
- 代码:https://github.com/NiniAndy/Paraformer-V2
- 论文:https://arxiv.org/abs/2409.17746
原始 Paraformer 在非自回归语音识别方面取得了显著成效,尤其在普通话任务中表现突出,但其也存在一些局限性,特别是在跨语言适配和噪声鲁棒性方面。
背景:
1. 多语言适配能力有限(Multilingual Limitations)
- CIF 模块难以适应非拼音型语言(如英语):
原始 Paraformer 使用 CIF(Continuous Integrate-and-Fire) 预测每个 token embedding。该机制假设每个语音片段可以通过声学模式推断出输出 token 数量。但英语等语言往往使用 BPE(Byte Pair Encoding) 等子词单元,token 数量波动大、边界不规则,CIF 很难准确预测 token 数。
- 在英语、法语等语言上性能显著下降;
- CIF 在 token 数量估计不准时,会导致对齐错乱、token 重复或丢失。
2、 对噪声敏感(Noise Sensitivity)
- CIF 预测 α 权重完全基于声学表示,不含语义约束:
- 如果输入中含有背景噪声(如会议环境),CIF 模块可能将噪声解释为有意义的语音特征;
- 导致触发 α → β 条件时“错误地触发 token”,产生虚假输出。
- 噪声环境下 WER/CER 明显上升;
- 无语音输入时仍有输出(无法正确“输出空白”)。
3. 训练对目标长度高度敏感
- CIF 模块需预测 token 数量,训练时必须强制调节 α 的归一化,使 token 数接近 ground truth;
- 若目标长度估计不准,Decoder 会收不到足够 token embedding,导致学习不稳定
原始Paraformer:
Encoder 提取帧级表示:

CIF 生成 token embedding:使用 CIF(Continuous Integrate-and-Fire) 模块将帧级特征聚合为 token embedding 序列:

CIF 中权重 α 的生成:
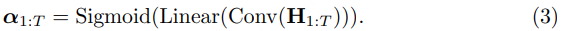
Decoder 并行预测:
为使预测长度 U′U’U′ 尽可能接近 ground truth 长度 UUU,训练时需要对α1:T 做归一化:
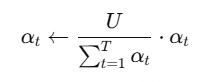
Decoder 并行预测:Decoder 是一个 双向 Transformer
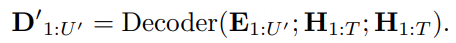
Loss:
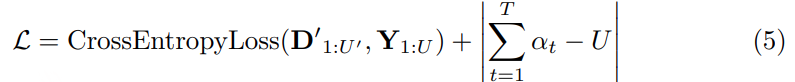
改进:
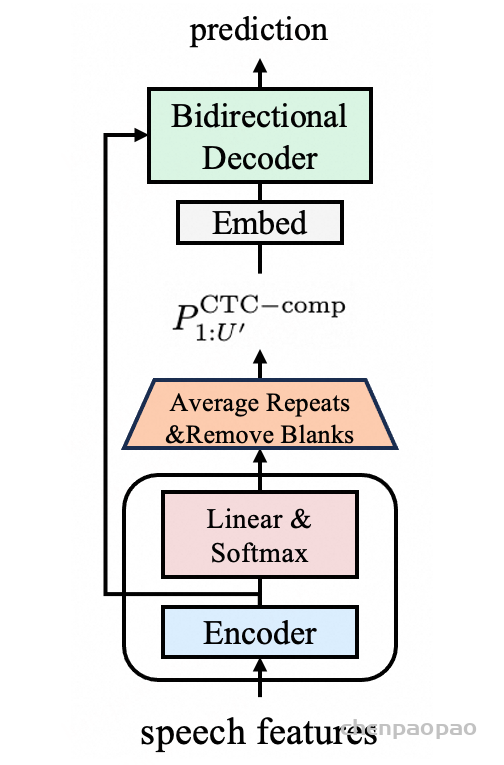
利用 CTC 模块来获取 token embedding,事实证明,该模块具有更好的多语言适应性和更强的抗噪性。
使用 CTC 模块提取 Token Embedding:
生成帧级 posterior:类似于标准 CTC 解码头,对每一帧计算 token 分布(含 blank)
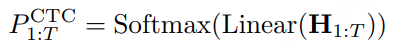
Greedy 解码得到 token 序列:
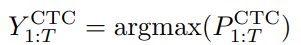
每一帧取最大概率的 token index(可能含 blank 和重复)
压缩 token 序列(Remove blanks & merge repeats):
对重复 token 合并并平均其 posterior,得到 token 数量为 U′U’U′ 的 embedding 概率序列,去除 blank;
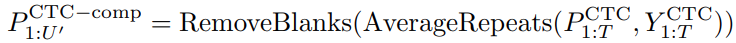
映射为 Token Embedding:
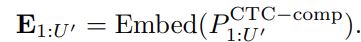
并行 Decoder 解码(Bidirectional):(没有因果掩码(causal mask)限制上下文访问,每个位置的 token 同时关注其左侧和右侧所有位置)
CTC 压缩后的长度 U′U’U′ 和真实 token 长度 UUU 不一致,导致无法直接计算 CE Loss,解决方法:使用 Viterbi 对齐 将 CTC posterior 对齐到 target:
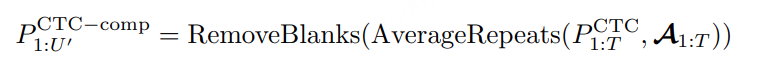
- 其中 A1:T 是 Viterbi 解码得到的帧与 token 的对齐序列;
- 这样生成的压缩 posterior 长度严格等于目标长度 U。
Paraformer-v2 同时优化:
- Decoder 输出与目标之间的 CE Loss;
- Encoder 输出与目标之间的 CTC Loss。
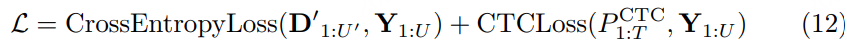
实验结果:
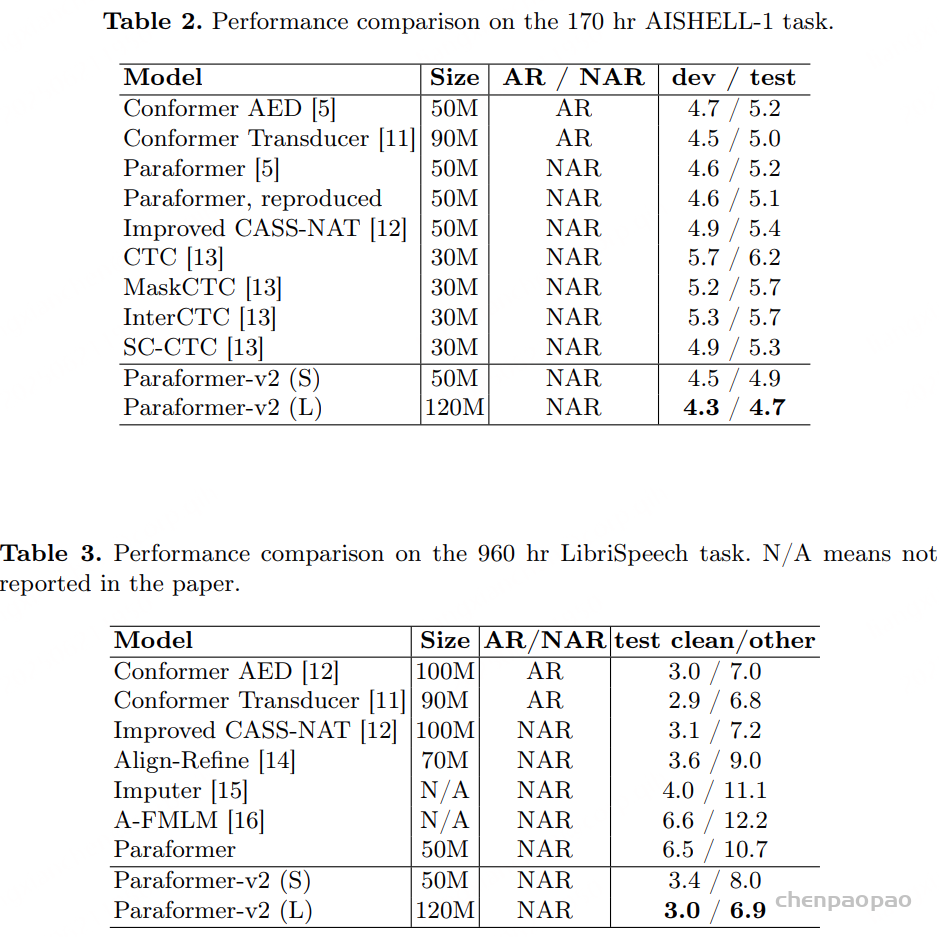
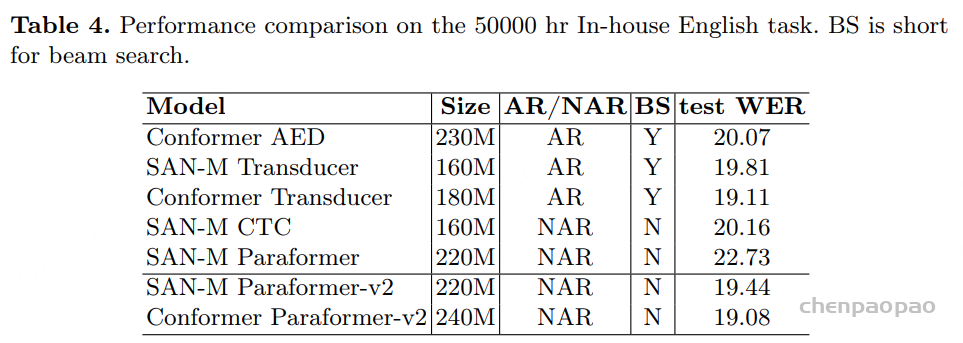
实际训练疑问:
