
来自wangshusen的课件: https://github.com/wangshusen/DeepLearning

小样本学习就是用极少的数据做分类or回归。
如上面的suppoort set 里面有两个类别,右边query图片你认为是set里面的哪个类别?对于人类来说非常简单,对于机器来说能不能像人一样去识别query属于哪一类?
对于小样本学习,不可能按照传统的方法去训练一个分类模型。小样本不能训练出一个神经网络。few-shot learing就是去解决小样本分类问题。
few-shot learing 的训练目标与传统的监督学习目标不同,传统的分类是学会识别训练集合里面的图片 ,并且泛化到测试机,神经网络识别出该图片属于哪个类。而few shot learing是让机器自己学会学习,学习的目的不是让机器学会那个是大象那个是老虎,而是让模型学会学习不同类别的不同之处,给定两张图片,模型知道两个图片是否是同一类别。哪怕模型训练集中没有出现过该类别。

虽然模型没有见过斗牛犬和穿山甲,但能够知道这两个是不是一个东西。

给神经网络一个query和六张图片(support set),现在神经网络依次将query和supportset做对比,判断query和那个更相似。
support set 和 train set 区别:
训练集很大每一类下面有很多图片,support set小,只能在预测的时候提供一些额外信息,用一个大的训练集训练一个神经网络,训练的目的不是让模型识别图片里面的大象老虎,而是学会理解不同类别的异同。

Meta learing:元学习,自己学会学习


传统监督学习 vs few shot learing
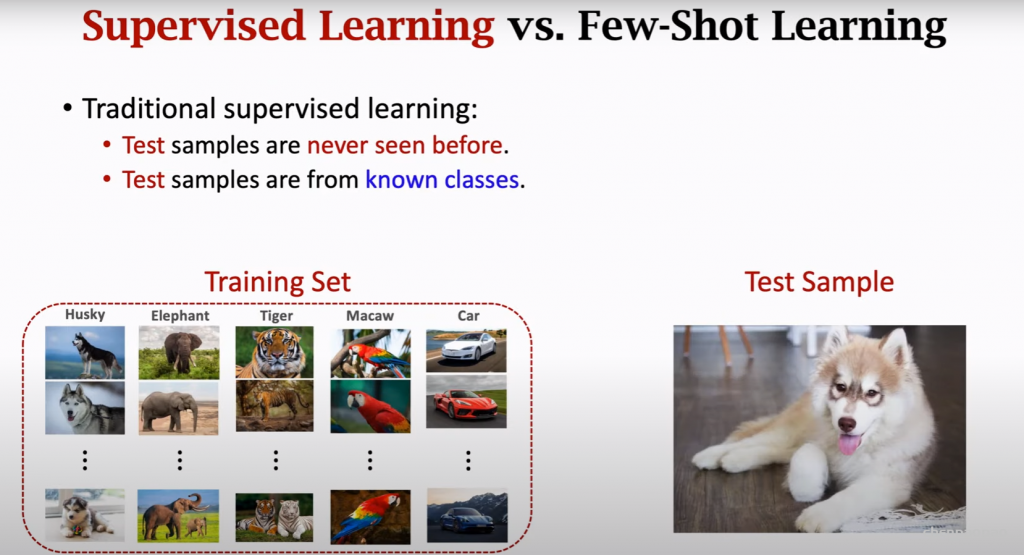
主要区别就是:是否训练集中存在测试的类别。query可以是模型没见过的类别。因此会更难。

为了让模型识别没见的东西:需要为模型提供一个参考:support set,计算相似度。

K-way N-shot support set: K-有K个类别,,每个类别有n个样本。

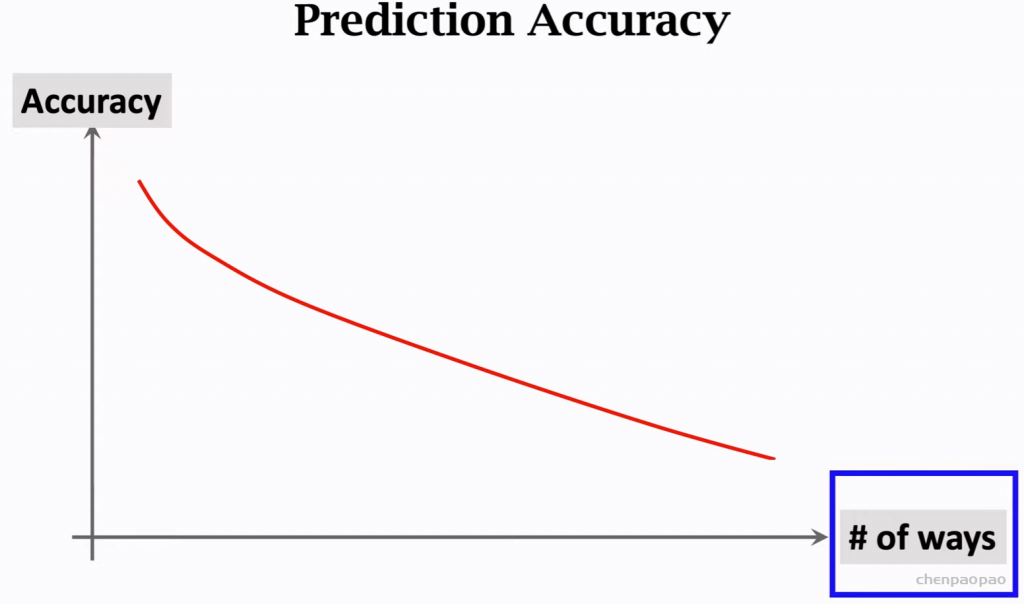
准确度随着 K个类别 数增加而降低。
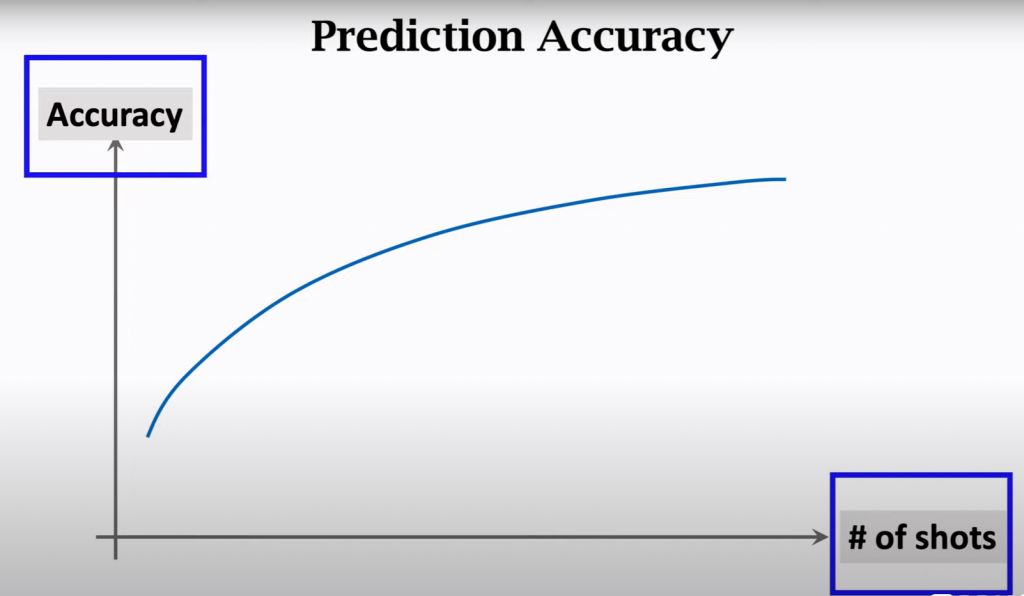
准确度随着每个类的样本数而增加
小样本学习最基本的想法:
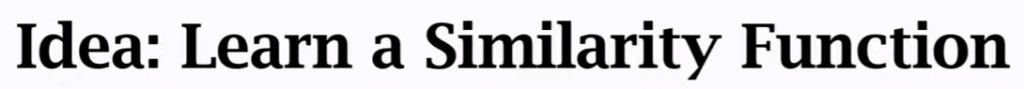

可以用大规模数据集做训练:

数据集:
1、手写数字:

2、图片数据
