
论文: https://arxiv.org/abs/2205.11487
demo地址:https://imagen.research.google/
文本生成图像模型界又出新手笔!
这次的主角是Google Brain推出的 Imagen,再一次突破人类想象力,将文本生成图像的逼真度和语言理解提高到了前所未有的新高度!比前段时间OpeAI家的DALL·E 2更强!
话不多说,我们来欣赏这位AI画师的杰作~A brain riding a rocketship heading towards the moon.(一颗大脑乘着火箭飞向月球。)


Imagen的工作原理

本方案的主要内容包括三部分,如下图所示,首先是文本编码器部分,本文直接使用的是T5,然后是Diffusion生成模型,这部分与Glide类似,都是使用classifier-free引导的方式。最后就是对生成的小图进行超分,变为大图。下面分模块详细介绍:
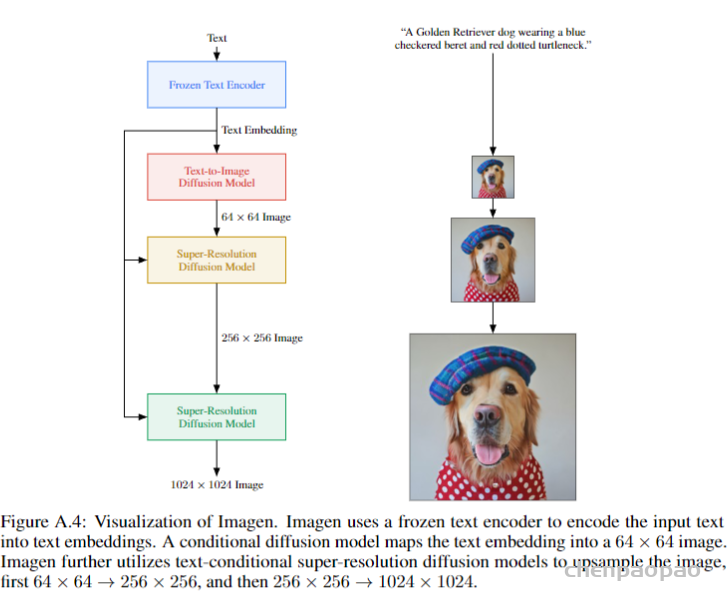
2.1. text编码部分
文本编码器部分对比了BERT(base模型参数量:1.1亿)、CLIP(0.63亿)以及T5(模型参数量:110亿),后来发现T5效果最好。并且还舍弃了之前常规的基于<text, image>数据对,对Text Encoder进行finetune的流程。理由个很直接,因为参数量大好几个量级,不需要finetune。
2.2. Diffusion生成部分
这部分跟Glide中的基本相近,可以直接与Glide文章中对eps建模公式进行对比。只是在uncondition的时候没有使用空的文本表示。
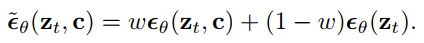
classifier-free应该是diffusion必备的优化方式了。融合text特征到生成模型中的部分也可以直接看Glide。这部分的模型还是典型的64*64的U-Net结构,如下图2所示。之所以选择小模型主要还是diffusion的迭代过程太长,导致生成过程慢,所以生成小图是提速最方便的,但是也注定了无法生成比较复杂内容和空间关系的大图。UNet网络由左编码部分,右解码部分和下两个卷积+激活层组成。
编码部分:左边红框架构中是由4个重复结构组成:2个3×3卷积层,非线形ReLU层和一个stride为2的2×2 max pooling层。每一次下采样特征通道的数量加倍。
解码部分:右边蓝框,反卷积也有4个重复结构组成。每个重复结构前先使用反卷积,每次反卷积后特征通道数量减半,特征图大小加倍反卷积之后,反卷积的结果和编码部分对应步骤的特征图拼接起来。拼接后的特征图再进行2次3×3的卷积,最后一层的卷积核为1×1 的卷积核,将64通道的特征图转化为特定类别数量的结果
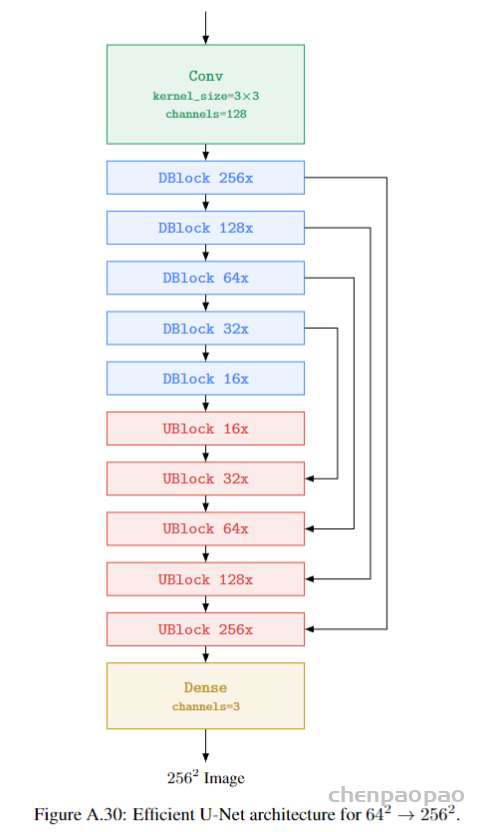
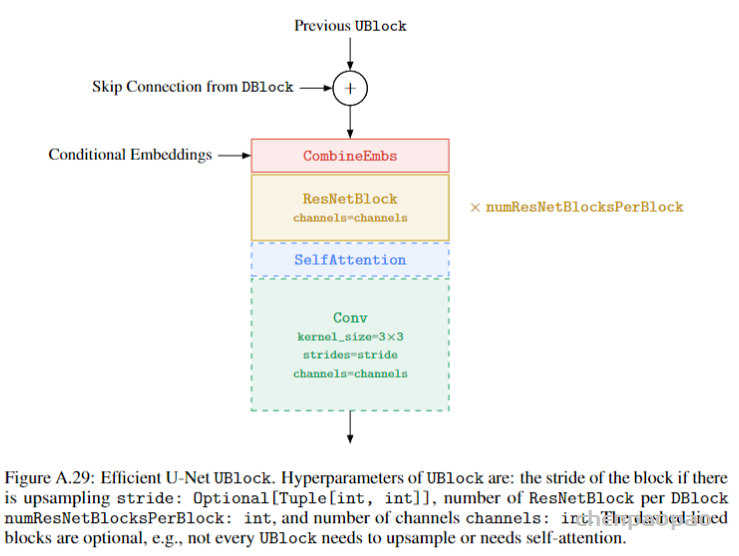
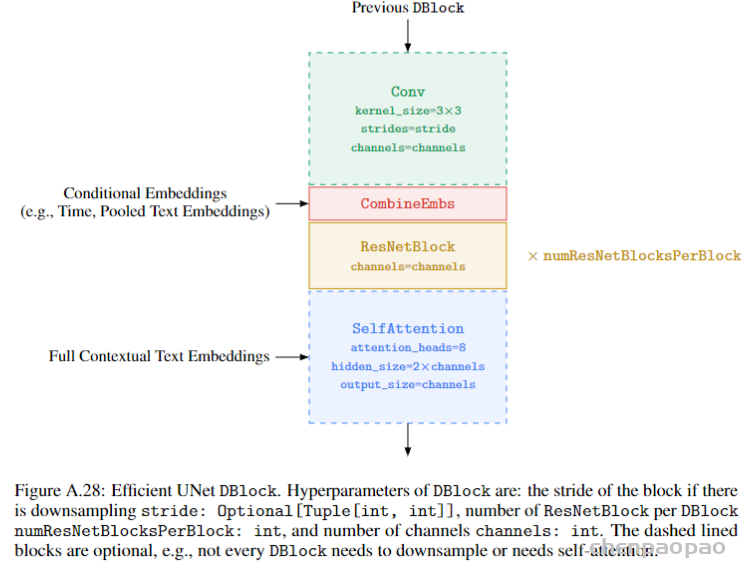
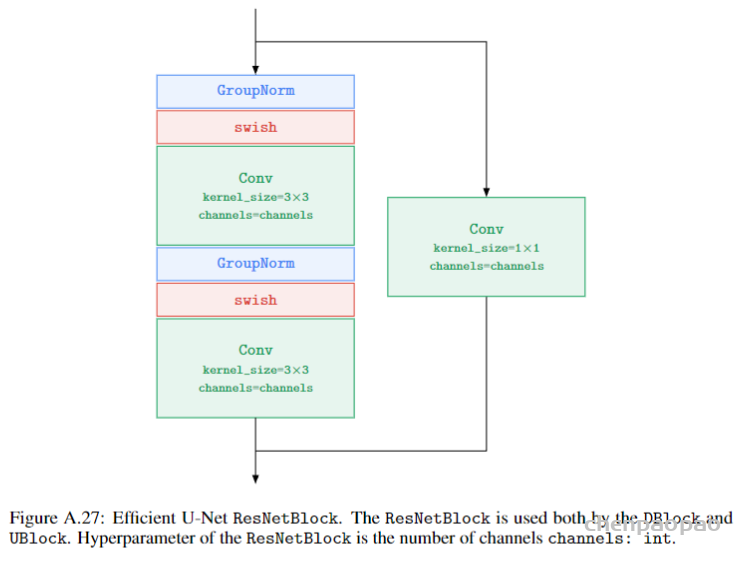
2.3. Diffusion超分部分
超分的好处是可以直接带来效率的提高,但是可能会影响最终生成的细节失真,本文在本文提到通过噪声的增强,可以提升模型在控制失真上鲁棒性,具体原理还是要详细看论文了。这部分模型使用的是U-Net的变体Efficient U-Net模型,有点就是提升记忆感知、推理效率以及训练收敛速度。
大型预训练语言模型×级联扩散模型
Imagen使用在纯文本语料中进行预训练的通用大型语言模型(例如T5),它能够非常有效地将文本合成图像:在Imagen中增加语言模型的大小,而不是增加图像扩散模型的大小,可以大大地提高样本保真度和图像-文本对齐。
Imagen的研究突出体现在:
- 大型预训练冻结文本编码器对于文本到图像的任务来说非常有效;
- 缩放预训练的文本编码器大小比缩放扩散模型大小更重要;
- 引入一种新的阈值扩散采样器,这种采样器可以使用非常大的无分类器指导权重;
- 引入一种新的高效U-Net架构,这种架构具有更高的计算效率、更高的内存效率和更快的收敛速度;
- Imagen在COCO数据集上获得了最先进的FID分数7.27,而没有对COCO进行任何训练,人类评分者发现,Imagen样本在图像-文本对齐方面与COCO数据本身不相上下。
2
引入新基准DrawBench
为了更深入地评估文本到图像模型,Google Brain 引入了DrawBench,这是一个全面的、具有挑战性的文本到图像模型基准。通过DrawBench,他们比较了Imagen与VQ-GAN+CLIP、Latent Diffusion Models和DALL-E 2等其他方法,发现人类评分者在比较中更喜欢Imagen而不是其他模型,无论是在样本质量上还是在图像-文本对齐方面。
- 并排人类评估;
- 对语意合成性、基数性、空间关系、长文本、生词和具有挑战性的提示几方面提出了系统化的考验;
- 由于图像-文本对齐和图像保真度的优势,相对于其他方法,用户强烈倾向于使用Imagen。
3 打开了潘多拉魔盒?
像Imagen这样从文本生成图像的研究面临着一系列伦理挑战。
首先,文本-图像模型的下游应用多种多样,可能会从多方面对社会造成影响。Imagen以及一切从文本生成图像的系统都有可能被误用的潜在风险,因此社会要求开发方提供负责任的开源代码和演示。基于以上原因,Google决定暂时不发布代码或进行公开演示。而在未来的工作中,Google将探索一个负责任的外部化框架,从而将各类潜在风险最小化。
其次,文本到图像模型对数据的要求导致研究人员严重依赖于大型的、大部分未经整理的、网络抓取的数据集。虽然近年来这种方法使算法快速进步,但这种性质的数据集往往会夹带社会刻板印象、压迫性观点、对边缘群体有所贬损等“有毒”信息。
为了去除噪音和不良内容(如色情图像和“有毒”言论),Google对训练数据的子集进行了过滤,同时Google还使用了众所周知的LAION-400M数据集进行过滤对比,该数据集包含网络上常见的不当内容,包括色情图像、种族主义攻击言论和负面社会刻板印象。Imagen依赖于在未经策划的网络规模数据上训练的文本编码器,因此继承了大型语言模型的社会偏见和局限性。这说明Imagen可能存在负面刻板印象和其他局限性,因此Google决定,在没有进一步安全措施的情况下,不会将Imagen发布给公众使用。