
Stable Diffusion
Stable Diffusion was made possible thanks to a collaboration with Stability AI and Runway and builds upon our previous work:
High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach*, Andreas Blattmann*, Dominik Lorenz, Patrick Esser, Björn Ommer
CVPR ’22 Oral | GitHub | arXiv | Project page


参考: https://zhuanlan.zhihu.com/p/573984443
参考: https://zhuanlan.zhihu.com/p/599160988
扩散模型汇总 :https://github.com/heejkoo/Awesome-Diffusion-Models
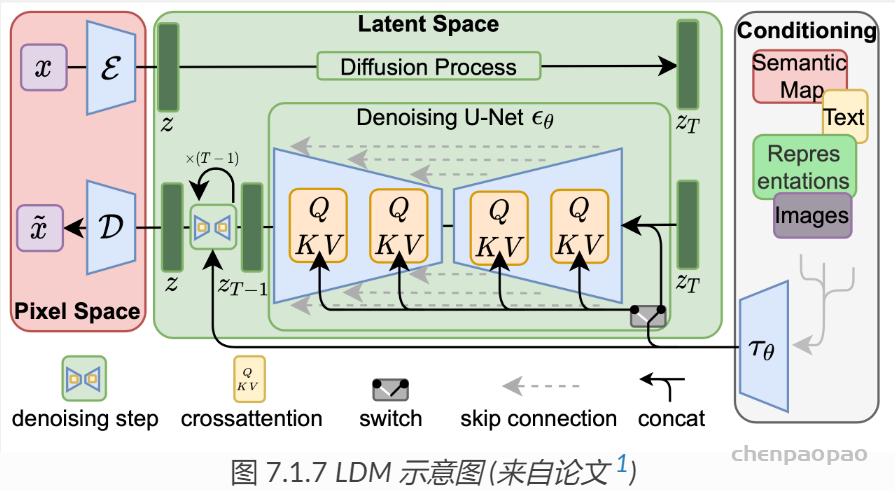
DDPM 模型在生成图像质量上效果已经非常好,但它也有个缺点, 那就是xt 的尺寸是和图片一致的,xt的元素和图片的像素是一一对应的, 所以称 DDPM 是像素(pixel)空间的生成模型。 我们知道一张图片的尺寸是 3×H×W ,如果想生成一张高尺寸的图像, Xt的张量大小是非常大的,这就需要极大的显卡(硬件)资源,包括计算资源和显存资源。 同样的,它的训练成本也是高昂的。高昂的成本极大的限制了它在民用领用的发展。
1. 潜在扩散模型(Latent diffusion model,LDM)
2021年德国慕尼黑路德维希-马克西米利安大学计算机视觉和学习研究小组(原海德堡大学计算机视觉小组), 简称 CompVis 小组,发布了论文 High-Resolution Image Synthesis with Latent Diffusion Models,针对这个问题做了一些改进, 主要的改进点有:
- 引入一个自编码器,先对原始对象进行压缩编码,编码后的向量再应用到扩散模型。
- 通过在 UNET 中加入 Attention 机制,处理条件变量 y。
潜在空间
针对 DDPM 消耗资源的问题,解决方法也简单。 引入一个自编码器,比如上一章介绍的变分编码器(VAE),先对原始图像进行压缩编码,得到图像的低维表示 z0 ,然后 x0 作为 DDPM 的输入,执行 DDPM 的算法过程,DDPM 生成的结果再经过解码器还原成图像。 由于 z0 是压缩过的,其尺寸远远小于原始的图像,这样就能极大的减少 DDPM 资源的消耗。 压缩后 z0 所在的数据空间称为潜在空间(latent space), z0 可以称为潜在数据。
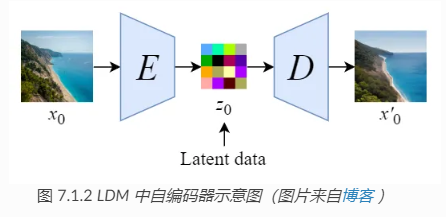
这个自编码器(VAE)可以是提前预训练好的模型,在训练扩散模型时,自编码器的参数是冻住的, 如 图 7.1.2 所示
- 通过使用预训练的编码器 E,我们可以将全尺寸图像编码为低维潜在空间数据(压缩数据)。
- 通过使用预训练的解码器 D,我们可以将潜在空间数据解码回图像。
这样在 DDPM 外层增加一个 VAE 后,DDPM 的扩散过程和降噪过程都是在潜空间(Latent Space)进行, 潜空间的尺寸远远小于像素空间,极大了降低了硬件资源的需求,同时也能加速整个过程。
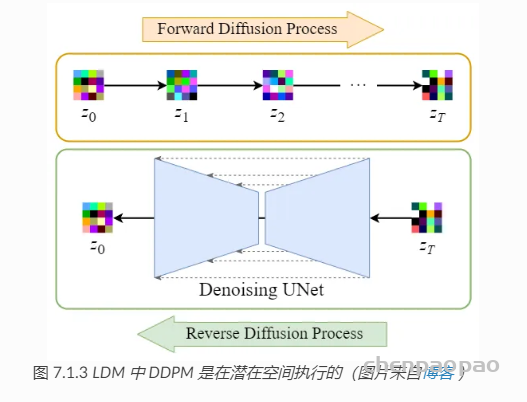
正向扩散过程→给潜在数据增加噪声,逆向扩散过程→从潜在数据中消除噪声。 整个 DDPM 的过程都是在潜在空间执行的, 所以这个算法被称为潜在扩散模型(Latent diffusion model,LDM)。增加一个自编码器并没有改变 DDPM 的算法过程,所以并不需要对 DDPM 算法代码做任何改动。
条件处理
在 DDPM 的过程中,可以增加额外的指导信息,使其生成我们的想要的图像, 比如文本生成图像、图像生成图像等等。
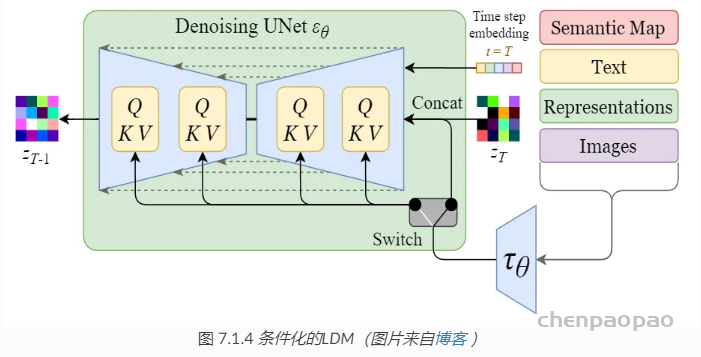

关于注意力机制的实现细节,可以直接参考论文代码, LDM模型论文的代码和预训练的模型已经在 Github 开源,地址为: https://github.com/CompVis/latent-diffusion 。
训练过程
相比于 DDPM ,条件化的 LDM 目标函数稍微变化了一点,具体变化内容可以参考:

生成(采样)过程:
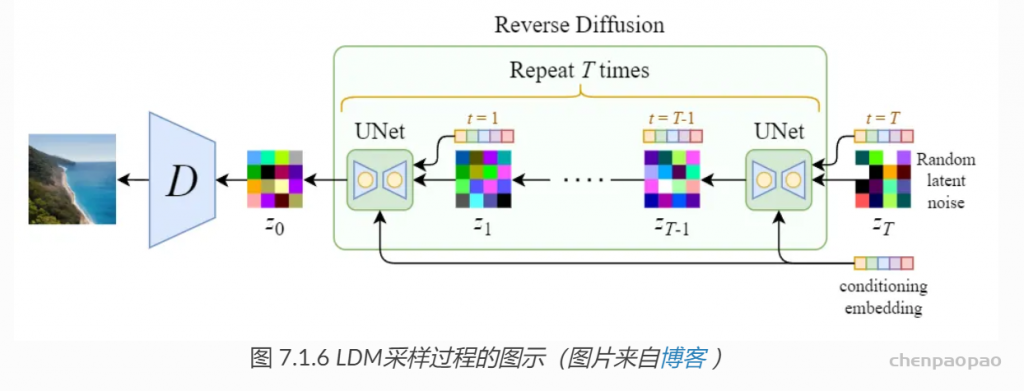
图 7.1.6 是 LDM 采样过程的图形化表示, 过程并不复杂,经过 DDPM 采样生成的 Z0 需要用解码器 D 还原成图像。
2、稳定扩散模型(Stable diffusion,SD)
LDM 本身是由 CompVis 提出并联合 Runway ML进行开发实现,后来 Stability AI 也参与进来并提供了一些资源, 联合搞了一个预训练的 LDM 模型,称为 Stable diffusion。 所以,Stable diffusion 是 LDM 的一个开源预训练模型,由于它的开源迅速火爆起来。 目前 Stable diffusion 已经占据了图像生成开源领域的主导地位。
由于 Stable diffusion 只是LDM的一个开源预训练模型,没有额外的复杂数学公式需要讨论, 这里我们就直接上代码吧。 我们不用 Stable diffusion 的官方代码库 stablediffusion ,而是 huggingface 开源库 diffusers 中的实现, 它的易读性更好一些。
diffusers 把模型的核心逻辑都封装在各种 DiffusionPipeline 中, StableDiffusionPipeline 核心代码在 diffusers.StableDiffusionPipeline 先看初始化代码,可明显看到整个 StableDiffusionPipeline 包含几个关键组件:vae,text_encoder/tokenizer,unet,scheduler。 这几个组件和 LDM 中是对应的。
- vae: VAE 自编码器,负责前后的编解码(压缩、解压缩)工作。
- text_encoder/tokenizer: 文本编码器,负责对文本Prompt进行编码处理。
- unet: 噪声预测模型,也是DDPM的核心。
- scheduler: 负责降噪过程(逆过程)的计算,也就是实现 xt−>xt−1 ,对应着 DDPM、DDIM、ODE等不同的降采样实现。
- safety_checker: 做生成图像安全性检查的,可选,暂时可以不关注它。
- feature_extractor: 如果输入条件中存在 img,也就是以图生图(img2img),可以用它对条件图片进行特征抽取,也就是图像编码器(img encoder),可选。