Jascha Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. 2015. arXiv:1503.03585.2(1,2,3,4,5,6,7)
Calvin Luo. Understanding diffusion models: a unified perspective. 2022. arXiv:2208.11970.3(1,2,3,4)
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. 2020. arXiv:2006.11239.4
Diederik P. Kingma, Tim Salimans, Ben Poole, and Jonathan Ho. Variational diffusion models. 2022. arXiv:2107.00630.5
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. 2019. arXiv:1907.05600.
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. 2019. arXiv:1907.05600.
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. 2021. arXiv:2011.13456.
Aapo Hyvärinen and Peter Dayan. Estimation of non-normalized statistical models by score matching. Journal of Machine Learning Research, 2005.
Yang Song and Stefano Ermon. Improved techniques for training score-based generative models. 2020. arXiv:2006.09011.
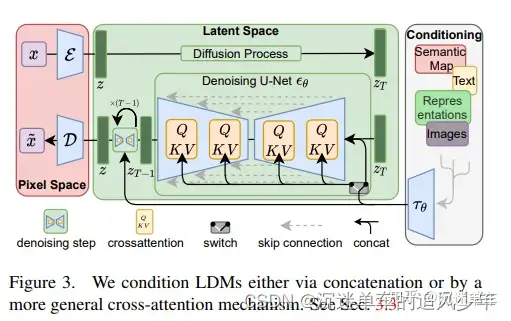
条件控制扩散模型
Prafulla Dhariwal and Alex Nichol. Diffusion models beat gans on image synthesis. 2021. arXiv:2105.05233.2(1,2)
Calvin Luo. Understanding diffusion models: a unified perspective. 2022. arXiv:2208.11970.3
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. 2022. arXiv:2207.12598.4
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: towards photorealistic image generation and editing with text-guided diffusion models. 2022. arXiv:2112.10741.5
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. 2022. arXiv:2204.06125.6
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding. 2022. arXiv:2205.11487.
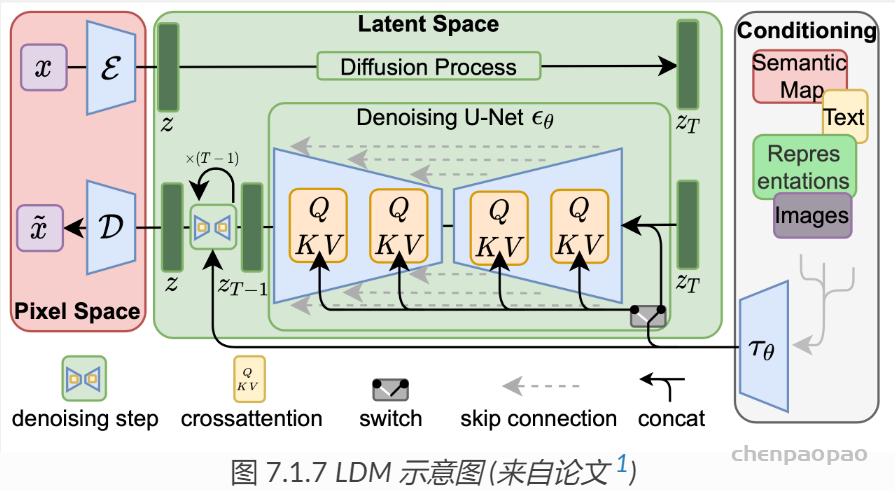
稳定扩散模型(Stable diffusion model)
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. 2021. arXiv:2112.10752.
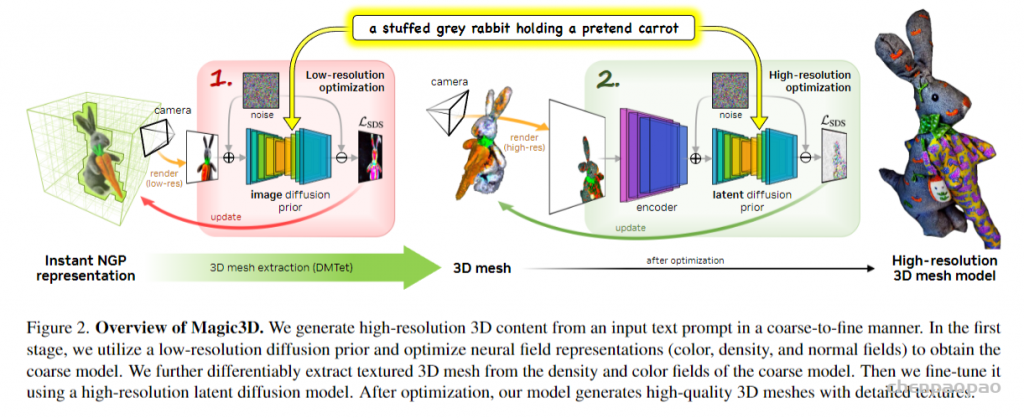
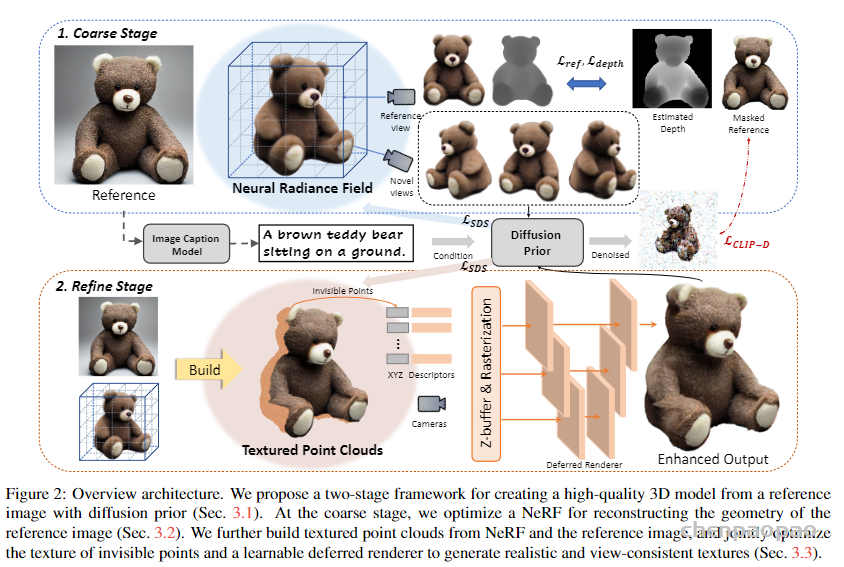
人们只需要输入一段文字比如「一只坐在睡莲上的蓝色箭毒蛙」,AI 就能给你生成个纹理造型俱全的 3D 模型出来。Magic3D 还可以执行基于提示的 3D 网格编辑:给定低分辨率 3D 模型和基本提示,可以更改文本从而修改生成的模型内容。此外,作者还展示了保持画风,以及将 2D 图像样式应用于 3D 模型的能力。
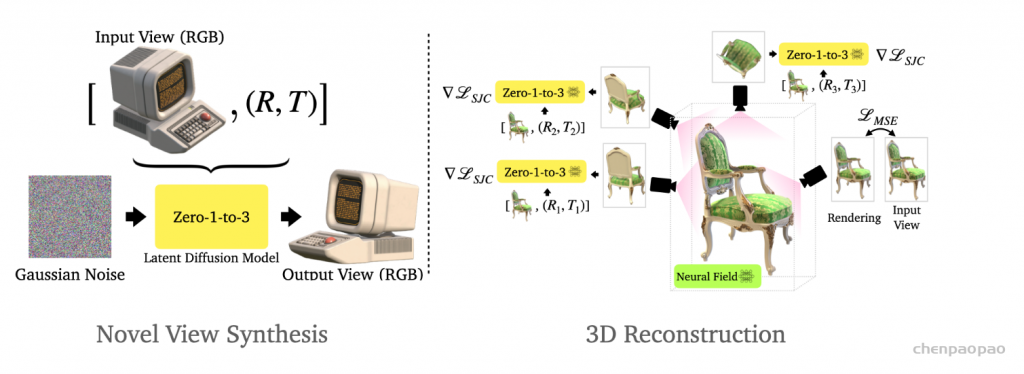
We learn a view-conditioned diffusion model that can subsequently control the viewpoint of an image containing a novel object (left). Such diffusion model can also be used to train a NeRF for 3D reconstruction (right). Please refer to our paper for more details or checkout our code for implementation.
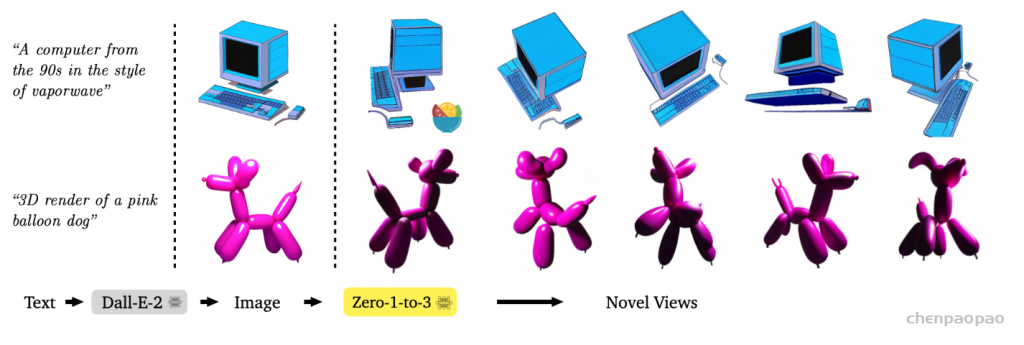
Text to Image to Novel Views
Here are results of applying Zero-1-to-3 to images generated by Dall-E-2.
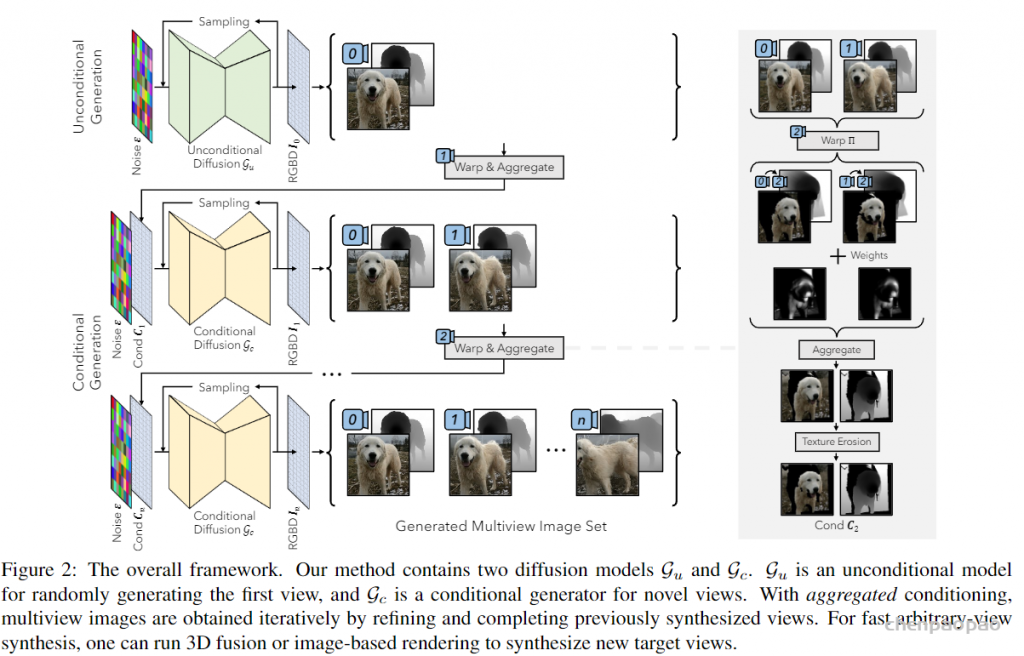
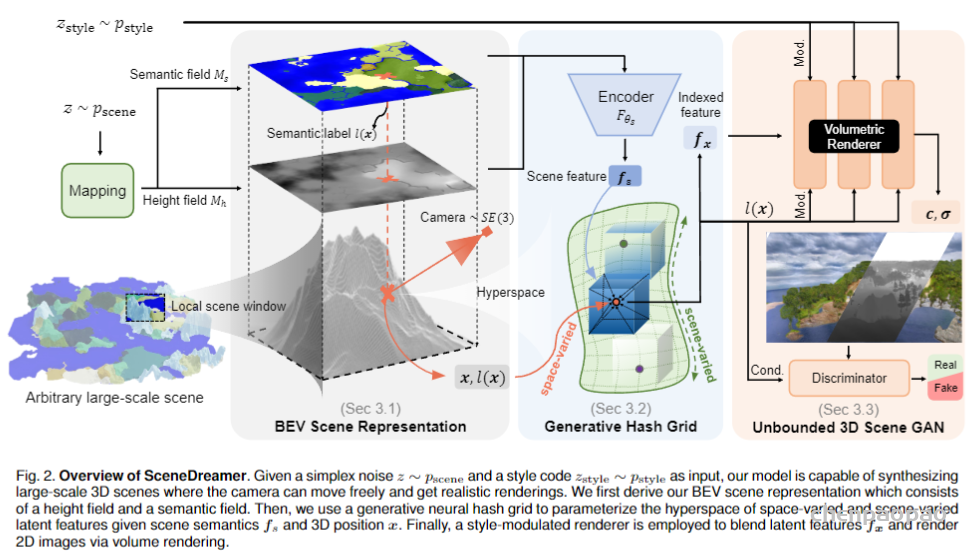
为满足元宇宙中对 3D 创意工具不断增长的需求,三维场景生成最近受到了相当多的关注。3D 内容创作的核心是逆向图形学,旨在从 2D 观测中恢复 3D 表征。考虑到创建 3D 资产所需的成本和劳动力,3D 内容创作的最终目标将是从海量的互联网二维图像中学习三维生成模型。最近关于三维感知生成模型的工作在一定程度上解决了这个问题,多数工作利用 2D 图像数据生成以物体为中心的内容(例如人脸、人体或物体)。然而,这类生成任务的观测空间处于有限域中,生成的目标占据了三维空间的有限区域。这就产生了一个问题,我们是否能从海量互联网 2D 图像中学习到无界场景的 3D 生成模型?比如能够覆盖任意大区域,且无限拓展的生动自然景观
我们先来看一下生成效果。与根据文字生成图像类似,Shap・E 生成的 3D 物体模型主打一个「天马行空」。
本文提出的 Shap・E 是一种在 3D 隐式函数空间上的潜扩散模型,可以渲染成 NeRF 和纹理网格。在给定相同的数据集、模型架构和训练计算的情况下,Shap・E 更优于同类显式生成模型。研究者发现纯文本条件模型可以生成多样化、有趣的物体,更彰显了生成隐式表征的潜力。
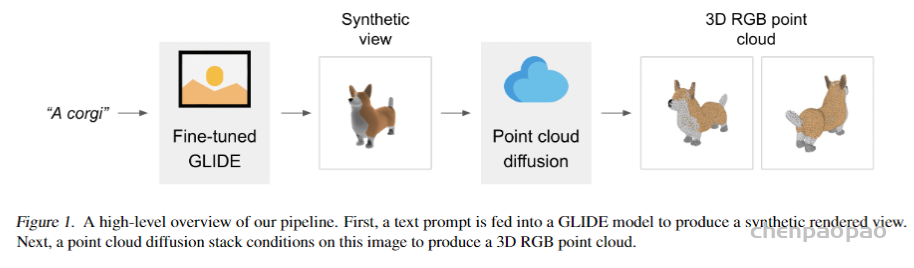
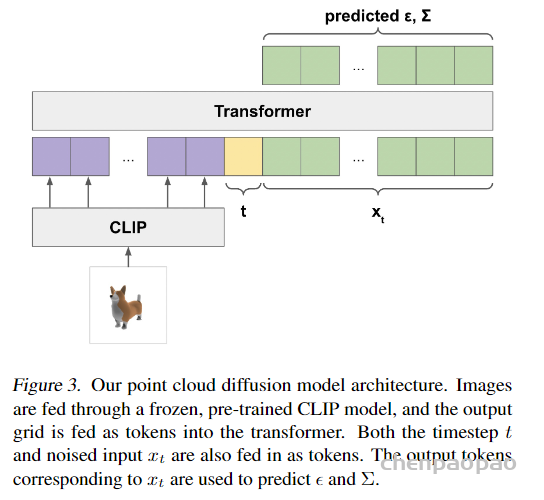
不同于 3D 生成模型上产生单一输出表示的工作,Shap-E 能够直接生成隐式函数的参数。训练 Shap-E 分为两个阶段:首先训练编码器,该编码器将 3D 资产确定性地映射到隐式函数的参数中;其次在编码器的输出上训练条件扩散模型。当在配对 3D 和文本数据的大型数据集上进行训练时, 该模型能够在几秒钟内生成复杂而多样的 3D 资产。与点云显式生成模型 Point・E 相比,Shap-E 建模了高维、多表示的输出空间,收敛更快,并且达到了相当或更好的样本质量。
研究者首先训练编码器产生隐式表示,然后在编码器产生的潜在表示上训练扩散模型,主要分为以下两步完成: 1. 训练一个编码器,在给定已知 3D 资产的密集显式表示的情况下,产生隐式函数的参数。编码器产生 3D 资产的潜在表示后线性投影,以获得多层感知器(MLP)的权重;
2. 将编码器应用于数据集,然后在潜在数据集上训练扩散先验。该模型以图像或文本描述为条件。 研究者在一个大型的 3D 资产数据集上使用相应的渲染、点云和文本标题训练所有模型。
清华大学 TSAIL 团队最新提出的文生 3D 新算法 ProlificDreamer,在无需任何 3D 数据的前提下能够生成超高质量的 3D 内容。ProlificDreamer 算法为文生 3D 领域带来重大进展。利用 ProlificDreamer,输入文本 “一个菠萝”,就能生成非常逼真且高清的 3D 菠萝:
将 Imagen 生成的照片(下图静态图)和 ProlificDreamer(基于 Stable-Diffusion)生成的 3D(下图动态图)进行对比。有网友感慨:短短一年时间,高质量的生成已经能够从 2D 图像领域扩展到 3D 领域了
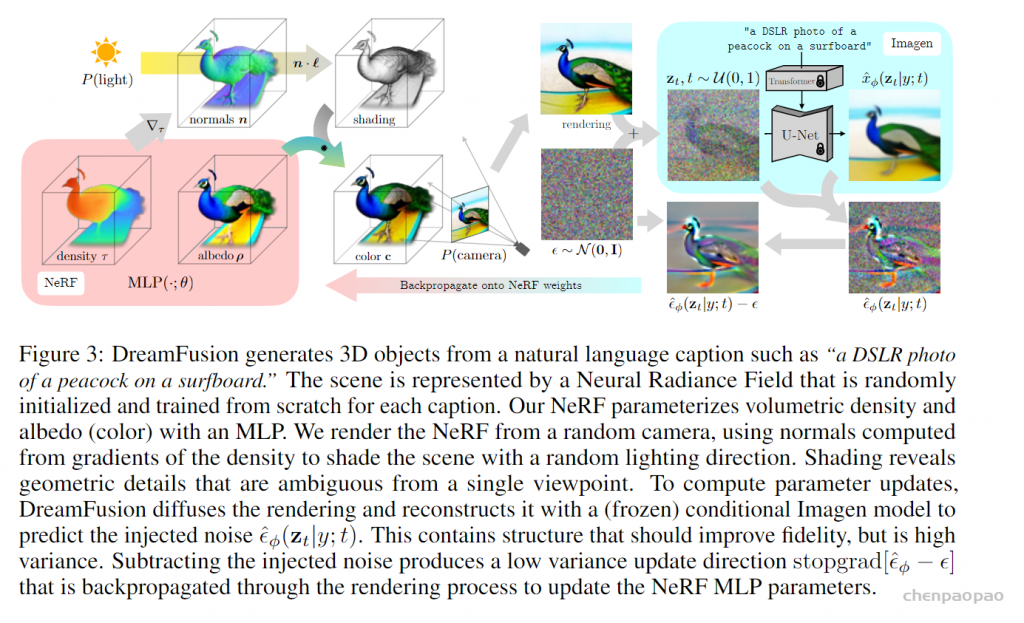
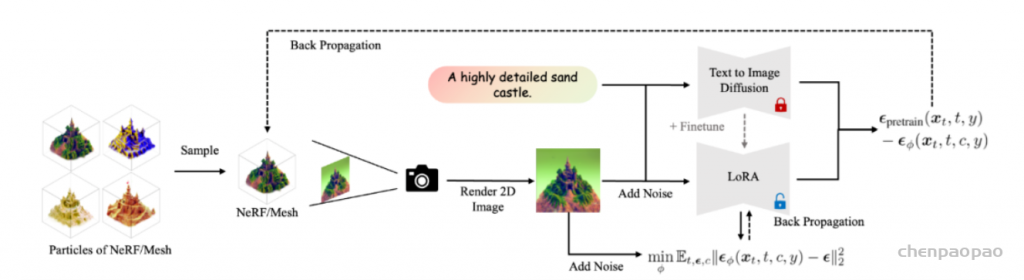
在数字创作和虚拟现实等领域,从文本到三维模型(Text-to-3D)的技术具有重要的价值和广泛的应用潜力。这种技术可以从简单的文本描述中生成具体的 3D 模型,为设计师、游戏开发者和数字艺术家提供强大的工具。然而,为了根据文本生成准确的 3D 模型,传统方法需要大量的标记 3D 模型数据集。这些数据集需要包含多种不同类型和风格的 3D 模型,并且每个模型都需要与相应的文本描述相关联。创建这样的数据集需要大量的时间和人力资源,目前还没有现成的大规模数据集可供使用。由谷歌提出的 DreamFusion [1] 利用预训练的 2D 文本到图像扩散模型,首次在无需 3D 数据的情况下完成开放域的文本到 3D 的合成。但是 DreamFusion 提出的 Score Distillation Sampling (SDS) [1] 算法生成结果面临严重的过饱和、过平滑、缺少细节等问题。高质量 3D 内容生成目前仍然是非常困难的前沿问题之一。ProlificDreamer 论文提出了 Variational Score Distillation(VSD)算法,从贝叶斯建模和变分推断(variational inference)的角度重新形式化了 text-to-3D 问题。具体而言,VSD 把 3D 参数建模为一个概率分布,并优化其渲染的二维图片的分布和预训练 2D 扩散模型的分布间的距离。可以证明,VSD 算法中的 3D 参数近似了从 3D 分布中采样的过程,解决了 DreamFusion 所提 SDS 算法的过饱和、过平滑、缺少多样性等问题。此外,SDS 往往需要很大的监督权重(CFG=100),而 VSD 是首个可以用正常 CFG(=7.5)的算法。
与以往方法不同,ProlificDreamer 并不单纯优化单个 3D 物体,而是优化 3D 物体对应的概率分布。通常而言,给定一个有效的文本输入,存在一个概率分布包含了该文本描述下所有可能的 3D 物体。基于该 3D 概率分布,我们可以进一步诱导出一个 2D 概率分布。具体而言,只需要对每一个 3D 物体经过相机渲染到 2D,即可得到一个 2D 图像的概率分布。因此,优化 3D 分布可以被等效地转换为优化 2D 渲染图片的概率分布与 2D 扩散模型定义的概率分布之间的距离(由 KL 散度定义)。这是一个经典的变分推断(variational inference)任务,因此 ProlificDreamer 文中将该任务及对应的算法称为变分得分蒸馏(Variational Score Distillation,VSD)。具体而言,VSD 的算法流程图如下所示。其中,3D 物体的迭代更新需要使用两个模型:一个是预训练的 2D 扩散模型(例如 Stable-Diffusion),另一个是基于该预训练模型的 LoRA(low-rank adaptation)。该 LoRA 估计了当前 3D 物体诱导的 2D 图片分布的得分函数(score function),并进一步用于更新 3D 物体。该算法实际上在模拟 Wasserstein 梯度流,并可以保证收敛得到的分布满足与预训练的 2D 扩散模型的 KL 散度最小。