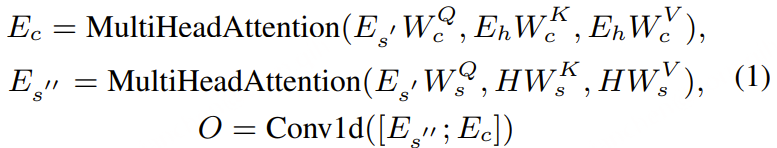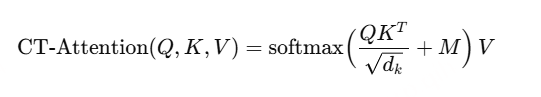paper: https://arxiv.org/pdf/2603.10468
G-STAR是一个LLM-based端到端多说话人ASR系统:1)Sortformer风格流式说话人追踪模块 + 到达顺序说话人缓存(AOSC);2)Speech-LLM转录主干(Qwen2-7B-Instruct + LoRA);3)交错时序融合(K:1插入)结合声学和说话人嵌入;4)缓存一致的SOT解码。三阶段训练:会议式ASR预训练→局部SA-ASR训练→全局SA-ASR训练。
💡 为什么值得关注
LLM-based ASR近两年进展比较显著,但在多说话人ASR场景,依然需要持续持续探索。G-STAR解决了局部说话人日志与全局身份一致性难以兼顾的问题,将“时间感知的说话人跟踪”与“基于LLM的转录生成”耦合在一个可端到端训练的框架中,从而在“何时”、“何人”、“说了什么”这三个维度的信息上实现协同。此外,G-STAR支持分块流式推理且无需用户提前进行语音注册。对做会议转录、语音助手的团队有直接参考价值。
多方会议转写不只是“把语音变成文字”。系统还需要判断每句话是谁说的、发生在什么时间,并且在长音频被切成多个片段处理时,让同一个人的说话人编号始终保持一致。G-STAR 的主要贡献,就是把带缓存的全局说话人跟踪器与 Speech-LLM 生成模型连接起来,让文字、时间戳和全局说话人标签在同一条件上下文中联合生成。
一、论文要解决什么问题
给定长音频波形,模型需要输出一组带说话人和时间边界的文本片段:
\( Y=\left\{\left(s_n,\tau_n^{\mathrm{st}},\tau_n^{\mathrm{ed}},y_n\right)\right\}_{n=1}^{N} \)其中,\(s_n\) 是说话人身份,\(\tau_n^{\mathrm{st}}\) 和 \(\tau_n^{\mathrm{ed}}\) 是起止时间,\(y_n\) 是对应文本。真正困难的地方在于:长会议通常必须分块推理,但说话人身份不能在每个块中重新编号。例如第一块中的 spk1,到了第十块仍然应该指向同一个真实说话人。
此前方法通常只解决其中一部分问题:SpeakerLM 更擅长块内说话人建模,但缺少显式的跨块全局身份关联;JEDIS-LLM 使用说话人缓存维持全局标签,却没有细粒度时间边界;TagSpeech 强化了时间锚点和说话人提示,但没有解决长音频分块推理中的会议级身份链接。G-STAR 的目标是同时覆盖时间戳、重叠语音、说话人归属和跨块全局一致性。
二、G-STAR 的总体设计
G-STAR 由三部分组成:ASR 声学分支、说话人跟踪分支,以及维护全局身份的 Arrival-Order Speaker Cache(AOSC)。两条分支生成的特征按照时间顺序交错融合,随后送入大语言模型,以 Serialized Output Training(SOT)格式输出文字、时间戳和全局说话人标签。
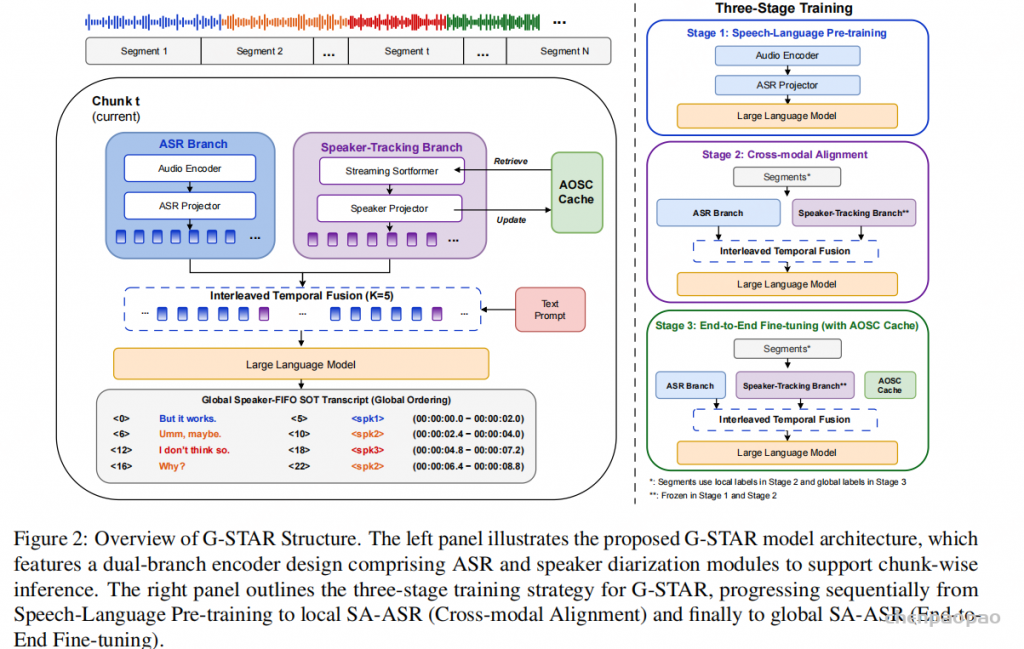
1. 分块处理与全局输出格式
长音频 \(x\) 被划分为连续的 \(T\) 个块:
\( x=\left\{x^{(t)}\right\}_{t=1}^{T} \)每个块生成一个序列化结果,结构可以表示为:
\( z^{(t)}=\left[\langle t_{\mathrm{st}}\rangle,\;w,\;\langle t_{\mathrm{ed}}\rangle,\;\langle \mathrm{spk}=k\rangle\right]^{*} \)这里的 \(k\) 不是当前块内的临时编号,而是由 AOSC 维护的会议级到达顺序编号。
2. ASR 声学分支
音频编码器首先把第 \(t\) 个音频块转换为帧级声学特征:
\( H^{(t)}=f_{\mathrm{enc}}\left(x^{(t)}\right)\in\mathbb{R}^{L_t\times d_h} \)随后 ASR projector 将其映射到 LLM 的嵌入空间:
\( U^{(t)}=g_1\left(H^{(t)}\right)\in\mathbb{R}^{L_t\times d_{\mathrm{llm}}} \)实现中,音频编码器和投影器初始化自 FireRed-LLM,语言模型使用 Qwen2-7B-Instruct,并继承 FireRed-LLM 的 LoRA 权重。
3. 说话人跟踪分支与 AOSC
说话人分支采用 Streaming Sortformer。它不只读取当前音频,还读取上一块保留下来的缓存:
\( S^{(t)},C^{(t)}=f_{\mathrm{trk}}\left(x^{(t)},C^{(t-1)}\right),\qquad S^{(t)}\in\mathbb{R}^{M_t\times d_s} \)其中 \(C^{(t-1)}\) 是历史 AOSC 状态,\(S^{(t)}\) 是当前块的帧同步说话人提示。实现中,该分支初始化自 NVIDIA 的 diar_streaming_sortformer_4spk-v2;说话人 projector 由步长为 5 的一维卷积降采样模块和两层 MLP 组成,再把提示映射到 LLM 空间:
AOSC 按说话人在会议中首次出现的顺序保存紧凑状态。新说话人出现时分配下一个槽位;历史说话人再次出现时,系统从缓存中找回原槽位。因此,全局编号具有可解释性,也避免了不同音频块之间的标签置换漂移。

4. 交错时间融合
论文没有在最后阶段才把 ASR 与说话人时间轴做“后融合”,而是把说话人特征直接插入声学 token 流。设插入步长为 \(K\),融合结果为:
\( E^{(t)}=\operatorname{Interleave}\left(U^{(t)},V^{(t)};K\right)\in\mathbb{R}^{N_t\times d_{\mathrm{llm}}} \) \( N_t\approx L_t+\left\lceil\frac{L_t}{K}\right\rceil \)具体来说,每经过 \(K\) 个声学位置就插入一次说话人提示。如果两条分支的帧率不同,则使用确定性的最近邻或线性重采样对齐。论文默认重点验证 \(K=5\),即在信息密度和对词汇建模的干扰之间取折中。
5. 全局 SOT 解码
LLM 在文本提示、融合后的声学/说话人表示以及已生成 token 的条件下进行自回归解码:
\( p\left(z^{(t)}\mid x^{(t)},C^{(t-1)}\right)=\prod_{m=1}^{\left|z^{(t)}\right|}p\left(z_m^{(t)}\mid p,E^{(t)},z_{<m}^{(t)}\right) \)由于 <spk=k> 与 AOSC 中第 \(k\) 个到达顺序槽位绑定,模型可以在逐块解码时直接生成全局一致的说话人标签,不再依赖会后全局聚类。
三、三阶段训练策略
- 会议风格 ASR 预训练:让音频编码器、ASR projector 和 LLM 适应对话及会议语音。
- 局部 SA-ASR 跨模态对齐:在最长 20 秒的分段语音上学习时间戳、文本和块内说话人标签。Figure 2 显示说话人跟踪模块在前两个阶段冻结。
- 全局 SA-ASR 端到端微调:引入 AOSC 和全局标签,训练跨块一致的说话人归属。同时使用四个数据集构造的 90 秒片段独立调优 Sortformer,以增强长音频跟踪能力。
Speech-LLM 各阶段保持可训练模块一致:ASR projector、说话人 projector 和 LoRA adapter。LoRA rank 为 64,缩放因子为 16,dropout 为 0.05。训练样本最大打包长度为 12,000 tokens。
前两个阶段分别训练 20,000 steps,峰值学习率为 \(5\times10^{-5}\);全局阶段训练 5,000 steps,峰值学习率降为 \(2\times10^{-5}\)。均使用 AdamW、0.01 warmup ratio 和余弦退火。Sortformer 调优采用学习率 \(10^{-4}\)、batch size 4,共训练 5 epochs。
为了让模型更加重视结构 token,论文使用分层交叉熵:时间戳 token 权重为 1.5,说话人标签 token 权重为 2。可将其直观写成:
\( \mathcal{L}=\mathcal{L}_{\mathrm{lexical}}+1.5\,\mathcal{L}_{\mathrm{timestamp}}+2\,\mathcal{L}_{\mathrm{speaker}} \)四、数据集与评价协议
公开实验使用四个会议或对话数据集:MLC 英文子集、AMI、Fisher,以及只使用音频模态的 Candor。训练音频被切分为最长 20 秒的片段。内部模型还使用中文对话数据;公开配置则使用 AISHELL-4 和 AliMeeting 等公开会议数据作为对应数据来源。
- 局部设置:输入不超过 20 秒,使用 oracle VAD/分段,重点考察后端的联合转写和说话人归属能力。
- 全局设置:输入完整会议,各系统使用自己的 VAD 或分段前端并逐块推理,更接近真实部署,但 VAD 差异也会进入最终结果。
- 指标:cpWER 衡量考虑说话人匹配后的转写错误,DER 衡量说话人日志错误;两者都是越低越好。
- DER collar:公开实验为 0,内部测试集为 0.5 秒。模型幻觉产生的额外片段会被计入 cpWER 和 DER 错误。
论文还实现了一个受控后融合基线:ASR 使用同一 Speech-LLM 后端,VAD 切出语音段,CTC 强制对齐补充词级时间戳,Sortformer 生成全局说话人时间轴,最后再按时间重叠关系合并。这个对照可以较好地区分“组件更强”和“跟踪条件直接参与生成”之间的差异。
五、局部实验结果
表 1 对应论文 Table 1,单位为 cpWER/DER(%),输入最长 20 秒,oracle VAD,DER collar=0。
| 系统 | AMI | Fisher | MLC | Candor |
|---|---|---|---|---|
| Sortformer(仅 DER) | — / 29.87 | — / 18.33 | — / 17.76 | — / 30.92 |
| Parakeet(仅 cpWER) | 24.62 / — | 27.73 / — | 25.90 / — | 27.44 / — |
| VibeVoice-ASR | 30.51 / 31.99 | 15.18 / 17.68 | 21.74 / 14.01 | 22.12 / 30.89 |
| MOSS-Diarizen | 25.13 / 32.20 | 11.69 / 21.61 | 14.16 / 10.58 | 16.38 / 31.76 |
| G-STAR | 24.86 / 19.00 | 10.29 / 8.18 | 13.90 / 6.49 | 14.54 / 17.56 |
G-STAR 在四个数据集上都显著降低了 DER,并且在 Fisher、MLC 和 Candor 上获得最低 cpWER。AMI 的 cpWER 为 24.86,与 Parakeet 的 24.62 基本相当,但 DER 从 Sortformer 的 29.87 降到 19.00。结果说明,说话人提示被注入 LLM 后,并没有以牺牲词汇识别为代价,反而提升了联合生成的稳定性。
六、完整会议的全局实验
表 2 对应论文 Table 2,单位为 cpWER/DER(%),完整会议逐块推理,DER collar=0。
| 系统 | Fisher | MLC | Candor | AMI |
|---|---|---|---|---|
| Sortformer(仅 DER) | — / 15.21 | — / 21.92 | — / 18.03 | — / 28.35 |
| Parakeet(仅 cpWER) | 24.41 / — | 31.03 / — | 26.92 / — | 35.70 / — |
| VibeVoice-ASR | 25.03 / 27.15 | 25.41 / 19.83 | 27.24 / 25.68 | 34.19 / 39.95 |
| 受控后融合级联 | 21.01 / 23.41 | 23.18 / 21.38 | 17.62 / 17.67 | 39.52 / 37.63 |
| G-STAR | 16.44 / 16.85 | 17.15 / 14.25 | 15.17 / 24.89 | 30.85 / 32.23 |
G-STAR 在 Fisher、MLC、Candor 和 AMI 上都取得最低的会议级 cpWER。相对使用相近主干组件的受控后融合方案,cpWER 分别从 21.01、23.18、17.62、39.52 降至 16.44、17.15、15.17、30.85,相对降幅约为 21.8%、26.0%、13.9% 和 21.9%。这说明改进并不只是来自更强的 ASR 或说话人模块,而是因为说话人跟踪信息在生成过程中直接参与了决策。
不过,DER 结果需要客观看待:G-STAR 在 MLC 上最好,但 Fisher 的 Sortformer、Candor 的受控后融合方案以及 AMI 的 Sortformer 都得到更低 DER。换言之,G-STAR 的优势重点是最终的“谁说了什么”联合转写,而不是在所有场景中取代专门的说话人日志系统。
内部域外会议测试
内部测试集包含 0.50 小时双人会议、0.49 小时三人会议和 1.86 小时四人会议。论文将三至四人场景合并报告,DER collar 为 0.5 秒。
| 系统 | 2 人 | 3–4 人 | 平均 |
|---|---|---|---|
| VibeVoice-ASR | 11.10 / 14.83 | 54.48 / 38.33 | 47.64 / 34.62 |
| 聚类式 Pipeline | 23.56 / 14.20 | 41.14 / 30.76 | 38.37 / 28.15 |
| G-STAR | 10.42 / 4.86 | 38.85 / 28.59 | 34.37 / 24.88 |
G-STAR 的平均 cpWER/DER 为 34.37/24.88,优于 VibeVoice-ASR 的 47.64/34.62,也优于聚类式 Pipeline 的 38.37/28.15。双人场景提升最明显,DER 只有 4.86;三至四人会议仍然明显更难,说明说话人数增加后,全局跟踪和重叠语音依旧是主要挑战。
七、消融实验说明了什么
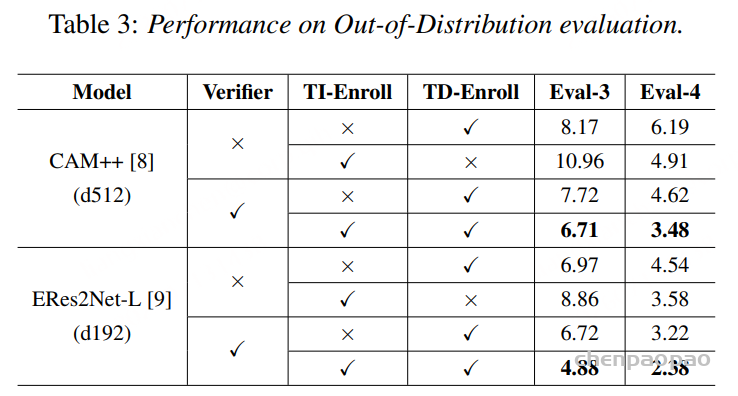
表 3 对应论文 Table 4,单位为 cpWER/DER(%)。
| 分层 CE | 交错时间融合 | AMI | Fisher | Candor |
|---|---|---|---|---|
| 否 | 是 | 26.33 / 21.06 | 10.88 / 10.24 | 14.97 / 20.21 |
| 是 | 否 | 28.63 / 21.28 | 14.23 / 9.02 | 18.30 / 18.10 |
| 是 | 是 | 24.86 / 19.00 | 10.29 / 8.18 | 14.54 / 17.56 |
两项设计的作用并不相同。交错时间融合对 cpWER 的帮助更大,说明周期性注入说话人提示能够协助 LLM 同时生成正确文字和结构 token;分层交叉熵对 DER 的改善更直接,因为更高的时间戳与说话人 token 权重会强化边界和说话人切换预测。两者同时启用时,三个数据集都得到最佳综合结果。
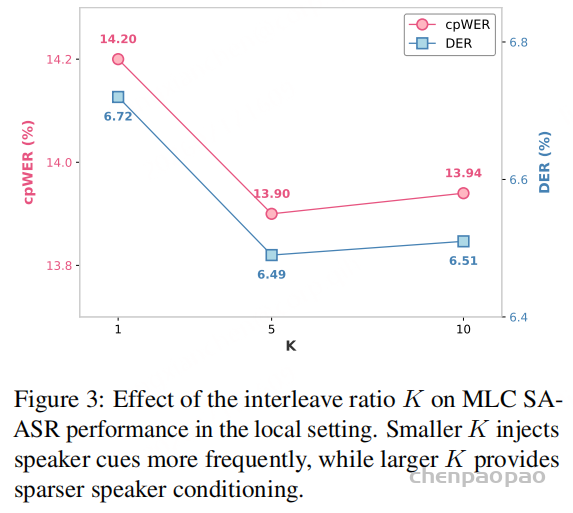
Figure 3 进一步比较了 MLC 上不同插入步长:
| 插入步长 K | cpWER | DER |
|---|---|---|
| 1 | 14.20 | 6.72 |
| 5 | 13.90 | 6.49 |
| 10 | 13.94 | 6.51 |
\(K=1\) 时提示过密,非词汇条件可能干扰语言建模;\(K=10\) 时提示偏稀疏;\(K=5\) 在 cpWER 和 DER 上取得最优平衡。
八、论文的主要创新点
- 把说话人归属从后处理变成生成条件。说话人时间信息在 LLM 解码前进入统一嵌入序列,而不是 ASR 完成后再做时间轴拼接。
- 用 AOSC 解决跨块身份漂移。按首次到达顺序维护说话人槽位,使长会议中的全局标签具备持续状态和可解释编号。
- 统一生成文字、时间戳和全局说话人标签。SOT 输出接口让多个结构化目标被组织为单一自回归序列,同时保留重叠语音片段。
- 兼顾模块化训练和端到端优化。说话人跟踪器可以独立调优,Speech-LLM 又能在其提示条件下联合优化,适合训练数据来源不一致或存在域偏移的情况。
- 建立局部与全局两套评价协议。oracle 分段实验隔离后端能力,完整会议实验则验证 VAD、跟踪、时间戳和转写共同作用下的真实表现。
九、局限性
第一,论文采用分块推理,但没有完整评估严格实时流式部署,尚缺少端到端延迟、缓存内存开销和在线缓存更新稳定性数据。第二,训练数据规模和多样性仍然有限,跨语言、复杂声学环境、更多说话人以及更强重叠场景的泛化能力还有提升空间。第三,从公开实验可以看到,模型对最终 cpWER 的优化非常稳定,但纯 DER 并非全面领先;如果应用只关注高精度说话人日志,专门的 diarization 系统仍可能更合适。
十、总结
G-STAR 最值得关注的不是简单增加一个说话人编码器,而是重新定义了说话人归属在 Speech-LLM 中的位置:它不再是 ASR 后面的拼接步骤,而是影响生成过程的显式条件。AOSC 负责记住“谁已经出现过”,交错时间融合负责在合适的时间点把信息交给 LLM,全局 SOT 则把文字、时间戳和身份转换为可直接阅读的统一序列。
实验表明,这一路线尤其适合长会议的“谁说了什么”任务:G-STAR 在四个完整会议基准上都获得最低 cpWER,并在内部域外数据上继续保持优势。其下一步关键问题,是把这种缓存条件生成机制推进到低延迟、严格在线的真实流式系统中。



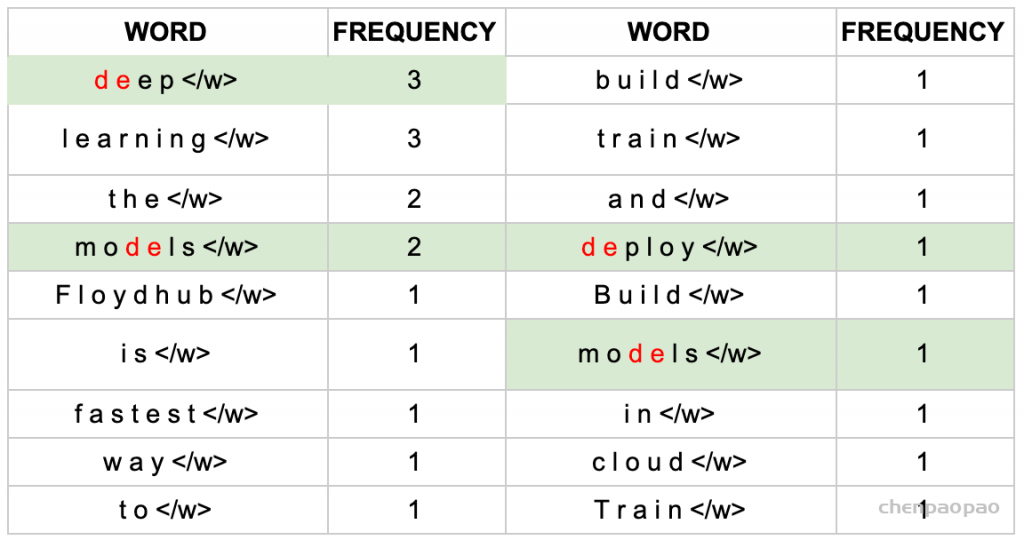
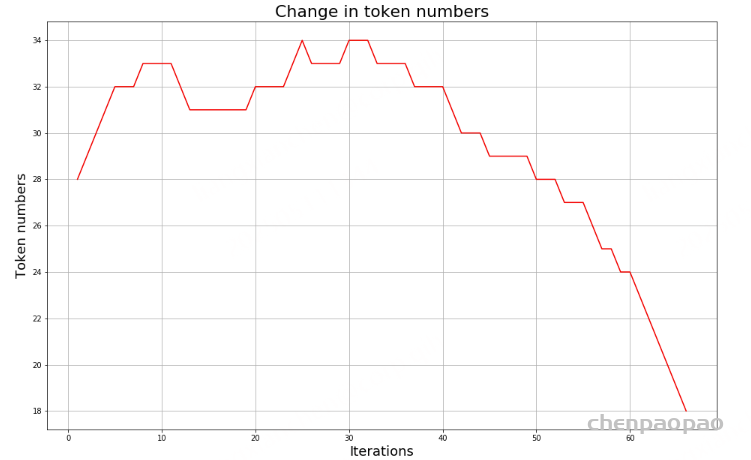
 继续迭代直到达到预设的subwords词表大小或下一个最高频的字节对出现频率为1。
继续迭代直到达到预设的subwords词表大小或下一个最高频的字节对出现频率为1。