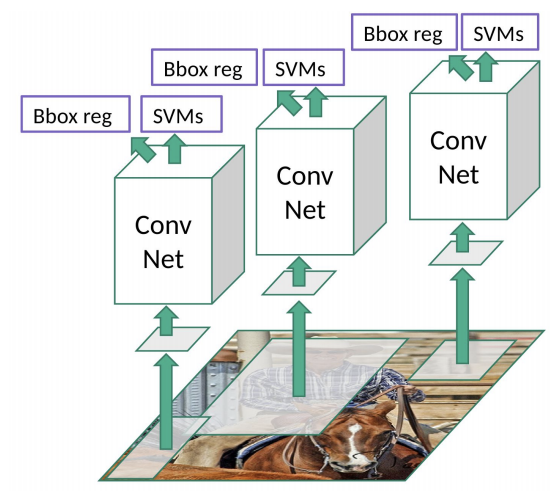
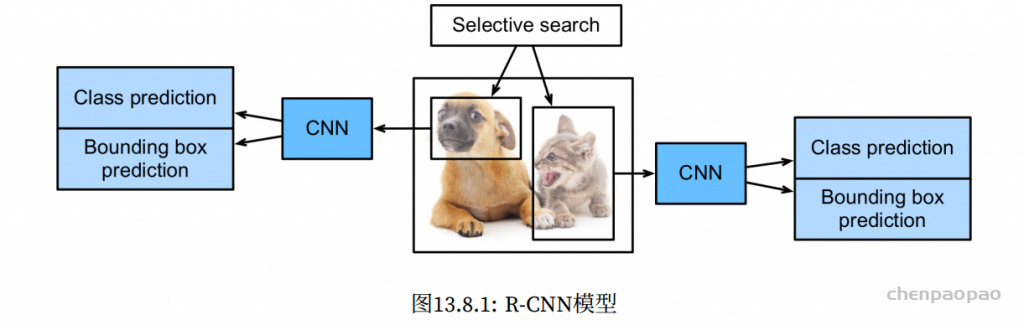
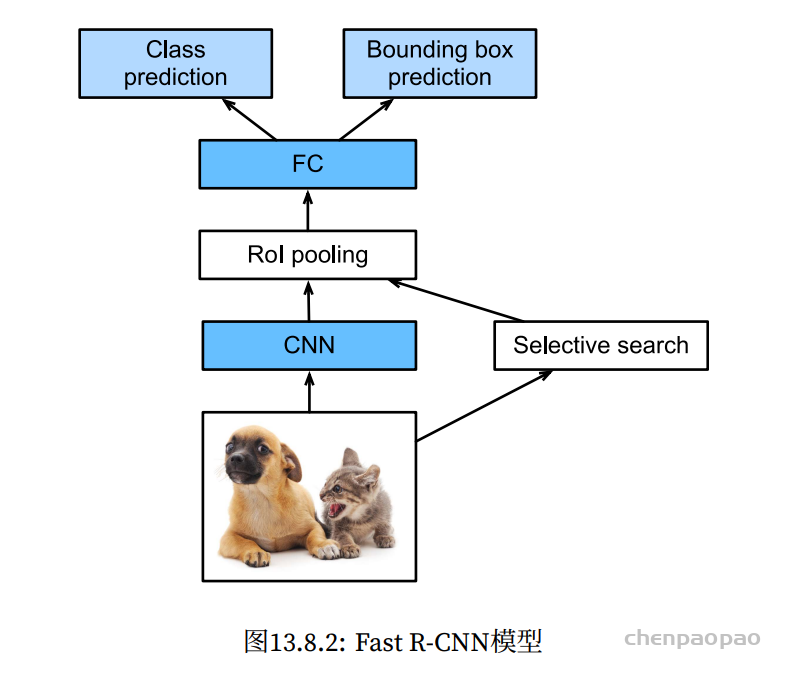
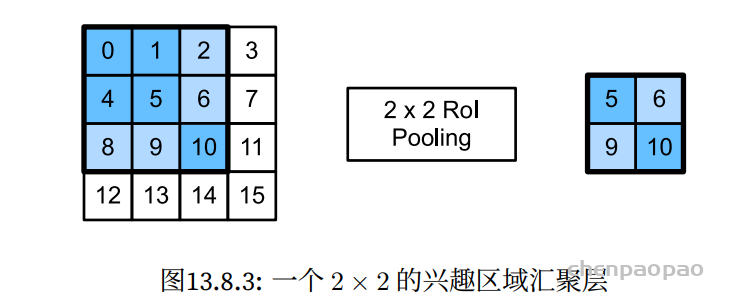
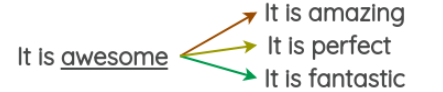
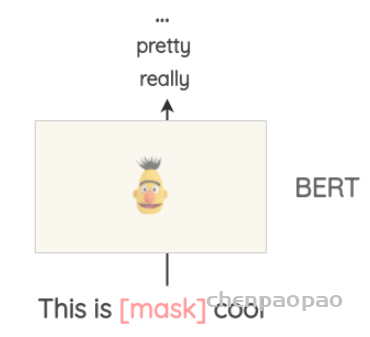
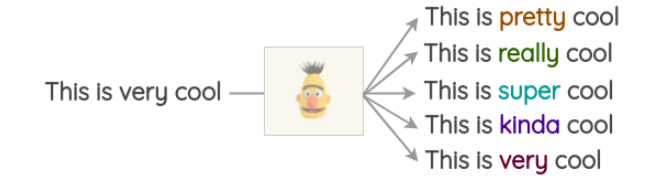
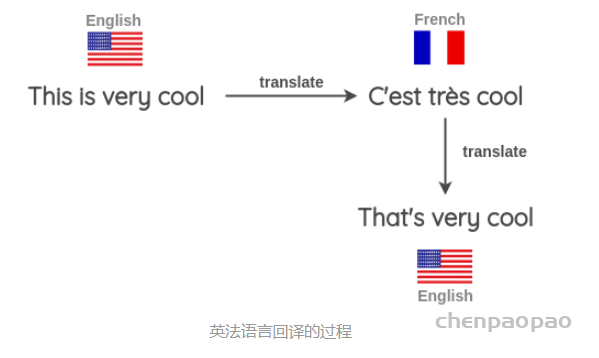
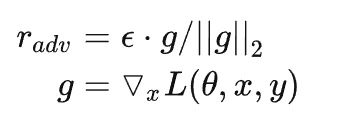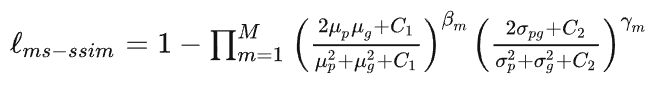class RCUBlock(nn.Module):
def __init__(self, in_planes, out_planes, n_blocks, n_stages):
super(RCUBlock, self).__init__()
for i in range(n_blocks):
for j in range(n_stages):
setattr(self, '{}{}'.format(i + 1, stages_suffixes[j]),
conv3x3(in_planes if (i == 0) and (j == 0) else out_planes,
out_planes, stride=1,
bias=(j == 0)))
self.stride = 1
self.n_blocks = n_blocks
self.n_stages = n_stages
def forward(self, x):
for i in range(self.n_blocks):
residual = x
for j in range(self.n_stages):
x = F.relu(x)
x = getattr(self, '{}{}'.format(i + 1, stages_suffixes[j]))(x)
x += residual
return
class CRPBlock(nn.Module):
def __init__(self, in_planes, out_planes, n_stages):
super(CRPBlock, self).__init__()
for i in range(n_stages):
setattr(self, '{}_{}'.format(i + 1, 'outvar_dimred'),
conv3x3(in_planes if (i == 0) else out_planes,
out_planes, stride=1,
bias=False))
self.stride = 1
self.n_stages = n_stages
self.maxpool = nn.MaxPool2d(kernel_size=5, stride=1, padding=2)
def forward(self, x):
top = x
for i in range(self.n_stages):
top = self.maxpool(top)
top = getattr(self, '{}_{}'.format(i + 1, 'outvar_dimred'))(top)
x = top + x
return x
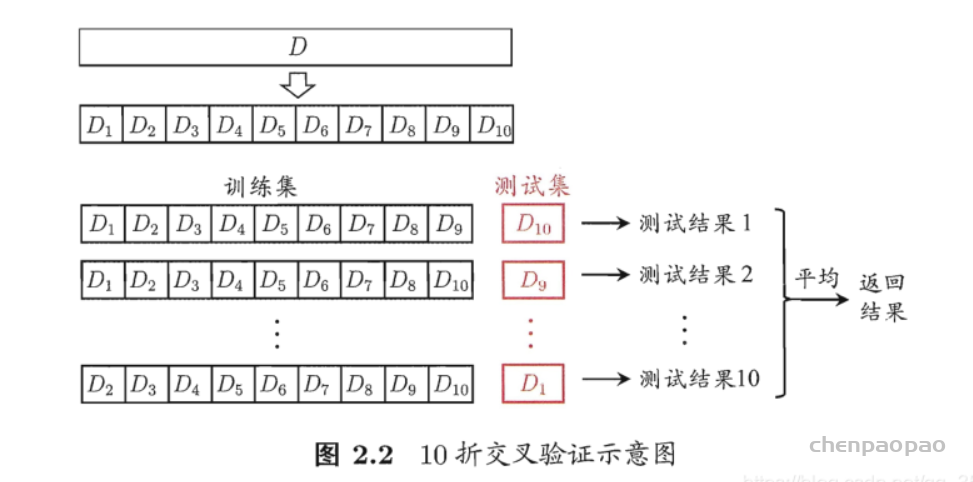
实际上就是取消了符号函数,用二范式做了一个scale,需要注意的是:这里的norm计算的是,每个样本的输入序列中出现过的词组成的矩阵的梯度norm。原作者提供了一个TensorFlow的实现 [10],在他的实现中,公式里的 x 是embedding后的中间结果(batch_size, timesteps, hidden_dim),对其梯度 g 的后面两维计算norm,得到的是一个(batch_size, 1, 1)的向量 ||g||2 。为了实现插件式的调用,笔者将一个batch抽象成一个样本,一个batch统一用一个norm,由于本来norm也只是一个scale的作用,影响不大。实现如下:
import torch
class FGM():
def __init__(self, model):
self.model = model
self.backup = {}
def attack(self, epsilon=1., emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
self.backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0 and not torch.isnan(norm):
r_at = epsilon * param.grad / norm
param.data.add_(r_at)
def restore(self, emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.backup
param.data = self.backup[name]
self.backup = {}
import torch
class PGD():
def __init__(self, model):
self.model = model
self.emb_backup = {}
self.grad_backup = {}
def attack(self, epsilon=1., alpha=0.3, emb_name='emb.', is_first_attack=False):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
if is_first_attack:
self.emb_backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0 and not torch.isnan(norm):
r_at = alpha * param.grad / norm
param.data.add_(r_at)
param.data = self.project(name, param.data, epsilon)
def restore(self, emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.emb_backup
param.data = self.emb_backup[name]
self.emb_backup = {}
def project(self, param_name, param_data, epsilon):
r = param_data - self.emb_backup[param_name]
if torch.norm(r) > epsilon:
r = epsilon * r / torch.norm(r)
return self.emb_backup[param_name] + r
def backup_grad(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
self.grad_backup[name] = param.grad.clone()
def restore_grad(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
param.grad = self.grad_backup[name]
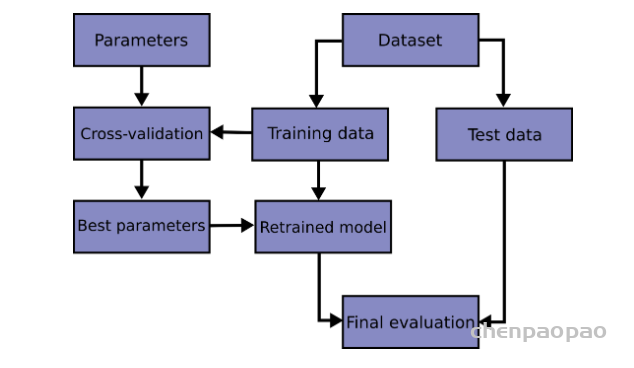
使用的时候,要麻烦一点:
pgd = PGD(model)
K = 3
for batch_input, batch_label in data:
# 正常训练
loss = model(batch_input, batch_label)
loss.backward() # 反向传播,得到正常的grad
pgd.backup_grad()
# 对抗训练
for t in range(K):
pgd.attack(is_first_attack=(t==0)) # 在embedding上添加对抗扰动, first attack时备份param.data
if t != K-1:
model.zero_grad()
else:
pgd.restore_grad()
loss_adv = model(batch_input, batch_label)
loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度
pgd.restore() # 恢复embedding参数# 梯度下降,更新参数
optimizer.step()
model.zero_grad()
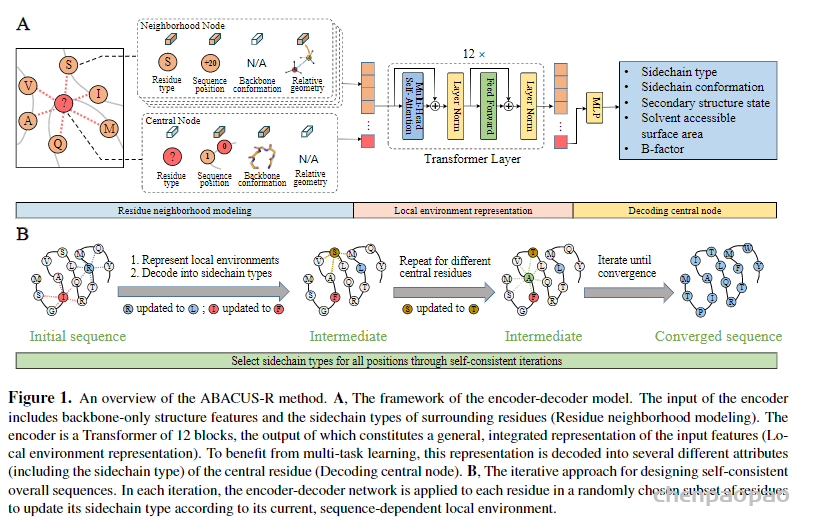
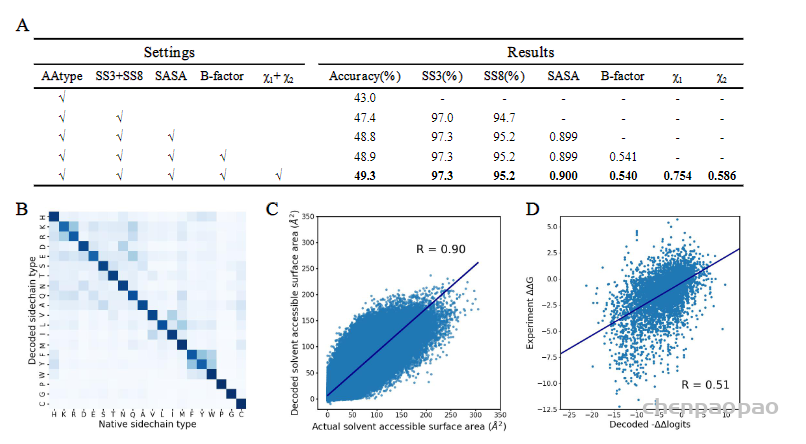
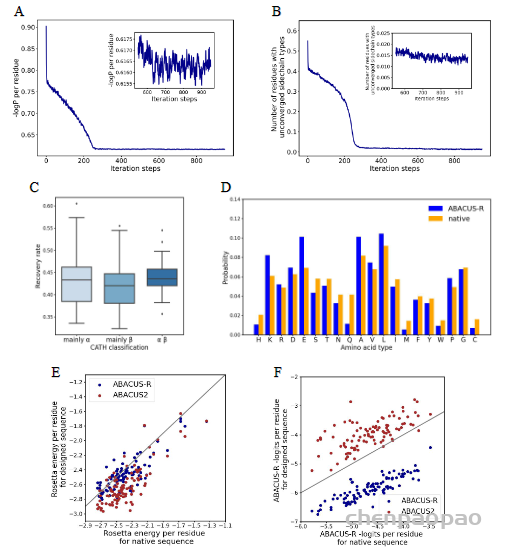
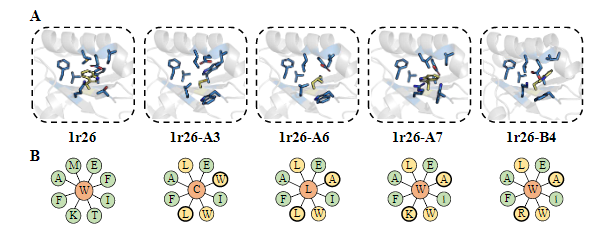
中国科学技术大学生命科学与医学部刘海燕教授、陈泉副教授团队与信息科学技术学院李厚强教授团队合作,开发了一种基于深度学习为给定主链结构从头设计氨基酸序列的算法ABACUS-R,在实验验证中,ABACUS-R的设计成功率和设计精度超过了原有统计能量模型ABACUS。相关成果以“Rotamer-Free Protein Sequence Design Based on Deep Learning and Self-Consistency”为题于北京时间2022年7月21日发表于Nature Computational Science。
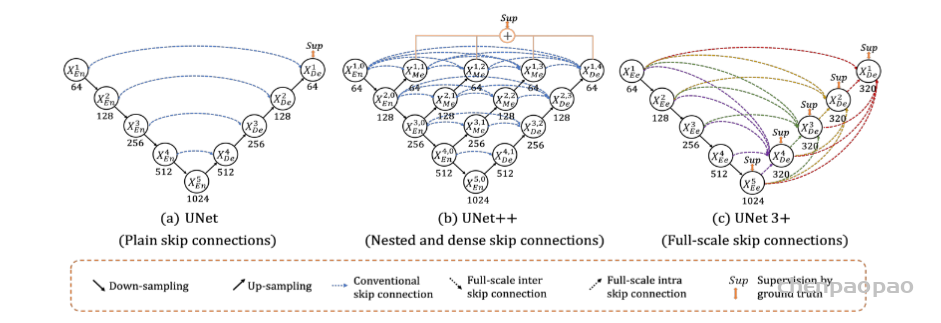
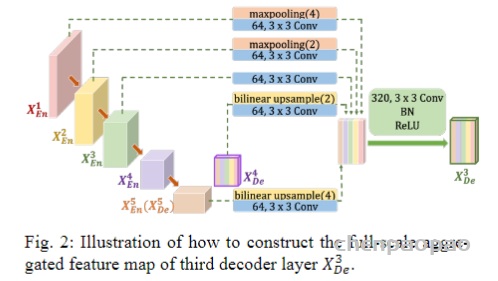
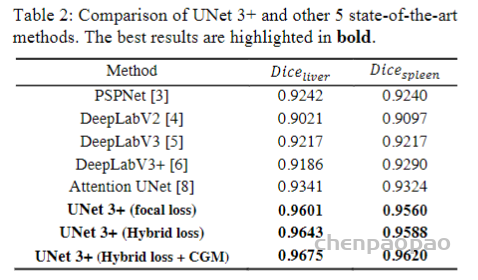
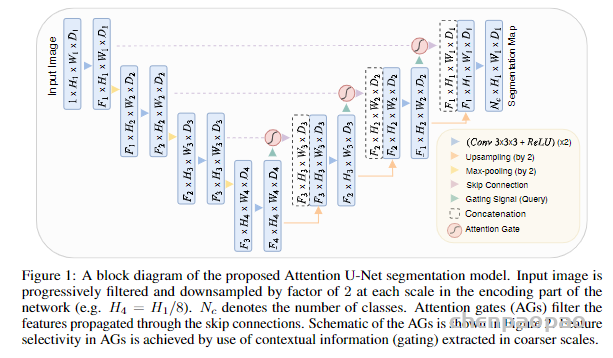
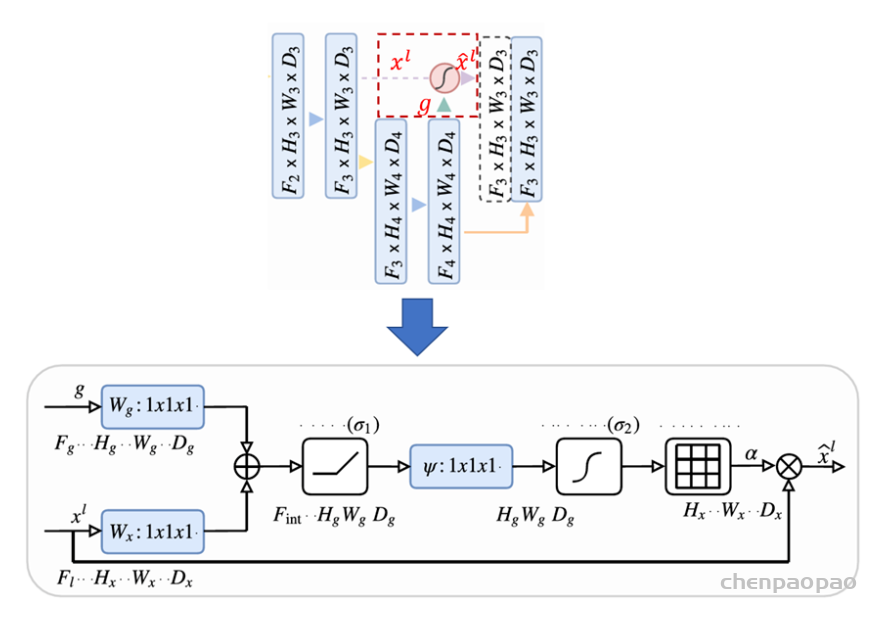
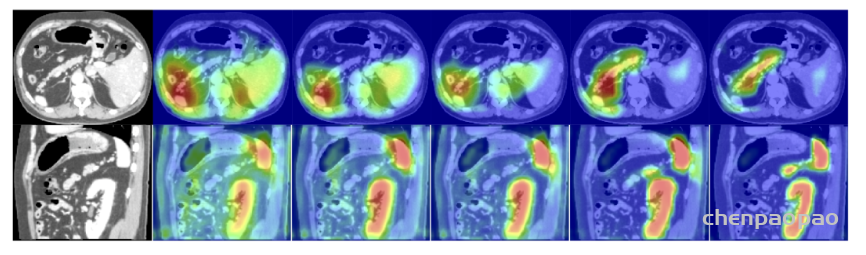
以CNN为基础的编解码结构在图像分割上展现出了卓越的效果,尤其是医学图像的自动分割上。但一些研究认为以往的FCN和UNet等分割网络存在计算资源和模型参数的过度和重复使用,例如相似的低层次特征被级联内的所有网络重复提取。针对这类普遍性的问题,相关研究提出了给UNet添加注意力门控(Attention Gates, AGs)的方法,形成一个新的图像分割网络结构:Attention UNet。提出Attention UNet的论文为Attention U-Net: Learning Where to Look for the Pancreas,发表在2018年CVPR上。注意力机制原先是在自然语言处理领域被提出并逐渐得到广泛应用的一种新型结构,旨在模仿人的注意力机制,有针对性的聚焦数据中的突出特征,能够使得模型更加高效。