
论文:https://arxiv.org/abs/1902.10482?context=cs.CL
IJCNLP 2019 paper代码: https://github.com/wuzhiye7/Induction-Network-on-FewRel
在深度学习领域,监督式深度学习对大型标记数据集的贪婪需求是出了名的,然而又由于标注数据集的昂贵成本,这就限制了深度模型对新类的可泛化性。本文提出了一个用于在文本分类领域的小样本学习训练工作。
什么是小样本学习:(以图片为例)
few-shot learing 的训练目标与传统的监督学习目标不同,传统的分类是学会识别训练集合里面的图片,并且泛化到测试集合,神经网络识别出该图片属于哪个类。而few shot learing是让机器自己学会学习,学习的目的不是让机器学会那个是大象那个是老虎,而是让模型学会学习不同类别的不同之处,给定两张图片,模型知道两个图片是否是同一类别。哪怕模型训练集中没有出现过该类别。
当前的小样本学习技术经常会将输入的query和support的样本集合进行sample-wise级别的对比。但是,如果跟同一个类别下的不同表达的样本去对比的时候产生的效果就不太好,除此之外,目前的技术会使用简单地求和或平均表示来计算类别,这会丢失一些信息。因此本文利用胶囊网络,通过学习sample所属于的类别的表示得到class-wise的向量,然后跟输入的query进行对比。

模型如下:
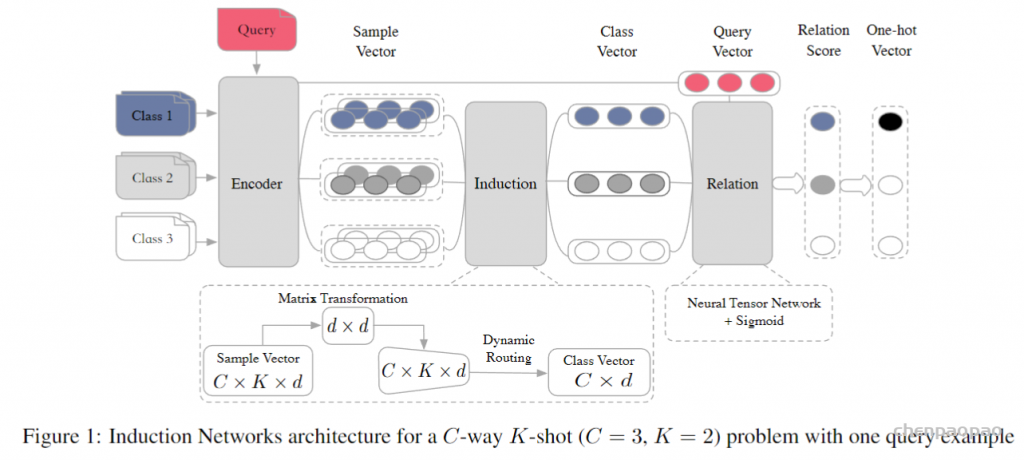
模型分为三个模块:Encoder Module, Induction Module and Relation Module.
Encoder Module
编码器使用双向LSTM,然后对每个隐藏层进行self-attention。
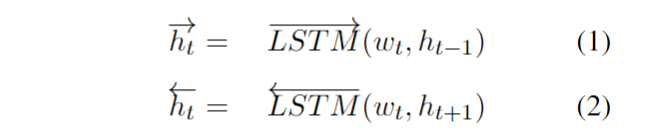
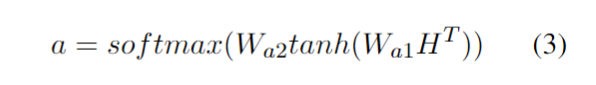
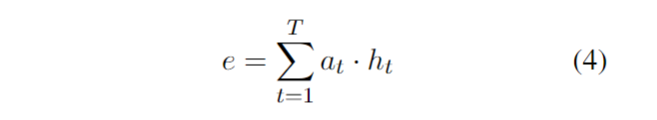
其中H维度为[C*K, T, 2u] ,经过矩阵变化,a的维度变为[C*K, T] ,最后e的维度为[C*K, 2u]。
Induction Module
本模块的主要目的是设计一个从样本向量到类向量的非线性映射。
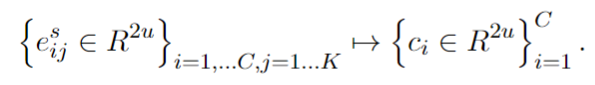
这是使用动态路由算法,输出的capsule数为1.

首先将样本表征进行一次变换,这里为了能够支持不同大小的C,对原Capsule Network中不同类别使用不同的W做了修改,也就是使用一个所有类别共享的W。
Relation Module
在得到类表示后,就可以计算ci与query set的相关性了。
Objective Function
使用均方误差来计算损失,匹配对的相似度为1,不匹配的相似度为0。