
Github:https://github.com/state-spaces/mamba
论文:https://arxiv.org/abs/2405.21060

Mamba2 模型再次回归,引发 AI界新的雀跃。它重要性在于很可能开启了一个新的时代,注意力机制2.0时代,由单一注意力机制变成混合注意力机制。人们苦Transformer 这个大语言模型核心模块的硬伤久矣(传统自注意力机制运算效率低),初代的 Mamba 理论上仍然不够完善,所以才会被人诟病。不过,这种争论充分说明了 LLM核心架构的变革已经势在必行。
标题剑指“Transformers 就是 SSM 状态空间模型”,俨然是要做个大一统的工作,气吞山河Generalized models and efficient algorithms 叫法感人,可以想象后续工作会一片一片。
一、重要结论
这次的摘要非常简短,但字少事更大,人狠话不多。三句话三层意思:
1.尽管 Transformers 多年来一直是深度学习在语言建模领域成功的主要架构,但近年来,状态空间模型(SSMs)如 Mamba 已被证明在小到中等规模上能够匹敌甚至超越。人话就是SSM 是新的政治正确!
2.本文展示这些横型家族实际上是密切相关的,可以在一个称为“状态空间对偶“理论框架下连接 SSM 和注意力变体。选择性 SSM 就是一种新的注意力机制,看,这么快就应验了,当然人家牛的是数学上证明了。别死盯着传统的 Transformer 架构了,它的内核其实还是注意力。就像雷达一样,要搞新体制雷达。新型注意力才是正途!但方法并非从 Transformer 侧搞。
3.据此设计的 Mamba-2速度比 Transformers快 2-8倍,而准确率更优。算力昂贵的今天效率将是新模型竞争的重点!
理解整篇文章的核心其实就是这个对偶 duality,我们将围绕着它展开,明白了它也就是彻底搞懂了 Mamba2 的精髓。
二、统一 SSM 和注意力机制(两性话题)
2.1 什么是对偶关系
在数学、物理学乃至哲学中,“对偶性”是指两种看似不同的理论或模型之间存在的一种深层次的等价关系。通过这种对偶关系,可以将一个复杂的问题转化为另一个相对简单的问题来解决,或者在一种表示形式下无法轻易看到的性质在另一种表示形式下变得显而易见。比如太极图就是典型的对偶关系,阴阳对应。
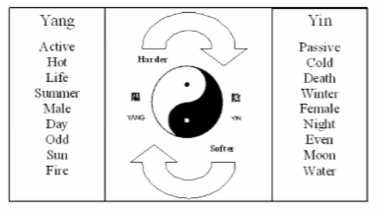
本文提出的状态空间对偶一边是结构化状态空间模型(SSMS),一边是注意力变体,关联方式也就是分界线是具有次平方参数和乘法复杂性的结构化矩阵。
这个理论的基础其实是线性注意力(LA)框架,它也是一种对偶:一边是线性递归神经网络(RNN),一边是传统的自回归注意力机制。也就是刚说的Transformeris RNN.
核心思路就是传统的自回归注意力机制在处理长序列时复杂度较高,而通过对偶关系,可以将其转化为线性 RNN 来处理,从而显著降低计算复杂度。这就好比一个忙碌的咖啡馆,顾客们不断地排队下单。自回归注意力机制传统方法中,咖啡师逐个处理每个订单,计算复杂度随着订单数量增加而成平方增长。通过对偶关系,我们可以转换成一种更高效的处理方法:先收集一批订单根据订单类型(拿铁、卡布等)分类,然后批量制作再分发,这就是线性 RNN 处理长序列数据的思路。
简单总结一句话:阳谋不行咱们来阴谋啊,哪个管用来哪个,效果类似能达到目的就行
既然是在 SSM 和注意力之间进行对偶,我们分别回归一下它们都是啥。
2.2 时空模型 SSM 的本质
2.1洋洋酒酒公式不少,看起来费劲,其实就是在讲下面这幅图,上上期我们分析过。本质上左边就是一个简单的线性时不变系统建模,中间是离散化后的模型就是个RNN,最右边是并行化用卷积核进行处理,也就是 CNN 化的模型。这种表示方式是用图模型来建模,强调的是序列数据之间的依赖关系和动态变化。所谓的 SSM 其实可以理解为就是 RNN,只不过更强调通过线性代数方程来描述系统状态的变化,利用状态空间模型中的状态转移矩阵和观测矩阵来进行建模。也就是下面的两组公式。
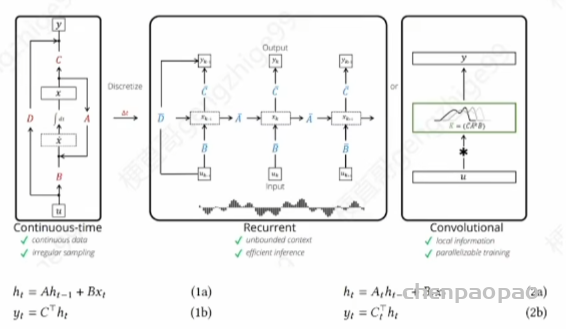
前者 ABC 都是时不变的,后者变成了随时间变化的,也就是 Mamba 模型的工作,放宽了对系数矩阵的约束。因此某种程度上说,SSM 就是线性代数版的RNN,借助线代这个数学工具来更深入的分析 RNN。差分方程进行时序动态建模,CNN能并行化处理,而 ABC 系数矩阵能实现特征空间的结构化分析。
2.3 注意力机制的本质
再来看看注意力机制。本意是给序列中每个位置的元素分配分数,使每个元素能够“关注”序列中的其他元素。前最常见和重要的注意力机制变体是 softmax 自注意力
Y = softmax(QKT).V
其中 QK 成对比较的机制引发了注意力机制的平方训练成本。你看它的本质上就是矩阵运算。这与 SSM(结构化状态空间横型)是一致的,两者在线性代数层面上有很强的关联性,统一分析和优化的视角可以帮助我们更好地理解它们的内部机制,并发现新的改进方法。
以前学深度学习,坦率说 CS 占优势,需要的数学知识不多,代码实现能力强就可以了。但现在的趋势明显不同了,对线性代数等熟悉理论知识的功力要求越来越高,自动化或者应用数学背景的同学优势更加明显。
2.3 怎么实现二者的对偶

例如,Toeplitz 矩阵是指每条对角线上的元素都相同的短阵。Cauchy 矩阵是指每个元素都由两个向量的元素之间的差的倒数来定义的矩阵。Vandermonde 矩阵是由一个向量的幂组成的矩阵。低秩矩阵是指其秩远小于其行或列数的矩阵。类似的特殊结构矩阵,通过压缩表示可以用更少参数和更快算法计算,减少存储需求,加快运算速度,在大规模数据处理和机器学习中尤为重要。SSM 本质上也是一种结构化矩阵。讲到这你明白了吧,这文章就是玩儿线性代数,在注意力机制和 SSM 之间建立统一的对偶关联关系。
那到底是怎么用所谓的结构化矩阵让二者勾连的呢?其实也很简单就是在 SSM 的计算中,特别是矩阵 A,引入了类似注意力机制的公式和方法。
具体来说:
1.简化A矩阵的结构,使其可以用标量乘以单位矩阵表示,从而减少计算复杂度
2.类似 Transformer 中多头注意力的概念,增加了头维度(P)以增强模型的表达能力。
3.使用类似注意力的对偶形式,去除了softmax,并引入了一个额外的掩码矩阵L,根据数据生成,控制信息在时间上的传递量。
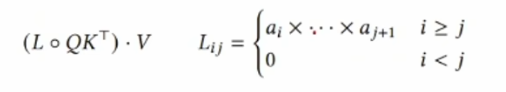
圆圈表示元素相乘,也就是哈德马积。右边的式子有点难懂,给你写成矩阵形式好理解,假设a =[a1, a2, a3]这个 mask 其实就是个下三角矩阵:
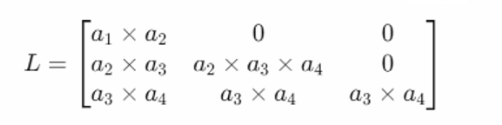
还是看不懂是吧,行标是i,列标是j,i<j 的部分全是零,意味着只考虑时间上早于或同一时间点的元素之间的关系。换句话说,它是一种类似 GPT 模型中的单向注意力机制,只考虑过去的时间步,而不考虑未来的时间步。通过这种下三角矩阵,可以有效地控制信息在时间上的流动,确保信息只能从过去传递到现在,而不能反向传播。
很多人到这里可能会很困惑?为什么这就是对偶啊?明明就是在 A中应用了类似注意力的计算方式嘛!我们打两个比方加深你的理解。如同太极图中的阴阳互补相互转换一样,无论是注意力机制还是 SSM,它们的核心都是处理和更新信息状态,只是方式不同。SSM 像个男人强调逻辑和顺序,注意力机制像个女人本强调细节和关联,对偶就像是二者的结婚,你中有我我中有你,到底是谁干谁也说不清。站在SSM 视角,内嵌了注意力,站在注意力机制的视角,这是新型计算方式。它不是一种简单的内嵌,而是有着数学和功能上的深层联系,这就牛逼了。正如你能说生活不需要技巧,随随便便就能登峰造极吗?
到此,你已经 get了本文的核心思想,来看看它的组织结构。
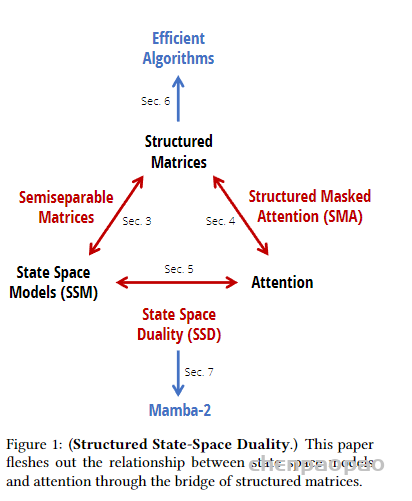
这张图乍一看是一脸惜逼的,不过借用刚才打的比方让你秒懂。SSM 是个男的,Attention 是个女的,SSD 是二者的对偶就是性生活,这种结合不仅仅是表面的叠加,而是深层次的融合。那我问你 Mamba-2是啥?造人生娃啊!通过深层次结合,达到最佳的计算效果和性能。上边的 Structured Matrices 就是爱爱的结品,受孕的胚胎,叫结构化矩阵,它能带来更加高效的算法。
到目前为止,我们讲完了原文1和2部分的内容,接下来正如上图所示,分别详细讲述几条边。首先是 SSM 如何生成结构化短阵,也就是这个所谓的半可分矩阵。
三、SSM 矩阵的巧妙设计(MAN)
半可分矩阵对应原文第3部分,充斥大量线性代数定理推导,读起来基础不扎实那是相当的费劲。人话总结归纳,其实说穿了就是两层意思:一是 SSM 可以表示为 y=Mx 的形式,其中 M 是 ABC 的表达式:二是 M 具有专门设计的半可分结构,能简化运算。
3.1 SSM的表达式

原来的 RNN 也好,时序系统也好,可以卷积化,写成y=Mx的形式。这里的M 是什么就有讲
头了。
3.2 顺序半可分矩阵 SSS
对矩阵 M 专门设计,可以实现更高效的计算。看图一目了然

首先是序列化的,其次是下三角的,第三是低秩的。顺序半可分矩阵(sss,SequentiallySemiseparable Structure)的原因是:半指主要关注下三角部分,可分指的是每个蓝色小块的秩较小,不超过N,意味着可以用更少的独立成分表示,从而实现高效计算。 y=SSS(A, B,C)·x
而定理 3.5指出,人话状态空间模型 SSM,如果状态的维度为 N,等价于一个秩为 N 的SSS
绕来绕去,就是说任何 SSM 其实都可以转写成一个等价的局部下对角阵M 的形式。
SSM 是一个整体的框架,用于处理输入x并生成输出y,如果把它类比为一个男人,那么 M短阵在其中起到核心作用。提升了计算效率。
比如来个更特别的,让秩 N=1,就是 M=1SS

归纳起来,到目前为止,和 Mamba 初代的区别在于两个:
一是在 A 矩阵的计算中嵌入了注意力公式;
二是让 M 矩阵设计为顺序半可分的形式;
说到底,都是在设计更为机巧特殊的矩阵结构,也就是我们先前所说的阀门结构,从而能更好的控制记忆的流淌融合,也是一种新型注意力机制的体现。这里没有说清楚A和M之间的关系,其实是A设计成了半可分,也就是下对角阵的形式,然后M继承了过来,而BC 没变
3.3 张量收缩下的 SSM 计算
这部分写的堪称混乱,不过说穿了就一句话:SSS 的计算过程可以被看作是一系列张量收缩操作,借助顺序半可分矩阵的特殊结构能实现高效计算。理论上,所有 SSM 的计算都可以通过这种方式优化,从而在处理大规模数据时显著提高计算效率。具体来说,可以分解为三个步球:

我们知道,张虽收缩是矩阵乘法的扩展,允许处理更高维的张量,并进行复杂的维度变换和求和操作。使用诸如 NumPy 的 einsum 函数(爱因斯坦求和约定),可以方便地实现这种操作。如下图所示
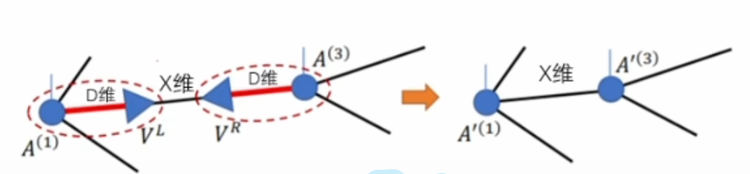
三个步骤第一步将输入矩阵X 与矩阵 B 进行结合,以产生一个中间结果 Z。矩阵A没有出现,它体现在第二步因状态更新中,L的定义依赖于 A。第三步是最终输出。
讲完了 SSM 并行化时矩阵 M的形式进行了哪些机巧设计,以及张量收缩视角下的 SSM 计算。再来看看注意力机制怎么也能统一到同样的框架下。
四、注意力机制的通用实现(WOMAN)
这部分原文写的比较啰嗦,让人有点晕头转向。梗直哥把其表达的意思用人话翻译帮你理解
4.1 张量收缩视角下注意力计算
简单说,就是换一种视角,把不同注意力机制的计算一般化,用更加通用的形式来描述,具体来说,就是站到张虽收缩的视角来看,纳入一个统一的框架
比如,常见的注意力计算形式如下:
Q=input (T,N)
K=input (S,N)
V =input(S,P)
G =QKT(T, S)
M=f(G)(T,S)
Y= GV(T,P)
这里的S 和 T 代表源序列和目标序列的长度,N 代表特征维度,P 代表头部维度,最常见的 softmax 这里用f来更一般化的表示。自注意力机制比较简单,就是源序列和目标序列相同S=T,特征维度和头部维度相同 N=P。4.1.1-4.1.3:主要是回顾和总结已有的注意力机制和方法,没有啥新内容。
4.1.4 回顾了矩阵 A 中嵌入注意力机制的掩码注意力
y=(L°(QKT))·V
所有的这些计算方式都可以写成张量收缩的形式,也就是矩阵乘法的扩展,允许处理更高维的张量,并进行复杂的维度变换和求和操作。使用诸如 NumPy 的 einsum 函数(爱因斯坦求和约定),可以方便地实现这种操作。
Y = contract(TN, SN, SP, TS → TP)(Q, K, V, L)
其中还可以进一步拆解成多步收缩,可以更高效地实现注意力机制,提升计算效率。
G= contract(TN, SN → TS)(Q,K)
M = contract(Ts,TS → TS)(G, L)
Y= contract(TS, SP → TP)(M, V)
(T,S)(T,S)(T,P)
也就是先计算相似性矩阵 G=QK^T,应用掩码矩阵L后得到新的相似性矩阵
然后再计算最终的输出 Y=MV,后面对应的是相应的维度。归纳来说,用张量收缩来实现,使得注意力机制的计算过程更加清晰和高效。
4.2 线性注意力
线性注意力及其他许多高效注意力变种,通常通过改变矩阵关联的顺序来实现,例如(OKT)V=Q(KTV).
具体来说,它将标准注意力中的复杂计算简化为累加和操作,从而提高了计算效率。
Y=Q·cumsum(KTV)
同时可以证明它一样可以用张量收缩表达
4.3 结构化掩码注意力
结构化掩码注意力是结合了结构化矩阵和掩码注意力,更加高效的计算方式,用张量收缩来实现:
Z= contract(SP,SN → SPN)(V,K) (S,P,N)
H = contract(TS, SPN → TPN)(L,Z) (T,P,N)
Y = contract(TN, TPN → TP)(Q, H) (T,P)
第一步为扩展操作V和K运算,然后是线性部分计算(L,Z),然后是收缩操作。
如下图所示不同的掩码矩阵(如因果掩码、衰减掩码、Toeplitz 矩阵等)L定义了不同的序列变换矩阵 M,从而实现不同形式的结构化注意力。
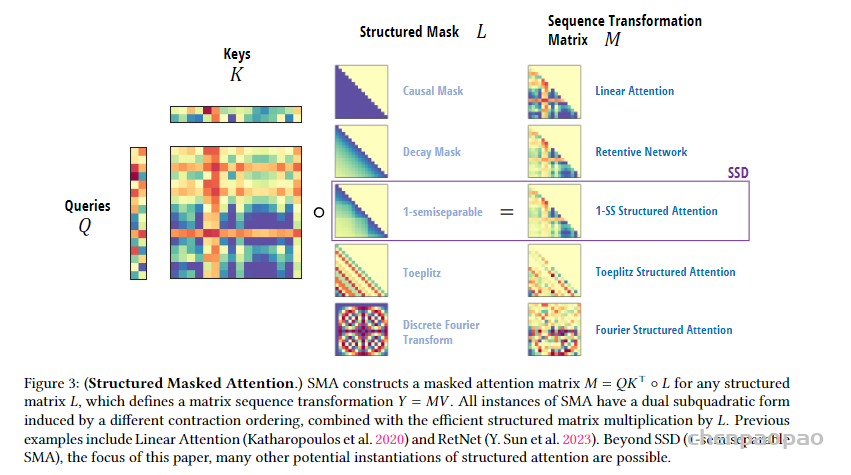
如同前面类比 SSM 为男人,SSS为精子,这里不同的注意力机制就像是女人,而structuredmasked attention,SMA 就像是卵子
对比公式 15 和公式8,陡然之间发现他们一样,说明无论是从状态空间模型(SSM)侧,还是从注意力机制侧来看,都可以统一到张量收缩的视角下进行操作。还是借用人类的比方类比,张虽收缩就如同生殖过程,或者说遗传生物学,对男人女人都是类似的,都遵循着同样的DNA 遗传信息传递。
五、状态空间的对偶性(SEX)
原文第 5部分用一个简单的例子进一步验证了状态空间的对偶性。首先,从 SSM 侧来看,假设Aj是个标量,那么SSM的矩阵M为:

而这正是二次掩码核注意力定义的原始定义。换句话说标量结构下的SSM,通过明确写出M的矩阵形式,然后执行二次矩阵-向虽乘法来计算输出,本质上是在执行与二次掩码核注意力相同的计算步骤。这意味着从计算角度来看,二者是等价的,可以相互转换。在特定情况下,SSM 的计算方式可以视为一种注意力机制,特别是当我们使用标星结构和半可分矩阵时。
反之,从注意力机制侧看,当掩码矩阵 LLL 具有特定的结构时(如因果掩码或1-半可分矩阵),注意力机制的计算可以视为 SSM 的计算。
这种关系从图4看的更加清楚:
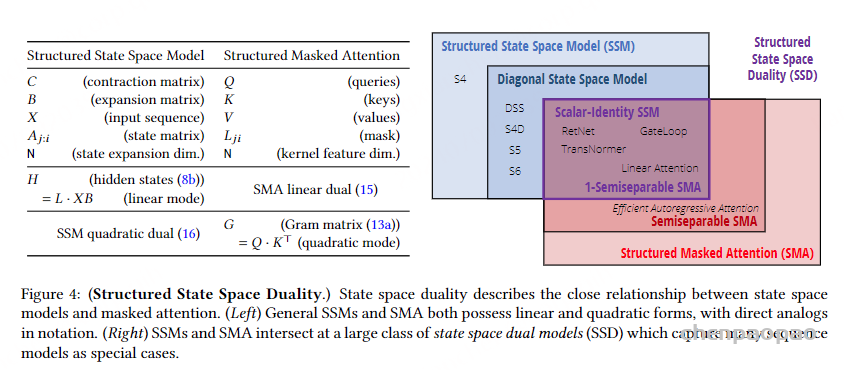
核心思想:SSM 和 SMA在很多情况下是等价的,可以通过相同的数学操作实现。这种等价性为理解和实现这些模型提供了统一的视角和方法。无论是在状态空间模型还是注意力机制的应用中,都可以利用这种统一视角来选择最合适的计算方法,从而提高模型的效率和效果。图中显示了一大类的状态空间双重模型(SSD),这些模型捕捉了许多序列模型的特性。特别的,1-半可分 SMA 和标量恒等 SSM 在这一交集中。交集部分确实可以看作是不同模型(SSM 和SMA)结合后的统一体,就像结婚后的一家人,不再分你我。
六、算法示例(造人)
6.1 算法原理
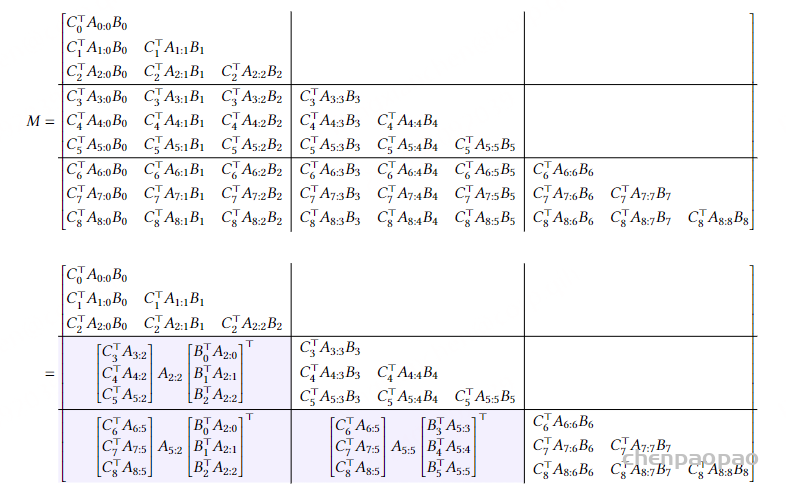
既然 SSM 和注意力机制两种对偶等价,结合起来进行计算效率显然更高,如同男女搭配干活不累,你中有我,我中有你。整体上是SSM,但是通过块分解把大矩阵拆解成小的子矩阵每个小问题特别是低秩块,再用注意力机制计算,利用矩阵乘法上的高效性和并行计算能力使得计算过程更加高效。如下图所示,一个大的M矩阵,分解成9块,其中蓝色块用矩阵乘法。
整个计算过程如下图所示。半可分矩阵 MMM 被分解成多个子矩阵块,包括对角块(Diagonal Block)和低秩块(Low-Rank Block)。前者表示输入到输出的计算,后者被进步分成三类:从输入到状态(Input-State),从状态到状态(State- State)从状态到输出(State – Output)
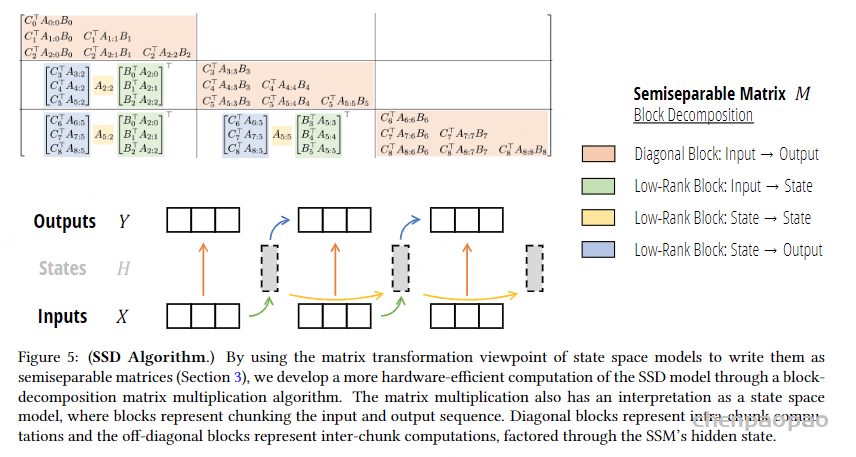
图的下半部分展示了通过这种块分解方法进行计算的流程。输入序列 X 被分解成多个块,每个块对应图中的一个黑色虚线框。输入块通过低秩块(绿色箭头)和对角块(色箭头)进行计算,得到中间的状态块 H。状态块之间通过低秩块(黄色箭头)进行计算,表示状态间的传递。最终,状态块通过对角块(蓝色箭头)计算得到输出块Y。
通过这种块分解方法,可以将一个大规模矩阵运算问题分解成多个小规模的块级别运算问题,每个块可以独立进行计算。这种方法利用了半可分短阵的低秩特性,减少了计算复杂度,同时提高了并行计算能力,使得计算过程更加硬件友好。
6.2代码实现
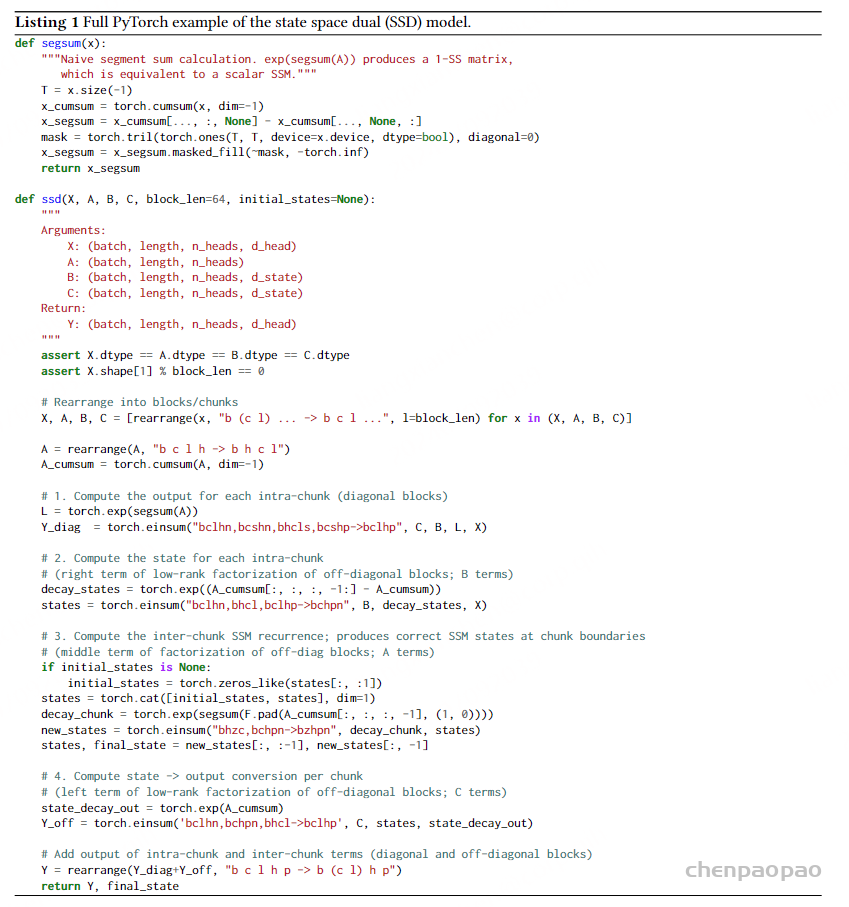
segsum(x): 是一个辅助函数,用于计算分段累加和。ssd(X,A,B,C,block len=64,initial states=None): 这是主函数,用于计算 SSD 模型A,B,C:分别表示状态短阵、扩展短阵和收缩矩阵先对输入张量 X、A、B 和 C 进行重排,将它们重排成块的形式。
1.对每个块内的对角块(Diagonal Block)进行计算,使用 torch.einsum 计算块内的矩阵来法。
2.计算每个块内的低秩块(Low-Rank Block),用于生成下一个块的输入状态。
3.生成块间的状态转移,确保在块边界处的状态正确。
4.对块内的低秩块进行计算,将状态转换为输出。最后将块内和块间的输出汇总,得到最终输出Y和最终状态final state。该代码的主要目的是通过块分解的方法,将一个大规模的状态空间模型问题分解成多个小规模的块级别运算问题。这种方法利用了半可分矩阵的特性,能够提高计算效率和并行性,适合硬件加速。
七、Mamba2 网络架构(KIDS)
7.1 多种设计
Mamba-1基于SSM(状态空间模型)设计,线性投影之后生成SSM参数 A,B,C。Mamba-2的两种块设计:顺序 Mamba块和并行 Mamba块。SSM 层从 A,X,B,C直接映射到输出Y,前者在序列变换中并行生成参数 A,B.C,后者在块开始时并行生成,适合更大规模的并行处理。这种方法类似于标准注意力架构中的并行生成 Q.K,V。这种设计减少参数数量,适合更大模型的张量并行计算。每个 Mamba 块中增加额外归一化层,改善模型稳定性,尤其是大模型。总体来说,Mamba-2模型通过并行化和增加归一化层来优化原始 Mamba 模型的计算效率和稳定性。

7.2 并行化处理方法
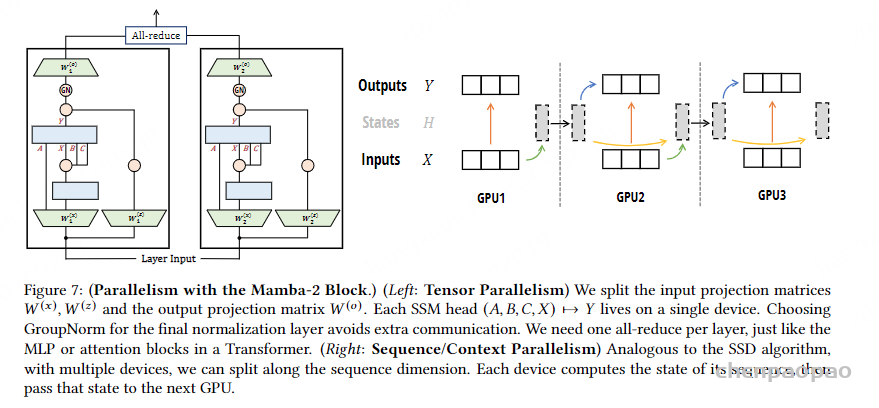
主要分为两种类型:张量并行(TensorParallelism)和序列/上下文并行(Sequence/ContextParallelism)。如下图所示,左边输入和输出投影矩阵分割,并在单个设备上处理。每个SSM头(即 A、B、C、X)到Y 的映射都在单个设备上进行。最终归一化层选择 GroupNorm,以避免额外的通信。右图将序列维度上的计算分配到多个设备上,每个设备负责一部分序列的计算,然后将结果传递给下一个设备。
八、实验验证
8.1合成记忆任务
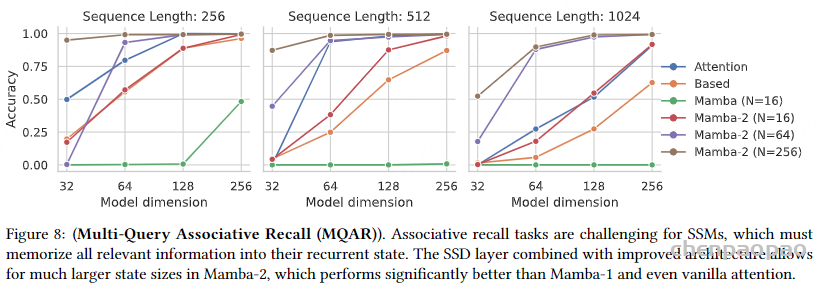
上图展示了不同模型在多查询关联记忆(MQAR)任务中的表现。三张子图对应不同的序列长度(256、512、1024)。横轴代表模型的维度(32、64、128、256)纵轴代表准确率(从0到 1)Mamba-2 系列模型在较大的模型维度下表现优异,特别是当维度达到 128 和 256 时,其准确率接近 1.0。Mamba-2 模型明显优于 Mamba-1 和普通注意力模型,尤其在更大的状态规模(N=256)下表现尤为显著。
8.2语言模型预训练与评估
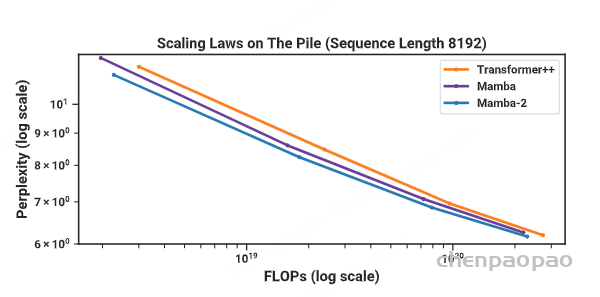
(缩放定律)在 The Pile 上进行训练的模型,Mamba-2的性能匹配或超过了 Mamba 和强大的“Transformer++”方案。与我们的 Transformer基线相比,Mamba-2 在性能(困惑度)、理论 FLOPs 和实际壁钟时间上都是帕累托占优的。
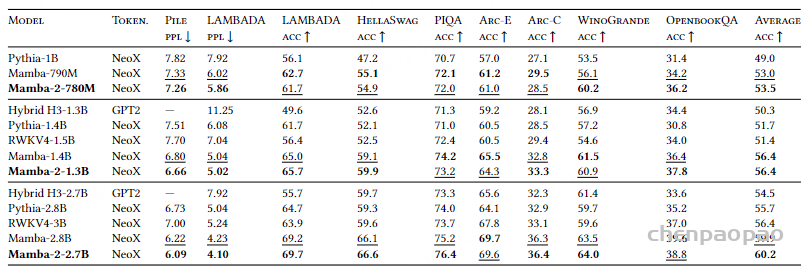
零样本评估:在每种模型规模中,Mamba-2 模型的表现普遍优于其他模型。特别是Mamba-2 在较大的模型规模下(2.78 参数)表现尤为突出,证明其在不同任务上的泛化能力更强。
不同数量的注意力层下的困惑度。大约10%的注意力层比例表现最佳。

适量的注意力层可以显著提高模型性能,超过了完全不使用注意力层或完全使用注意力层的情况。
(零样本评估)比较了 SSD、MLP 和注意力层的不同组合方式,在2.78规模上进行评估困惑度(ppl)和准确率(acc)

Mamba-2与注意力层的结合(后4个)在多个任务上的表现优于其他模型组合,显示出更强的泛化能力和任务适应性。
8.3 速度性能
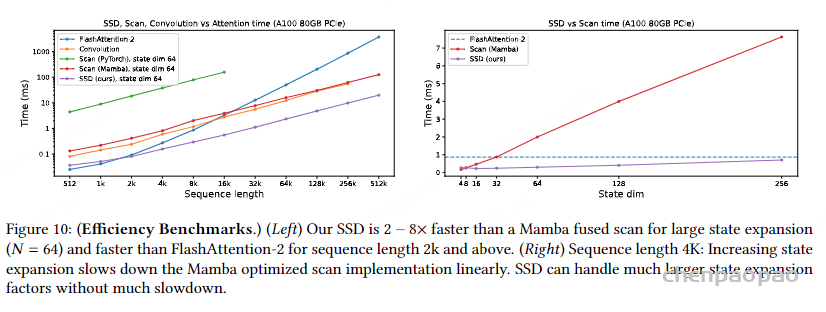
左图不同方法在处理序列长度(从512到512k)时所需的时间(以毫秒为单位)。右图展示了在处理固定序列长度(4K)时,不同状态维度(从16到256)下所需的时间(以毫秒为单位)。SSD 方法在处理大状态扩展时表现优异,比Mamba的融合扫描快2到8倍(比如64k时紫色线1毫秒,Mamba为 10毫秒),并且在序列长度超过2k时也比FlashAttention-2更快。
总体结论:
Mamba-2 模块在结合并行处理和额外归一化后,显著提升了模型性能,表现优于传统的Mamba-1 模块。
多头结构中,复杂的头组合和状态扩展通常可以提高性能,特别是当型规模增大时。
对于核近似,Swish和LayerNorm 方法通常效果较好,且适用于不同规模的模型·增加复杂度和头的数虽一般有助于提高模型性能,但需要权衡参数数呈的增加。
九、小结
1.统一的理论框架:将 SSM 和注意力机制在张量收缩视角下实现统一,并建立对偶性关联无疑是本文最大的贡献。这意味着注意力机制与 RNN两种网络在底层逻辑上被关联起来了打破了男人和女人的界限,实现了灵活的性别转换。
新型注意力机制:借助 SSM 时空建模,实现创新。从男人的视角研究女人,而线性代数要在注意力机制创新中起到越来越重要的关键性作用。
3.混合模型成为新的趋势。整体 SSM,局部注意力机制,实现灵活组合,提升整体性能。
如果今天的分享对你有所帮助,欢迎三连支持。我是直哥。学好AI不迷路。只说人话,专治好奇。