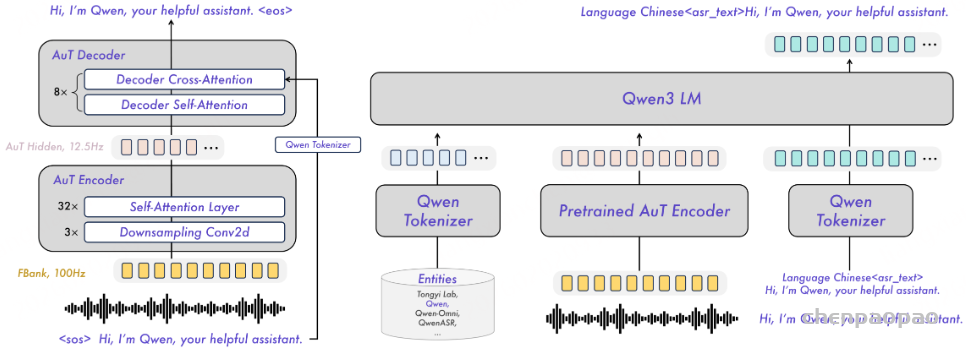
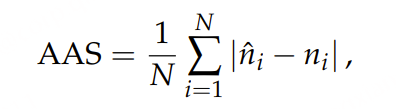- 论文题目:LLM-ForcedAligner: A Non-Autoregressive and Accurate LLM-Based Forced Aligner for Multilingual and Long-Form Speech
- 论文预印版:https://arxiv.og/pdf/2601.18220
背景
在语音处理中,强制对齐(Forced Alignment,FA)的目标是在给定相应转录文本的情况下,估计语音信号中每个词或字符的起始和结束时间戳。FA在众多应用中不可或缺,包括大规模语音语料库的构建与清理、自动字幕生成和词级高亮显示,以及语音合成中的时长建模和韵律分析。随着多语言和多模态应用的不断发展,高效且准确的FA变得日益重要。
现有的FA方法大致可分为两大类:传统混合系统和端到端模型。Montreal forced aligner(MFA)通常是一种混合高斯混合模型-隐马尔可夫模型(GMM-HMM)框架,通过维特比解码计算帧级音素到文本的对齐路径来获取时间戳。CTC是一种常见的端到端强制对齐方法,它利用基于CTC的自动语音识别(ASR)模型计算的帧到token对齐,采用动态规划在受限的搜索路径中找到与文本序列对齐的最优路径。CIF为每个编码器输出帧预测一个权重,并随时间对这些权重进行积分。当累积权重超过阈值时,会触发一个触发事件,此时计算累积的帧级声学向量的加权和,生成与输出token对齐的声学嵌入,从而能够为每个token分配相应的时间戳。WhisperX采用轻量级端到端音素识别模型对语音进行帧级音素分类,然后使用动态时间规整(DTW)将得到的音素序列与转录文本对齐,通过聚合音素级时间戳来获取词级时间戳。
然而,上述FA方法与特定语言的音素、词汇或结构设计紧密相关,这意味着在多语言场景中,部署通常需要一系列结构各异的独立系统,导致工程成本和维护复杂度随语言数量呈线性增长。此外,以往的FA方法可概括为一个先计算局部声学相似度,再进行单调路径搜索的过程。虽然这些方法能为短片段生成相当准确的边界,但在长语音中,它们往往会积累显著的系统性时间偏移。
大型语言模型(LLMs)在多语言文本理解和长序列处理任务中展现出了强大的能力,为支持多语言、跨语言和长语音的语音文本对齐提供了新的可能性。越来越多的研究探索将语音编码器与LLMs相结合,构建语音大语言模型(SLLMs),以在统一框架内处理语音和文本。然而,现有的SLLMs主要在高级语义任务上取得了成功,例如ASR、语音理解、语音合成和口语对话。对于对声学特征更为敏感的FA,这些SLLMs通常将其视为ASR的副产品,通过next-token prediction来生成词级或字符级的时间戳。这种模式容易产生时间非单调的幻觉,并且会导致显著的推理延迟。

LLM-ForcedAligner
提出了一种新的强制对齐(Forced Alignment, FA)框架,称为 LLM-ForcedAligner。该方法将强制对齐重新表述为一种槽位填充(slot-filling)范式:
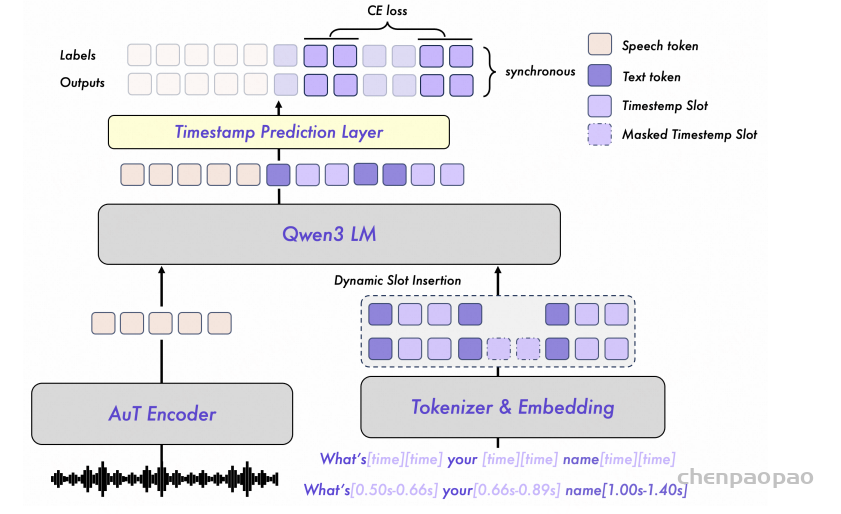
将每个单词或字符的起始和结束时间戳视为离散的时间索引,并在转录文本中插入专门的特殊标记作为“槽位”。这样,在语音嵌入表示以及插入了这些槽位的转录文本作为条件输入的情况下,语音大语言模型(SLLM)可以直接在指定的槽位位置预测对应的时间索引。
这一新的强制对齐范式有效利用了大语言模型在槽位填充能力和长上下文处理能力方面的优势,将传统基于纯声学、音素级别的对齐方法扩展为具备语义边界感知能力的字符级或词级对齐方法。
在具体实现上,为了进行槽位填充,我们在训练阶段采用了因果注意力掩码(causal attention masking),且不对输入序列和标签序列引入任何偏移(shift)。这使得每个槽位可以基于其自身及其之前的上下文信息来预测对应的时间索引。同时,损失函数仅在槽位位置上进行计算。
此外,我们采用了一种动态槽位插入策略:在转录文本中,随机决定是否为每个单词或字符插入特殊标记,从而使 LLM-ForcedAligner 能够对任意单词或字符进行时间戳预测。
在推理阶段,LLM-ForcedAligner 支持非自回归(non-autoregressive)解码,相比自回归解码方式可以完全避免幻觉(hallucination)问题,并且实现更快的推理速度。
实验结果表明,在多语言、跨语言以及最长达 300 秒的长语音场景下,LLM-ForcedAligner 相较于以往的强制对齐方法,在累计平均偏移(Accumulated Averaging Shift, AAS)指标上实现了 69%~78% 的相对下降,同时仅带来了轻微的实时因子(Real-Time Factor, RTF)增加。
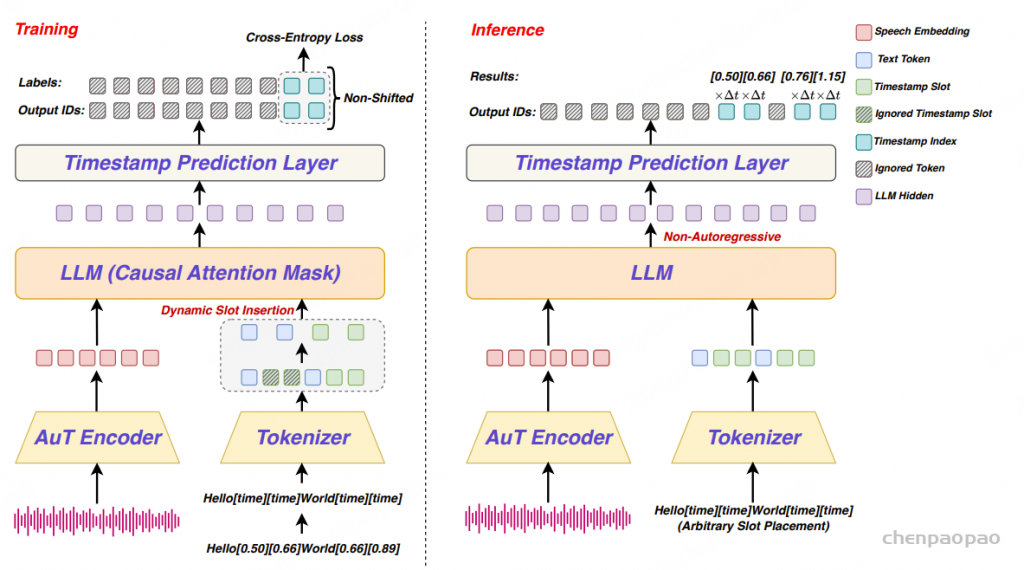
[time],将其作为“槽位(slot)”。同时采用动态槽位插入策略,随机决定忽略哪些词或字符对应的槽位。由 AuT 编码器生成的语音嵌入(speech embeddings)随后与文本序列拼接,并输入到 LLM 中,在**因果注意力掩码(causal attention masking)**下进行训练。
Overall Architecture
LLM-ForcedAligner将FA构建为一种槽位填充范式:给定语音信号和一个添加了表示词级或字符级的开始和结束时间槽位特殊token“[time]”的转录文本,SLLM直接为每个槽位预测相应的离散时间戳索引。与以往首先进行帧级或音素级的对齐,然后将结果聚合为词级或字符级的时间戳FA方法不同,LLM-ForcedAligner则直接预测词级或字符级的时间戳索引。
训练LLM-ForcedAligner需要大量语音-转录文本对的词级或字符级时间戳标签;然而,由于人工标注成本过高,我们采用了由MFA生成的伪时间戳标签,因为MFA是现有对齐方法中准确率最高的。需要强调的是,MFA伪标签本身存在噪声和系统性偏移。LLM-ForcedAligner并非简单复制MFA的输出,而是利用SLLM对这些伪标签进行提炼和平滑处理,从而实现更稳定、偏移更小的时间戳预测。
LLM-ForcedAligner 中的语音编码器来自AuT,其输出的每个语音嵌入帧对应80毫秒的语音信号。在将带有MFA伪标签的转录文本输入Tokenizer之前,我们用[time] 替换所有MFA伪标签时间戳。此外带有MFA伪标签的转录文本同时将每个时间戳除以80毫秒以离散成时间序列索引,作为模型训练时的标签。
时间戳预测层是一个线性层,具有3750个输出类(300秒除以80毫秒),用于预测整个输入序列的时间戳索引。
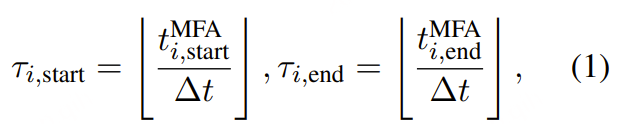
LLM-ForcedAligner的多语言和跨语言能力由AuT语音编码器和多语言LLM共同提供。具体而言,在大规模多语言语料库上预训练的AuT编码器能为多种语言生成有效的帧级语音嵌入,而多语言LLM则处理不同语言的语义信息。此外,特殊token[time]和时间戳预测层不依赖于特定语言的音素集或词典。因此,LLM-ForcedAligner能够处理多语言和跨语言的语音-文本对,克服了以往FA方法的特定语言限制。
训练策略
SLLM通常采用一种训练方案,即移除输出序列的最后一个标记和标签序列的第一个标记,使两个序列之间产生一个位置的偏移;然后计算交叉熵损失,从而实现标准的下一个标记预测范式。然而,这种范式并不适合填充时间戳槽位填充。
相反,我们采用因果训练,使输出和标签序列不发生偏移,这让LLM-ForcedAligner在训练过程中能够明确感知时间戳槽位,并预测要填充到这些槽位中的时间戳。此外,因果训练使LLM-ForcedAligner在预测当前槽位的时间戳时能够结合先前的上下文,确保时间戳预测的全局一致性。在训练过程中,我们仅在时间戳槽位位置计算交叉熵损失,从而将LLM-ForcedAligner的训练目标集中在时间戳槽位填充上。
此外,在训练过程中为每个词或字符持续插入开始和结束时间戳槽位,会导致LLM-ForcedAligner过度依赖之前预测的时间戳。我们提出了一种训练过程中的动态槽位插入策略,以增强LLM-ForcedAligner的泛化能力。具体而言,对于每个样本,我们以50%的概率决定是否应用动态槽位插入。当应用动态槽位插入时,样本中的每个词或字符有50%的概率在其后插入开始和结束时间戳槽位。该策略使LLM-ForcedAligner能够预测任意位置的词或字符的开始和结束时间戳。
非自回归推理
由于在训练过程中输出和标签序列保持不偏移,LLM-ForcedAligner能够使用非自回归解码同时预测转录文本中所有槽位的时间戳索引。具体来说,对于一个语音-转录文本对,用户可以在任意单词或字符之后自定义起始和结束时间戳槽位。给定用户定义的时间戳槽位位置,LLM-ForcedAligner通过非自回归解码预测其时间戳索引,然后将时间戳索引乘以80毫秒就转换为毫秒级时间戳。
实验
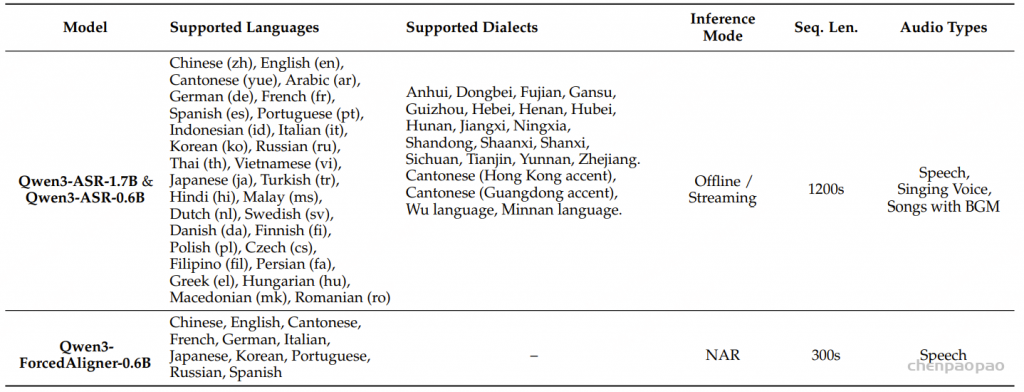
我们的实验基于56000小时的语音数据展开,涵盖10种语言:中文、英语、法语、德语、意大利语、日语、韩语、葡萄牙语、俄语和西班牙语。这些数据来源于内部和开源数据集的组合,覆盖了多种场景,如朗读语音、对话语音、播客和会议等。所有训练和测试数据集都标注了由MFA生成的伪时间戳,此外,我们还在一个带有手动标注时间戳的内部中文测试数据集上评估了LLM-ForcedAligner的性能。训练数据集中的转录文本要么来自人工标注,要么来自ASR模型的预测结果,这增强了LLM-ForcedAligner对不同质量转录文本的泛化能力。
LLM-ForcedAligner中的AuT编码器包含316.42M参数,其初始化源自Qwen3-Omni的AuT编码器,LLM使用的是Qwen3-0.6B,时间戳预测层是一个单一的线性层,具有3750个输出时间戳类别,包含3.84M参数。
在训练过程中,AuT编码器、LLM和时间戳预测层联合优化。我们使用累积平均偏移(AAS)来衡量时间戳预测的性能。AAS值越低,表明时间戳预测性能越好。具体来说,AAS计算每个时间戳槽位的平均偏移,其定义为测试数据集中所有槽位的预测时间戳与真实时间戳之间的平均绝对差。
实验结果
表1和表2在多语言、跨语言和长语音场景下,基于MFA标注的测试数据集,将LLM-ForcedAligner与其他FA方法进行了比较。Monotonic-Aligner只支持中文,NFA和WhisperX需要根据不同的语言切换模型。我们观察到,LLM-ForcedAligner不仅支持多种语言且无需切换模型,而且与其他FA方法相比,在多语言原始语音上的AAS相对降低了66%~73%。此外,LLM-ForcedAligner在多语言和跨语言长语音上实现了极低的平均AAS,而在这种场景下,其他FA方法往往表现不佳。


表3在人工标注的中文测试数据集上对LLM-ForcedAligner与其他FA方法进行了比较,涵盖了带噪声、跨语言和长语音场景。我们发现,在人工标注的测试数据集上,LLM-ForcedAligner的平均AAS相较于其他FA方法实现了68%~78%的相对降低,这表明使用MFA标注数据训练的LLM-ForcedAligner能够很好地泛化到真实世界的场景中。
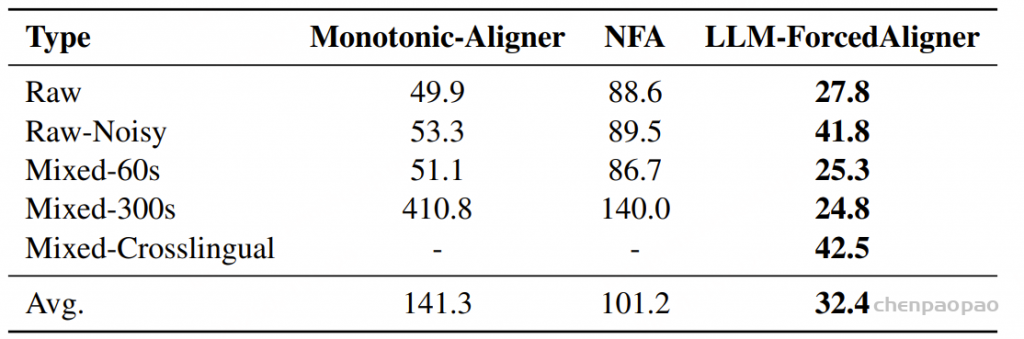
此外在表2中,MFA标注测试数据集上长语音的平均AAS略高于原始语音的平均AAS,这反映了MFA在长语音上的系统性偏移。相比之下在表3中,在人工标注的测试数据集上,长语音的平均AAS低于原始语音的平均AAS,这表明LLM-ForcedAligner并非简单复制MFA的时间戳预测,而是学习到了更稳健、更可靠的时间戳预测,能够在长语音场景中有效修正MFA的标签。此外,在长语音推理过程中,LLM-ForcedAligner可以利用更长的历史上下文来预测当前片段的时间戳,从而在人工标注的长语音测试数据集上取得了更优异的性能。
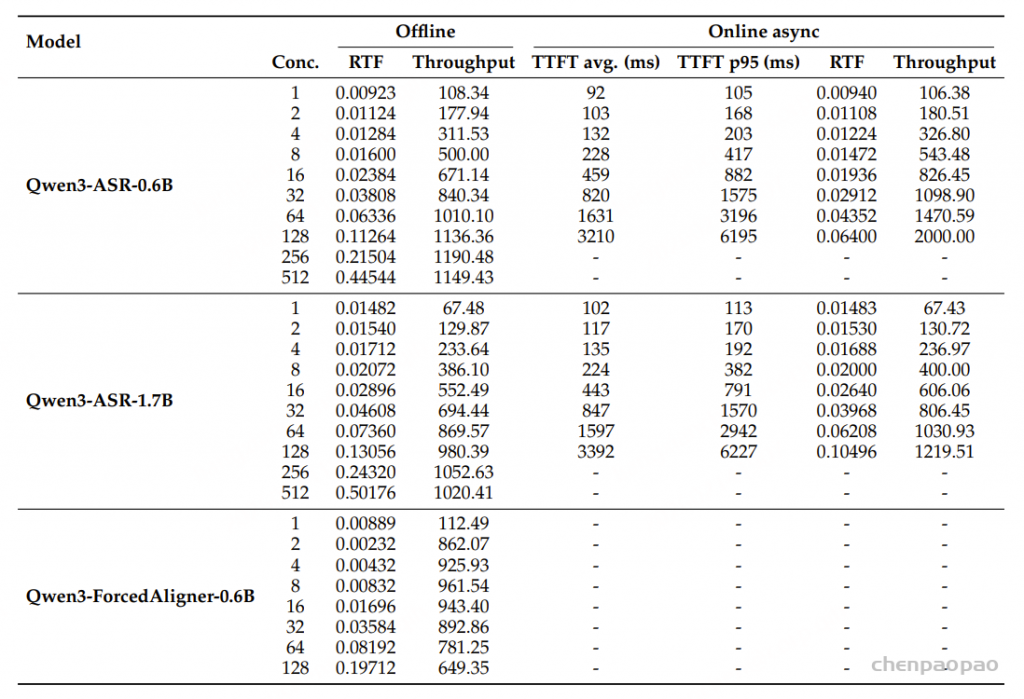
表4报告了在相同的推理条件下,LLM-ForcedAligner与其他FA方法的平均实时因子(RTF)。随着模型参数数量的增加,RTF略有上升。由于LLM-ForcedAligner采用非自回归推理的优势,它在AAS上实现了大幅降低,RTF仅略有增加。用户可以根据AAS与RTF的权衡来选择最合适的FA方法。
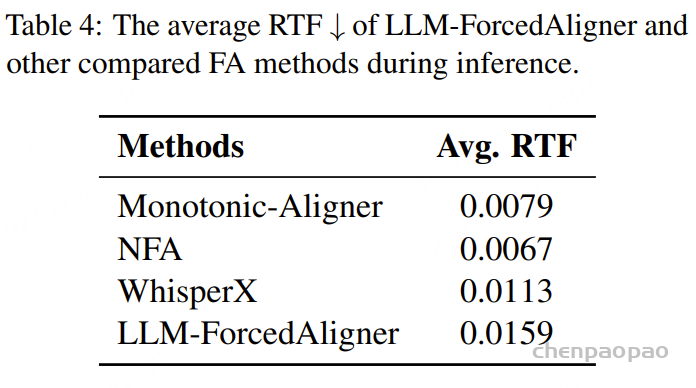
表5展示了在MFA标注和人工标注的测试数据集上,使用不同时间戳token时长训练的LLM-ForcedAligner的平均AAS结果。当时间戳token时长为120毫秒时,时间戳预测层有2500个类别(300秒除以120毫秒);当时长为80毫秒时,有3750个类别(300秒除以80毫秒);当时长为40毫秒时,有7500个类别(300秒除以40毫秒)。随着时间戳token时长的缩短,MFA标注测试数据集上的AAS稳步下降,这表明更精细的时间戳预测更符合MFA标签。然而,在人工标注的测试数据集上,更精细的时间戳预测并没有带来更低的AAS,因为它更贴合MFA的时间戳分布,从而导致泛化能力下降。80毫秒的时间戳token时长是最佳选择,因为AuT编码器输出的每个帧也代表80毫秒的语音,这有助于LLM-ForcedAligner根据语音边界更好地确定单词或字符的起始和结束时间戳。
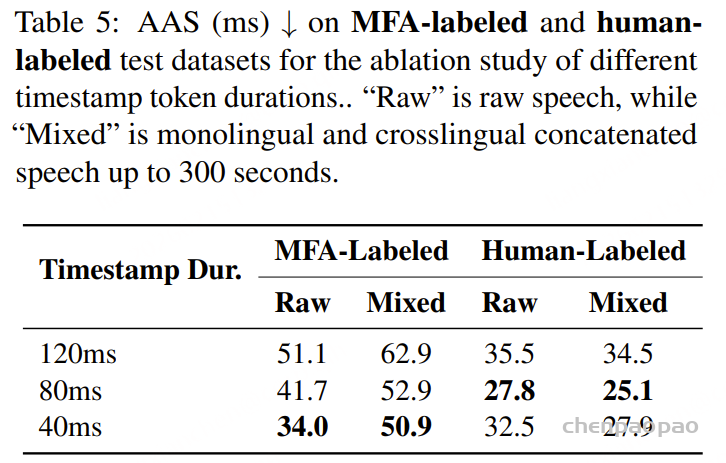
表6展示了LLM-ForcedAligner在MFA标注和人工标注的测试数据集上的平均AAS结果,并对比了训练期间有无动态槽位插入的情况。动态槽位插入会随机决定是否在每个单词或字符后插入时间戳槽位,使LLM-ForcedAligner能够在任意位置预测开始和结束时间戳,并防止其过度依赖先前预测的时间戳。我们发现,动态槽位插入降低了两个测试数据集上的AAS,其中对长语音的改进更为明显。这一现象的原因是,动态槽位插入通过随机决定是否在每个单词或字符后插入时间戳槽位,避免了LLM-ForcedAligner过度依赖历史预测的时间戳,否则可能会导致系统性的时间偏移。此外,动态槽位插入使LLM-ForcedAligner能够在任意位置为单词或字符预测开始和结束时间戳,支持用户自定义的时间戳预测。
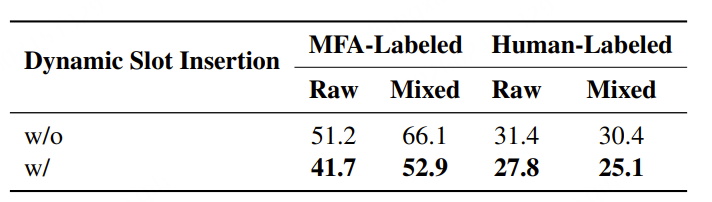
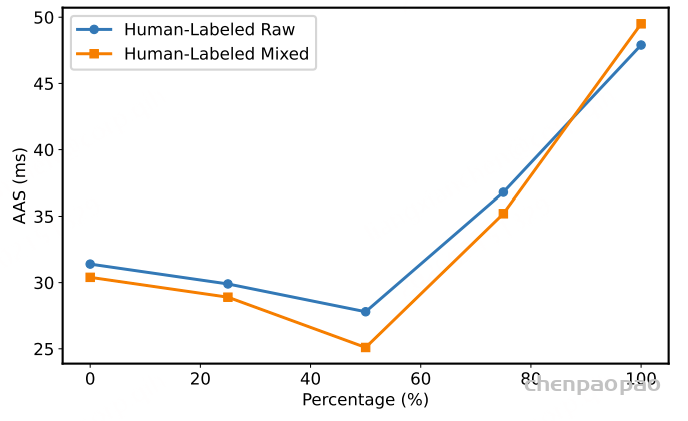
图3展示了在 LLM-ForcedAligner 以不同动态槽位插入比例进行训练时,在人工标注的测试数据集上的AAS结果。当动态槽位插入比例低于训练样本的50%时,LLM-ForcedAligner的AAS较低,且随着比例的增加,AAS持续下降。然而,当该比例超过训练样本的50%时,AAS开始上升,在100%时达到最高值。因此,选择50%这一合适的动态槽位插入比例对于增强LLM-ForcedAligner的泛化能力至关重要。
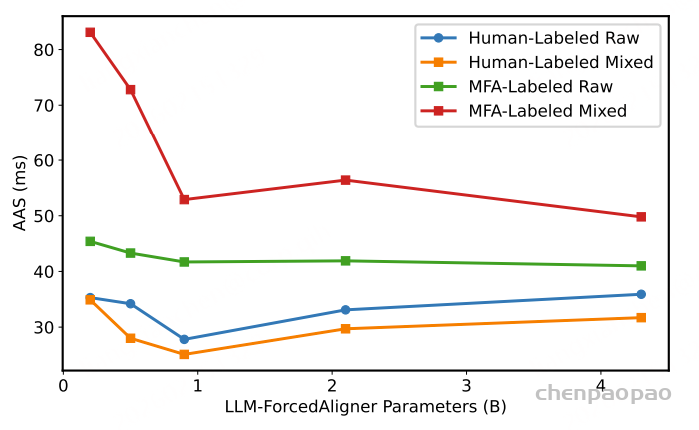
图4展示了在不同参数设置下,LLM-ForcedAligner在MFA标注和人工标注的测试数据集上的AAS结果。当LLM-ForcedAligner的参数规模小于0.9B时,时间戳预测性能受到模型容量不足的限制。当参数规模超过0.9B时,MFA标注测试数据集上的AAS没有显著变化,而人工标注测试数据集上的AAS则有所上升,这表明LLM-ForcedAligner过拟合了MFA时间戳分布。因此,0.9B的参数规模是最优的。在这一规模下,LLM-ForcedAligner不会严格拟合MFA时间戳分布,而是学习到更平滑、更稳健的时间戳预测行为,具有更好的泛化性能。
参考文献
- [1] Michael McAuliffe, Michaela Socolof, Sarah Mihuc, Michael Wagner, and Morgan Sonderegger. 2017. Montreal Forced Aligner: Trainable Text-Speech Alignment Using Kaldi. In Proc. Interspeech, pages 498–502.
- [2] Xian Shi, Yanni Chen, Shiliang Zhang, and Zhijie Yan. 2023. Achieving Timestamp Prediction While Recognizing with Non-Autoregressive End-to-End ASR Model. CoRR, arXiv:2301.12343.
- [3] Max Bain, Jaesung Huh, Tengda Han, and Andrew Zisserman. 2023. WhisperX: Time-Accurate Speech Transcription of Long-Form Audio. In Proc. Interspeech
- [4] Xian Shi et. al., Qwen3-ASR Technical Report, https://arxiv.org/abs/2601.21337