Smart Turn 是一个开源的语义语音活动检测(Semantic VAD)模型,它通过分析原始音频波形(而不是转录文本),来判断说话者是否已经完成了当前的发言轮次。
轮次检测(Turn Detection) 是对话式语音 AI 技术栈中最关键的功能之一。
轮次检测的核心目标,是判断语音智能体应当在何时对人类的语音作出回应。
目前,大多数语音智能体都基于 语音活动检测(Voice Activity Detection,VAD) 来实现轮次检测。VAD 的作用是将音频划分为“有语音”和“无语音”片段。然而,VAD 无法理解语音中的实际语言内容或声学信息。人类在进行轮次判断时,会综合语法结构、语调、语速,以及多种复杂的声学和语义线索。我们的目标是构建一种模型,使其在轮次判断上的表现能够更接近人类的直觉,而不是受限于基于 VAD 的方法。
架构
模型架构:尝试了多种架构和基础模型,包括 wav2vec2-BERT、wav2vec2、LSTM 和额外的 transformer 分类器层,最终,Smart Turn v3 以 Whisper Tiny 为基础,并包含一个线性分类器层。该模型基于 Transformer 架构,拥有约 800 万个参数。尽管模型规模很小,但它在测试集上的准确率却比 v2 版本更高
Smart Turn 以 16kHz 单声道 PCM 音频作为输入,与 Silero 等轻量级 VAD 模型配合使用。一旦 VAD 模型检测到静音,便会对用户回合的整个录音运行 Smart Turn 功能,如有必要,将从开头截断音频,将其缩短至约 8 秒。
当前模型的架构相对较为简单。未来可以尝试探索其他建模方式,以提升整体性能,或者让模型输出关于音频的更多附加信息,亦或是在输入端引入更多上下文信息。
如果在 Smart Turn 尚未完成执行之前 检测到用户有新的语音输入,则应当 基于整个当前轮次的完整录音重新运行 Smart Turn,而不是仅对新增的音频片段进行推理。Smart Turn 在获得足够上下文信息的情况下效果最佳,其设计目标并非用于处理非常短的音频片段。
例如,如果能够为模型提供额外的上下文信息,用于对推理过程进行条件约束,将会非常有价值。一个典型的使用场景是:让模型“知道”用户当前正在朗读的是 信用卡号码、电话号码或电子邮箱地址。在这种情况下,模型可以基于特定的语义或结构模式,对轮次检测做出更符合人类预期的判断。
能力:
体积相比 v2 缩小近 50 倍,仅 8 MB 🤯
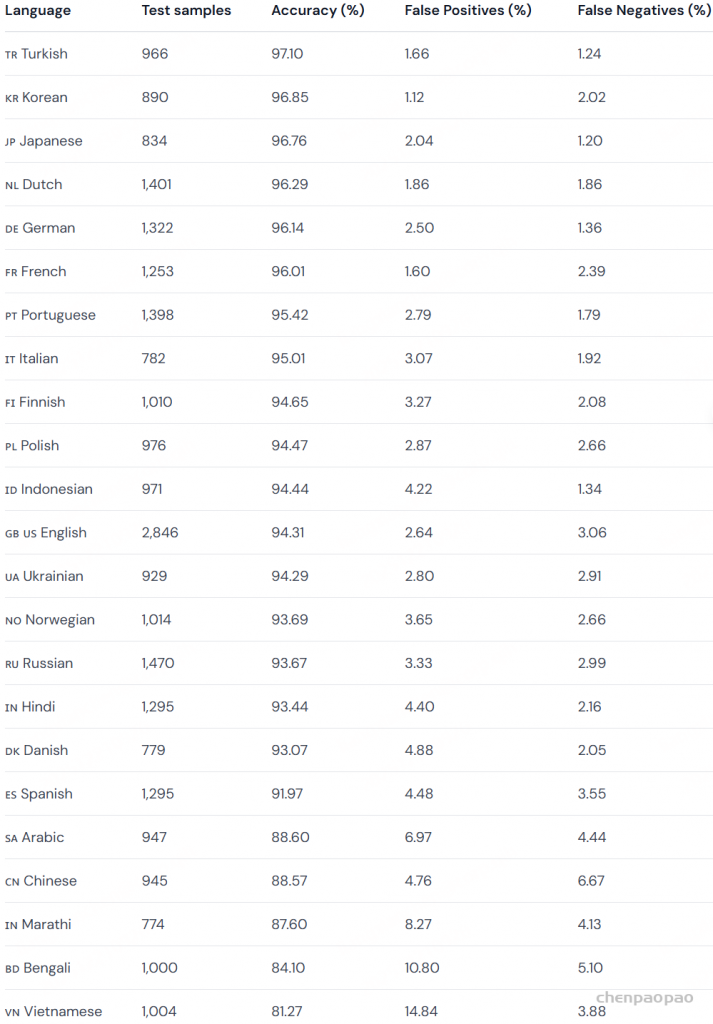
语言支持大幅扩展:现已覆盖 23 种语言:
🇸🇦 阿拉伯语、🇧🇩 孟加拉语、🇨🇳 中文、🇩🇰 丹麦语、🇳🇱 荷兰语、🇩🇪 德语、🇬🇧 🇺🇸 英语、🇫🇮 芬兰语、🇫🇷 法语、🇮🇳 印地语、🇮🇩 印度尼西亚语、🇮🇹 意大利语、🇯🇵 日语、🇰🇷 韩语、🇮🇳 马拉地语、🇳🇴 挪威语、🇵🇱 波兰语、🇵🇹 葡萄牙语、🇷🇺 俄语、🇪🇸 西班牙语、🇹🇷 土耳其语、🇺🇦 乌克兰语,以及 🇻🇳 越南语。
在模型体积大幅缩小的情况下,准确率相比 v2 反而进一步提升
Accuracy results