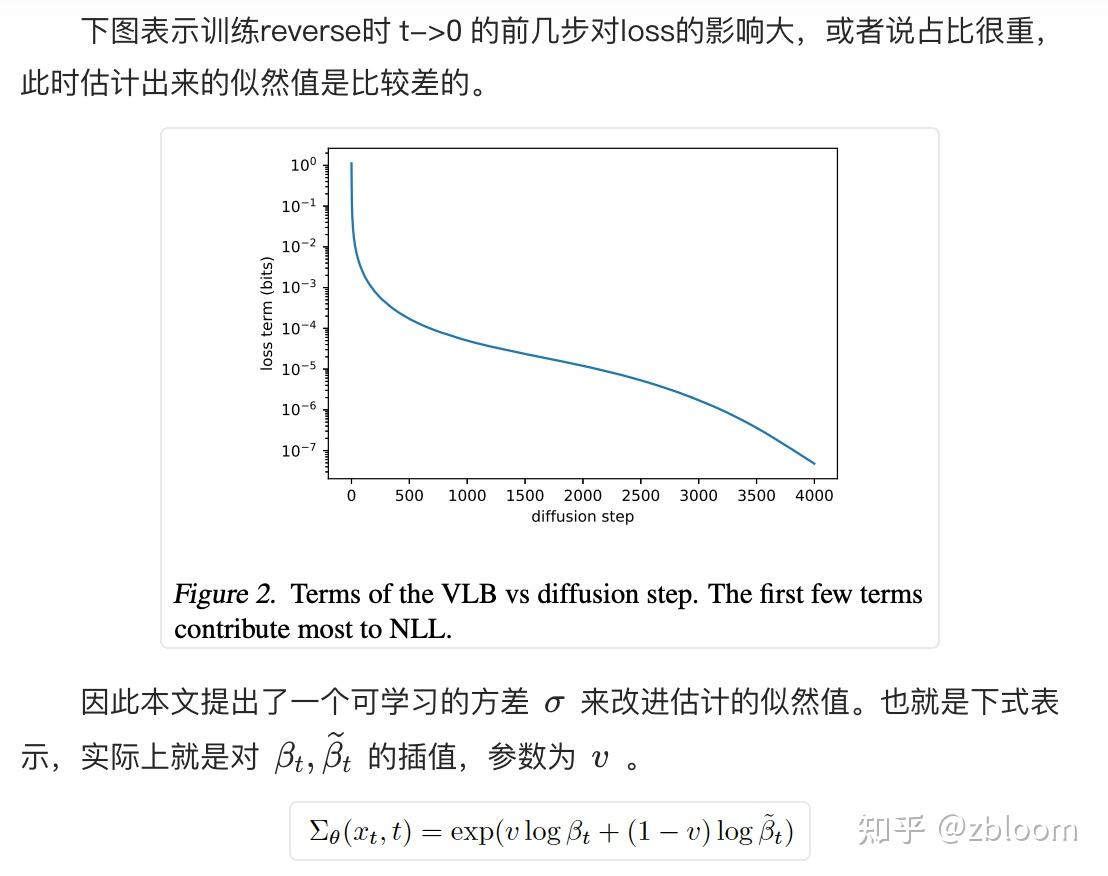
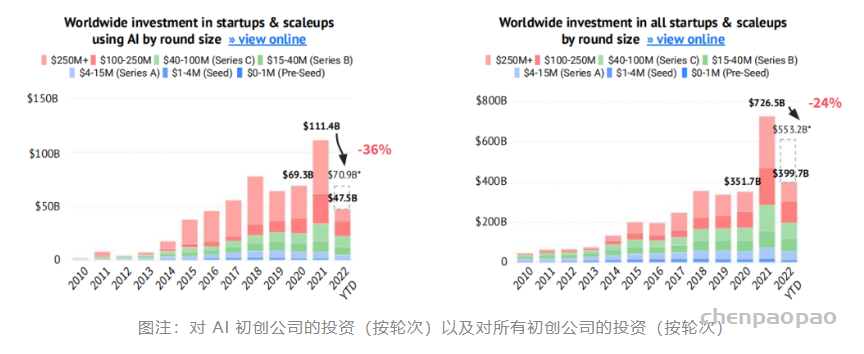
网格有多种,三角形,四边形或者其他的多边形。但是目前使用最多的,也是本文着重介绍的是三角网格。三角网格是计算机中表示三维模型最重要的方法。这篇文章主要介绍一下网格的相关概念以及技术算法。
定义
网格就是使用多边形来表示物体的表面。一个网格模型的描述之前也说到过,它包含一系列的面片和顶点。
面片F=(f1,…,fn)F=(f1,…,fn),对于三角网格,每个面片都是三角形。
顶点V=(v1,…,vm)V=(v1,…,vm)。其中,每个面片又是由3个顶点构成的三角形,因此:fi=(vi1,vi2,vi3);vi1,vi2,vi3∈V.fi=(vi1,vi2,vi3);vi1,vi2,vi3∈V.
网格的由来
计算机生成的三维模型和实际获取的数据表示模式是不同的。计算机生成的模型可能是平滑曲线曲面,而实际获取的数据,如激光扫描得到的,一般都是以点云的形式存在。图形学中需要一个统一的表示方式,同时要求视觉精度和处理速度都在可以接受的范围内。于是就选择了网格,用多边形来近似曲面,三角网格最为简单高效,再加上图形硬件的快速发展,三角网格和光栅化已经可以嵌入到硬件中去渲染。
三维数据的来源
一般来说,获取三维模型数据的方法有多种。我们可以直接在几何文件中输入,也可以通过程序创建,比较高级的建模软件有3Ds/max,maya等。第二种就是通过激光扫描,结构光技术等等获取深度,得到点云模型。也有一些别的方法,如SFM,从多视图(多张照片)中构建三维模型。
三维模型又可以分为实体模型和表面模型。
- 实体模型,多用于CAD领域,通常强调对应实际工业生产中的加工过程,如切割,钻孔等。它是实心的而非空心,在显示过程中需要考虑很多的东西,占用内存较大,因此不利于显示。
- 表面模型,我们平时见到的模型多是表面模型,只考虑物体的表面细节并直接进行处理,这种模型易于显示。
网格化
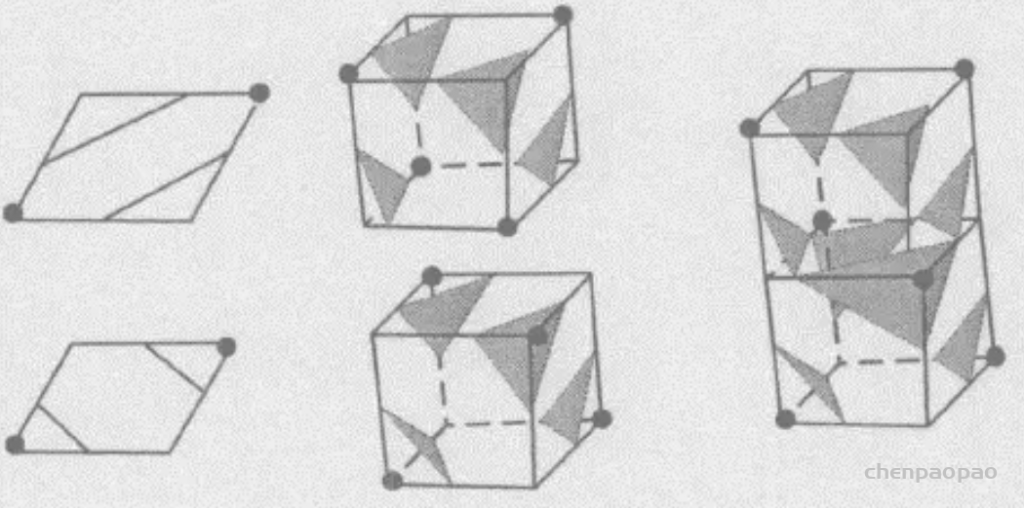
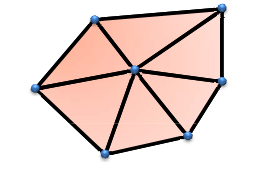
网格化是指将模型(点云,多边形等等)分割称为更容易处理的图元,如凸多边形,三角形或者四边形。如果分割成三角形,被称为三角化。我们先看看2D网格化,而3D空间中的网格化也和2D中类似。

如上图,最左侧的多边形不能被称作网格化,第二个是凸多边形网格化,第三个是三角化,最右侧是被均匀分割。
这里介绍两个三角网格化的非常简单的算法。
- 基本的网格化算法
给定多边形,检验其任意两个顶点之间的线段是否与该多边形的边相交或者部分重叠。如果是,则不能用于分割三角形,否则,用该线段来将多边形分成两个多边形,对每个部分继续上述算法。
- 割耳(ear clipping)算法
首先找到多边形的ear:查看所有具有顶点序列i,i+1,i+2(modn)i,i+1,i+2(modn)的三角形,称这个三角形为顶点为i+1i+1的三角形,检查线段i,i2i,i2是不是没有与任何边相交。如果是,则这个三角形构成一个ear,去掉该ear,检查顶点ii和i+2i+2处的三角形是不是构成ear。重复上述过程。这个算法每次都会分出一个新的三角形。
上述两种算法对凹多边形进行三角化,会使得其变成凸多边形的样子。原本不是面的部分由于三角化而多了面片。
除此之外,我们还需要注意一种特殊的情况叫T型顶点:

它最常出现在网格细分或者网格简化过程中,使得一个顶点出现在了某个面片的边上。理论上这个点是完全在边上,但是实际渲染中顶点的位置可能不会那么精确。当一个模型中有T顶点存在,一些算法可能会失败。
网格简化
网格的简化有很多好处。比如当前我做的项目中,就需要网格简化来节省内存。同时,网格简化还有很多好处。
- 减少几何冗余:如果一个具有很多共面小三角形的平坦区域,可以将这些小三角形合并成大的多边形来降低模型复杂度。
- 减小模型大小
- 提高运行性能
而且有时候,对于网格的简化,并不会引起多大的感官差异,例如我们可以对较远的场景进行网格简https://www.baidu.com/baidu?wd=163&tn=ubuntuu_cb&ie=utf-8的东西看不清,复杂的网格和简化之后的网格差别不大。这也是当前很多游戏能实时运行的一个重要的技术,叫做生成场景中物体的层次细分。
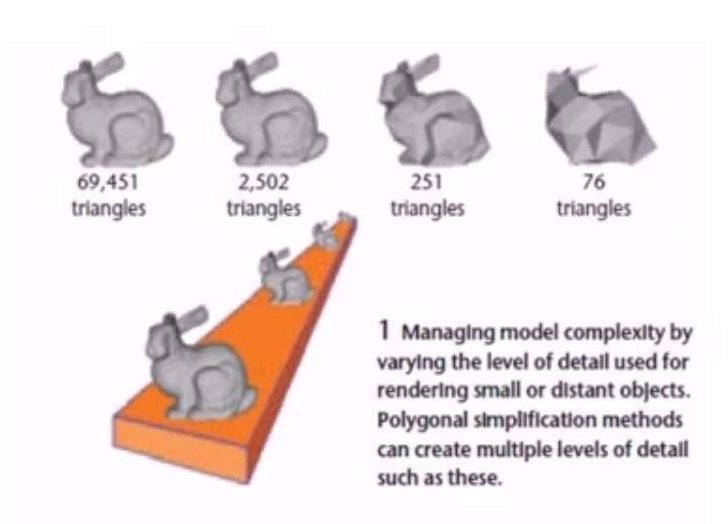
拓扑结构
拓扑结构指的是多边形网格的连接结构。有一些专业术语需要了解一下,对于网格简化,细分等会用到。
- 亏格(genus)
亏格指的是网格表面孔洞的数目。如下:

- 面片,边或顶点的拓扑结构,指相邻元素的局部连接关系。如下图:

临界边只接一个三角形, 普通边接两个三角形, 奇异边接三个三角形。对于没有临界边的网格称为closed mesh。
- 二维流形(2-manifold)
二维流行网格定义如下:
- 一条网格边为一个或两个网格三角面片共享;
- 一个网格顶点的一环邻域三角片构成一个闭合或者开放的扇面。
看上去不好理解,看图片就比较好明白。
非流形网格:
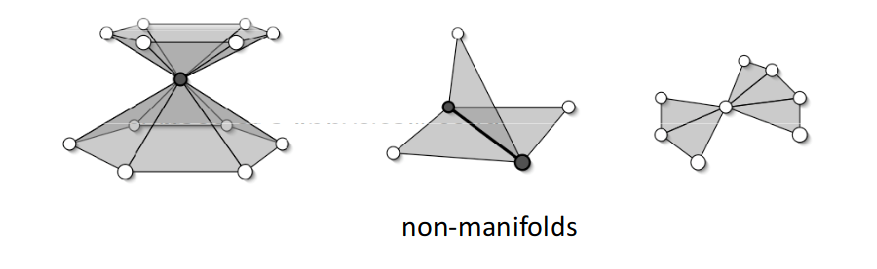
流形网格:
很显然,流形网格只包含临界边和普通边。
网格简化的方法有很多,但是不外乎是下面四种的改进或者组合。
- 采样(sample)。很好理解,简单的选取模型表面上的点进行几何采样,编程较为复杂。这种方法对高频特征难以精确采样,通常在没有尖角的光滑表面上能取得最好的效果。
- 自适应细分(adaptive subdivision)通过寻找一个可以递归细分逼近最初模型的基网格,该算法在基模型容易获取的情况下能取到很好的效果,但是它会保持表面拓扑细节,因此对模型进行大规模简化的能力不足。
- 去除(decimation)。去除方法迭代地去除网格上的顶点或者面片,并三角化每次去除后的空洞。这类方法比较简单,易于编程实现而且运行效率也较高,且通常保持原有的亏格,尤其适用于处理像共面多边形这种冗余的几何。
- 顶点合并(vertex merging)。顶点合并一般将多个顶点合并成一个顶点,该算法也比较好实现,但是需要采用多种技术来确定哪些点被合并以及合并次序。
有一个例子是边坍塌算法,将共边的两个顶点合并为一个点,该算法通常保持局部拓扑,但也允许修改拓扑。
细分
网格的细分和简化相反。对于一个给定的原始网格,通过网格细分产生更光滑的效果。细分广泛应用于电影行业,实际上算法提出者之一Catmull还是皮克斯和迪士尼的总裁。
下面是几个细分的例子:
一维细分,原本是4个点的线段,通过向中间插入点得到下一张图,不断迭代得到圆滑曲线。

三维网格细分,根据特定细分规则,每次细分每一个三角形被细分成4个小的三角形。
细分可以看做是一个两阶段过程,最初的网格被称为控制网格。
- 细化阶段,创建新的顶点并与先前顶点相连,产生新的更小的三角形
- 平滑阶段,计算新顶点的位置
这两步的细节决定了不同的细分方案,在第一步中一个三角形可以以不同的形式进行分割,第二部新顶点的位置可以以不同的方式插值产生。
Loop细分
Loop细分是第一个基于三角网格的细分方案。它更新每个已有的顶点,并对每条边创建一个新的顶点,这样每个三角形被分割成4个新的三角形。经过n步细分,一个三角形被分割成4n4n个三角形。
下图为一个loop细分的例子,新的顶点以黑色显示。
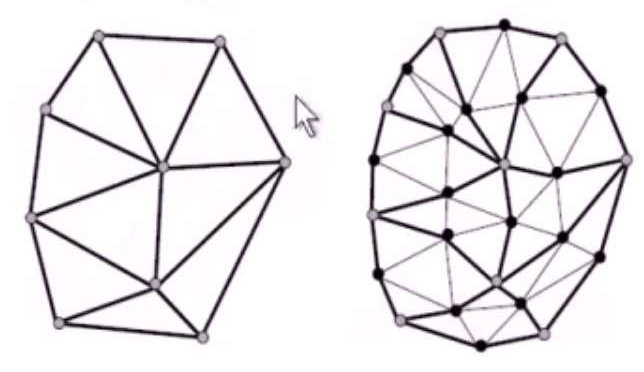
为了更好说明Loop细分的步骤

下图中左侧给出了第二个公式的相关点,右侧给出了第一个公式的相关点:
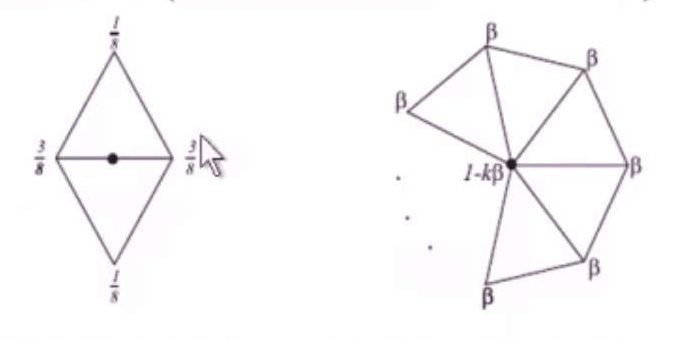
β是n的函数
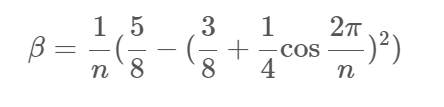
√3细分
另外有一种细分方法,被称为3–√3细分。和Loop细分不同的地方在于,Loop把每个三角形划分成4个三角形,而3–√3细分把每个三角形细分成3个三角形。这意味着新增加的顶点在原三角形内部。不过,很明显内部点直接与各个点连线构成的三角形很奇怪,如下图中的第二张。而3–√3在连线之后,会做一个边翻转,把原来的边删掉,而连接新的顶点的作为边,像是把原来的边进行了一个翻转,如下图中最后一张: