
paper:https://arxiv.org/abs/2107.10224
作者单位:香港大学, 商汤科技
代码:https://github.com/ShoufaChen/CycleMLP
核心:用 Cycle-FC来替换Spatial FC(计算量大且网络对于不同图像分辨率的输入不可接受,且不能用于下游任务)
本文提出了一个简单的 MLP-like 的架构 CycleMLP,它是视觉识别和密集预测的通用主干,不同于现代 MLP 架构,例如 MLP-Mixer、ResMLP 和 gMLP,其架构与图像大小相关,因此是在目标检测和分割中不可行。
与现代方法相比,CycleMLP 有两个优势。
(1) 可以应对各种图像尺寸。
(2) 利用局部窗口实现对图像大小的线性计算复杂度。
相比之下,以前的 MLP 具有二次计算,因为它们具有完全的空间连接。
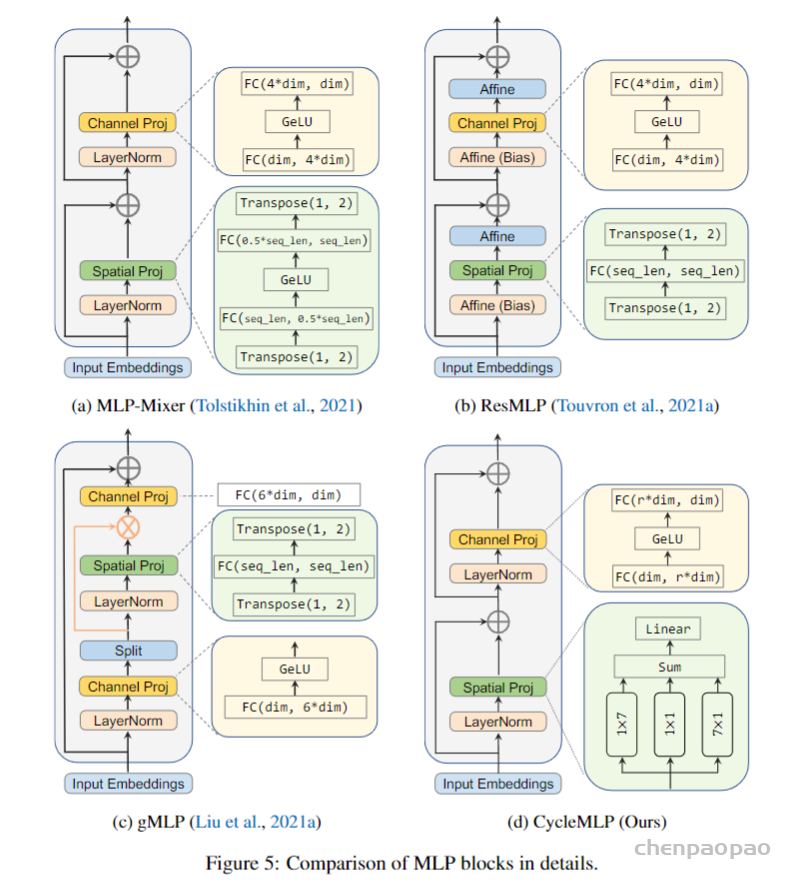
单个 CycleMLP Block 依然是分为 Token-mixing MLP 和 Channel mixing MLP,其中作者主要的贡献点在于替换 MLP-mixer 的 Token-mixing MLP 为 Cycle-FC。所以整个 CycleMLP Block 可以描述为:

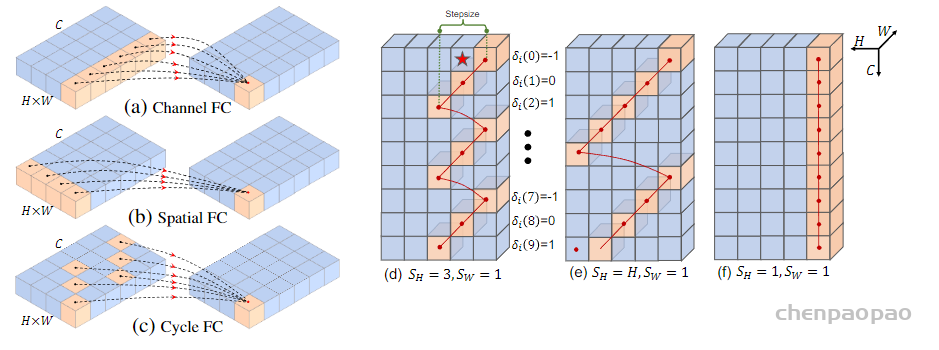
何为 Cycle-FC ?要回答这个问题,我们首先来回顾一下 Channel FC 以及 Spatial FC.
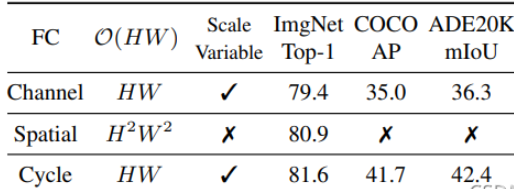
Channel FC 即通道方向的映射,等效与1×1 卷积,其参数量与图像尺寸无关,而与通道数(token 维度)有关。假设输入输出特征图尺寸一致,则参数量为 C^2,其中 C 为通道数。而计算量则为 HWC^2,其中 H W 分别为特征图的高和宽。如果只考虑计算量与图像尺寸的影响的话,则为 O ( H W ) 。
Spatial FC 即 MLP-Mixer 使用的 Token-mixing 全连接层,在这里我们都是只考虑一个全连接层,则其实现的是 H W − > H W 的映射,参数量为 H^2W^2,计算量也为 H 2 W 2 C H^2W^2C,如果只考虑计算量与图像尺寸的影响的话,则为 O(H^2W^2)。并且HW 大小固定,网络对于不同图像分辨率的输入不可接受,且不能用于下游任务以及使用类似 EfficientNetV2 等的多分辨率训练策略。
为什么我们可以在复杂度分析时只考虑 H W 的影响呢?因为在金字塔结构的 MLP 中,通常一开始的 patch size 为 4,然后输入尺寸为 224×224,则一开始的 H = W = 56 = 224 / 4 ,而 C = 64 或者 96 ,所以C≪HW。如果对于下游任务而言,例如输入变为了512×512,则它们之间的差距更大了。为此在这里我们可以在复杂度分析中暂时只考虑 H W 而忽略 C 。
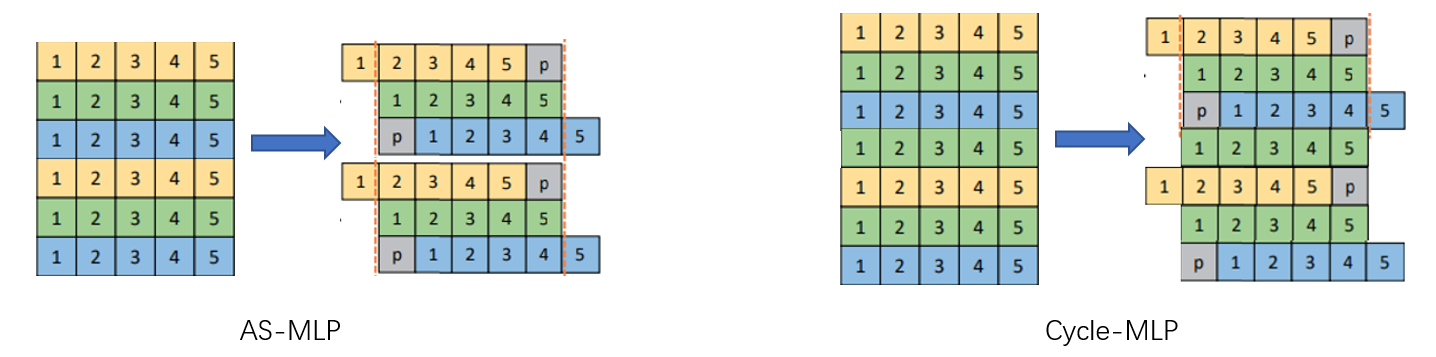
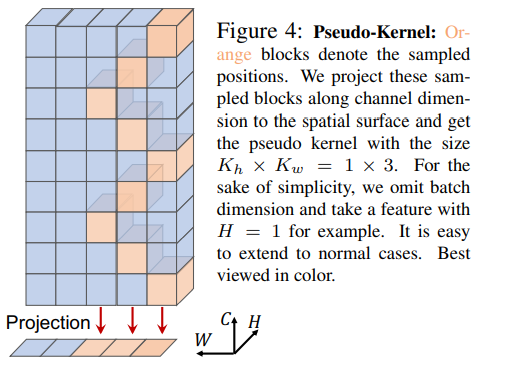
为了同时克服 Spatial 对于图像输入尺寸敏感以及计算量大的问题,作者提出了 Cycle-FC。其只是用通道方向的映射并且计算量和 Channel FC 保持一致。其说白了就是不断地以 [+1 0 -1 0 +1 0 -1 0 +1 …] 的方式移动特征图,将不同空间位置的特征对齐到同一个通道上,然后使用1×1 卷积。
回忆 AS-MLP,其采用的特征图移动方式则为 [+1 0 -1 +1 0 -1 +1 0 -1] 这样的成组方式,CycleMLP 则是使用“楼梯型”方式,但是其思想没有本质不同。此外,AS-MLP 确实对特征图进行了 Shift,并且采用了 zero-padding,而 CycleMLP 在具体实现过程中则是使用可变形卷积加以实现的。我个人对于 AS-MLP 与 CycleMLP 的理解如下图所示,可见他们其实核心思想是一致的。
from torchvision.ops.deform_conv import deform_conv2d
CycleMLP 与 AS-MLP 只并行 H 和 W 方向的移动不同,CycleMLP 其实是三条支路并行:H 方向,W 方向,以及不移动特征图做通道方向映射。此外,AS-MLP 在一开始还做了一次 Channel Projection 进行降维。
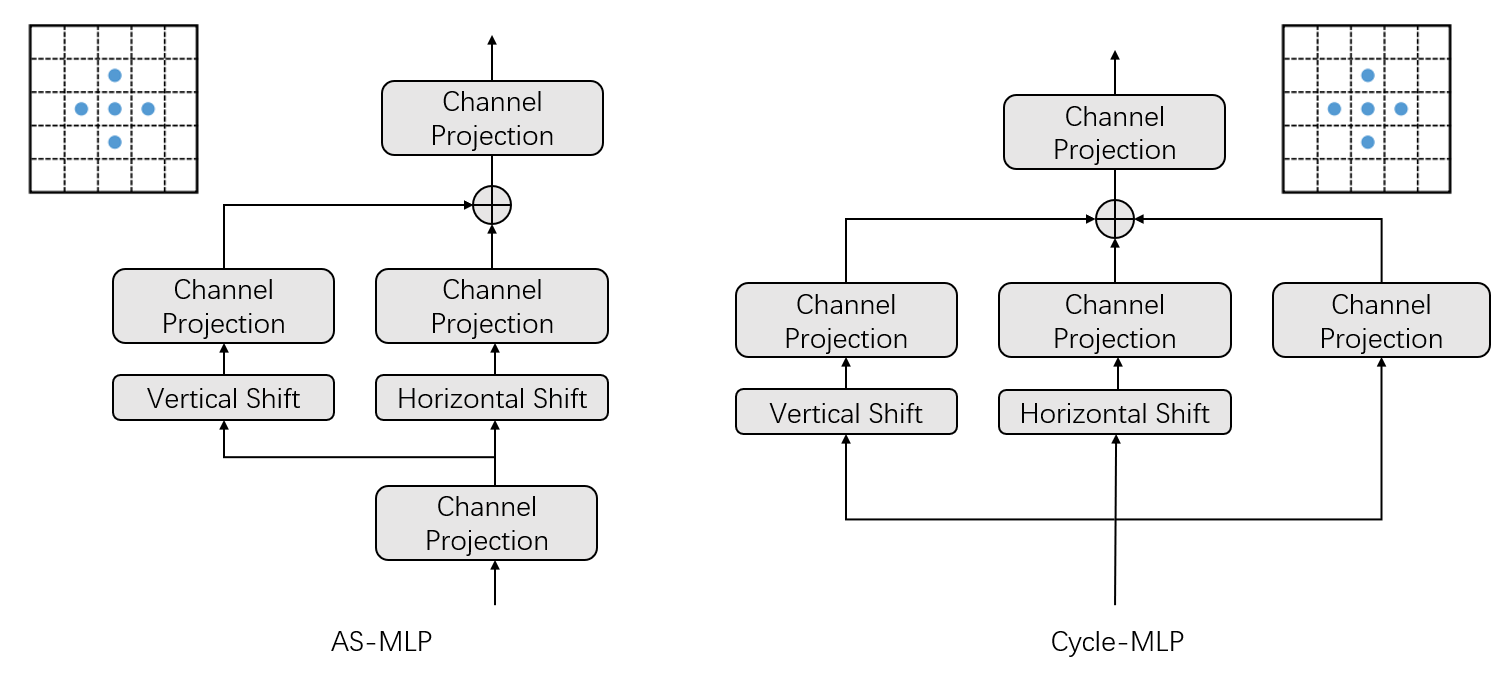
CycleMLP 最终使用的和 ViP 一样,使用 Split Attention 来融合三条支路。
class CycleMLP(nn.Module):
def __init__(self, dim, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.mlp_c = nn.Linear(dim, dim, bias=qkv_bias)
self.sfc_h = CycleFC(dim, dim, (1, 3), 1, 0)
self.sfc_w = CycleFC(dim, dim, (3, 1), 1, 0)
self.reweight = Mlp(dim, dim // 4, dim * 3)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, H, W, C = x.shape
h = self.sfc_h(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
w = self.sfc_w(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
c = self.mlp_c(x)
a = (h + w + c).permute(0, 3, 1, 2).flatten(2).mean(2)
a = self.reweight(a).reshape(B, C, 3).permute(2, 0, 1).softmax(dim=0).unsqueeze(2).unsqueeze(2)
x = h * a[0] + w * a[1] + c * a[2]
x = self.proj(x)
x = self.proj_drop(x)
return x最后提一句,作者将投影区间定义为是 Pseudo-Kernel,这其实也是我们常说的 感受野 一词。
2.2 整体网络结构
CycleMLP 的 Patch Embedding 也很有特色,使用卷积核大小为 7×7 ,步长为 4 的卷积。后续 Hire-MLP 其实也是这样进行的 Patch Embedding。相比而言 Swin 使用卷积核大小为 4×4,步长为 4 的卷积。在近期的我自己的小实验中也发现:Patch Embedding 时具有重叠会更好,这样可以避免边界效应并在小数据集上提升性能。CycleMLP 中间采用多阶段金字塔模型,总共分为 4 个阶段,每个阶段交替重复使用 CycleMLP Block。下采样使用卷积核大小为3×3,步长为 2 的卷积,这样做也有重叠,Hire-MLP 也是这样子哈。最后经过全局池化后连接一个全连接分类器即可。作者一共提出来了四种配置:

在这四种配置,Si 指 Patch Embedding 中的 Patch size,Ci 指 Patch Embedding 的输出编码特征维度,E i 为 Channel-mixing MLP 中两个全连接层中第一个全连接层的 expand radio,Li 则是不同 Stage 中 Block 的重复次数。
3. 下游任务实验
CycleMLP 旨在为 MLP 模型的目标检测、实例分割和语义分割提供一个有竞争力的基线。与 AS-MLP 不同之处在于,CycleMLP 在 ADE20K 上进行实验,而 AS-MLP 在 COCO 上进行的实验。这真的是巧合,还是故意避开?不敢问也不敢说。
目标检测性能表现:相比 PVT,CycleMLP 都更具有优势。

语义分割性能表现:特别是,CycleMLP 在 ADE20K val 上达到了 45.1 mIoU,与 Swin (45.2 mIOU) 相当。

4. 消融实验
作者一共进行了三组消融实验:
- Cycle-FC VS Spacial-FC and Channel-FC: 作者将 CycleMLP 中的 Cycle-FC 替换为 Spacial-FC 或者 Channel-FC,结果发现 CycleMLP 具有更好的性能。但是只有 Channel-FC,也能达到 79.4% 的性能,真的这么高吗,比 ResNet 高那么多…

- Cycle-FC 中三条支路的选择:Cycle-FC 中作者并行了三条支路,对他们的消融实验发现,同时拥有正交 H 和 W 方向效果很好,加上不动之后效果更好。两倍 H 方向或者两倍 W 方向比仅含有 H 或者 W 方向会好一些。

- 测试分辨率的影响:最终发现测试正确率随分辨率先升后降,CycleMLP 表现最好。

4. 总结与反思
CycleMLP 提出了 Cycle-FC,即将不同 token 的特征对齐到同一个通道,然后使用通道映射,从而实现网络参数量计算量的降低,以及对图像分辨率不敏感。CycleMLP 也在下游任务上测试了自己的性能表现。整体而言做得还是很充分的。不过其试图造一些新的名词以强化贡献,例如 Cycle-FC 其实就是移动特征图,Pseudo-Kernel 其实就是卷积核感受野的概念。最终 CycleMLP 通过三条并行的支路构建了十字形感受野。相比 AS-MLP,CycleMLP 在感受野分析上略显不足,没有更泛化地分析以及进行消融实验。比如 CycleMLP 也可以间隔采样,例如 [+4 +2 0 -2 -4 -2 0 2 4 2 0 -2 …],就可以构建 AS-MLP 那种空洞的更大范围的感受野。(最后插一句:CycleMLP 和 AS-MLP,就像 ResMLP 与 MLP-Mixer,学术界的 Idea 真的能够这么惊人的一致吗?)