
论文地址: Mamba: Linear-Time Sequence Modeling with Selective State Spaces

代码: https://github.com/state-spaces/mamba
天下苦 Transformer 久矣!整整7年了,一个理论上一点也不漂亮,纯粹靠着模型堆砌和工程上的大力出奇迹,统治了整个NLP 领域和如今大模型的发展。然而,它的局限性日益凸显,计算量的庞大,数据和算力需求越来越让凡人仰望。俱往矣,数风流人物,还看今朝。Mamba 模型的破土而出,让我们看到了结束这一切的曙光,也是为什么引起 A1 界广泛兴奋的原因,尤其是它回归时空序列建模,从中寻找灵感并将其与新型注意力机制结合的思路很有启发。
原文较为晦涩,网上技术文章虽然不少,但一方面写文章的人照本宣科念经的比较多,自己压根没懂,导致读的人反而怀疑自己的智商;另一方面看到网上很多吃瓜群众跟着瞎起哄What l can say, Mamba out!你连它是啥都不知道,嘴都没亲一下,就 OUTOUT 啥?
它其实是用一个李指数映射代替了 Transformer 的非线性状态方程。估计大部分人连啥是“李指数”都没听说过。那这个模型到底是什么来头?凭什么能对transformer 的江湖地位形成挑战?原理是什么,与 RNN 等模型的联系是那些?为什么说它是用流体力学的思想指导了时序建模?牛逼之处和未来发展的看点在哪里?子日:知之为知之,不知为不知,是知也。
首先我们快速回顾一下 transformer 的本质缺陷。然后从传统的序列数据状态空间模型讲起补充所需的知识。接着重点讲解 Mamba 模型的核心原理、技术细节和真正精髓。然后通过实验体会它的牛逼效果以及代码实现。最后是总结和展望。
一、Transformer 的死穴
Transformer 结构的核心是自注意力机制层,甭管是encoder,还是 decoder,序列数据都先经过位置编码后喂给这个模块。
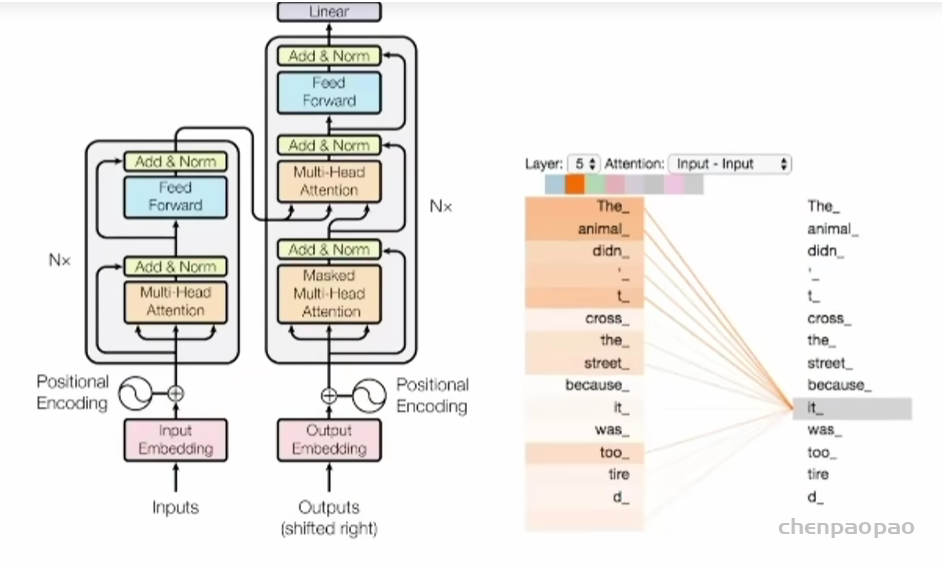
这里有个天然的缺陷,就是自注意力机制的计算范围仅限于窗口内,而无法直接处理窗口外的元素。像极了古语所说:两耳不闻窗外事,一心只读圣贤书。某种程度上造成视野狭窄,信息孤立,缺乏全局观一样,这种机制无法建模超出有限窗口的任何内容,看不到更长序列的世界。
于是有人说了,那增加窗口长度不就行了,没毛病,理论上可行。但对不起,这样会导致计算复杂度随着窗口长度的增加呈平方增长0(n^2),因为每个位置的计算都需要与窗口内的所有其他位置进行比较,如右图所示。
本质上说,它这是通过位置编码,把序列数据空间化,然后通过计算空间相关度反向建模时序相关度。这个过程中忽视了数据内在结构的细腻关联关系,而是采取了一种一视同仁的暴力关联模式,好处是直接简单,但显然参数效率低下,兄余度高,训练起来不易。那怎么办呢?俗话说:魔鬼的归魔鬼,天使的归天使。明明是时序数据,非要用空间化实现注意力机制。这在当年是为了充分利用 GPU的并行能力,非常有效,但并不是万能的。本质上说还是有问题的。让长序列数据建模回归传统,某种程度上说,这是整个SSM 类模型思考问题的初衷和视角。而 mamba 是其中的佼佼者。因此,咱们先从时序状态空间模型开始讲起。
二、时序状态空间模型 SSM
Mamba是基于结构化状态空间序列模型(SSMs)的,这是2021年提出的工作,算是火了两年了。需要补充读这篇文章。

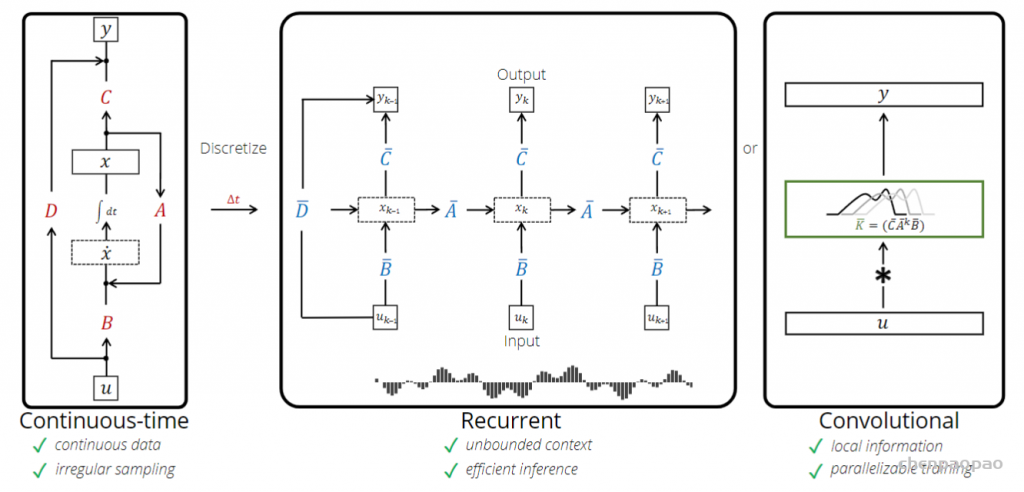
实际上还是旧瓶装新酒,模型还是时序的,本身就是个 RNN 模型。我们用下面这三幅图来讲清它是怎么来的,长什么样,又怎么用。
1.连续空间的时序建模
很多实际问题都能用左图所示的连续空间模型来建模。尤其是控制理论、信号处理或者线性系统领域特别常见。我们称为 LTI,线性时不变 linear tiem-invariant 系统,用公式表示就是:
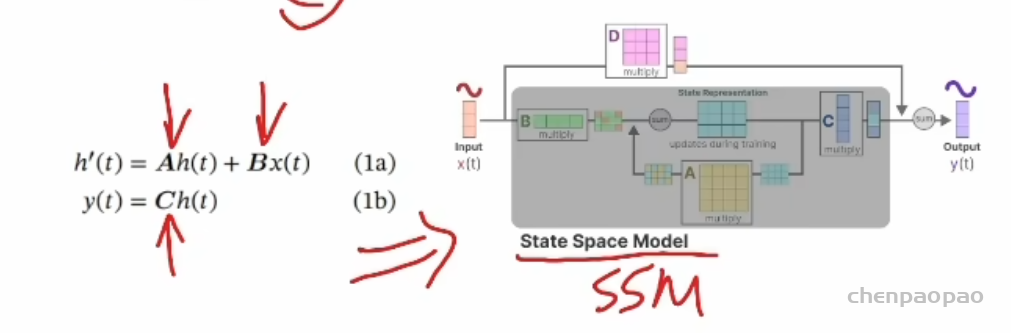
线性时不变系统(linear, time-invariant system, LTI) 就是有如下两个性质的一类系统: 线性:如果你同时向系统输入两个不同的信号,那么得到的输出和这两个信号各自向系统的输出之和相同。 用数学语言描述为,如果输入 x1 产生输出 y1 ,输入 x2 产生输出 y2,那么 输入 ax1+bx2 产生的输出为 ay1+by2 。这里 a 和 b 为常数。 时不变性:系统的作用效果不随时间的变化而变化,仅依赖于系统本身的状态。因此,如果输入变化仅是在时间上平移, 那么产生的输出变化也仅仅是相同的时间平移,其他都是一样的。
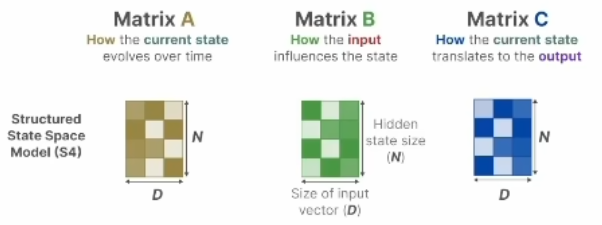
输入x乘以B+隐状态h乘以A得到隐状态导数,h乘以C得到输出。上面的叫状态方程,下面是观测方程,ABCD 是参数矩阵。也可以用右图更加清楚的看到它的矩阵变化关系。之所以叫时不变,就是 ABCD 是固定的,这当然是一种假设,而且是个强假设。D在上面的式子中没写主要是因为在许多实际系统中,它可以是零。很多人学SSM 弄着弄着就忘了这个强假设。transformer 本身是没有这样的假设的,也就是说可以用于时变系统和非线性系统。牺牲通用性,换来特定场景下的更高性能,这就是所有 SSM 模型的最底层逻辑。(画图:表示逻辑关系)

2.时序离散化与 RNN
连续系统不方便计算机处理,中间图是对它的离散化展开,就是沿时间拉长,模型和RNN 长相上几乎一样。公式与上面类似,只是导数h'(t)改为不同时刻角标,形成递归过程,这些完全是大学线性系统的内容。
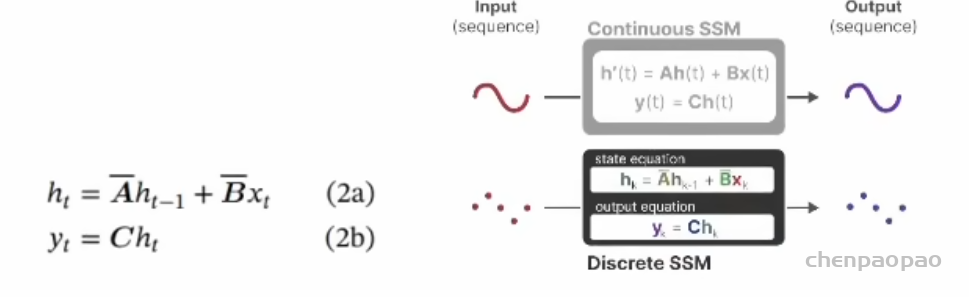
原文在这里给出了一种从连续系统转换为离散系统的 ABC 参数对应关系,这段如果你没有控制理论基础或者线性代数不好的话,基本直接懵逼。不过它其实只是一种方法的举例,学名叫“零阶保持(Zero-Order Hold,ZOH)”。公式不用记,只要知道用了这么一个 delta 函数,经过这么一通运算能得到新的A和B就可以了。这个后面用得到。
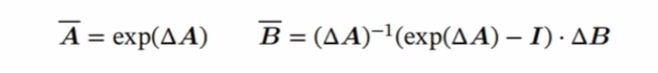
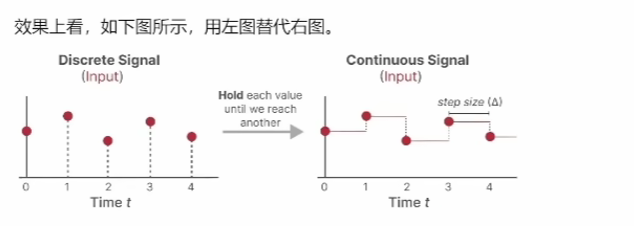
其实,还有很多种离散化方法。离散化主要是为了方便计算机处理,同时也是 Mamba的一个技巧,后面会讲它怎么转化成类似 RNN 的门控机制。
3.并行化处理与CNN
如果只是时序建模,SSM 和 RNN 相比也就没啥意思了。它最大的特点就是通过下图卷积实现了计算上的并行化。
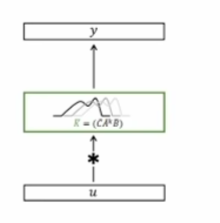
看图,就是把长长的链条一下子弄成了输入输出直接对应的样子,隐变量关联关系都跑到中间肚子里去了。先说结论:核心思想是用 CNN 对时序数据建模,借助不同尺度的卷积核,从不同时间尺度上捕获时序特征。数学上一番推导猛如虎之后能得到下面的公式。
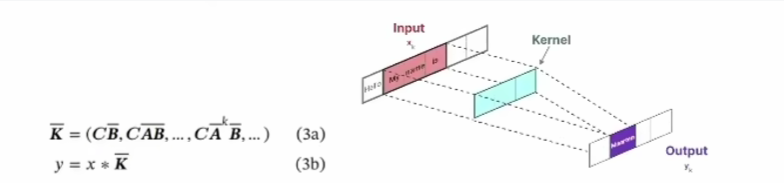
第二个式子和前面的图完全对应,就是个CNN 实现。时序递归状态方程改用卷积操作实现了,ABC参数矩阵变成了K,就是图中绿色框内的卷积核。这就牛逼了哈,拖拖拉拉的时序计算变成了能一口气的并行计算。体现在效果上,借助不同卷积核捕捉局部时间序列特征,能同时对短期和长期依赖关系学习,并行计算提高了训练和推理效率,使得 SSMs 在处理复杂的时序数据时表现出色。
结论知道了,爱学习的同学一定好奇这是怎么来的,凭啥就能做这种转换。其实也没那么猛,全是线性系统中现成的内容,学信号处理或自动控制的同学应该很熟。为了让没学过的同学们过过瘾,梗直哥这里用人话给你快速推导一遍,也不难。前面的RNN 公式不是沿着时间迭代的嘛,以两个时刻为例:

离散卷积的定义:
将两个离散序列中的数,按照规则,两两相乘再相加的操作。计算卷积的过程:序列翻转,移位,相乘,取和。
你会发现,二者在结构上类似:
首先,最外面都是求和 Sigma,与虽然上限不同,但都是在一个范围内进行求和,对不同时间步和相应权重的线性组合,因此类似。其次,看输入信号,一个是x_{t-k},一个是x[k],无非是不同的时间步,都涉及时间偏移,因此也类似。
第三,看权重,一个是CB,一个是h[t-k],都是随着时间k变化的量。因此,时序的状态空间模型能改写成卷积的形式啦。到这里,不得不感慨一下。卷积可以说是个极其伟大的数学运算发明,起源于 100 多年前傅里叶变换的工作。它就像是一个“滤镜”,可以帮助我们突出信号中的某些特征,识别和提取信号中的重要信息,因此在信号处理与通信系统领域占据了核心地位。
除此之外,在上面式子中需要注意的是,实际问题中往往会对 ABC矩阵进一步简化假设成更简单的对角阵方便计算,这就是所谓的结构化 SSM,S4 模型。
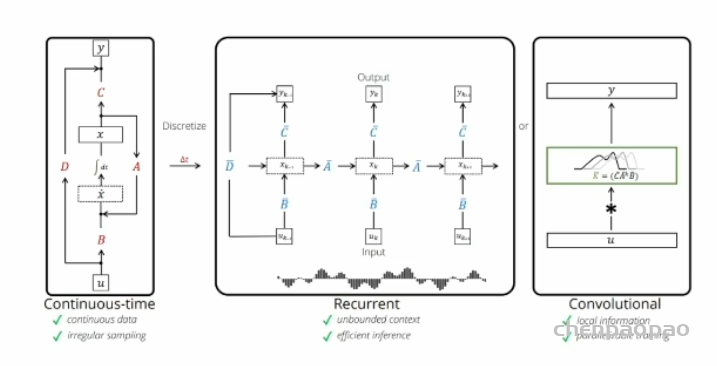
到这里,再回来看看这幅图。你有没有赫然发现,历史总是重演的,三十年河东,三十年河西。大家熟悉的 CNN、RNN,眼瞅着过时了,没想到又能杀回来。我常提醒大家,想学好深度学习,一定要系统的学,这样你才能高屋建瓴,有全局观。不要一上来总盯着 transformer,但有些人不信邪,往往只想偷懒追风。其实,很多时候,“横看成岭侧成峰,远近高低各不同”。不同模型的巧妙利用和合理组合,也许会迸发新的活力,就像这个 SSM 一样,某种程度上,其实只是换了个名字的CNN 化的 RNN。
我们用生活中的例子来帮你更好理解 RNN 和 SSM 的区别。想象你在读一本书,时序嵌套的 RNN 每次只能读一行,然后把记忆传递到下一行,这种方法只适合处理短故事,故事一长,容易忘记前面的情节。而SSM 并行处理,同时打开所有页看到每行内容,这样就能快速找到和理解整本书,无需逐行传递记忆。
我们用生活中的例子来帮你更好理解 RNN 和 SSM 的区别。想象你在读一本书,时序嵌套的 RNN 每次只能读一行,然后把记忆传递到下一行,这种方法只适合处理短故事,故事一长,容易忘记前面的情节。而SSM 并行处理,同时打开所有页看到每行内容,这样就能快速找到和理解整本书,无需逐行传递记忆。
对应原文,我们已经讲完了简介和第二部分。你可能会问,看上去并行的SSM 就挺好的啊为啥不行呢?别忘了,这个系统还有两个强假设:线性+时不变。极大的限制了它的应用范围,因为实际系统大多为非线性、时变系统。Mamba本质上就是一个 SSM 模型的改进版,放开了这两个约束。
三、Mamba: 选择性 SSM
解决了 SSM 线性+时不变的缺陷
接下来咱们着重讲解什么是选择性 SSM。Mamba 主要体现在设计了一种机制,让状态空间具备选择性,达到了 Transformers 的建模能力,同时在序列长度上实现了线性扩展,也就是克服了 Transformers 的缺陷,可处理最长达百万长度的序列,而且效率贼高,与 GPU 硬件适配,比Transformers 快5倍,准确率相当甚至更好。这就是它为啥牛逼起来的原因啦。
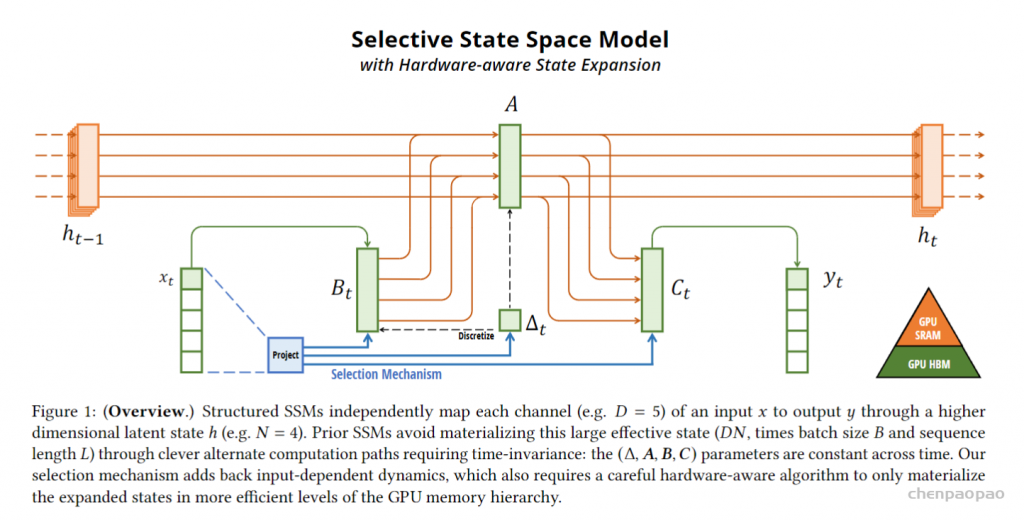
核心就是搞懂这幅图,其实大致看看就明白,在时间序列模型中间设计了这么一坨非常类似LSMT的门结构,实现所谓的选择性,BC都带了t变成了时变参数,A虽然没有直接含t,但由于delat函数影响A,所以A其实也是时变的了。下面的蓝色部分就是所谓的选择机制,这个delat别小瞧,它就是前面离散函数,也是一个非线性的函数,一会有大用。要真正明白其中的细节,先要从增加选择性的动机开始讲,但其实简单理解就是把整个系统该用:
一个总开关 delat+若干个旋钮Bt,Ct ==非线性时变系统
下面的解释可以认为是对这种选择的合理化。
1.要解决什么问题
从某种角度看,序列建模的核心就是研究如何将长序列的上下文信息压缩到一个较小的状态中。比如,语言模型实际上就是在一个有限的词汇集合中不断进行转换。有统计表明,3500 多个常用中文字,3000个常用英文词能覆盖90%以上的日常用语。transformer 的注意力机制虽然很有效,但效率低,因为它需要存储整个上下文,导致推理和训练时间较长。前面讲的 SSM 递归模型可以并行处理,但因为它们的状态是有限的(单纯时不变导致),效率高但有效性受限于状态的压缩能力。

那能不能设计一种模型,平衡一下,实现这种类似的强选择能力。具体来说,本文关注两种能力:
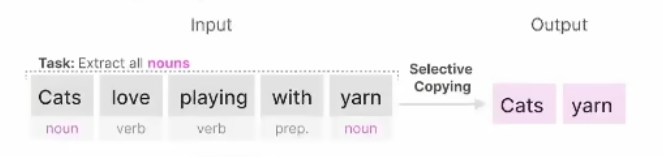
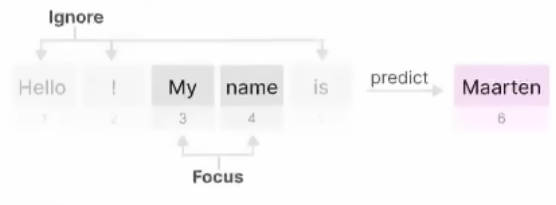
一是抓重点的能力(选择性复制任务)。从大量信息中选择和记住关键的信息,忽略不相关的部分。类似于在人群中找到你的朋友或者在一篇文章中找到关键词。比如从下面句子中找出名词。
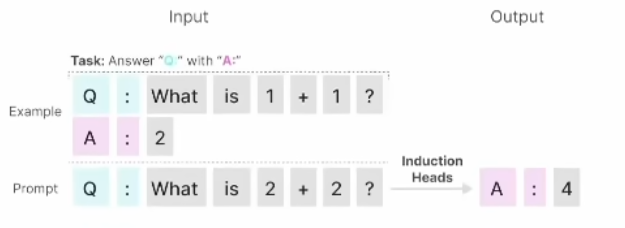
二是上下文联想/推理能力(诱导头任务)。在处理连续的信息时,能够保持逻辑一致
性和上下文的连贯性。比如下图的回答能力,只用了单样本学习。
这就像我们经常说一个人口才好,又能抓住重点,逻辑性又强
那具体怎么改进呢?当然还是在 SSM 基础上。前面我们说过,原来的 SSM 有个 LTI线性时不变系统的强假设(ABC是固定的),这样就导致难以有效的选择上下文信息。以下图为例,甭管输入x是啥,B自岿然不动,这不行,得想办法让它时变。
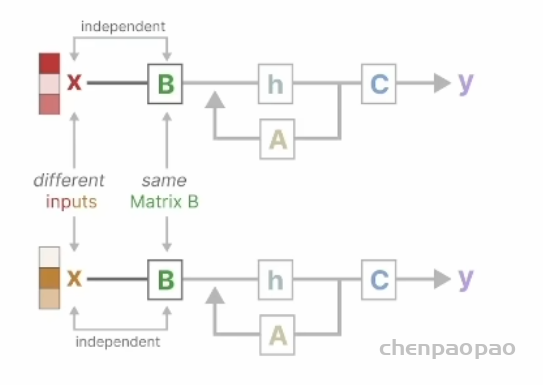
前面的全局卷积虽然能用不同的卷积核进行时序特征捕捉,但是缺乏内容感知,也就是不知道输入的重点和逻辑。而 transformer 人家本身是没有这些限制的,别说时不变,连线性系统假设都没有。这么一分析,改进的方向就很明确了哈。放开LTI模型的时不变约束,让模型参数依赖于输入内容不就行了吗?说起来简单,具体看看是怎么实现的。
2.怎么增加选择性
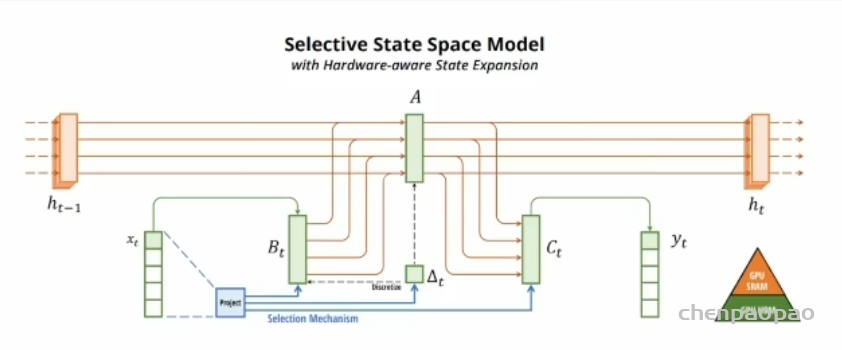
说穿了就是让 B和C由固定的变成了可变的,根据输入xt和它的压缩投影学习可变参数。A为了简化,自身还是不变的。蓝色部分(包括投影及其连线)就是所谓的选择机制,目的是根据输入内容选择性地记忆和处理信息,从而提高对复杂序列数据的适应能力。你看,这个思想是不是像极了LSTM,就是增加开关。
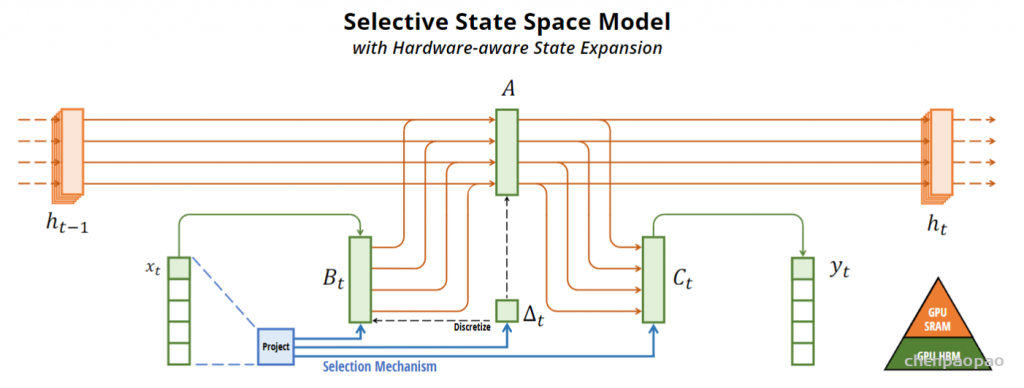
所谓的选择,其实人话理解,就是“掺和”。一次不够,用三条线给 B_t掺和了三次,给Ct掺和了两次,给A掺和了两次,看下面的算法因为函数 \tau 是非线性激活函数因此 delta 是非线性的,所以 ABC 都是非线性时变的,整个系统两个条件都放开了加了几个开关,多接了几条水管子。
(画图)演示
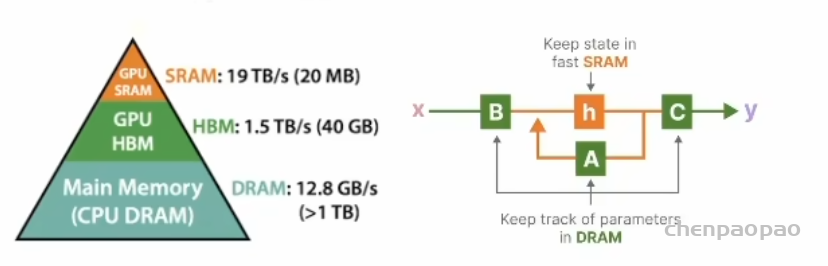
这里面的 deltat是前面离散化计算时的参数,我们刚才讲了。投影出来的三条蓝线其实就是S_B,S_C,S_delta 三个选择函数,共享一个投影模块(Project),主要是为了实现参数共享和计算效率。右边的 GPU SPAM、HBM 我们稍等再解释,主要和硬件实现相关。
来看看算法上是怎么实现的。如下面右图,不难就是分别用三个S函数根据输入把 B/C/delta都变成了时变的,这就是所谓的“掺和“过程,就这么简单。


再打个比方,左边就是直接拿一套固定的配方做菜,不管食材是什么。右边每次不同的食材调整配方,确保做出来的菜更适合当前的食材。你说哪个更香呢?
这么看 Mamba 的思想也不复杂啊,本质上就是拿 LSTM 的门控思想移植到了 SSM 模型上,放开了时不变的约束放成非线性系统。。
注意:这里的 B/L/N/D 符号乍一看让人很困惑,其实就是张量的维度。
B:批次大小(Batch size)。表示一次输入的数据量的大小。
L:序列长度(Sequence length)。表示每个序列中包含的时间步数。
N:特征维度(Feature dimension)。表示每个时间步的特征数量
D:输入特征维度(Inputfeature dimension)。
对左边的传统 SSM 模型,参数矩阵长这样,都是静止的
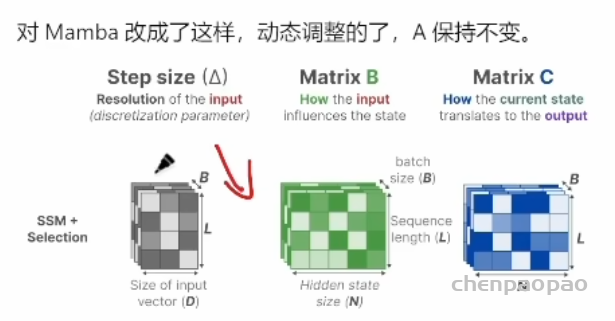
其中步长大小 delta 像是个放大镜观察窗口,影响信息处理的焦点。步长较小时模型倾向于忽略具体的单词,而更多地依赖于之前的上下文信息。你可以简单的认为,就是靠着它,实现了注意力的选择。拿着放大镜忽远忽近的看。
另外,原文没有详细解释这几个选择函数,让人有些困惑。我这里都给你补上了。
SB(x)= LinearN(x),Sc(x)= LinearN(x),都是线性投影,这是种常见的神经网络操作,用于将输入数据转换到一个新的空间或维度。这里的 Linear 表示是用线性层来学习这几个函数。
SΔ(x)= BroadcastD(Linear(x)),广播是一个数组操作,它使得维度较小的数组能
够与维度较大的数组进行算术操作。
Ta= softplus,这是个平滑的非线性函数,通常用于网络中以添加非线性特征并帮助网络学习复杂的模式。
经过这样的优化设计,最终希望达到一个什么样的效果呢?图2给了一个示意图
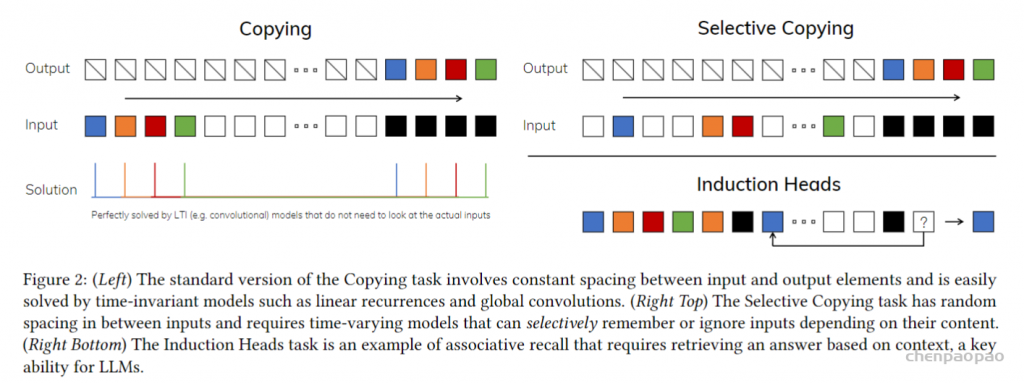
左边是 LTI的效果,输出只能对规则的输入特征进行发现,而右边上面能自己找重了,带色的尽管开始间隔大小不一,但都能找出来排好队。右下是联想能力的体现再看到黑的后就想到以前后面应该跟着蓝色的。也就是说,对于非线性时变数据备了很强的特征捕捉能力。
3.核心原理:流体力学与李指数映射
明白了上面的内容,你只能算是知其然,还没有知其所以然。梗直哥带你从更高角度来理解 Mamba 的精髓,这部分内容的理解其实是哥的发挥,已然超出原文。Transformer 描述的是粒子运动,通过自注意力机制映射动态调整每个输入的权重,类似粒子间通过牛顿力学相互作用力来动态调整自己的轨迹。训练的过程,就是在用牛顿力学拟合粒子轨迹,每个输入(粒子)独立计算与其他输入的关系。
而 Mamba 描述的是流体运动,通过李指数映射来建模时空结构。流体运动描述的是连续介质中的分子集体行为,运动是整体的,内部各点之间有强烈的相互关系和依赖。流体的每个部分都受到整体流体运动的影响,通过内部压力、粘性等因素相互作用。这更符合记忆的本质,因为记忆系统具有连续性、动态变化性和整体关联性,这些特性与流体的性质非常相似。流体模型能够更好地描述记忆中的信息如何相互关联、如何随着时间和新信息的出现进行动态调整和整合李指数映射(Lie exponential map)是一种数学工具,用于描述和分析一个向量场如何沿着另一个向量场发生变化,比如流体力学、电磁场、广义相对论的时空结构等解决了动态系统中相互作用的描述。它是群论和微分几何中重要的概念,来源于李群和李代数的理论,是挪威数学家索菲斯 李引入的。
如果把记忆的流淌比作一个水流管道系统,可以看做一个“李群”,进行各种复杂变换(比如旋转、推移等)。固定矩阵A就是主管道(全局演变路径),类似于流体运动的全局关系,让系统状态更新有固定的全局路径和规则,因此能表现出更高的灵活性和适应性。Bt/Ct就是阀门或旋钮,delta这个离散化因子,就像是流体力学中的时间步长,决定流体运动的离散时间点。选择机制就像是根据具体情况选择和调整旋钮,控制流体在管道中的流动路径。
训练 mamba 的过程就是用李指数映射拟合流体力学动态系统,找到主管道 A,调整阀门和旋钮 Bt、Ct、At,获得最优流体流动路径,让模型能在高维特征空间中进行高效导航和决策。
想象一下:你站在输入 x_t和隐状态 h_t-1构成的向量场中,顺着记忆箭头(h_t-1的更新方向)的方向走,看其他箭头(系统各部分)是如何变化的。这就是流体力学中向量场间的相互作用。
Transformer 的自注意力机制粒子运动强调个体的独立性和动态调整,灵活性高,能动态调整权重,捕捉复杂的上下文依赖关系,但计算复杂度高,资源消耗大。Mamba流体运动强调整体的连续性和全局关系,借用独特的矩阵 A的固定性,提供了稳定性和确定性,通过李指数映射实现高效状态更新和决策。
我噻,绕了这么大一个弯子,其实就是在原来的 RNN 结构上增加了一些类似 LSTM 的门控机制嘛。idea 虽然不难,但难在认知深度是否到位,是否能够举一反三。此外,魔鬼在细节,明白了核心思想,我们接着再来看下。
4.实现细节和网络结构
这部分主要研究如何充分利用 GPU 实现选择性 SSM 的并行计算,也就是前面的图和算法。原文细节很多,大量引用了前人的工作,读起来有些费劲,尤其在没有阅读之前文章的情况下。
简单说,就是努力解决好“既要又要”“的问题,要立又要当立住表现力强的人设需要隐状态维度够大,而要当,速度和内存不能牺牲。为此,提出了三种创新的解决方案:内核融合、并行扫描和重计算。
1)所谓的内核融合:就是把离散化和循环在 GPU SRAM 内存中实现,快然后加载和存储参数 ABC矩阵都用 HBM 高带宽内存。这俩简写对 GPU 不熟的同学可能不知道,其实就是一种分层提升效率的新技术,前者快但内存带宽小,后者慢但是带宽大。这是随着 AI崛起的芯片新技术。
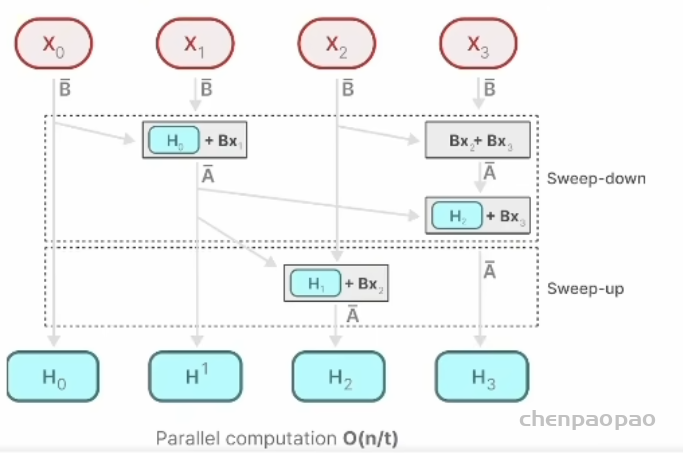
2)并行扫描:这是啥意思呢?本来 SSM 好不容易能用卷积并行运算了,但是放开 LTI假设后又回归 RNN 动态模型,每次 Bt不一样导致并行卷积不行了。Mamba为此做了改进,提出了并行扫描技术,scan 就是操作或处理的意思,
原文基本看不懂到底干了什么怎么实现的,看下图也很难理解。我人话讲下就懂了每个状态 H相当于一个人,看它对应的这条处理线程。自己忙活自己的,吃着碗里看着锅里,当别人的饭做好后,就抢过来用一下,所以某种程度上实现了并行计算。
3)重计算:这步是为了避免存储反向传播所需的中间状态,在输入从 HBM 加载到SRAM 时在反向通道中重计算。这部分的更多细节在附录 D中。简单小结:这部分讲解的就是内存管理、并行计算和动态计算方面的执行细节。开始看不懂不影响整篇文章主体内容的理解。可以先放放。
好,到这里我们总算把 Mamba 的核心原理讲完了,那它的网络结构具体是怎么实现的呢?是不是有点“干呼万唤始出来,犹抱琵琶半遮面”。
“Mamba”这个名字来源于黑曼巴蛇 (Black Mamba),以速度和致命著称。这种命名意在传达该架构的速度、灵活性和高效性,反映出它在处理和转换数据方面的强大能力。其实就是前面 selective SSM 的一种具体实现或者说封装。
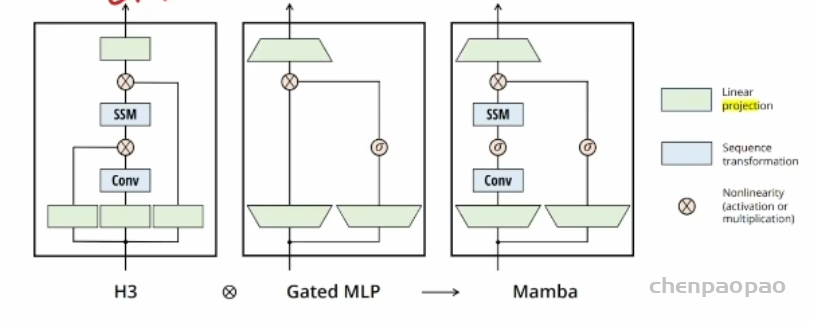
看下面两幅图就都明白了。原文给出的这幅图讲解了它的来源,网络结构延续了 H3 作为标准的 SSM 模型的实现,简单说就是用线性投影+卷积 +SSM,这个只适用于 LTI 系统。现在改成时变系统了,怎么弄,又借鉴了门控 MLP的执行,通过梯形的投影操作实现数据准备。二者合成的 mamba就是右者。除了梯形外,还有激活函数进一步实现非线性。
下图是放大版,看的更清楚,修改了一下它用线性投影实现维度调整,以及部分特征提取与转换,输出时用于数据压缩。增加了卷积层捕捉局部的时间依赖性
Selective ssM(状态空间模型)相当于把时序链条又折叠回去,肚子里包含了sA(x)和 T_Δ。用来捕获更广泛的依赖性,包括长距离的时间依赖性和复杂的内容依赖关系。Silu 函数与算法中的 softplus 函数类似,都是用来增加非线性。其实这个 silu 是工程上人为进一步增加的非线性,增强模型表达力。此外,增加卷积模块是为了捕获局部时空特征。
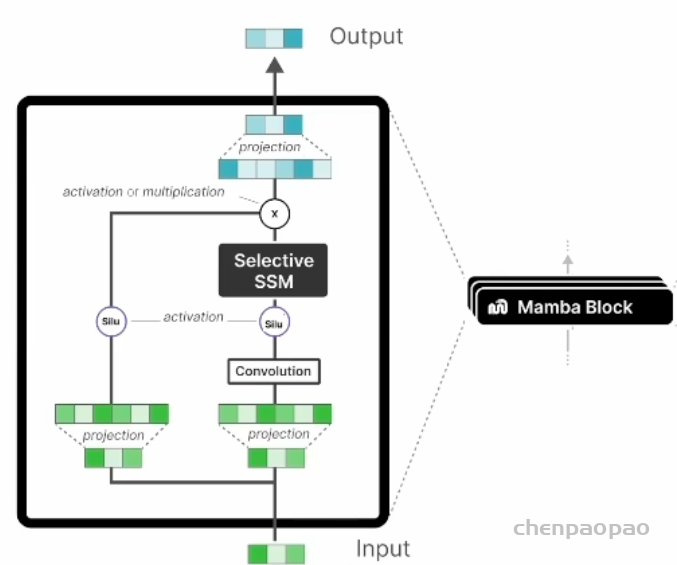
封装后就是一个的模块,如同 transformer 的 decoder 一样可以实现进一步的堆叠,形成大模型。把这个模块和前面的框图对比学习,同时要清楚的意识到哪里是对应的哪些是工程化添加的边角料。当然,这也是为啥再单独起一个名字 Mamba 的原因毕竟和前面讲的 selective ssM 不完全一样了。
到目前为止,我们已经讲完了 3.4 部分,原文 3.5 部分是对上述结构的一些更具体解释,包括在特定情况下,可以退化为类似 RNN 门控机制。再看后面关于选择机制的解释,这篇文章的一大特点就是旁征博引,说实话读起来不太容易,估计很少有人能原汁原味的读懂,大多数都在道听途说或者直接调库拉倒。但真懂了,你的认知绝对不一样。这部分涉及更细的一些内容,不建议一开始一猛子扎太深容易晕,先抓整体逻辑。
接下来看看实验内容。
四、实验
对比 transformer/RNN和Mamba 的训练与推理性能。transformer 训练快推理慢,RNN 训练慢推理快,Mamba结合了二者的优点,都快。实验部分很全面也是一大特点。我们重点看结论。
1.合成任务验证选择机制
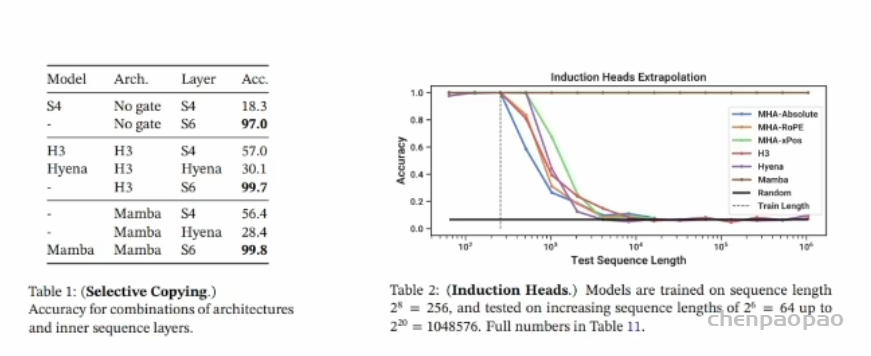
选择性复制任务要求模型能够记住并复制序列中的特定单词。表- Mamba 架构与选择性机制结合后的表现优秀,(S6):准确率为 99.8扩展序列长度任务要求模型看到一个二元组(如“Harry Potter”)时,能够记住“Harry并在序列中再次出现时预测“Potter”。Mamba架构,也就是最上面的棕色线,比其他方法要好两倍。
2、语言模型预训练
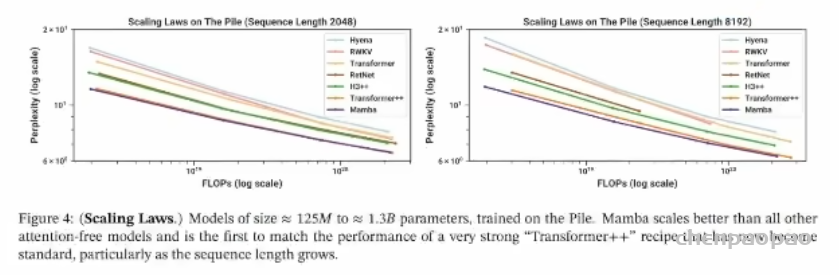
左图是较短右图是较长的序列长度,
对比了不同模型,横轴为 FLOPs 计算复杂度由低到高,纵轴为困惑度 Mamba 模型最低。它是第一个无需注意力机制就能在扩展定律 scaling Laws 上匹敌强大Transformer++模型的架构。
3.DNA 序列
由于大型语言模型的成功,人们开始探索将基础模型范式应用于基因组学。DNA被视为一种由有限词汇组成的离散序列,需要模型处理长程依赖。实验和图表展示了Mamba 架构在 DNA 建模任务中的卓越性能,特别是在处理长序列和扩展模型大小方面。
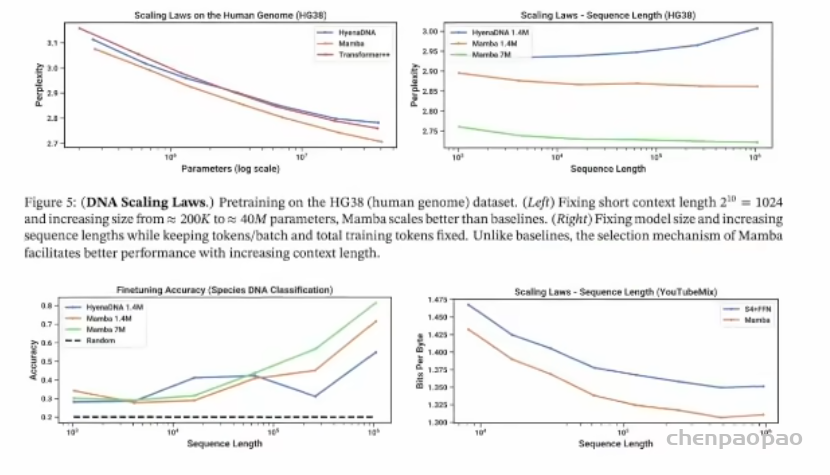
横轴为参数量,纵轴为困惑度。Mamba(橙色线)的困惑度左图随着参数数量的增加(从约 200K 到约 40M)显著下降,右图随着序列长度保持稳定。下面是物种 DNA分类任务的微调准确率和不同数据集上的扩展定律。随序列长度,Mamba性能更好。
4.音频例子
音频波形建模和生成问题也是序列建模任务。
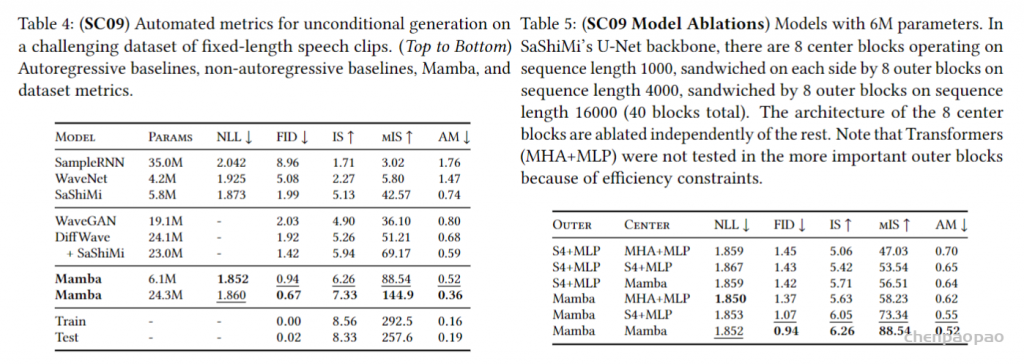
5.训练推理效率分析
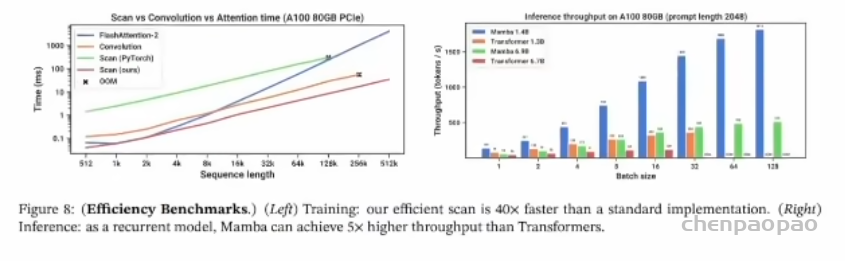
训练效率:Mamba 的扫描实现比标准实现快 40 倍,处理长序列时时间增长最慢(橙线)。对比蓝线,最右边512时,1ms/0.025ms=40倍
·推理效率:Mamba 在推理阶段的吞吐量比Transformers 高5倍,特别是在大批次处理时,显著优于其他模型。蓝色条的高度明显高于其他模型。此外,文章最后还给出了消融实验分析架构。
6.消融实验分析
主要结论包括:
Δ是最重要的参数,其次是B和C的组合使用,这个好理解,选择性主要就靠它来确定几个函数S_B,S_C,S_delta。随机初始化表现较好,复杂初始化效果较差。增大 N(SSM 状态维度)显著改善性能,成本增加微乎其微,但只有在B和C也选择性时才有效。这些发现验证了选择性 SSM 在语言建模任务中的有效性和优势。
五、代码实现
GitHub:https://github.com/state-spaces/mamba

Mamba 类:
主要用于实现选择性状态空间模型(SSM),通过一维卷积和状态更新来处理输入特征。
使用线性投影和激活函数来调整特征维度和计算时间步长。
通过选择性扫描函数来高效地更新状态。
六、小结与探讨
- Transformer注意力机制的窗口小了效果差,大了计算复杂度平方暴涨,的死穴:两难。时序问题空间化出现了瓶颈,单纯的注意力机制有缺陷,并非万能,不是机制本身有问题,而是实现方式。这促使人们思考更换视角。
- SSM 模型:从 LTI连续空间线性时不变系统讲起,类似 RNN 离散化,CNN 并行化,但都没离开线性+参数矩阵时不变两个假设。
- Mamba 原理:提出了选择机制,其实就是时序门控单元。通过离散化函数 delta 这个非线性总开关控制 ABC矩阵三个小旋钮开关,相当于放开了时不变约束,实现时变。与此同时,在选择性 SSM 这个核心模块之外,还通过增加激活函数进一步提升模型表征力,利用卷积层增强空间特征捕捉力。可以认为Mamba=RNN(变形GRU)+CNN+选择性注意力机制
- 思想精髓:流体力学系统+李指数映射+固定矩阵A最优主管道=独特的处理方法
transformer 横行霸道7年了,七年之痒也该到了。凭什么注意力机制就是王者,记忆的问题还用时序解决就不行吗?只不过平衡好时空关系,兼顾准确与效率就可以了。Mamba 的出现让人们看到了一种新的可能,传统模型依然可以重见天日。无数成熟模型,依然可以老当益壮,重上战场,面对大模型的时代再创辉煌。从某种程度上说选择性机制又何尝不是一种注意力机制,这个视角看起来,Mamba 并没有丢掉它,而是换了一种方式结合了时序模型和注意力机制的优势,以另外一种面目示人。RNN 如此,更何况 LSTM 呢!