- GitHub 主页:https://github.com/xiaomi-research/dasheng-lm
- 技术报告:https://github.com/xiaomi-research/dasheng-lm/tree/main/technical_report
首次提出了通过通用字幕进行音频文本对齐的方法,而无需依赖 ASR 或基于声音事件的模型:
- 融合多模态音频描述:首次将语音转录文本、环境声音字幕和音乐字幕统一融合为一个通用的文本描述,打破了传统分别处理三类音频信息的局限。
- 构建丰富语义的整体音频描述:通过统一的多模态文本表达,捕获更全面、更细致的音频场景信息,包括语义细节、环境声学特征等,而非仅仅停留在简单的标签或“有人讲话”等表面描述。
- 促进音频与语言的深度对齐:提升音频理解模型对复杂、多样化音频内容的描述能力,推动声音和文本的跨模态融合与理解。

MiDashengLM-7B 基于 Xiaomi Dasheng 作为音频编码器和 Qwen2.5-Omni-7B Thinker 作为自回归解码器,通过创新的通用音频描述训练策略,实现了对语音、环境声音和音乐的统一理解。
MiDashengLM 完整公开了 77 个数据源的详细配比,技术报告中详细介绍了从音频编码器预训练到指令微调的全流程。
MiDashengLM 集成了 Dasheng —— 一个专为高效处理多样化音频信息而设计的开源音频编码器。与以往主要依赖自动语音识别(ASR)进行音频与文本对齐的方法不同,该策略以通用音频字幕为核心,将语音、声音与音乐信息融合为统一的文本表达,从而能够对复杂音频场景进行整体性描述。
Motivation:
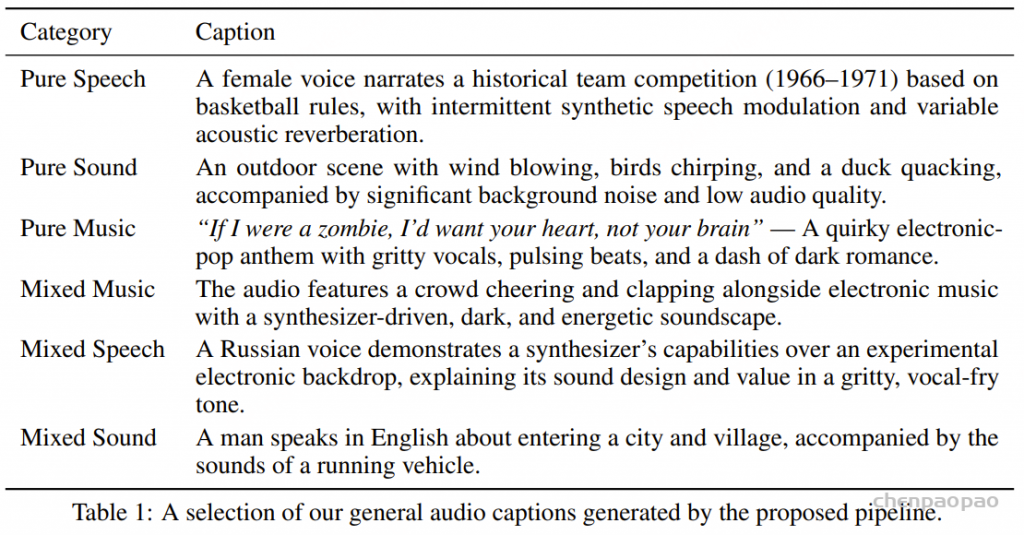
当前的音频理解研究通常将语音转录、音频字幕和音乐字幕分别处理。这种独立处理的方法限制了对听觉场景分析的深度和完整性。另一个关键限制来自现有的音频字幕,这些字幕往往只提供表面性的描述。例如,语音内容常被简化为“有人在说话”,忽略了语义细节。此外,这些数据集通常未能捕捉诸如房间声学特性(如混响)或信号质量等关键听觉要素。
为克服这些限制,本文提出将语音转录、音频字幕和音乐字幕融合为一个统一的通用字幕。我们的目标是构建一个整体的文本表示,联合涵盖所有相关的音频信息,从而提供对听觉环境更为详细且语义丰富的描述。
基于 ASR 的预训练对于一般的音频语言理解而言,其效果有限,原因如下:
- 数据利用效率低:仅使用ASR数据导致大量潜在有价值的数据被丢弃,如音乐、环境噪声,甚至静默片段。
- 目标过于简单:基于文本的训练相比,模型从ASR数据中学到的有意义信息相对较少,型仅需建立局部对应关系,将口语词与文本对应,而无需理解更广泛的(全局)音频上下文。
- 基于ASR预训练的局限性:超越语音内容。基于ASR的预训练主要关注语音内容,忽视了其他信息。这导致重要的语音元信息,如说话者的性别、年龄或情绪状态,无法在预训练过程中被捕获或整合。
Framework
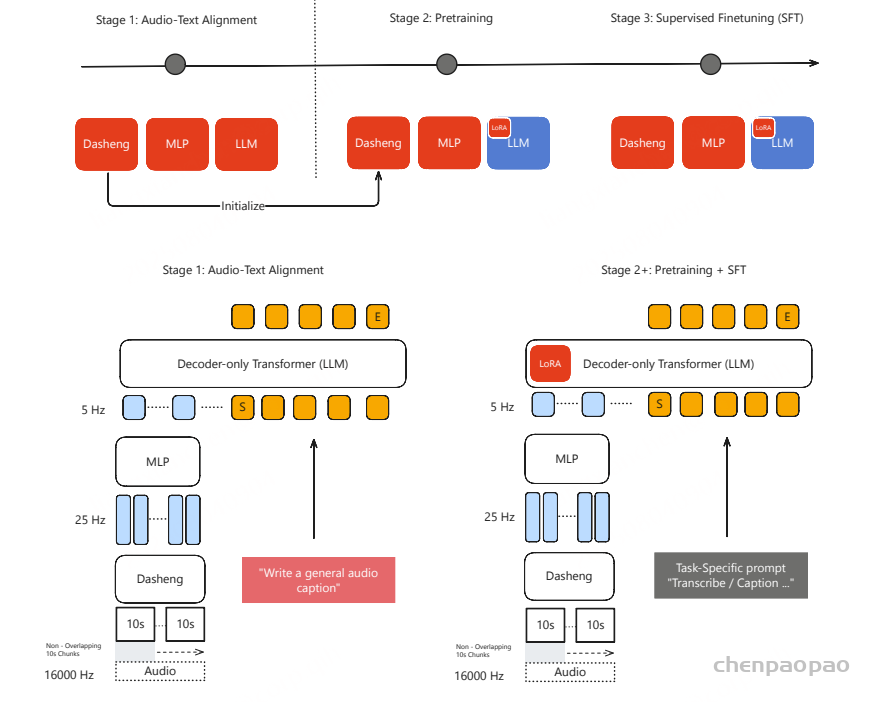
当前,绝大多数工作都使用预训练的音频编码器,本文首次提出了通过通用字幕进行音频文本对齐的方法,而无需依赖 ASR 或基于声音事件的模型。此外,我们仅使用一个能够同时处理语音、声音和音乐的通用音频编码器。
架构设计:基于通用前缀的大型语言模型,通过多层感知机(MLP)将音频编码器的特征映射到语言模型的嵌入空间,实现音频与文本的对齐。
数据使用:只采用公开可用的音频-文本数据进行预训练和微调,数据来源多样且公开透明。
音频编码器选择:首次提出利用单一通用音频编码器联合处理语音、环境声音和音乐,无需依赖ASR或特定声音事件模型。
训练效率优化:支持可变长度输入,避免了大量无效的填充,提高计算效率;同时通过将音频序列下采样到5Hz,实现快速训练和推理。
Datasets
MiDashengLM 在预训练和监督微调阶段仅基于公开数据集进行训练。
ACAVCaps:基于ACAV100M制作通用字幕数据
字幕数据集不足,主要是因为缺乏语音理解,且其数据来源单一,主要来自 Audioset 、VGGSound 和 FSD50k 。就我们的目的而言,需要一个公开可用且内容丰富的数据集,包含多语言语音、不同类型的音乐和大量复杂的音频环境。我们认为 ACAV100M [https://acav100m.github.io/]是一个合理的候选源数据集,因为它之前没有被标记为用于音频字幕,并且与前面提到的数据集几乎没有重叠。
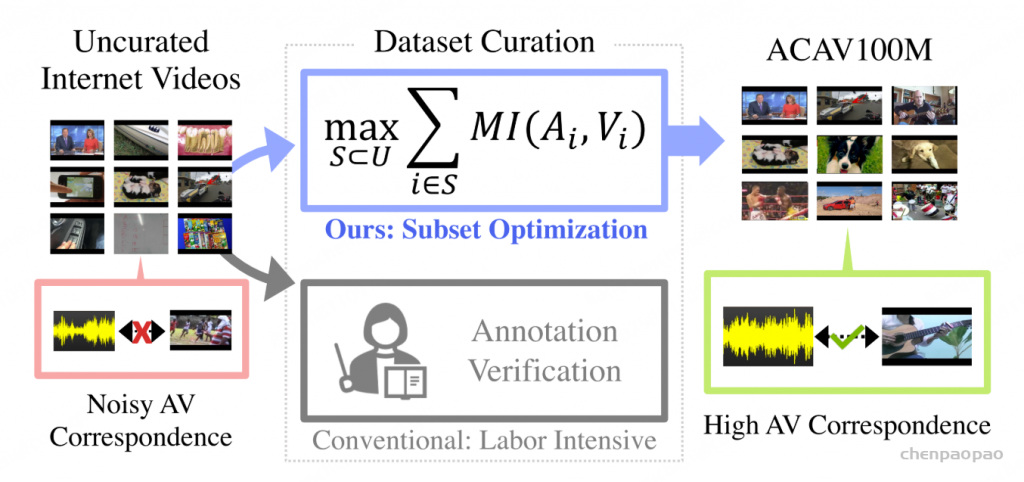
由于 ACAV100M 缺乏标签,我们开发了一套高效的数据管理流程。我们首先使用 CED-Base 以 2 秒为单位预测 AudioSet 标签。我们使用这个更精细的 2 秒尺度,使我们的字幕能够捕捉时间关系。获得声音事件标签后,我们进一步使用大量不同的音频分类模型来处理数据,每个模型都针对特定任务量身定制。
- 语音分析:该任务识别口语内容,区分不同说话者,对音频进行说话人分割(说话人分离),检测语音情感,分类说话者的性别和年龄,并使用Whisper推断转录文本。
- 声纹分析:除了基本的语音内容外,该任务进一步细化声音情感检测,评估声音健康状况,分析音高和音色等独特声学特征。
- 音乐分析:针对音乐内容,模型进行音乐风格分类、乐器识别、节奏检测、音乐情绪分析以及歌唱声音识别。
- 环境声学:该流程部分对声学场景进行分类,评估音频质量,分析混响情况,并识别各种噪声类型。
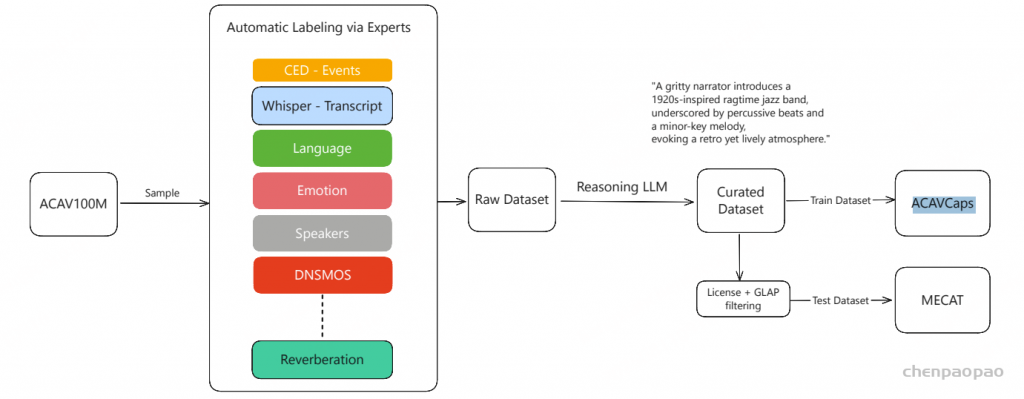
在获得上述所有标签后,我们使用推理型大型语言模型(DeepSeek-R1)生成简短的音频字幕。生成的精编音频字幕数据集随后被划分为训练集(ACAVCaps)和测试集(用于细粒度音频理解任务的多专家构建基准,MECAT)。MECAT测试集是从精编数据集中筛选而来,首先依据视频授权类型过滤各来源视频,最终通过GLAP 方法对音频-文本一致性进行评分。
MECAT-QA:

MECAT-QA 中,每段音频配备了五个问答对,涵盖不同类别和难度等级,总计超过10万个问答对。问答任务分为三个主要认知类别:
a) 感知(Perception):包含一个子类别——直接感知(Direct Perception),侧重于对音频内容和事件的直接识别与命名。
b) 分析(Analysis):由两个子类别组成——声音特征(Sound Characteristics),用于考察声音的声学属性(如音高);质量评估(Quality Assessment),用于评估音频的技术质量(如噪声水平)。
c) 推理(Reasoning):涵盖更高级的认知能力,分为三个子类别——环境推理(Environment Reasoning),需要推断声音发生的声学场景;推断与判断(Inference & Judgement),基于音频内容进行逻辑推理和判断;应用场景(Application Context),测试对声音实际用途或情境的理解。
Training datasets and tasks
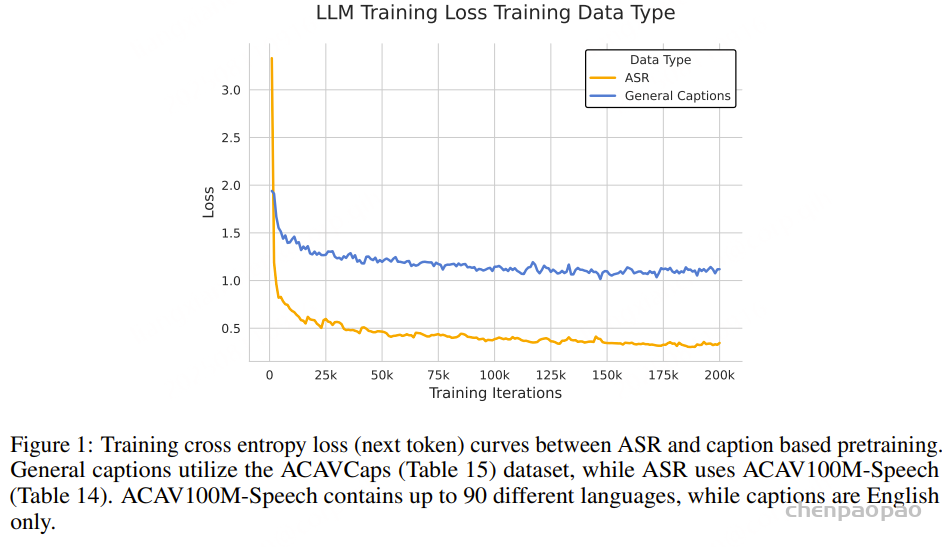
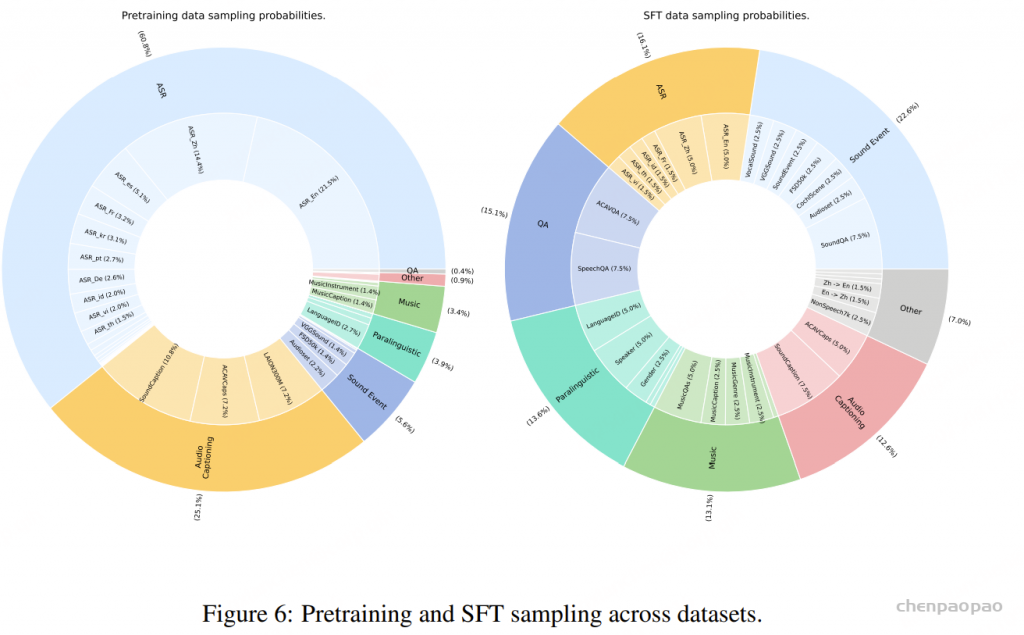
总计约110万小时的数据。其中约90%的训练数据来自公开的自动语音识别(ASR)数据集,其余数据集规模明显较小。如果不加以合理处理,模型在除ASR以外的任务上表现可能不足。数据采样情况如图6所示。
在音频-文本对齐阶段,我们使用前文介绍的ACAVCaps数据集,该数据集包含3.8万小时高质量的通用字幕。我们在ACAVCaps上训练3个epoch,以实现音频编码器与文本的对齐。
完成对齐后,我们对MiDashengLM模型在全量110万小时训练数据上进行预训练,约训练1.4个epoch。预训练结束后,在一个精选的预训练子集上进行一次监督微调,子集总时长约35.2万小时。
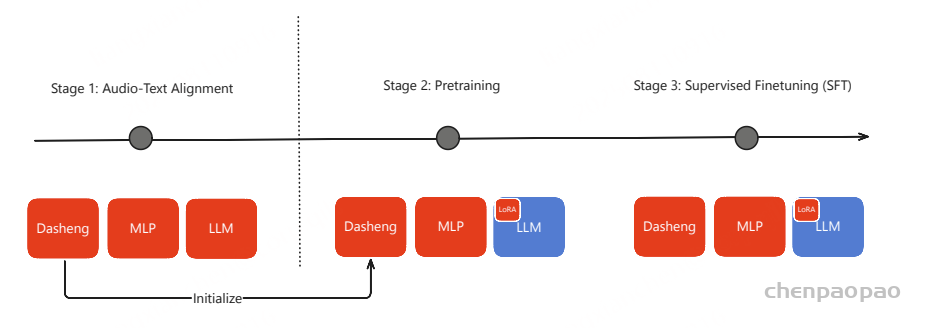
模型和三阶段训练:
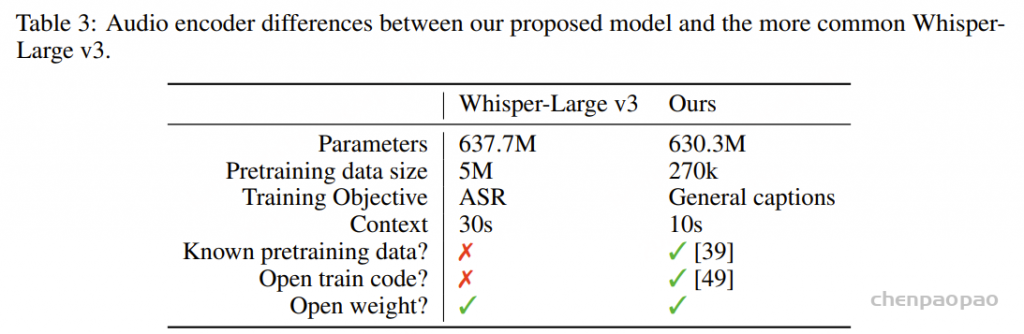
音频编码器基于 Dasheng-0.6B构建,是一个帧级的视觉Transformer(ViT),使用掩码自动编码器(MAE)目标在主要的 ACAV100M 数据集上进行预训练。
MiDashengLM 仅支持16 kHz的音频输入,所有输入数据都会自动重采样到此采样率。音频波形被转换成64维的梅尔频谱图(mel-spectrogram),Dasheng-0.6B 通过提取32毫秒帧特征,步幅为10毫秒来处理这些频谱图。默认情况下,Dasheng 会将输入特征进一步下采样4倍,产生40毫秒间隔的高级特征。Dasheng 支持可变长度输入,最大输入长度为1008帧(约10.08秒)。对于超过该长度的输入,我们采用无重叠滑动窗口方法,将每个音频片段分别输入 Dasheng,随后拼接得到的帧级特征。
Audio-text alignment
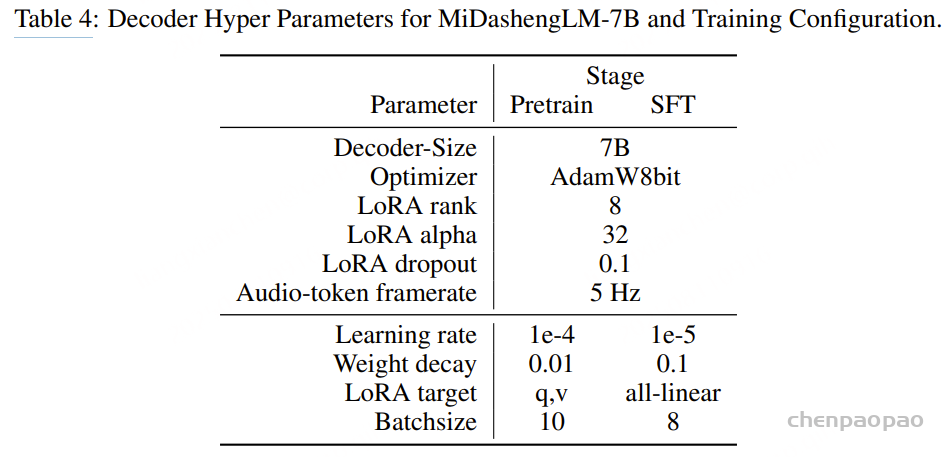
MiDashengLM 的第一步是将音频编码器与文本数据对齐。在此对齐阶段,我们使用 ACAVCaps 数据集,对音频编码器和文本解码器组件进行端到端微调。对齐之后,我们提取训练好的音频编码器,以便在后续的预训练和 SFT 阶段进行初始化。在模型开发期间,我们根据经验评估了两种替代方法:(1) 与冻结的大型语言模型 (LLM) 集成和 (2) 低秩自适应 (LoRA)。然而,这两种方法的音频编码器性能都不令人满意。音频文本对齐在 8 个 GPU 上以 256 的有效批次大小运行了一天。
解码器:
文本解码器使用 Qwen2.5-Omni-3B (一个公开的预训练语言模型)进行初始化。在预训练和监督微调阶段,我们都采用了 LoRA 来提升参数效率。训练目标是最小化标准交叉熵损失:
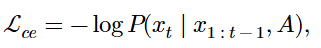
Training :
所有训练过程均采用线性学习率预热(warm-up),持续前1000次迭代,期间学习率从零线性上升至目标值。随后,学习率遵循余弦衰减策略,训练结束时降低至最大值的10%。预训练与监督微调(SFT)之间的主要区别包括:(1)SFT阶段采用较低的学习率;(2)通过LoRA技术扩展了可训练参数。
Results
音频编码器性能:
为了评估我们用通用音频字幕训练的音频文本对齐框架,我们将生成的音频编码器与 Whisper-Large V3 进行了比较。我们采用 X-Ares 基准 ,该基准通过轻量级 MLP 层评估冻结的编码器嵌入,涵盖三个核心音频领域:语音、音乐和(环境)声音。
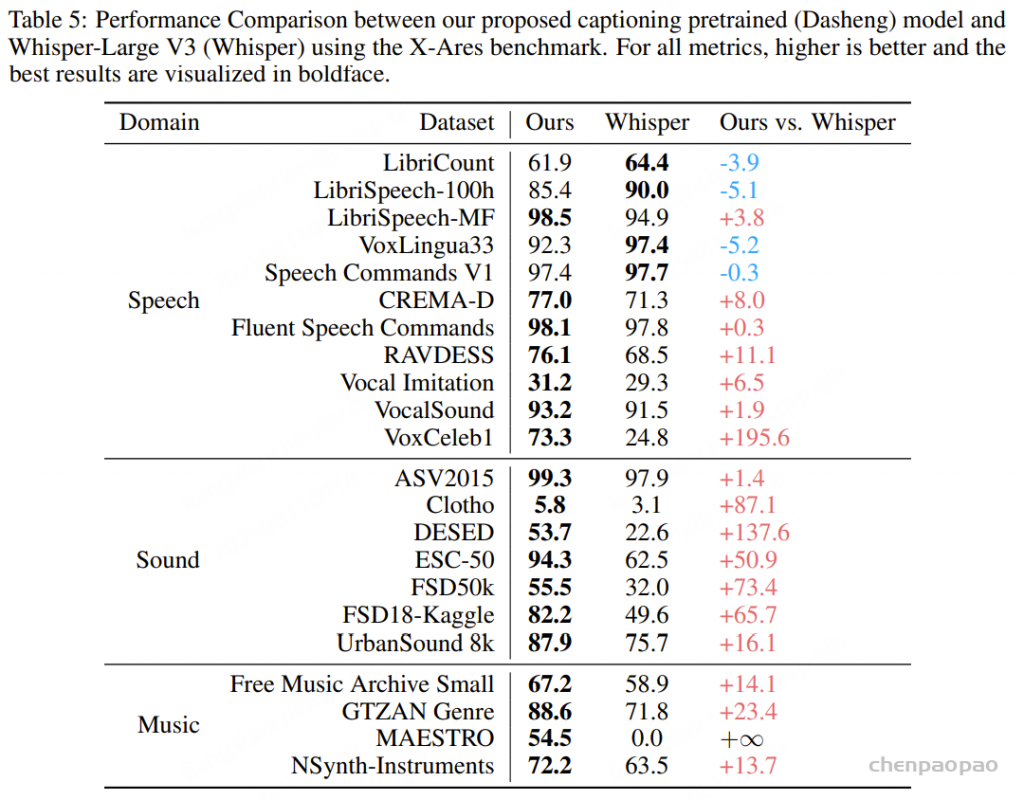
基于 Dasheng 的编码器在各种音频分类任务中表现出色。比较分析表明,虽然 Whisper-Large v3 在 22 个任务中的 4 个任务上取得了更好的结果,但我们的编码器在其余 18 个任务上优于 Whisper。在某些严格与语音相关的任务上,如自动语音识别(ASR,WER 提高约 5%)、说话人数统计(LibriCount)、口语语言识别(VoxLingua33)以及关键词检测(Speech Commands V1),Whisper 的表现优于我们提出的编码器。
传统数据集基准
模型配置介绍:

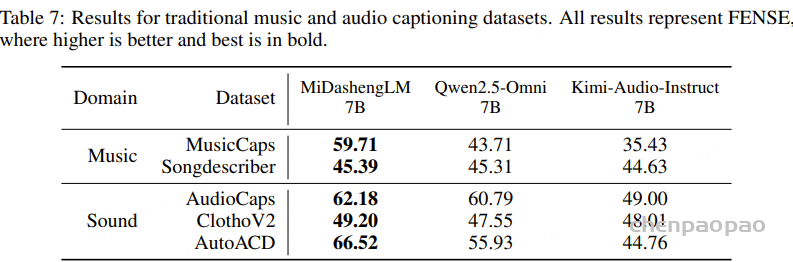
Audio captioning results:
在音乐和音频(声音)字幕数据集上,MiDashengLM 的表现均优于基线模型。对于通用音频,性能提升尤为显著,我们的模型在 AutoACD 上的表现显著优于基线模型,而在音乐专用基准测试中,其性能提升则较为平缓。
音频和副语言分类:
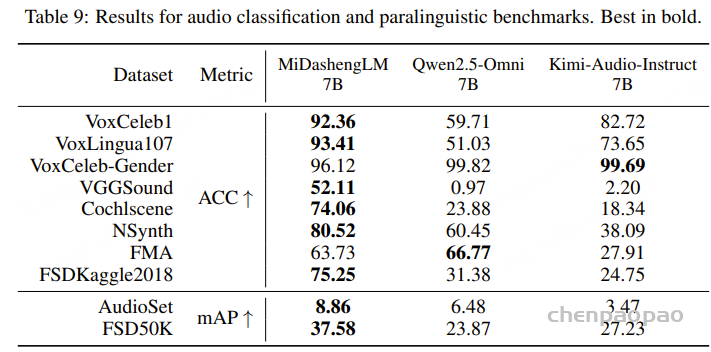
在十项测试任务中的表现表明,MiDashengLM 在说话人验证(VoxCeleb1)、语言识别(VoxLingua107)、声音分类(VGGSound、FSD50k)和音乐分类(NSynth、FMA)方面的表现优于基准。
Automatic speech recognition:
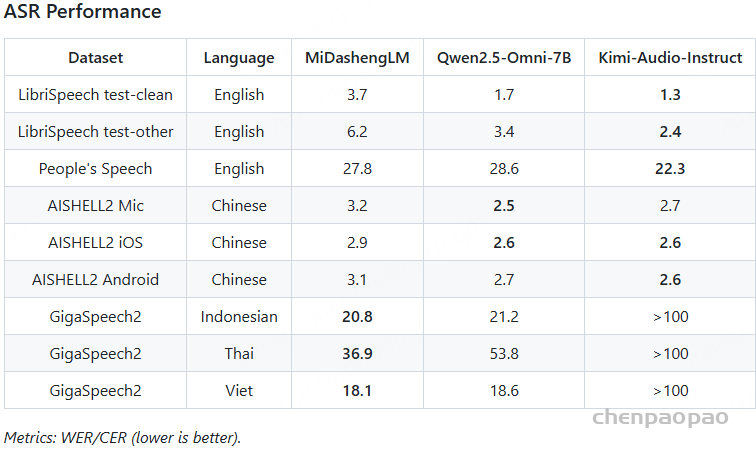
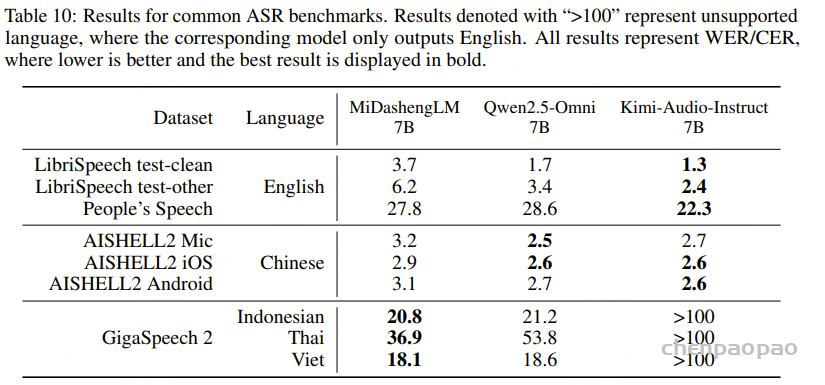
音频令牌的帧率会显著影响 ASR 性能,更高的帧率会提高性能,但计算效率会有所下降。这些结果与我们之前发现一致,表明我们的编码器仍然落后于闭源 Whisper 模型——两个基线系统都采用的音频编码器。由于 MiDashengLM 首先是一个字幕模型,因此它的 ASR 性能在传统 LibriSpeech 数据集上与基线相比有所下降。然而,在更大的测试集(如 People’s Speech)上的性能优于 Qwen2.5-Omni 基线。Kimi-Audio 在英语和普通话语音识别方面表现最佳,这可能源于它使用大量英语和中文 ASR 数据进行预训练。然而,MiDashengLM 和 Qwen2.5-Omni 均能够对印尼语、越南语和泰语等不同语言进行自动语音识别。这表明,尽管我们的编码器没有经过专门的语音训练,却拥有令人惊讶的强大多语言能力。
问答结果:
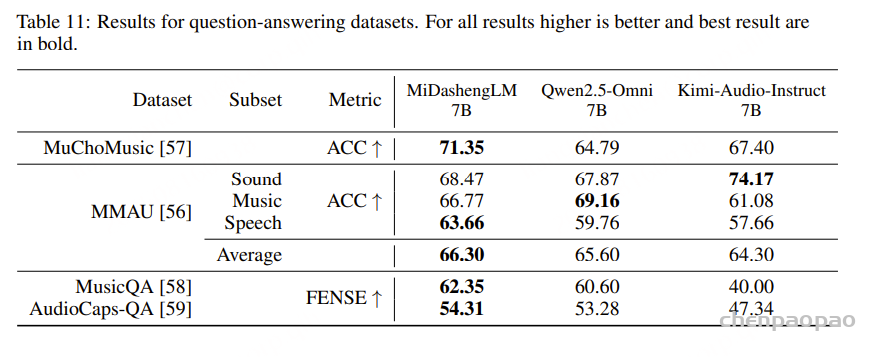
MiDashengLM 在这些任务中保持领先地位,而 Kimi-Audio-Instruct 的性能最弱
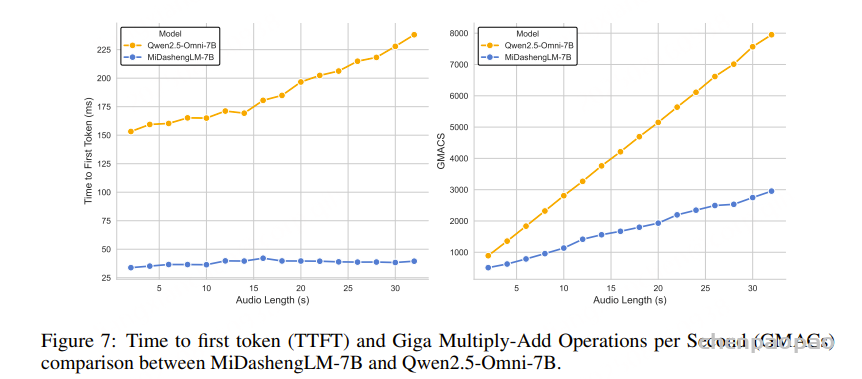
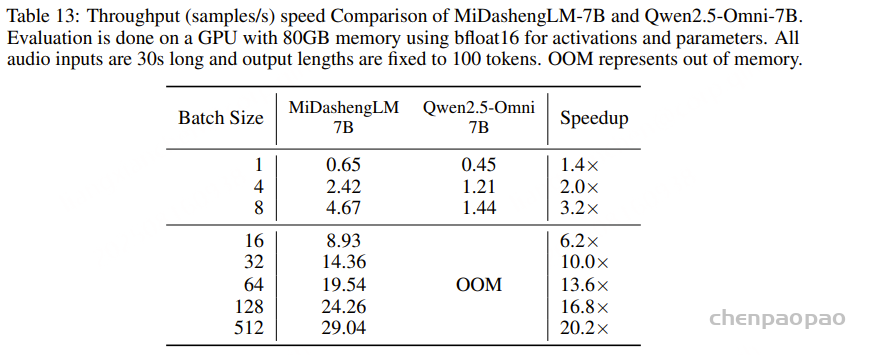
Inference speed