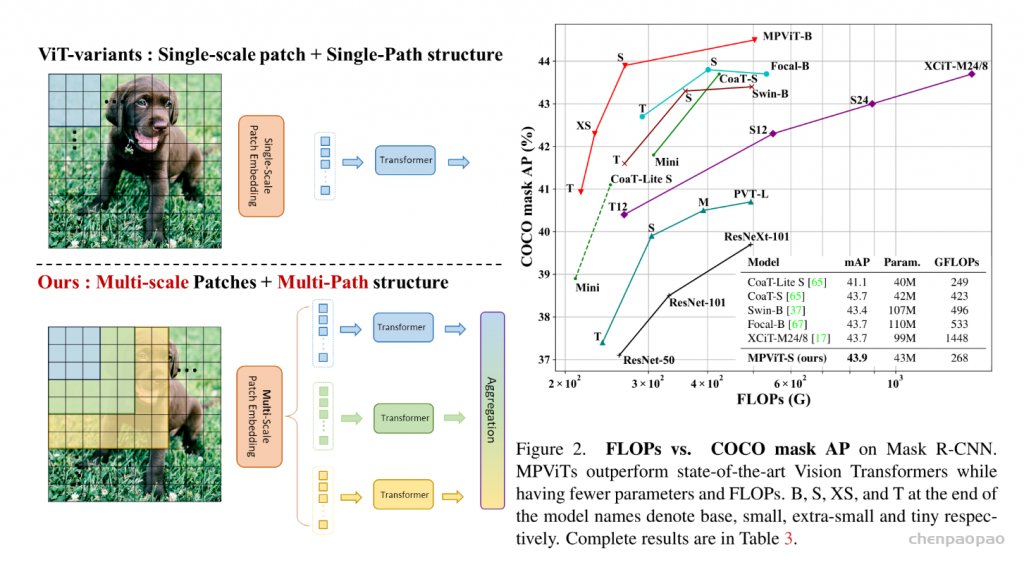
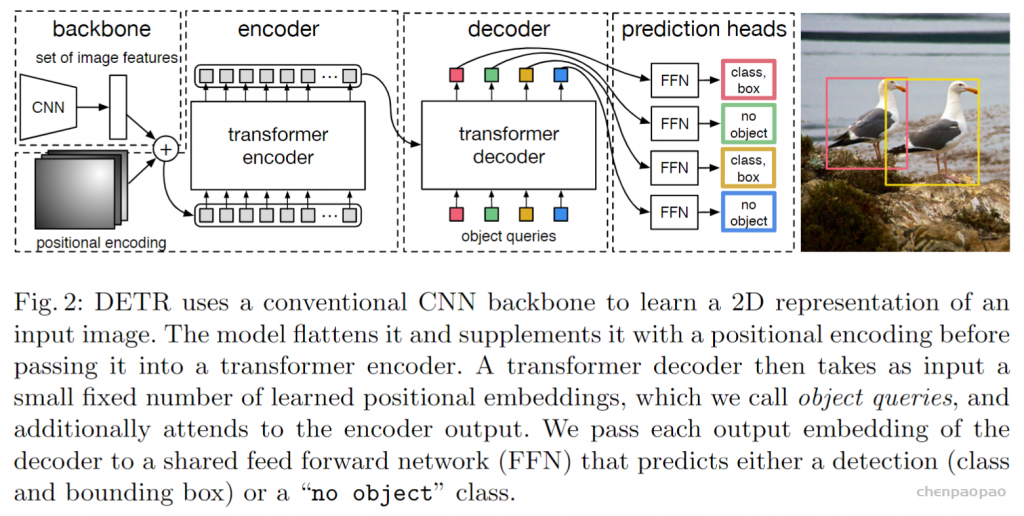
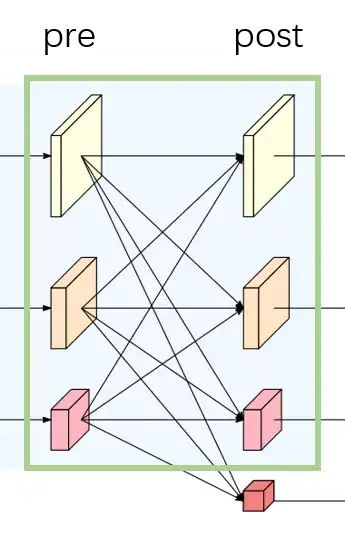
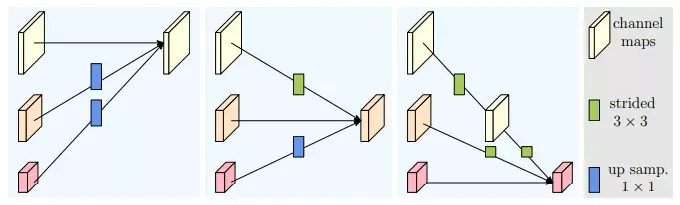
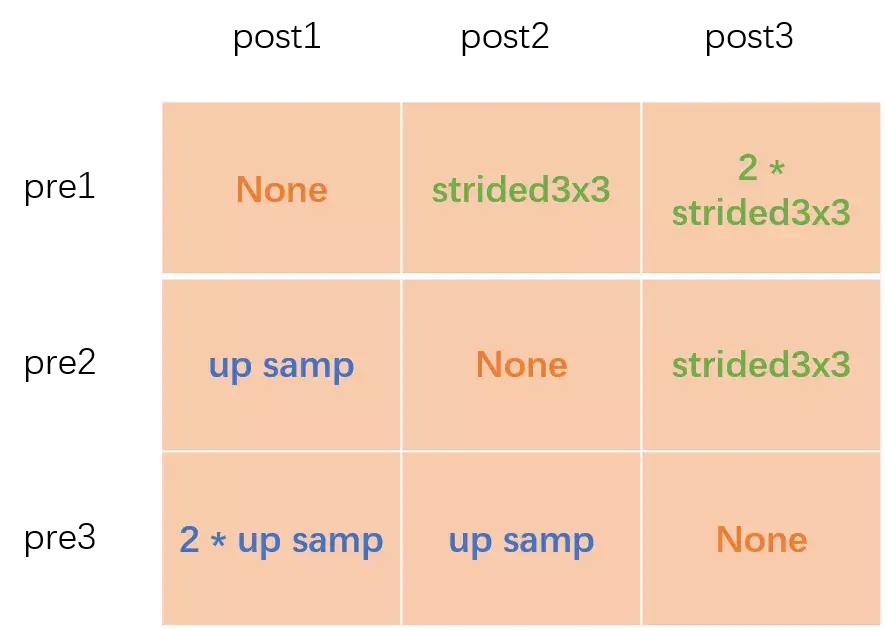
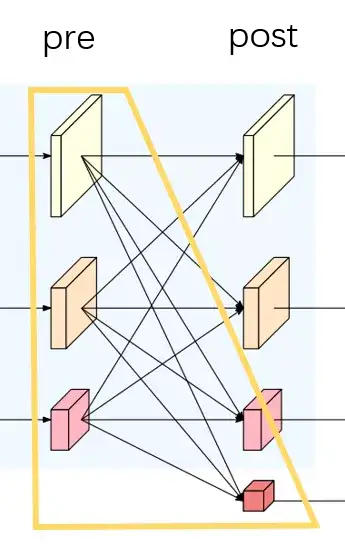
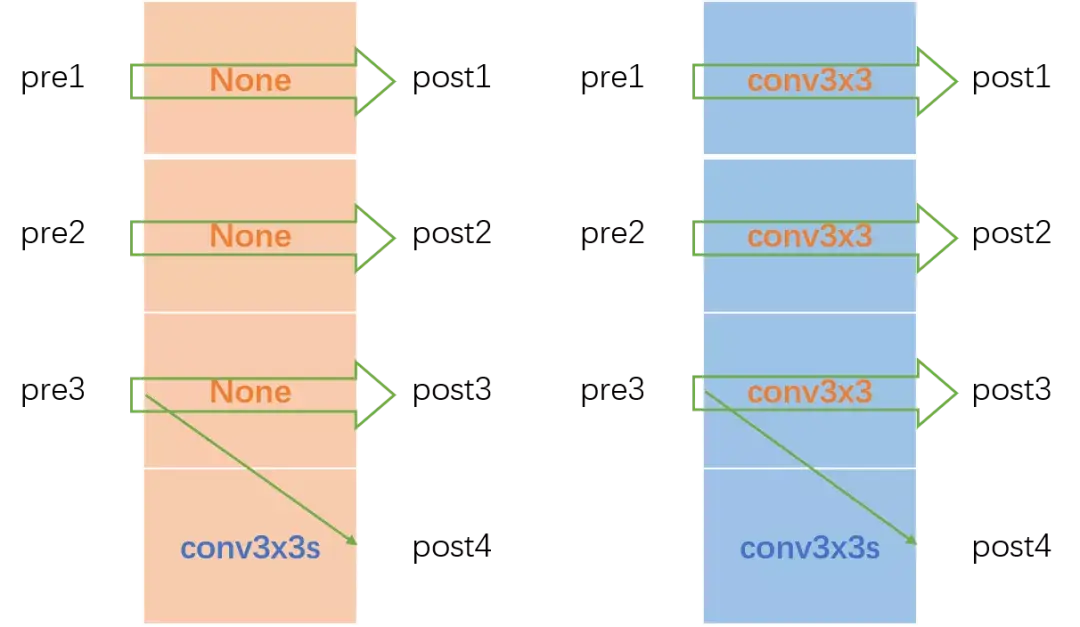
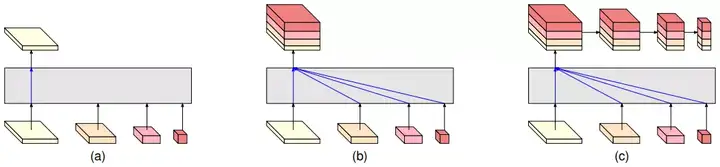
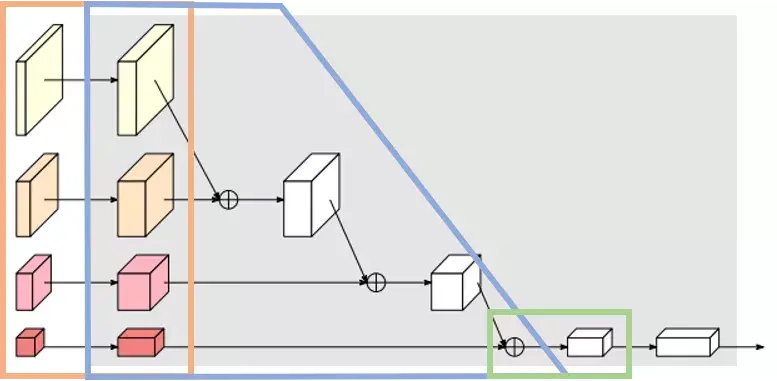
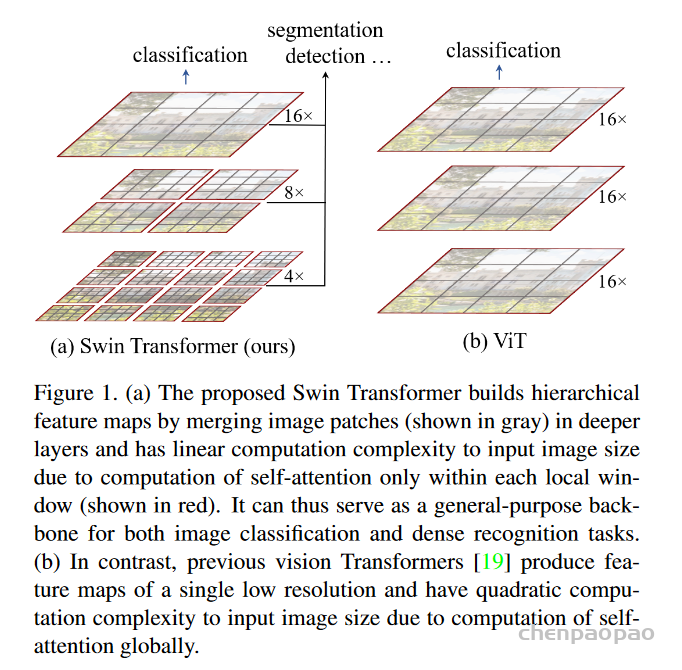
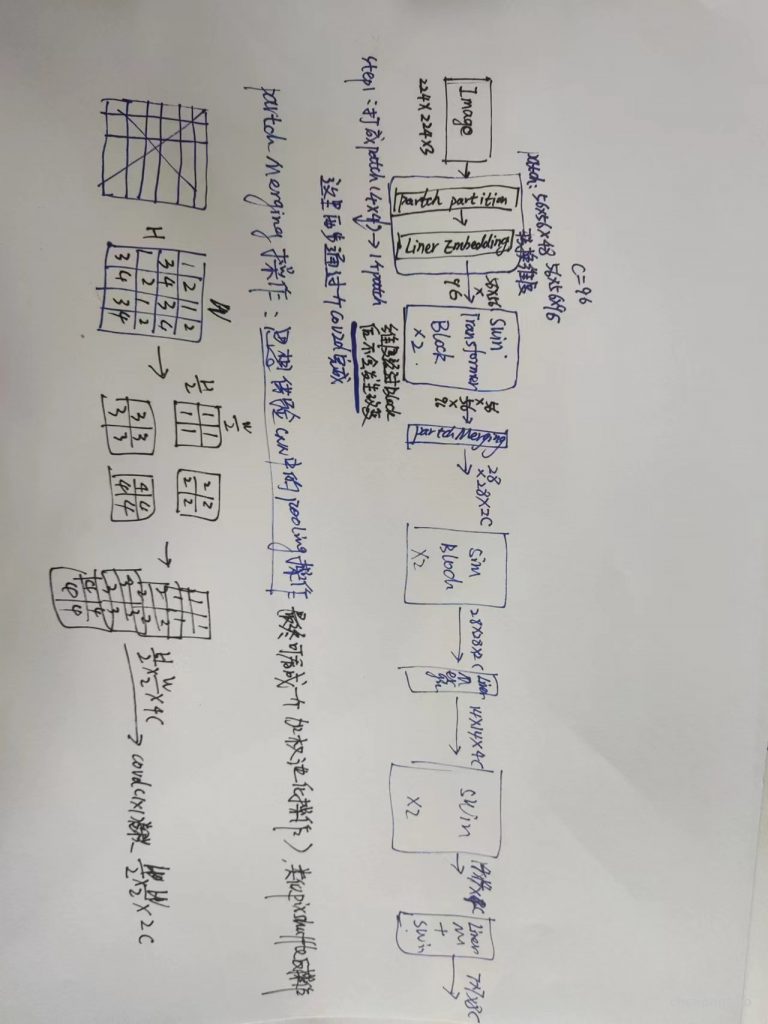
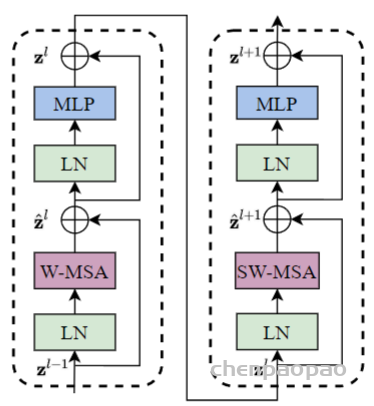
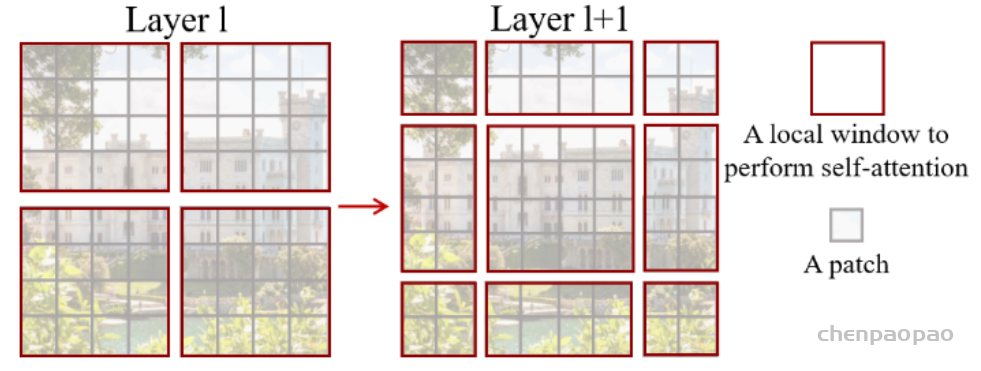
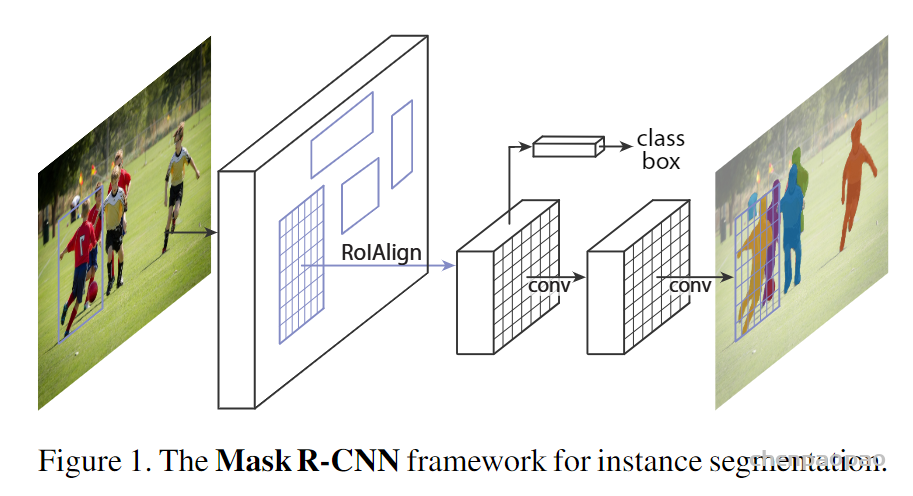
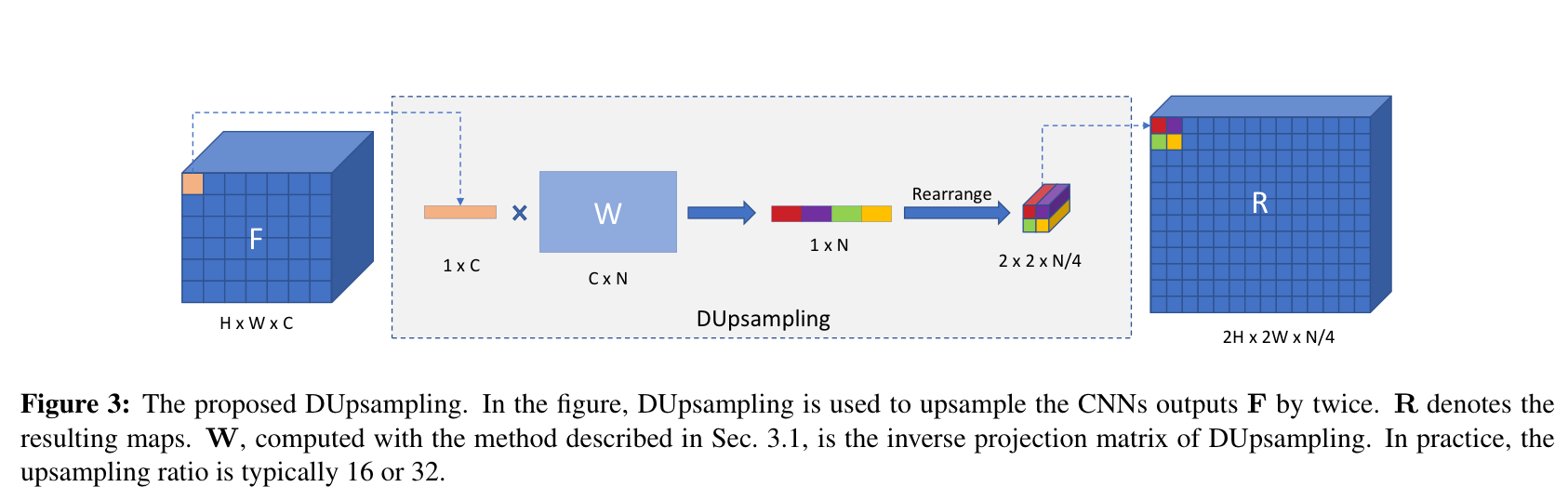
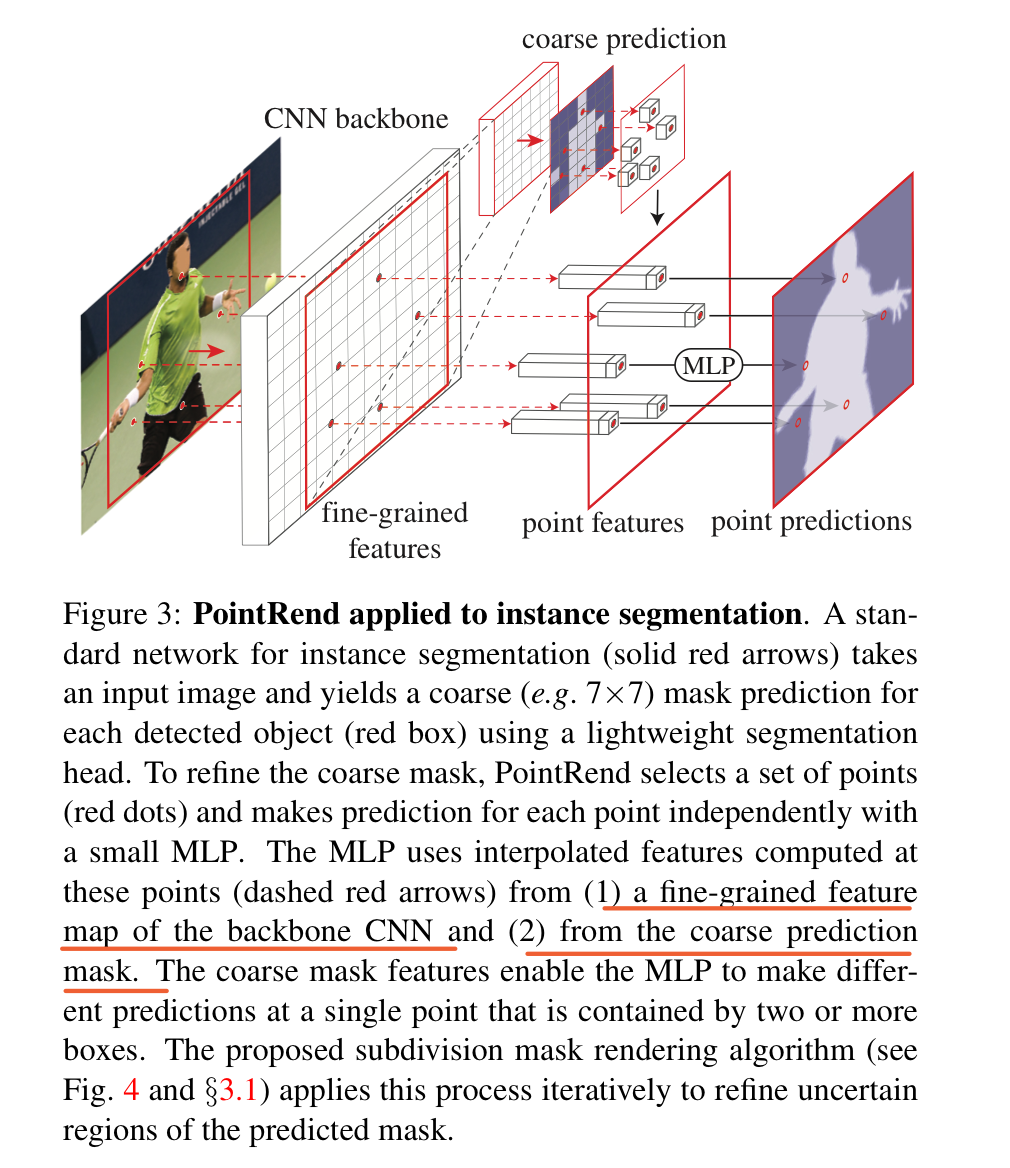
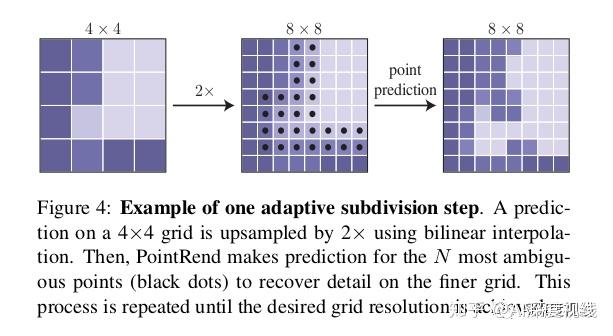
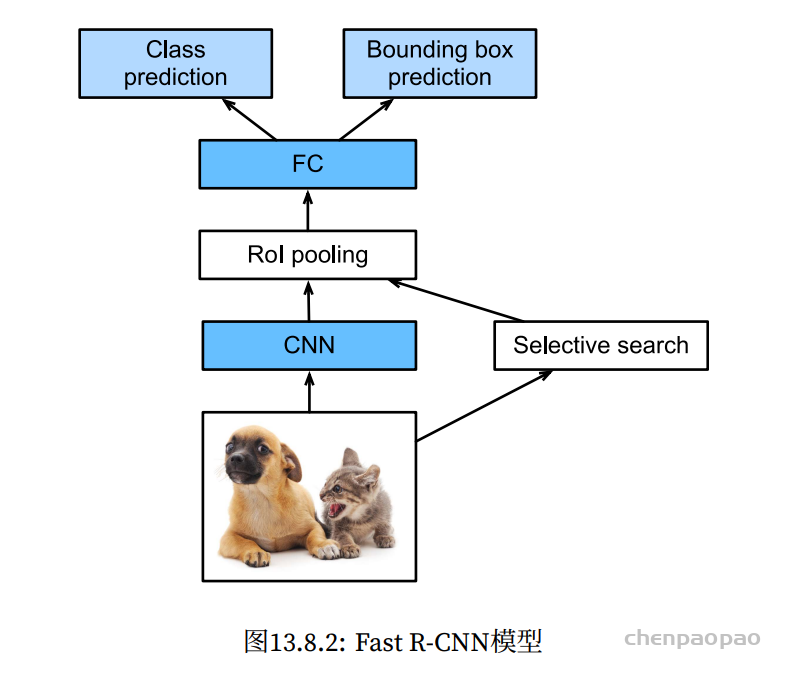
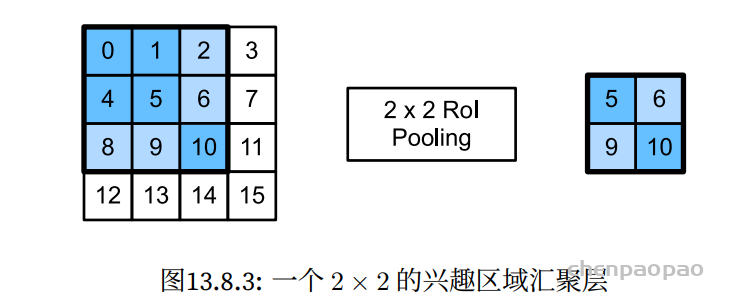
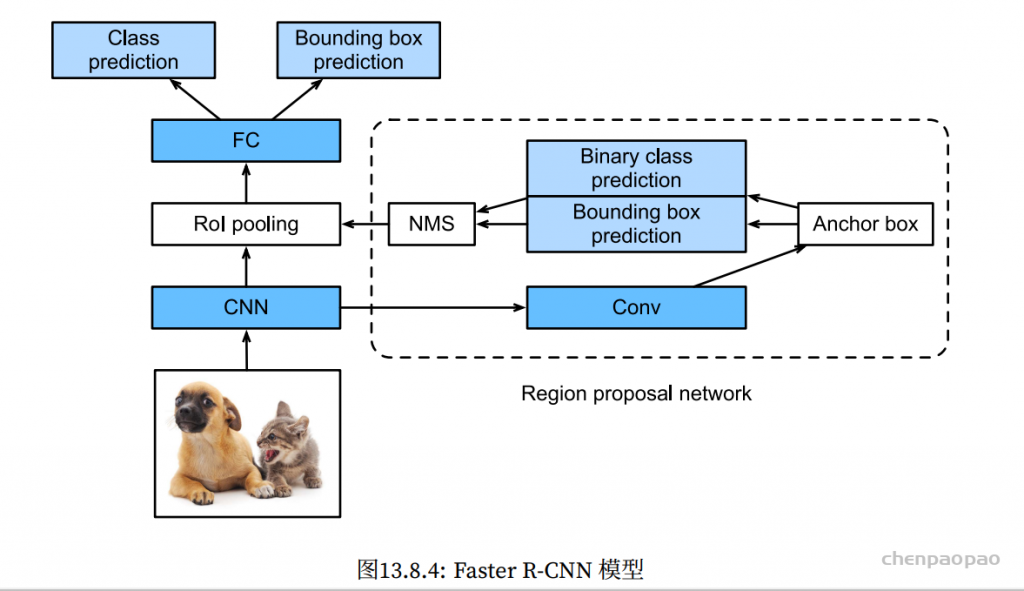
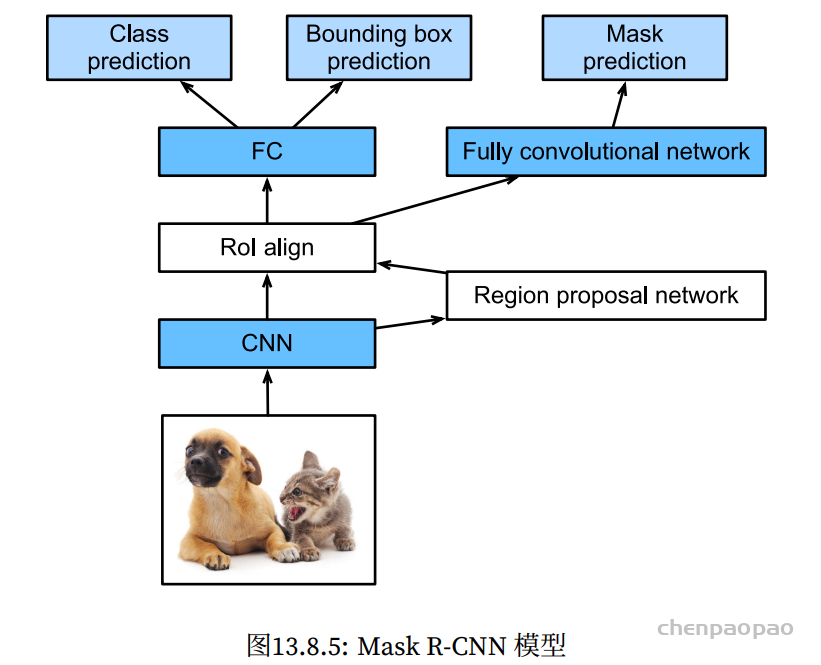
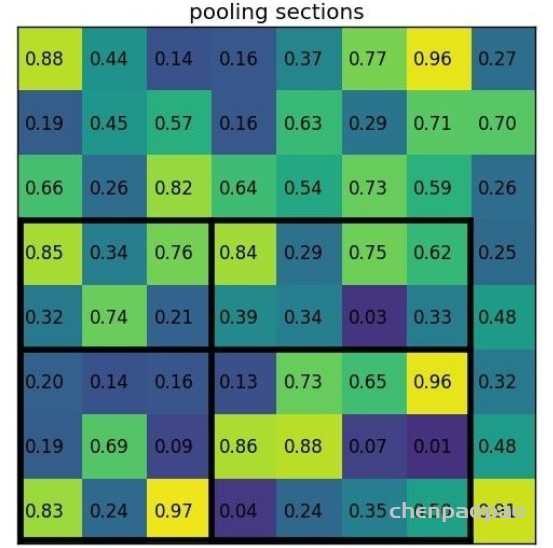
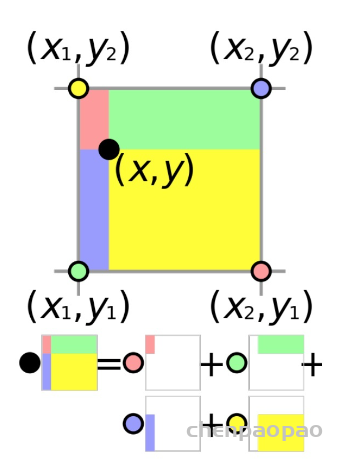
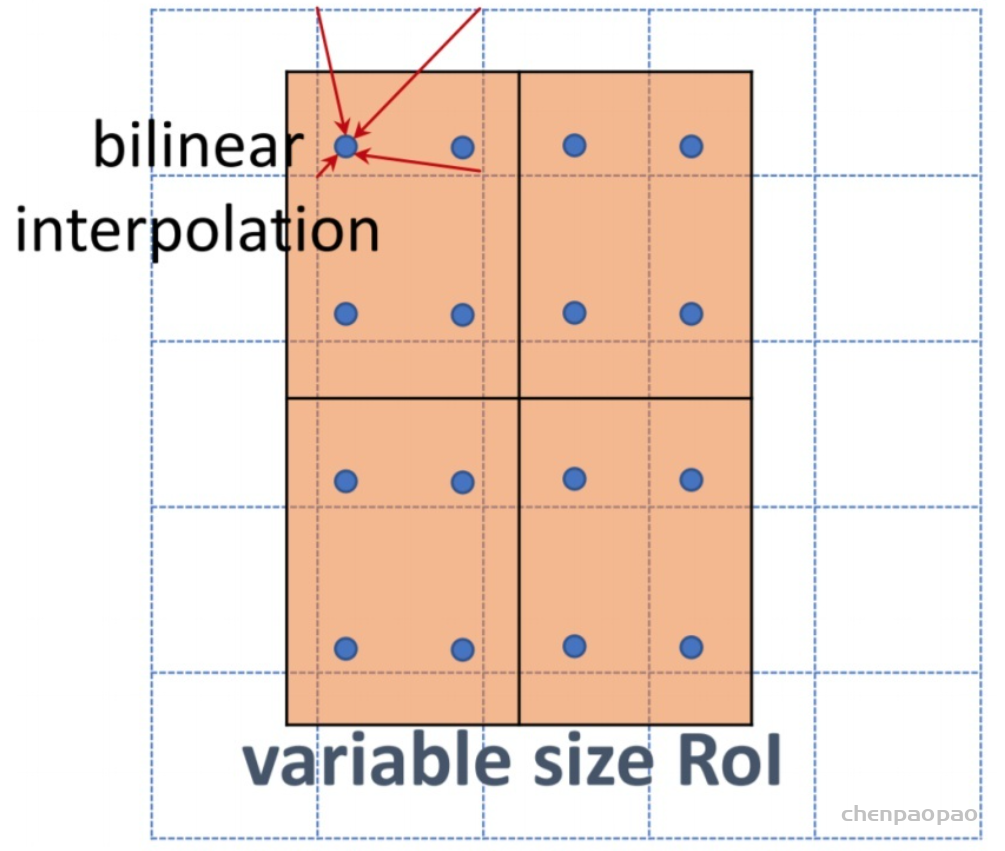
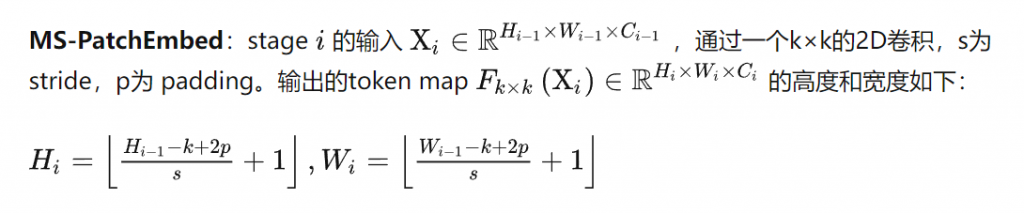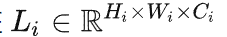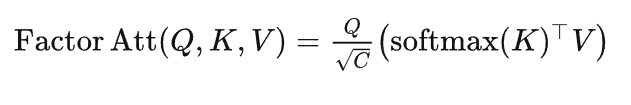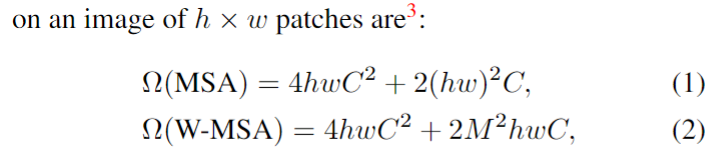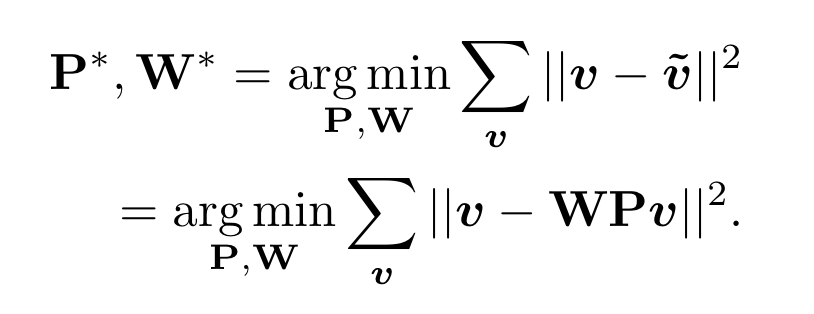In LeViT , a convolutional stem block shows better low-level representation (i.e., without losing salient information) than non-overlapping patch embedding.
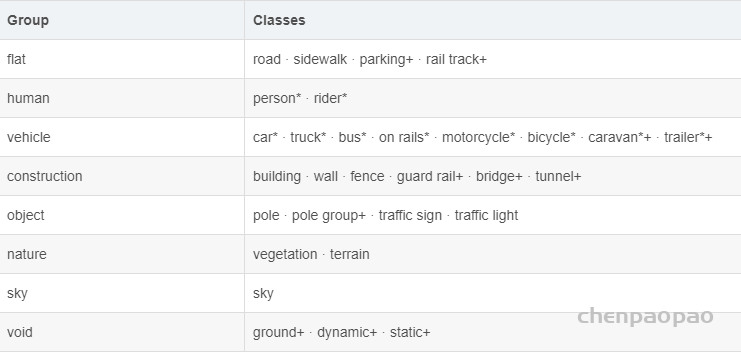
二分图又称作二部图,是图论中的一种特殊模型。 设G=(V,E)是一个无向图,如果顶点V可分割为两个互不相交的子集(A,B),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in A,j in B),则称图G为一个二分图。简而言之,就是顶点集V可分割为两个互不相交的子集,并且图中每条边依附的两个顶点都分属于这两个互不相交的子集,两个子集内的顶点不相邻。
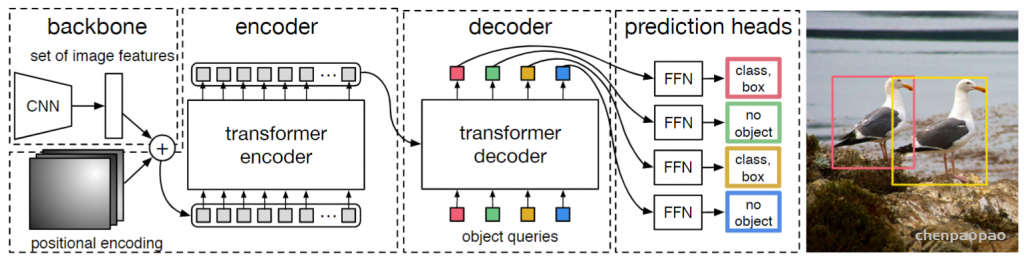
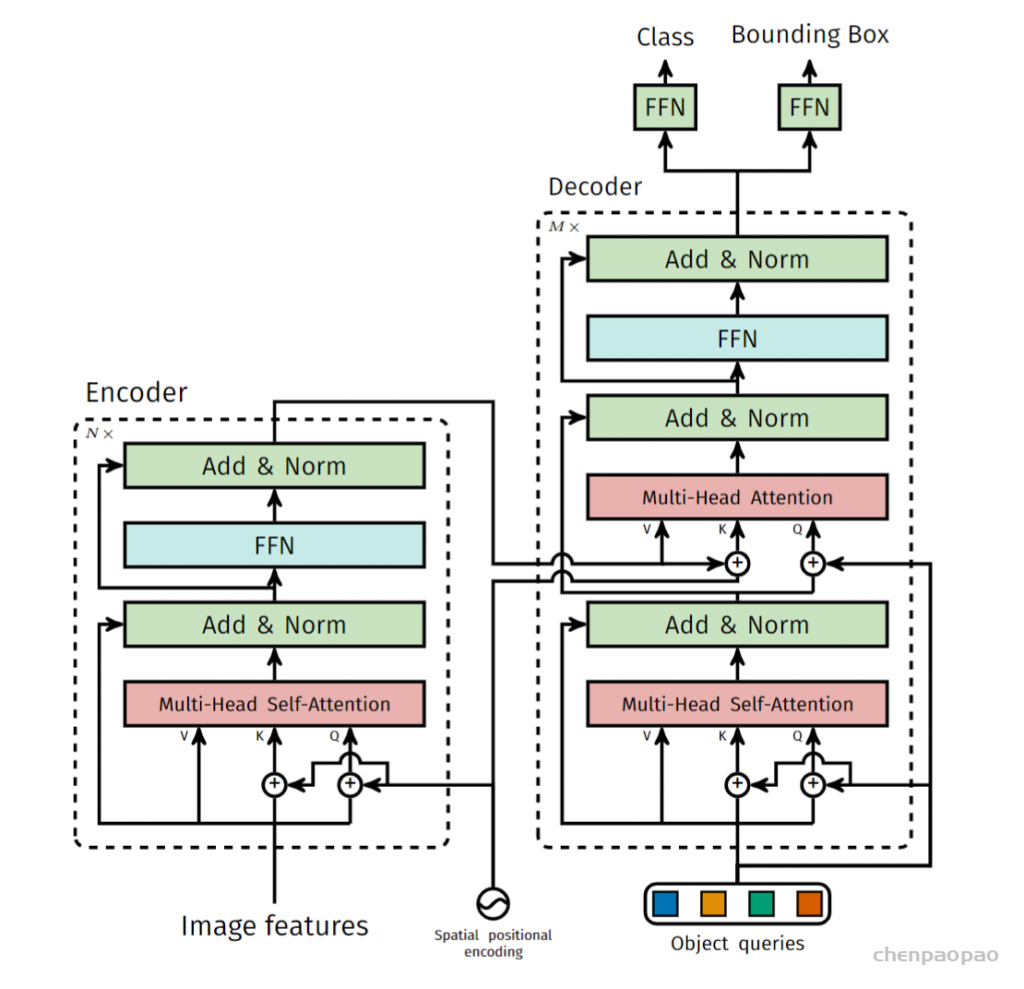
另外scipy包提供的linear sum assignment可以完成这个最优排列。detr论文里:代码也用的linear sum assignment函数来计算对应的匹配关系,只需要提供一个cost matrix矩阵就可以。a,b,c看成100个预测框,x,y,z看成GT框, cost matrix 损失矩阵未必都是正方形,最后丢到这个函数里面得到一个最优匹配。
cd $CITYSCAPES_ROOT
# 训练和校准对应的数据集
ls leftImg8bit/train/*/*.png > trainImages.txt
ls leftImg8bit/val/*/*.png > valImages.txt
# 训练和校准标签对应的数据集
ls gtFine/train/*/*labelIds.png > trainLabels.txt
ls gtFine/val/*/*labelIds.png.png > valLabels.txt
# 训练和校准实例标签对应的数据集
ls gtFine/train/*/*instanceIds.png > trainInstances.txt
ls gtFine/val/*/*instanceIds.png.png > valInstances.txt
# 训练和校准深度标签对应的数据集
ls disparity/train/*/*.png > trainDepth.txt
ls disparity/val/*/*.png.png > valDepth.txt
另外,torchvision支持很多现成数据集:
Class Definitions:
cityscapesscripts 脚本工具:
cityscapes scripts公开以下工具:
csDownload: 命令行下载cityscapes包
csViewer: 查看图像并覆盖批注(overlay the annotations)。
csLabelTool: 标注工具.
csEvalPixelLevelSemanticLabeling: Evaluate pixel-level semantic labeling results on the validation set. This tool is also used to evaluate the results on the test set.像素级评估
csEvalInstanceLevelSemanticLabeling: Evaluate instance-level semantic labeling results on the validation set. This tool is also used to evaluate the results on the test set.实例级评估
csEvalPanopticSemanticLabeling: Evaluate panoptic segmentation results on the validation set. This tool is also used to evaluate the results on the test set.全景分割评估
csCreateTrainIdLabelImgs: Convert annotations in polygonal format to png images with label IDs, where pixels encode “train IDs” that you can define in labels.py.将多边形格式的注释转换为带标签ID的png图像,其中像素编码“序列ID”,可以在labels.py中定义。
csCreateTrainIdInstanceImgs: Convert annotations in polygonal format to png images with instance IDs, where pixels encode instance IDs composed of “train IDs”.将多边形格式的注释转换为具有实例ID的png图像,其中像素对由“序列ID”组成的实例ID进行编码。
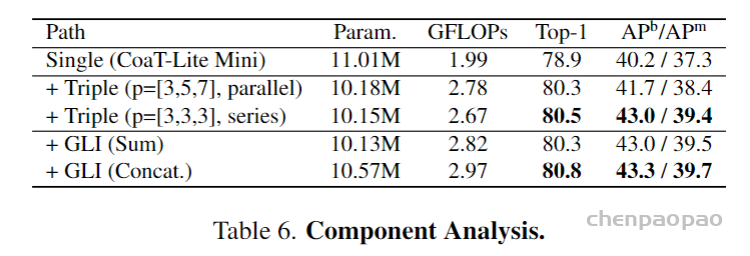
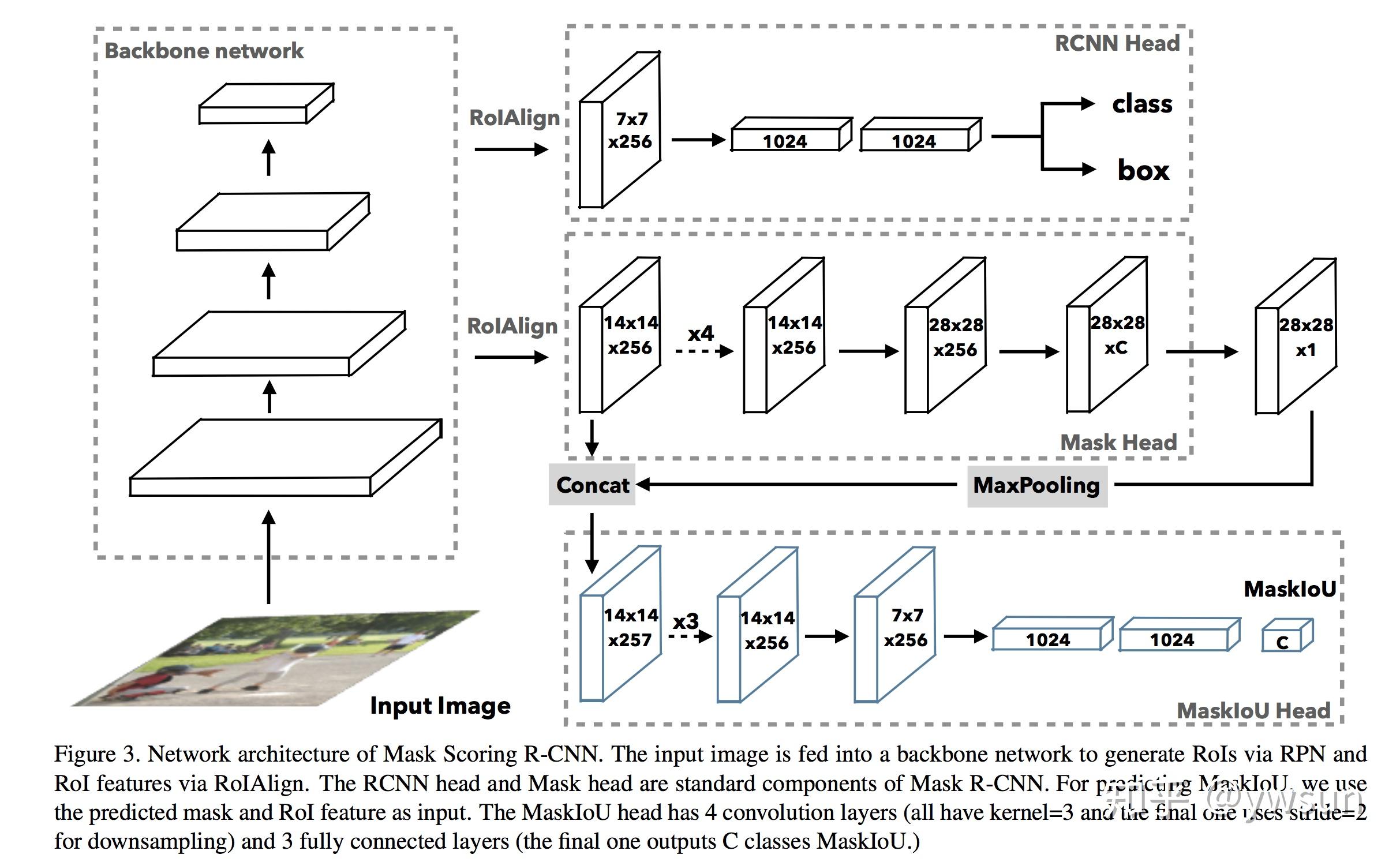
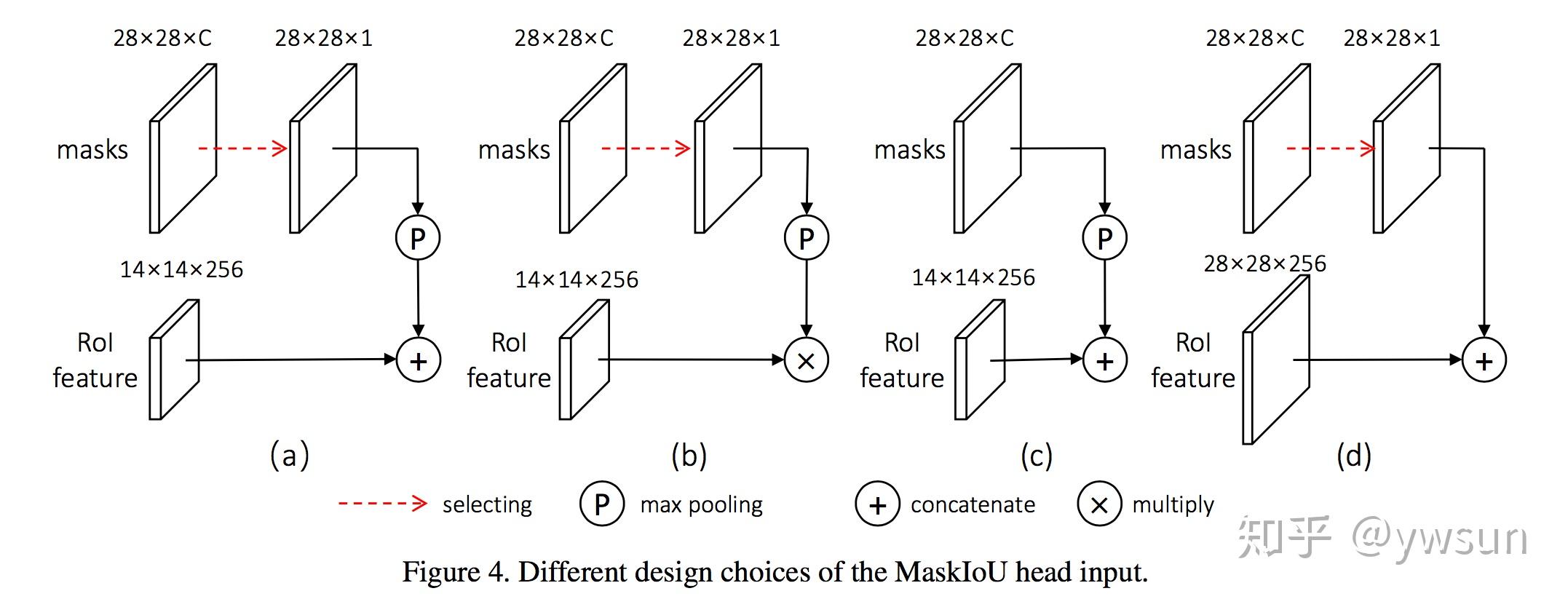
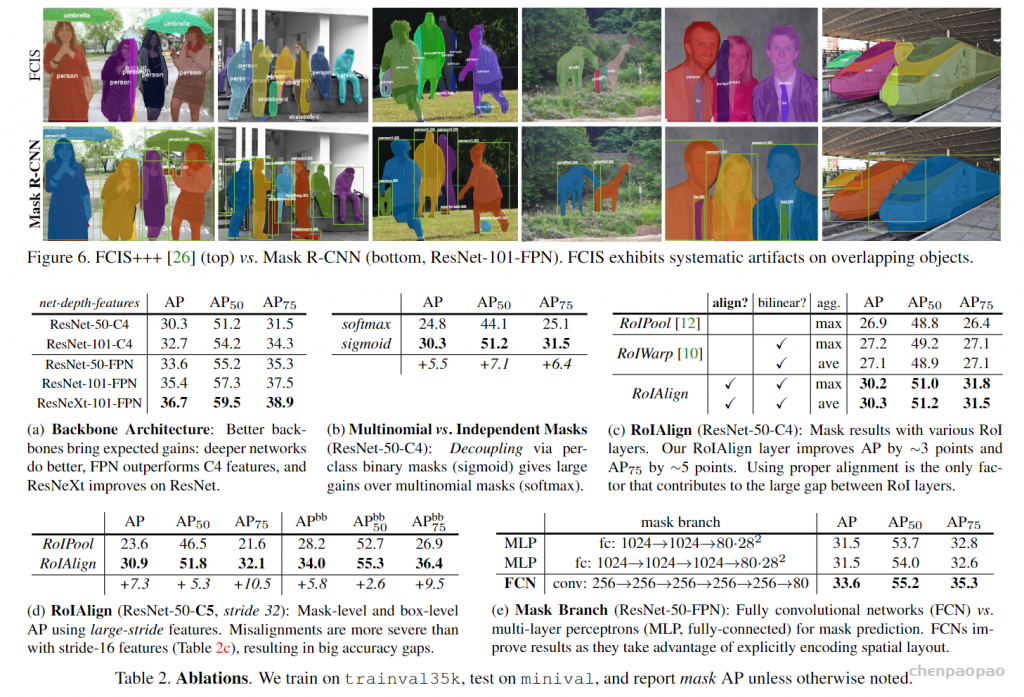
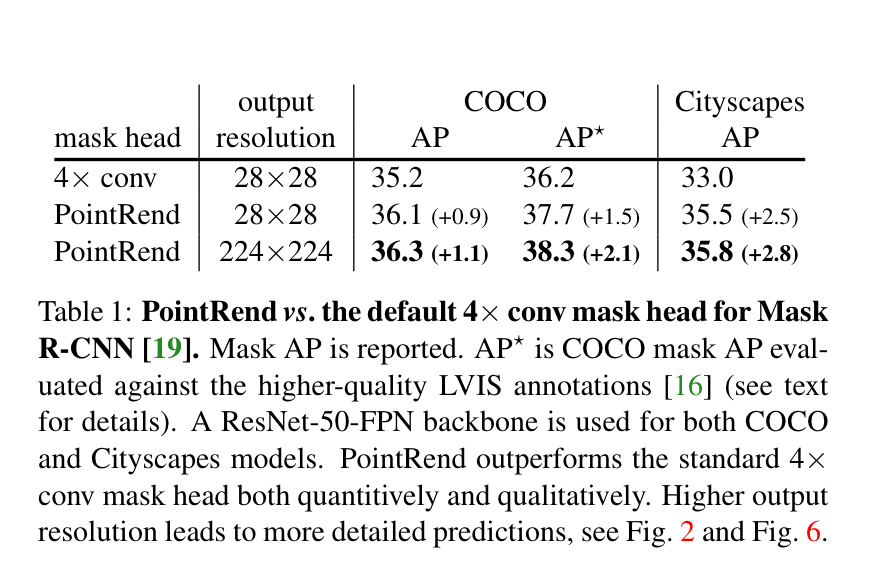
Multinomial vs. Independent Masks:(mask分支是否进行类别预测)从table 2b中可以看出,使用sigmoid(二分类)和使用softmax(多类别分类)的AP相差很大,证明了分离类别和mask的预测是很有必要的
Class-Specific vs. Class-Agnostic Masks:目前使用的mask rcnn都使用class-specific masks,即每个类别都会预测出一个mxm的mask,然后根据类别选取对应的类别的mask。但是使用Class-Agnostic Masks,即分割网络只输出一个mxm的mask,可以取得相似的成绩29.7vs30.3
RoIAlign:tabel 2c证明了RoIAlign的性能
Mask Branch:tabel 2e,FCN比MLP性能更好
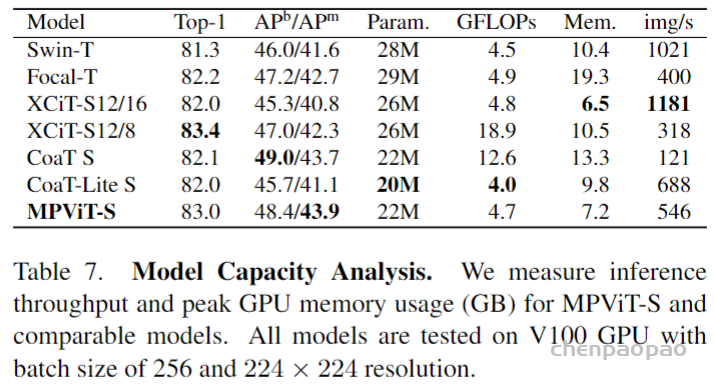
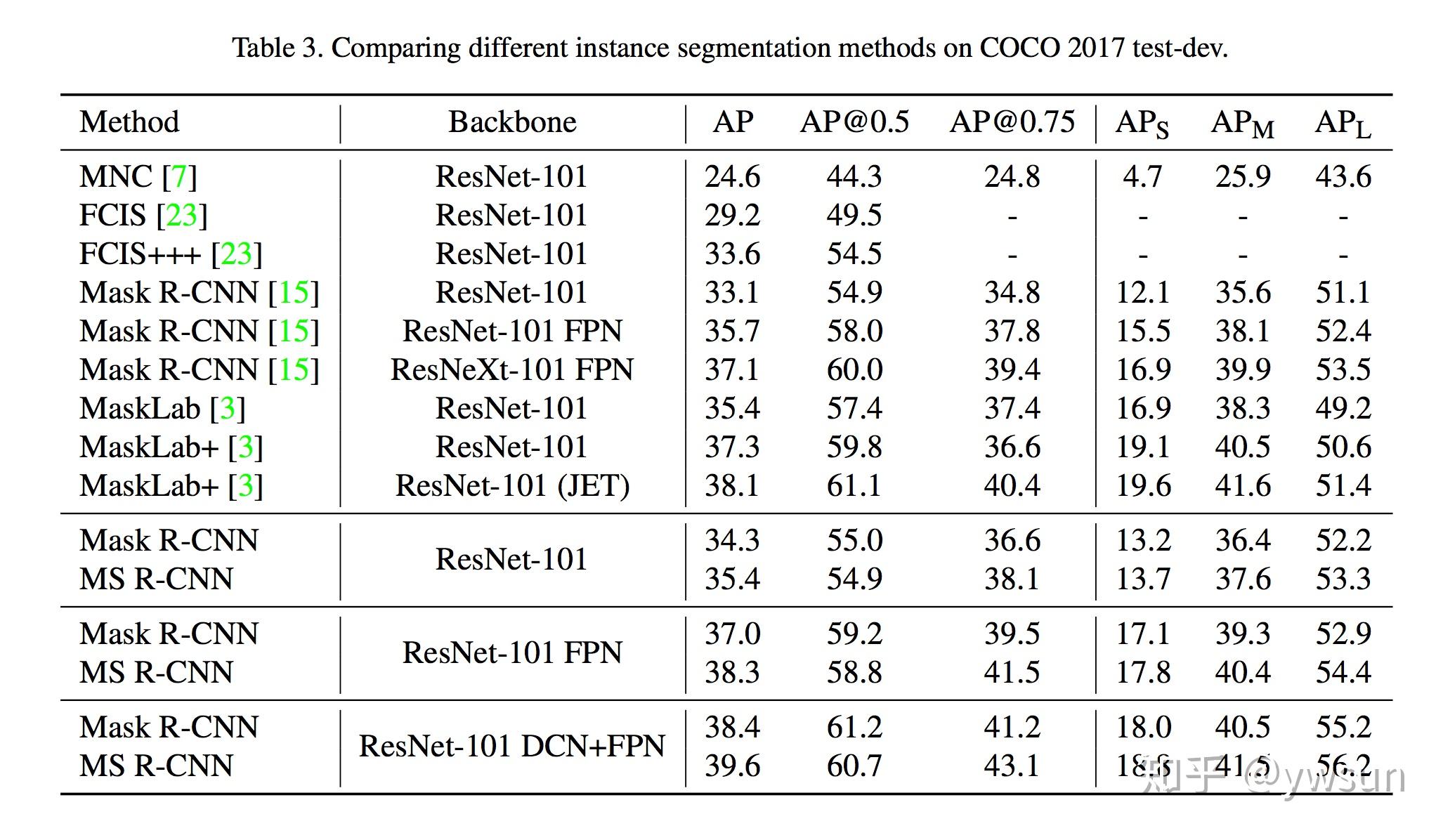
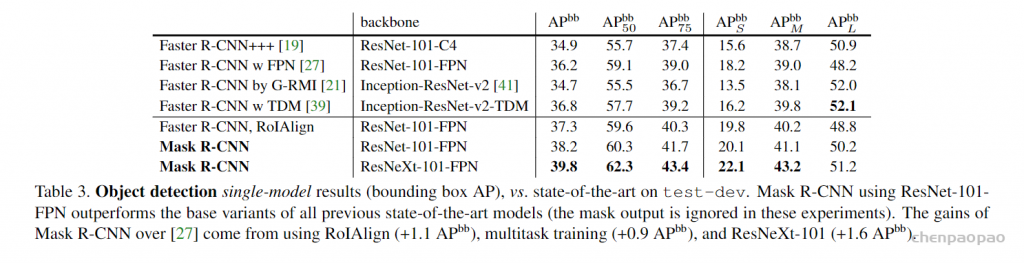
Bounding Box Detection Results
Mask RCNN精度高于Faster RCNN
Faster RCNN使用RoI Align的精度更高
Mask RCNN的分割任务得分与定位任务得分相近,说明Mask RCNN已经缩小了这部分差距。
Timing
Inference:195ms一张图片,显卡Nvidia Tesla M40。其实还有速度提升的空间,比如减少proposal的数量等。
Training:ResNet-50-FPN on COCO trainval35k takes 32 hours in our synchronized 8-GPU implementation (0.72s per 16-image mini-batch),and 44 hours with ResNet-101-FPN。
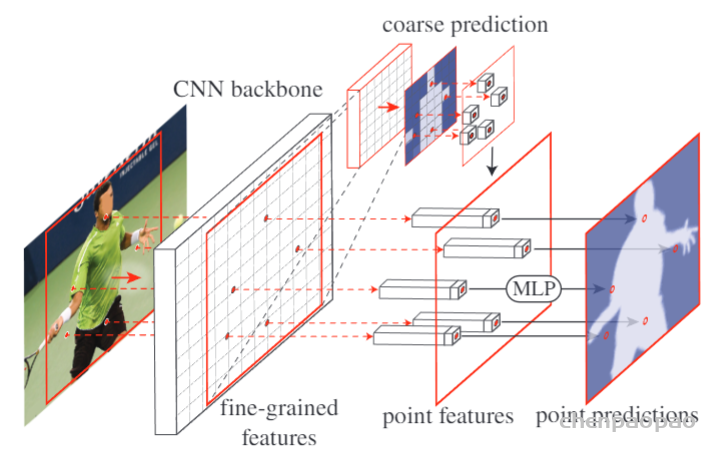
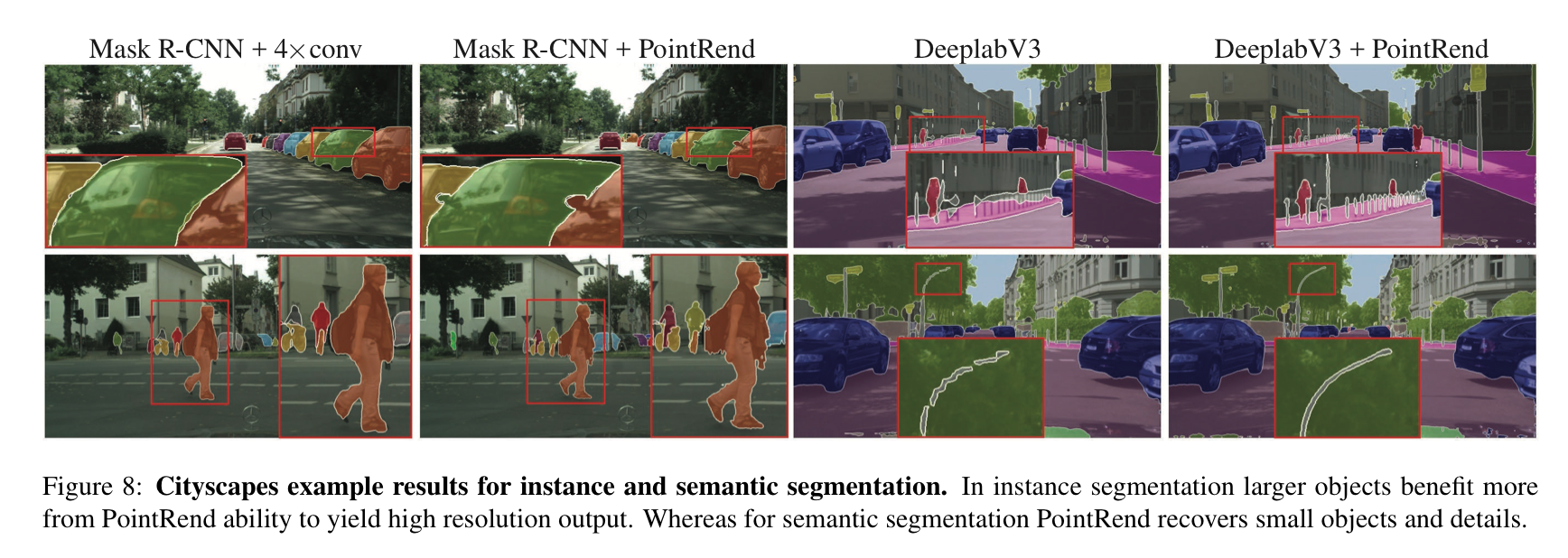
事实上,在图像分割任务上边缘预测不理想这个情况其实在许多前人的工作中都有提及,比如 Not All Pixels Are Equal: Difficulty-Aware Semantic Segmentation via Deep Layer Cascade 中就详细统计了语义分割中,模型最容易误判的 pixel基本上都在物体边缘(如下图右上红色部分标记) 。
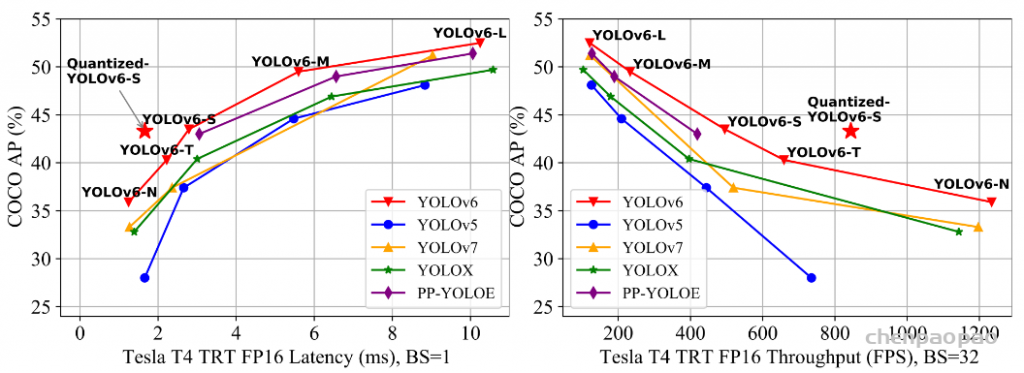
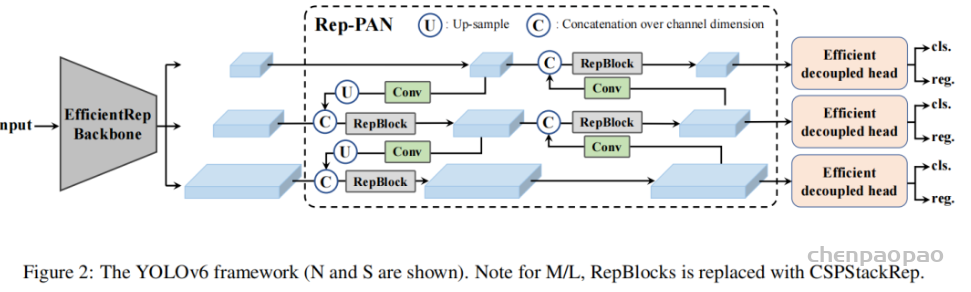
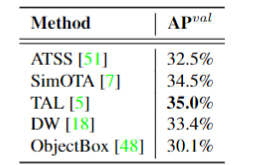
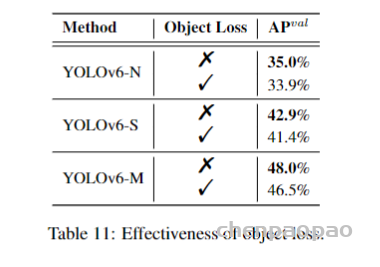
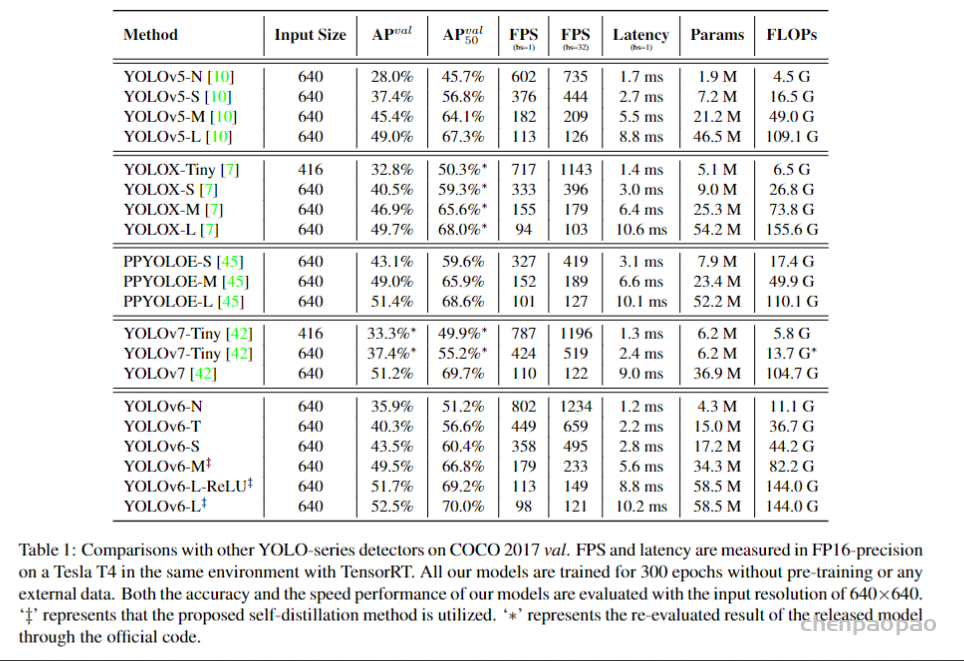
此外,作者观察到 TAL 可以带来比 SimOTA 更多的性能提升并稳定训练。因此,采用 TAL 作为 YOLOv6 中的默认标签分配策略。
2.3、损失函数
1、Classification Loss
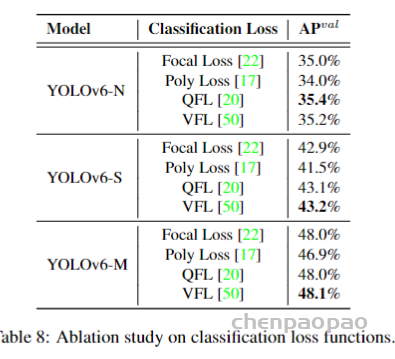
提高分类器的性能是优化检测器的关键部分。Focal Loss 修改了传统的交叉熵损失,以解决正负样本之间或难易样本之间的类别不平衡问题。为了解决训练和推理之间质量估计和分类的不一致使用,Quality Focal Loss(QFL)进一步扩展了Focal Loss,联合表示分类分数和分类监督的定位质量。而 VariFocal Loss (VFL) 源于 Focal Loss,但它不对称地对待正样本和负样本。通过考虑不同重要性的正负样本,它平衡了来自两个样本的学习信号。Poly Loss 将常用的分类损失分解为一系列加权多项式基。它在不同的任务和数据集上调整多项式系数,通过实验证明比交叉熵损失和Focal Loss损失更好。
在 YOLOv6 上评估所有这些高级分类损失,最终采用 VFL。
2、Box Regression Loss
框回归损失提供了精确定位边界框的重要学习信号。L1 Loss 是早期作品中的原始框回归损失。逐渐地,各种精心设计的框回归损失如雨后春笋般涌现,例如 IoU-series 损失和概率损失。
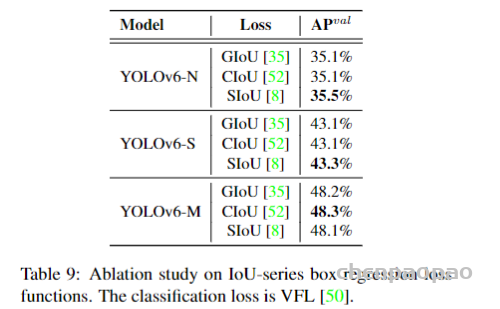
IoU-series Loss IoU loss 将预测框的四个边界作为一个整体进行回归。它已被证明是有效的,因为它与评估指标的一致性。IoU的变种有很多,如GIoU、DIoU、CIoU、α-IoU和SIoU等,形成了相关的损失函数。我们在这项工作中对 GIoU、CIoU 和 SIoU 进行了实验。并且SIoU应用于YOLOv6-N和YOLOv6-T,而其他的则使用GIoU。
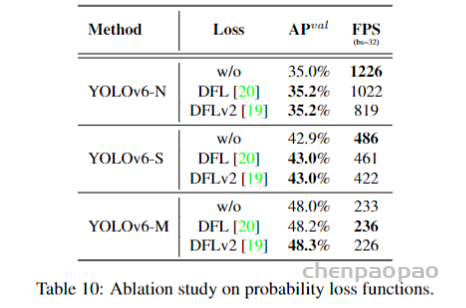
Probability Loss Distribution Focal Loss (DFL) 将框位置的基本连续分布简化为离散化的概率分布。它在不引入任何其他强先验的情况下考虑了数据中的模糊性和不确定性,这有助于提高框定位精度,尤其是在ground-truth框的边界模糊时。在 DFL 上,DFLv2 开发了一个轻量级的子网络,以利用分布统计数据与真实定位质量之间的密切相关性,进一步提高了检测性能。然而,DFL 输出的回归值通常比一般框回归多 17 倍,从而导致大量开销。额外的计算成本阻碍了小型模型的训练。而 DFLv2 由于额外的子网络,进一步增加了计算负担。在实验中,DFLv2 在模型上为 DFL 带来了类似的性能提升。因此,只在 YOLOv6-M/L 中采用 DFL。