
论文:
- SeACo-Paraformer: A Non-Autoregressive ASR System with Flexible and Effective Hotword Customization Ability
- FunASR: A Fundamental End-to-End Speech Recognition Toolkit
模型:
在使用语音识别服务进行语音转文字的过程中,大多数情况下模型能正确地预测高频词汇,但是对诸如人名地名、命名实体等词频较低或与用户强相关的词汇,模型往往会识别为一个发音相近的其他结果,这使得语音识别模型在日常生活中、垂直领域落地时并不完美。
contextual_paraformer模型
论文:FunASR: A Fundamental End-to-End Speech Recognition Toolkit
NN热词定制化–CLAS
如何能够利用神经网络的建模与拟合能力,将用户自定义的热词纳入端到端语音识别模型的解码过程中,输出热词定制化的识别结果是ASR领域多年来备受关注的问题之一。在2018年,Google提出了Contextual Listen, Attend and Spell (CLAS)框架,在LAS这一经典的E2E ASR模型中进行了基于神经网络的热词定制化。CLAS主要通过两个核心思想进行热词建模:1.在训练阶段从label中随机采样文本片段模拟热词;2.在decoder的建模中引入额外的attention以建立文本隐状态与热词embedding的注意力连接;后续大量的工作证明了CLAS方案的有效性,在近几年出现了CPP-Network,NAM,Col-Dec CIF,Contextual RNN-T等等基于不同ASR基础框架的热词定制化工作,其算法核心均与上述两点一致。在对通义实验室自研的非自回归端到端语音识别模型Paraformer进行NN热词定制化支持时,我们首先采用了结合CLAS算法的方案,开源了工业级Contextual-Paraformer模型,有很强的热词召回能力。
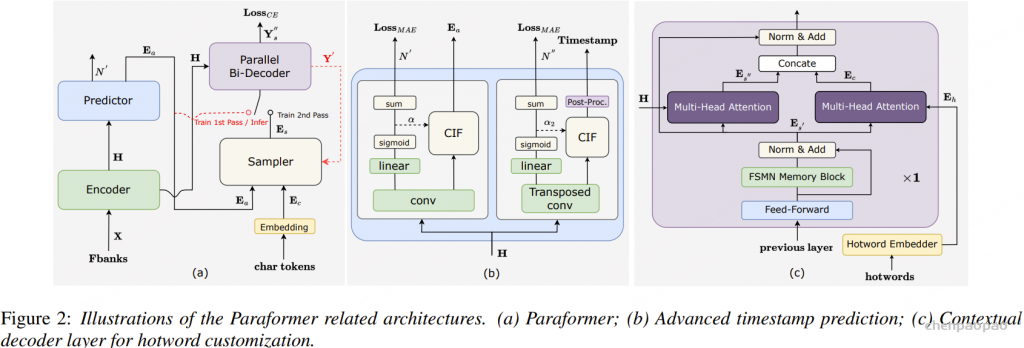
如图2(a)所示。Paraformer是一个单步非自回归(NAR)模型,结合了基于语言模型的快速采样模块,以增强NAR解码器捕捉标记之间依赖关系的能力。
Paraformer由两个核心模块组成:预测器和采样器。预测器模块用于生成声学嵌入,捕捉输入语音信号中的信息。在训练过程中,采样器模块通过随机替换标记到声学嵌入中,结合目标嵌入生成语义嵌入。这种方法使得模型能够捕捉不同标记之间的相互依赖关系,并提高模型的整体性能。然而,在推理过程中,采样器模块处于非激活状态,声学嵌入仅通过单次传递输出最终预测结果。这种方法确保了更快的推理时间和更低的延迟。
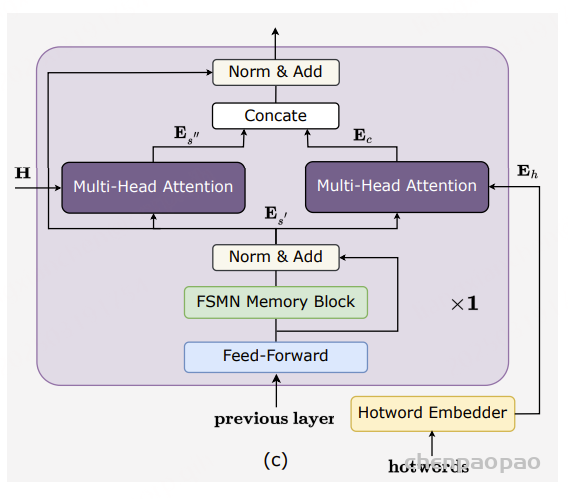
Contextual Paraformer提供了通过利用命名实体自定义热词的功能,从而增强了激励机制,并提高了召回率和准确性。为了扩展基本的Paraformer模型,增加了两个附加模块——热词嵌入器和解码器最后一层的多头注意力,如图2(c)所示。
我们将热词表示为 𝒘 = 𝒘₁, …, 𝒘ₙ,作为输入传递给我们的热词嵌入器 。热词嵌入器由一个嵌入层和一个LSTM层组成,LSTM层接受上下文热词作为输入,并通过使用LSTM的最后状态生成一个嵌入,记作 𝑬𝒉。具体来说,某个热词首先被输入到热词嵌入器中,生成一系列隐藏状态。然后,我们使用最后一个隐藏状态作为热词的嵌入,捕捉输入序列的上下文信息。
- 步骤1:Embedding 层将每个 token 映射为一个密集向量:xi=EmbedLayer(wi)(i=1…n),输出形状:[n × dₑₘ_bₑd]
- 步骤 2:向 LSTM 编码将整个 token 序列输入到一个单向 LSTM(或 GRU)中:hi=LSTM(xi,hi−1)
- 步骤 3:取 LSTM 的最后隐藏状态作为表示:Eh=hn 这是一个固定长度向量(维度 d_h),代表整个热词含义。
为了捕捉热词嵌入 𝑬𝒉 与 FSMN 记忆块最后一层的输出 𝑬𝒔′ 之间的关系,我们采用了多头注意力模块。然后,我们将 𝑬𝒔′ 和上下文注意力 𝑬𝒄 连接起来。此操作在公式中形式化:
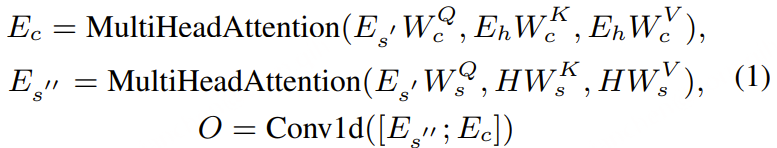
我们使用一维卷积层( Conv1d )来降低其维数以匹配隐藏状态 𝑬𝒔′ ,后者作为后续层的输入。值得注意的是,除了这一修改之外,我们的 Contextual Paraformer 的其他流程与标准 Paraformer 的流程相同。
在训练过程中,热词会在每个训练批次中从目标中随机生成。至于推理,我们可以通过向模型提供命名实体列表来指定热词。
CT-Transformer:
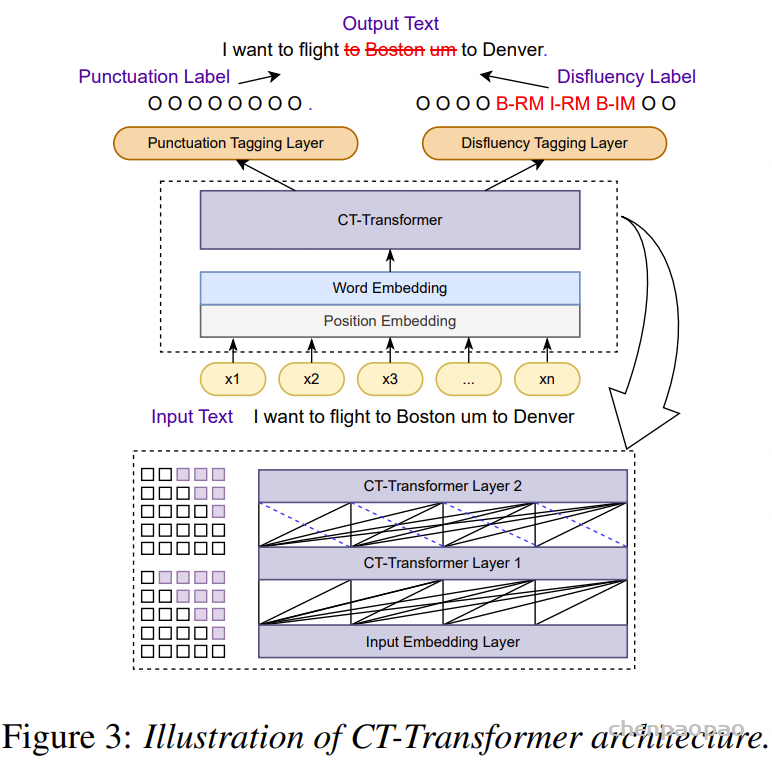
CT‑Transformer 旨在实时联合完成标点预测与非流畅语(disfluency)检测,并通过可控延迟机制确保满足流式输出约束,提升下游应用(如对话系统、翻译)对 Partial Decode 的实时性支持
Controllable Time-delay Transformer是达摩院语音团队提出的高效后处理框架中的标点模块。本项目为中文通用标点模型,模型可以被应用于文本类输入的标点预测,也可应用于语音识别结果的后处理步骤,协助语音识别模块输出具有可读性的文本结果。
Controllable Time-delay Transformer 模型结构如上图所示,由 Embedding、Encoder 和 Predictor 三部分组成。Embedding 是词向量叠加位置向量。Encoder可以采用不同的网络结构,例如self-attention,conformer,SAN-M等。Predictor 预测每个token后的标点类型。
在模型的选择上采用了性能优越的Transformer模型。Transformer模型在获得良好性能的同时,由于模型自身序列化输入等特性,会给系统带来较大时延。常规的Transformer可以看到未来的全部信息,导致标点会依赖很远的未来信息。这会给用户带来一种标点一直在变化刷新,长时间结果不固定的不良感受。基于这一问题,我们创新性的提出了可控时延的Transformer模型(Controllable Time-Delay Transformer, CT-Transformer),在模型性能无损失的情况下,有效控制标点的延时。
CT‑Self‑Attention 的核心目标是:限定每一层可访问的未来 token 数量,从而控制模型的整体延迟。
引入一个控制 mask M,对不允许访问的位置打分为 −∞,得到:
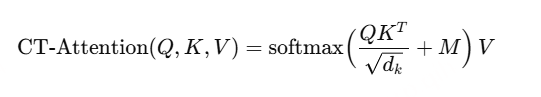
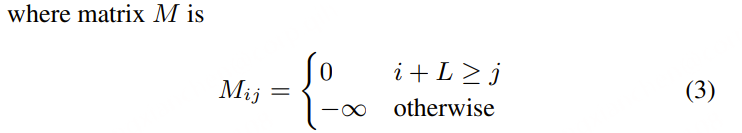
新一代 SeACo-Paraformer 模型
热词定制化 (Hotword Customization)是针对低频偏僻词语识别而出现的语音模型研究。通过基于WFST或神经网络的热词定制化方案,模型允许用户在识别语音时预设一些已知的先验词汇,将识别结果中发音相近的词汇识别或修正为用户预期的结果。本文介绍阿里巴巴通义实验室语音团队自研的新一代基于神经网络的热词定制化模型SeACo-Paraformer(Semantic-Augmented Contextual-Paraformer),较前一代基于CLAS的Contextual-Paraformer有着生效稳定,训练灵活,召回率更高等优势。
WFST热词激励方案从解码过程入手,召回稳定,但是需要在ASR模型推理之外进行基于N-gram的解码,并且对于一些训练数据中出现较少的词,ASR模型提供的后验概率过低,导致候选路径中没有包含待激励的词,此时基于WFST的热词增强大概率失效。
在Contextual-Paraformer开源一年之后,我们进一步开源新一代的NN热词定制化模型SeACo-Paraformer,旨在解决随机初始化CLAS模型生效不稳定的问题,同时进一步提升热词召回率。
SeACo-Paraformer在Paraformer的encoder-predictor-decoder框架中引入了用于热词建模的bias decoder,通过与感知热词位置的label计算loss进行显式的热词预测训练,在解码阶段将热词后验概率与原始ASR后验概率进行加权融合,实现了更加稳定的热词召回。
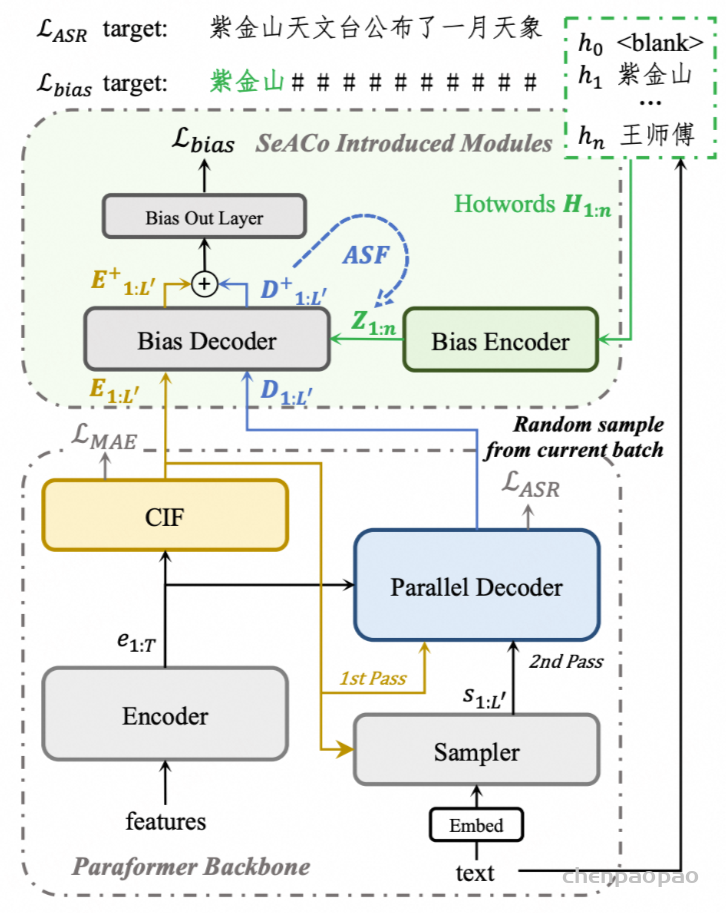
NN热词方案对decoder状态与热词embedding进行attention计算以捕捉相关性,在热词数量上升时attention会由于稀疏问题导致注意力分散,SeACo-Paraformer利用了bias decoder中深层attention的score进行了注意力预计算与筛选(Attention Score Filtering,ASF),实验表明ASF能够缓解热词数量增加导致的召回性能损失。

考虑一个语音特征 x1:T 和对应的文本y1:L,我们在Paraformer推理过程中保留CIF输出 E1:L′ 和并行解码器隐藏状态(在输出层之前)D1:L′:
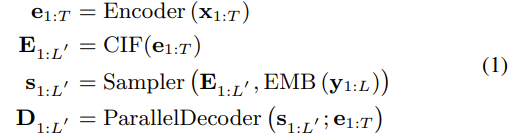
然后,从大小为 bs 的 y1:L 批次中随机采样出 n 个热词,记作 H1:n。我们在这里使用4个超参数来控制采样过程:rb 用于控制批次采样的比例,其他批次的前向传播将使用默认的热词 ⟨blank⟩;ru 类似于rb,但在一个活跃批次内部的发音级别进行控制,活跃批次中平均采样的热词数量为 ru×bs+1(其中一个是默认的热词);lmin 和 lmax 用于控制采样热词的最小和最大长度。
然后,热词列表中的字符序列会通过偏置编码器进行嵌入,偏置编码器包含一个嵌入层(与ASR嵌入共享参数)和一个LSTM层。
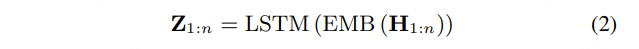
Z1:n∈Rn×d 被去除维度并在第0维度上重复以进行批处理计算。接下来进入SeACo-Paraformer的主要部分。在偏置解码器内部,热词的偏置信息通过注意力机制引入到声学嵌入 E1:L′ 和解码器隐藏状态 D1:L′ 中。

偏置解码器由多个多头注意力层和前馈层组成。通过偏置声学嵌入和偏置解码器隐藏状态,可以通过输出层获得偏置概率 PASR1:L′。需要注意的是,一个额外的标记(计为#,表示无偏)会被添加到ASR输出词汇表中,以标记非热词位置的输出。
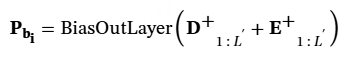
根据偏置概率 Pb1:L′,可以使用热词位置感知准则来更新与偏置相关的参数,其中非热词位置的标签被替换为 #(如图 1 中的 Lbias 所示)。
在冻结经过充分训练的 Paraformer 模型的情况下,我们通过引入偏置输出层、偏置解码器和偏置编码器,并使用随机采样的热词及其对应目标进行训练,使 ASR 系统具备热词上下文化能力。值得注意的是,偏置相关参数的训练是独立于 ASR 训练的,因此可以使用专门的热词数据(例如低频语言短语)和训练策略,而不会影响 ASR 的整体性能。
对于使用给定热词列表进行 SeACo-Paraformer 推理的第 i 步,我们得到语境化 ASR 的最终合并概率为:
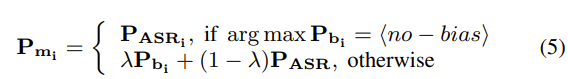
当没有传入热词或未检测到热词时,SeACo-Paraformer仅使用 𝐏ASRi 。 λ 是一个可调参数,用于调整信任偏差解码器输出的程度。
在实际应用中,随着输入的热词数量的扩大,热词激活的性能会相应下降——偏见解码器内的交叉注意很难在 ASR 解码器输出 𝐃1:L′ 和大规模稀疏热词嵌入 𝐙1:n 之间建立正确的联系。为了使 SeACo-Paraformer 能够使用大规模热词列表进行热词定制,我们提出了注意分数过滤(ASF)策略。首先对全热词列表进行偏见解码器推理,得到注意分数矩阵 𝐀∈RL×n ,其中 L 是输出 token 的长度, n 是热词的数量。然后,我们将 L 中各个步骤的分数相加,得到每个热词的注意分数。根据注意分数,我们可以挑选出最活跃的 k 热词,从而进行真正有效的偏见解码器推理。与细粒度的上下文知识选择相比,我们的偏差解码器由多个交叉注意层组成,我们发现最后一层的分数对于过滤最有效。
热词理论上无限制,但为了兼顾性能和效果,建议热词长度不超过10,个数不超过1k,权重1~100