
名词解释:
- 误差累积(error accumulation):指在连续的转录或翻译步骤中,由于前一步骤的错误会在后续步骤中积累,导致最终结果的质量逐渐下降的现象。这种误差累积通常在语音到文本(Automatic Speech Recognition, ASR)系统和文本到文本(机器翻译或文本转写)系统之间的多步骤流程中出现。在这些系统中,声音信号首先被转录成文本,然后文本再被翻译成目标语言或者以其他方式进行处理。如果在转录步骤中出现错误,这些错误将传递到后续步骤,影响最终的翻译或文本转写质量。
- 自回归(Autoregressive):在 E2E ST(End-to-End Speech Translation)模型中,”autoregressive” 表示模型会逐个生成翻译文本的每个词或子词,每次生成都会依赖于前一个时间步生成的内容。这是一种逐步、串行的生成过程。典型的 autoregressive 模型包括循环神经网络(RNN)、长短时记忆网络(LSTM)、和变换器(Transformer)等。
- 早期的语音翻译【Speech-to-text translation (ST)】解决方案是通过级联系统,使用多个子任务进行处理。
- 比如首先通过ASR(Automatic Speech Recognition)系统,将语音转录为文本,然后再使用 MT(Machine Translation)系统将文本翻译为另一种语言。
- 对于这样的级联系统,研究方向主要为解决误差累积(error accumulation)的问题。
- 端到端语音翻译【end-to-end speech translation (E2E ST)】有这样的好处:
- 能够减少误差累积
- 能够减少延迟
- 拥有更多的上下文建模
- 适用于不成文语言
- 基础建模:
- ST 的语料库通常包含语音 s,转义文字 x,以及翻译结果 y
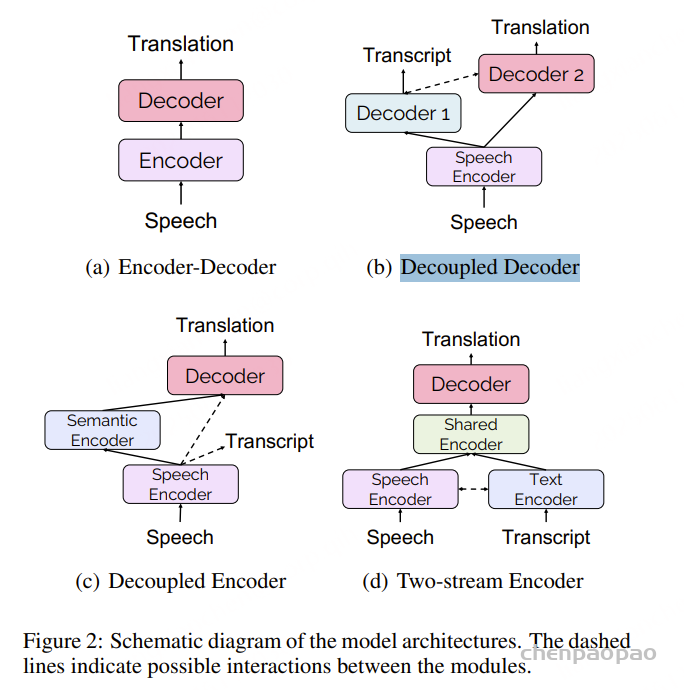
- 基础的 E2E ST 模型框架是基于 Encoder-Decoder 架构的
- 然而,E2E ST 模型的训练并不容易,其效果也只是接近于级联系统的结果,并不是性能最好的技术。
- 目前,E2E ST 模型研究方向主要为:
- 建模负担(Modeling Burden):
- 需要同时处理跨模态(声音到文本)和跨语言(源语言到目标语言)的问题,导致模型建模会很复杂
- 收敛困难,性能较差
- 数据稀缺(Data scarcity):
- ASR、MT 的语料库非常多,且有些非常大
- 但是 ST 的语料库其标注难度较高,因此 ST 的数据很少
- 应用问题(Application issues):
- 需要考虑实际应用中的问题,如实时翻译,长格式音频分割等等。
- 建模负担(Modeling Burden):
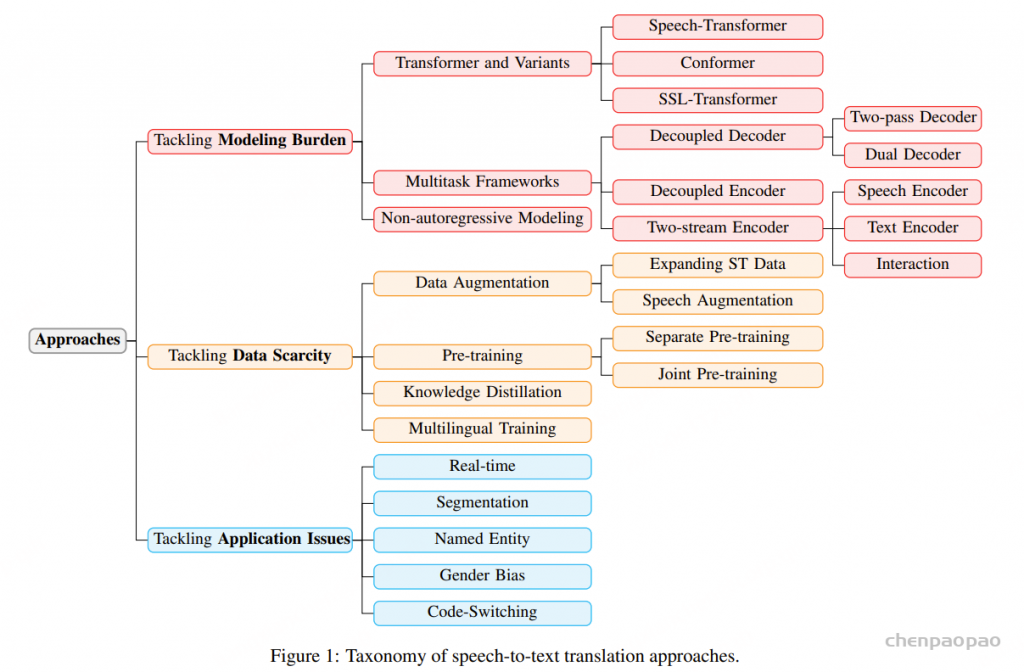
Tackling Modeling Burden:
- 对于语音信号这种长序列输入,我们采用高容量端到端模型,通常是 Transformer及其变种架构。
- 对于建模负担问题,通常采用多任务学习框架,对原始的 Transformer-based 模型进行修改。
- 对解码效率问题,我们采用非自回归模型,从而提高解码速度
Transformer :
Speech-Transformer
- 基于 text-to-text Transformer
- 主要改进点为 acoustic features 在进入自注意力编码器前,首先由卷积层(通常是步长为 2 的两层,将长度压缩 4 倍)压缩,然后再接一个归一化层
Conformer
- 主要改进点在于,在每个 encoder blocks 的 多头自注意力模块 和 前馈层 之间加入了 卷积模块
- 卷积模块包括了注意力和卷积组件,由两个 Macaron-net 风格的前馈层(feed-forward layers)和残差连接(residual connections)所包围。
SSL-Transformer
- 这是一种结合了自监督学习(self-supervised learning,SSL)得到的语音表示模型
- SSL 已经被成功应用到了提取语音特征的任务中去
- SSL-Transformer 主要就是将原始的音频波形输入到自监督学习模型中,通过多个卷积层和编码层的处理,从而提取语音特征。
- SSL-Transformer 模型中,自监督学习模型可以被整合到解码器中:或者作为一个独立的编码器,或者作为一个语音特征提取器,然后与整个 Transformer 模型相连接。
Multitask Frameworks:
针对模型负担的问题,多任务的核心思想是利用一些辅助工具来辅助目标任务的完成。比如ASR和MT。而有些任务模块和辅助模块的参数是可以共享的,这就导致了辅助任务的可行性。目前有三种类型的多任务框架:
Decoupled Decoder(解耦解码器)
额外的解码器用于引导模型学习文本转录(transcript),同时仍然以端到端的方式进行模型训练。主要思想有两种,一种是如何通过生成的文本转录来更好促进翻译,比如采用两遍解码器(two-pass decoder);还有一种是同时生成文本转录和翻译(dual decoder)
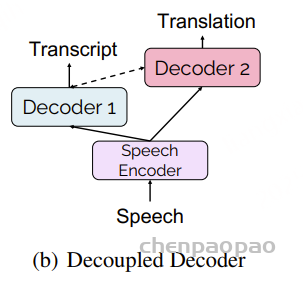
- Two-pass decoder:先将声学特征通过这个Decoder,然后再把转录结果和解码器结果结合起来用于翻译工作。但由于采用的是顺序生成(sequential generation),失去了低延迟的固有优势。因此有人用非自回归方法进行第一段的解码。
- Dual decoder:交互式解码(interactive decoding)使用两个解码器同步生成转录和翻译。与此同时还额外使用了交叉注意力模块(cross-attention module)来为两个解码器交换信息。wait-k 策略(wait-k policy)通过首先预测转录文本的标记,为翻译标记的解码(the decoding of the translation tokens)提供了更多有用的信息。
Decoupled Encoder(解耦编码器)
对于解耦解码器,当遇到多重推理的时候可能会导致设计与延迟问题。更好的解决方案是通过解耦编码器同时识别和理解原始语音输入的语义。因此我们采用下面这张图的方案,共有两个encoder,低级语音编码器首先对来自语音输入的声学信息进行编码,语义编码器进一步学习翻译解码所需的语义表示。
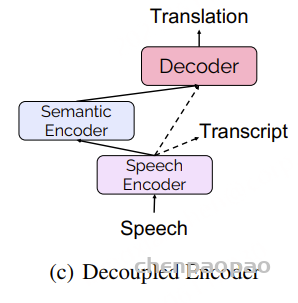
- 编码每个阶段都可以通过转录信息进行监督学习
- 转录也提供了语音的对齐,可以缓解 encoding 负担
Two-stream Encoder(双流编码器)
ASR 的数据可以用来增强组件,那么 MT 的数据也可以吗?在训练过程中,我们可以同时接收语音和文字的输入,其各自有各自的编码器,还有个共享编码器。这个结构通常通过多任务训练损失进行优化,例如用于语音翻译(ST)和机器翻译(MT)的负对数似然(NLL)损失。其中的优势在于,通过与 MT 编码器共享,可以学到更好的语义表示,以提高翻译性能。
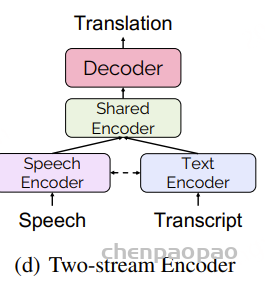
在推断过程中,则是输入语音数据,通过语音编码器,共享编码器,解码器,最终生成翻译后的文本。
- Speech encoder:其需要更有能力单独提取语音输入的声学特征。Wav2vec2 等预训练语音模型可用作语音编码器,以获得更好的 ST 性能
- Text encoder:文本编码器可以是文本嵌入层(text embedding layer)或文本 Transformer 编码器的几层。同时,还可以用语音音素(phoneme)来代替原始转录作为文本输入,这样可以减少两种输入的模态差异。
- Interaction:也有很多语音编码器和文本编码器交互的变种。
- 有使用对比学习法(contrastive learning method)来缩短语音和文字的表达差异的
- 有提出 Chimera model 来将语音和文字表达长度对齐的。
- 还有同时考虑到表达和长度差异,从而在共享编码器后面添加交叉注意力正则化模块(cross-attentive regularization module)的,正则化模块首先通过自注意力或交叉注意力从文本或语音编码器生成两个具有相同长度的重构序列,然后优化重构序列之间的L2距离。
Non-autoregressive Modeling
端到端模型相比于同等级的级联系统大大降低了计算时延,但是这种优势仅在自回归解码的情况下有效,这个技术研究有两条路线:
- 参考自动语音识别(ASR)和机器翻译(MT)任务中的方法,如条件掩码语言模型和重新评分技术,来开发非自回归语音翻译模型。
- 探索更高效的架构,依赖纯粹的CTC(Connectionist Temporal Classification)进行预测,以提高速度。CTC 是一种用于序列标签任务的损失函数,它可以用于训练模型,使其能够将输入序列映射到输出序列。
未来发展:
LLM(Large Language Model)
LLMs 包括 ChatGPT、Bloom等等,它们都有非常强大的能力,那么如何将LLM强大的生成能力融入到 ST 的任务中去,以及如何将语音数据也纳入LLM 的训练中去,是很值得研究的方向。
- 第一步我们可以先优化语音的表示,使得其能够与文本的表示相媲美。
- 伪语言——语音离散表示(speech discrete representations as pseudo-language)就是一个不错的方向。
- 此外,预训练大规模 acoustics-aware LLMs 也是一个很 promising 的方向。
Multimodality(多模态)
人工智能生成的文本、图像、语音、视频等多模态信息爆发,推动了ST领域去探索更加复杂的人机交互(HCI,human-computer interaction)场景的研究,比如交流翻译(speech-to-speech translation),视频翻译等等。
而多模态数据爆炸式的增长也致使在多模态数据上进行上下文学习(ICL,In-Context Learning)也成为了一个很有前途的研究方向,以更好地理解和利用不同模态数据之间的关联,从而实现更准确、更综合的多模态分析和应用。
多模态预训练也被证明在许多领域中都是有效的。
多模态之间的信息交互和关联也有待被发掘,比如视频中角色的语音和同一时间段角色的图像帧、韵律环境(prosodic environments,比如声调,音高,音量,语速,停顿等等,可以传达语言的情感、语气等)之间的关联。