
摘自: https://zhuanlan.zhihu.com/p/360988428
众所周知,BERT模型自2018年问世起就各种屠榜,开启了NLP领域预训练+微调的范式。到现在,BERT的相关衍生模型层出不穷(XL-Net、RoBERTa、ALBERT、ELECTRA、ERNIE等),要理解它们可以先从BERT这个始祖入手。

HuggingFace是一家总部位于纽约的聊天机器人初创服务商,很早就捕捉到BERT大潮流的信号并着手实现基于pytorch的BERT模型。这一项目最初名为pytorch-pretrained-bert,在复现了原始效果的同时,提供了易用的方法以方便在这一强大模型的基础上进行各种玩耍和研究。
随着使用人数的增加,这一项目也发展成为一个较大的开源社区,合并了各种预训练语言模型以及增加了Tensorflow的实现,并且在2019年下半年改名为Transformers。截止写文章时(2021年3月30日)这一项目已经拥有43k+的star,可以说Transformers已经成为事实上的NLP基本工具。https://github.com/huggingface/transformersgithub.com/huggingface/transformers
本文基于Transformers版本4.4.2(2021年3月19日发布)项目中,pytorch版的BERT相关代码,从代码结构、具体实现与原理,以及使用的角度进行分析,包含以下内容:
- BERT Tokenization分词模型(BertTokenizer)
- BERT Model本体模型(BertModel)
- BertEmbeddings
- BertEncoder
- BertLayer
- BertAttention
- BertSelfAttention
- BertSelfOutput
- BertIntermediate
- BertOutput
- BertAttention
- BertPooler
- BertLayer
- BERT-based Models应用模型(请看下篇)
- BertForPreTraining
- BertForSequenceClassification
- BertForMultiChoice
- BertForTokenClassification
- BertForQuestionAnswering
- BERT训练与优化(请看下篇)
- Pre-Training
- Fine-Tuning
- AdamW
- Warmup
1 Tokenization(BertTokenizer)
和BERT有关的Tokenizer主要写在/models/bert/tokenization_bert.py和/models/bert/tokenization_bert_fast.py 中。
这两份代码分别对应基本的BertTokenizer,以及不进行token到index映射的BertTokenizerFast,这里主要讲解第一个。
class BertTokenizer(PreTrainedTokenizer):
"""
Construct a BERT tokenizer. Based on WordPiece.
This tokenizer inherits from :class:`~transformers.PreTrainedTokenizer` which contains most of the main methods.
Users should refer to this superclass for more information regarding those methods.
...
"""BertTokenizer 是基于BasicTokenizer和WordPieceTokenizer 的分词器:
BasicTokenizer负责处理的第一步——按标点、空格等分割句子,并处理是否统一小写,以及清理非法字符。- 对于中文字符,通过预处理(加空格)来按字分割;
- 同时可以通过
never_split指定对某些词不进行分割; - 这一步是可选的(默认执行)。
WordPieceTokenizer在词的基础上,进一步将词分解为子词(subword) 。- subword介于char和word之间,既在一定程度保留了词的含义,又能够照顾到英文中单复数、时态导致的词表爆炸和未登录词的OOV(Out-Of-Vocabulary)问题,将词根与时态词缀等分割出来,从而减小词表,也降低了训练难度;
- 例如,tokenizer这个词就可以拆解为“token”和“##izer”两部分,注意后面一个词的“##”表示接在前一个词后面。
BertTokenizer 有以下常用方法:
from_pretrained:从包含词表文件(vocab.txt)的目录中初始化一个分词器;tokenize:将文本(词或者句子)分解为子词列表;convert_tokens_to_ids:将子词列表转化为子词对应下标的列表;convert_ids_to_tokens:与上一个相反;convert_tokens_to_string:将subword列表按“##”拼接回词或者句子;encode:对于单个句子输入,分解词并加入特殊词形成“[CLS], x, [SEP]”的结构并转换为词表对应下标的列表;对于两个句子输入(多个句子只取前两个),分解词并加入特殊词形成“[CLS], x1, [SEP], x2, [SEP]”的结构并转换为下标列表;decode:可以将encode方法的输出变为完整句子。
以及,类自身的方法:
>>> from transformers import BertTokenizer
>>> bt = BertTokenizer.from_pretrained('./bert-base-uncased/')
>>> bt('I like natural language progressing!')
{'input_ids': [101, 1045, 2066, 3019, 2653, 27673, 999, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]}2 Model(BertModel)
和BERT模型有关的代码主要写在/models/bert/modeling_bert.py中,这一份代码有一千多行,包含BERT模型的基本结构和基于它的微调模型等。
下面从BERT模型本体入手分析:
class BertModel(BertPreTrainedModel):
"""
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in `Attention is
all you need <https://arxiv.org/abs/1706.03762>`__ by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the :obj:`is_decoder` argument of the configuration
set to :obj:`True`. To be used in a Seq2Seq model, the model needs to initialized with both :obj:`is_decoder`
argument and :obj:`add_cross_attention` set to :obj:`True`; an :obj:`encoder_hidden_states` is then expected as an
input to the forward pass.
""" BertModel主要为transformer encoder结构,包含三个部分:
embeddings,即BertEmbeddings类的实体,对应词嵌入;encoder,即BertEncoder类的实体;pooler, 即BertPooler类的实体,这一部分是可选的。
补充:注意BertModel也可以配置为Decoder,不过下文中不包含对这一部分的讨论。
下面将介绍BertModel的前向传播过程中各个参数的含义以及返回值:
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_values=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
): ...input_ids:经过tokenizer分词后的subword对应的下标列表;attention_mask:在self-attention过程中,这一块mask用于标记subword所处句子和padding的区别,将padding部分填充为0;token_type_ids: 标记subword当前所处句子(第一句/第二句/padding);position_ids: 标记当前词所在句子的位置下标;head_mask: 用于将某些层的某些注意力计算无效化;inputs_embeds: 如果提供了,那就不需要input_ids,跨过embedding lookup过程直接作为Embedding进入Encoder计算;encoder_hidden_states: 这一部分在BertModel配置为decoder时起作用,将执行cross-attention而不是self-attention;encoder_attention_mask: 同上,在cross-attention中用于标记encoder端输入的padding;past_key_values:这个参数貌似是把预先计算好的K-V乘积传入,以降低cross-attention的开销(因为原本这部分是重复计算);use_cache: 将保存上一个参数并传回,加速decoding;output_attentions:是否返回中间每层的attention输出;output_hidden_states:是否返回中间每层的输出;return_dict:是否按键值对的形式(ModelOutput类,也可以当作tuple用)返回输出,默认为真。
补充:注意,这里的head_mask对注意力计算的无效化,和下文提到的注意力头剪枝不同,而仅仅把某些注意力的计算结果给乘以这一系数。
返回部分如下:
# BertModel的前向传播返回部分
if not return_dict:
return (sequence_output, pooled_output) + encoder_outputs[1:]
return BaseModelOutputWithPoolingAndCrossAttentions(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
past_key_values=encoder_outputs.past_key_values,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
cross_attentions=encoder_outputs.cross_attentions,
)可以看出,返回值不但包含了encoder和pooler的输出,也包含了其他指定输出的部分(hidden_states和attention等,这一部分在encoder_outputs[1:])方便取用:
# BertEncoder的前向传播返回部分,即上面的encoder_outputs
if not return_dict:
return tuple(
v
for v in [
hidden_states,
next_decoder_cache,
all_hidden_states,
all_self_attentions,
all_cross_attentions,
]
if v is not None
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=next_decoder_cache,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
cross_attentions=all_cross_attentions,
)此外,BertModel还有以下的方法,方便BERT玩家进行各种骚操作:
get_input_embeddings:提取embedding中的word_embeddings即词向量部分;set_input_embeddings:为embedding中的word_embeddings赋值;_prune_heads:提供了将注意力头剪枝的函数,输入为{layer_num: list of heads to prune in this layer}的字典,可以将指定层的某些注意力头剪枝。
补充:剪枝是一个复杂的操作,需要将保留的注意力头部分的Wq、Kq、Vq和拼接后全连接部分的权重拷贝到一个新的较小的权重矩阵(注意先禁止grad再拷贝),并实时记录被剪掉的头以防下标出错。具体参考
BertAttention部分的prune_heads方法。
2.1 BertEmbeddings
包含三个部分求和得到:
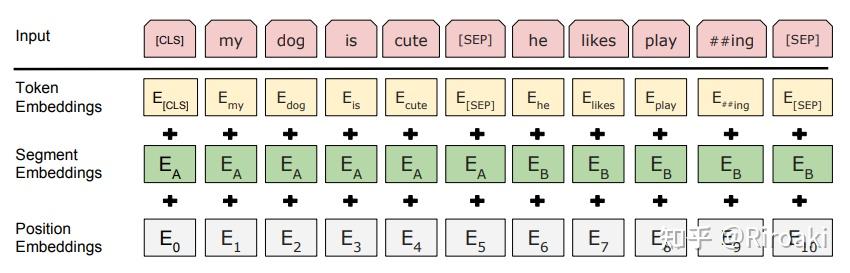
- word_embeddings,上文中subword对应的嵌入。
- token_type_embeddings,用于表示当前词所在的句子,辅助区别句子与padding、句子对间的差异。
- position_embeddings,句子中每个词的位置嵌入,用于区别词的顺序。和transformer论文中的设计不同,这一块是训练出来的,而不是通过Sinusoidal函数计算得到的固定嵌入。一般认为这种实现不利于拓展性(难以直接迁移到更长的句子中)。
三个embedding不带权重相加,并通过一层LayerNorm+dropout后输出,其大小为(batch_size, sequence_length, hidden_size)。
补充:这里为什么要用LayerNorm+Dropout呢?为什么要用LayerNorm而不是BatchNorm?可以参考一个不错的回答:
transformer 为什么使用 layer normalization,而不是其他的归一化方法?369 赞同 · 15 评论回答
2.2 BertEncoder
包含多层BertLayer,这一块本身没有特别需要说明的地方,不过有一个细节值得参考:
利用gradient checkpointing技术以降低训练时的显存占用。
补充:gradient checkpointing即梯度检查点,通过减少保存的计算图节点压缩模型占用空间,但是在计算梯度的时候需要重新计算没有存储的值,参考论文《Training Deep Nets with Sublinear Memory Cost》,过程如下示意图:
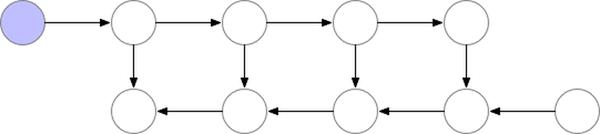
在BertEncoder中,gradient checkpoint是通过torch.utils.checkpoint.checkpoint实现的,使用起来比较方便,可以参考文档:torch.utils.checkpoint – PyTorch 1.8.1 documentationpytorch.org/docs/stable/checkpoint.html
这一机制的具体实现比较复杂(没看懂),在此不作展开。
再往深一层走,就进入了Encoder的某一层:
2.2.1 BertLayer
这一层包装了BertAttention和BertIntermediate+BertOutput(即Attention后的FFN部分),以及这里直接忽略的cross-attention部分(将BERT作为Decoder时涉及的部分)。
理论上,这里顺序调用三个子模块就可以,没有什么值得说明的地方。
然而这里又出现了一个细节:

# 这是forward的一部分
self_attention_outputs = self.attention(
hidden_states,
attention_mask,
head_mask,
output_attentions=output_attentions,
past_key_value=self_attn_past_key_value,
)
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
# 中间省略一部分……
layer_output = apply_chunking_to_forward(
self.feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, attention_output
)
outputs = (layer_output,) + outputs
# 省略一部分……
return outputs
# 这是feed_forward_chunk的部分
def feed_forward_chunk(self, attention_output):
intermediate_output = self.intermediate(attention_output)
layer_output = self.output(intermediate_output, attention_output)
return layer_output看到上面那个apply_chunking_to_forward和feed_forward_chunk了吗(为什么要整这么复杂,直接调用它不香吗)?
那么这个apply_chunking_to_forward到底是啥?深入看看……
def apply_chunking_to_forward(
forward_fn: Callable[..., torch.Tensor], chunk_size: int, chunk_dim: int, *input_tensors
) -> torch.Tensor:
"""
This function chunks the :obj:`input_tensors` into smaller input tensor parts of size :obj:`chunk_size` over the
dimension :obj:`chunk_dim`. It then applies a layer :obj:`forward_fn` to each chunk independently to save memory.
If the :obj:`forward_fn` is independent across the :obj:`chunk_dim` this function will yield the same result as
directly applying :obj:`forward_fn` to :obj:`input_tensors`.
...
"""哦,又是一个节约显存的技术——包装了一个切分小batch或者低维数操作的功能:这里参数chunk_size其实就是切分的batch大小,而chunk_dim就是一次计算维数的大小,最后拼接起来返回。
不过,在默认操作中不会特意设置这两个值(在源代码中默认为0和1),所以会直接等效于正常的forward过程。
继续往下深入,就是Transformer的核心:BertAttention部分,以及紧随其后的FFN部分。
2.2.1.1 BertAttention
本以为attention的实现就在这里,没想到还要再下一层……其中,self成员就是多头注意力的实现,而output成员实现attention后的全连接+dropout+residual+LayerNorm一系列操作。
class BertAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.self = BertSelfAttention(config)
self.output = BertSelfOutput(config)
self.pruned_heads = set()首先还是回到这一层。这里出现了上文提到的剪枝操作,即prune_heads方法:
def prune_heads(self, heads):
if len(heads) == 0:
return
heads, index = find_pruneable_heads_and_indices(
heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
)
# Prune linear layers
self.self.query = prune_linear_layer(self.self.query, index)
self.self.key = prune_linear_layer(self.self.key, index)
self.self.value = prune_linear_layer(self.self.value, index)
self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
# Update hyper params and store pruned heads
self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
self.pruned_heads = self.pruned_heads.union(heads) 这里的具体实现概括如下:
find_pruneable_heads_and_indices是定位需要剪掉的head,以及需要保留的维度下标index;prune_linear_layer则负责将Wk/Wq/Wv权重矩阵(连同bias)中按照index保留没有被剪枝的维度后转移到新的矩阵。
接下来就到重头戏——Self-Attention的具体实现。
2.2.1.1.1 BertSelfAttention
预警:这一块可以说是模型的核心区域,也是唯一涉及到公式的地方,所以将贴出大量代码。
初始化部分:
class BertSelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (config.hidden_size, config.num_attention_heads)
)
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
self.max_position_embeddings = config.max_position_embeddings
self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
self.is_decoder = config.is_decoder- 除掉熟悉的query、key、value三个权重和一个dropout,这里还有一个谜一样的position_embedding_type,以及decoder标记(当然,我不打算介绍cross-attenton部分);
- 注意,hidden_size和all_head_size在一开始是一样的。至于为什么要看起来多此一举地设置这一个变量——显然是因为上面那个剪枝函数,剪掉几个attention head以后all_head_size自然就小了;
- hidden_size必须是num_attention_heads的整数倍,以bert-base为例,每个attention包含12个head,hidden_size是768,所以每个head大小即attention_head_size=768/12=64;
- position_embedding_type是什么?继续往下看就知道了……
然后是重点,也就是前向传播过程。
首先回顾一下multi-head self-attention的基本公式:
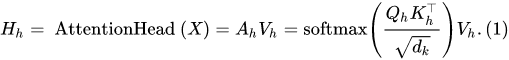

其中 |h| 表示注意力头的个数, [⋅] 表示向量拼接, Wo∈R|h|dv×dx 。
而这些注意力头,众所周知是并行计算的,所以上面的query、key、value三个权重是唯一的——这并不是所有heads共享了权重,而是“拼接”起来了。
补充:原论文中多头的理由为Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this.而另一个比较靠谱的分析有:
为什么Transformer 需要进行 Multi-head Attention?1036 赞同 · 46 评论回答
看看forward方法:
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=None,
output_attentions=False,
):
mixed_query_layer = self.query(hidden_states)
# 省略一部分cross-attention的计算
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
query_layer = self.transpose_for_scores(mixed_query_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
# ...- 这里的transpose_for_scores用来把hidden_size拆成多个头输出的形状,并且将中间两维转置以进行矩阵相乘;
- 这里key_layer/value_layer/query_layer的形状为:
(batch_size, num_attention_heads, sequence_length, attention_head_size); - 这里attention_scores的形状为:
(batch_size, num_attention_heads, sequence_length, sequence_length),符合多个头单独计算获得的attention map形状。
到这里实现了K与Q相乘,获得raw attention scores的部分,按公式接下来应该是按dk进行scaling并做softmax的操作。然而——
先出现在眼前的是一个奇怪的positional_embedding,以及一堆爱因斯坦求和:
# ...
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
seq_length = hidden_states.size()[1]
position_ids_l = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
position_ids_r = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
distance = position_ids_l - position_ids_r
positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
if self.position_embedding_type == "relative_key":
relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores
elif self.position_embedding_type == "relative_key_query":
relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key
# ...补充:关于爱因斯坦求和约定,参考以下文档
torch.einsum – PyTorch 1.8.1 documentationpytorch.org/docs/stable/generated/torch.einsum.html
补充:这里的
positional_embedding引入了attention map中的位置嵌入——为什么要这么做呢?我目前还没搞明白……
对于不同的positional_embedding_type,有三种操作:
absolute:默认值,这部分就不用处理;relative_key:对key_layer作处理,将其与这里的positional_embedding和key矩阵相乘作为key相关的位置编码;relative_key_query:对key和value都进行相乘以作为位置编码。
暂时跳过这一迷惑的部分,回到正常attention的流程:
# ...
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
attention_scores = attention_scores + attention_mask # 这里为什么是+而不是*?
# Normalize the attention scores to probabilities.
attention_probs = nn.Softmax(dim=-1)(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
# 省略decoder返回值部分……
return outputs重大疑问:这里的attention_scores = attention_scores + attention_mask是在做什么?难道不应该是乘mask吗?
因为这里的attention_mask已经【被动过手脚】,将原本为1的部分变为0,而原本为0的部分(即padding)变为一个较大的负数,这样相加就得到了一个较大的负值:
- 至于为什么要用【一个较大的负数】?因为这样一来经过softmax操作以后这一项就会变成接近0的小数。
(Pdb) attention_mask
tensor([[[[ -0., -0., -0., ..., -10000., -10000., -10000.]]],
[[[ -0., -0., -0., ..., -10000., -10000., -10000.]]],
[[[ -0., -0., -0., ..., -10000., -10000., -10000.]]],
...,
[[[ -0., -0., -0., ..., -10000., -10000., -10000.]]],
[[[ -0., -0., -0., ..., -10000., -10000., -10000.]]],
[[[ -0., -0., -0., ..., -10000., -10000., -10000.]]]],
device='cuda:0')那么,这一步是在哪里执行的呢?
我在modeling_bert.py中没有找到答案,但是在modeling_utils.py中找到了一个特别的类:class ModuleUtilsMixin,在它的get_extended_attention_mask方法中发现了端倪:
def get_extended_attention_mask(self, attention_mask: Tensor, input_shape: Tuple[int], device: device) -> Tensor:
"""
Makes broadcastable attention and causal masks so that future and masked tokens are ignored.
Arguments:
attention_mask (:obj:`torch.Tensor`):
Mask with ones indicating tokens to attend to, zeros for tokens to ignore.
input_shape (:obj:`Tuple[int]`):
The shape of the input to the model.
device: (:obj:`torch.device`):
The device of the input to the model.
Returns:
:obj:`torch.Tensor` The extended attention mask, with a the same dtype as :obj:`attention_mask.dtype`.
"""
# 省略一部分……
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
# masked positions, this operation will create a tensor which is 0.0 for
# positions we want to attend and -10000.0 for masked positions.
# Since we are adding it to the raw scores before the softmax, this is
# effectively the same as removing these entirely.
extended_attention_mask = extended_attention_mask.to(dtype=self.dtype) # fp16 compatibility
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
return extended_attention_mask那么,这个函数是在什么时候被调用的呢?和BertModel有什么关系呢?
OK,这里涉及到BertModel的继承细节了:BertModel继承自BertPreTrainedModel ,后者继承自PreTrainedModel,而PreTrainedModel继承自[nn.Module, ModuleUtilsMixin, GenerationMixin] 三个基类。——好复杂的封装!
这也就是说, BertModel必然在中间的某个步骤对原始的attention_mask调用了get_extended_attention_mask ,导致attention_mask从原始的[1, 0]变为[0, -1e4]的取值。
真相只有一个!

最终在BertModel的前向传播过程中找到了这一调用(第944行):
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
# ourselves in which case we just need to make it broadcastable to all heads.
extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape, device)问题解决了:这一方法不但实现了改变mask的值,还将其广播(broadcast)为可以直接与attention map相加的形状。
不愧是你,HuggingFace。

除此之外,值得注意的细节有:
- 按照每个头的维度进行缩放,对于bert-base就是64的平方根即8;
- attention_probs不但做了softmax,还用了一次dropout,这是担心attention矩阵太稠密吗……这里也提到很不寻常,但是原始Transformer论文就是这么做的;
- head_mask就是之前提到的对多头计算的mask,如果不设置默认是全1,在这里就不会起作用;
- context_layer即attention矩阵与value矩阵的乘积,原始的大小为:
(batch_size, num_attention_heads, sequence_length, attention_head_size); - context_layer进行转置和view操作以后,形状就恢复了
(batch_size, sequence_length, hidden_size)。
OK, that’s all for attention.
2.2.1.1.2 BertSelfOutput
这一块操作略多但不复杂,一目了然:
class BertSelfOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states补充:这里又出现了LayerNorm和Dropout的组合,只不过这里是先Dropout,进行残差连接后再进行LayerNorm。至于为什么要做残差连接,最直接的目的就是降低网络层数过深带来的训练难度,对原始输入更加敏感~
2.2.1.2 BertIntermediate
看完了BertAttention,在Attention后面还有一个全连接+激活的操作:
class BertIntermediate(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = ACT2FN[config.hidden_act]
else:
self.intermediate_act_fn = config.hidden_act
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states- 这里的全连接做了一个扩展,以bert-base为例,扩展维度为3072,是原始维度768的4倍之多;
补充:为什么要过一个FFN?不知道……谷歌最近的论文貌似说明只有attention的模型什么用都没有:
- 这里的激活函数默认实现为
gelu(Gaussian Error Linerar Units(GELUS): GELU(x)=xP(X<=x)=xΦ(x) ;当然,它是无法直接计算的,可以用一个包含tanh的表达式进行近似(略)。
作为参考(图源网络):
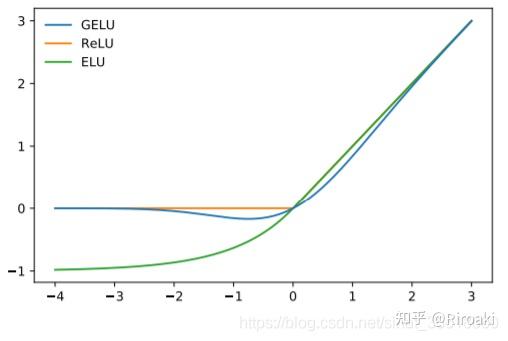
至于为什么在transformer中要用这个激活函数……

补充:看了一些研究,应该是说GeLU比ReLU这些表现都好,以至于后续的语言模型都沿用了这一激活函数。
2.2.1.3 BertOutput
在这里又是一个全连接+dropout+LayerNorm,还有一个残差连接residual connect:
class BertOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states这里的操作和BertSelfOutput不能说没有关系,只能说一模一样……非常容易混淆的两个组件。
以下内容还包含基于BERT的应用模型,以及BERT相关的优化器和用法,将在下一篇文章作详细介绍。
2.2.3 BertPooler
这一层只是简单地取出了句子的第一个token,即[CLS]对应的向量,然后过一个全连接层和一个激活函数后输出:
(这一部分是可选的,因为pooling有很多不同的操作)
class BertPooler(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states):
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_outputTakeaways·小结
- 在HuggingFace实现的Bert模型中,使用了多种节约显存的技术:
- gradient checkpoint,不保留前向传播节点,只在用时计算;
- apply_chunking_to_forward,按多个小批量和低维度计算FFN部分;
- BertModel包含复杂的封装和较多的组件。以bert-base为例,主要组件如下:
- 总计
Dropout出现了1+(1+1+1)x12=37次; - 总计
LayerNorm出现了1+(1+1)x12=25次; - 总计
dense全连接层出现了(1+1+1)x12+1=37次,并不是每个dense都配了激活函数……
- 总计
BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(30522, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
# 如此重复11层,直到大厦崩塌:)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()3 BERT-based Models
基于BERT的模型都写在/models/bert/modeling_bert.py里面,包括BERT预训练模型和BERT分类模型,UML图如下:
BERT模型一图流(建议保存后放大查看):

首先,以下所有的模型都是基于BertPreTrainedModel这一抽象基类的,而后者则基于一个更大的基类PreTrainedModel。这里我们关注BertPreTrainedModel的功能:
- 用于初始化模型权重,同时维护继承自
PreTrainedModel的一些标记身份或者加载模型时的类变量。
下面,首先从预训练模型开始分析。
3.1 BertForPreTraining
众所周知,BERT预训练任务包括两个:
- Masked Language Model(MLM):在句子中随机用
[MASK]替换一部分单词,然后将句子传入 BERT 中编码每一个单词的信息,最终用[MASK]的编码信息预测该位置的正确单词,这一任务旨在训练模型根据上下文理解单词的意思; - Next Sentence Prediction(NSP):将句子对A和B输入BERT,使用
[CLS]的编码信息进行预测B是否A的下一句,这一任务旨在训练模型理解预测句子间的关系。
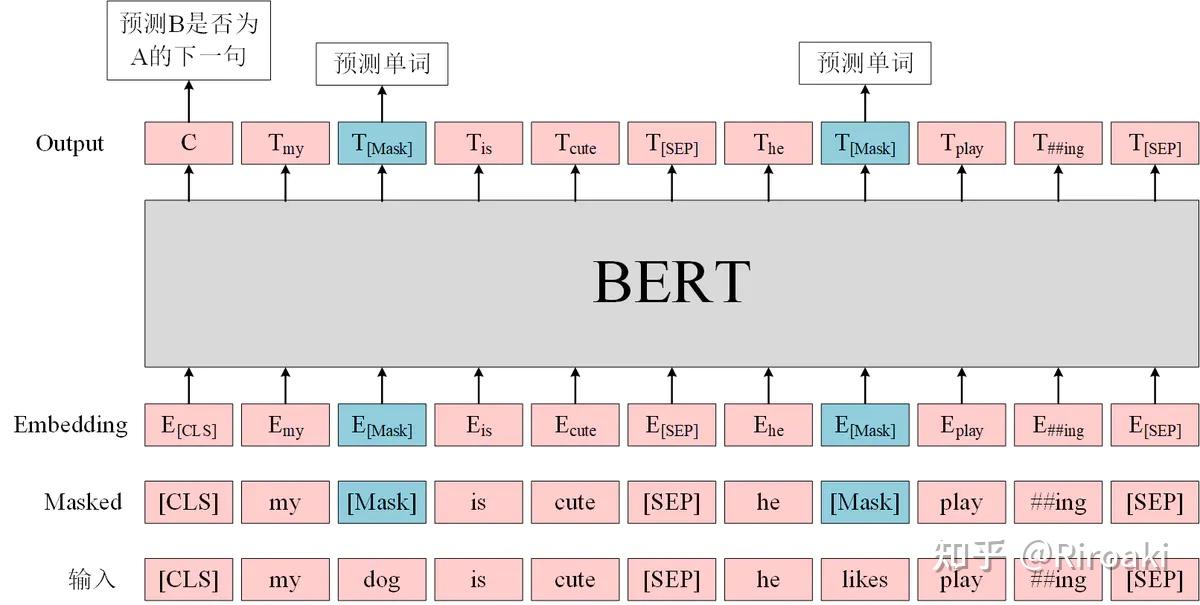
而对应到代码中,这一融合两个任务的模型就是BertForPreTraining,其中包含两个组件:
class BertForPreTraining(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.bert = BertModel(config)
self.cls = BertPreTrainingHeads(config)
self.init_weights()
# ...这里的BertModel在上一篇文章中已经详细介绍了(注意,这里设置的是默认add_pooling_layer=True,即会提取[CLS]对应的输出用于NSP任务),而BertPreTrainingHeads则是负责两个任务的预测模块:
class BertPreTrainingHeads(nn.Module):
def __init__(self, config):
super().__init__()
self.predictions = BertLMPredictionHead(config)
self.seq_relationship = nn.Linear(config.hidden_size, 2)
def forward(self, sequence_output, pooled_output):
prediction_scores = self.predictions(sequence_output)
seq_relationship_score = self.seq_relationship(pooled_output)
return prediction_scores, seq_relationship_score 又是一层封装:BertPreTrainingHeads包裹了BertLMPredictionHead 和一个代表NSP任务的线性层。这里不把NSP对应的任务也封装一个BertXXXPredictionHead,估计是因为它太简单了,没有必要……
补充:其实是有封装这个类的,不过它叫做
BertOnlyNSPHead,在这里用不上……
继续下探BertPreTrainingHeads :
class BertLMPredictionHead(nn.Module):
def __init__(self, config):
super().__init__()
self.transform = BertPredictionHeadTransform(config)
# The output weights are the same as the input embeddings, but there is
# an output-only bias for each token.
self.decoder = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
self.bias = nn.Parameter(torch.zeros(config.vocab_size))
# Need a link between the two variables so that the bias is correctly resized with `resize_token_embeddings`
self.decoder.bias = self.bias
def forward(self, hidden_states):
hidden_states = self.transform(hidden_states)
hidden_states = self.decoder(hidden_states)
return hidden_states这个类用于预测[MASK]位置的输出在每个词作为类别的分类输出,注意到:
- 该类重新初始化了一个全0向量作为预测权重的bias;
- 该类的输出形状为
[batch_size, seq_length, vocab_size],即预测每个句子每个词是什么类别的概率值(注意这里没有做softmax); - 又一个封装的类:
BertPredictionHeadTransform,用来完成一些线性变换:
class BertPredictionHeadTransform(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
if isinstance(config.hidden_act, str):
self.transform_act_fn = ACT2FN[config.hidden_act]
else:
self.transform_act_fn = config.hidden_act
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.transform_act_fn(hidden_states)
hidden_states = self.LayerNorm(hidden_states)
return hidden_states补充:感觉这一层去掉也行?输出的形状也没有发生变化。我个人的理解是和Pooling那里做一个对称的操作,同样过一层dense再接分类器……
回到BertForPreTraining,继续看两块loss是怎么处理的。它的前向传播和BertModel的有所不同,多了labels和next_sentence_label 两个输入:
labels:形状为[batch_size, seq_length],代表MLM任务的标签,注意这里对于原本未被遮盖的词设置为-100,被遮盖词才会有它们对应的id,和任务设置是反过来的。- 例如,原始句子是
I want to [MASK] an apple,这里我把单词eat给遮住了输入模型,对应的label设置为[-100, -100, -100, 【eat对应的id】, -100, -100]; - 为什么要设置为-100而不是其他数? 因为
torch.nn.CrossEntropyLoss默认的ignore_index=-100,也就是说对于标签为100的类别输入不会计算loss。
- 例如,原始句子是
next_sentence_label: 这一个输入很简单,就是0和1的二分类标签。
# ...
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
next_sentence_label=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
): ...OK,接下来两部分loss的组合:
# ...
total_loss = None
if labels is not None and next_sentence_label is not None:
loss_fct = CrossEntropyLoss()
masked_lm_loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
next_sentence_loss = loss_fct(seq_relationship_score.view(-1, 2), next_sentence_label.view(-1))
total_loss = masked_lm_loss + next_sentence_loss
# ...直接相加,就是这么单纯的策略。
当然,这份代码里面也包含了对于只想对单个目标进行预训练的BERT模型(具体细节不作展开):
BertForMaskedLM:只进行MLM任务的预训练;- 基于
BertOnlyMLMHead,而后者也是对BertLMPredictionHead的另一层封装;
- 基于
BertLMHeadModel:这个和上一个的区别在于,这一模型是作为decoder运行的版本;- 同样基于
BertOnlyMLMHead;
- 同样基于
BertForNextSentencePrediction:只进行NSP任务的预训练。- 基于
BertOnlyNSPHead,内容就是一个线性层……
- 基于
接下来介绍的是各种Fine-tune模型,基本都是分类任务:
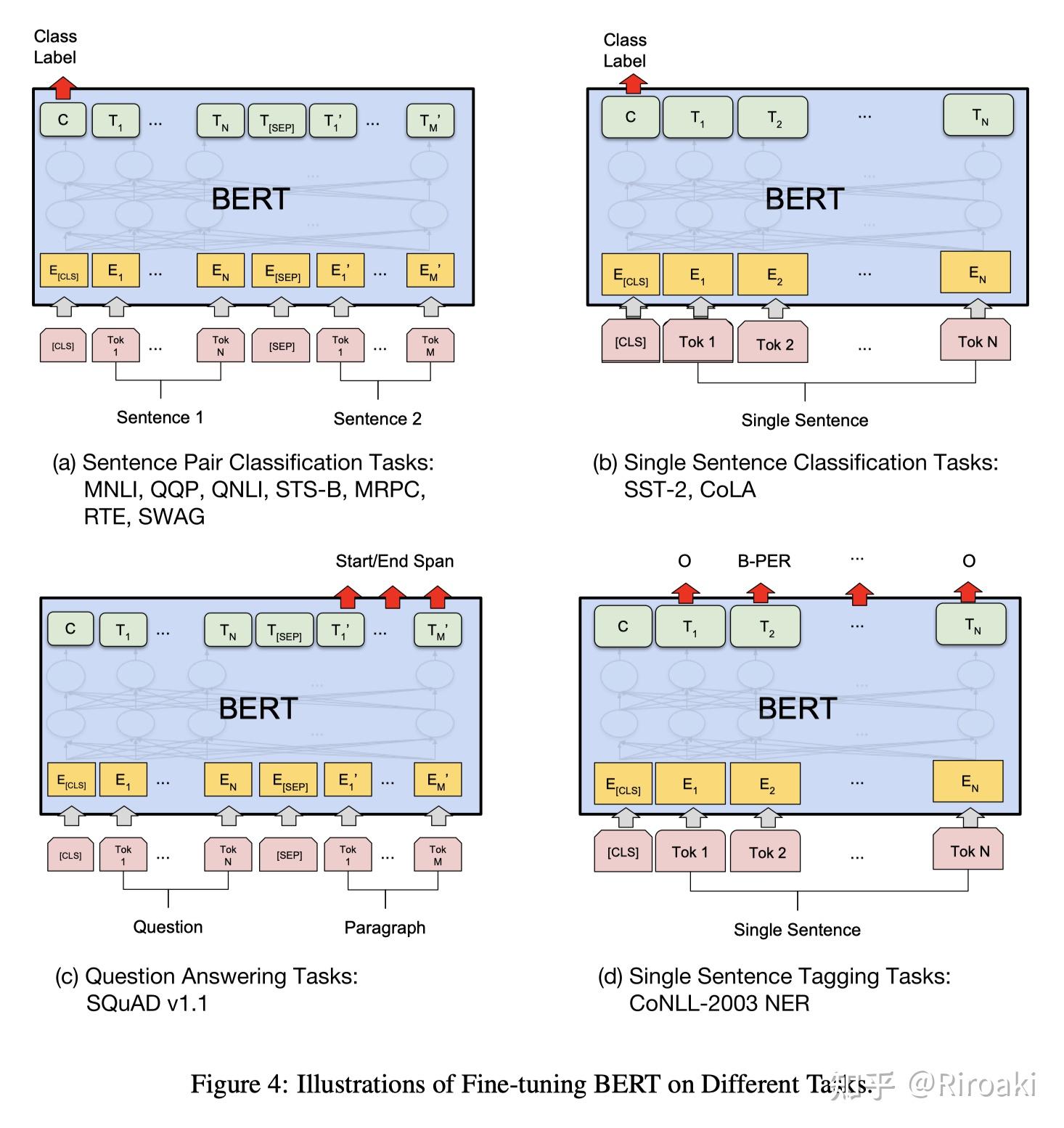
3.2 BertForSequenceClassification
这一模型用于句子分类(也可以是回归)任务,比如GLUE benchmark的各个任务。
- 句子分类的输入为句子(对),输出为单个分类标签。
结构上很简单,就是BertModel(有pooling)过一个dropout后接一个线性层输出分类:
class BertForSequenceClassification(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.bert = BertModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
self.init_weights()
# ...在前向传播时,和上面预训练模型一样需要传入labels输入。
- 如果初始化的
num_labels=1,那么就默认为回归任务,使用MSELoss; - 否则认为是分类任务。
3.3 BertForMultipleChoice
这一模型用于多项选择,如RocStories/SWAG任务。
- 多项选择任务的输入为一组分次输入的句子,输出为选择某一句子的单个标签。
结构上与句子分类相似,只不过线性层输出维度为1,即每次需要将每个样本的多个句子的输出拼接起来作为每个样本的预测分数。
- 实际上,具体操作时是把每个batch的多个句子一同放入的,所以一次处理的输入为
[batch_size, num_choices]数量的句子,因此相同batch大小时,比句子分类等任务需要更多的显存,在训练时需要小心。
3.4 BertForTokenClassification
这一模型用于序列标注(词分类),如NER任务。
- 序列标注任务的输入为单个句子文本,输出为每个token对应的类别标签。
由于需要用到每个token对应的输出而不只是某几个,所以这里的BertModel不用加入pooling层;
- 同时,这里将
_keys_to_ignore_on_load_unexpected这一个类参数设置为[r"pooler"],也就是在加载模型时对于出现不需要的权重不发生报错。
3.5 BertForQuestionAnswering
这一模型用于解决问答任务,例如SQuAD任务。
- 问答任务的输入为问题+(对于BERT只能是一个)回答组成的句子对,输出为起始位置和结束位置用于标出回答中的具体文本。
这里需要两个输出,即对起始位置的预测和对结束位置的预测,两个输出的长度都和句子长度一样,从其中挑出最大的预测值对应的下标作为预测的位置。
- 对超出句子长度的非法label,会将其压缩(
torch.clamp_)到合理范围。
作为一个迟到的补充,这里稍微介绍一下
ModelOutput这个类。它作为上述各个模型输出包装的基类,同时支持字典式的存取和下标顺序的访问,继承自python原生的OrderedDict类。
以上就是关于BERT源码的介绍,下面介绍一些关于BERT模型实用的训练细节。
4 BERT训练和优化
4.1 Pre-Training
预训练阶段,除了众所周知的15%、80%mask比例,有一个值得注意的地方就是参数共享。
不止BERT,所有huggingface实现的PLM的word embedding和masked language model的预测权重在初始化过程中都是共享的:
class PreTrainedModel(nn.Module, ModuleUtilsMixin, GenerationMixin):
# ...
def tie_weights(self):
"""
Tie the weights between the input embeddings and the output embeddings.
If the :obj:`torchscript` flag is set in the configuration, can't handle parameter sharing so we are cloning
the weights instead.
"""
output_embeddings = self.get_output_embeddings()
if output_embeddings is not None and self.config.tie_word_embeddings:
self._tie_or_clone_weights(output_embeddings, self.get_input_embeddings())
if self.config.is_encoder_decoder and self.config.tie_encoder_decoder:
if hasattr(self, self.base_model_prefix):
self = getattr(self, self.base_model_prefix)
self._tie_encoder_decoder_weights(self.encoder, self.decoder, self.base_model_prefix)
# ...至于为什么,应该是因为word_embedding和prediction权重太大了,以bert-base为例,其尺寸为(30522, 768),降低训练难度。
4.2 Fine-Tuning
微调也就是下游任务阶段,也有两个值得注意的地方。
4.2.1 AdamW
首先介绍一下BERT的优化器:AdamW(AdamWeightDecayOptimizer)。
这一优化器来自ICLR 2017的Best Paper:《Fixing Weight Decay Regularization in Adam》中提出的一种用于修复Adam的权重衰减错误的新方法。论文指出,L2正则化和权重衰减在大部分情况下并不等价,只在SGD优化的情况下是等价的;而大多数框架中对于Adam+L2正则使用的是权重衰减的方式,两者不能混为一谈。
AdamW是在Adam+L2正则化的基础上进行改进的算法,与一般的Adam+L2的区别如下:

关于AdamW的分析可以参考:AdamW and Super-convergence is now the fastest way to train neural netswww.fast.ai/2018/07/02/adam-weight-decay/paperplanet:都9102年了,别再用Adam + L2 regularization了1183 赞同 · 34 评论文章ICLR 2018 有什么值得关注的亮点?610 赞同 · 21 评论回答
话说,《STABLE WEIGHT DECAY REGULARIZATION》这篇好像吐槽AdamW的Weight Decay实现还是有问题……有空整整优化器相关的内容。
通常,我们会选择模型的weight部分参与decay过程,而另一部分(包括LayerNorm的weight)不参与(代码最初来源应该是Huggingface的示例):
补充:关于这么做的理由,我暂时没有找到合理的解答,但是找到了一些相关的讨论
# model: a Bert-based-model object
# learning_rate: default 2e-5 for text classification
param_optimizer = list(model.named_parameters())
no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in param_optimizer if not any(
nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in param_optimizer if any(
nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters,
lr=learning_rate)
# ...4.2.2 Warmup
BERT的训练中另一个特点在于Warmup,其含义为:
- 在训练初期使用较小的学习率(从0开始),在一定步数(比如1000步)内逐渐提高到正常大小(比如上面的2e-5),避免模型过早进入局部最优而过拟合;
- 在训练后期再慢慢将学习率降低到0,避免后期训练还出现较大的参数变化。
在Huggingface的实现中,可以使用多种warmup策略:
TYPE_TO_SCHEDULER_FUNCTION = {
SchedulerType.LINEAR: get_linear_schedule_with_warmup,
SchedulerType.COSINE: get_cosine_schedule_with_warmup,
SchedulerType.COSINE_WITH_RESTARTS: get_cosine_with_hard_restarts_schedule_with_warmup,
SchedulerType.POLYNOMIAL: get_polynomial_decay_schedule_with_warmup,
SchedulerType.CONSTANT: get_constant_schedule,
SchedulerType.CONSTANT_WITH_WARMUP: get_constant_schedule_with_warmup,
}具体而言:
- CONSTANT:保持固定学习率不变;
- CONSTANT_WITH_WARMUP:在每一个step中线性调整学习率;
- LINEAR:上文提到的两段式调整;
- COSINE:和两段式调整类似,只不过采用的是三角函数式的曲线调整;
- COSINE_WITH_RESTARTS:训练中将上面COSINE的调整重复n次;
- POLYNOMIAL:按指数曲线进行两段式调整。
具体使用参考transformers/optimization.py:
- 最常用的还是
get_linear_scheduler_with_warmup即线性两段式调整学习率的方案……
def get_scheduler(
name: Union[str, SchedulerType],
optimizer: Optimizer,
num_warmup_steps: Optional[int] = None,
num_training_steps: Optional[int] = None,
): ...