
作为刚入门的小白,有必要去记录一些NLP分类任务的小trick,感觉对于涨点提分十分有用。这个文章后面有新的想法会持续更新
华为有一个NLP关于医学电子病历的疾病多标签分类比赛,因为之前比较少去做NLP方向的东西,仅仅是学习过相关rnn、transformer、bert论文呢,所以,参赛纯粹是为了了解了解NLP方向,好在nlp做文本分类算是比较简单的下游任务,但在参赛过程中,会发现,其实对于文本分类来说,基本的bert-base的效果不是很好,但其实感觉不是出在模型架构方面,对于简单的分类任务,一个12层的bert应该适足以胜任了,因此将注意力不要过多的放在模型结构上。
任务说明
本赛题是利用病人电子病历文本信息推断出其可能患有疾病的疾病诊断任务。电子病历文本信息主要包括病人的性别、年龄、主诉、现病史、既往史、体格检查和辅助检查。标签信息为病人的出院诊断疾病。本赛题任务需要根据病人的电子病历文本信息推断出病人所患有的全部疾病。(注:病人的出院诊断疾病并不是单一的)
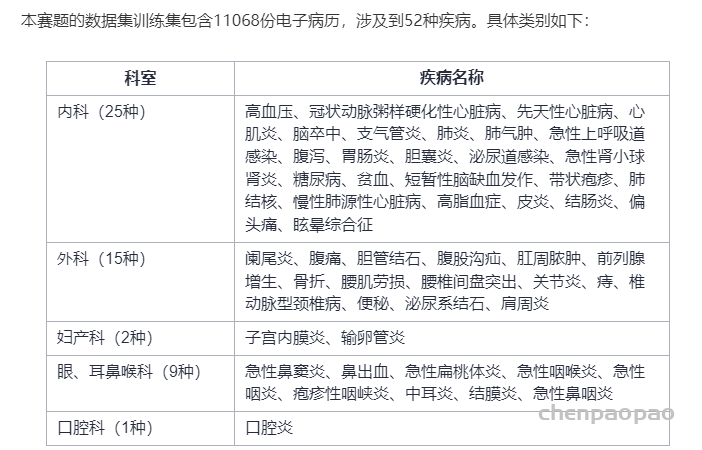
模型输出格式:
{ “ZY000001”: [“高血压”, “肺气肿”, “先天性心脏病”]}

评分标准
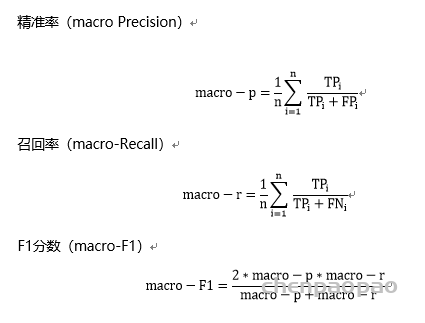
本赛题采用macro F1作为评价指标。评价指标计算公式如下:
对于每一个预测的疾病有真阳性(True Positive,TP),假阳性(False Positive,FP),假阴性(False Negative),真阴性(True Negative),n表示n种疾病。
这个得分最高在 0.83左右。我也试了几次,但到0.57就没再动过了…..,后面准备去尝试下下面的方法,看看有啥效果吗。
思路:
在github中找到一个分类会议任务的比赛ppt模型讲解:
https://github.com/TJBioMedNLP/chip2019task3
废话说完,来点或许能提分的干货:
数据方面:
1、数据清洗(很多脏数据)、数据增强
说实话,感觉这个比赛的要点就是数据处理,想提分就看你的数据的好坏,现在是真的意识到数据处理对于一个模型的影响之大了,后面要着重关注下这方面了。
本次提供的训练集中出现了一些不需要诊断的疾病:睾丸鞘膜积液、宫颈炎性疾病、口腔粘膜溃疡、头部外伤、急性阴道炎、女性盆腔炎、急性气管炎,需要自己去将该类数据清洗,另外,通过数据统计分析,可以获得训练集中各个label的数量严重不平衡,如何处理也是一个问题,是否可以通过数据集增强,提高某些类别的测试数据。
另外 性别、年龄、主诉、现病史、既往史、体格检查和辅助检查 等长度会超出模型的最大长度,如何解决、最大化利用上述信息也是一个问题。我做过对这些数据做过分析,对于 性别、年龄、主诉、现病史、既往史、体格检查和辅助检查 等 统计过平均长度、最大最小长度,从几十到几百不等。另外,去看下数据集就可以看到,有大量的标点符号和短语。另外,据说emr_id这个信息也是一个重要的信息???我一脸震惊。此外年龄和性别也会影响。
其他:
1、如果训练时使用文本长度为n,测试使用比n长一些的长度,可以涨点分
2、模型预训练会提分(或者找相关领域预训练模型)
这里我找了两个预训练模型:
https://huggingface.co/trueto/medbert-base-chinese
https://huggingface.co/nghuyong/ernie-health-zh
3、增大训练时输入编码长度(文本序列长度),当然,需要显卡的性能支持
all_tokens = self.tokenizer.encode_plus(content, max_length=pad_size, padding=”max_length”, truncation=True)
可以提高max_length的大小,但是比较吃显卡。
4、交叉验证
交叉验证经常用于给定的数据集训练、评估和最终选择机器学习模型,因为它有助于评估模型的结果在实践中如何推广到独立的数据集,最重要的是,交叉验证已经被证明产生比其他方法更低的偏差的模型。重复的k折交叉验证,主要是会重复进行n次的k折交叉验证,这样会产生n次结果,一般通过平均方法或者(投票规则)得到最后的结果
第一种是简单交叉验证,所谓的简单,是和其他交叉验证方法相对而言的。首先,我们随机的将样本数据分为两部分(比如: 70%的训练集,30%的测试集),然后用训练集来训练模型,在测试集上验证模型及参数。接着,我们再1把样本打乱,重新选择训练集和测试集,继续训练数据和检验模型。最后我们选择损失函数评估最优的模型和参数。
选择分层k-折交叉验证:
分层采样就是在每一份子集中都保持原始数据集的类别比例,保证采样数据跟原始数据的类别分布保持一致,该方法在有效的平衡方差和偏差。当针对不平衡数据时,使用随机的K-fold交叉验证,可能出现在子集中叫少的类别的分布与原始类别分布不一致。因此,针对不平衡数据往往使用stratified k-fold交叉验证。
当训练数据集不能代表整个数据集分布是,这时候使用stratified k折交叉验证可能不是好的方法,而可能比较适合使用简单的重复随机k折交叉验证。
- 1.把整个数据集随机划分成k份
- 2.用其中k-1份训练模型,然后用第k份验证模型
- 3.记录每个预测结果获得的误差
- 4.重复这个过程,知道每份数据都做过验证集
- 5.记录下的k个误差的平均值,被称为交叉验证误差。可以被用做衡量模型性能的标准
>>> from sklearn.model_selection import StratifiedKFold
>>> X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
>>> y = np.array([0, 0, 1, 1])
>>> skf = StratifiedKFold(n_splits=2)
>>> skf.get_n_splits(X, y)
2
>>> print(skf)
StratifiedKFold(n_splits=2, random_state=None, shuffle=False)
>>> for train_index, test_index in skf.split(X, y):
... print("TRAIN:", train_index, "TEST:", test_index)
... X_train, X_test = X[train_index], X[test_index]
... y_train, y_test = y[train_index], y[test_index]
TRAIN: [1 3] TEST: [0 2]
TRAIN: [0 2] TEST: [1 3]
具体来说:
以k-fold CV为例:仍然是把原始数据集分成训练集和测试集,但是训练模型的时候不使用测试集。最常见的一个叫做k_fold CV。
- 具体来说就是把训练集平分为k个fold,其中每个fold依次作为测试集、余下的作为训练集,进行k次训练,得到共计k组参数。取k组参数的均值作为模型的最终参数。
- 优点:充分压榨了数据集的价值。在样本集不够大的情况下尤其珍贵。
- 缺点:运算起来花时间。
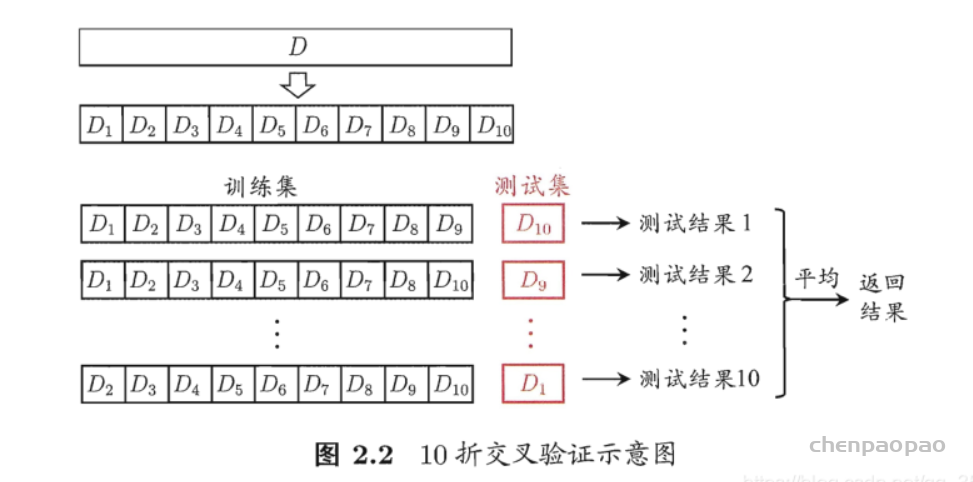
K折交叉验证训练单个模型:
通过对 k 个不同分组训练的结果进行平均来减少方差,因此模型的性能对数据的划分就不那么敏感,经过多次划分数据集,大大降低了结果的偶然性,从而提高了模型的准确性。具体做法如下:
- step1:不重复抽样将原始数据随机分为 k 份。
- step2:每一次挑选其中 1 份作为验证集,剩余 k-1 份作为训练集用于模型训练。一共训练k个模型。
- step3:在每个训练集上训练后得到一个模型,用这个模型在测试集上测试,计算并保存模型的评估指标,
- step4:计算 k 组测试结果的平均值作为模型最终在测试集上的预测值,求k 个模型评估指标的平均值,并作为当前 k 折交叉验证下模型的性能指标。
6、模型融合
模型融合:通过融合多个不同的模型,可能提升机器学习的性能。这一方法在各种机器学习比赛中广泛应用, 也是在比赛的攻坚时刻冲刺Top的关键。而融合模型往往又可以从模型结果,模型自身,样本集等不同的角度进行融合。即多个模型的组合可以改善整体的表现。集成模型是一种能在各种的机器学习任务上提高准确率的强有力技术。
模型融合是比赛后期一个重要的环节,大体来说有如下的类型方式:
1. 简单加权融合:
- 回归(分类概率):算术平均融合(Arithmetic mean),几何平均融合(Geometric mean);
- 分类:投票(Voting);
- 综合:排序融合(Rank averaging),log融合。
2. stacking/blending:
- 构建多层模型,并利用预测结果再拟合预测。
3. boosting/bagging:
- 多树的提升方法,在xgboost,Adaboost,GBDT中已经用到。
平均法(Averaging)
基本思想:对于回归问题,一个简单直接的思路是取平均。稍稍改进的方法是进行加权平均。权值可以用排序的方法确定,举个例子,比如A、B、C三种基本模型,模型效果进行排名,假设排名分别是1,2,3,那么给这三个模型赋予的权值分别是3/6、2/6、1/6。
平均法或加权平均法看似简单,其实后面的高级算法也可以说是基于此而产生的,Bagging或者Boosting都是一种把许多弱分类器这样融合成强分类器的思想。
简单算术平均法:Averaging方法就多个模型预测的结果进行平均。这种方法既可以用于回归问题,也可以用于对分类问题的概率进行平均。
加权算术平均法:这种方法是平均法的扩展。考虑不同模型的能力不同,对最终结果的贡献也有差异,需要用权重来表征不同模型的重要性importance。
投票法(voting)
基本思想:假设对于一个二分类问题,有3个基础模型,现在我们可以在这些基学习器的基础上得到一个投票的分类器,把票数最多的类作为我们要预测的类别。
绝对多数投票法:最终结果必须在投票中占一半以上。
相对多数投票法:最终结果在投票中票数最多。
加权投票法:每个弱学习器的分类票数乘以权重,并将各个类别的加权票数求和,最大值对应的类别即最终类别。
硬投票:对多个模型直接进行投票,不区分模型结果的相对重要度,最终投票数最多的类为最终被预测的类。
软投票:增加了设置权重的功能,可以为不同模型设置不同权重,进而区别模型不同的重要度。
堆叠法(Stacking)
基本思想
stacking 就是当用初始训练数据学习出若干个基学习器后,将这几个学习器的预测结果作为新的训练集,来学习一个新的学习器。对不同模型预测的结果再进行建模。
将个体学习器结合在一起的时候使用的方法叫做结合策略。对于分类问题,我们可以使用投票法来选择输出最多的类。对于回归问题,我们可以将分类器输出的结果求平均值。
上面说的投票法和平均法都是很有效的结合策略,还有一种结合策略是使用另外一个机器学习算法来将个体机器学习器的结果结合在一起,这个方法就是Stacking。在stacking方法中,我们把个体学习器叫做初级学习器,用于结合的学习器叫做次级学习器或元学习器(metalearner),次级学习器用于训练的数据叫做次级训练集。次级训练集是在训练集上用初级学习器得到的。
- step1:训练T个初级学习器,要使用交叉验证的方法在Train Set上面训练(因为第二阶段建立元学习器的数据是初级学习器输出的,如果初级学习器的泛化能力低下,元学习器也会过拟合)
- step2:T个初级学习器在Train Set上输出的预测值,作为元学习器的训练数据D,有T个初级学习器,D中就有T个特征。D的label和训练初级学习器时的label一致。
- step3:T个初级学习器在Test Set上输出的预测值,作为训练元学习器时的测试集,同样也是有T个模型就有T个特征。
- step4:训练元学习器,元学习器训练集D的label和训练初级学习器时的label一致。
混合法(Blending)
基本思想:Blending采用了和stacking同样的方法,不过只从训练集中选择一个fold的结果,再和原始特征进行concat作为元学习器meta learner的特征,测试集上进行同样的操作。
把原始的训练集先分成两部分,比如70%的数据作为新的训练集,剩下30%的数据作为测试集。
- 第一层,我们在这70%的数据上训练多个模型,然后去预测那30%数据的label,同时也预测test集的label。
- 在第二层,我们就直接用这30%数据在第一层预测的结果做为新特征继续训练,然后用test集第一层预测的label做特征,用第二层训练的模型做进一步预测。
Blending训练过程:
- 整个训练集划分成训练集training sets和验证集validation sets两个部分;
- 在training sets上训练模型;
- 在validation sets和test sets上得到预测结果;
- 将validation sets的原始特征和不同基模型base model预测得到的结果作为新的元学习器meta learner的输入,进行训练 ;
- 使用训练好的模型meta learner在test sets以及在base model上的预测结果上进行预测,得到最终结果。
Stacking与Blending的对比:
优点在于:
- blending比stacking简单,因为不用进行k次的交叉验证来获得stacker feature
- blending避开了一个信息泄露问题:generlizers和stacker使用了不一样的数据集
缺点在于:
- blending使用了很少的数据(第二阶段的blender只使用training set10%的量)
- blender可能会过拟合
- stacking使用多次的交叉验证会比较稳健
Bagging
基本思想:Bagging基于bootstrap(自采样),也就是有放回的采样。训练子集的大小和原始数据集的大小相同。Bagging的技术使用子集来了解整个样本集的分布,通过bagging采样的子集的大小要小于原始集合。
- 采用bootstrap的方法基于原始数据集产生大量的子集
- 基于这些子集训练弱模型base model
- 模型是并行训练并且相互独立的
- 最终的预测结果取决于多个模型的预测结果
Bagging是一种并行式的集成学习方法,即基学习器的训练之间没有前后顺序可以同时进行,Bagging使用“有放回”采样的方式选取训练集,对于包含m个样本的训练集,进行m次有放回的随机采样操作,从而得到m个样本的采样集,这样训练集中有接近36.8%的样本没有被采到。按照相同的方式重复进行,我们就可以采集到T个包含m个样本的数据集,从而训练出T个基学习器,最终对这T个基学习器的输出进行结合。
Boosting
基础思想:Boosting是一种串行的工作机制,即个体学习器的训练存在依赖关系,必须一步一步序列化进行。Boosting是一个序列化的过程,后续模型会矫正之前模型的预测结果。也就是说,之后的模型依赖于之前的模型。
其基本思想是:增加前一个基学习器在训练训练过程中预测错误样本的权重,使得后续基学习器更加关注这些打标错误的训练样本,尽可能纠正这些错误,一直向下串行直至产生需要的T个基学习器,Boosting最终对这T个学习器进行加权结合,产生学习器委员会。
Boosting训练过程:
- 基于原始数据集构造子集
- 初始的时候,所有的数据点都给相同的权重
- 基于这个子集创建一个基模型
- 使用这个模型在整个数据集上进行预测
- 基于真实值和预测值计算误差
- 被预测错的观测值会赋予更大的权重
- 再构造一个模型基于之前预测的误差进行预测,这个模型会尝试矫正之前的模型
- 类似地,构造多个模型,每一个都会矫正之前的误差
- 最终的模型(strong learner)是所有弱学习器的加权融合
7、损失函数,注意不同类别的权重(使用F1_loss、Hamming Loss、数据类别分布不均,如何解决长尾分布(加权损失、先验权重))
相关论文: sigmoidF1: A Smooth F1 Score Surrogate Loss for Multilabel Classification
平时我们在做多标签分类,或者是多分类的时候,经常使用的loss函数一般是binary_crossentropy(也就是log_loss)或者是categorical_crossentropy,不过交叉熵其实还是有点问题的,在多标签分类的问题里,交叉熵并非是最合理的损失函数。在多标签分类的问题中,我们最终评价往往会选择F1分数作为评价指标,那么是否能直接将F1-score制作成为一个loss函数呢?当然是可以的。
在多分类/多标签分类中,F1-score有两种衍生格式,分别是micro-F1和macro-F1。是两种不同的计算方式。
micro-F1是先计算先拿总体样本来计算出TP、TN、FP、FN的值,再使用这些值计算出percision和recall,再来计算出F1值。
macro-F1则是先对每一种分类,视作二分类,计算其F1值,最后再对每一个分类进行简单平均。
简单的记的话其实是这样的,micro(微观)与macro(宏观)的含义其实是,micro-F1是在样本的等级上做平均,是最小颗粒度上的平均了,所以是微观。macro-F1是在每一个分类的层面上做平均,每一个分类都包含很多样本,所以相对是宏观。
作为loss函数的F1
F1-score改造成loss函数相对较为简单,F1是范围在0~1之间的指标,越大代表性能越好,在作为loss时只需要取(1-F1)即可。
一下是keras中的实现:
(这里的K就是keras的后端,一般来说就是tensorflow)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
K = keras.backend def f1_loss(y_true, y_pred): #计算tp、tn、fp、fn tp = K.sum(K.cast(y_true*y_pred, ‘float’), axis=0) tn = K.sum(K.cast((1-y_true)*(1-y_pred), ‘float’), axis=0) fp = K.sum(K.cast((1-y_true)*y_pred, ‘float’), axis=0) fn = K.sum(K.cast(y_true*(1-y_pred), ‘float’), axis=0) #percision与recall,这里的K.epsilon代表一个小正数,用来避免分母为零 p = tp / (tp + fp + K.epsilon()) r = tp / (tp + fn + K.epsilon()) #计算f1 f1 = 2*p*r / (p+r+K.epsilon()) f1 = tf.where(tf.is_nan(f1), tf.zeros_like(f1), f1)#其实就是把nan换成0 return 1 – K.mean(f1) |
这个函数可以直接在keras模型编译时使用,如下:
| 1 2 3 4 |
# 类似这样 model.compile(optimizer=tf.train.AdamOptimizer(0.003), loss=f1_loss, metrics=[‘acc’,’mae’]) |
def f1_loss(predict, target):
predict = torch.sigmoid(predict)
predict = torch.clamp(predict * (1-target), min=0.01) + predict * target
tp = predict * target
tp = tp.sum(dim=0)
precision = tp / (predict.sum(dim=0) + 1e-8)
recall = tp / (target.sum(dim=0) + 1e-8)
f1 = 2 * (precision * recall / (precision + recall + 1e-8))
return 1 - f1.mean()8、考虑将多分类 变成多个二分类任务
9、除了bert模型,还可以尝试Performer、ernie-health
Performer 是ICLR 2021的新paper,在处理长序列预测方面有非常不错的结果,速度快,内存小,在LRA(long range arena 一个统一的benchmark)上综合得分不错。
论文:https://arxiv.org/pdf/2009.14794.pdf
ernie-health :Building Chinese Biomedical Language Models via Multi-Level Text Discrimination
中文题目:基于多层次文本辨析构建中文生物医学语言模型
论文地址:https://arxiv.org/pdf/2110.07244.pdf
领域:自然语言处理,生物医学
发表时间:2021
作者:Quan Wang等,百度
模型下载:https://huggingface.co/nghuyong/ernie-health-zh
模型介绍:https://github.com/PaddlePaddle/Research/tree/master/KG/eHealth
模型代码:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-health
10、NLP中的对抗训练 (添加的扰动是微小)
- 提高模型应对恶意对抗样本时的鲁棒性;
- 作为一种regularization,减少overfitting,提高泛化能力。
对抗训练其实是“对抗”家族中防御的一种方式,其基本的原理呢,就是通过添加扰动构造一些对抗样本,放给模型去训练,以攻为守,提高模型在遇到对抗样本时的鲁棒性,同时一定程度也能提高模型的表现和泛化能力。
那么,什么样的样本才是好的对抗样本呢?对抗样本一般需要具有两个特点:
- 相对于原始输入,所添加的扰动是微小的;
- 能使模型犯错。
NLP中的两种对抗训练 + PyTorch实现
a. Fast Gradient Method(FGM)
上面我们提到,Goodfellow在15年的ICLR [7] 中提出了Fast Gradient Sign Method(FGSM),随后,在17年的ICLR [9]中,Goodfellow对FGSM中计算扰动的部分做了一点简单的修改。假设输入的文本序列的embedding vectors [v1,v2,…,vT] 为 x ,embedding的扰动为:
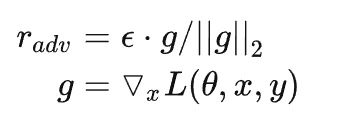
实际上就是取消了符号函数,用二范式做了一个scale,需要注意的是:这里的norm计算的是,每个样本的输入序列中出现过的词组成的矩阵的梯度norm。原作者提供了一个TensorFlow的实现 [10],在他的实现中,公式里的 x 是embedding后的中间结果(batch_size, timesteps, hidden_dim),对其梯度 g 的后面两维计算norm,得到的是一个(batch_size, 1, 1)的向量 ||g||2 。为了实现插件式的调用,笔者将一个batch抽象成一个样本,一个batch统一用一个norm,由于本来norm也只是一个scale的作用,影响不大。实现如下:
import torch
class FGM():
def __init__(self, model):
self.model = model
self.backup = {}
def attack(self, epsilon=1., emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
self.backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0 and not torch.isnan(norm):
r_at = epsilon * param.grad / norm
param.data.add_(r_at)
def restore(self, emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.backup
param.data = self.backup[name]
self.backup = {}需要使用对抗训练的时候,只需要添加五行代码:
# 初始化
fgm = FGM(model)
for batch_input, batch_label in data:
# 正常训练
loss = model(batch_input, batch_label)
loss.backward() # 反向传播,得到正常的grad
# 对抗训练
fgm.attack() # 在embedding上添加对抗扰动
loss_adv = model(batch_input, batch_label)
loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度
fgm.restore() # 恢复embedding参数
# 梯度下降,更新参数
optimizer.step()
model.zero_grad()PyTorch为了节约内存,在backward的时候并不保存中间变量的梯度。因此,如果需要完全照搬原作的实现,需要用register_hook接口[11]将embedding后的中间变量的梯度保存成全局变量,norm后面两维,计算出扰动后,在对抗训练forward时传入扰动,累加到embedding后的中间变量上,得到新的loss,再进行梯度下降。
b. Projected Gradient Descent(PGD)
内部max的过程,本质上是一个非凹的约束优化问题,FGM解决的思路其实就是梯度上升,那么FGM简单粗暴的“一步到位”,是不是有可能并不能走到约束内的最优点呢?当然是有可能的。于是,一个很intuitive的改进诞生了:Madry在18年的ICLR中[8],提出了用Projected Gradient Descent(PGD)的方法,简单的说,就是“小步走,多走几步”,如果走出了扰动半径为 ϵ 的空间,就映射回“球面”上,以保证扰动不要过大:

import torch
class PGD():
def __init__(self, model):
self.model = model
self.emb_backup = {}
self.grad_backup = {}
def attack(self, epsilon=1., alpha=0.3, emb_name='emb.', is_first_attack=False):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
if is_first_attack:
self.emb_backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0 and not torch.isnan(norm):
r_at = alpha * param.grad / norm
param.data.add_(r_at)
param.data = self.project(name, param.data, epsilon)
def restore(self, emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.emb_backup
param.data = self.emb_backup[name]
self.emb_backup = {}
def project(self, param_name, param_data, epsilon):
r = param_data - self.emb_backup[param_name]
if torch.norm(r) > epsilon:
r = epsilon * r / torch.norm(r)
return self.emb_backup[param_name] + r
def backup_grad(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
self.grad_backup[name] = param.grad.clone()
def restore_grad(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
param.grad = self.grad_backup[name]使用的时候,要麻烦一点:
pgd = PGD(model)
K = 3
for batch_input, batch_label in data:
# 正常训练
loss = model(batch_input, batch_label)
loss.backward() # 反向传播,得到正常的grad
pgd.backup_grad()
# 对抗训练
for t in range(K):
pgd.attack(is_first_attack=(t==0)) # 在embedding上添加对抗扰动, first attack时备份param.data
if t != K-1:
model.zero_grad()
else:
pgd.restore_grad()
loss_adv = model(batch_input, batch_label)
loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度
pgd.restore() # 恢复embedding参数
# 梯度下降,更新参数
optimizer.step()
model.zero_grad()实验对照
为了说明对抗训练的作用,笔者选了四个GLUE中的任务进行了对照试验。实验代码是用的Huggingface的transfomers/examples/run_glue.py [12],超参都是默认的,对抗训练用的也是相同的超参。
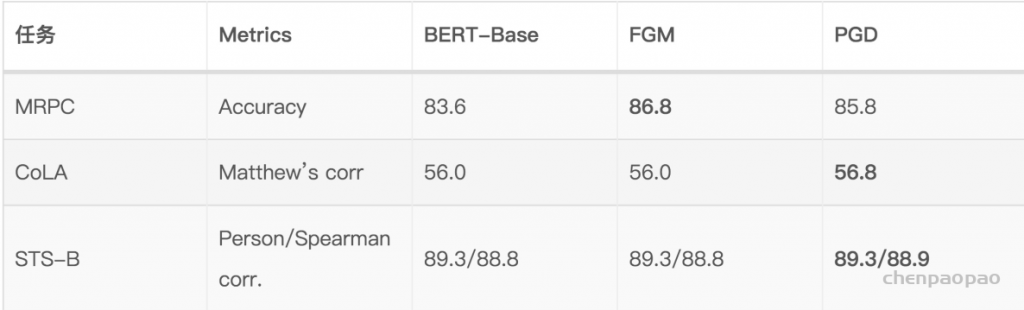
除了监督训练,对抗训练还可以用在半监督任务中,尤其对于NLP任务来说,很多时候输入的无监督文本多的很,但是很难大规模地进行标注,Distributional Smoothing with Virtual Adversarial Training. https://arxiv.org/abs/1507.00677 提到的 Virtual Adversarial Training进行半监督训练。
11、Pseudo Labeling(伪标签)提高模型的分类效果
简而言之,Pseudo Labeling将测试集中判断结果正确的置信度高的样本加入到训练集中,从而模拟一部分人类对新对象进行判断推演的过程。效果比不上人脑那么好,但是在监督学习问题中,Pseudo Labeling几乎是万金油,几乎能够让你模型各个方面的表现都得到提升。
- 使用原始训练集训练并建立模型
- 使用训练好的模型对测试集进行分类
- 将预测正确置信度高的样本加入到训练集中
- 使用结合了部分测试集样本的新训练集再次训练模型
- 使用新模型再次进行预测
总之:提分点很多,但能否有效以及能否实现又是另一个事情了,毕竟有时候是否有效也取决于数据集,毕竟缘分,妙不可言~,后续我会抽时间将上面的tricks都尝试尝试。