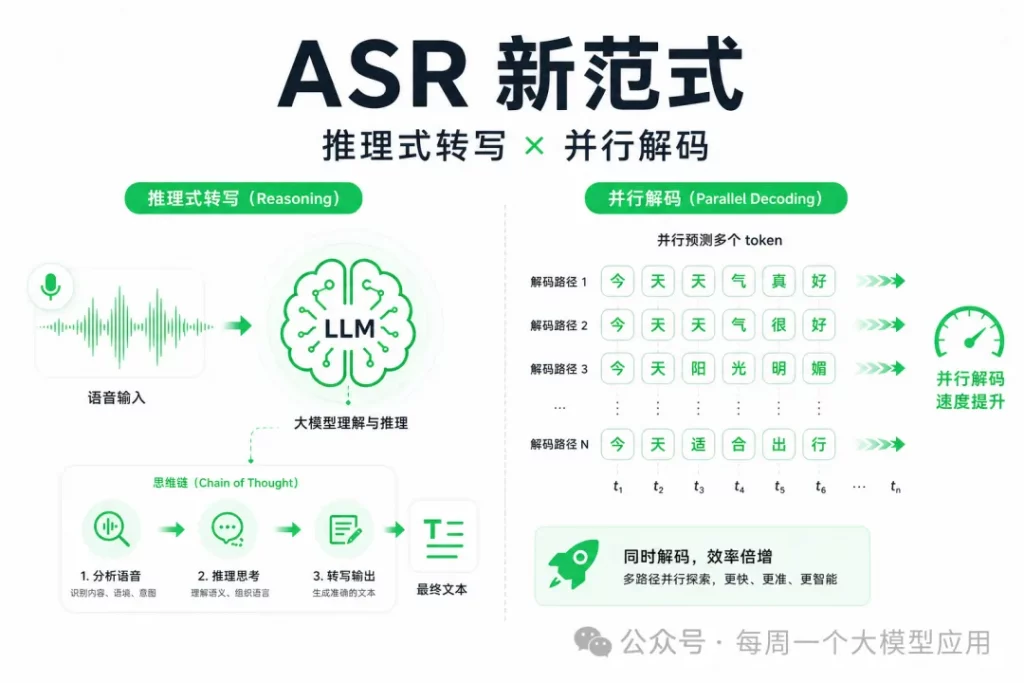
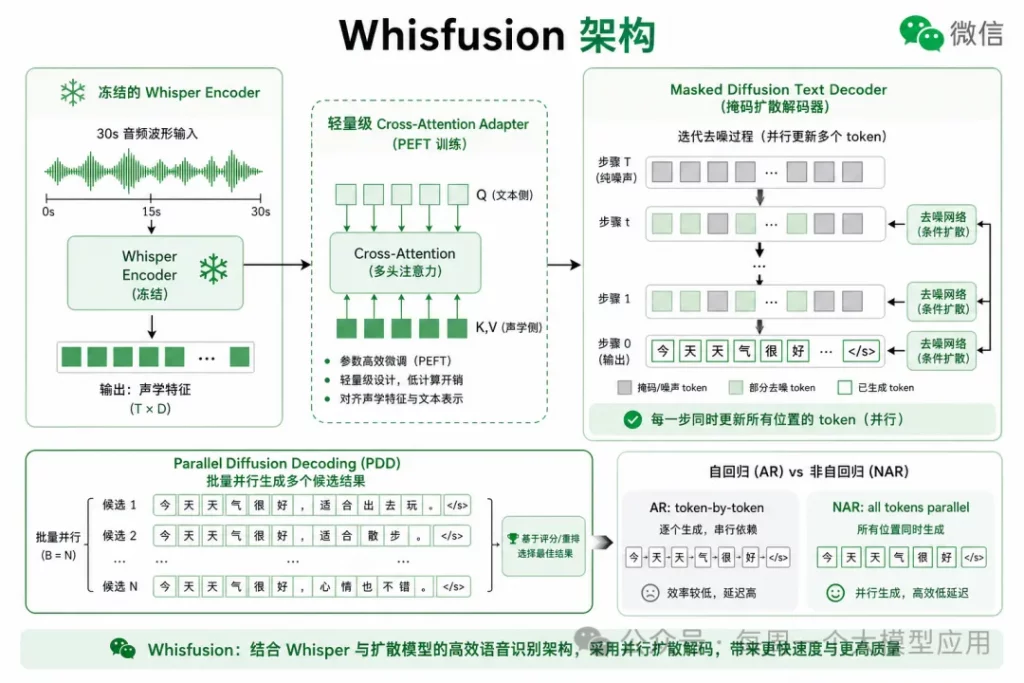
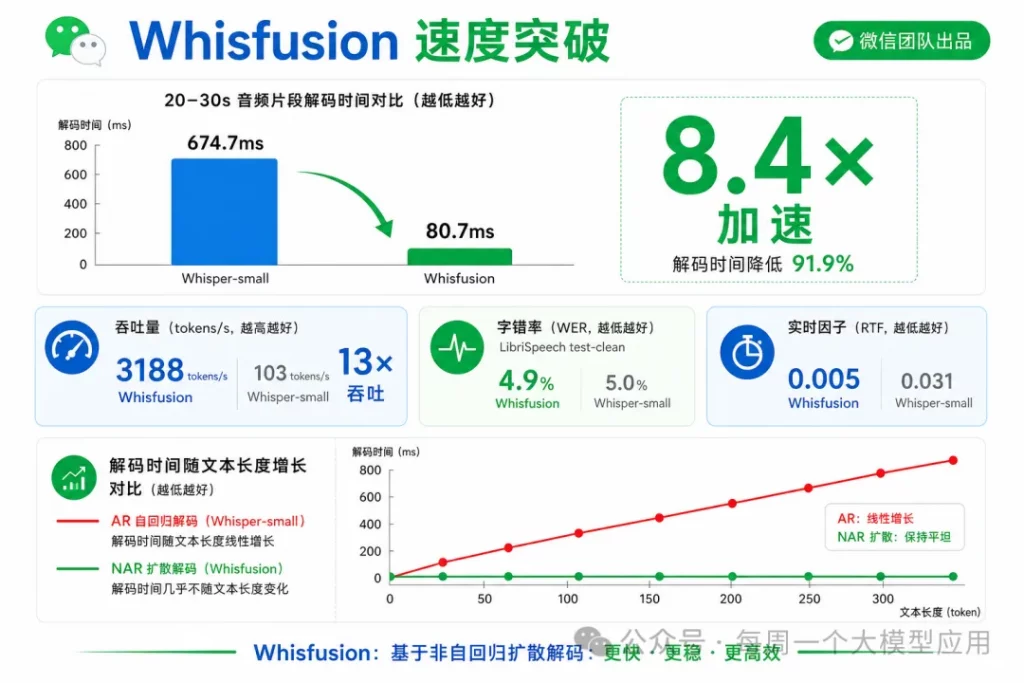
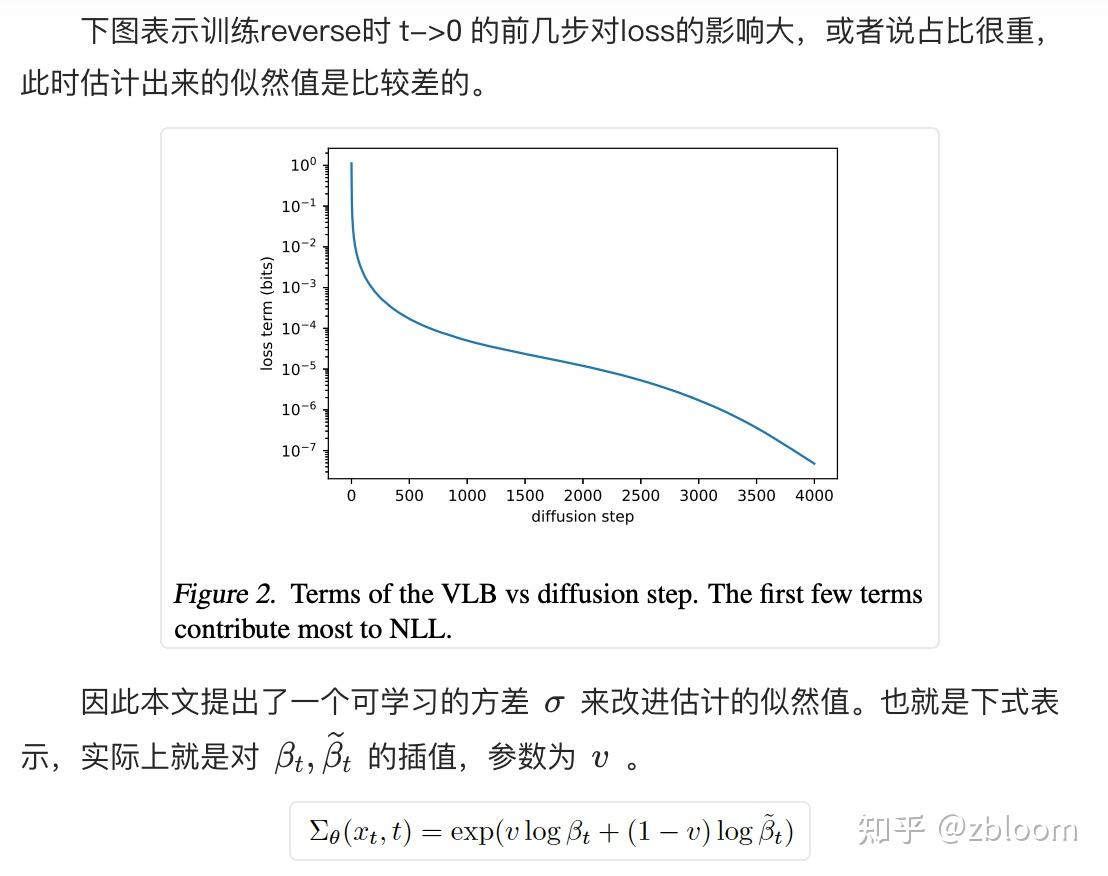
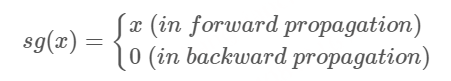- 论文标题:LangFlow: Continuous Diffusion Rivals Discrete in Language Modeling
- 论文链接:https://arxiv.org/abs/2604.11748
- github:https://github.com/nealchen2003/LangFlow
- huggingface:https://huggingface.co/papers/2604.11748
LangFlow 关注一个长期没有被充分解决的问题:连续扩散模型在图像、视频等连续模态上很强,但在语言建模中一直落后于离散扩散。作者认为问题不在于连续扩散本身不可行,而在于 embedding-space diffusion 的训练目标、似然评估和噪声调度设计还不够清楚。
这篇论文的核心结论是:如果把 embedding-space diffusion 重新表述为 Flow Matching,并用 Bregman divergence 解释交叉熵训练目标,再配合 ODE-based NLL 上界、Gumbel 噪声调度和 self-conditioning,连续扩散语言模型可以在 LM1B 和 OpenWebText 上接近甚至追平主流离散扩散语言模型。LangFlow 在 LM1B 上达到 PPL 30.0,在 OpenWebText 上达到 PPL 24.6,并且在 7 个 zero-shot 迁移评测中有 4 个超过自回归 Transformer。
1. 背景:为什么语言里的连续扩散一直难做?
扩散模型天然适合连续空间,因此在图像和视频生成中非常成功。但语言是离散 token 序列,扩散语言模型通常有两条路线:一类是直接在离散状态上做扩散,例如 absorbing-state 或 uniform-state discrete diffusion;另一类是在 token embedding 空间中做连续扩散。后者理论上保留了连续扩散的优点,比如可编辑轨迹、ODE/SDE 采样、未来可做少步蒸馏,但过去在 PPL 和生成质量上没有真正追上离散扩散。
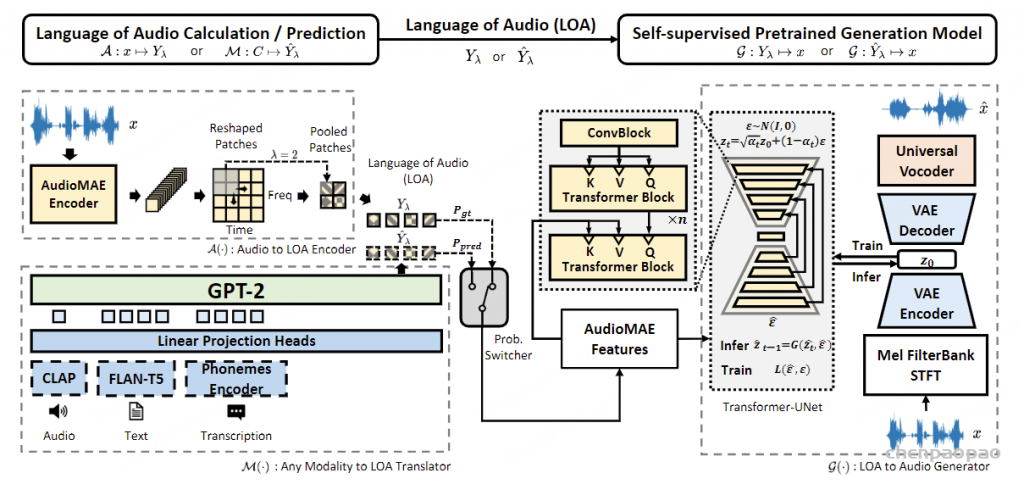
LangFlow 的切入点是 embedding-space diffusion。给定词表嵌入矩阵 \(E \in \mathbb{R}^{V \times d}\),一个 token 序列 \(y=(y_1,\ldots,y_L)\) 会先被映射成连续嵌入序列 \(x_1 = E[y]\)。模型不是在 one-hot simplex 上扩散,而是在连续 embedding 空间中从高斯噪声逐步移动到 clean embedding。
可以把 LangFlow 的生成过程抽象为一个 ODE:
\( \frac{d x_t}{d t}=v_\theta(x_t,t), \quad x_0 \sim \mathcal{N}(0,I), \quad x_1 \sim p_{\mathrm{data}} \)其中 \(v_\theta\) 是模型学习到的 velocity field。训练和采样的关键,不是直接回归某个 embedding,而是让模型在噪声状态下预测 clean token 的概率分布。
2. LangFlow 的模型设计
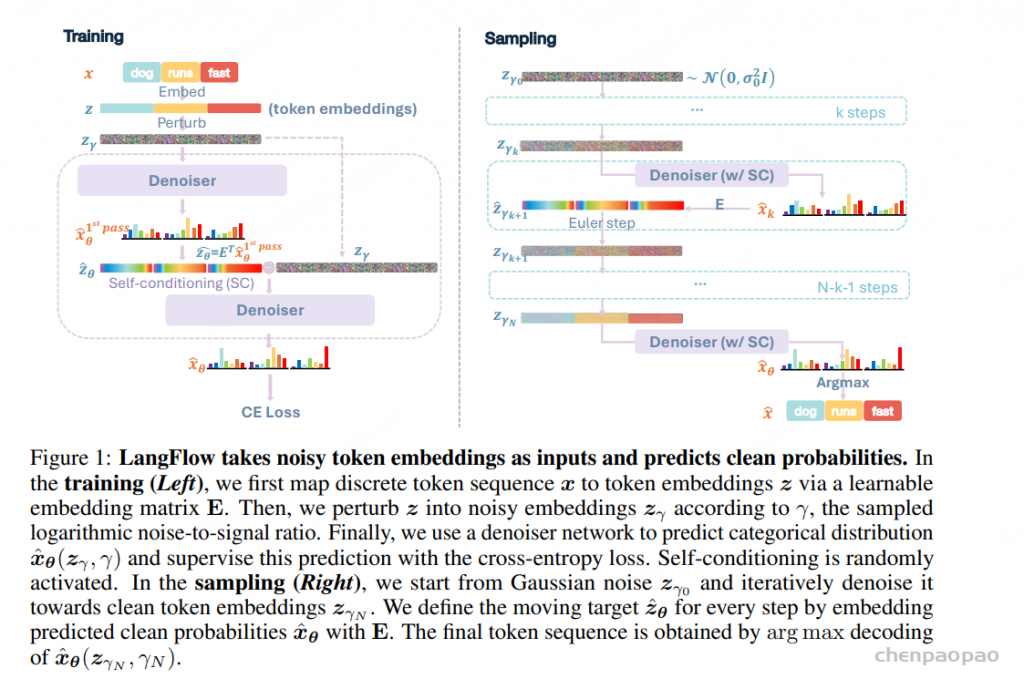
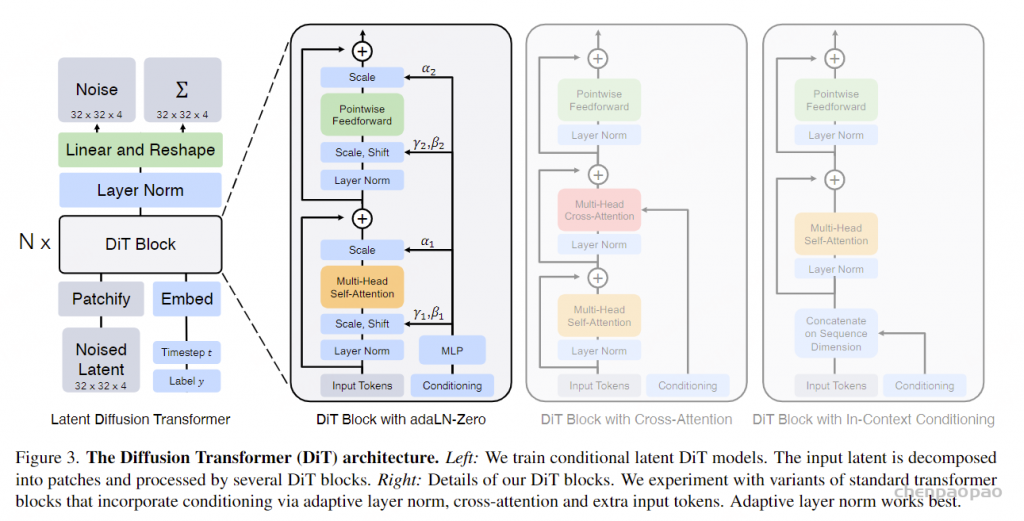
LangFlow 的主干结构使用与强离散扩散基线相同的 modified DiT-style Transformer,并加入 RoPE 位置编码。正文实验配置为约 130M 参数、12 层、hidden size 768、12 个 attention heads。这样设计的好处是:实验对比时,LangFlow 与 SEDD、MDLM、Duo 等基线的网络容量基本对齐,性能提升更能归因于连续扩散框架和训练策略,而不是模型规模。
模型输入是 noisy embedding \(x_\gamma\),时间条件不直接使用普通时间 \(t\),而使用 log noise-to-signal ratio:
\( \gamma = \log \frac{\sigma^2}{\alpha^2} \)在 variance-preserving 路径下,噪声状态可以写成:
\( x_\gamma = \alpha_\gamma x_1 + \sigma_\gamma \epsilon,\quad \alpha_\gamma = \frac{1}{\sqrt{1+e^\gamma}},\quad \sigma_\gamma = \sqrt{\frac{e^\gamma}{1+e^\gamma}} \)当 \(\gamma\) 很大时,状态接近纯噪声;当 \(\gamma\) 很小时,状态接近 clean embedding。这样做的直觉是:语言 denoising 的难度主要由噪声强度控制,而不是由任意定义的时间变量控制。
LangFlow 还做了三个小但重要的工程修改:第一,将 self-conditioning 的输入并入主输入;第二,把 token embedding 归一化到单位球面后再缩放,使数据方差与噪声方差更匹配;第三,在 logits 上加入 tokenwise bias,改善训练初期的概率预测。这些修改没有显著改变参数量,但会影响训练稳定性。
3. 训练目标:用 Bregman divergence 解释交叉熵
过去一些连续扩散语言模型会直接用 MSE 回归 clean embedding,但论文指出这种做法可能导致 embedding collapse:不同 token 的 embedding 被错误地拉近,削弱语言表示的可分性。LangFlow 改为预测 clean token 的类别分布,并使用交叉熵训练。
作者的理论贡献是说明:交叉熵不是一个临时技巧,而可以看成 Bregman-divergence Flow Matching 在 categorical data 上的一个特殊形式。Bregman divergence 定义为:
\( D_F(q,p)=F(q)-F(p)-\langle \nabla F(p), q-p\rangle \)当选择与负熵相关的凸函数时,token-level 交叉熵可以自然恢复出来。LangFlow 的训练目标可以简化写为:
\( \mathcal{L}_{\mathrm{CE}}(\theta) = \mathbb{E}_{\gamma,\,y,\,\epsilon} \left[-\log p_\theta(y \mid x_\gamma,\gamma)\right] \)模型输出的是 \(p_\theta(\cdot \mid x_\gamma,\gamma)\),即 clean token 的概率分布。采样时,再把这个概率分布映射回连续 denoised embedding:
\( \hat{x}_1 = \sum_{i=1}^{V} p_\theta(i \mid x_\gamma,\gamma) E_i \)这样就把两个世界连起来了:训练在 token space 中用交叉熵优化,采样在 embedding space 中沿 ODE 做连续移动。
4. ODE-based NLL:让连续扩散也能认真评估 PPL
语言模型的核心指标是 perplexity,但 embedding-space diffusion 过去主要依赖 SDE-based bound,和实际 ODE 采样并不完全一致。LangFlow 选择只用 deterministic ODE 采样,因为 ODE 保留从噪声到数据的确定性映射,也更适合未来做 flow-based distillation 和 few-step generation。
论文推导了一个 ODE-based NLL 上界。博客里可以把它理解为:沿着反向 ODE 轨迹积分概率密度变化,再加上末端 token 解码概率,从而得到可用于 PPL 评估的上界:
\( -\log p_\theta(y) \le \mathcal{L}_{\mathrm{ODE}}(y) \)其中 \(\mathcal{L}_{\mathrm{ODE}}\) 包含 ODE trajectory 上的 divergence term。论文实验中,PPL 评估使用 128-step Heun-2 solver,并用 Hutchinson trace estimator 估计 divergence。这一点很关键,因为它让连续扩散语言模型不再只能报告生成样本的 Gen. PPL,而可以和离散扩散在 PPL 上更公平地比较。
5. Gumbel 噪声调度:语言不是图像
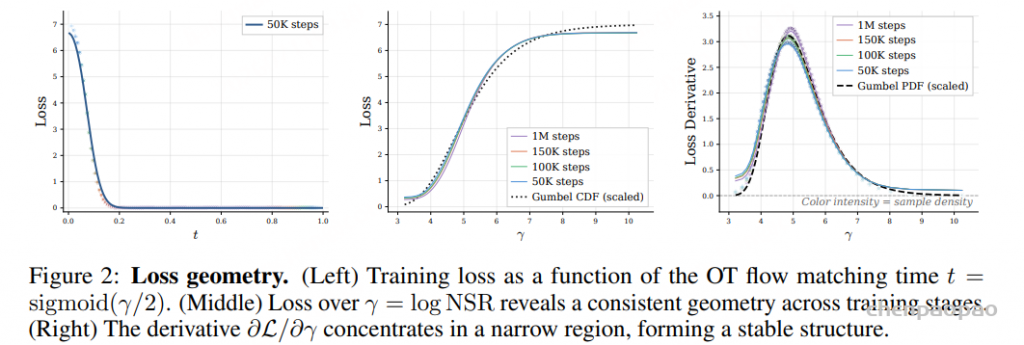
论文最有启发性的经验发现是:图像扩散里常用的均匀噪声调度,直接搬到语言上会浪费大量训练与采样步骤。作者观察到,在某些噪声区间,模型的 CE loss 几乎为 0,说明模型已经能轻松预测正确 token,这些区间继续分配大量 step 没有太多信息增益。
LangFlow 提出 information-uniform principle:噪声采样密度应该匹配每单位噪声水平带来的信息增益。直观写法是:
\( p(\gamma) \propto \left|\frac{d H(y \mid x_\gamma)}{d\gamma}\right| \)这里 \(H(y \mid x_\gamma)\) 可以理解为在噪声状态 \(x_\gamma\) 下 clean token 的后验熵。作者发现这个信息增益曲线很适合用 Gumbel 分布拟合:
\( p(\gamma;\mu,\beta) = \frac{1}{\beta} \exp\left( -\frac{\gamma-\mu}{\beta} -\exp\left(-\frac{\gamma-\mu}{\beta}\right) \right) \)实践中,LangFlow 让 Gumbel scheduler 的参数可学习。训练时从该分布采样 \(\gamma\),采样时按 Gumbel 分布分位点安排 ODE step。论文报告,这一设计能把 LangFlow 的 Gen. PPL 从 1000 级别显著降到 154.2,说明噪声调度不是细枝末节,而是连续扩散语言建模能否工作的关键。
6. Self-conditioning:连续扩散和离散扩散的效果不同
Self-conditioning 的做法是把上一步预测结果作为额外输入喂回模型。训练时随机开启,采样时始终开启。LangFlow 训练中 self-conditioning 概率为 0.25。
有意思的是,论文发现 self-conditioning 对离散扩散和连续扩散的作用不一样。在 LM1B 消融中,MDLM 加入 self-conditioning 后 Gen. PPL 从 103.9 降到 94.9,但 PPL 从 31.0 变差到 32.7;LangFlow 则从 Gen. PPL 154.2、PPL 49.0 改善到 Gen. PPL 81.5、PPL 30.0。也就是说,对 LangFlow 来说,self-conditioning 同时提升生成质量和似然上界,是把连续扩散追到离散扩散水平的关键组件。
7. 实验设置与关键结果
论文主要在 LM1B 和 OpenWebText(OWT)上评测。LM1B 使用 context length 128 和 bert-base-uncased tokenizer;OWT 使用 context length 1024 和 gpt2-large tokenizer。模型训练 1M steps,batch size 512。Gen. PPL 通过生成 1024 个样本并用 GPT2-Large 计算平均 perplexity 得到;PPL 则报告各扩散模型的上界。
LM1B:LangFlow 的 PPL 为 30.0,是表中扩散语言模型里最好的结果;Gen. PPL 为 92.2,低于 MDLM 的 103.9、SEDD Absorb 的 115.9、UDLM 的 99.8 和 Duo 的 97.6,仅略弱于 Plaid 的 77.3。相比早期连续方法 Diffusion-LM 的 PPL 118.6,LangFlow 的提升非常明显。

OpenWebText:LangFlow 的 Gen. PPL 为 36.5,是表中最优;PPL 为 24.6,接近 MDLM 的 23.2 和 SEDD Absorb 的 24.1,并优于 SEDD Uniform 的 29.7、UDLM 的 27.4 和 Duo 的 25.2。这说明 LangFlow 不只是小数据集上有效,在更接近真实网页语料的 OWT 上也有竞争力。
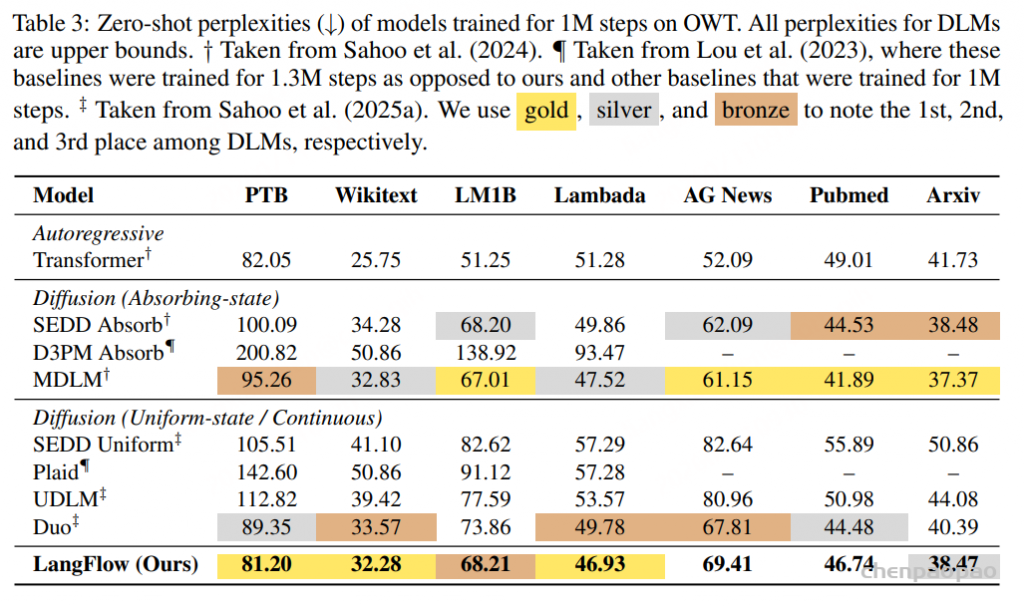
Zero-shot 迁移:用 OWT 训练后的模型在 PTB、Wikitext、LM1B、Lambada、AG News、PubMed、Arxiv 上评测。LangFlow 在 PTB 为 81.20、Wikitext 为 32.28、Lambada 为 46.93,均为扩散模型中的第一;Arxiv 为 38.47,仅略弱于 MDLM 的 37.37。论文总结为:LangFlow 在 7 个任务中有 4 个超过自回归 Transformer,并在 3 个任务中超过 MDLM。
采样步数:在 LM1B 上,LangFlow 的 NFE 从 128 降到 64、32、16 时,Gen. PPL 分别为 92.24、104.83、127.32、179.60,质量随步数减少而下降,但没有经过专门 few-step 蒸馏。OWT 上,在 1024 NFE 时 LangFlow Gen. PPL 为 36.53,明显优于 Duo 77.69、SEDD Uniform 99.90、MDLM 104.85 和 SEDD Absorb 105.03;即使 128 NFE,LangFlow 仍有 60.09。
8. 关键创新点总结
- 把 embedding-space diffusion 接到 Flow Matching:LangFlow 用连续 ODE 视角重新组织语言扩散,而不是把连续扩散当作简单的 embedding 回归。
- 交叉熵目标有理论解释:通过 Bregman divergence,作者说明 token-level CE 是 categorical Flow Matching 的合理目标,避免了 MSE 带来的 embedding collapse 风险。
- ODE-based NLL 上界:让连续扩散语言模型可以用更贴近 ODE 采样的方式评估 PPL,这是论文的核心理论贡献之一。
- information-uniform 噪声调度:根据后验熵变化分配噪声密度,并用可学习 Gumbel 分布实现,显著改善生成质量。
- self-conditioning 训练协议修正:论文证明 continuous DLM 中 self-conditioning 不只是改善 Gen. PPL,也能大幅改善 PPL,这和离散扩散中的现象不同。
- 公平对比离散扩散:模型规模、训练步数和主干结构尽量对齐,使 LangFlow 与 SEDD、MDLM、Duo 等方法的比较更有说服力。
9. 局限
LangFlow 证明连续扩散语言模型有机会追上离散扩散,但它还不是对自回归语言模型的全面替代。首先,AR Transformer 在 LM1B 和 OWT 的 PPL 仍更低,例如 LM1B 为 22.8、OWT 为 17.5。其次,LangFlow 的高质量采样仍需要较多 ODE steps,少步生成还依赖未来的 distillation。第三,OWT 生成样本的 entropy 偏低,作者也承认这可能反映全局词频偏置,仍需要更细的质量分析。
这篇论文最值得学习的地方,不是某一个指标刷新,而是它把连续扩散语言建模中几个原本分散的问题连成了闭环:如何训练、如何评估、如何调度噪声、如何采样、如何避免 embedding collapse。对于关注 diffusion LLM、非自回归生成、可编辑文本生成和少步生成的人来说,LangFlow 是一篇值得重点看的基础论文。