
整体思路:图片-网络-深度图->(直接转换)点云-网络-新视点(CVPR2020)
SynSin: End-to-end View Synthesis from a Single Image
项目主页: https://www.robots.ox.ac.uk/~ow/synsin.html
来自牛津大学、FAIR、Facebook 和密歇根大学的研究者提出了一种单一图像视图合成方法,允许从单一输入图像生成新的场景视图。它被训练在真实的图像上,没有使用任何真实的 3D 信息;引入了一种新的可微点云渲染器,用于将潜在的 3D 点云特征转换为目标视图;细化网络对投影特征进行解码,插入缺失区域,生成逼真的输出图像;生成模型内部的 3D 组件允许在测试时对潜在特征空间进行可解释的操作,例如,可以从单个图像动画轨迹。与以前的工作不同,SynSin 可以生成高分辨率的图像,并推广到其他输入分辨率,在 Matterport、Replica 和 RealEstate10K 数据集上超越基线和前期工作。

整体网络:
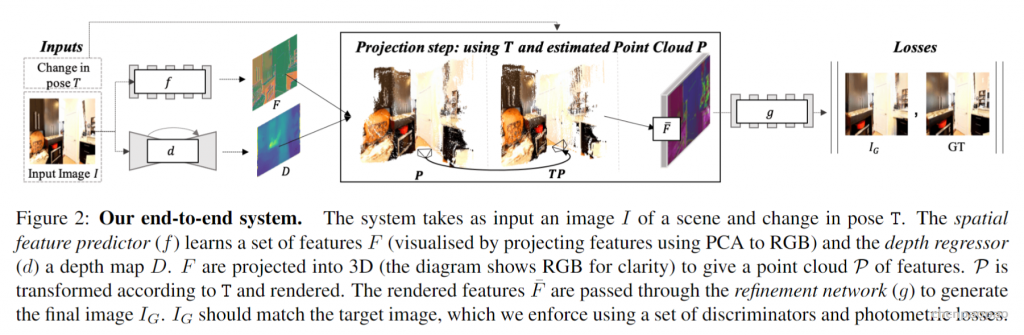
首先将图片输入特征和深度网络得到特征map和深度图,接着通过相机参数变换为带特征的点云,接着根据相对变换矩阵T,将带特征的点云渲染到二维像素位置上,接着通过一个GAN生成最终的新视角图片。
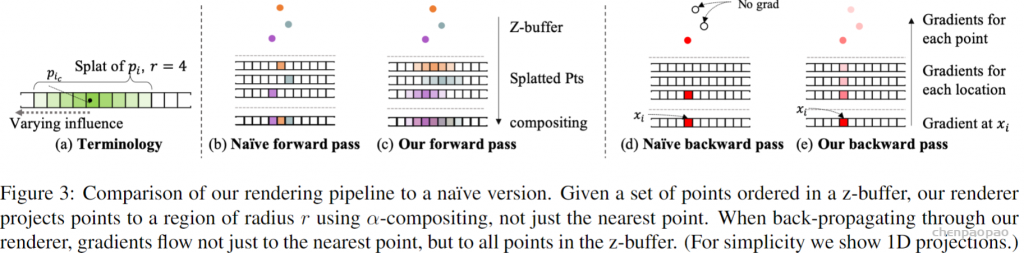
该论文的渲染方式值得关注,其并不是简单的使用zbuffer和固定投影像素位置渲染的,在z深度和平面广度上都是软映射的。平面广度上是线性递减的辐射,在深度上取k近邻并排序后,按照次序递减:
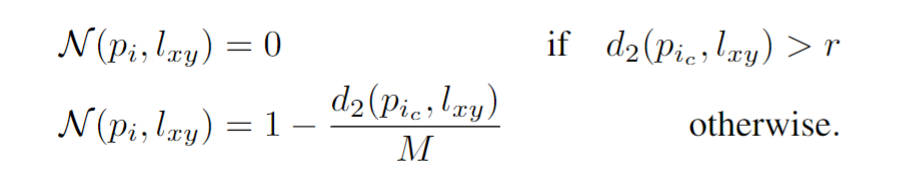
这种软渲染的方式估计会牺牲较大的渲染精度,但是对于优化问题来说非常合适不过。
总结:构建了一个先进的端到端模型SynSin,它可以获取单个RGB图像,然后从不同的角度生成同一场景的新图像,无需任何3D监督。我们系统主要是预测一个3D点云,后者通过PyTorch3D使用我们的可微渲染器投射到新的视图上,并且将渲染的点云传递到生成对抗网络(GAN)来合成输出图像。当前的方法通常是使用密集体素网格,它们在单个对象的合成场景中显示出优秀的应用前景,但无法扩展到复杂的真实场景。利用点云的灵活性,SynSin不仅能够实现这一点,而且比体素网格等替代方法更有效地推广到各种分辨率。SynSin的高效率可以帮助我们探索广泛的应用,如生成更好的3D照片和360度视频。