
小样本学习里面有一个非常常见和实用的方法:使用大数据集预训练,小数据集中微调。

参考文献和代码:
1. Chen, Liu, Kira, Wang, & Huang. A Closer Look at Few-shot Classification. In ICLR, 2019. 代码: https://github.com/wyharveychen/Close…
2. Dhillon, Chaudhari, Ravichandran, & Soatto. A baseline for few-shot image classification. In ICLR, 2020.
3. Chen, Wang, Liu, Xu, & Darrell. A New Meta-Baseline for Few-Shot Learning. arXiv, 2020. 代码:https://github.com/cyvius96/few-shot-…
小样本学习旨在通过有限标记数据学习识别新类别,可以将小样本学习算法分为三大类:基于初始化的方法、基于度量学习的方法和基于数据增强的方法。
基于初始化的方法:学习微调,旨在学习一个好的模型初始化策略,使得能够通过少量标记数据和有限的梯度更新轮次即可完成对新类别的分类,或者学习一个优化器。
基于距离度量的方法:学习比较,如果一个模型能够计算两张图像的相似度,那么它可能基于标记数据对未知图像进行分类,一般基于余弦相似度、欧式距离、岭回归、图神经网络等计算距离。
基于数据增强的方法:学习增强,旨在通过学习一个数据生成器,通过数据生成器增强新类的样本量。由于基于数据增强的方法往往与零样本方法协同优化,所以本文作者不考虑基于数据增强的方法。
领域自适应:一种旨在缓解源领域和目标领域间领域漂移现象的技术。小样本分类与领域自适应类似,区别在于在领域自适应中,目标域往往拥有大量的可用样本,而小样本学习在新领域中仅有少量可用样本。

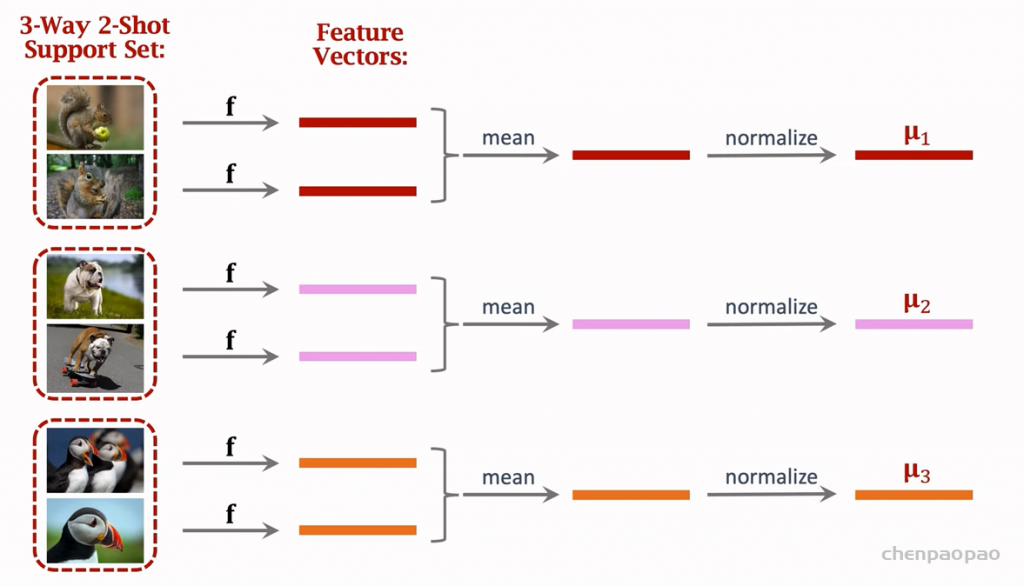
大部分的思路:通过一个大数据集进行训练一个神经网络,在做few-shot的时候,我们要用到这个与训练好的 神经网络,我们分别把query和support set送进神经网络,并获得特征向量,就可以比较 query和support set 在空间上的相似度(比如余弦相似度),然后就可以比较了。训练好的网络去掉全连接层。

2、不微调,直接使用预训练的网络进行预测:
3、对query分类:
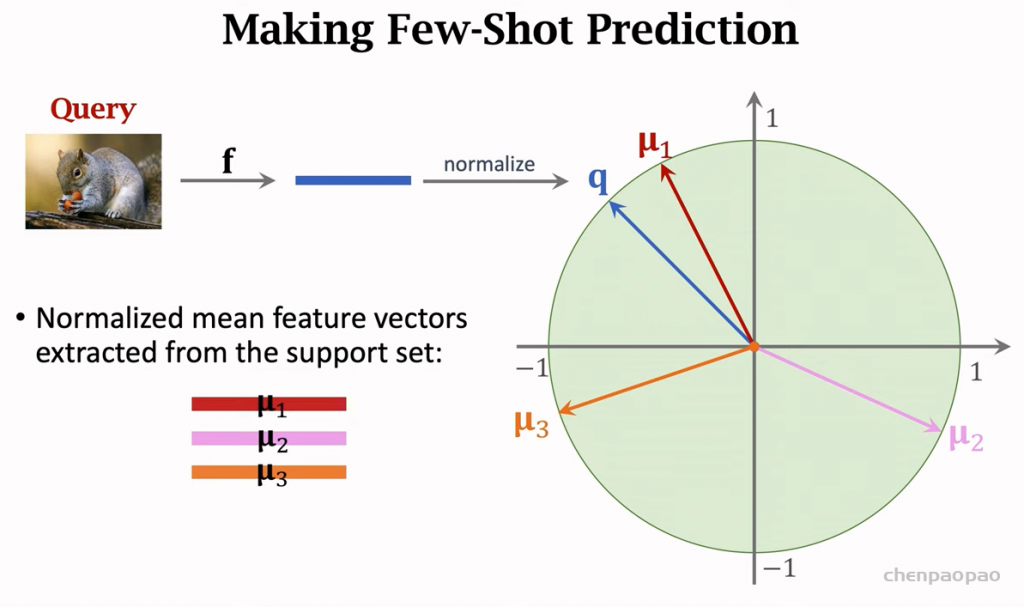
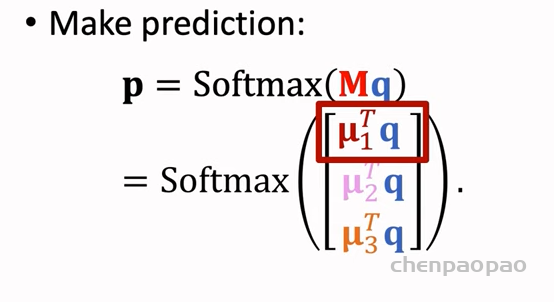
4、微调:


微调调的是softmax,而不是CNN特征提取网络!也就是微调下面的W和B
1、微调的初始化:让W=M,b=0
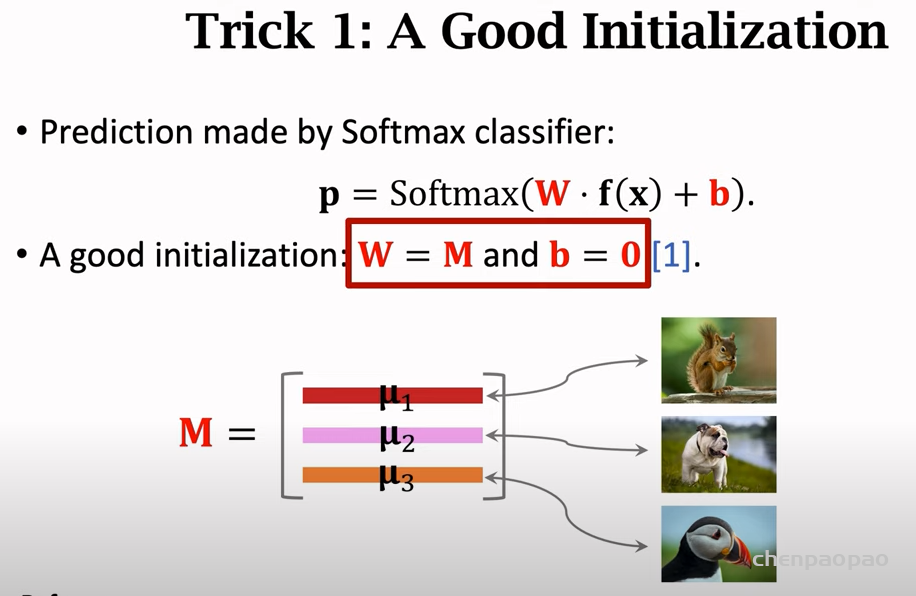
如何微调:使用entropy损失来更新w和b参数

