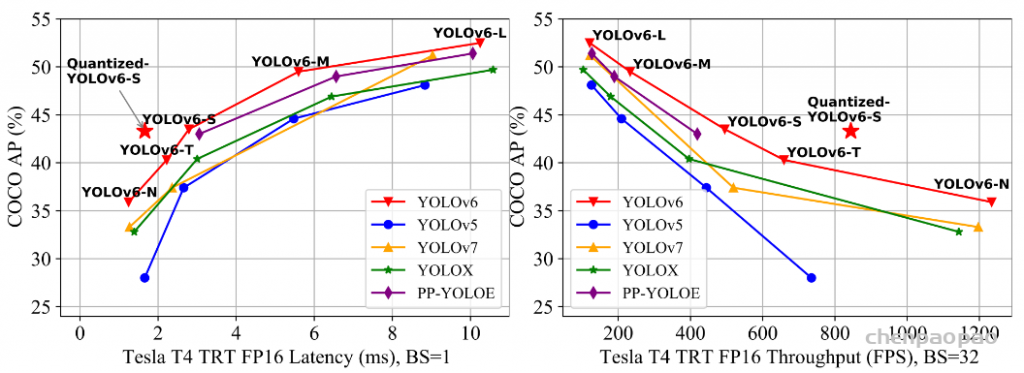
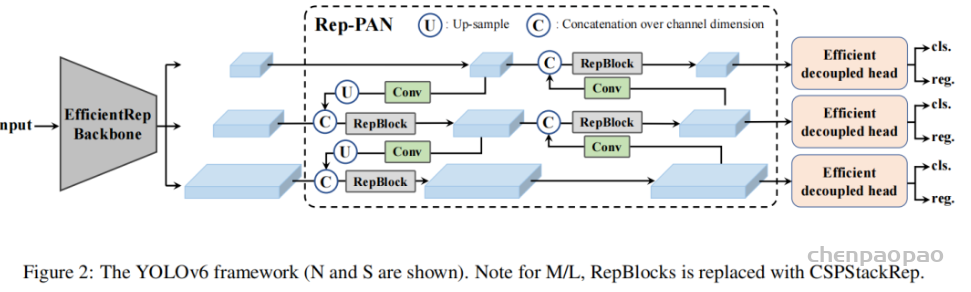
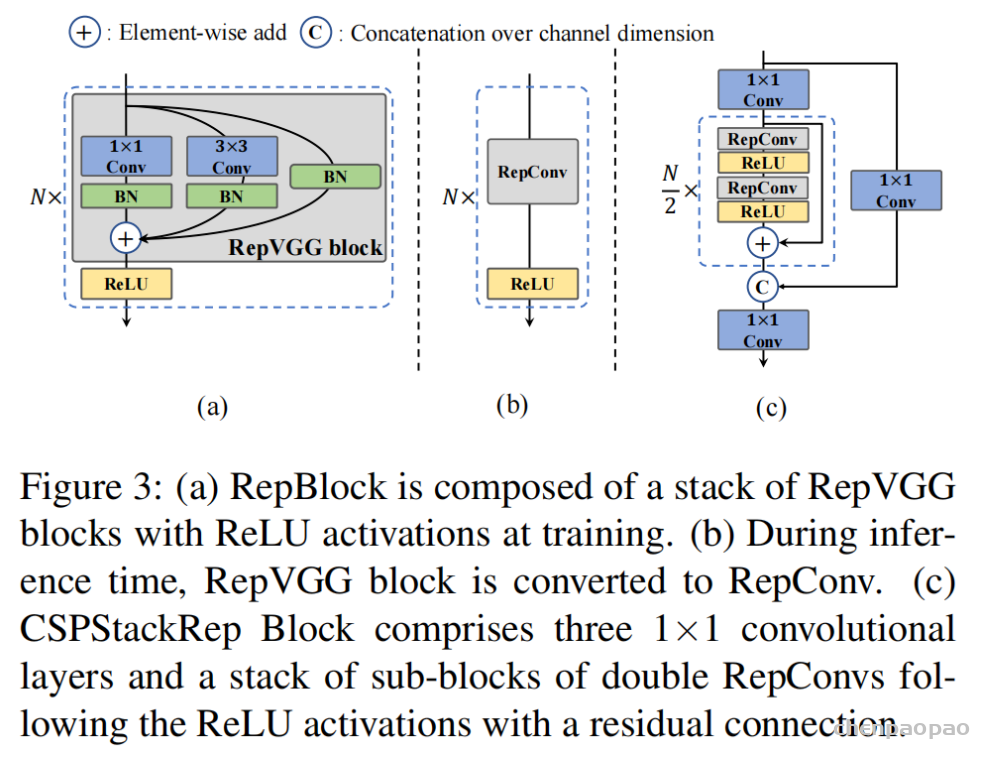
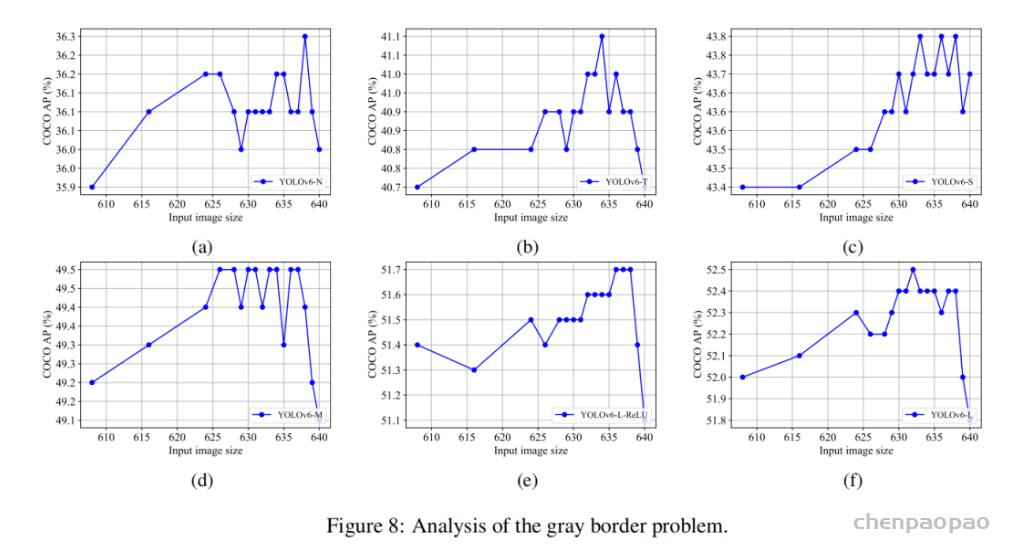
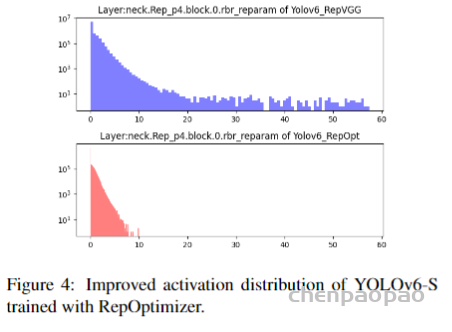
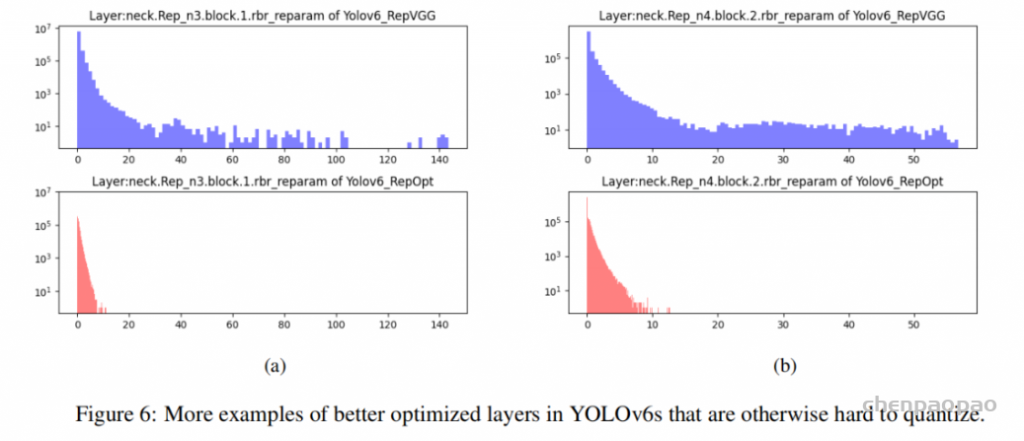
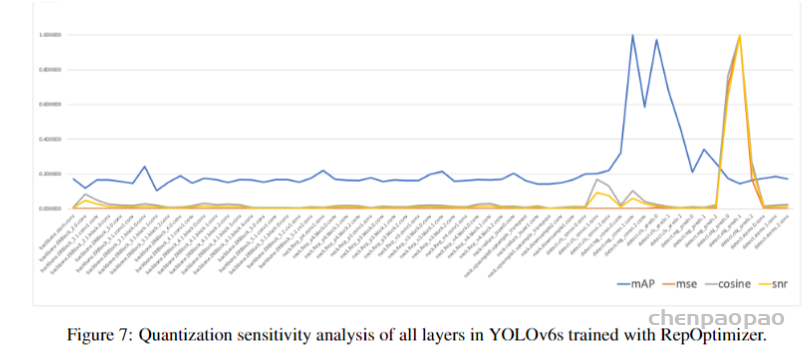
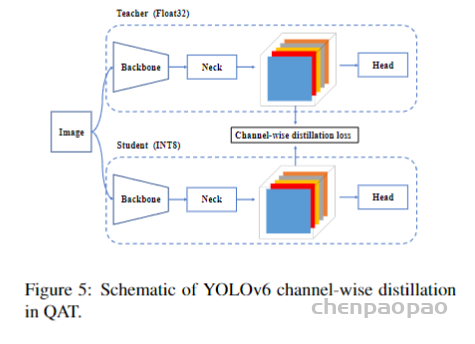
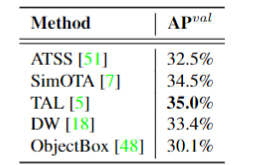
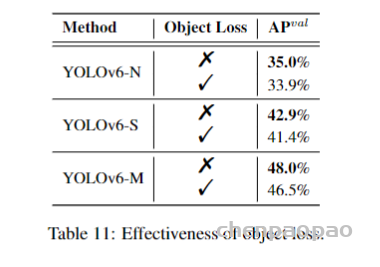
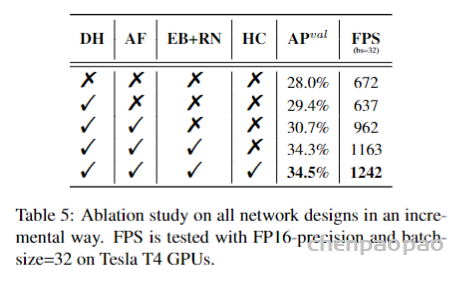
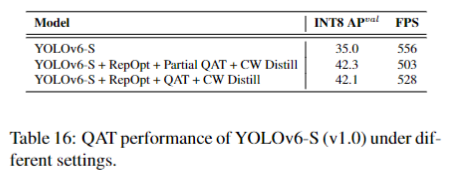
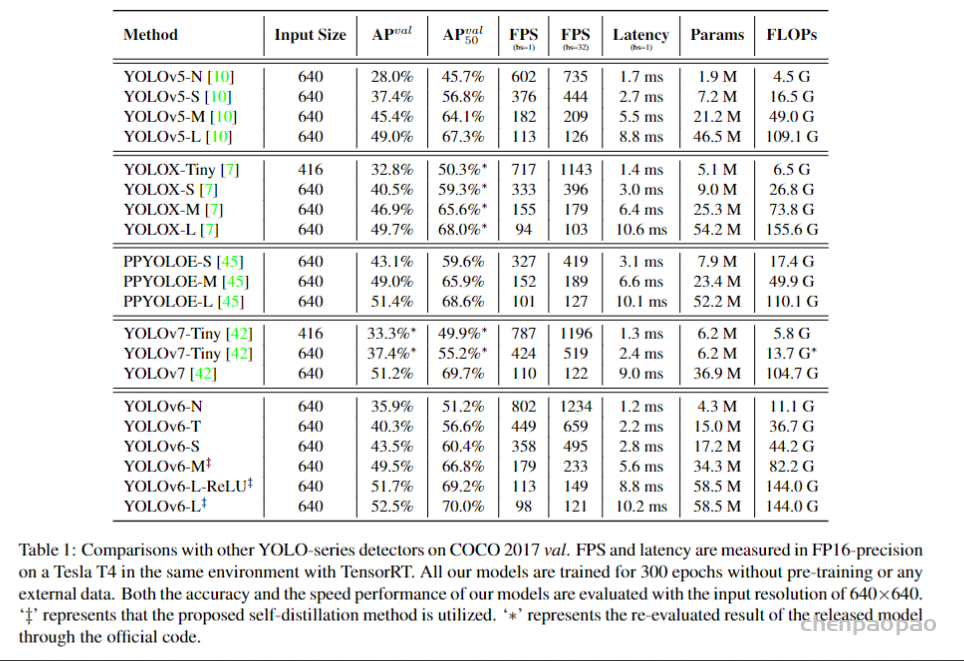
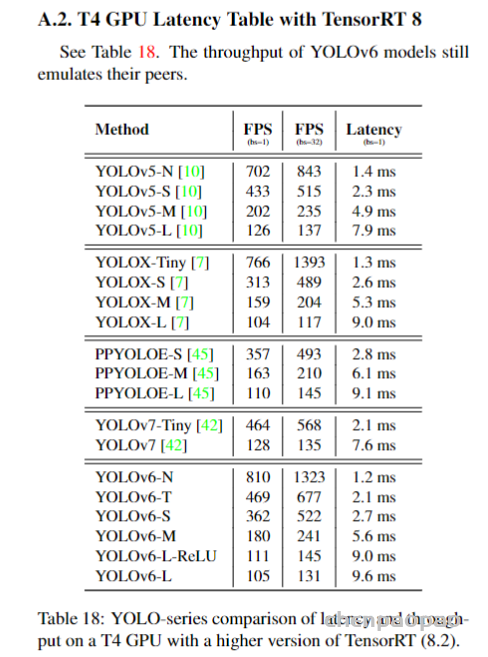
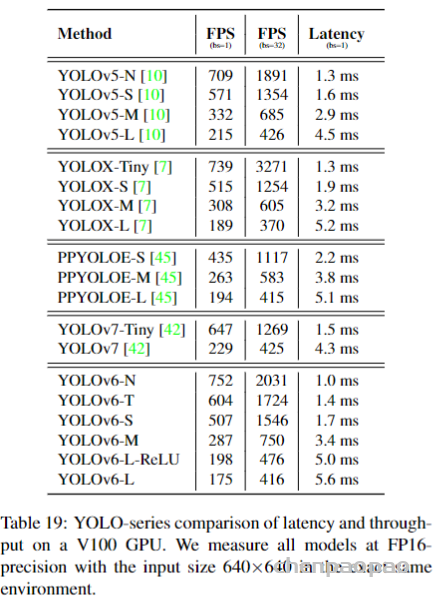
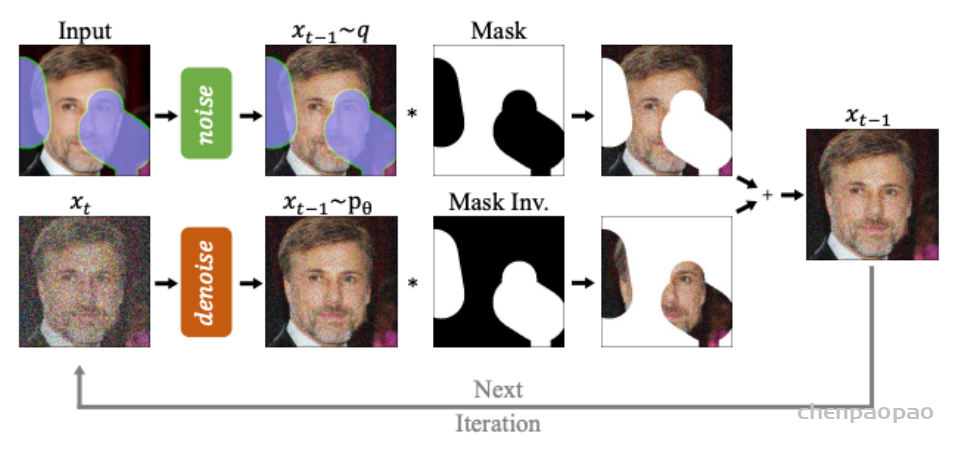
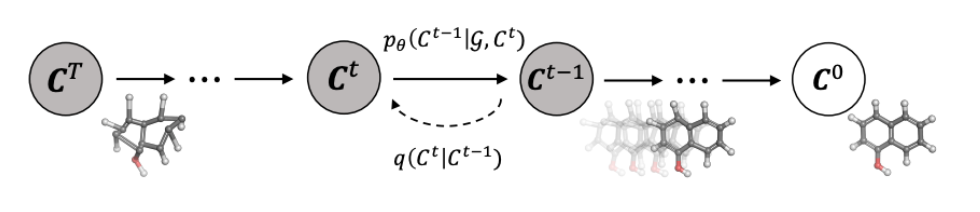
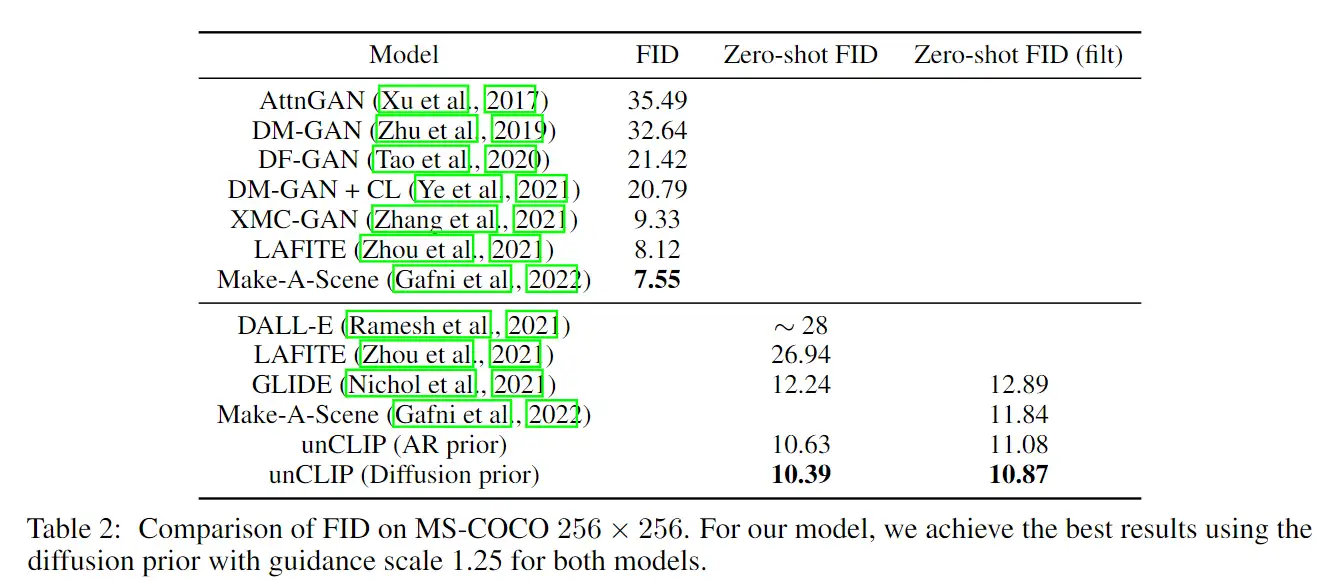
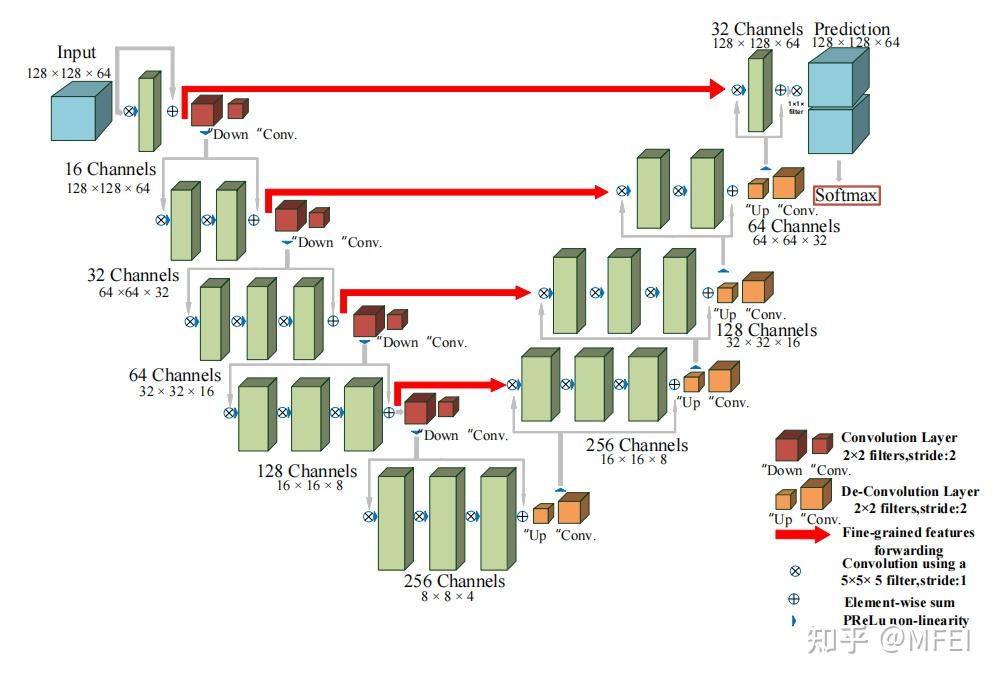
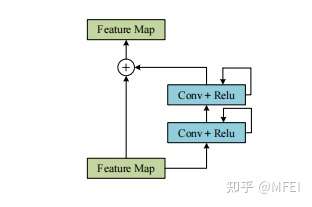
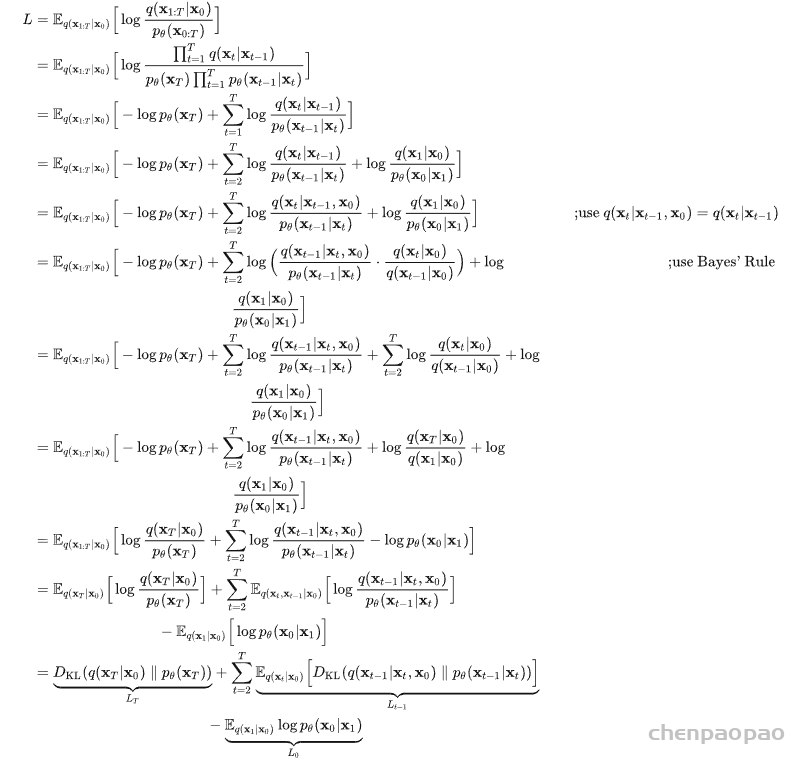
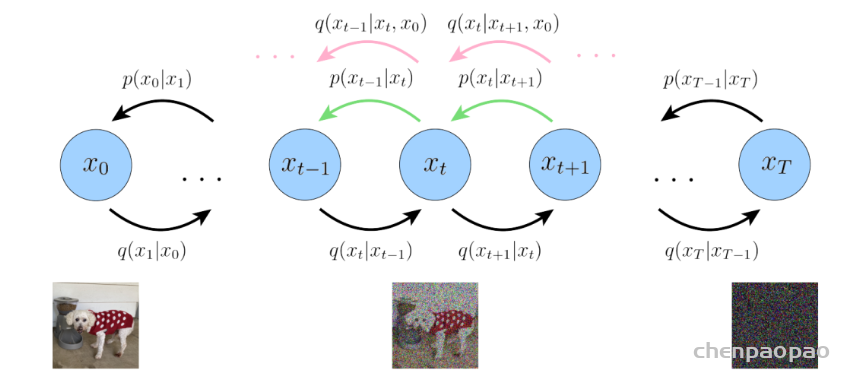
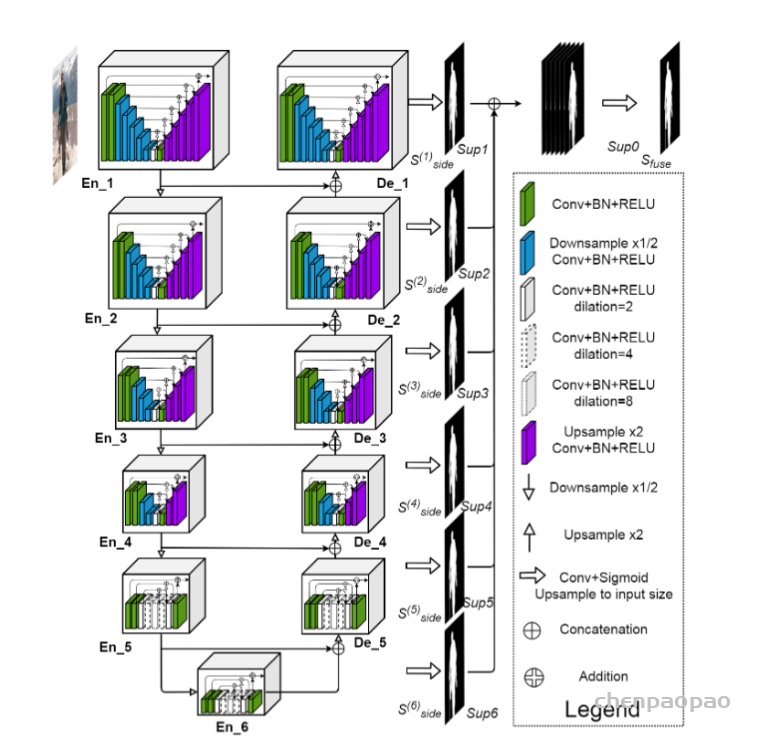
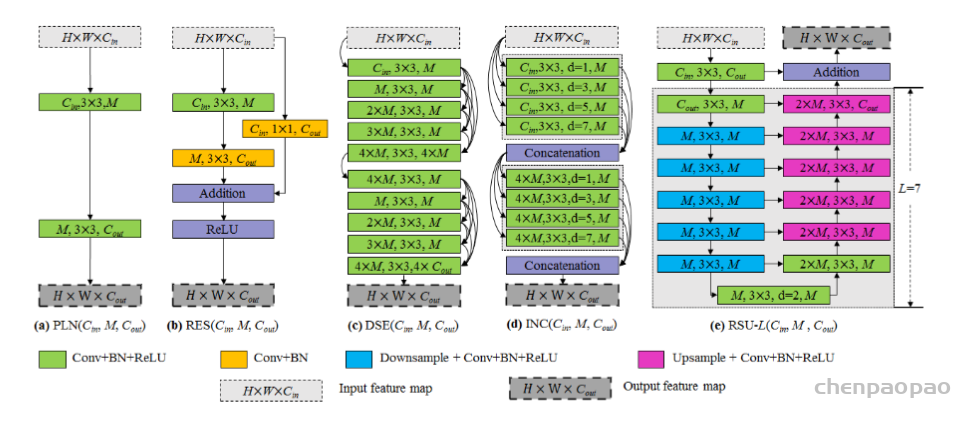
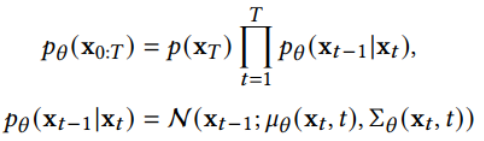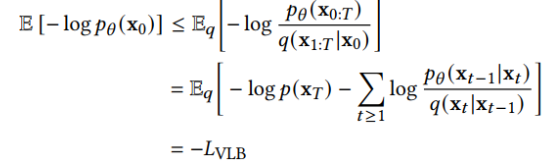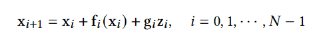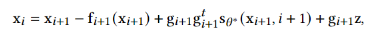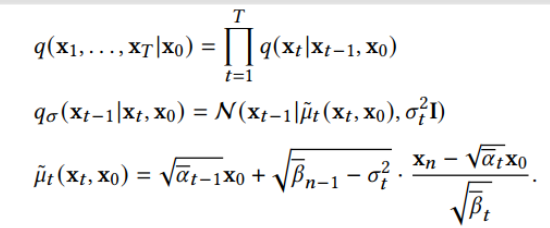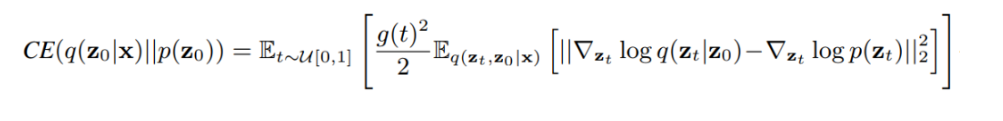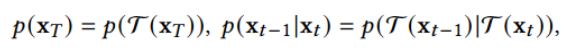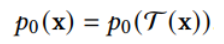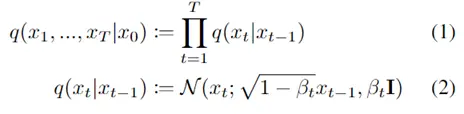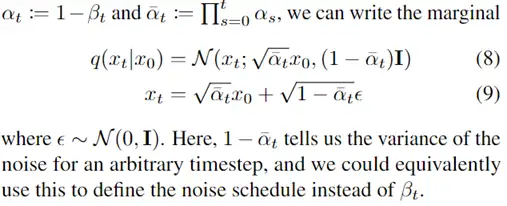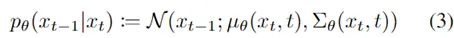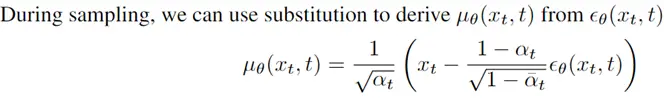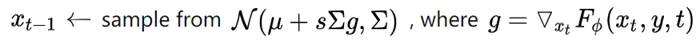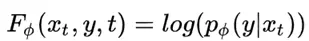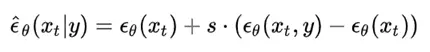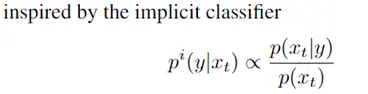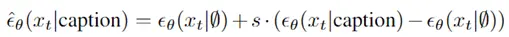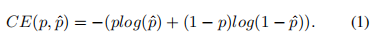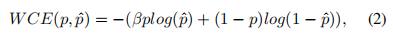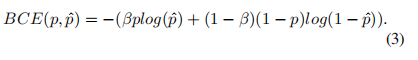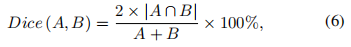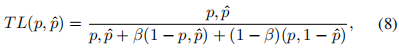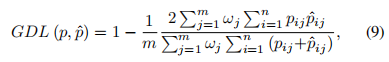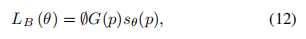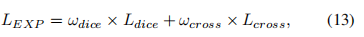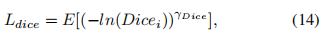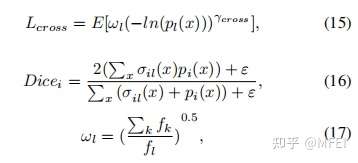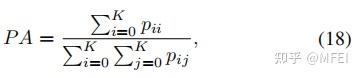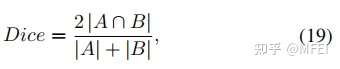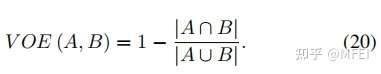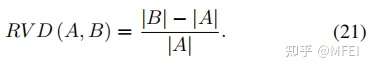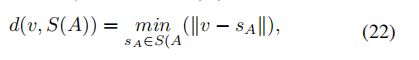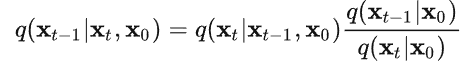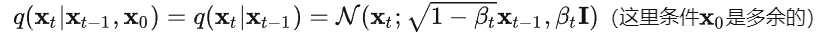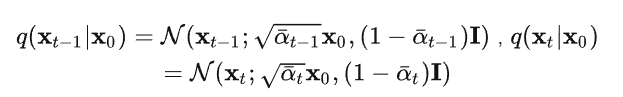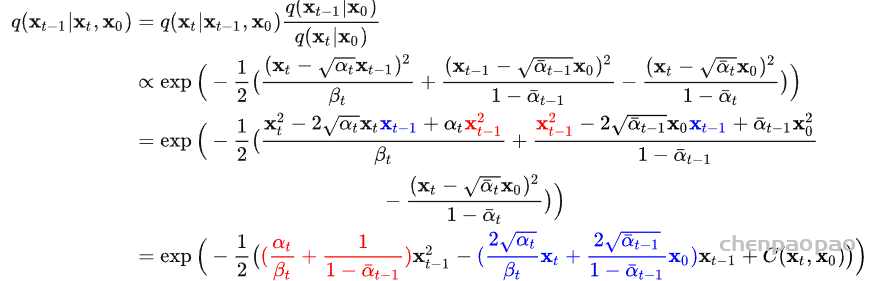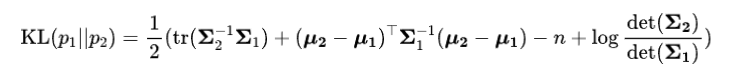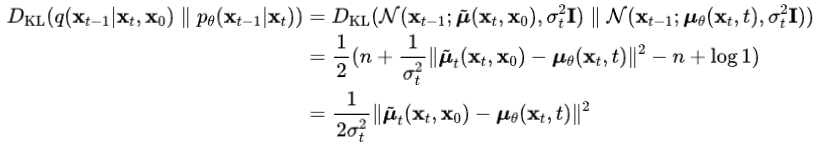此外,作者观察到 TAL 可以带来比 SimOTA 更多的性能提升并稳定训练。因此,采用 TAL 作为 YOLOv6 中的默认标签分配策略。
2.3、损失函数
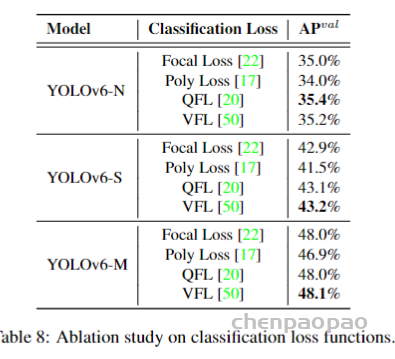
1、Classification Loss
提高分类器的性能是优化检测器的关键部分。Focal Loss 修改了传统的交叉熵损失,以解决正负样本之间或难易样本之间的类别不平衡问题。为了解决训练和推理之间质量估计和分类的不一致使用,Quality Focal Loss(QFL)进一步扩展了Focal Loss,联合表示分类分数和分类监督的定位质量。而 VariFocal Loss (VFL) 源于 Focal Loss,但它不对称地对待正样本和负样本。通过考虑不同重要性的正负样本,它平衡了来自两个样本的学习信号。Poly Loss 将常用的分类损失分解为一系列加权多项式基。它在不同的任务和数据集上调整多项式系数,通过实验证明比交叉熵损失和Focal Loss损失更好。
在 YOLOv6 上评估所有这些高级分类损失,最终采用 VFL。
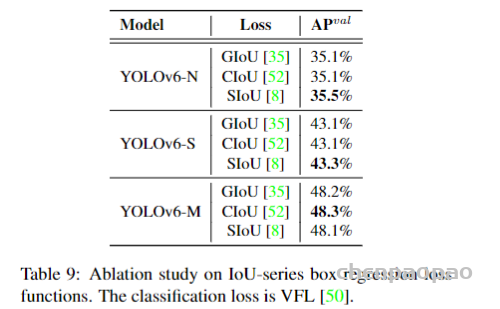
2、Box Regression Loss
框回归损失提供了精确定位边界框的重要学习信号。L1 Loss 是早期作品中的原始框回归损失。逐渐地,各种精心设计的框回归损失如雨后春笋般涌现,例如 IoU-series 损失和概率损失。
IoU-series Loss IoU loss 将预测框的四个边界作为一个整体进行回归。它已被证明是有效的,因为它与评估指标的一致性。IoU的变种有很多,如GIoU、DIoU、CIoU、α-IoU和SIoU等,形成了相关的损失函数。我们在这项工作中对 GIoU、CIoU 和 SIoU 进行了实验。并且SIoU应用于YOLOv6-N和YOLOv6-T,而其他的则使用GIoU。
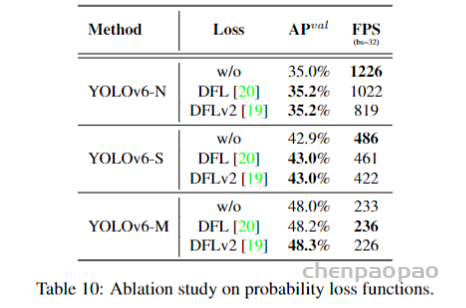
Probability Loss Distribution Focal Loss (DFL) 将框位置的基本连续分布简化为离散化的概率分布。它在不引入任何其他强先验的情况下考虑了数据中的模糊性和不确定性,这有助于提高框定位精度,尤其是在ground-truth框的边界模糊时。在 DFL 上,DFLv2 开发了一个轻量级的子网络,以利用分布统计数据与真实定位质量之间的密切相关性,进一步提高了检测性能。然而,DFL 输出的回归值通常比一般框回归多 17 倍,从而导致大量开销。额外的计算成本阻碍了小型模型的训练。而 DFLv2 由于额外的子网络,进一步增加了计算负担。在实验中,DFLv2 在模型上为 DFL 带来了类似的性能提升。因此,只在 YOLOv6-M/L 中采用 DFL。
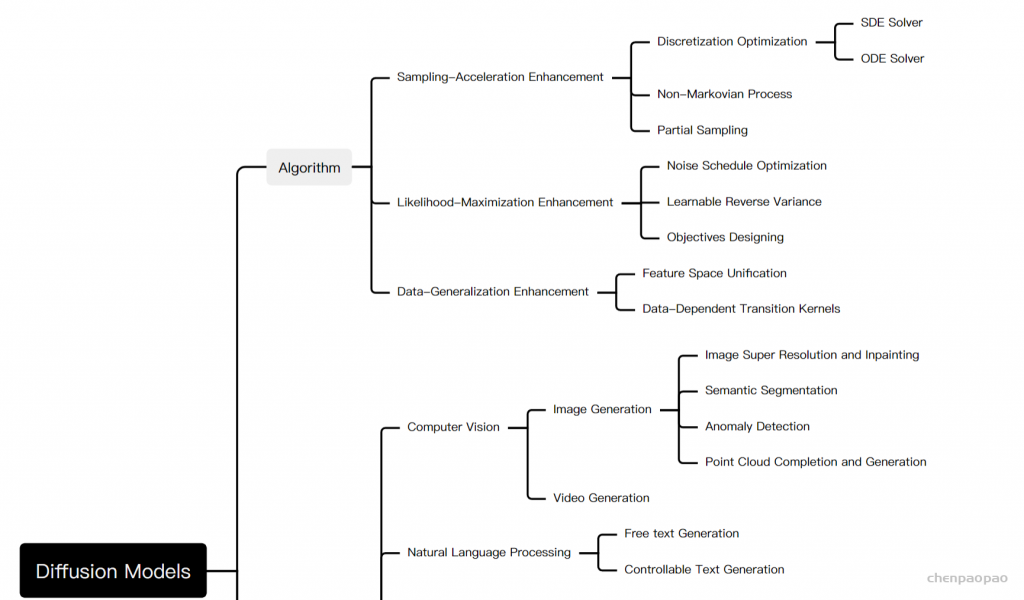
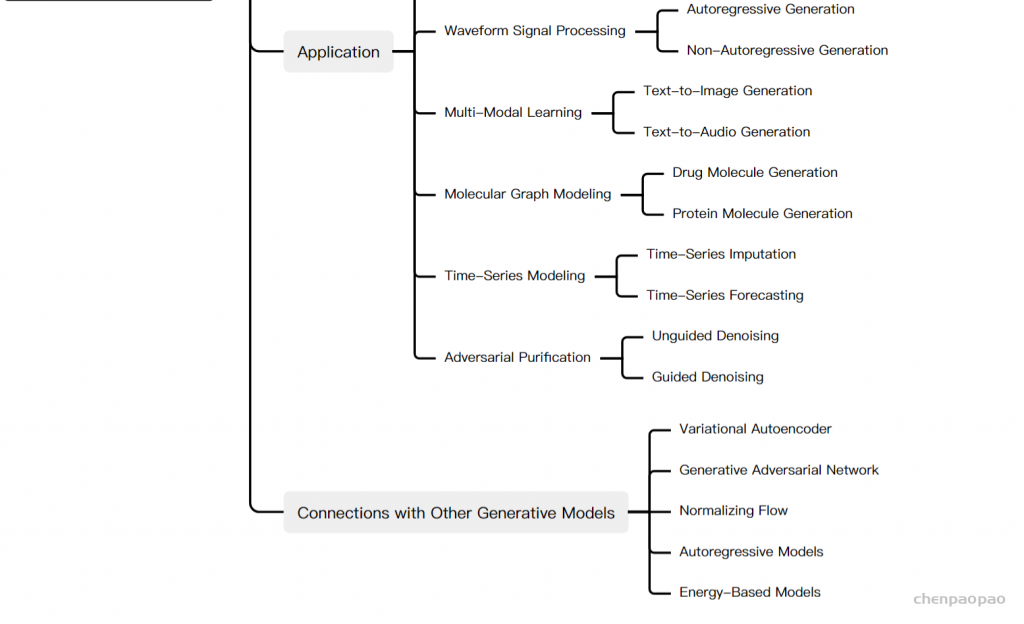
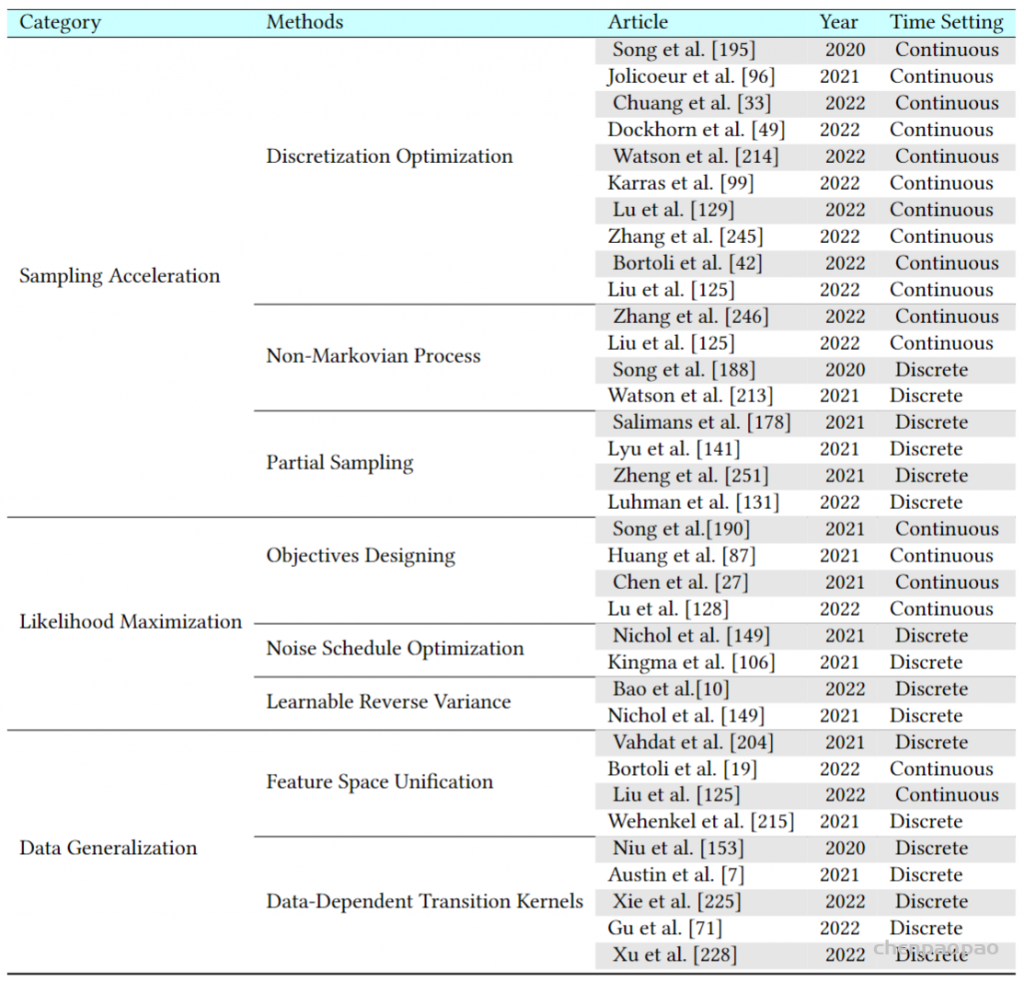
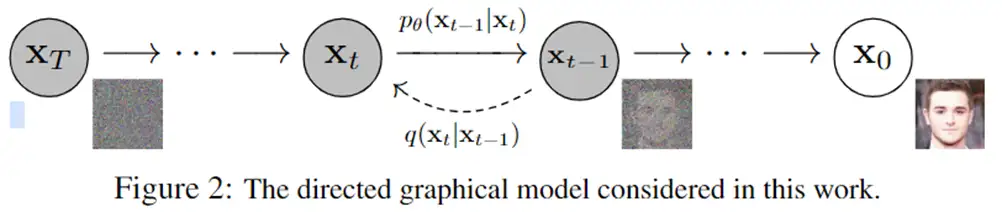
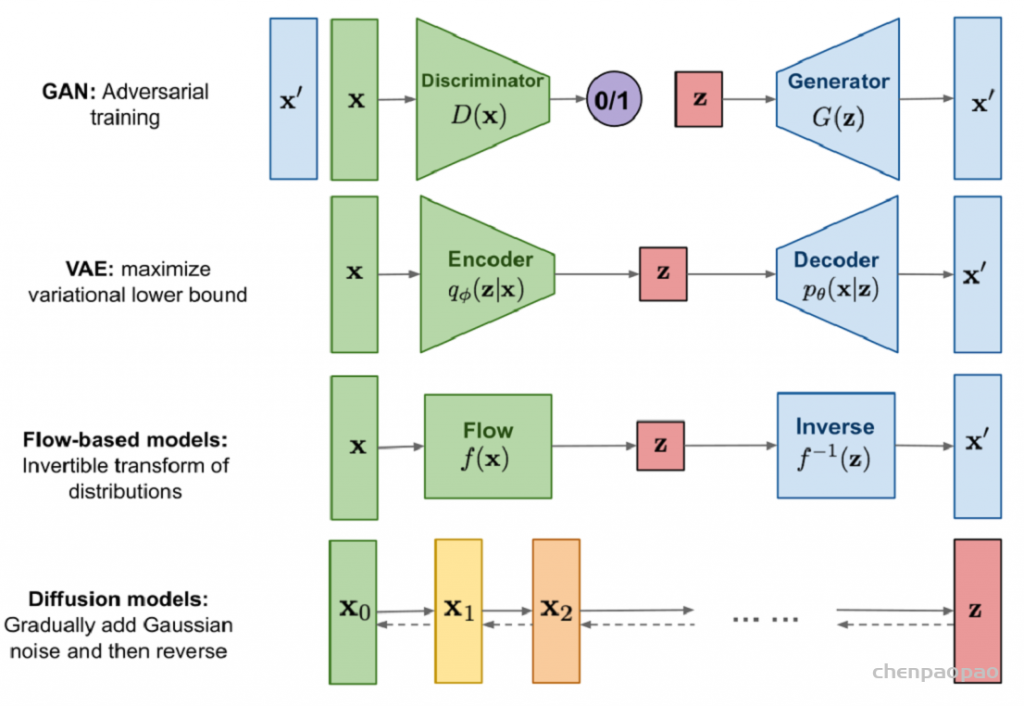
Diffusion Models: A Comprehensive Survey of Methods and Applications来自加州大学&Google Research的Ming-Hsuan Yang、北京大学崔斌实验室以及CMU、UCLA、蒙特利尔Mila研究院等众研究团队,首次对现有的扩散生成模型(diffusion model)进行了全面的总结分析,从diffusion model算法细化分类、和其他五大生成模型的关联以及在七大领域中的应用等方面展开,最后提出了diffusion model的现有limitation和未来的发展方向。
扩散模型假设数据存在于欧几里得空间,即具有平面几何形状的流形,并添加高斯噪声将不可避免地将数据转换为连续状态空间,所以扩散模型最初只能处理图片等连续性数据,直接应用离散数据或其他数据类型的效果较差。这限制了扩散模型的应用场景。数个研究工作将扩散模型推广到适用于其他数据类型的模型,我们对这些方法进行了详细地阐释。我们将其细化分类为两类方法:Feature Space Unification,Data-Dependent Transition Kernels。1.Feature Space Unification方法将数据转化到统一形式的latent space,然后再latent space上进行扩散。LSGM提出将数据通过VAE框架先转换到连续的latent space 上后再在其上进行扩散。这个方法的难点在于如何同时训练VAE和扩散模型。LSGM表明由于潜在先验是intractable的,分数匹配损失不再适用。LSGM直接使用VAE中传统的损失函数ELBO作为损失函数,并导出了ELBO和分数匹配的关系:
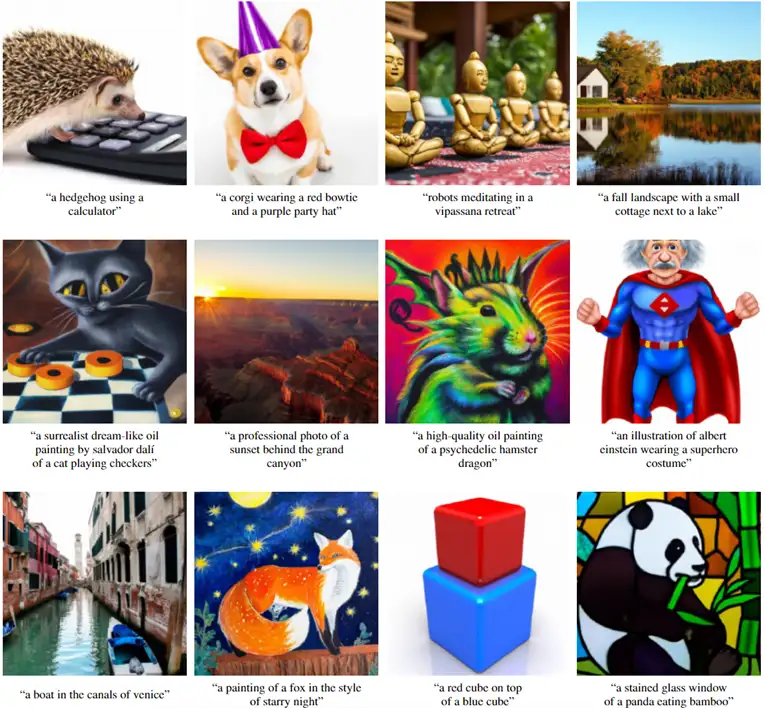
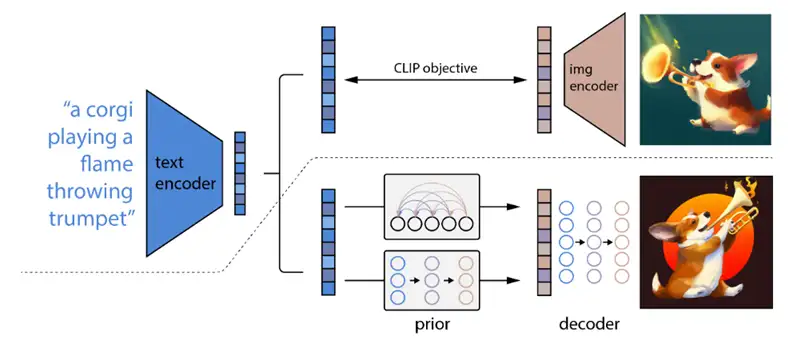
一种是auto-regressive model,将image embedding转换为一串离散的编码,并且基于condition caption y自回归地预测。(这里不一定要condition on caption(GLIDE的方法——额外用一个Transformer处理caption),也可以condition on CLIP text embedding)。此外,这里还用到了PCA来降维,降低运算复杂度。
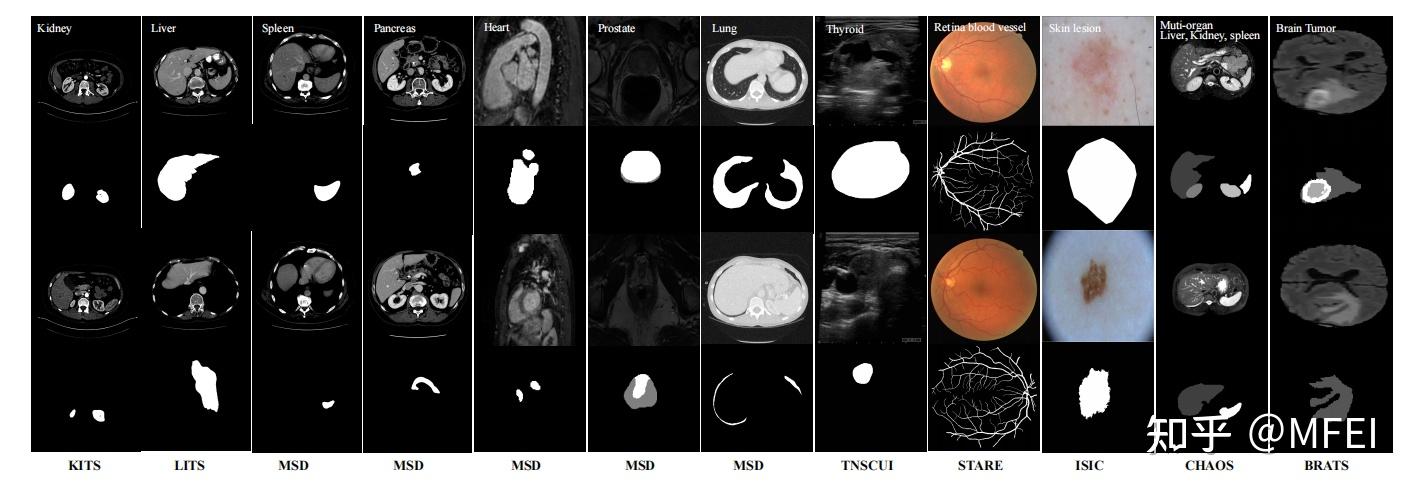
从正在进行的结直肠癌化疗试验和回顾性腹疝研究的组合中随机选择了 50 份腹部 CT 扫描。50 次扫描是在门静脉造影阶段捕获的,具有可变的体积大小 (512 x 512 x 85 – 512 x 512 x 198) 和视场(约 280 x 280 x 280 mm 3 – 500 x 500 x 650 mm 3) . 平面内分辨率从 0.54 x 0.54 mm 2到 0.98 x 0.98 mm 2不等,而切片厚度范围从 2.5 mm 到 5.0 mm。标准注册数据由NiftyReg生成。
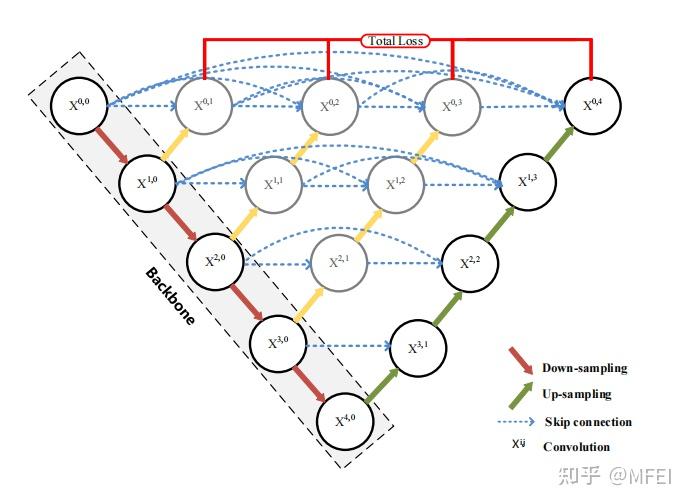
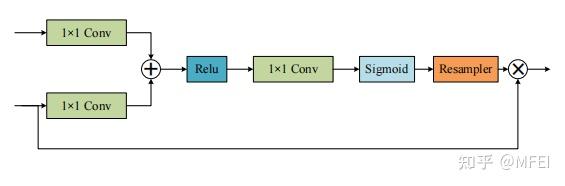
图9 The attention block in the attention U-Net 普通的pooling相当于信息合并,这很容易导致关键信息丢失。针对这个问题,设计了一个称为spatial transformer的块,通过执行空间变换来提取图像的关键信息。受此启发,Oktay等人[83]提出了attention U-Net。改进后的U-Net在融合来自编码器和相应的解码器的特征之前,使用一个注意块来改变编码器的输出。注意块输出门控信号来控制不同空间位置的像素的特征重要性。图9显示了该体系结构。这个块通过1×1卷积结合Relu和sigmoid函数,生成一个权重映射,通过与编码器的特征相乘来进行修正。
Channel Attention
图10 The channel attention in the SE-Net 通道注意力模块可以实现特征重新校准,利用学习到的全局信息,选择性地强调有用特征,抑制无用特征。 Hu等人[84]提出了SE-Net,将通道关注引入了图像分析领域,该方法通过三个步骤实现了对信道的注意力加权;图10显示了该体系结构。首先是压缩操作,对输入特征进行全局平均池化,得到1×1×通道特征图。第二种是激励操作,将信道特征相互作用以减少信道数,然后将减少后的信道特征重构回信道数。最后利用sigmoid函数生成[0,1]的特征权值映射,将尺度放回原始输入特征。
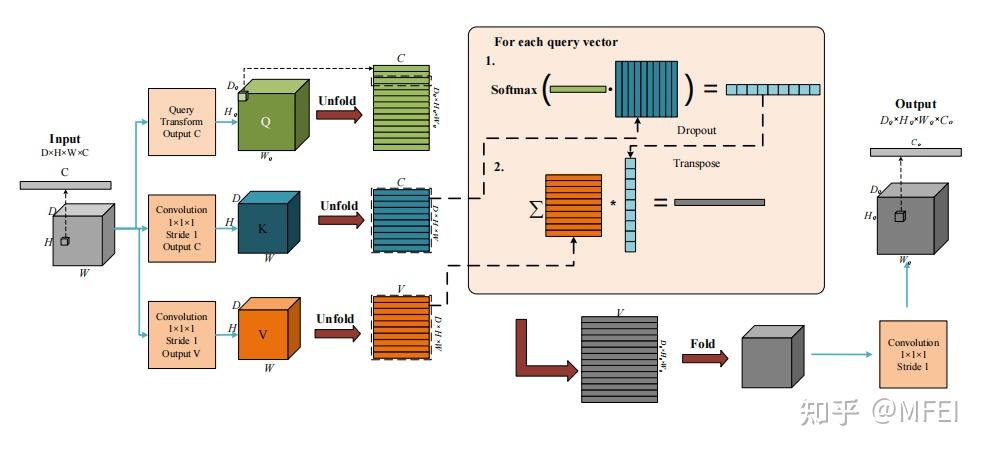
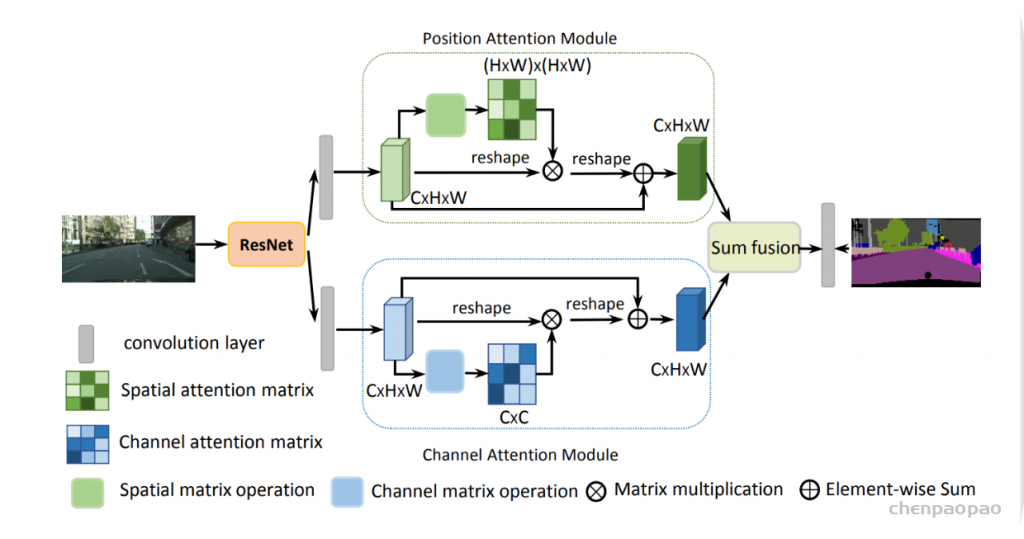
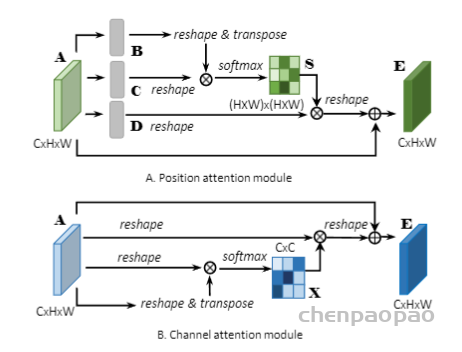
图11 The global aggregation block in the Non-Local U-Net 最近,Wang等人[87]提出了一种Non-local U-Net来克服局部卷积的缺点。Non-local U-Net在上采样和下采样部分均采用自注意机制和全局聚合块提取全图像信息,提高最终分割精度,图11显示了global aggregation block 。Non-local block是一种通用块,可以很容易地嵌入到不同的卷积神经网络中,以提高其性能。 该注意机制对提高图像分割精度是有效的。事实上,空间注意寻找有趣的目标区域,而通道注意寻找有趣的特征。混合注意机制可以同时利用空间和渠道。然而,与非局部注意相比,传统的注意机制缺乏利用不同目标与特征之间关联的能力,因此基于非局部注意的cnn在图像分割任务中通常比正常的cnn具有更好的性能。
Multi-scale Information Fusion 物体之间的大尺度范围是医学图像分割的挑战之一。例如,中晚期的肿瘤可能比早期的肿瘤要大得多。感知场的大小大致决定了我们可以使用多少上下文信息。一般的卷积或池化只使用单个内核,例如,一个3×3内核用于卷积,一个2×2内核用于池化。
Pyramid Pooling:多尺度池化的并行操作可以有效地改善网络的上下文信息,从而提取出更丰富的语义信息。He et al.[88]首先提出了spatial pyramid pooling(SPP)来实现多尺度特征提取。SPP将图像从细空间划分为粗空间,然后收集局部特征,提取多尺度特征。受SPP的启发,设计了一个多尺度信息提取块,并将其命名为multi-kernel pooling(RMP)[75],它使用四个不同大小的池内核对全局上下文信息进行编码。然而,RMP中的上采样操作不能由于池化而恢复细节信息的丢失,这通常会扩大接受域,但降低了图像的分辨率。
图12 The gridding effect (the way of treating images as a chessboard causes the loss of information continuity). 然而,ASPP在图像分割方面存在两个严重的问题。第一个问题是局部信息的丢失,如图12所示,其中我们假设卷积核为3×3,三次迭代的膨胀率为2。第二个问题是,这些信息在很大的距离上可能是无关的。
Non-local and ASPP:
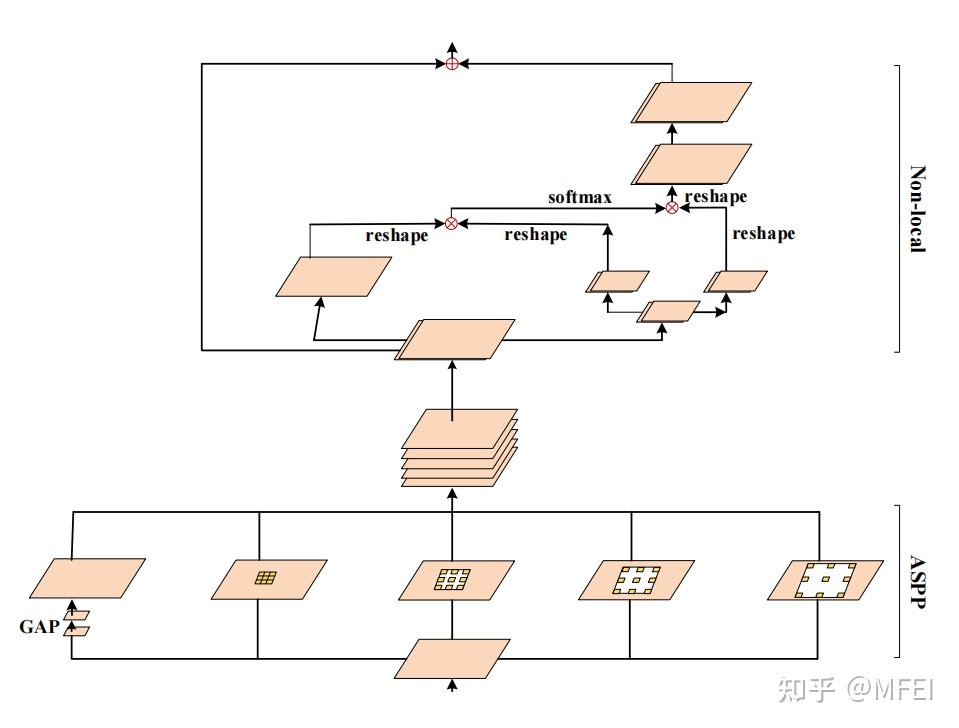
图13 The combination of ASPP and Non-local architecture atrous convolution可以有效地扩大接受域,收集更丰富的语义信息,但由于网格效应,导致了细节信息的丢失。因此,有必要添加约束或建立像素关联来提高无效卷积性能。最近,Yang等人提出了[92]的ASPP和非局部组合块用于人体部位的分割,如图13所示。ASPP使用多个不同规模的并行无性卷积来捕获更丰富的信息,而非本地操作捕获了广泛的依赖关系。该组合具有ASPP和非局部化的优点,在医学图像分割方面具有良好的应用前景。
C. Loss Function
除了通过设计网络主干和函数块来提高分割速度和精度外,设计新的损失函数也可以改进分割精度
Cross Entropy Loss 对于图像分割任务,交叉熵是最流行的损失函数之一。该函数将预测的类别向量和实际的分割结果向量进行像素级的比较。
Weighted Cross Entropy Loss 交叉熵损失对图像平均处理每个像素,输出一个平均值,忽略类不平衡,导致损失函数依赖于包含最大像素数的类的问题。因此,交叉熵损失在小目标分割中的性能往往较低。为了解决类的不平衡的问题,Long等人[32]提出了加权交叉熵损失(WCE)来抵消类的不平衡。对于二值分割的情况,将加权交叉熵损失定义为
Generalized Dice Loss Dice loss虽然一定程度上解决了分类失衡的问题,但却不利于严重的分类不平衡。例如小目标存在一些像素的预测误差,这很容易导致Dice的值发生很大的变化。Sudre等人提出了Generalized Dice Loss (GDL)
GDL优于Dice损失,因为不同的区域对损失有相似的贡献,并且GDL在训练过程中更稳定和鲁棒。
Boundary Loss 为了解决类别不平衡的问题,Kervadec等人[95]提出了一种新的用于脑损伤分割的边界损失。该损失函数旨在最小化分割边界和标记边界之间的距离。作者在两个没有标签的不平衡数据集上进行了实验。结果表明,Dice los和Boundary los的组合优于单一组合。复合损失的定义为
其中第一部分是一个标准的Dice los,它被定义为
第二部分是Boundary los,它被定义为
Exponential Logarithmic Loss 在(9)中,加权Dice los实际上是得到的Dice值除以每个标签的和,对不同尺度的对象达到平衡。因此,Wong等人结合focal loss [96] 和dice loss,提出了用于脑分割的指数对数损失(EXP损失),以解决严重的类不平衡问题。通过引入指数形式,可以进一步控制损失函数的非线性,以提高分割精度。EXP损失函数的定义为
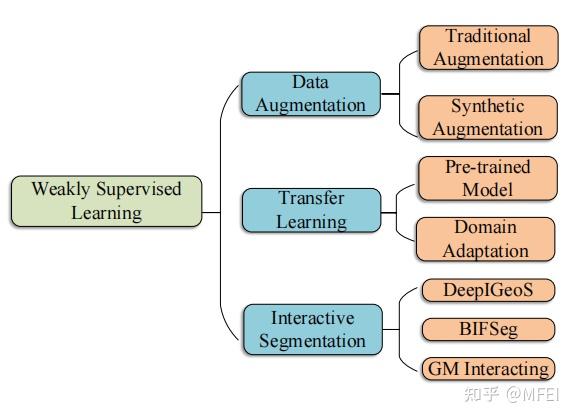
Traditional Methods 一般的数据增强方法包括提高图像质量,如噪声抑制,亮度、饱和度、对比度等图像强度的变化,以及旋转、失真、缩放等图像布局的变化。传统数据增强中最常用的方法是参数变换(旋转、平移、剪切、位移、翻转等)。由于这种转换是虚拟的,没有计算成本,并且对医学图像的标注很困难,所以总是在每次训练之前进行。
Conditional Generative Adversarial Nets(cGAN)
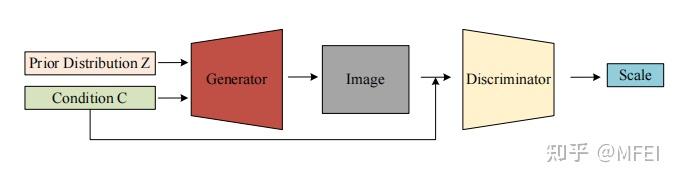
图15 The cGAN architecture 原始GAN生成器可以学习数据的分布,但生成的图片是随机的,这意味着生成器的生成过程是一种非引导的状态。相比之下,cGAN在原始GAN中添加了一个条件,以指导G的生成过程。图15显示了cGAN的体系结构。 Guibas等人[107]提出了一个由GAN和cGAN组成的网络架构。将随机变量输入GAN,生成眼底血管标签的合成图像,然后将生成的标签图输入条件GAN,生成真实的视网膜眼底图像。最后,作者通过检查分类器是否能够区分合成图像和真实图像来验证合成图像的真实性 虽然cGAN生成的图像存在许多缺陷,如边界模糊和低分辨率,但cGAN为后来用于图像样式转换的CycleGAN和StarGAN提供了一个基本的思路。
Pre-trained Model 转移学习通常用于解决数据有限的问题在医学图像分析,一些研究人员发现,使用预先训练的网络自然图像如ImageNet编码器在U-Net-like网络,然后对医疗数据进行微调可以进一步提高医学图像的分割效果。 在ImageNet上进行预训练的模型可以学习到医学图像和自然图像都需要的一些共同的基础特征,因此再训练过程是不必要的,而执行微调对训练模型是有用的。然而,当将预训练好的自然场景图像模型应用于医学图像分析任务时,领域自适应可能是一个问题。此外,由于预先训练好的模型往往依赖于二维图像数据集,因此流行的迁移学习方法很难适用于三维医学图像分析。如果带有注释的医疗数据集的数量足够大,那么就有可能这样做
Domain Adaptation
图16 The Cycle GAN architecture 如果训练目标域的标签不可用,而我们只能访问其他域的标签,那么流行的方法是将源域上训练好的分类器转移到没有标记数据的目标域。CycleGAN是一种循环结构,主要由两个生成器和两个鉴别器组成。图16为CycleGAN的体系结构。
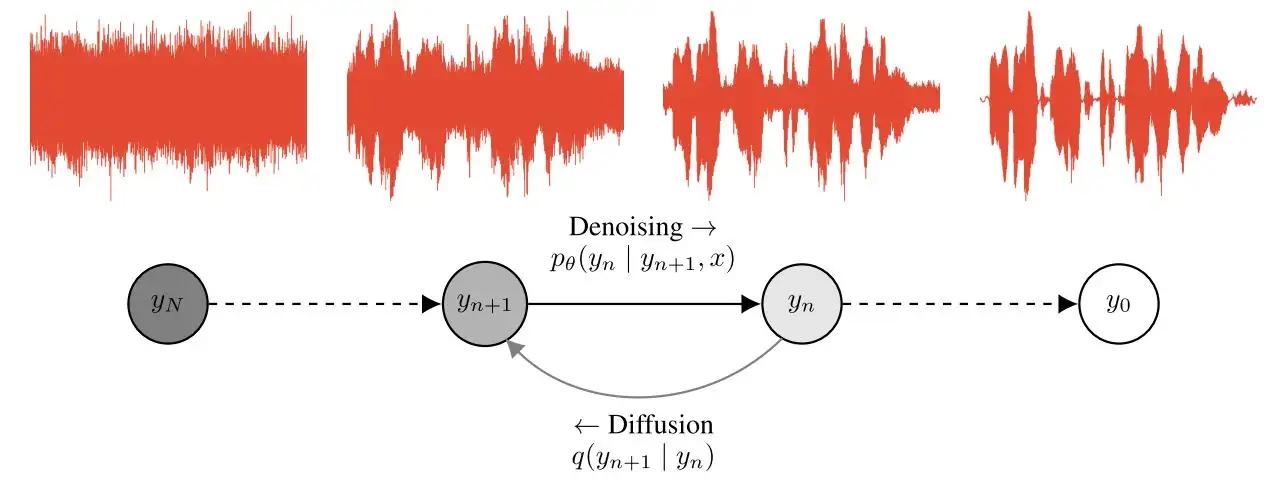
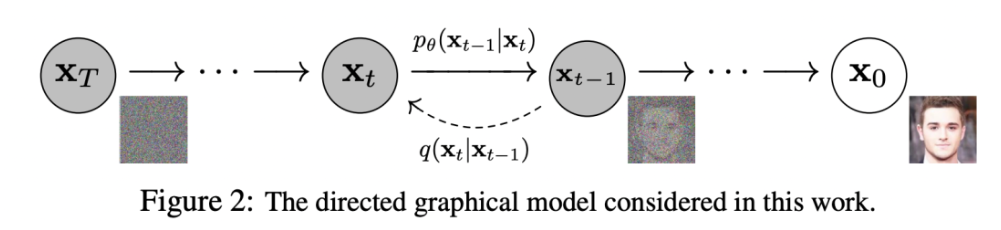
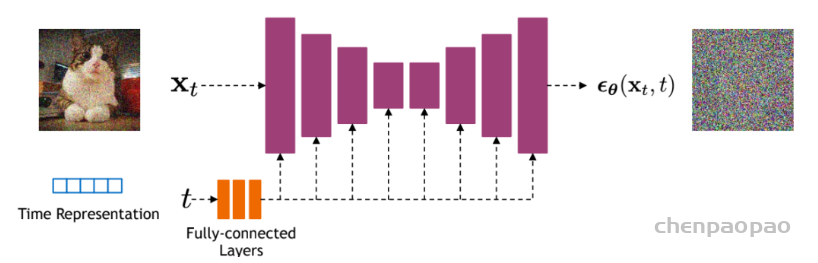
首先,是time embeding,这里是采用Attention Is All You Need中所设计的sinusoidal position embedding,只不过是用来编码timestep:
# use sinusoidal position embedding to encode time step (https://arxiv.org/abs/1706.03762)
def timestep_embedding(timesteps, dim, max_period=10000):
"""
Create sinusoidal timestep embeddings.
:param timesteps: a 1-D Tensor of N indices, one per batch element.
These may be fractional.
:param dim: the dimension of the output.
:param max_period: controls the minimum frequency of the embeddings.
:return: an [N x dim] Tensor of positional embeddings.
"""
half = dim // 2
freqs = torch.exp(
-math.log(max_period) * torch.arange(start=0, end=half, dtype=torch.float32) / half
).to(device=timesteps.device)
args = timesteps[:, None].float() * freqs[None]
embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)
if dim % 2:
embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1)
return embedding
# define TimestepEmbedSequential to support `time_emb` as extra input
class TimestepBlock(nn.Module):
"""
Any module where forward() takes timestep embeddings as a second argument.
"""
@abstractmethod
def forward(self, x, emb):
"""
Apply the module to `x` given `emb` timestep embeddings.
"""
class TimestepEmbedSequential(nn.Sequential, TimestepBlock):
"""
A sequential module that passes timestep embeddings to the children that
support it as an extra input.
"""
def forward(self, x, emb):
for layer in self:
if isinstance(layer, TimestepBlock):
x = layer(x, emb)
else:
x = layer(x)
return x
# upsample
class Upsample(nn.Module):
def __init__(self, channels, use_conv):
super().__init__()
self.use_conv = use_conv
if use_conv:
self.conv = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
def forward(self, x):
x = F.interpolate(x, scale_factor=2, mode="nearest")
if self.use_conv:
x = self.conv(x)
return x
# downsample
class Downsample(nn.Module):
def __init__(self, channels, use_conv):
super().__init__()
self.use_conv = use_conv
if use_conv:
self.op = nn.Conv2d(channels, channels, kernel_size=3, stride=2, padding=1)
else:
self.op = nn.AvgPool2d(stride=2)
def forward(self, x):
return self.op(x)
上面我们实现了U-Net的所有组件,就可以进行组合来实现U-Net了:
The full UNet model with attention and timestep embedding
class UNetModel(nn.Module):
def __init__(
self,
in_channels=3,
model_channels=128,
out_channels=3,
num_res_blocks=2,
attention_resolutions=(8, 16),
dropout=0,
channel_mult=(1, 2, 2, 2),
conv_resample=True,
num_heads=4
):
super().__init__()
self.in_channels = in_channels
self.model_channels = model_channels
self.out_channels = out_channels
self.num_res_blocks = num_res_blocks
self.attention_resolutions = attention_resolutions
self.dropout = dropout
self.channel_mult = channel_mult
self.conv_resample = conv_resample
self.num_heads = num_heads
# time embedding
time_embed_dim = model_channels * 4
self.time_embed = nn.Sequential(
nn.Linear(model_channels, time_embed_dim),
nn.SiLU(),
nn.Linear(time_embed_dim, time_embed_dim),
)
# down blocks
self.down_blocks = nn.ModuleList([
TimestepEmbedSequential(nn.Conv2d(in_channels, model_channels, kernel_size=3, padding=1))
])
down_block_chans = [model_channels]
ch = model_channels
ds = 1
for level, mult in enumerate(channel_mult):
for _ in range(num_res_blocks):
layers = [
ResidualBlock(ch, mult * model_channels, time_embed_dim, dropout)
]
ch = mult * model_channels
if ds in attention_resolutions:
layers.append(AttentionBlock(ch, num_heads=num_heads))
self.down_blocks.append(TimestepEmbedSequential(*layers))
down_block_chans.append(ch)
if level != len(channel_mult) - 1: # don't use downsample for the last stage
self.down_blocks.append(TimestepEmbedSequential(Downsample(ch, conv_resample)))
down_block_chans.append(ch)
ds *= 2
# middle block
self.middle_block = TimestepEmbedSequential(
ResidualBlock(ch, ch, time_embed_dim, dropout),
AttentionBlock(ch, num_heads=num_heads),
ResidualBlock(ch, ch, time_embed_dim, dropout)
)
# up blocks
self.up_blocks = nn.ModuleList([])
for level, mult in list(enumerate(channel_mult))[::-1]:
for i in range(num_res_blocks + 1):
layers = [
ResidualBlock(
ch + down_block_chans.pop(),
model_channels * mult,
time_embed_dim,
dropout
)
]
ch = model_channels * mult
if ds in attention_resolutions:
layers.append(AttentionBlock(ch, num_heads=num_heads))
if level and i == num_res_blocks:
layers.append(Upsample(ch, conv_resample))
ds //= 2
self.up_blocks.append(TimestepEmbedSequential(*layers))
self.out = nn.Sequential(
norm_layer(ch),
nn.SiLU(),
nn.Conv2d(model_channels, out_channels, kernel_size=3, padding=1),
)
def forward(self, x, timesteps):
"""
Apply the model to an input batch.
:param x: an [N x C x H x W] Tensor of inputs.
:param timesteps: a 1-D batch of timesteps.
:return: an [N x C x ...] Tensor of outputs.
"""
hs = []
# time step embedding
emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
# down stage
h = x
for module in self.down_blocks:
h = module(h, emb)
hs.append(h)
# middle stage
h = self.middle_block(h, emb)
# up stage
for module in self.up_blocks:
cat_in = torch.cat([h, hs.pop()], dim=1)
h = module(cat_in, emb)
return self.out(h)
# train
epochs = 10
for epoch in range(epochs):
for step, (images, labels) in enumerate(train_loader):
optimizer.zero_grad()
batch_size = images.shape[0]
images = images.to(device)
# sample t uniformally for every example in the batch
t = torch.randint(0, timesteps, (batch_size,), device=device).long()
loss = gaussian_diffusion.train_losses(model, images, t)
if step % 200 == 0:
print("Loss:", loss.item())
loss.backward()
optimizer.step()
这里我们以mnist数据简单实现了一个mnist-demo,下面是一些生成的样本:
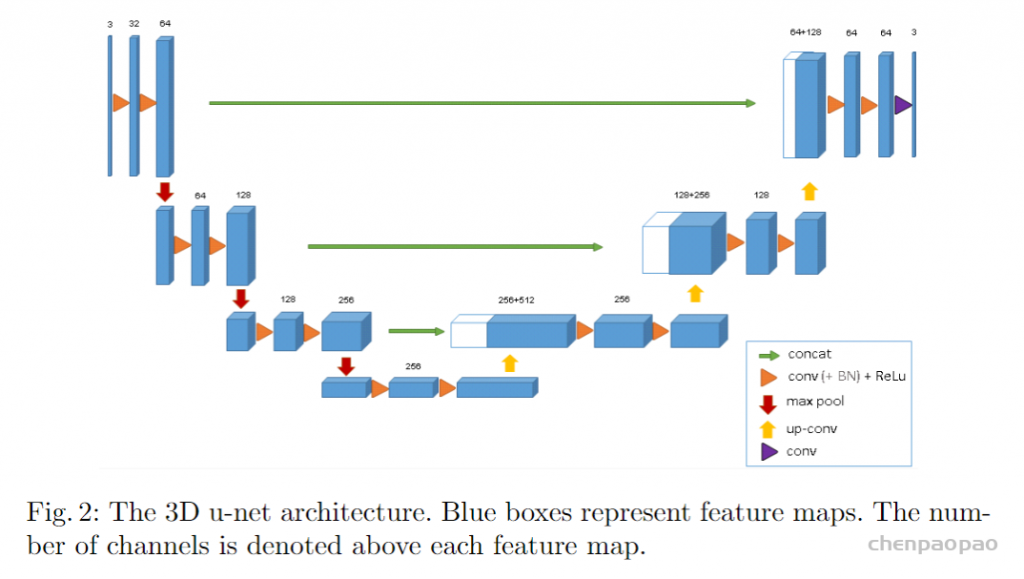
整体的一个网络结构如下图所示,其实可以看出来跟2D结构的U-Net是基本一样,唯一不同的就是全部2D操作换成了3D,这样子做了之后,对于volumetric image就不需要单独输入每个切片进行训练,而是可以采取图片整张作为输入到模型中(PS:但是当图像太大的时候,此时需要运用random crop的技巧将图片随机裁切成固定大小模块的图片放入搭建的模型进行训练,当然这是后话,之后将会在其他文章中进行介绍)。除此之外,论文中提到的一个亮点就是,3D U-Net使用了weighted softmax loss function将未标记的像素点设置为0以至于可以让网络可以更多地仅仅学习标注到的像素点,从而达到普适性地特点。
训练细节(Training)
3D U-Net同样采用了数据增强(data augmentation)地手段,主要由rotation、scaling和将图像设置为gray,于此同时在训练数据上和真实标注的数据上运用平滑的密集变形场(smooth dense deformation field),主要是通过从一个正态分布的随机向量样本中选取标准偏差为4的网格,在每个方向上具有32个体素的间距,然后应用B样条插值(B-Spline Interpolation,不知道什么是B样条插值法的可以点连接进行查看,在深度学习模型的创建中有时候也不需要那么复杂,所以这里仅限了解,除非本身数学底子很好已经有所了解),B样条插值法比较笼统地说法就是在原本地形状上找到一个类似地形状来近似(approximation)。之后就对数据开始进行训练,训练采用的是加权交叉熵损失(weighted cross-entropy loss function)以至于减少背景的权重并增加标注到的图像数据部分的权重以达到平衡的影响小管和背景体素上的损失。
实验的结果是用IoU(intersection over union)进行衡量的,即比较生成图像与真实被标注部分的重叠部分。