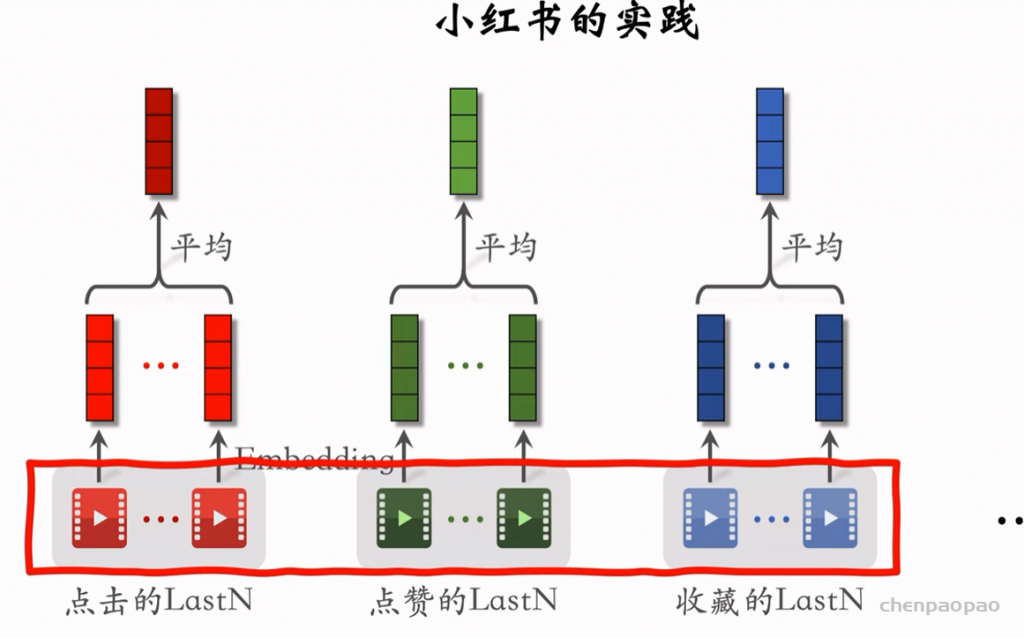
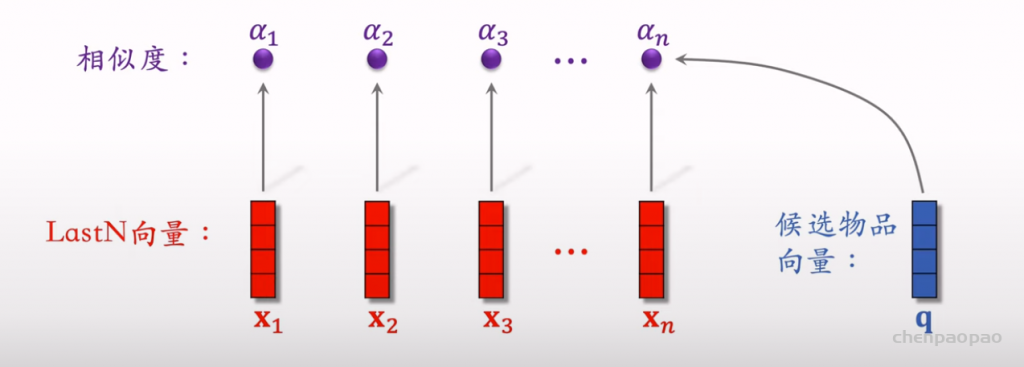
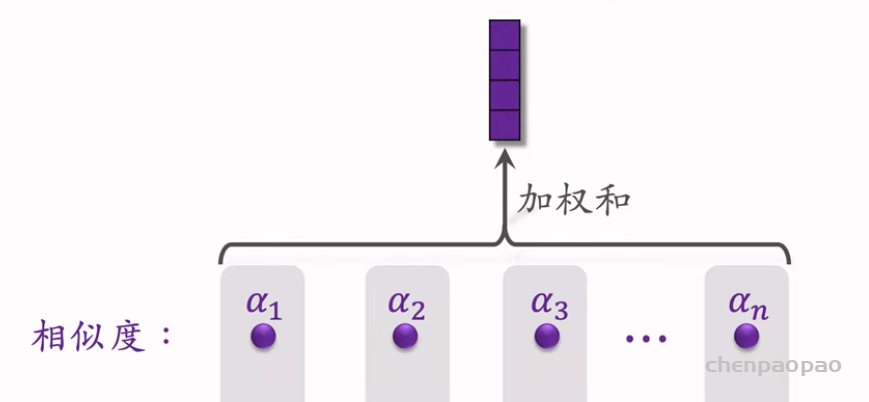
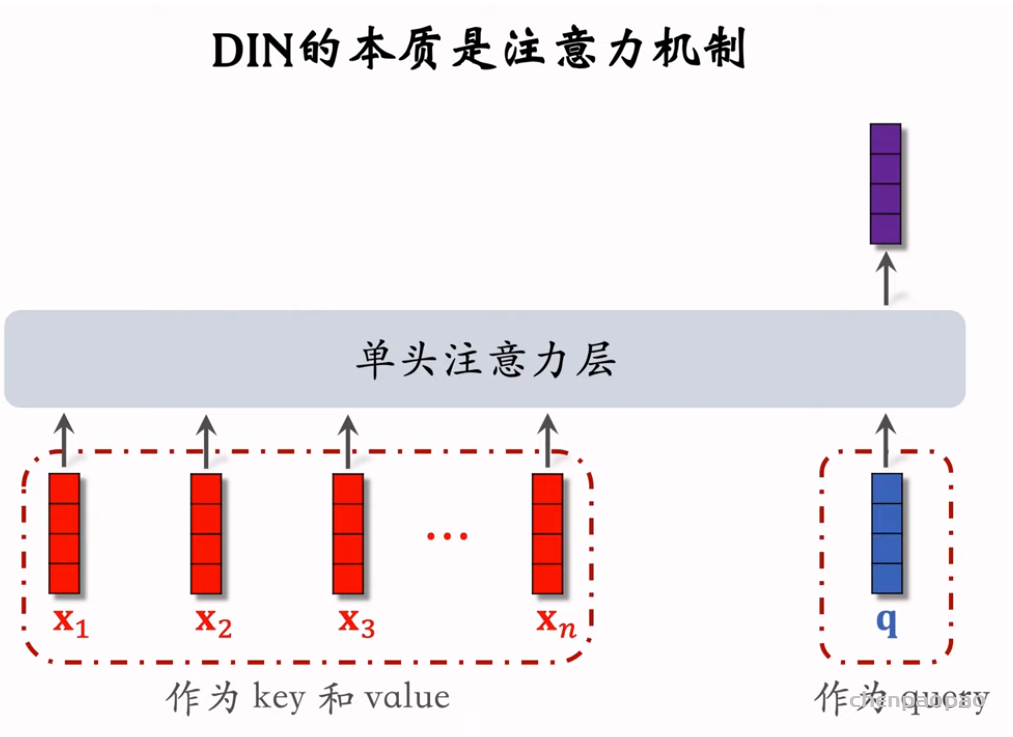
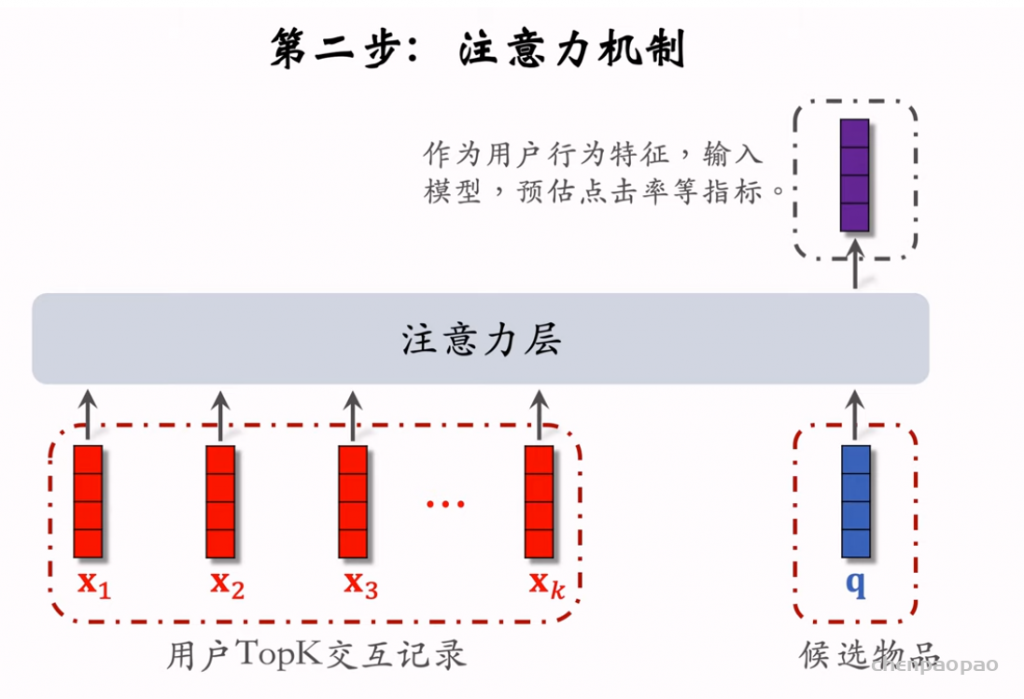
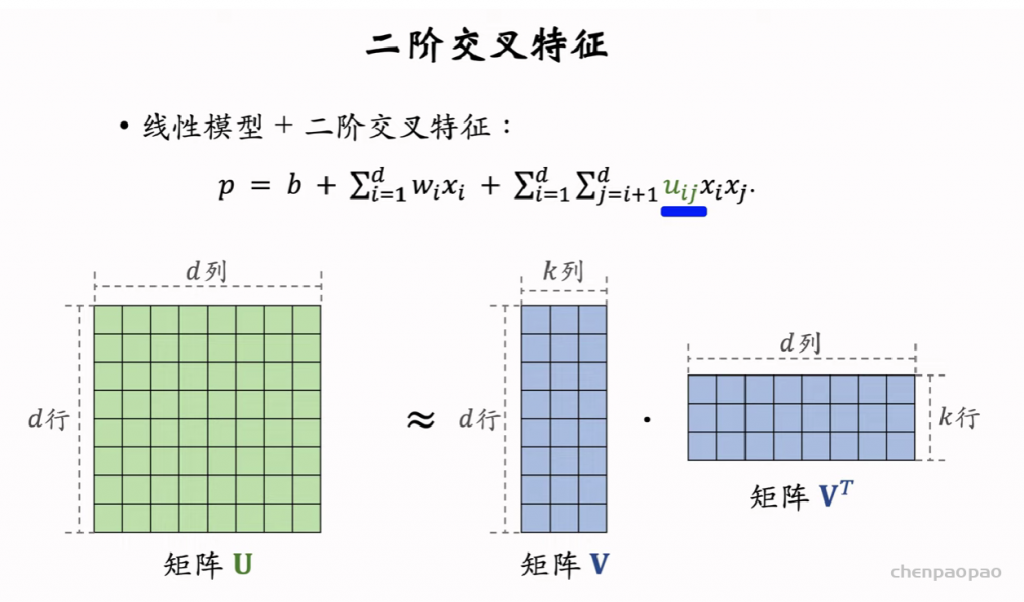
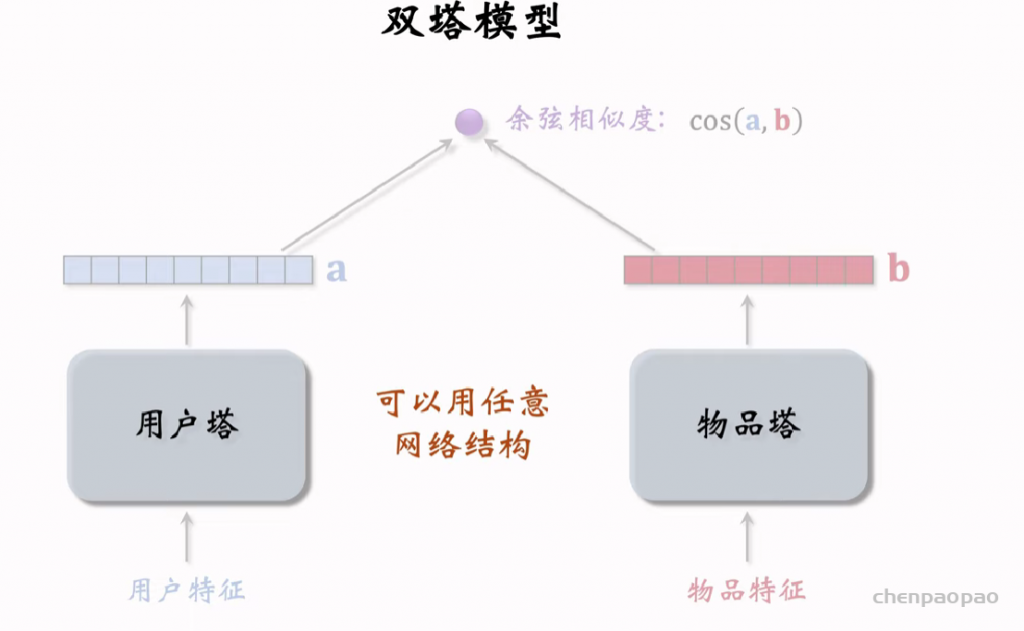
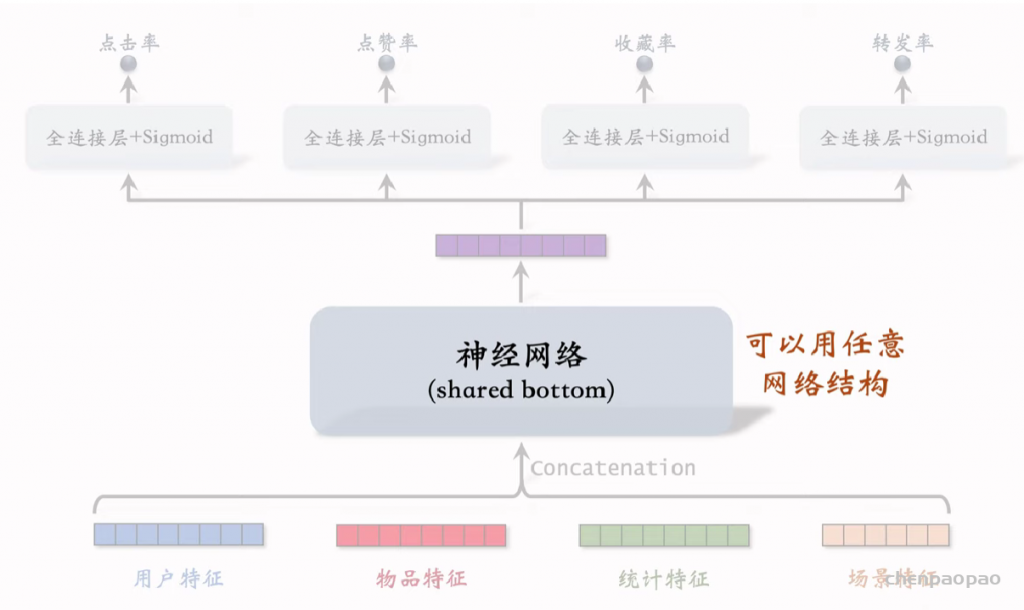
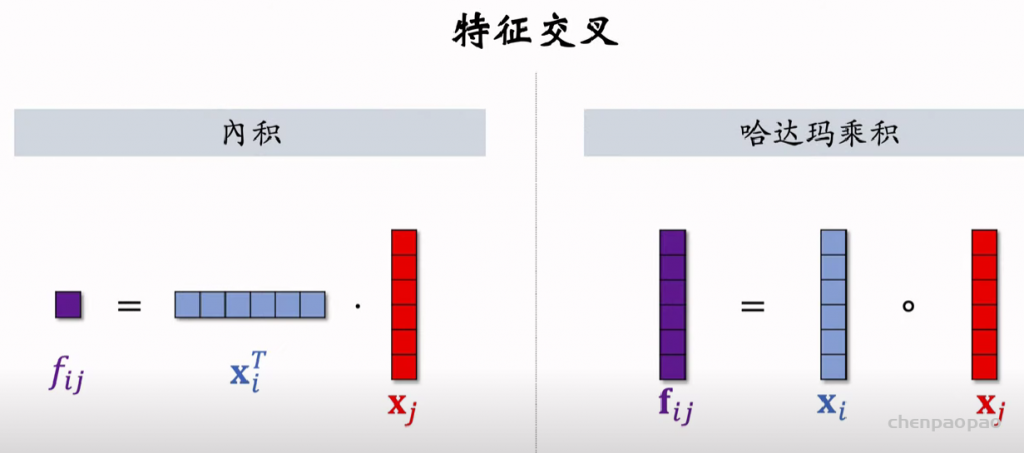
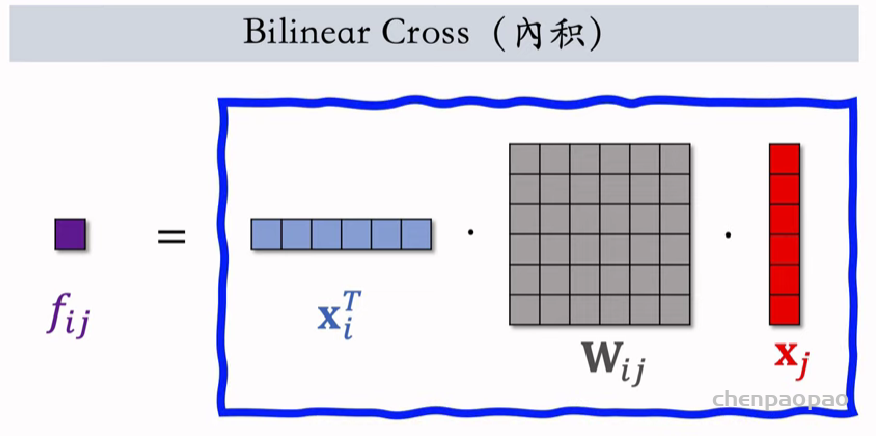
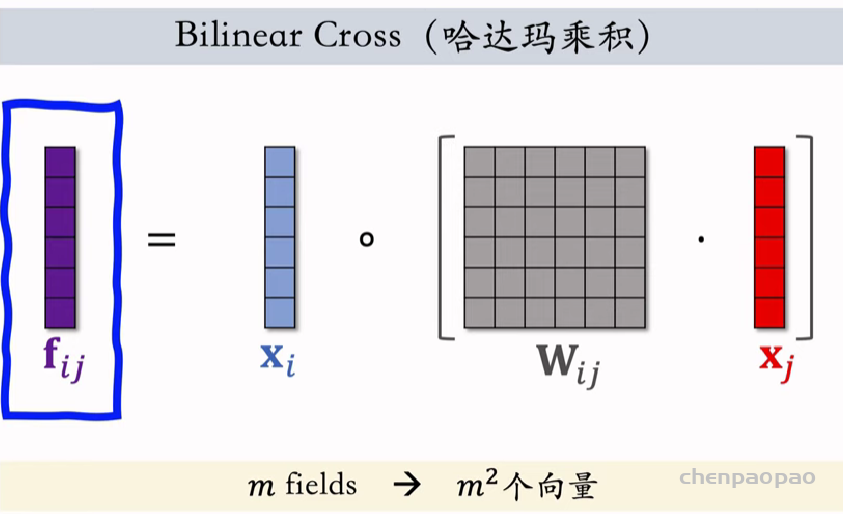
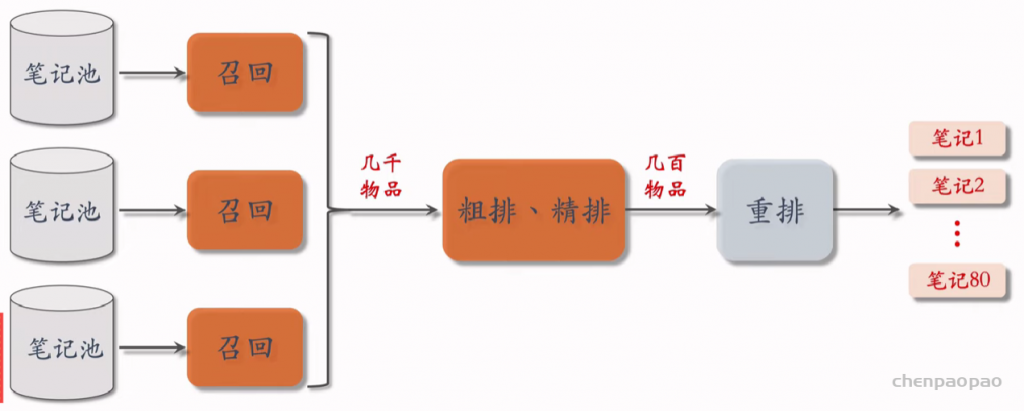
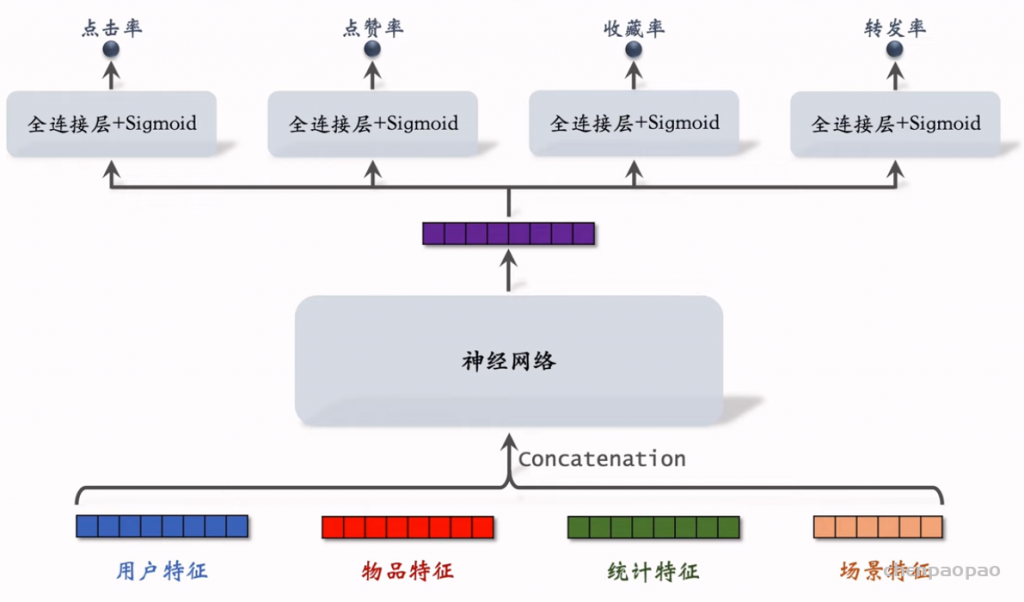
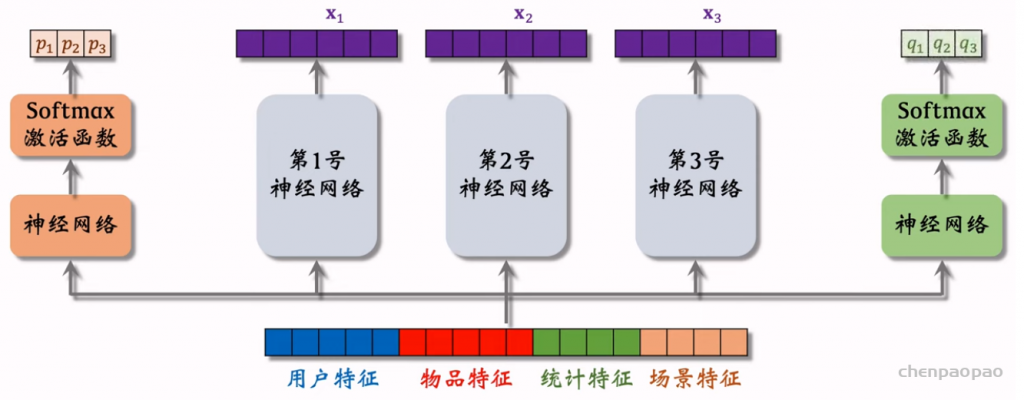
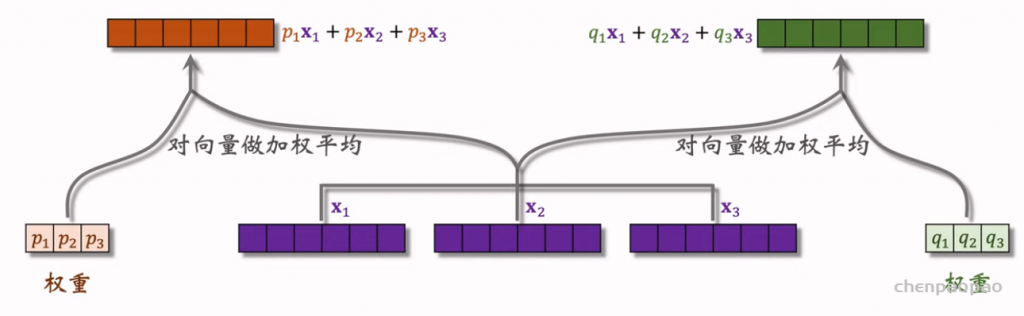
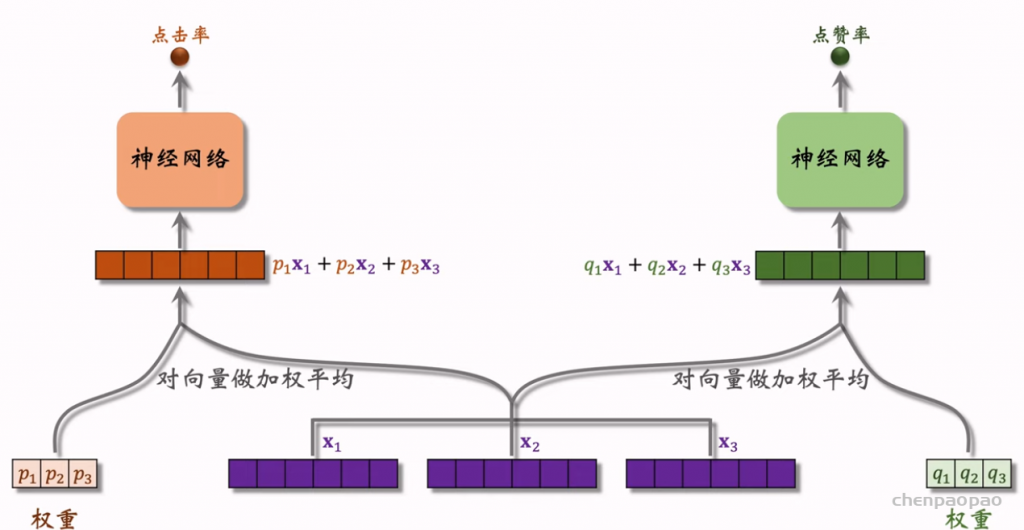
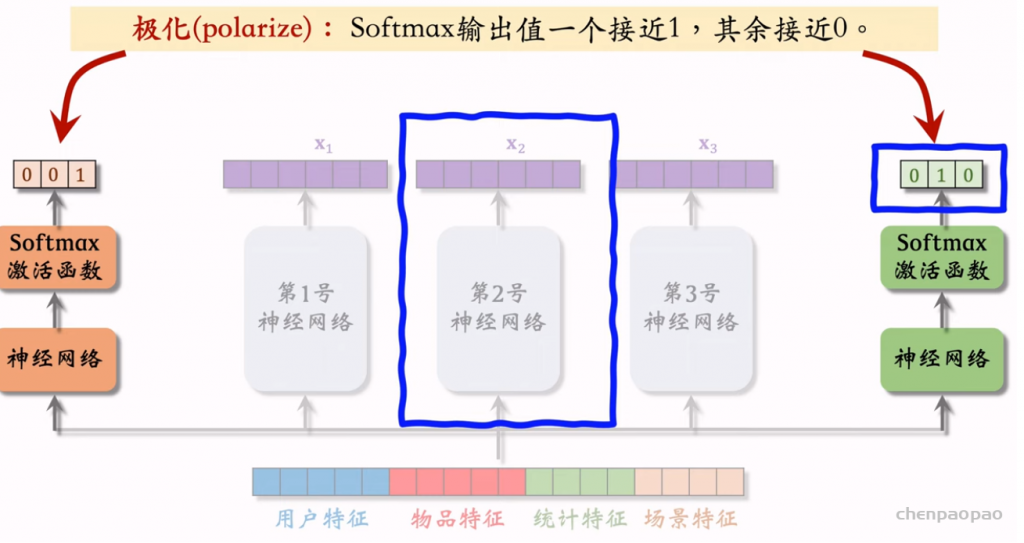
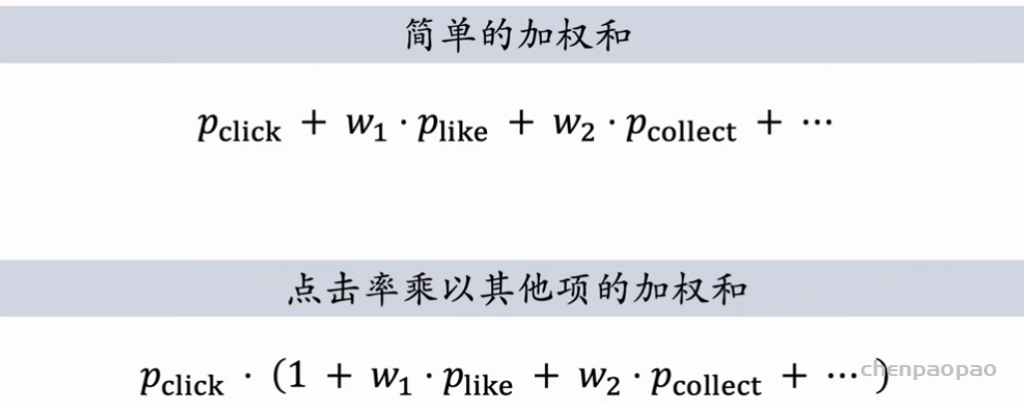
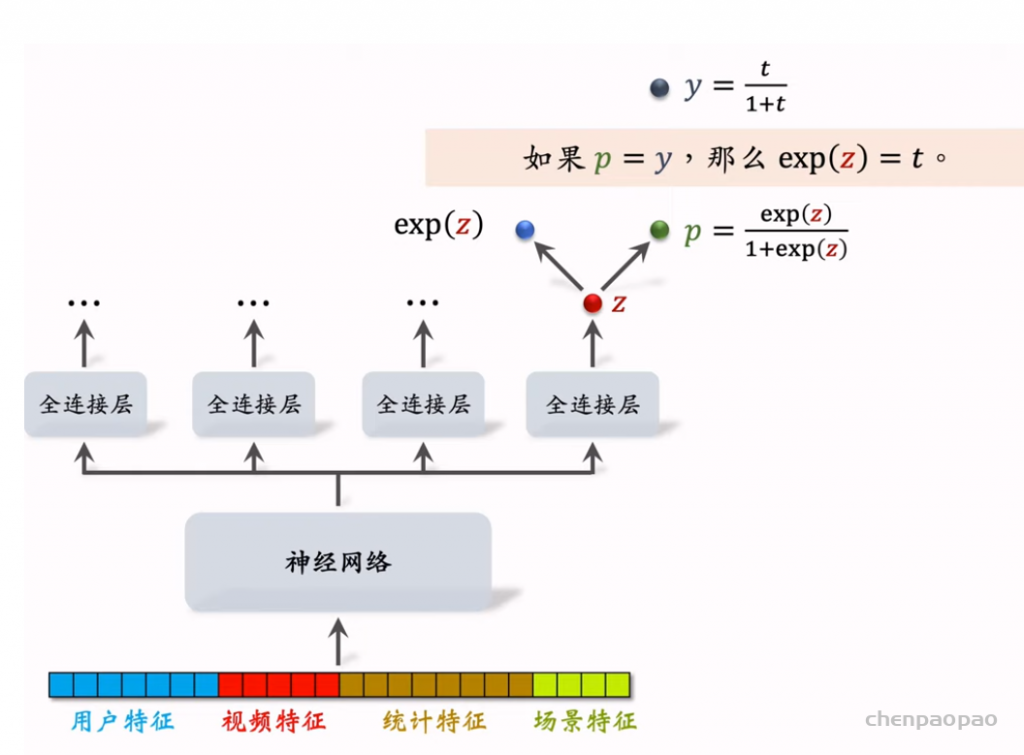
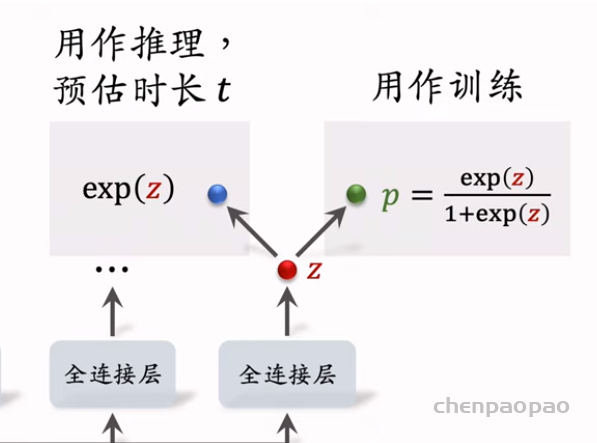
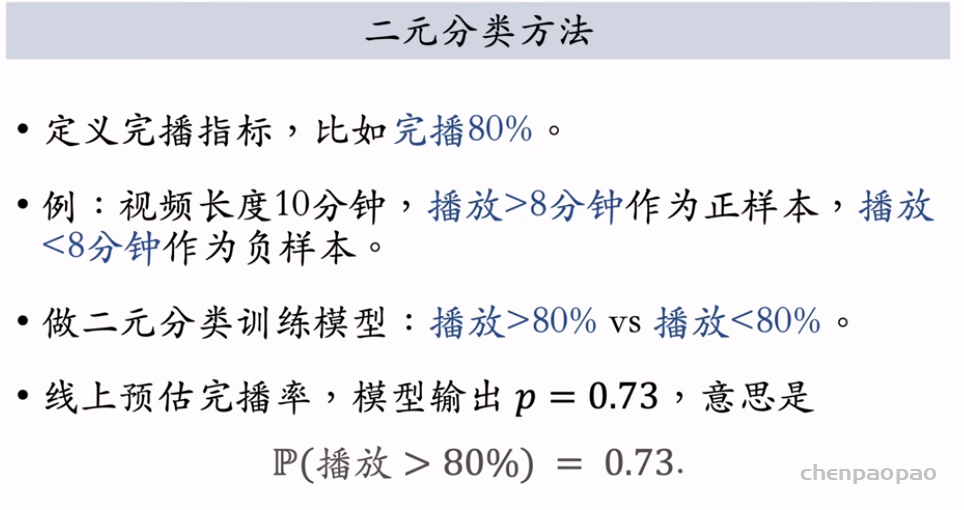
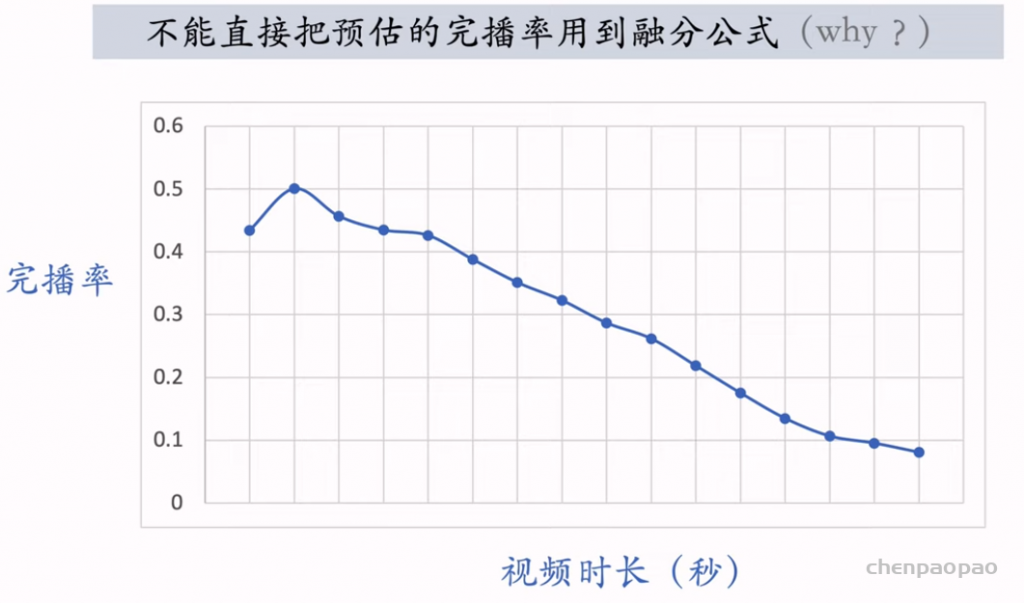
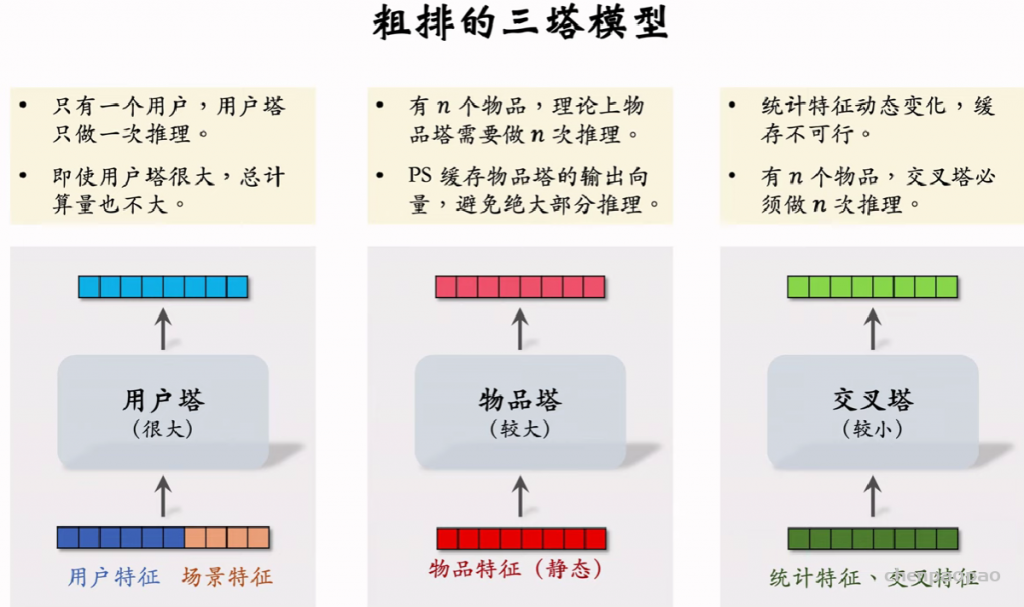
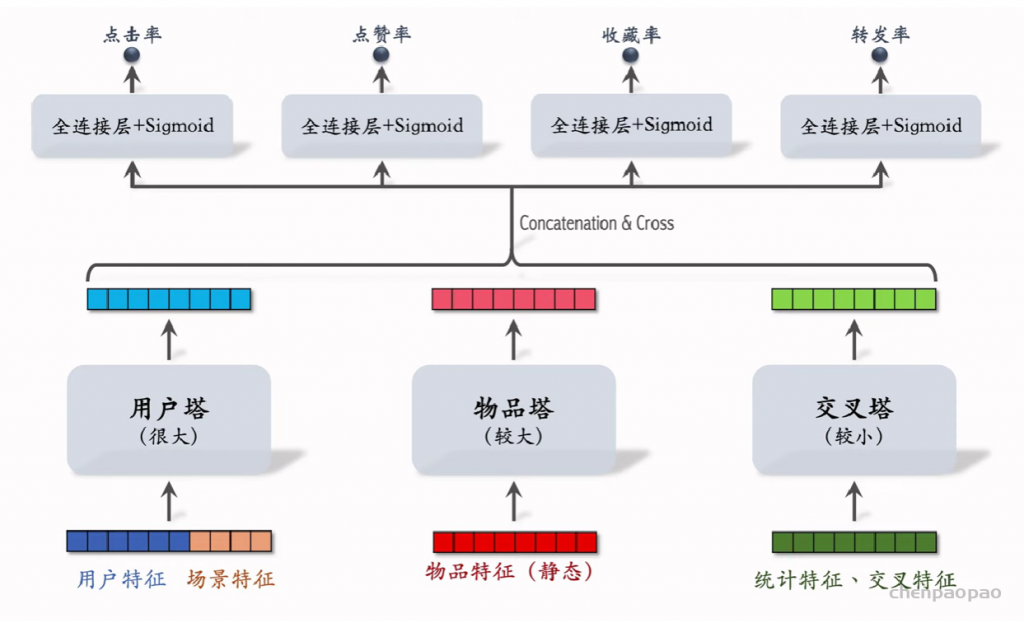
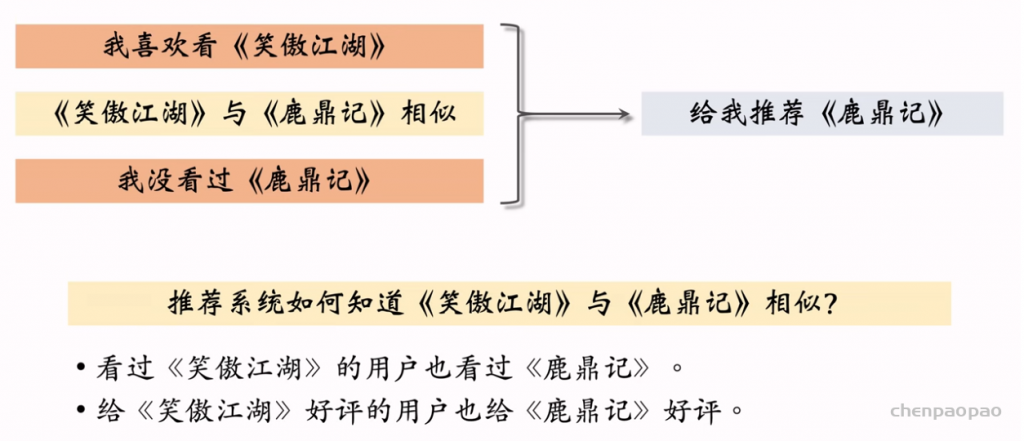
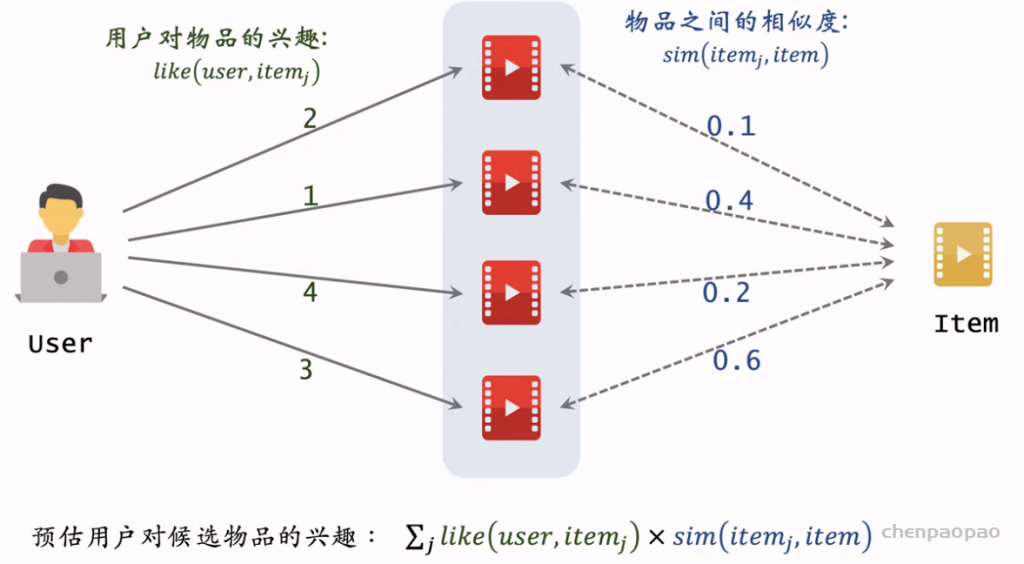
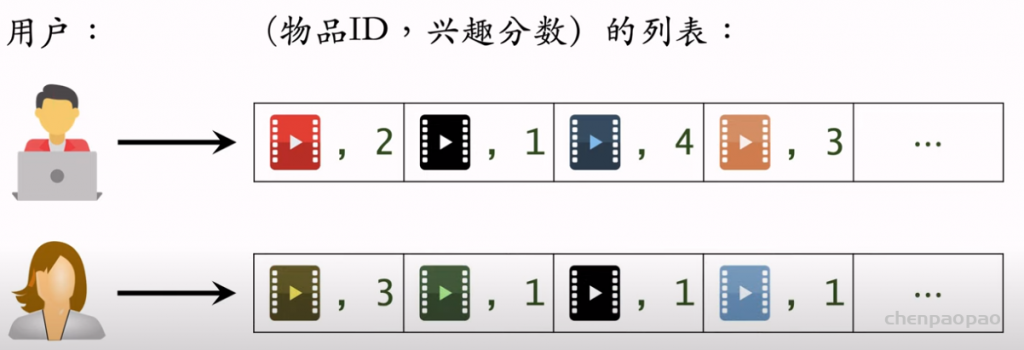
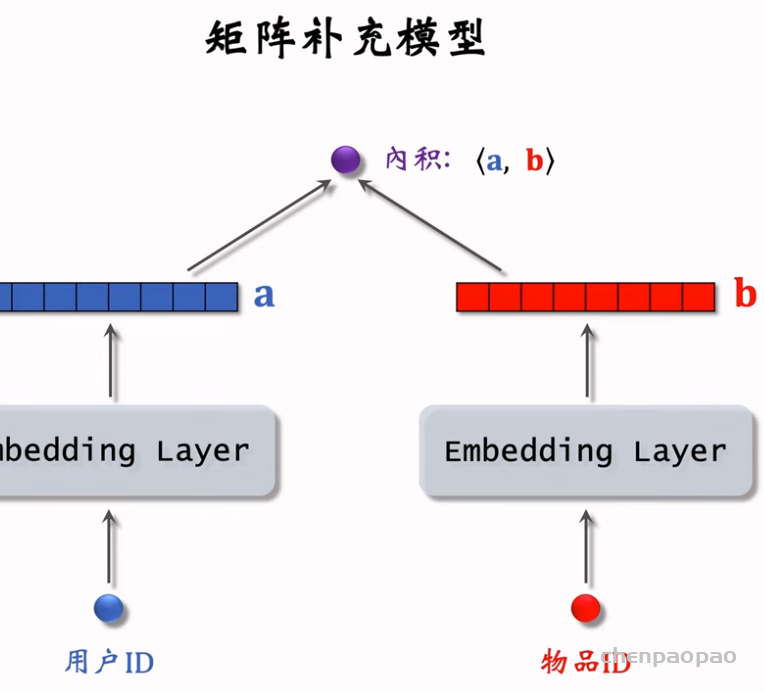
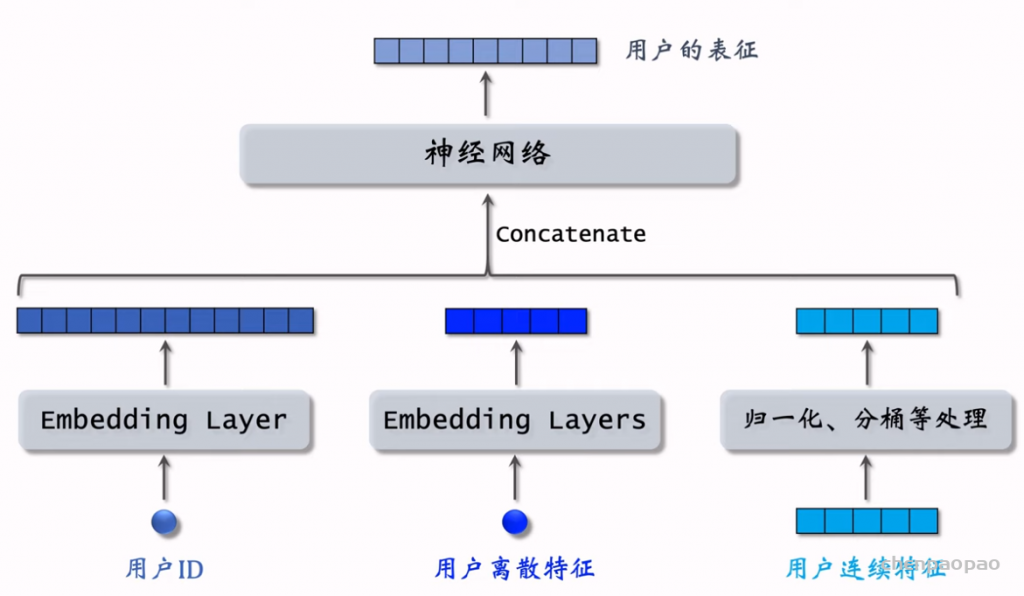
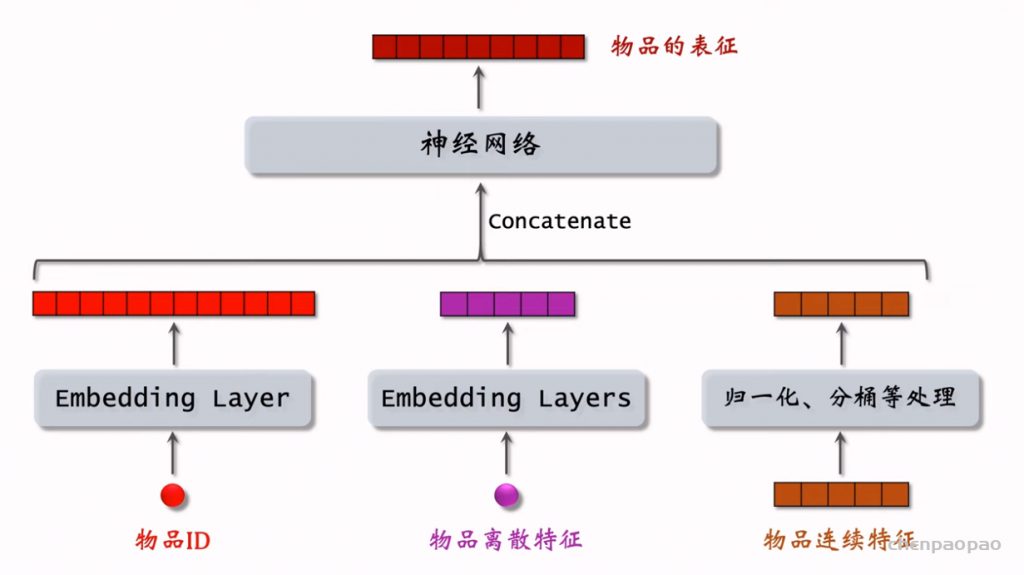
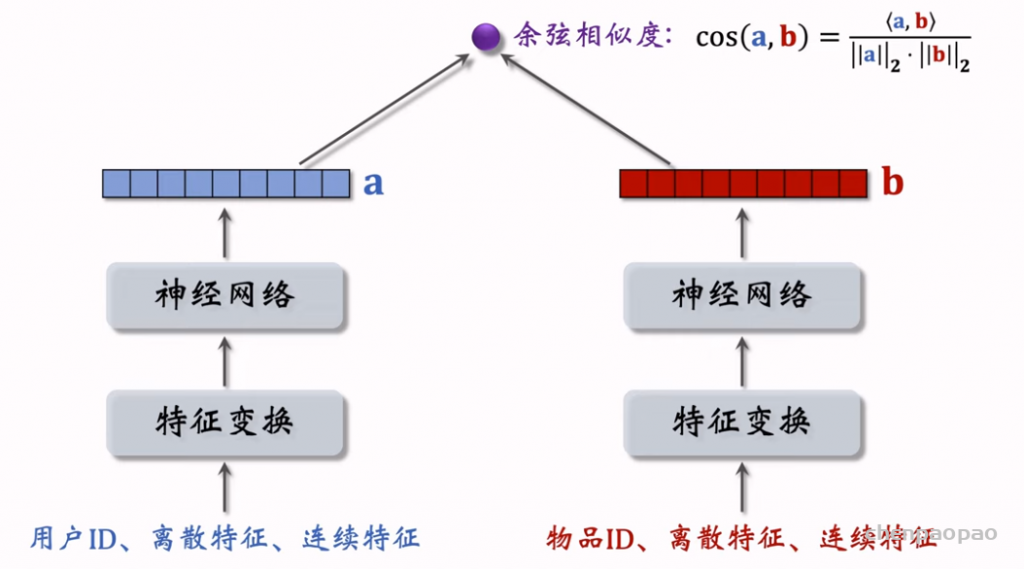
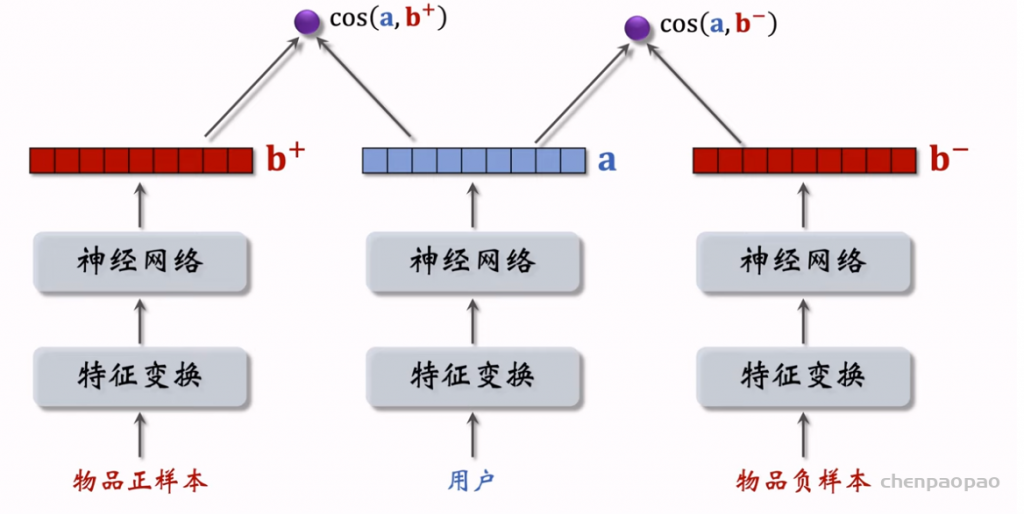
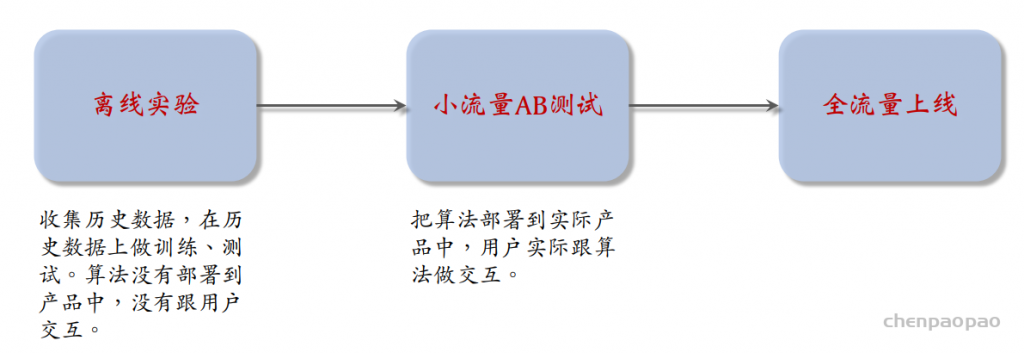
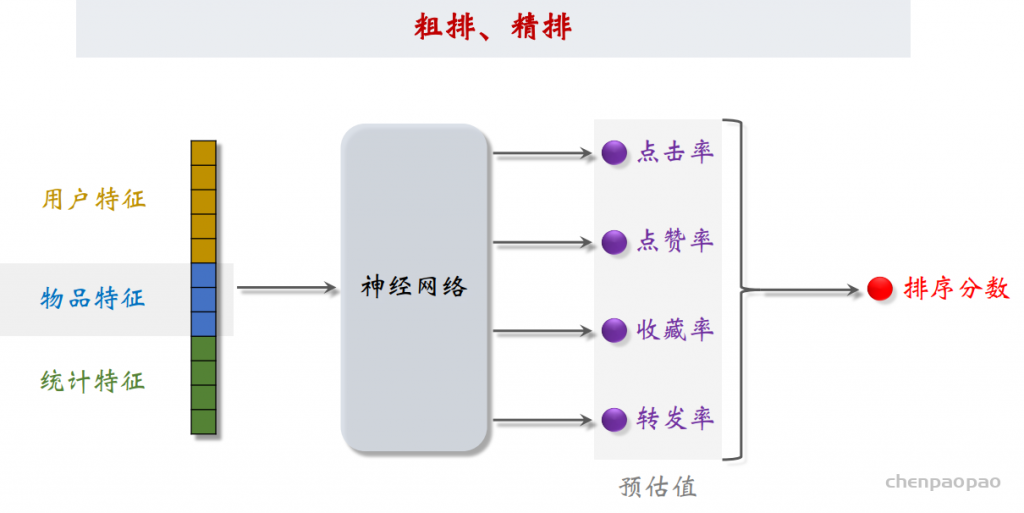
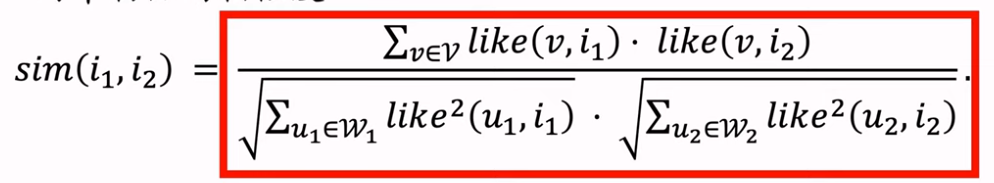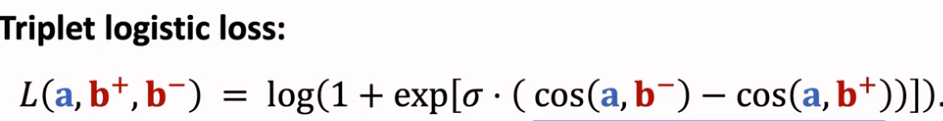物品冷启01:优化目标 & 评价指标
冷启动问题 (cold start) 主要分3类:
- 用户冷启动。用户冷启动主要解决如何给新用户做个性化推荐的问题。当新用户到来时,我们没有他的行为数据,所以也无法根据他的历史行为预测其兴趣,从而无法借此给他做个性化推荐。
- 物品冷启动。物品冷启动主要解决如何将新的物品推荐给可能对它感兴趣的用户这一问题。
- 系统冷启动。 系统冷启动主要解决如何在一个新开发的网站上(还没有用户,也没有用户行为,只有一些物品的信息)设计个性化推荐系统,从而在网站刚发布时就让用户体验到个性化推荐服务这一问题。
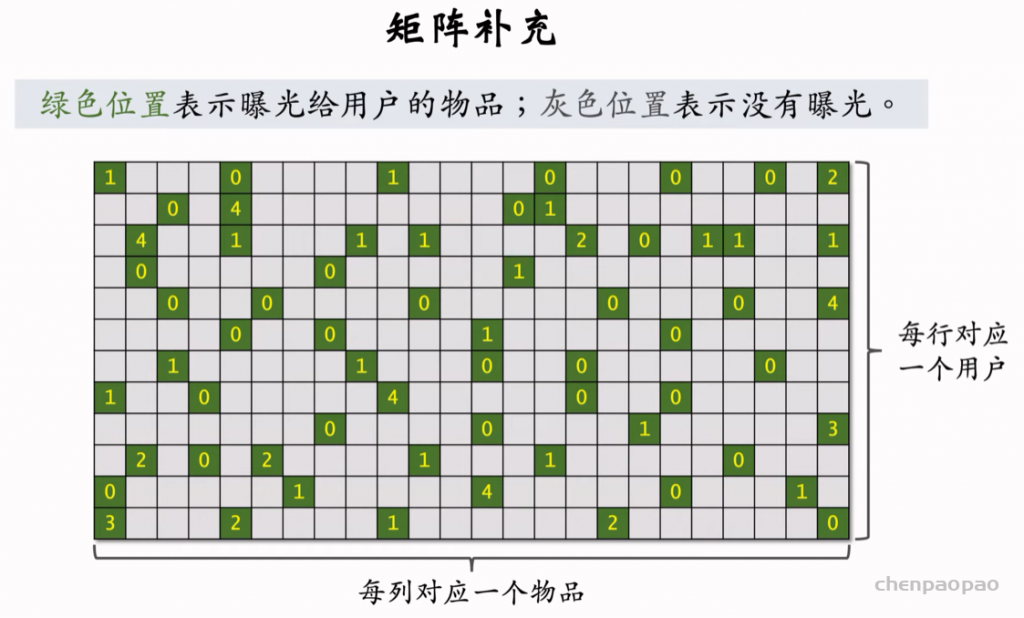
物品冷启动指的是如何对新发布的物品做分发。优化物品冷启动在小红书这样的 User-Generated Content (UGC) 平台尤为重要,这是因为新物品数量巨大,内容质量良莠不齐,分发非常困难。而且之气讲到的那些模型对于新发布的物品效果很差,曝光率比较低。
UGC 平台的物品冷启动有三个目标: 1. 精准推荐:克服冷启的困难,把新物品推荐给合适的用户,不引起用户反感。 2. 激励发布:流量向低曝光新物品倾斜,激励发布。 3. 挖掘高潜:通过初期小流量的试探,找到高质量的物品,给与流量倾斜。
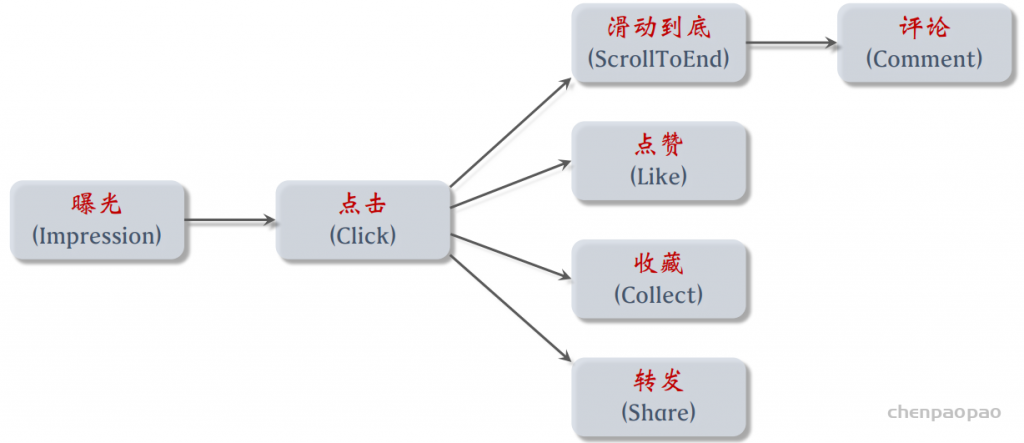
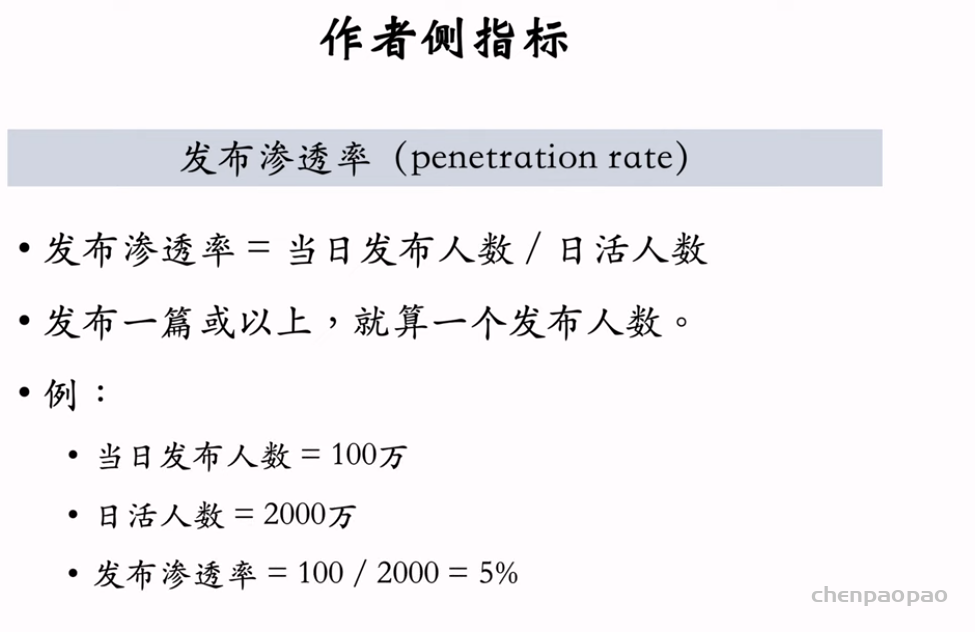
UGC 平台的物品冷启动主要考察三种指标: 1. 作者侧指标,包括发布渗透率、人均发布量。 2. 用户侧指标,包括大盘消费指标和新物品消费指标。 3. 内容侧指标,比如高热物品占比。


优化目标

评价指标






物品冷启02:简单的召回通道
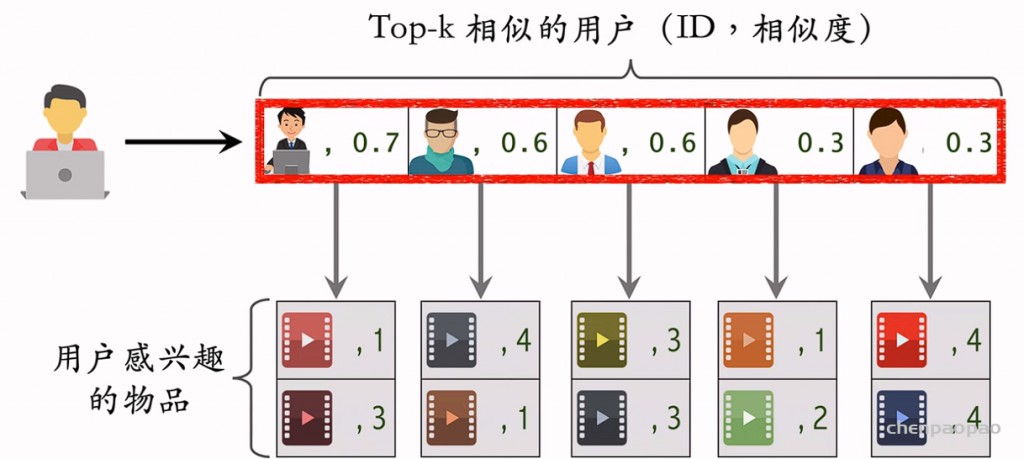
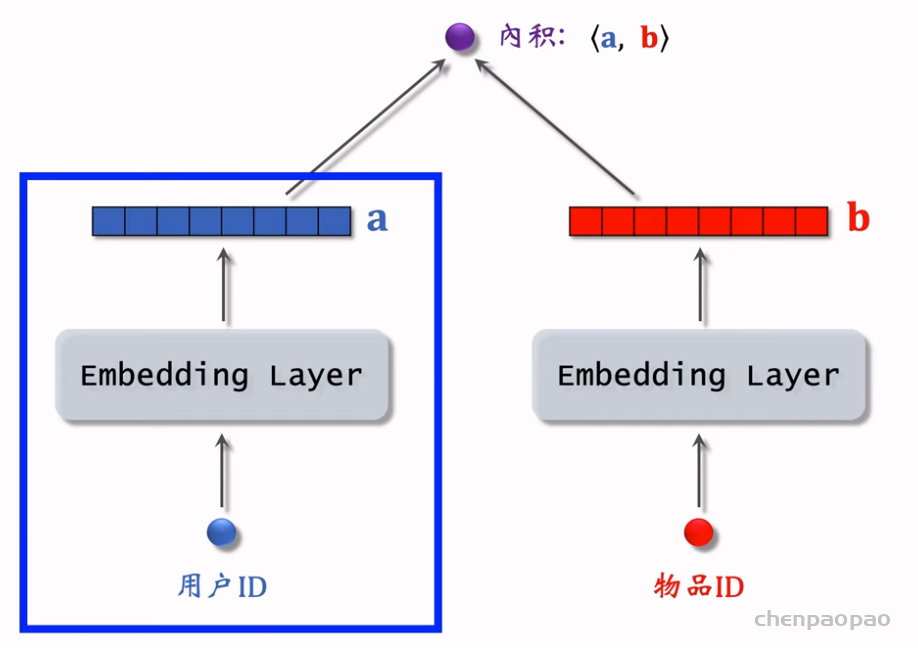
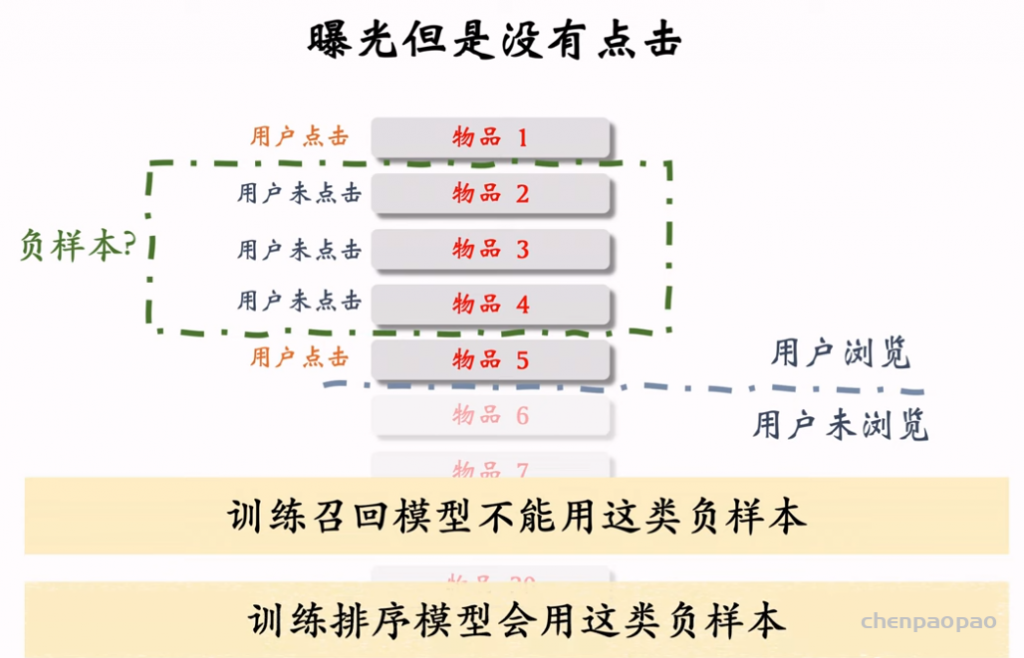
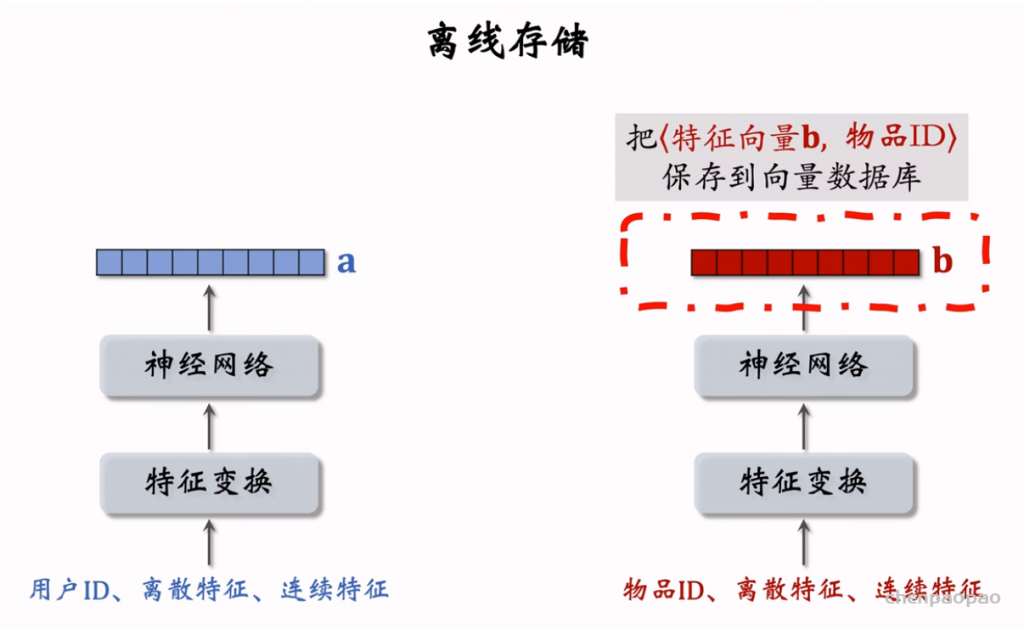
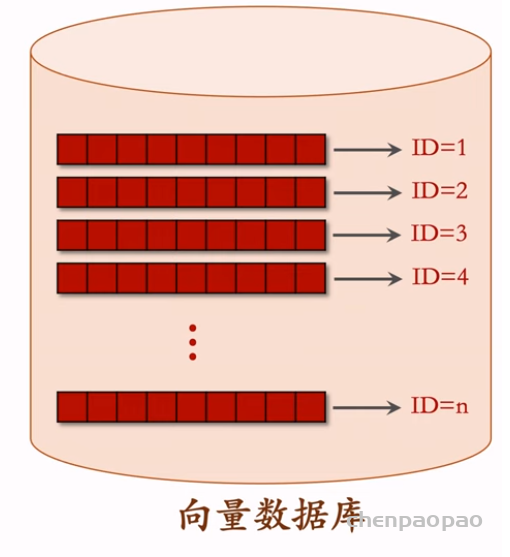
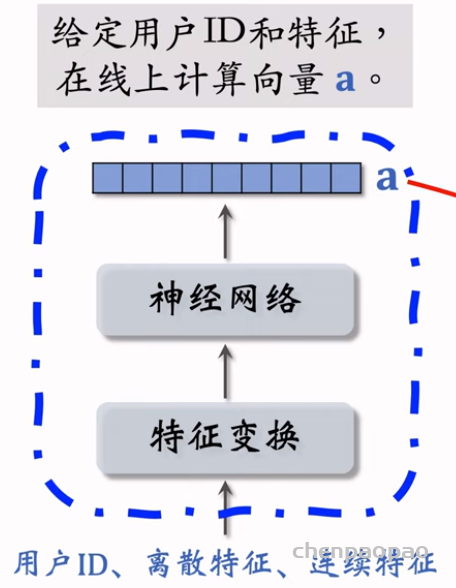
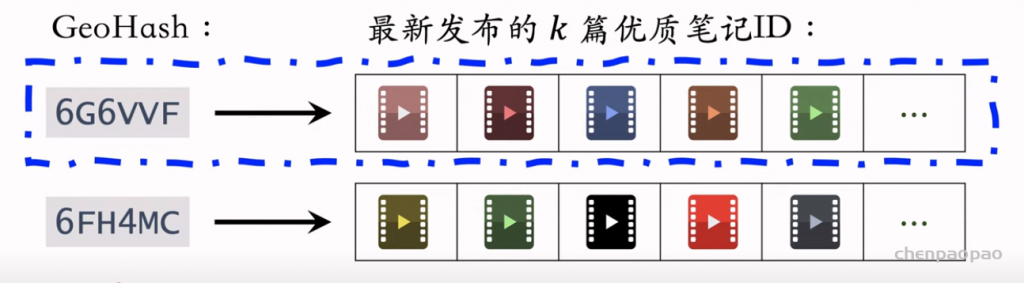
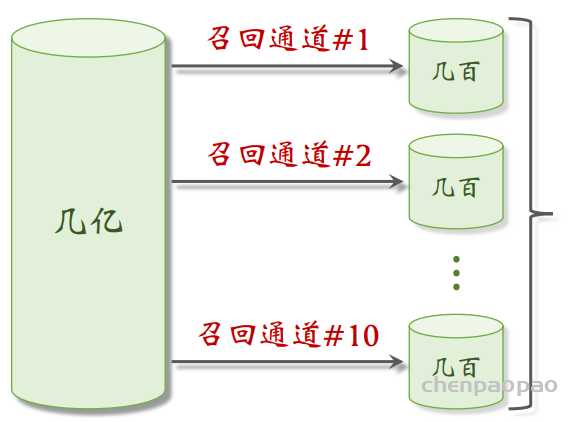
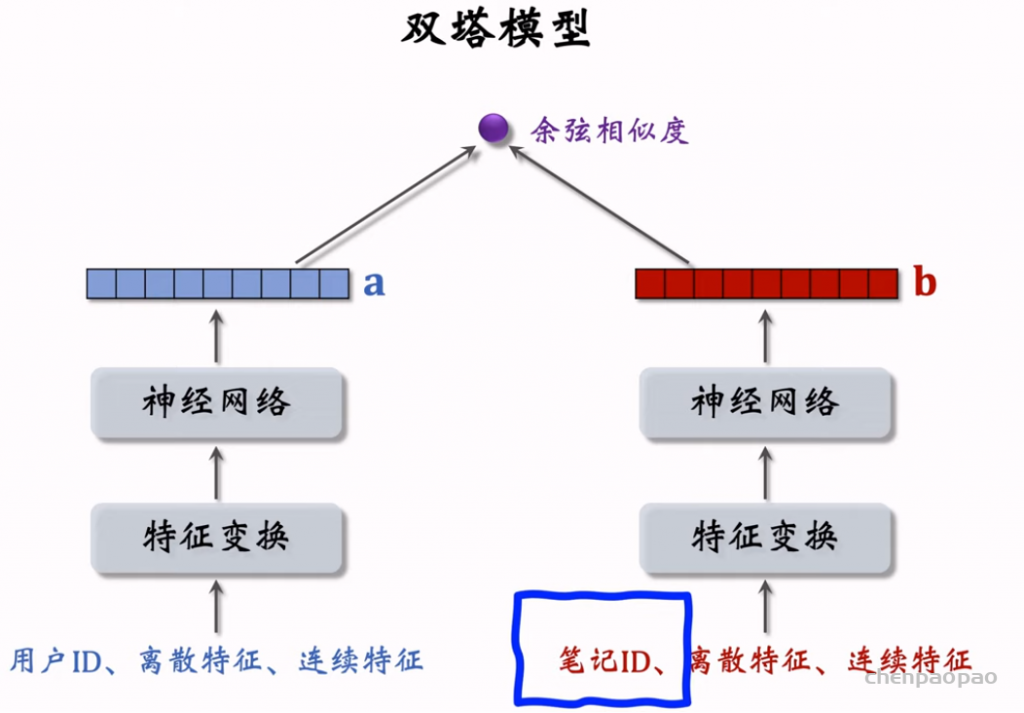
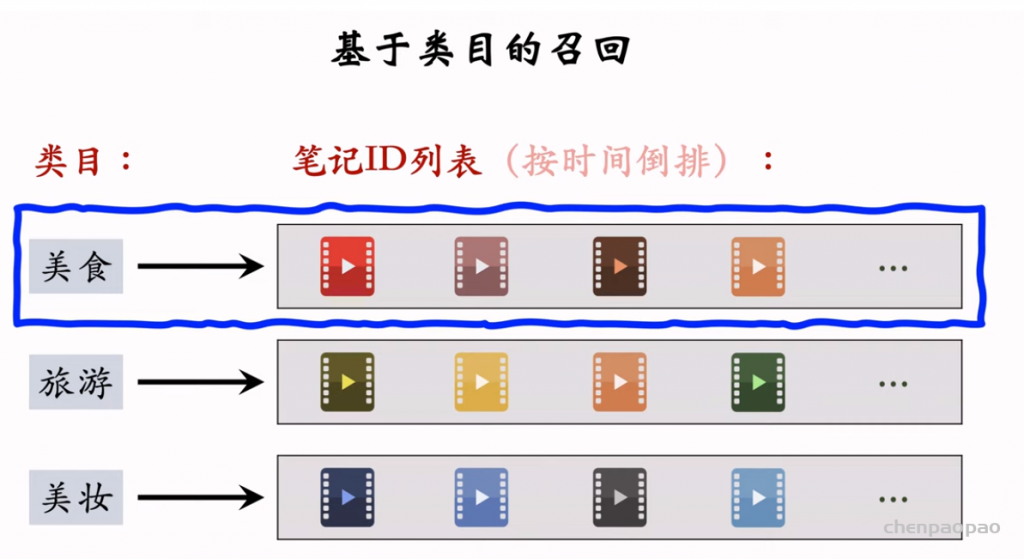
物品冷启动 (item cold start) 中的召回。冷启动召回的难点是缺少用户交互,还没学好笔记 ID embedding,导致双塔模型效果不好。而且缺少用户交互会导致 ItemCF 不适用。 这节课介绍两种简单的召回通道: 1. 改造双塔模型,使得它适用于冷启动。 2. 类目召回。










物品冷启03:聚类召回
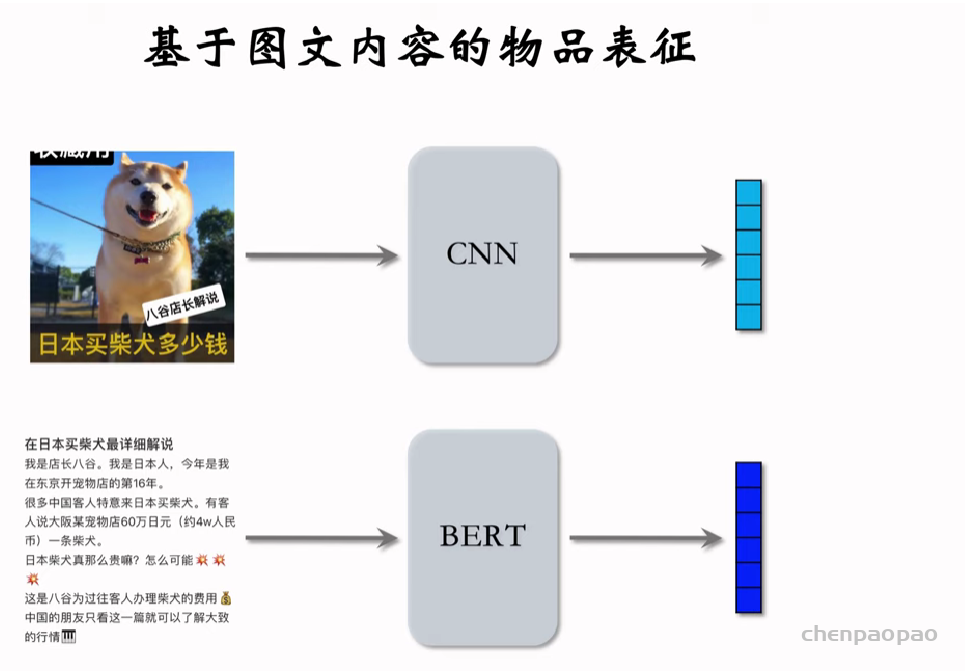
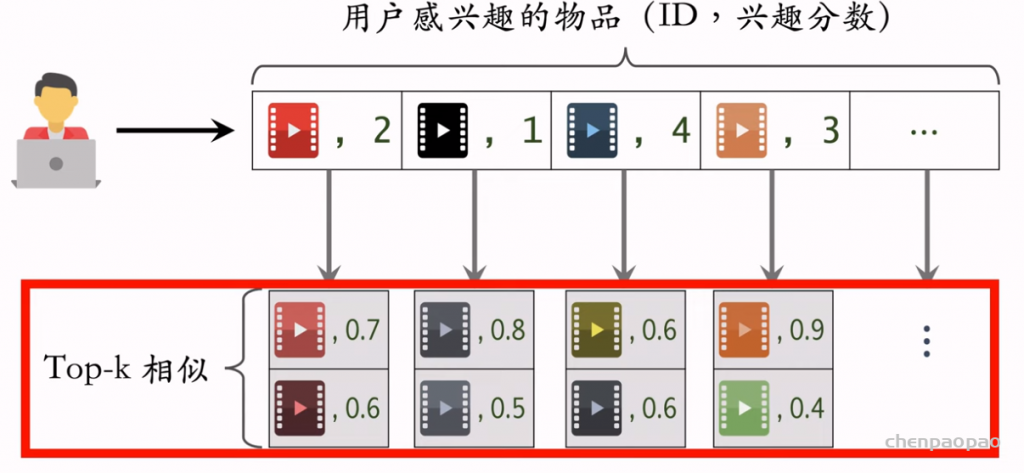
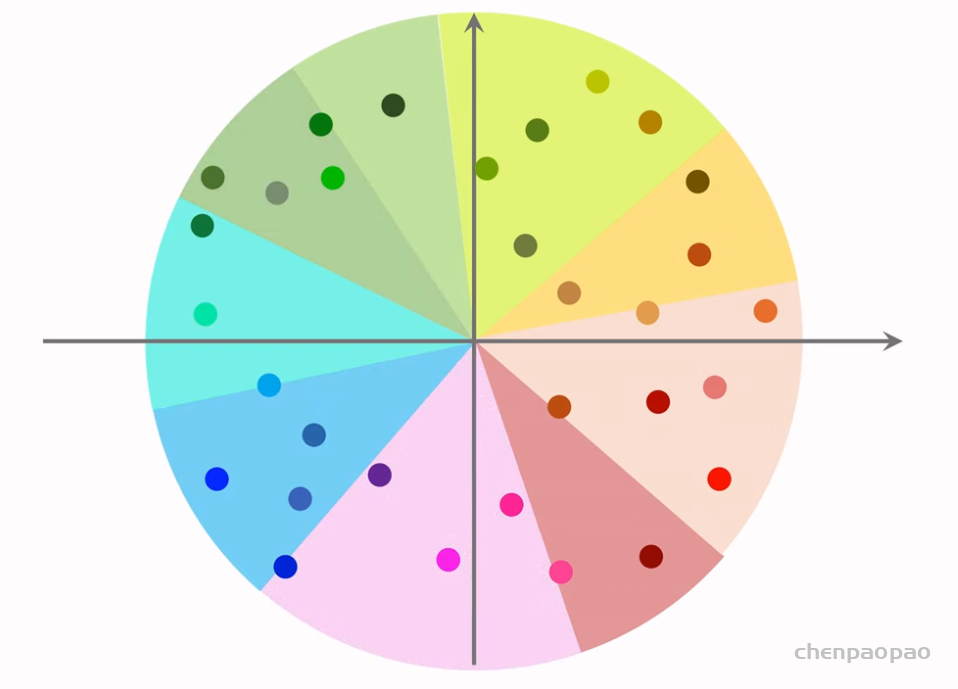
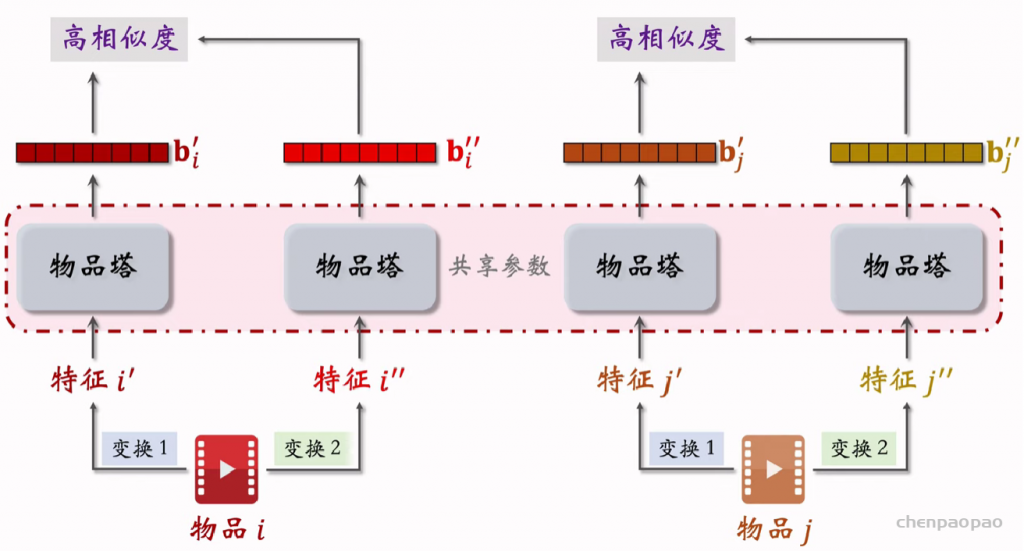
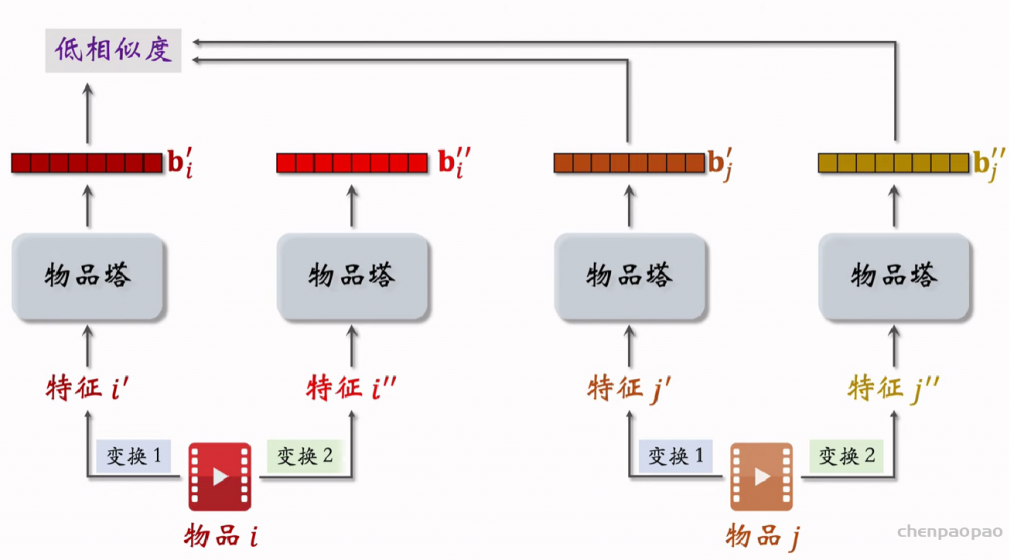
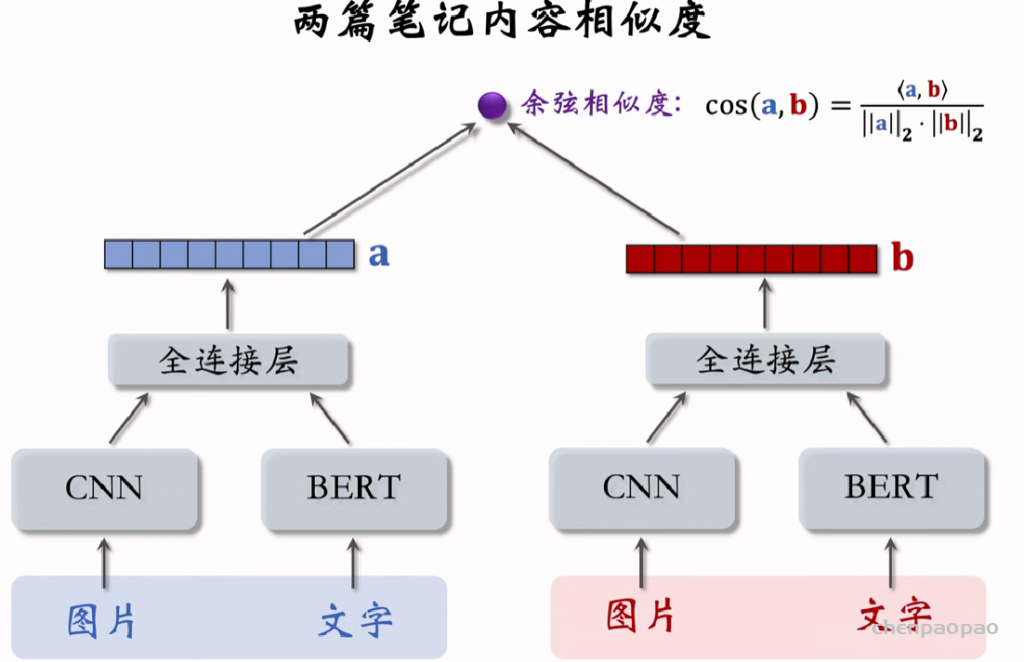
聚类召回是基于物品内容的召回通道。它假设如果用户喜欢一个物品,那么用户会喜欢内容相似的其他物品。使用聚类召回,需要事先训练一个多模态神经网络,将笔记图文表征为向量,并对向量做聚类,然后建索引。



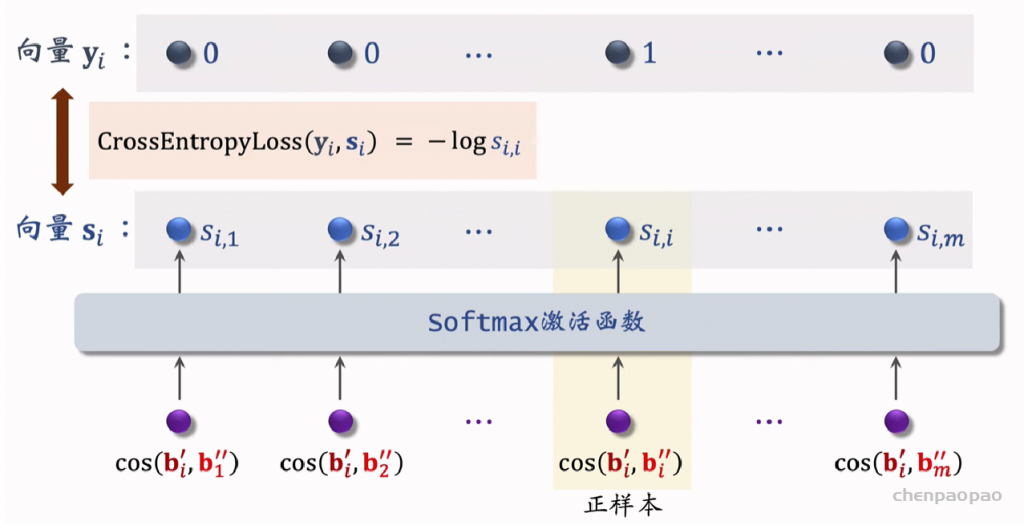
内容相似度模型:
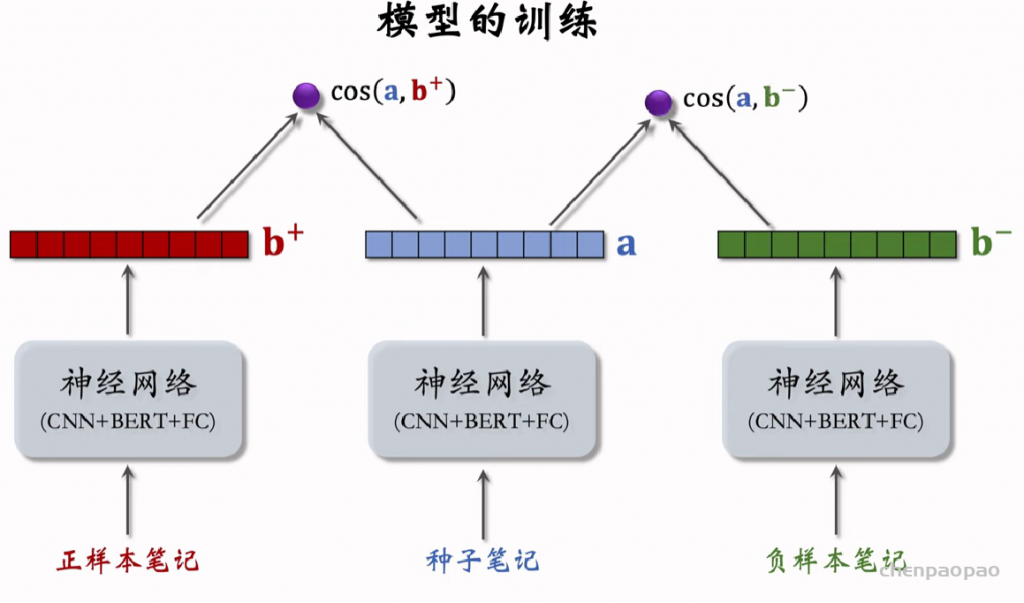
内容相似度模型的训练:



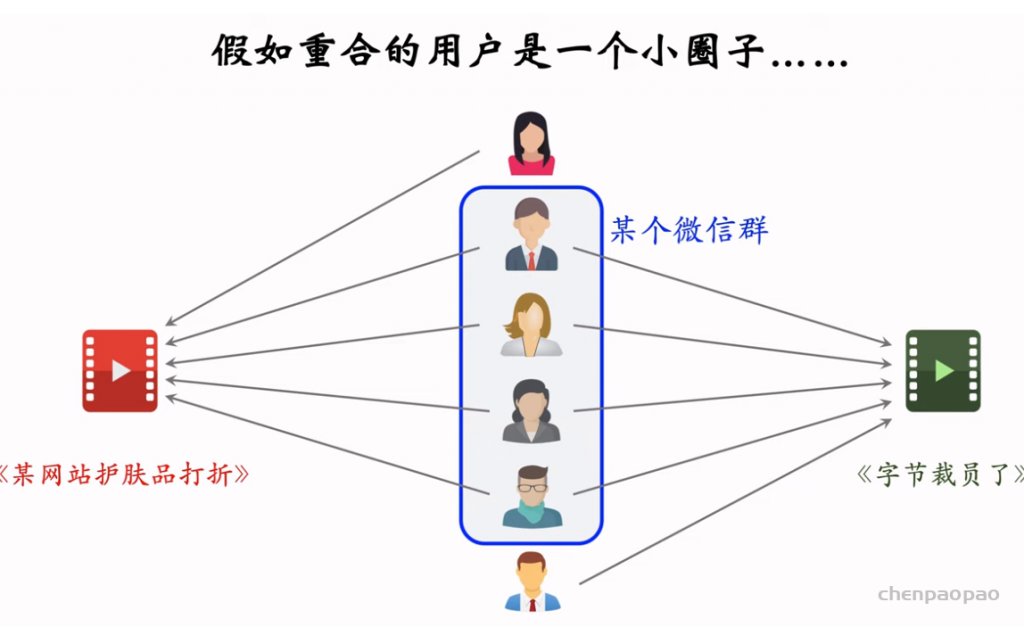
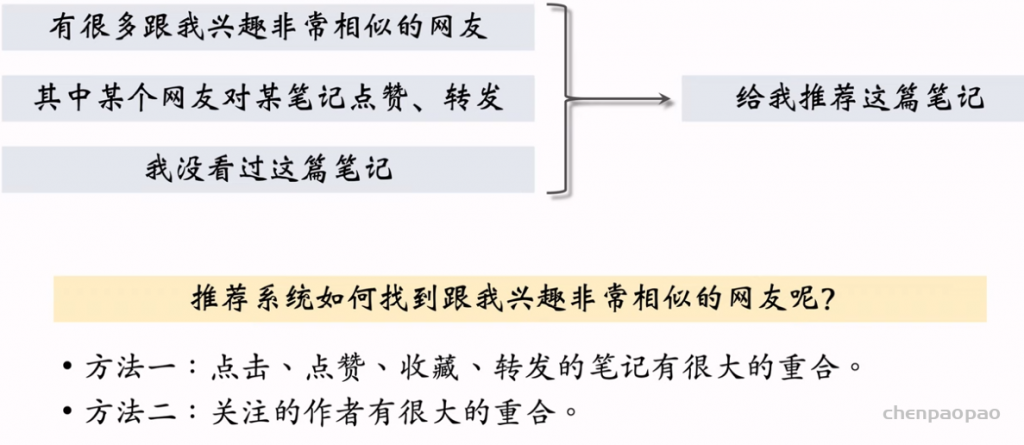
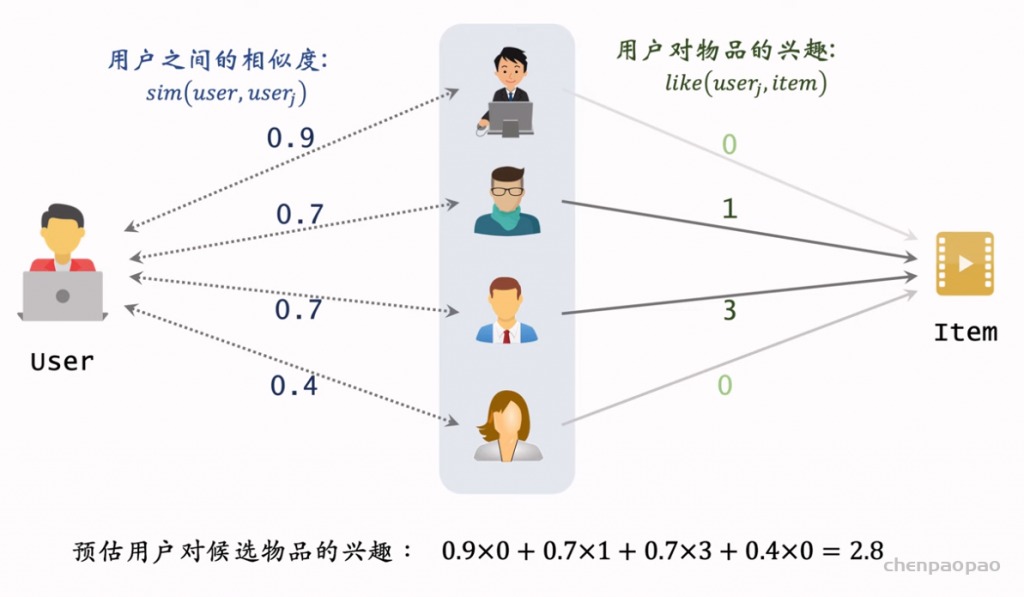
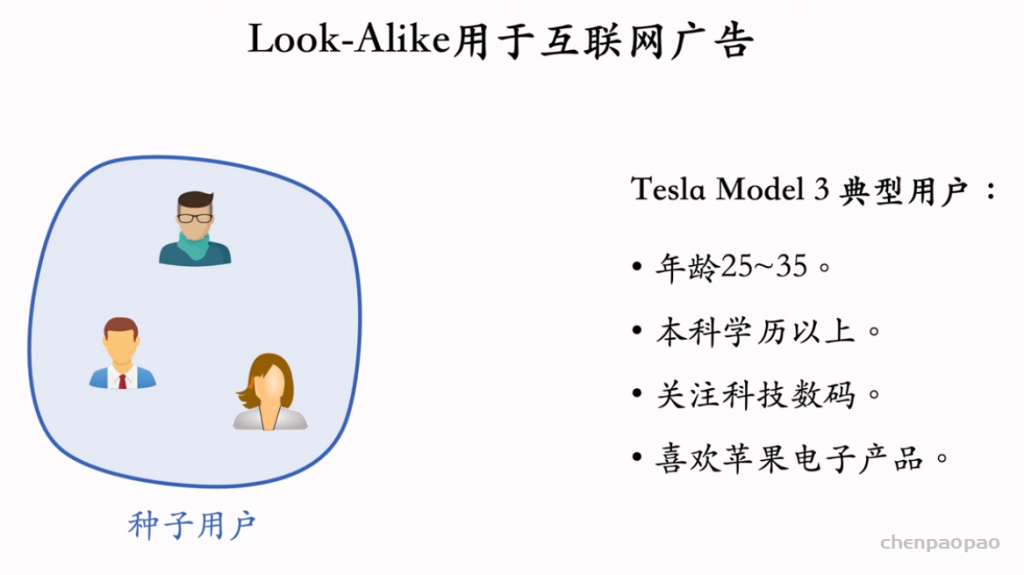
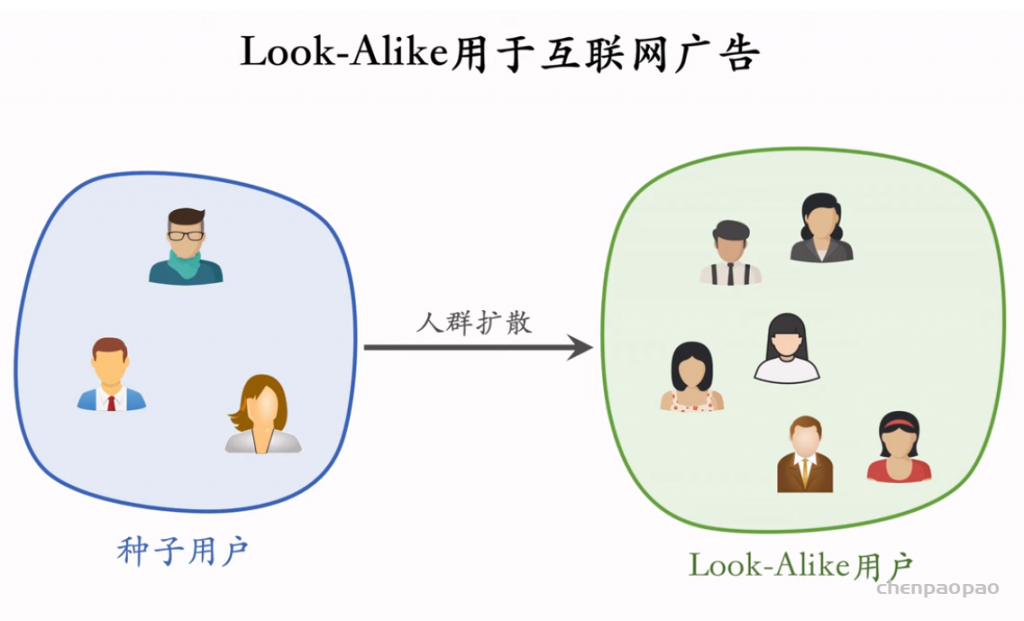
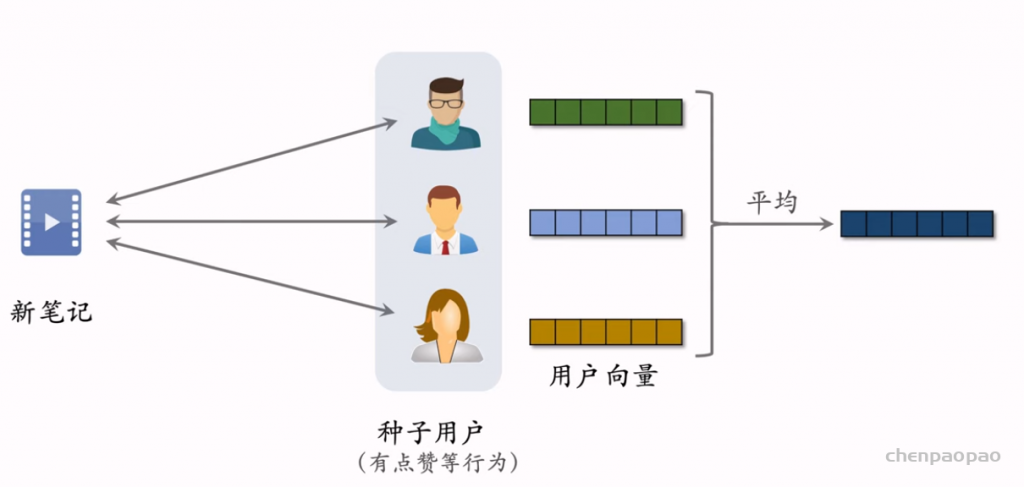
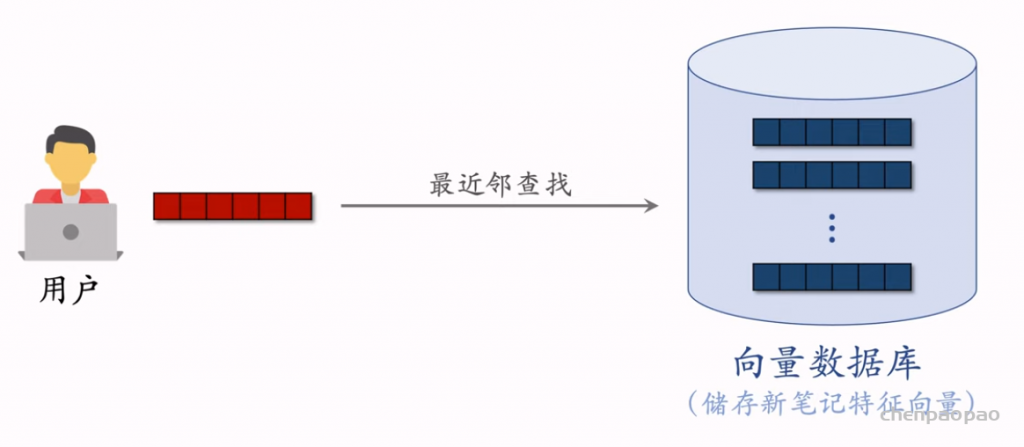
物品冷启04:Look-Alike 召回
Look-Alike 是一种召回通道,对冷启很有效。
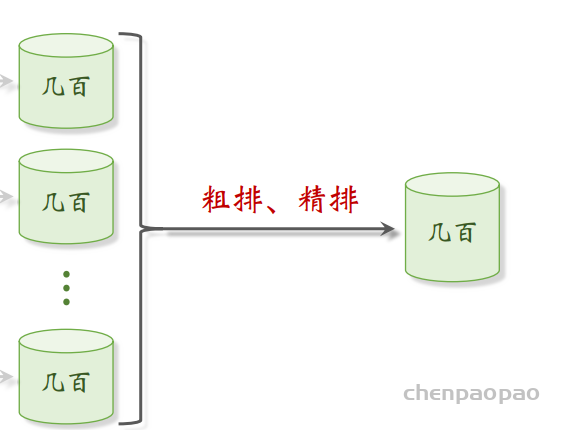
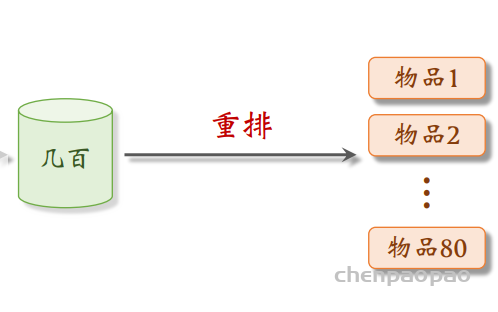
Look-Alike 适用于发布一段时间、但是点击次数不高的物品。物品从发布到热门,主要的透出渠道会经历三个阶段: 1. 类目召回、聚类召回。它们是基于内容的召回通道,适用于刚刚发布的物品。 2. Look-Alike 召回。它适用于有点击,但是点击次数不高的物品。 3. 双塔、ItemCF、Swing 等等。它们是基于用户行为的召回通道,适用于点击次数较高的物品。



物品冷启05:流量调控
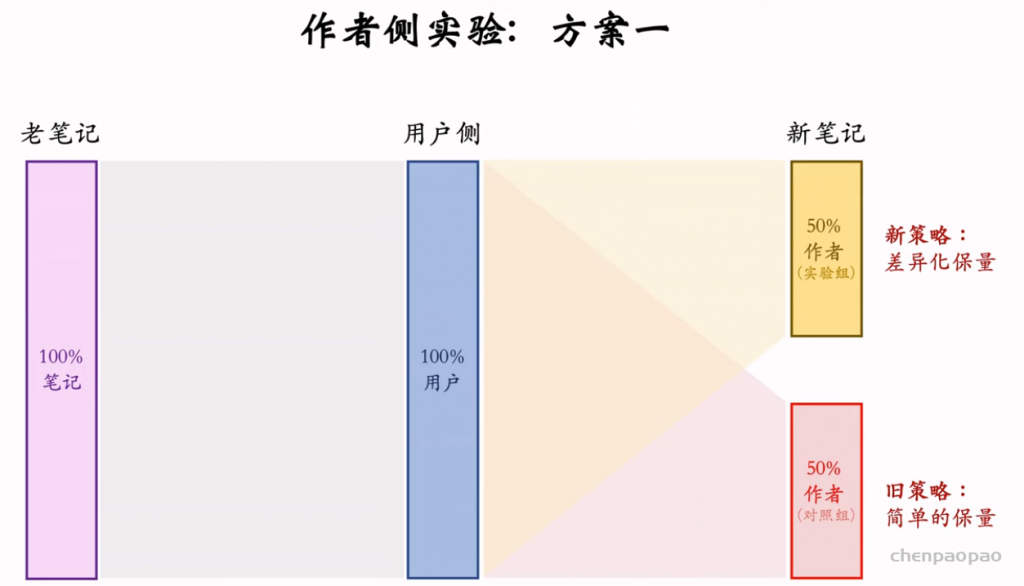
流量调控是物品冷启动最重要的一环,直接影响作者发布指标。流量调控的发展通常会经历这几个阶段:
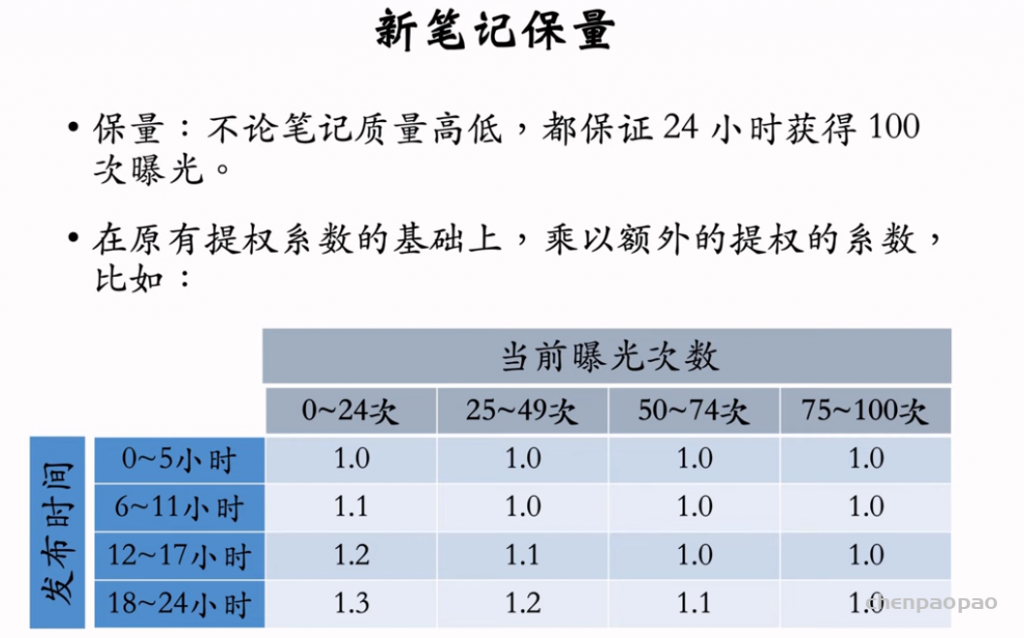
1. 在推荐结果中强插新笔记。 2. 对新笔记做提权(boost)。 3. 通过提权,对新笔记做保量。 4. 差异化保量。



新笔记做提权:










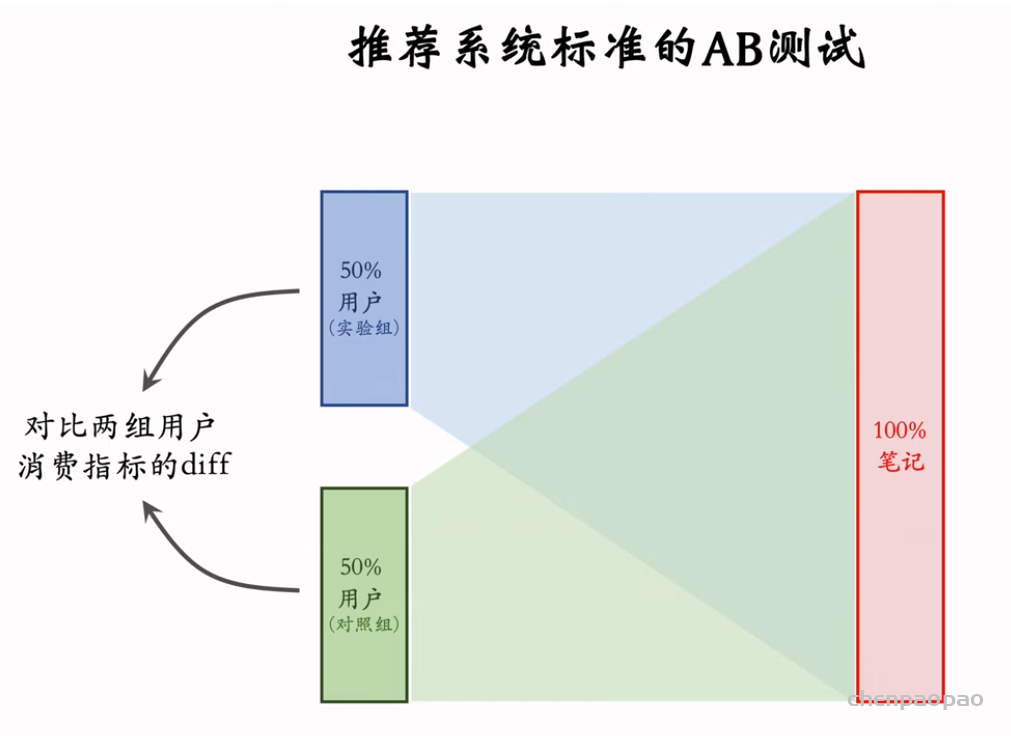
物品冷启06:冷启的AB测试
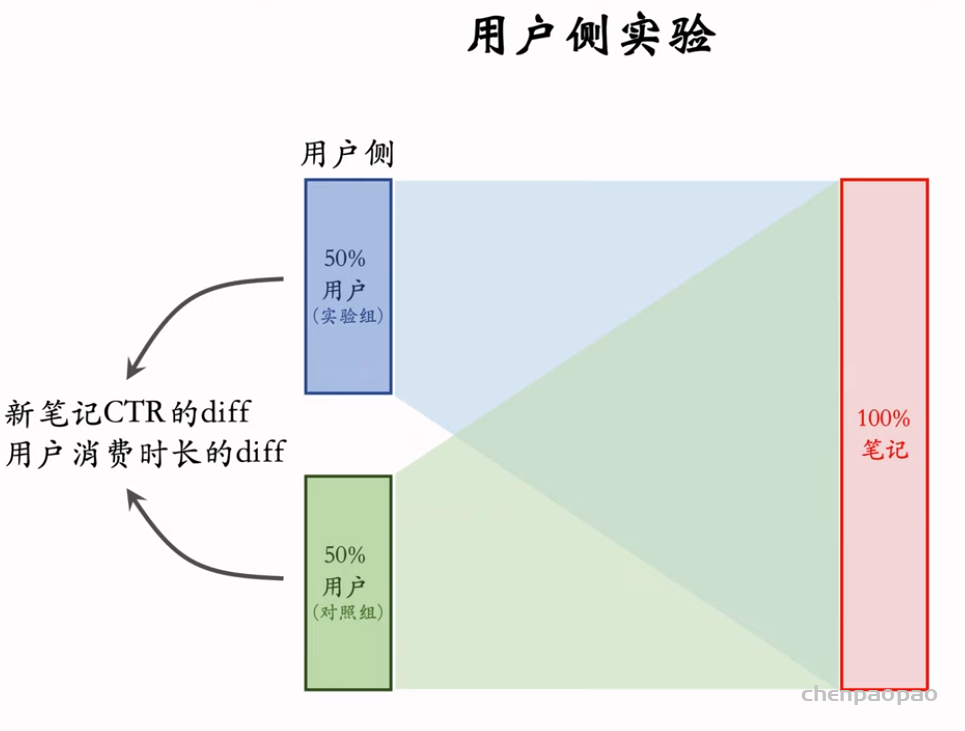
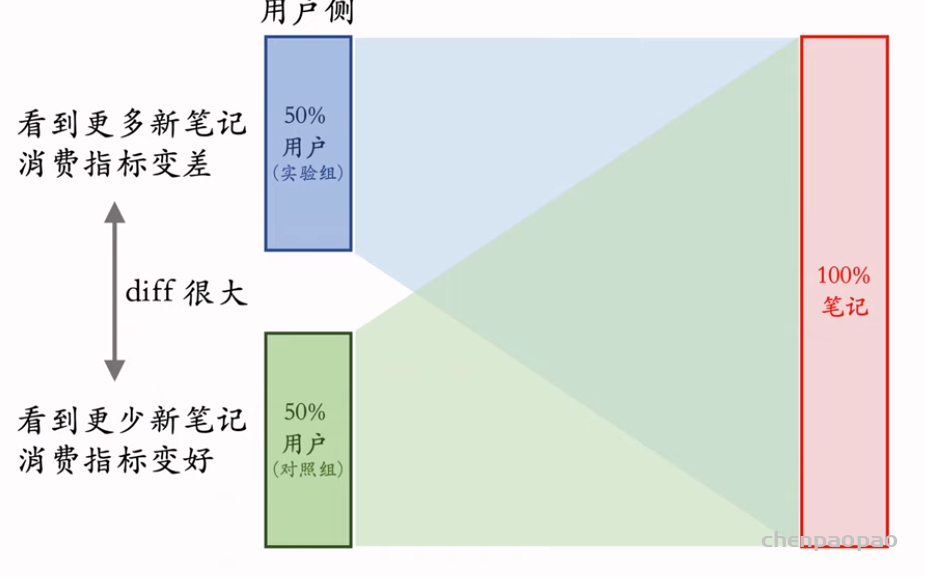
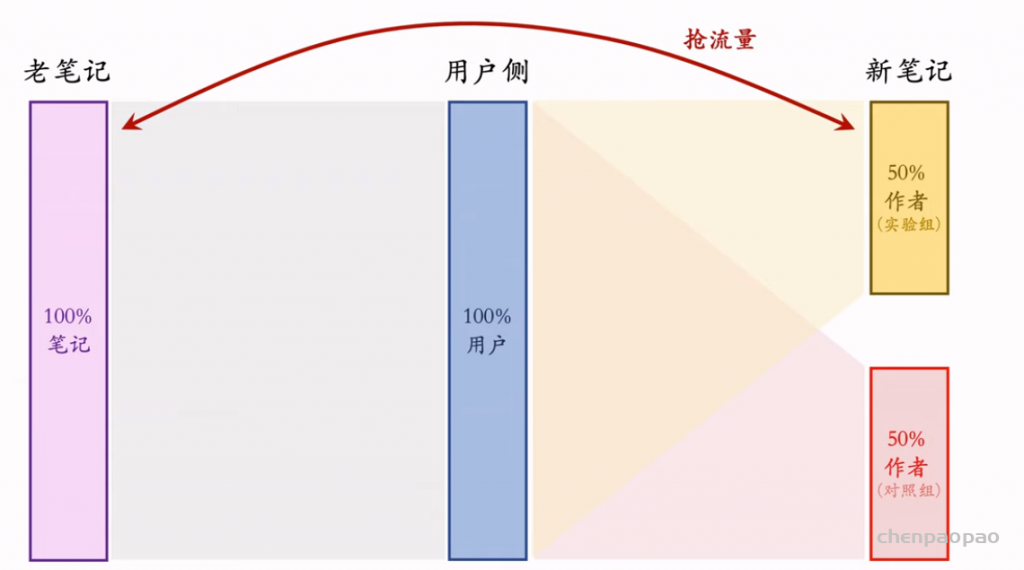
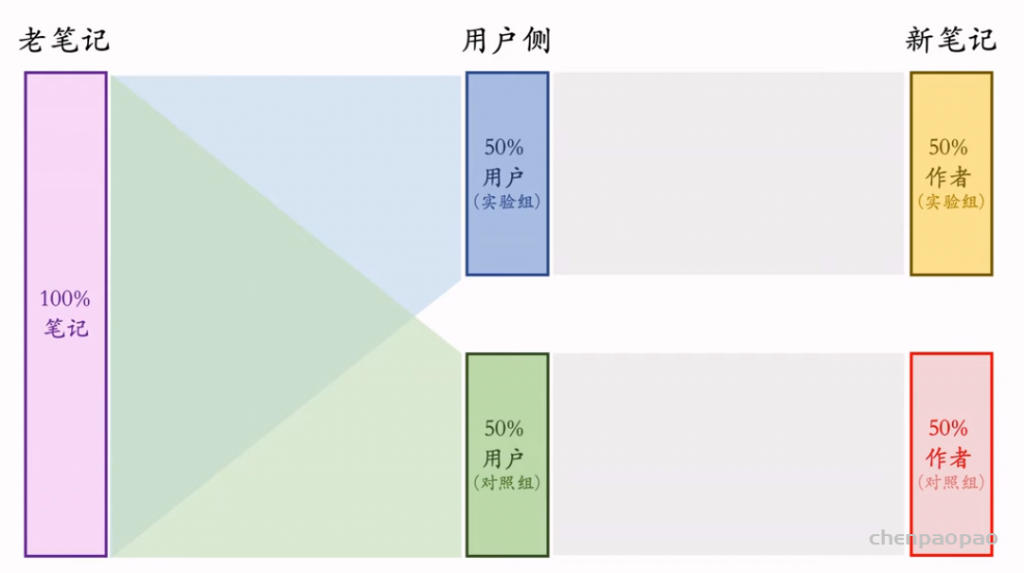
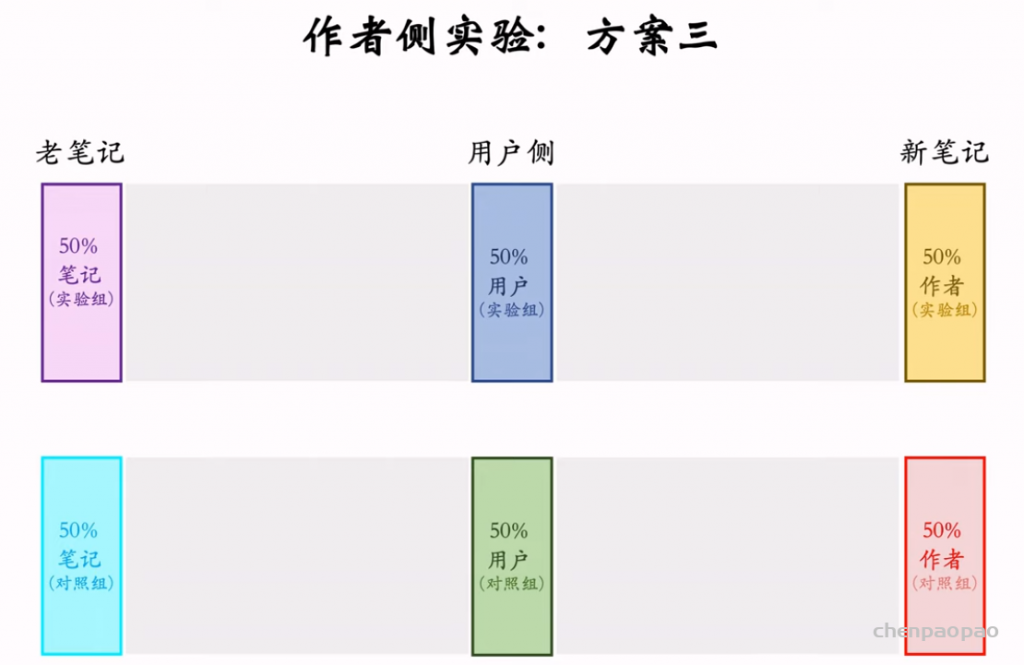
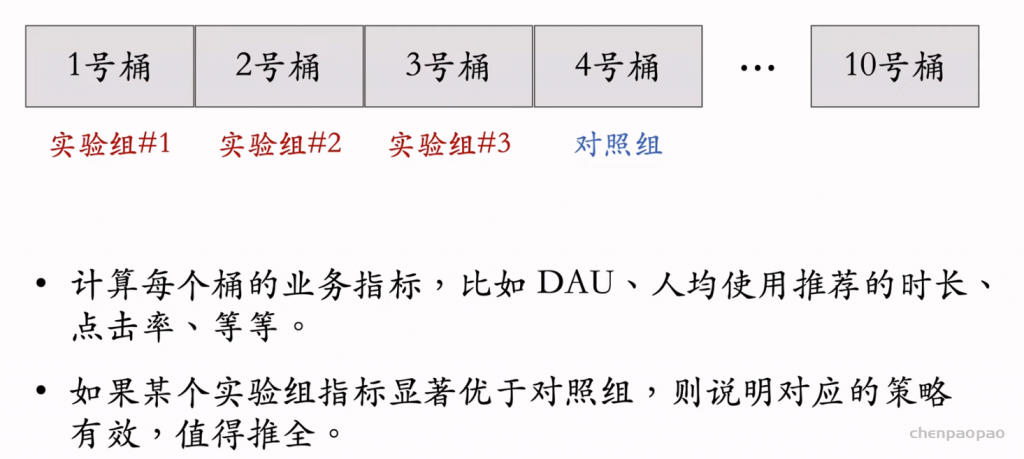
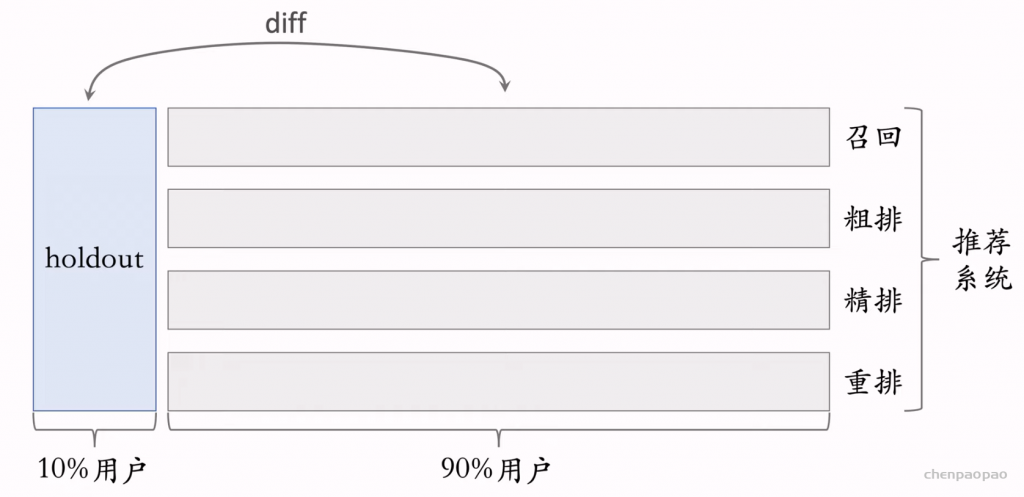
物品冷启动的AB测试,内容很烧脑,不建议初学者观看。推荐系统常用的AB测试只考察用户侧消费指标,而推荐系统的AB测试还需要额外考察作者侧发布指标。后者远比前者复杂,而且所有已知的实验方案都存在缺陷。