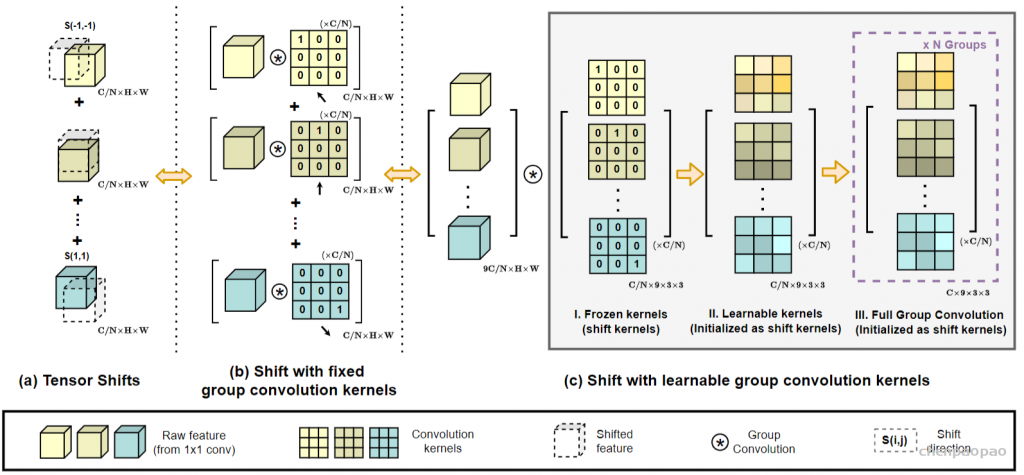

在此基础上,作者额外引入了一些配置来增强模块的灵活性,如下图所示,作者将卷积核释放为可学习的权重,对内核初始化,这不仅改善了模型容量,而且能够保持原有的能力,同时使用多组卷积内核来匹配卷积和自注意力路径的输出通道维度。
4、ACmix的计算成本
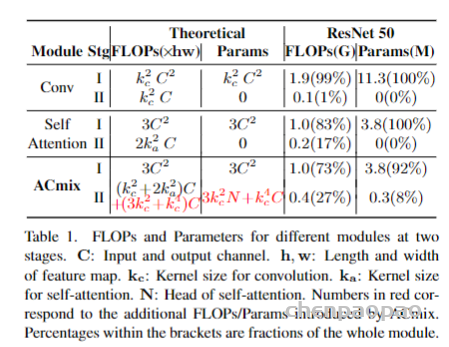
作者总结了ACmix的FLOPS和参数量,在stage1 的训练参数与self-attention相同,并且比传统的卷积更轻,在第二阶段,引入了额外的计算开销,包含轻量级的全连接层等。
5、向其他注意力模式推广
作者所提出的ACmix独立于自注意力机制,并且很容易衍生出其他变体,注意力的权重可以表示为
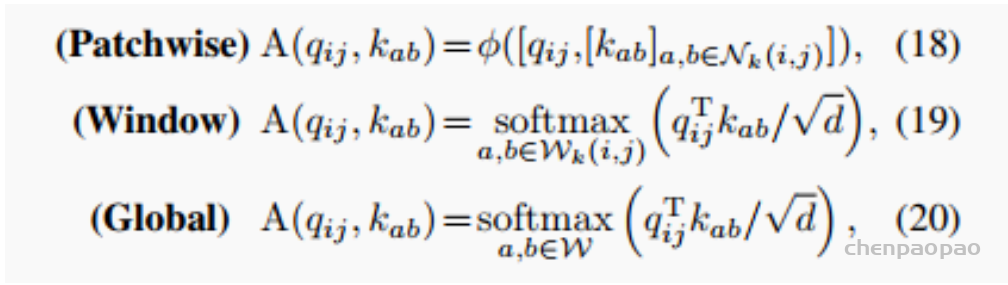
实验
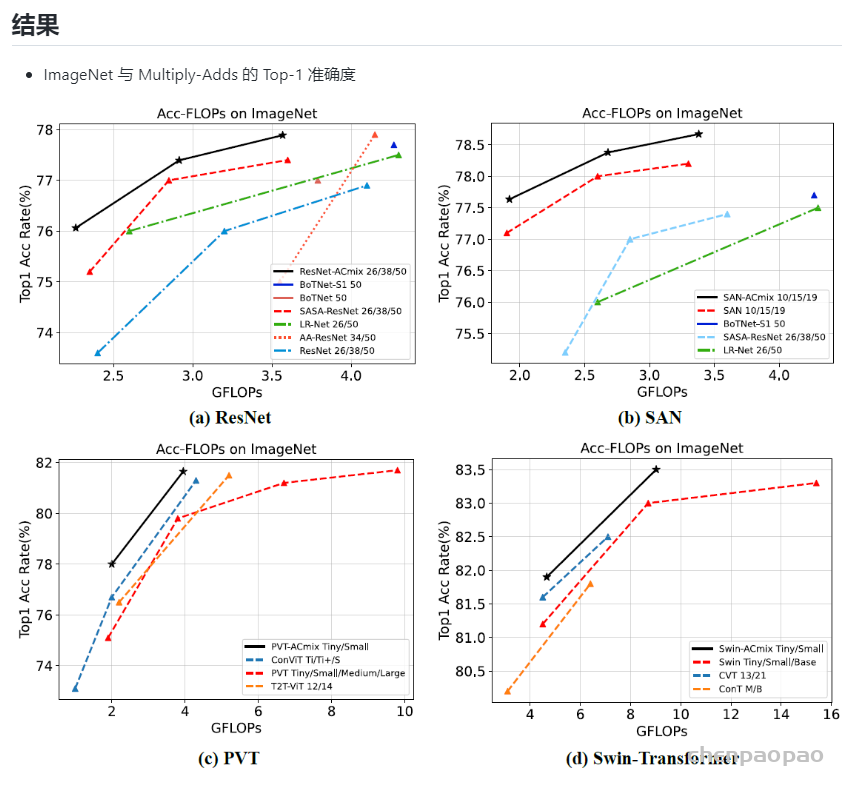
1、ImageNet分类
作者在4个baseline models上应用了ACmix,包括ResNet, SAN, PVT和 Swin-Transformer。
2、语义分割
作者在ADE20K上对比了Semantic-FPN、UperNet 两种方法
3、目标检测
在COCO benchmark上开展了实验,实验结果证实了ACmix的性能优于baseline
结论
在本文中,作者发掘了self-attention和convolution之间的潜在关系,两者的大部分计算实际上是相通的,所提的ACmix在目标检测、语义分割等多个任务上展示了优异的性能。