
召回01:基于物品的协同过滤(ItemCF)
Item Based Collaborative Filtering,缩写 ItemCF
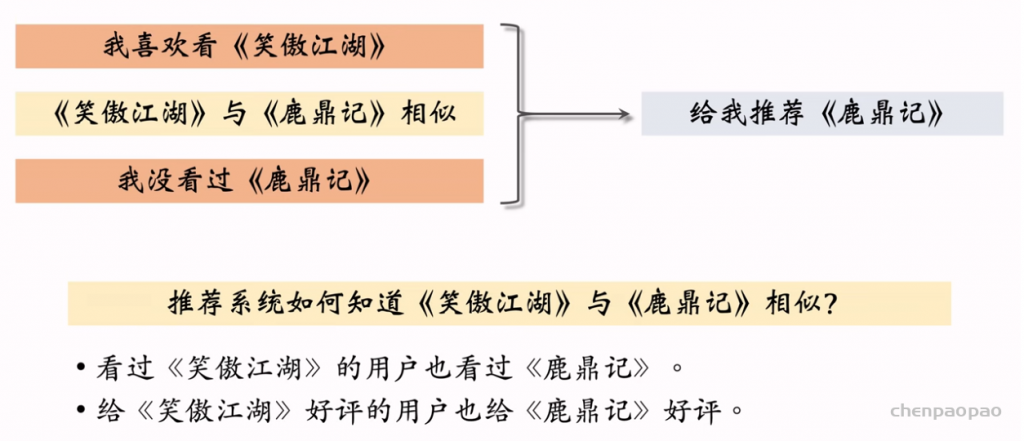
ItemCF 的原理:如果用户喜欢物品1,而且物品1与物品2相似,那么用户很可能喜欢物品2。
1. 如何计算两个物品之间的相似度。
2. 如何预估用户对候选物品的兴趣。
3. 如何利用索引在线上快速做召回。
ItemCF的实现
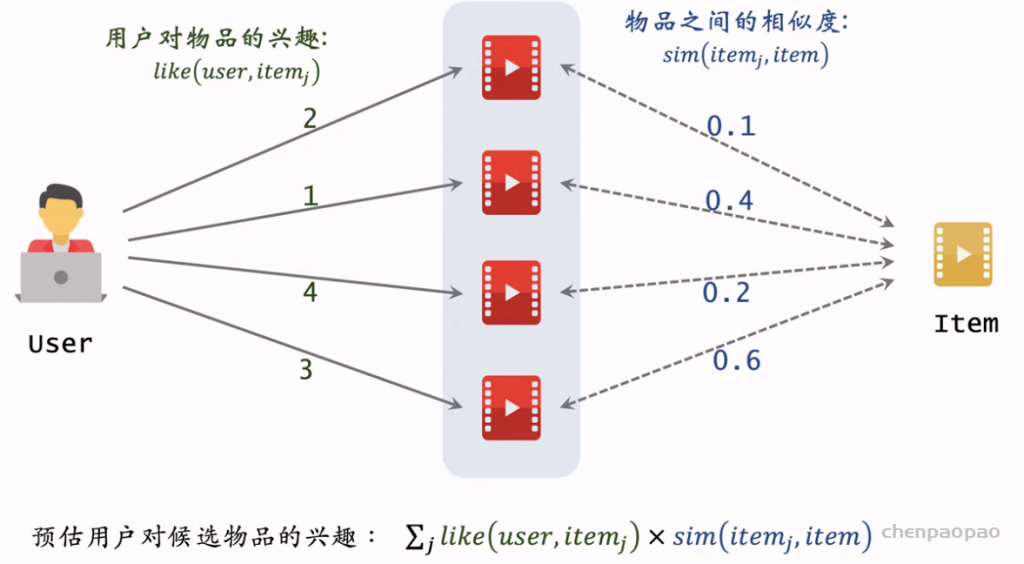
两个物体的受众重合度越高,表示两个物体越相似。

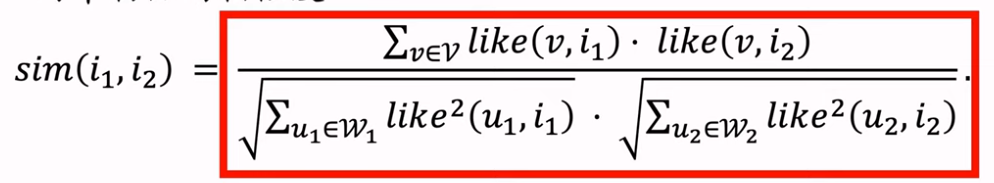

ItemCF完整流程:
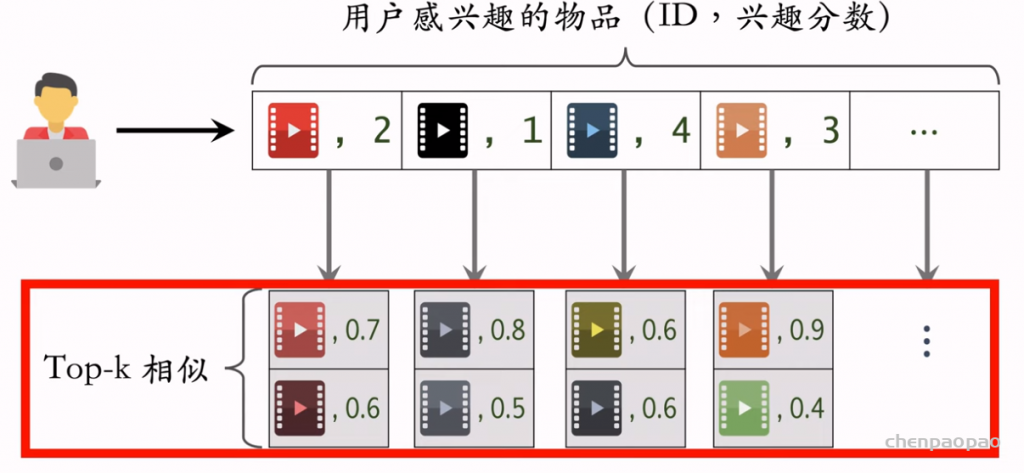
step1:事先做离线计算


step2 线上做召回:

为什么要用索引:


召回02:Swing召回通道
ItemCF :(缺点)
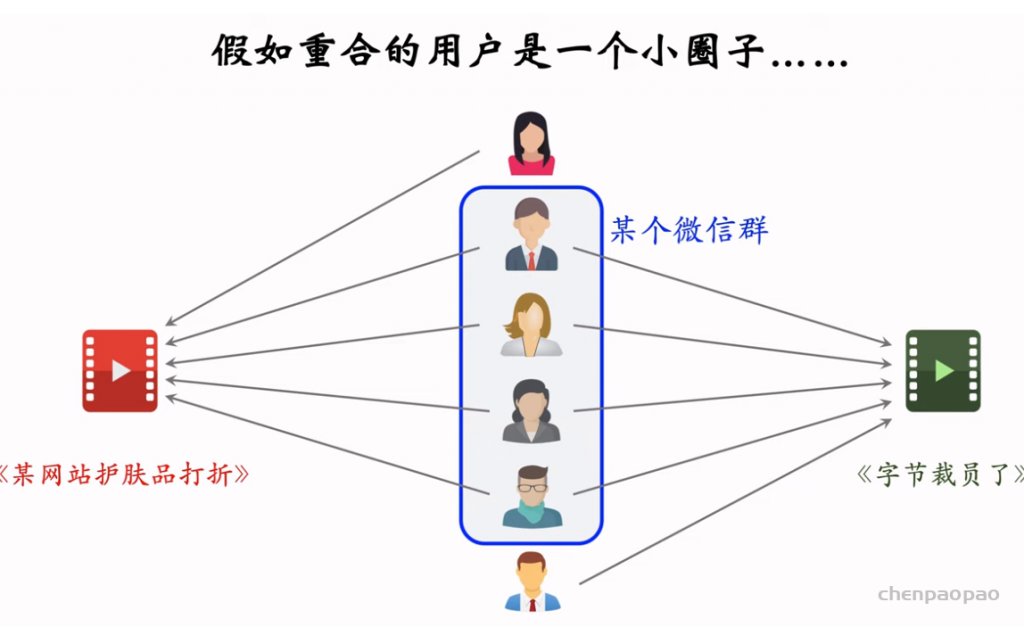
Swing模型:(为用户设置权重)




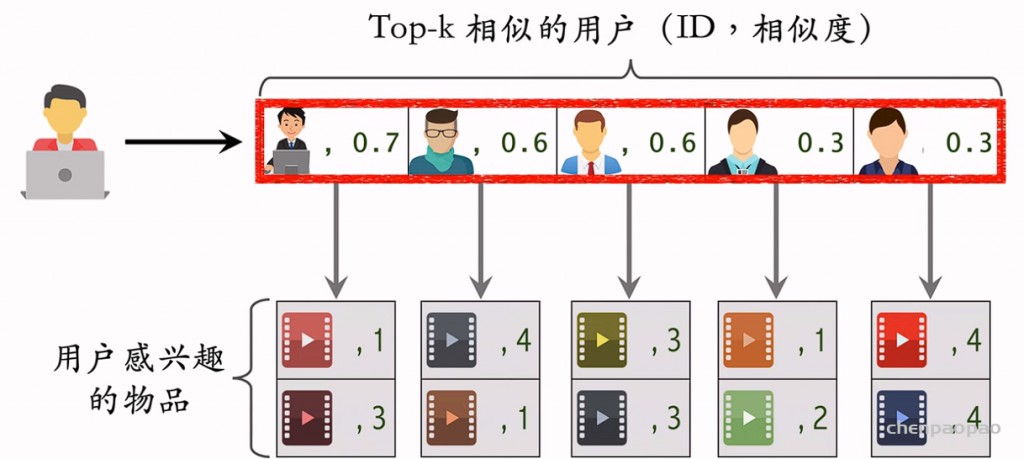
召回03:基于用户的协同过滤(UserCF)
UserCF 的原理:如果用户1跟用户2相似,而且用户2喜欢某物品,那么用户1很可能喜欢该物品。
关键:1. 如何计算两个用户之间的相似度。 2. 如何预估用户对候选物品的兴趣。 3. 如何利用索引在线上快速做召回。
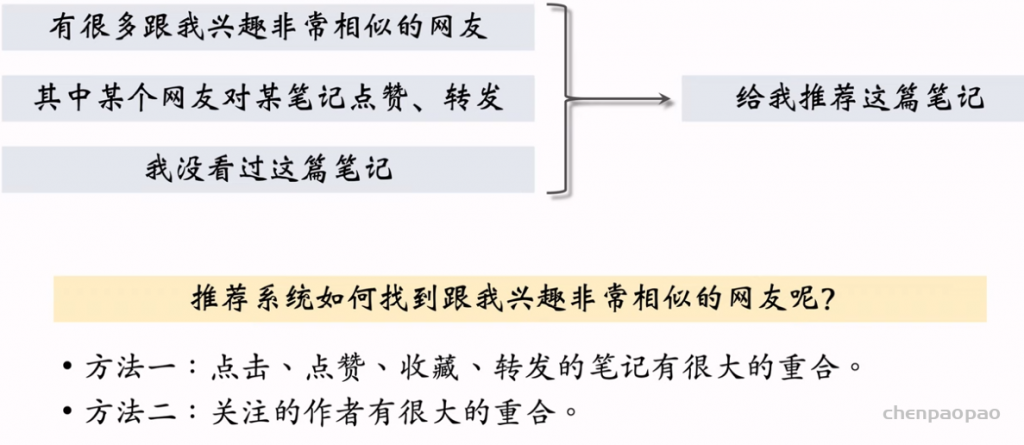
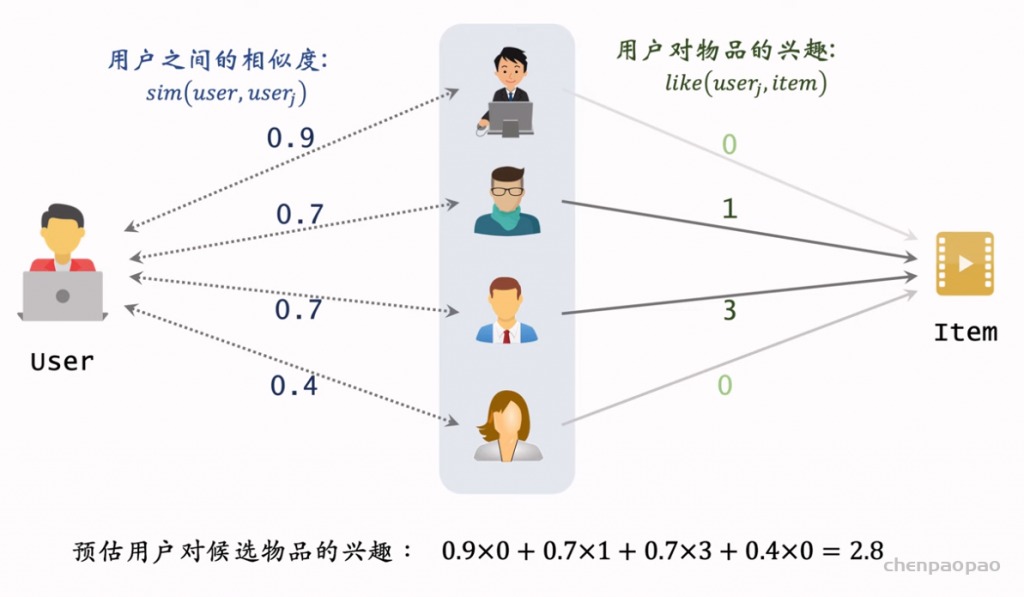
用户相似度:

如果是热门物体,那么大概率两个用户都会喜欢,因此需要降低热门物体的权重:

UserCF召回的完整流程
step1:离线计算


step2:线上做召回

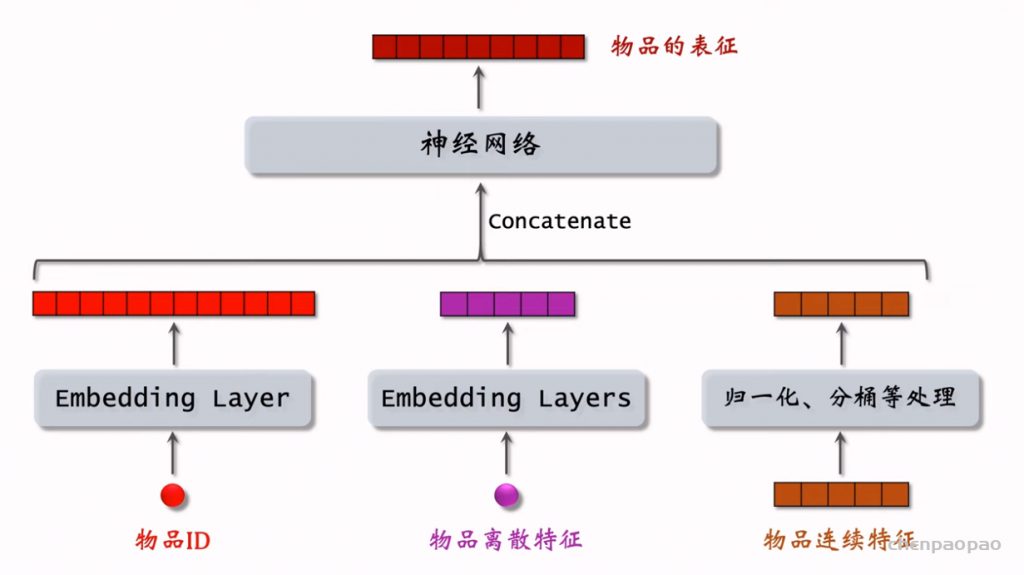
召回04: 向量召回 ,离散特征处理
one-hot encoding (独热编码) 和 embedding (嵌入)

召回05: 向量召回 ,矩阵补充、最近邻查找
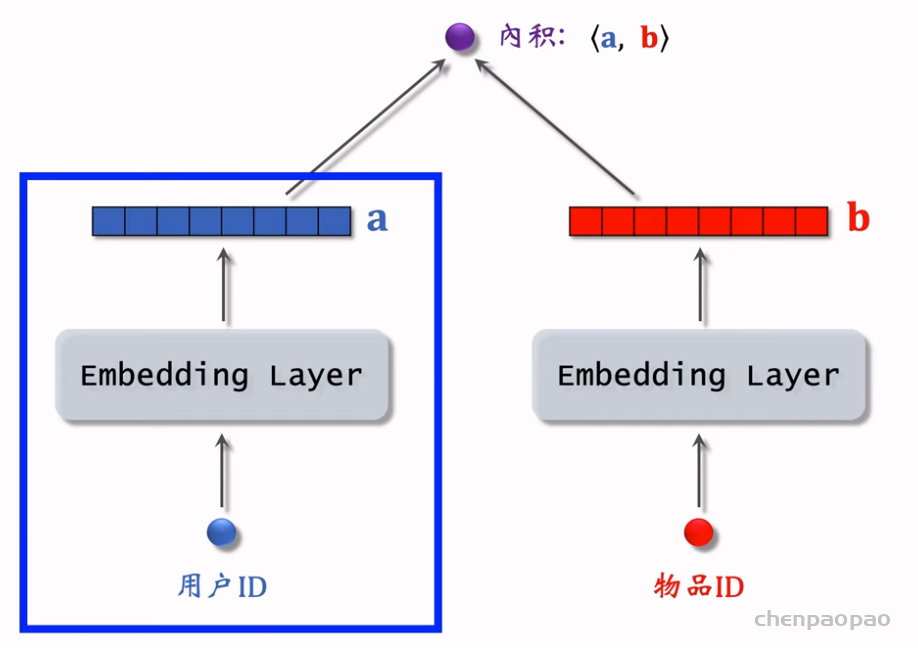
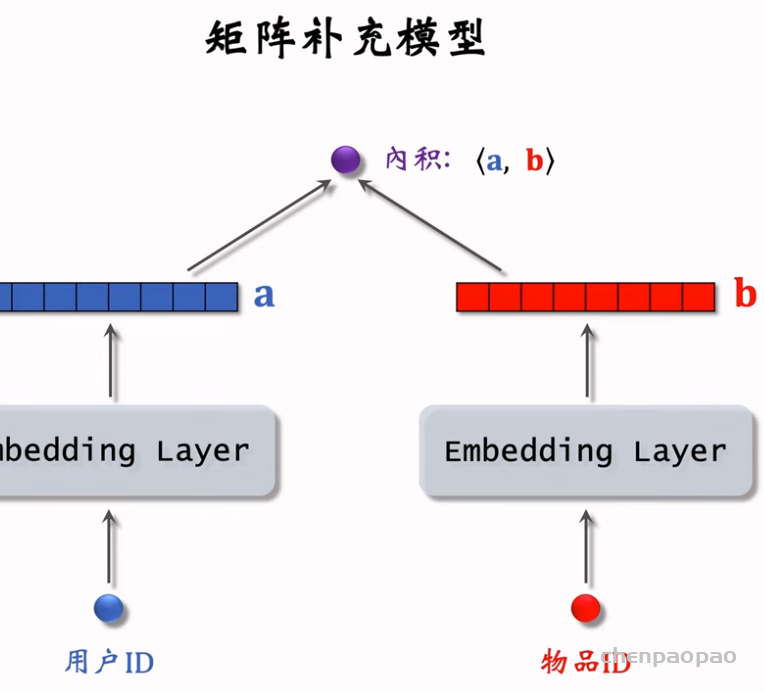
矩阵补充(matrix completion),它是一种向量召回通道。矩阵补充的本质是对用户 ID 和物品 ID 做 embedding,并用两个 embedding 向量的内积预估用户对物品的兴趣。值得注意的是,矩阵补充存在诸多缺点,在实践中效果远不及双塔模型。 做向量召回需要做最近邻查找(nearest neighbor search)。



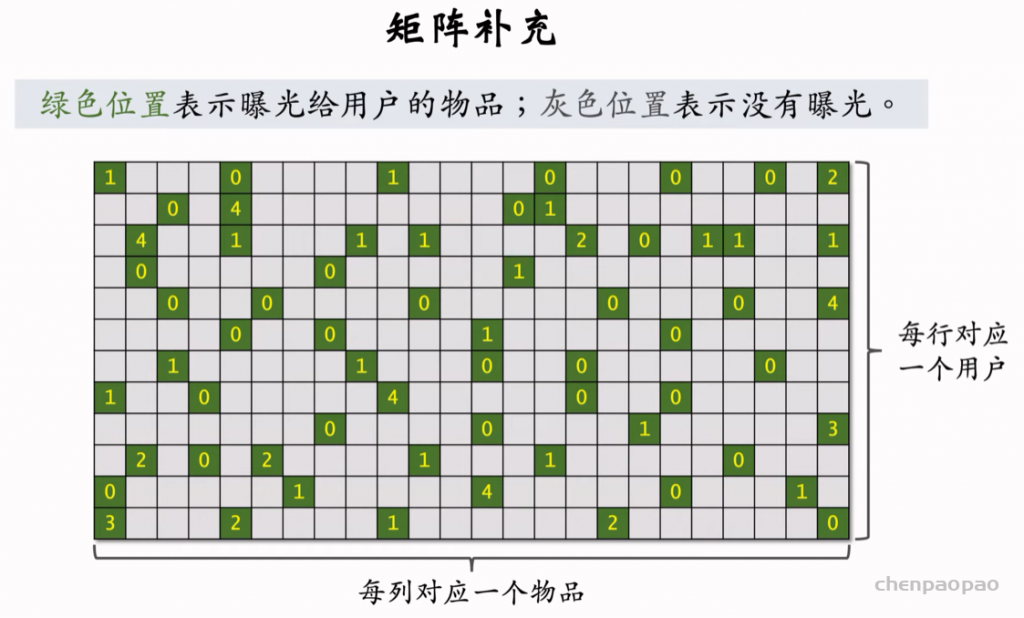
用绿色的信息做训练,来预测灰色的值,进而为用户做召回

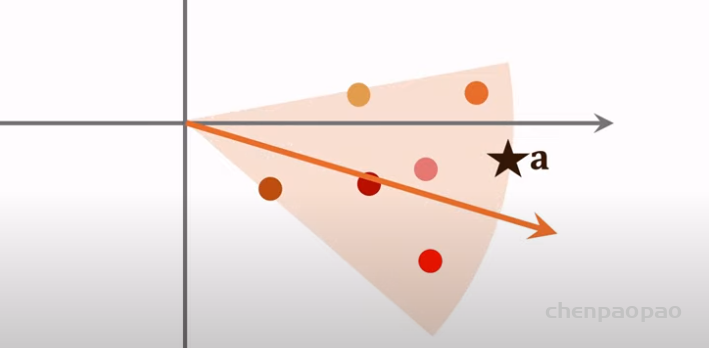
近似最近邻查找:

step1:划分区域
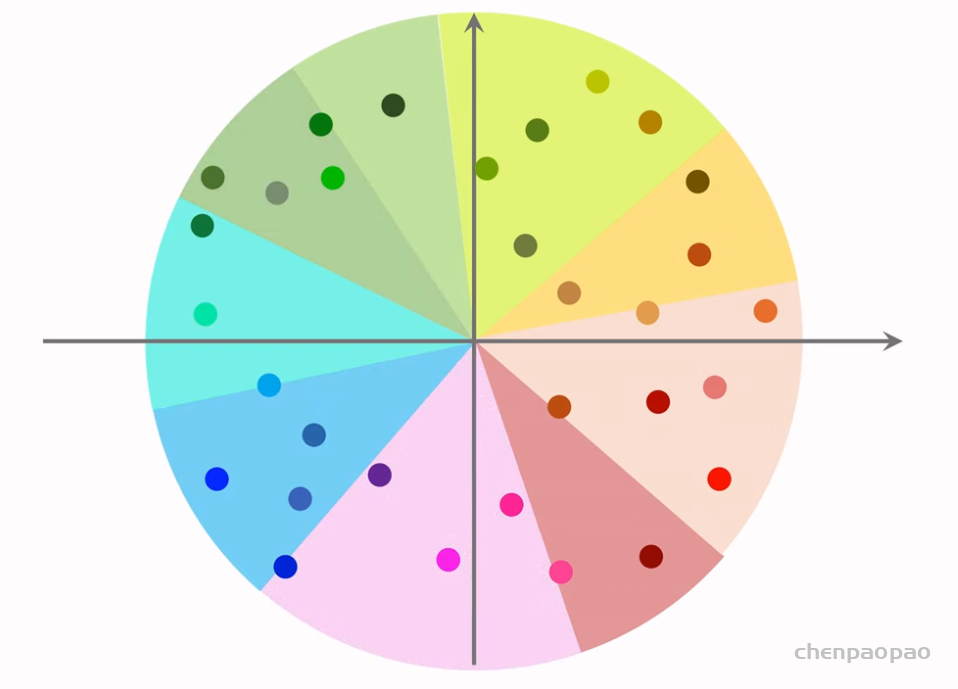
step2:用一个向量表示但各区域,给定一个物体,则返回所在的区域的物体
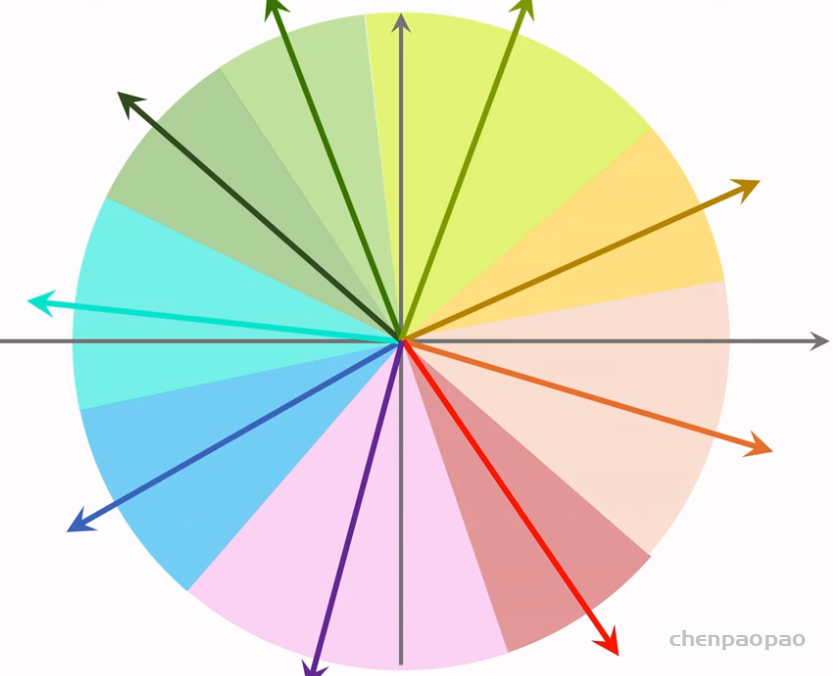
step3:只需计算该区域所在的相似度。
召回06:双塔模型:矩阵补充的升级版
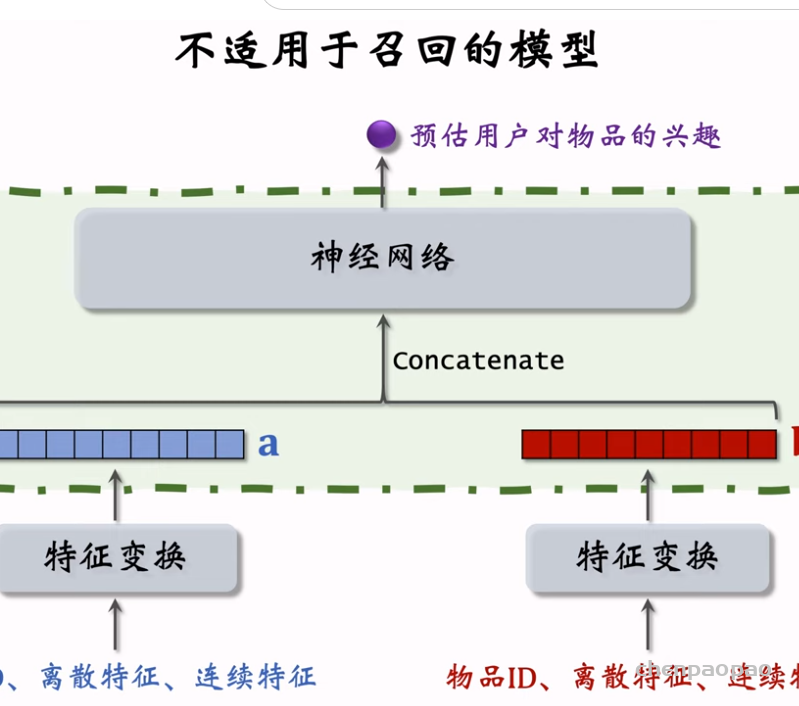
双塔模型(two-tower)也叫 DSSM,是推荐系统中最重要的召回通道,没有之一。双塔模型有两个塔:用户塔、物品塔。两个塔各输出一个向量,作为用户、物品的表征。两个向量的内积或余弦相似度作为对兴趣的预估。有三种训练双塔模型的方式:pointwise、pairwise、listwise。
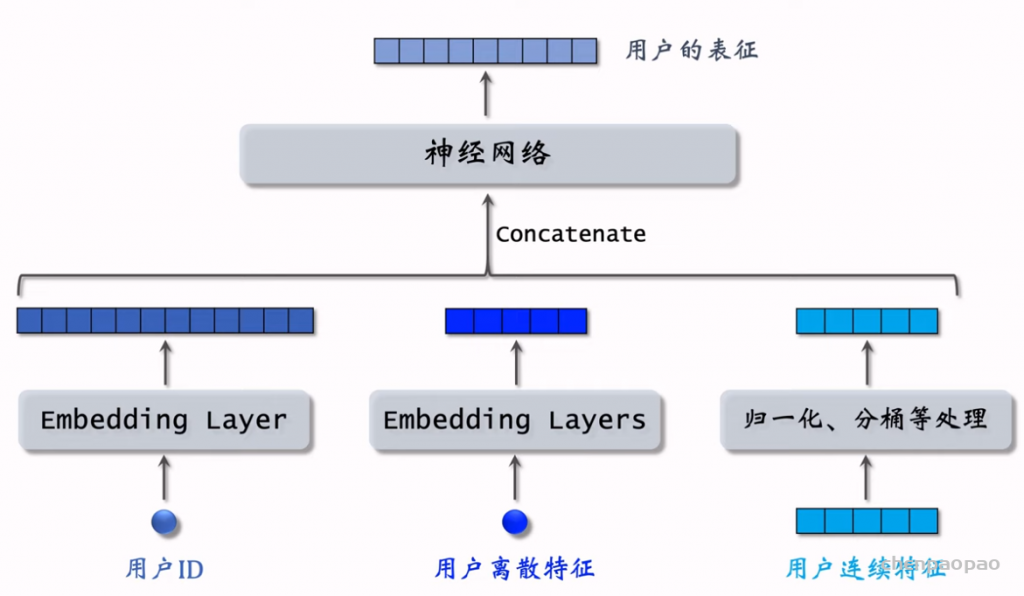
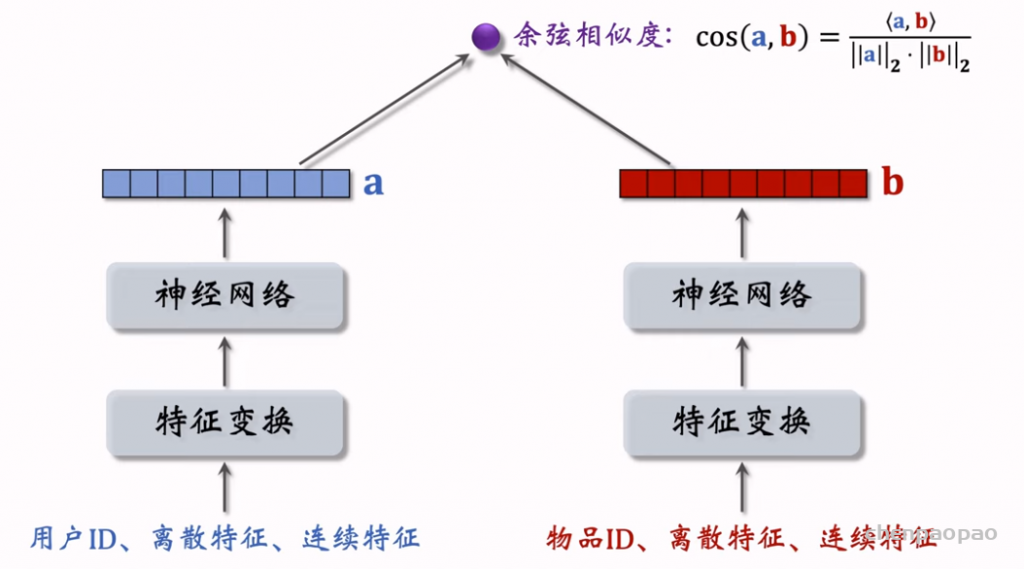
双塔模型训练:


pointwise:

pariwise:
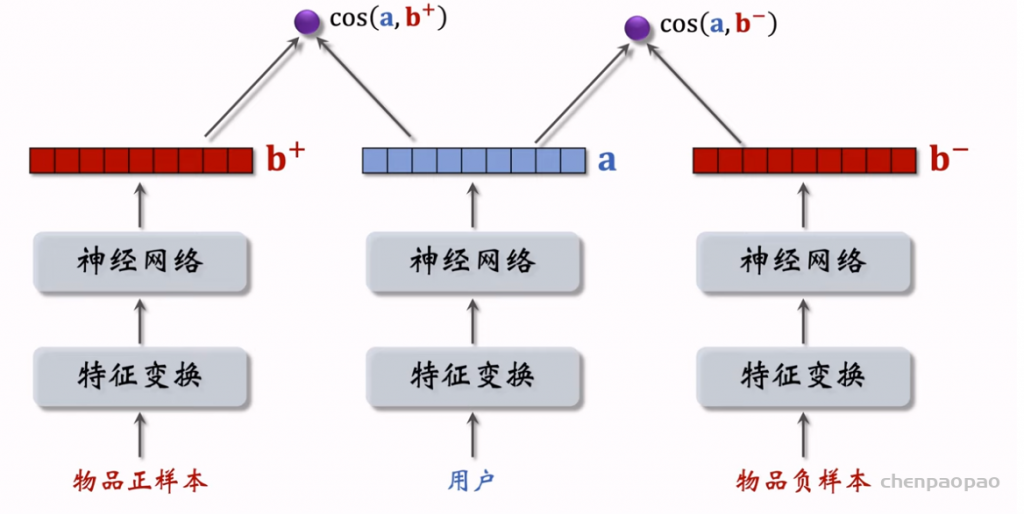

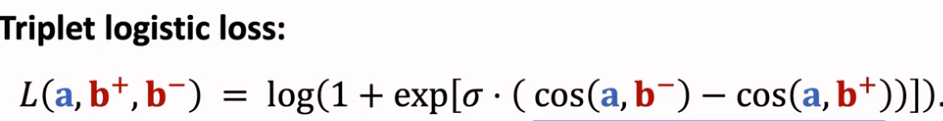
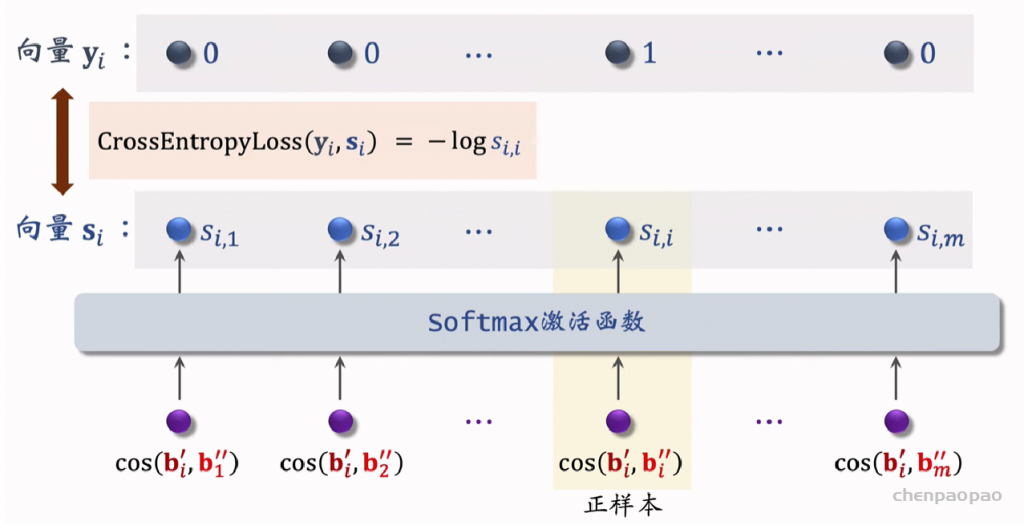
listwise:

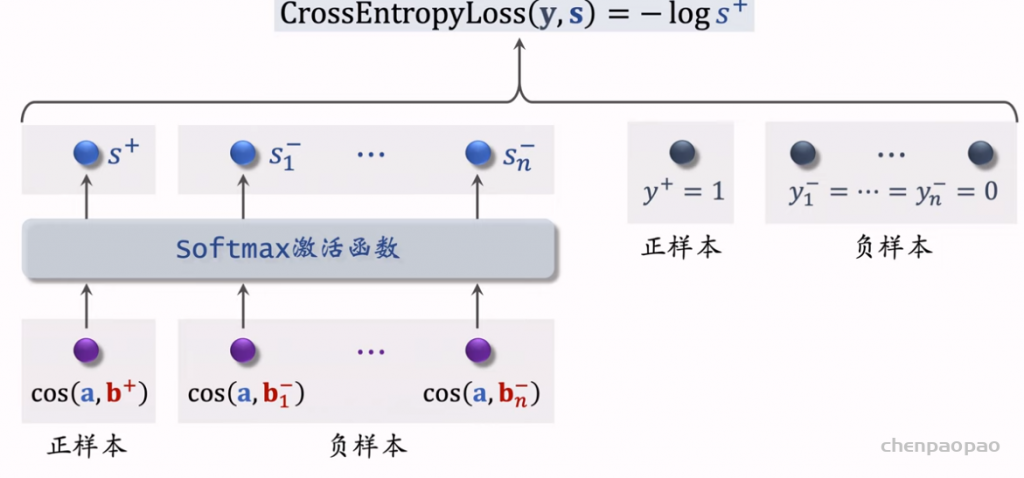

召回07:双塔模型–正负样本选择
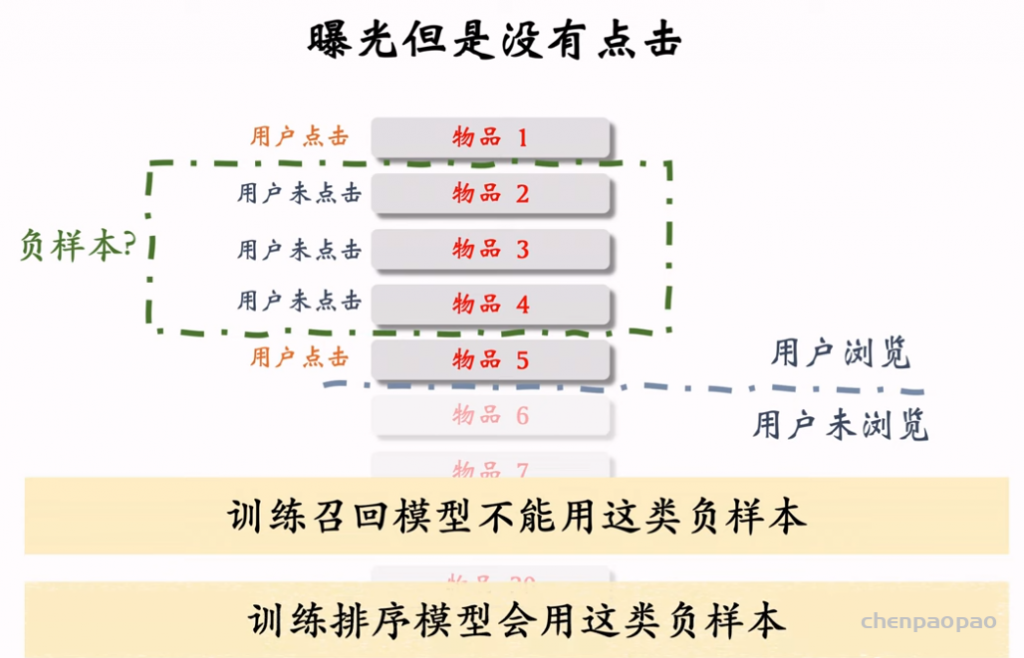
双塔模型(two-tower,也叫 DSSM)正负样本的选取。正样本是有点击的物品。负样本是被召回、排序淘汰的物品,分为简单负样本和困难负样本。

负样本:


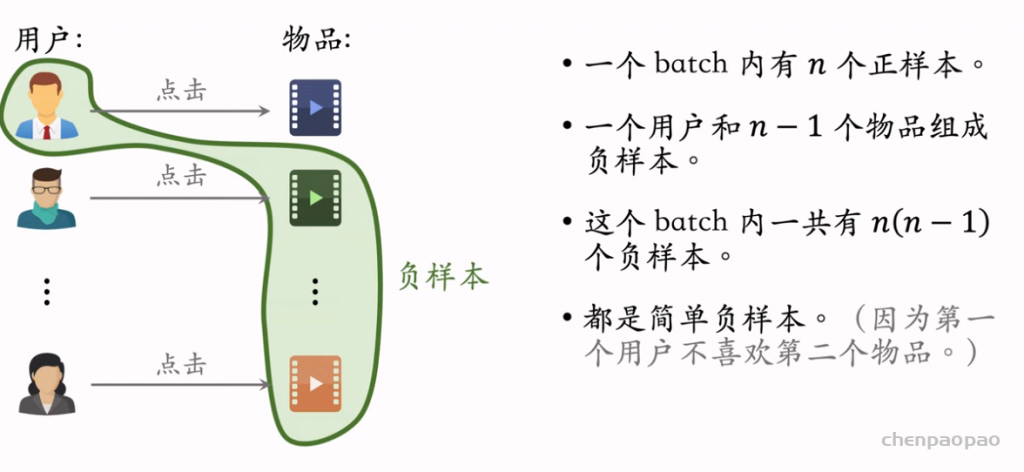
简单负样本:Batch内负样本

热门样本成为负样本的概率过大,解决办法:

困难负样本:




召回08:双塔模型的线上服务和模型更新
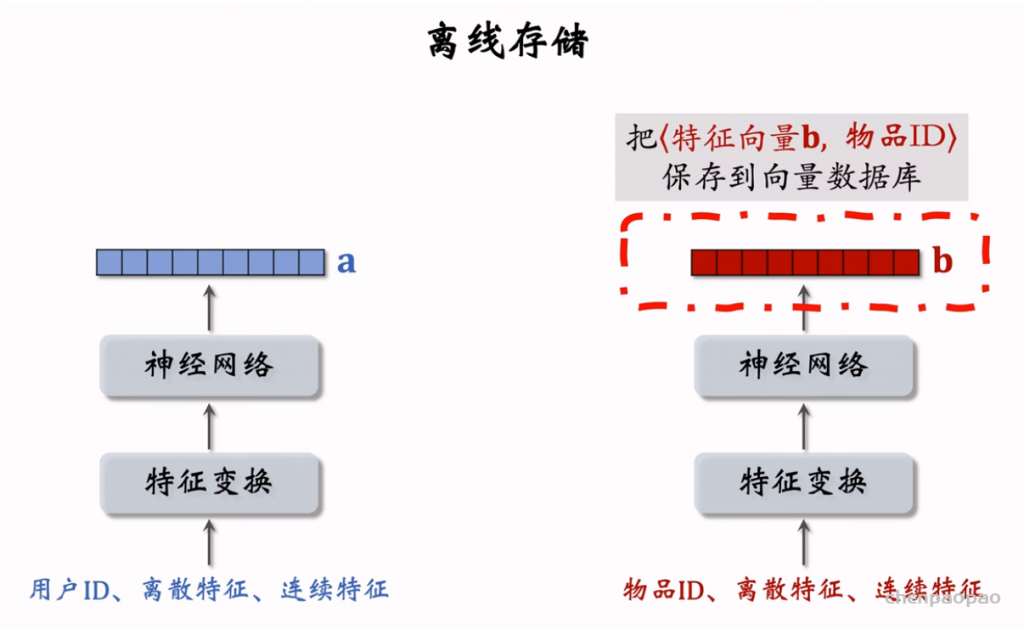
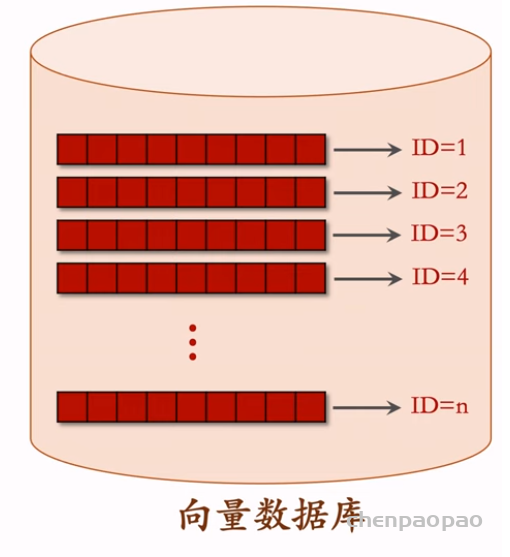
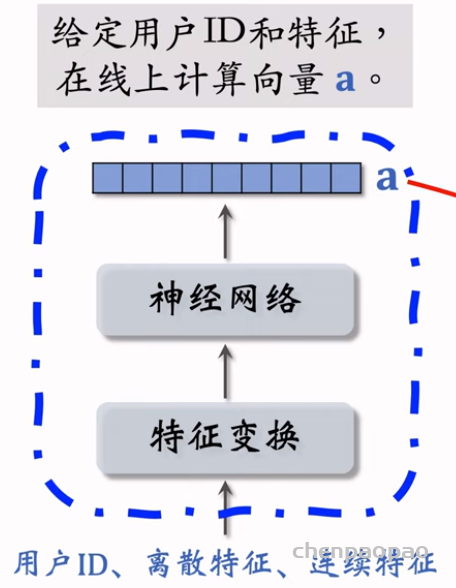
在开始线上服务之前,需要把物品向量存储到Milvus、Faiss、HnswLib这类向量数据库,供最近邻查找(KNN 或 ANN)。当用户发起推荐请求时,用户塔用用户ID和用户画像现算一个用户向量,作为query,去向量数据库中做最近邻查找。
模型需要定期做更新,分为全量更新(天级别)和增量更新(实时)。全量更新会训练整个模型,包括embedding和全连接层。而增量更新只需要训练embedding层。


模型更新:
全量更新:跟新用户和物体向量

增量更新:每隔几小时实现用户模型更新
为什么需要这个:用户的兴趣可能会随时改变,因此需要随时做用户的更新,且只更新用户embedding参数,其他参数不需要更新。

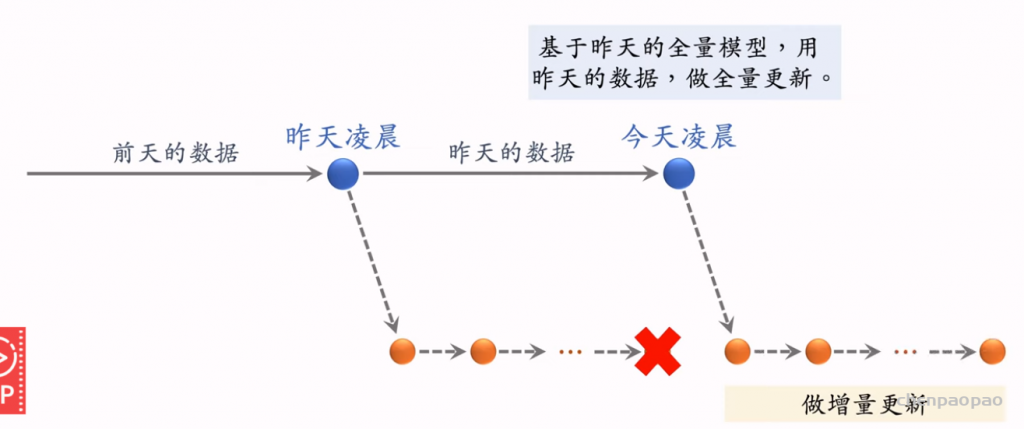
注意:每天的全量更新是基于昨天的全量更新后的模型进行训练的。
问题:能否只做增量更新,不做全量更新


召回09:双塔模型的改进–自监督学习
改进双塔模型的方法,叫做自监督学习(self-supervised learning),用在双塔模型上可以提升业务指标。这种方法由谷歌在2021年提出,工业界(包括小红书)普遍验证有效。
长尾效应:

参考文献: Tiansheng Yao et al. Self-supervised Learning for Large-scale Item Recommendations. In CIKM, 2021.
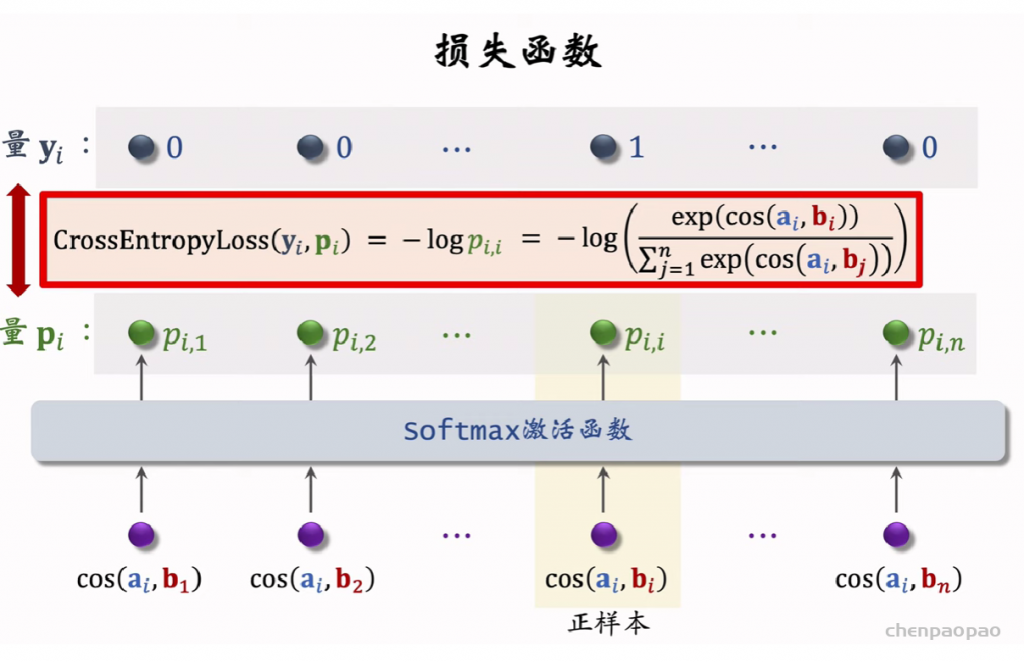


自监督学习:
对物品进行不同的特征变换得到的特征向量同类之间尽可能的相同,不同物体之间尽可能不同。
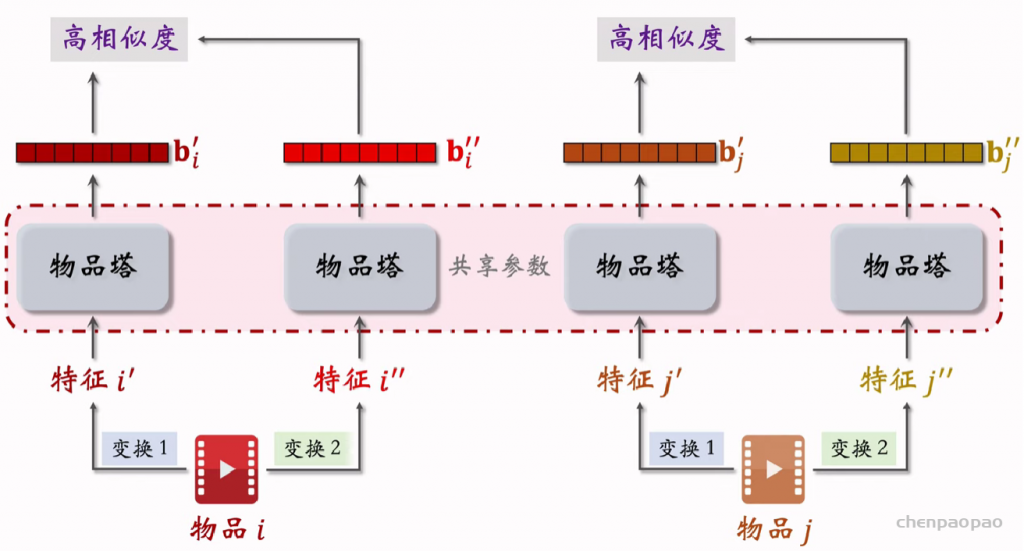
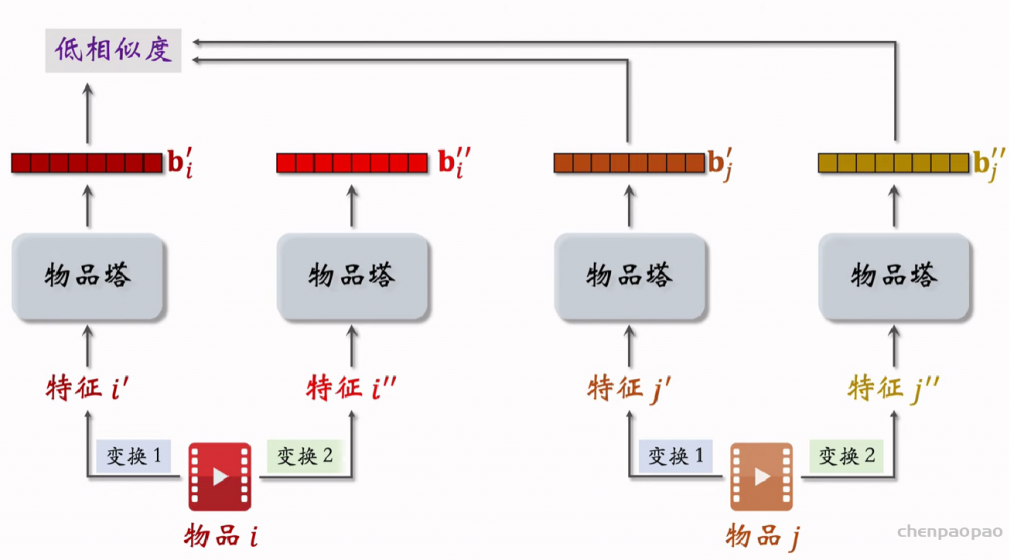

特征变换方法:
1、Random Mask

2、Dropout

3、互补特征

最好的办法 :Random mask(将一组相关联的特征全部mask)




召回10:其他召回通道
地理位置召回包括GeoHash召回和同城召回。作者召回包括关注作者、有交互作者、相似作者。缓存召回是储存精排打分高、而且未曝光的笔记。

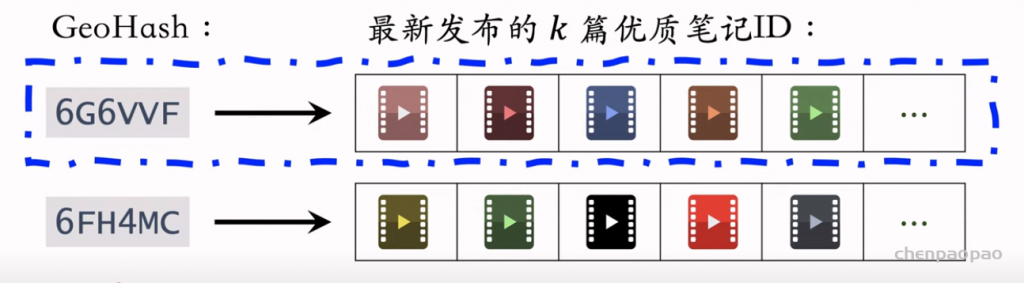







6个其他召回通道:
