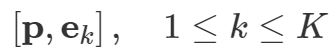论文链接:https://arxiv.org/pdf/2304.06718.pdf
项目链接:https://github.com/UX-Decoder/Segment-Everything-Everywhere-All-At-Once
试玩地址:https://huggingface.co/spaces/xdecoder/SEEM
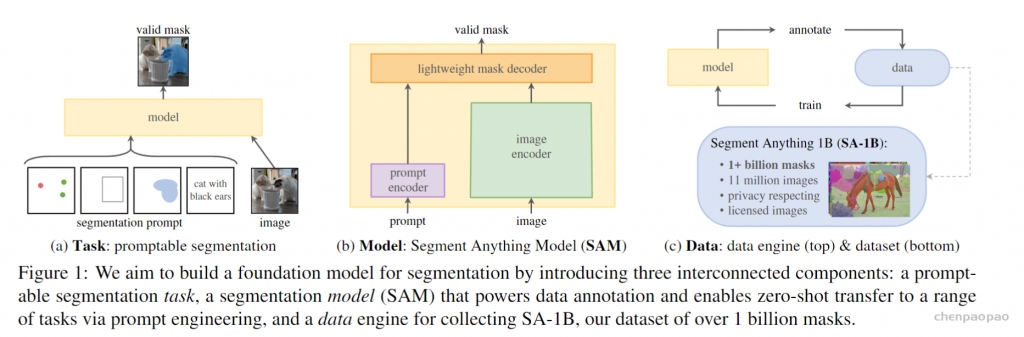
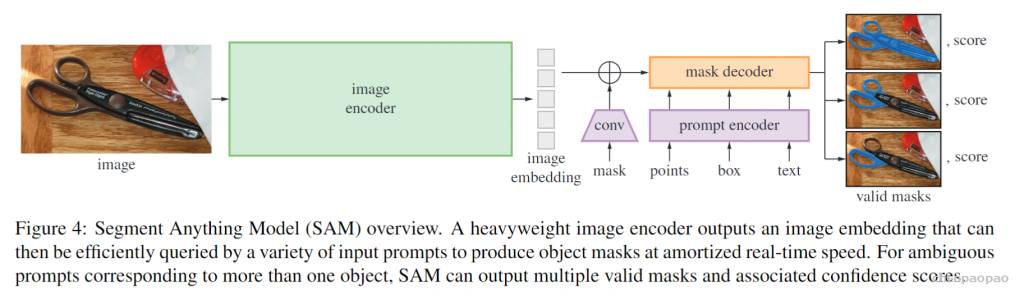
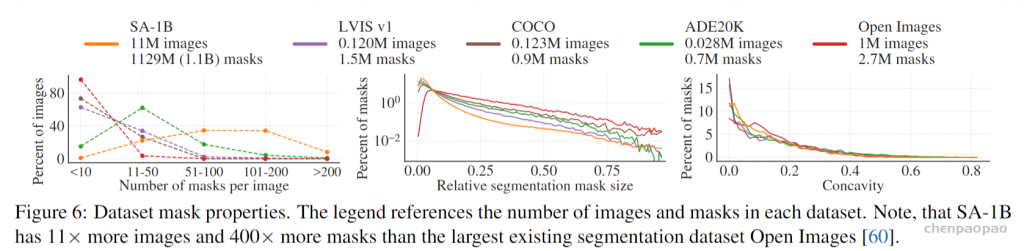
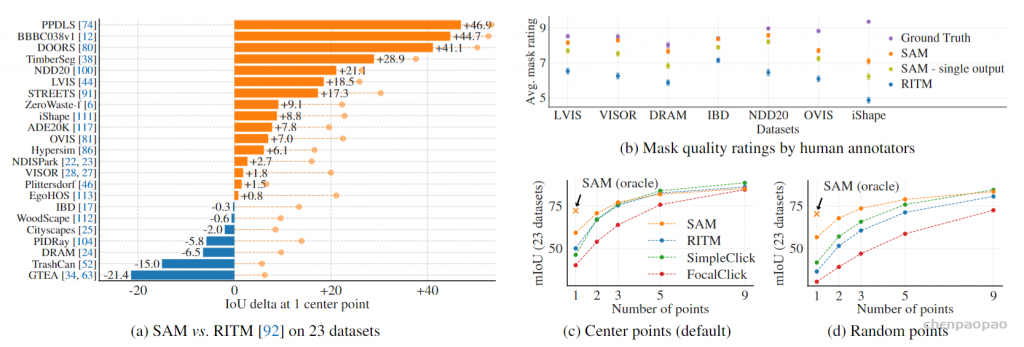
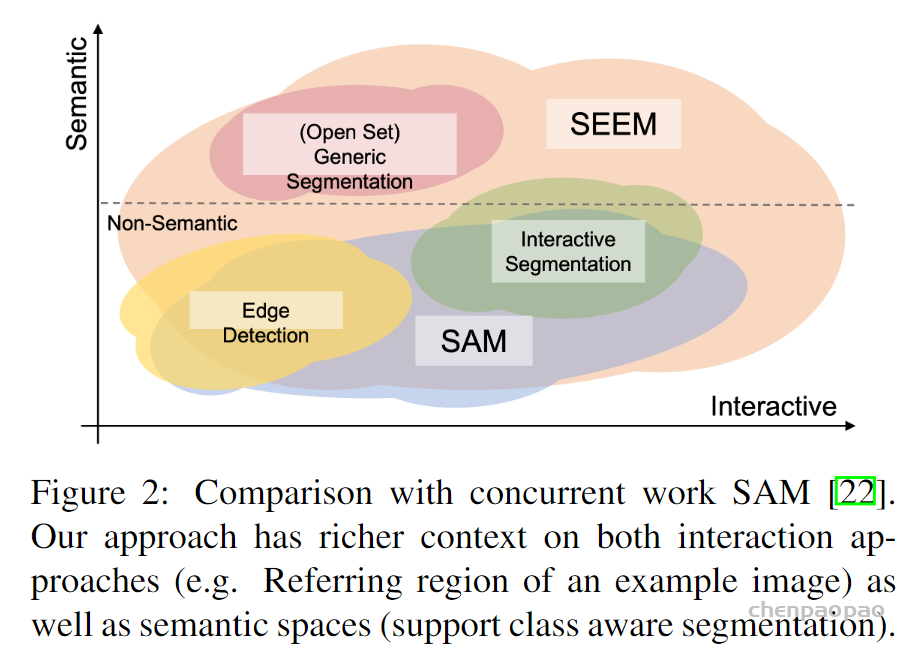
Meta 发布「分割一切」AI 模型 ——Segment Anything Model(SAM)。SAM 被认为是一个通用的图像分割基础模型,它学会了关于物体的一般概念,可以为任何图像或视频中的任何物体生成 mask,包括在训练过程中没有遇到过的物体和图像类型。这种「零样本迁移」的能力令人惊叹,甚至有人称 CV 领域迎来了「GPT-3 时刻」。
最近,一篇「一次性分割一切」的新论文《Segment Everything Everywhere All at Once》再次引起关注。在该论文中,来自威斯康星大学麦迪逊分校、微软、香港科技大学的几位华人研究者提出了一种基于 prompt 的新型交互模型 SEEM。SEEM 能够根据用户给出的各种模态的输入(包括文本、图像、涂鸦等等),一次性分割图像或视频中的所有内容,并识别出物体类别。该项目已经开源,并提供了试玩地址供大家体验。
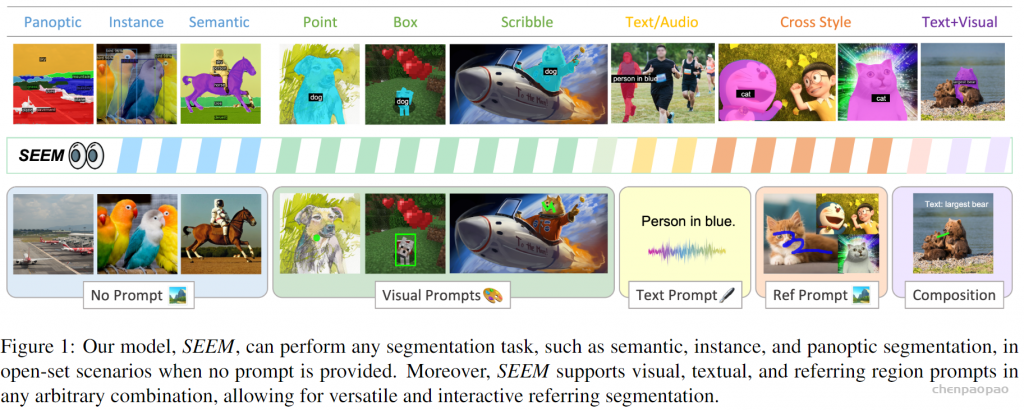
该研究通过全面的实验验证了 SEEM 在各种分割任务上的有效性。即使 SEEM 不具有了解用户意图的能力,但它表现出强大的泛化能力,因为它学会了在统一的表征空间中编写不同类型的 prompt。此外,SEEM 可以通过轻量级的 prompt 解码器有效地处理多轮交互。
大型语言模型 (Large Language Model, LLMs) 的成功,如 ChatGPT,证明了现代人工智能模型在与人类互动中的重要性,并提供了人工通用智能 (AGI) 的一瞥。与人类互动的能力需要一个用户友好的界面,可以接受尽可能多类型的人类输入,并生成人类容易理解的响应。在自然语言处理 (NLP) 领域,这样的通用交互界面已经出现并发展了一段时间,从早期的模型如 GPT 和 T5,到一些更高级的技术,如提示和思维链。在图像生成领域,一些最近的工作尝试将文本提示与其他类型,如草图或布局相结合,以更准确地捕捉用户意图,生成新的提示并支持多轮人工智能交互。
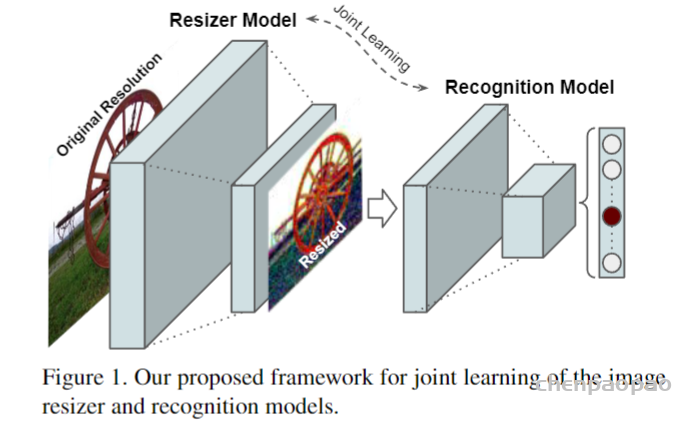
本文提出了一种通用的提示方案,可以通过多种类型的提示(如文本、点击、图像)与用户交互,进而构建一个通用的 “分割一切” 的模型 SEEM。该模型采用 Transformer 编码器-解码器结构,将所有查询作为提示输入到解码器中,并使用图像和文本编码器作为提示编码器来编码所有类型的查询,从而使视觉和文本提示始终保持对齐。
此外,该模型还引入了记忆提示来缩减以前的分割信息,并与其他提示进行通信,以增强互动性。与 SAM 等其他工作不同的是,该模型支持多种提示类型,具有零样本泛化能力。实验结果表明,SEEM 在许多分割任务中具有强大的性能,包括封闭集和开放集全景分割、交互式分割、接地分割以及使用多种提示的分割任务。
在变形金刚的合影中把「擎天柱」分割出来:

还能对一类物体做分割,比如在一张景观图片中分割出所有建筑物:

SEEM 也能轻松分割出视频中移动的物体:

这个分割效果可以说是非常丝滑了。我们来看一下该研究提出的方法。
方法概述
该研究旨在提出一个通用接口,以借助多模态 prompt 进行图像分割。为了实现这一目标,他们提出了一种包含 4 个属性的新方案,包括多功能性(versatility)、组合性(compositionality)、交互性(interactivity)和语义感知能力(semantic-awareness),具体包括
1)多功能性该研究提出将点、掩码、文本、检测框(box)甚至是另一个图像的参考区域(referred region)这些异构的元素,编码成同一个联合视觉语义空间中的 prompt。
2)组合性通过学习视觉和文本 prompt 的联合视觉语义空间来即时编写查询以进行推理。SEEM 可以处理输入 prompt 的任意组合。
3)交互性:该研究引入了通过结合可学习的记忆(memory) prompt,并通过掩码指导的交叉注意力保留对话历史信息。
4)语义感知能力:使用文本编码器对文本查询和掩码标签进行编码,从而为所有输出分割结果提供了开放集语义。
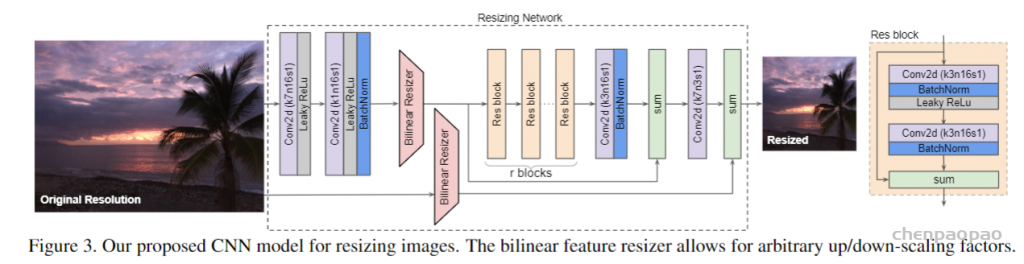
架构方面,SEEM 遵循一个简单的 Transformer 编码器 – 解码器架构,并额外添加了一个文本编码器。在 SEEM 中,解码过程类似于生成式 LLM,但具有多模态输入和多模态输出。所有查询都作为 prompt 反馈到解码器,图像和文本编码器用作 prompt 编码器来编码所有类型的查询。
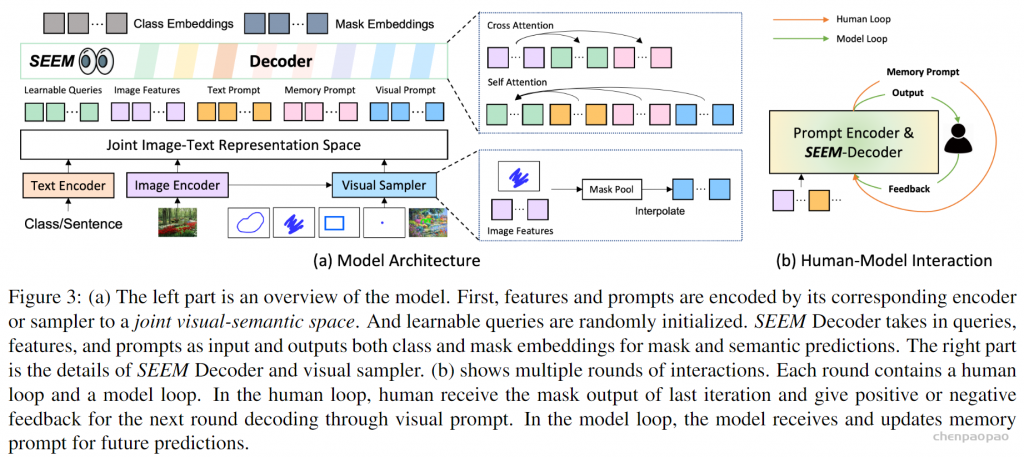
具体来说,该研究将所有查询(如点、框和掩码)编码为视觉 prompt,同时使用文本编码器将文本查询转换为文本 prompt,这样视觉和文本 prompt 就能保持对齐。5 种不同类型的 prompt 都能都映射到联合视觉语义空间中,通过零样本适应来处理未见过的用户 prompt。通过对不同的分割任务进行训练,模型具有处理各种 prompt 的能力。此外,不同类型的 prompt 可以借助交叉注意力互相辅助。最终,SEEM 模型可以使用各种 prompt 来获得卓越的分割结果。
除了强大的泛化能力,SEEM 在运行方面也很高效。研究人员将 prompt 作为解码器的输入,因此在与人类进行多轮交互时,SEEM 只需要在最开始运行一次特征提取器。在每次迭代中,只需要使用新的 prompt 再次运行一个轻量级的解码器。因此,在部署模型时,参数量大运行负担重的特征提取器可以在服务器上运行,而在用户的机器上仅运行相对轻量级的解码器,以缓解多次远程调用中的网络延迟问题。
如上图 3(b)所示,在多轮交互中,每次交互包含一个人工循环和一个模型循环。在人工循环中,人接收上一次迭代的掩码输出,并通过视觉 prompt 给出下一轮解码的正反馈或负反馈。在模型循环中,模型接收并更新记忆 prompt 供未来的预测。
SEEM 是一种采用通用编码器-解码器架构的模型, 但具有复杂的查询和提示交互, 如图3(a) 所示。给定输入图像 , 首先使用图像编码器提取图像特征 , 然后 SEEM 解码器基于与视觉、文本和记忆提示、 交互的查询输出 来预测掩模 和语义概念 。
在训练期间, 被复制用于全景分割、指代分割和交互分割。
在推断时,可学习的查询从相同的权重集合初始化,从而实现 zero-shot 组合。这种设计受到 X-Decoder 的成功实践的启发,但不同之处是,这允许使用具有以下属性的通用图像分割模型:
多功能
除了文本输入外,SEEM 还引入了视觉提示来处理所有的非文本输入,例如点、框、涂鸦和另一幅图像的区域引用等。
当文本提示无法准确识别正确的分割区域时,非文本提示就能够提供有用的补充信息,帮助准确定位分割区域。 以往的交互式分割方法通常将空间查询转换为掩模,然后将它们馈送到图像骨干网络中,或者针对每种输入类型(点、框)使用不同的提示编码器。然而,这些方法存在重量过大或难以泛化的问题。
为了解决这些问题,SEEM 提出了使用视觉提示来统一所有非文本输入。这些视觉提示以令牌的形式统一表示,并位于同一视觉嵌入空间中,这样就可以使用同一种方法来处理所有非文本输入。 为了提取这些视觉提示的特征,该模型还引入了一个称为“视觉采样器”的方法,用于从输入图像或引用图像的特征映射中提取特定位置的特征。
此外,SEEM 还通过全景和引用分割来持续学习通用的视觉-语义空间,使得视觉提示与文本提示能够自然地对齐,从而更好地指导分割过程。在学习语义标签时,提示特征与文本提示映射到相同的空间以计算相似度矩阵,从而更好地协同完成分割任务。
可组合
用户可以使用不同或组合的输入类型表达其意图,因此在实际应用中,组合式提示方法至关重要。
然而,在模型训练时会遇到两个问题。首先,训练数据通常只涵盖一种交互类型(例如,无、文本、视觉)。其次,虽然我们已经使用视觉提示来统一所有非文本提示并将它们与文本提示对齐,但它们的嵌入空间仍然本质上不同。
为了解决这个问题,本文提出了将不同类型的提示与不同的输出进行匹配的方法。在模型训练后,SEEM 模型变得熟悉了所有提示类型,并支持各种组合方式,例如无提示、单提示类型或同时使用视觉和文本提示。值得注意的是,即使是从未像这样训练过的样本,视觉和文本提示也可以简单地连接并馈送到 SEEM 解码器中。
可交互
SEEM 通过引入记忆提示来进行多轮交互式分割,使得分割结果得到进一步优化。记忆提示是用来传递先前迭代中的分割结果,将历史信息编码到模型中,以在当前轮次中使用。
不同于之前的工作使用一个网络来编码掩模,SEEM 采用掩模引导的交叉注意力机制来编码历史信息,这可以更有效地利用分割历史信息来进行下一轮次的优化。值得注意的是,这种方法也可以扩展到同时进行多个对象的交互式分割。
语义感知
与之前的类别无关的交互式分割方法不同,SEEM 将语义标签应用于来自所有类型提示组合的掩码,因为它的视觉提示特征与文本特征在一个联合视觉-语义空间中是对齐的。
在训练过程中,虽然没有为交互式分割训练任何语义标签,但是由于联合视觉-语义空间的存在,掩膜嵌入(mask embeddings)和 视觉取样器 (visual sampler)之间的相似度矩阵可以被计算出来,从而使得计算出的 logits 可以很好的对齐,如图3(a)所示。
这样,在推理过程中,查询图像就可以汇集多个示例的信息。
实验结果
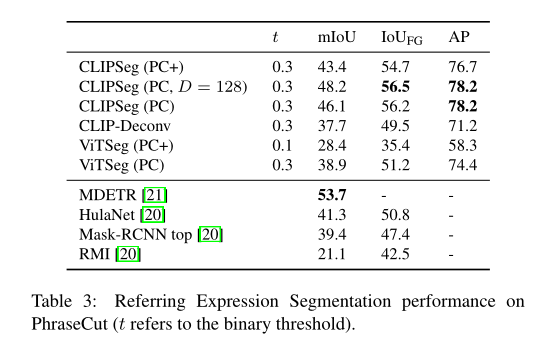
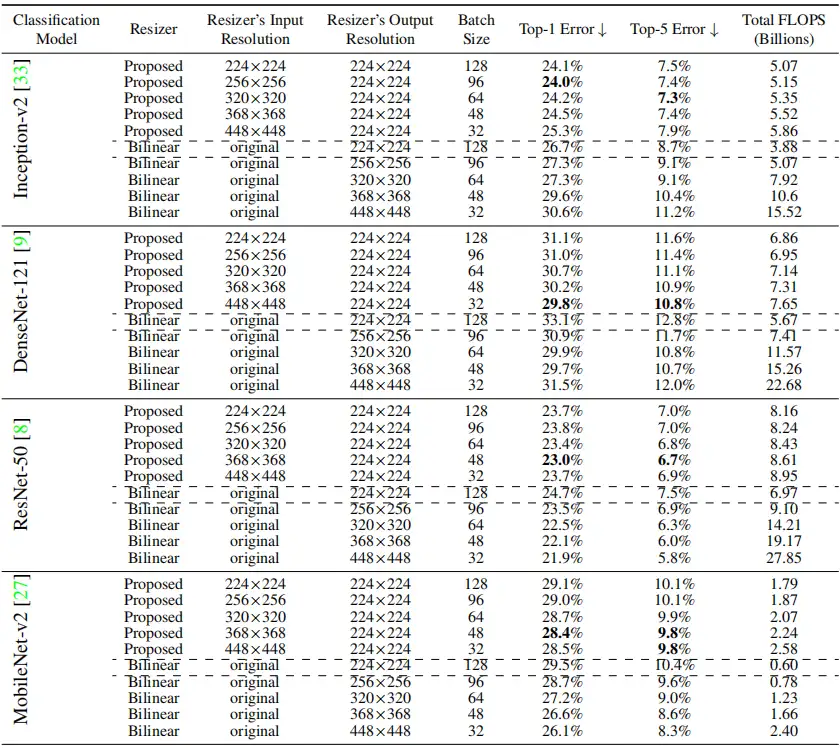
该研究将 SEEM 模型与 SOTA 交互式分割模型进行了实验比较,结果如下表 1 所示。
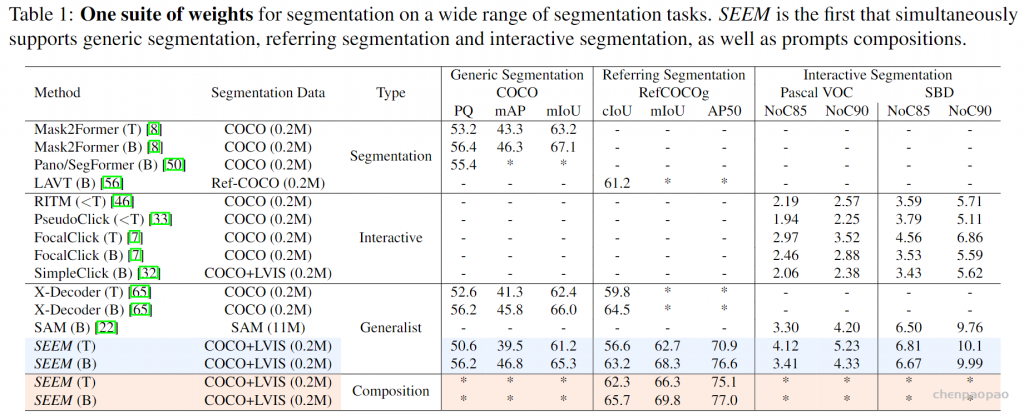
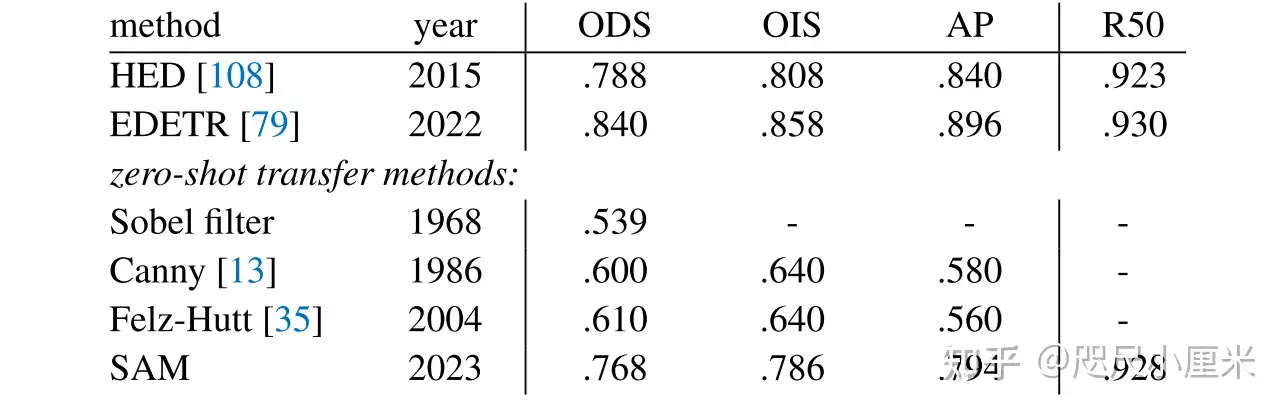
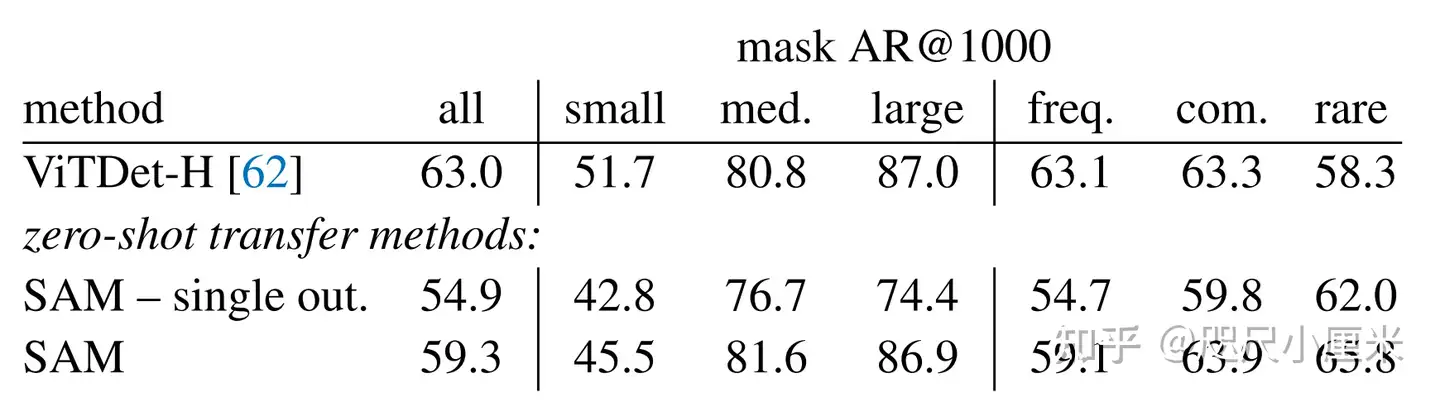
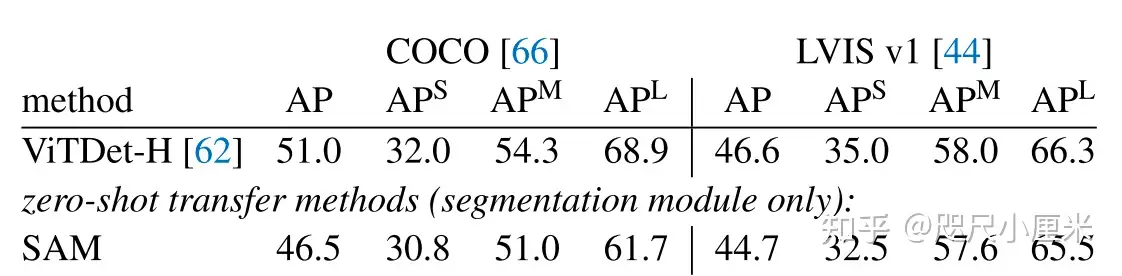
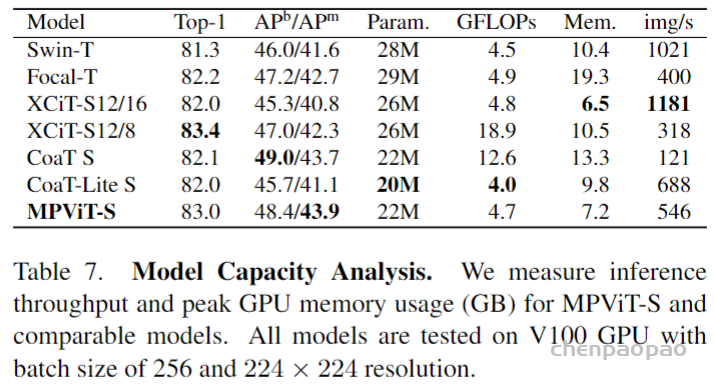
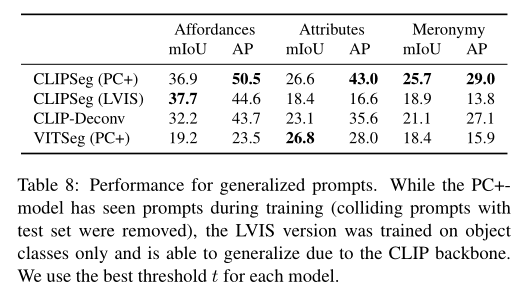
作为一个通用模型,SEEM 实现了与 RITM,SimpleClick 等模型相当的性能,并且与 SAM 的性能非常接近,而 SAM 用于训练的分割数据是 SEEM 的 50 倍之多。
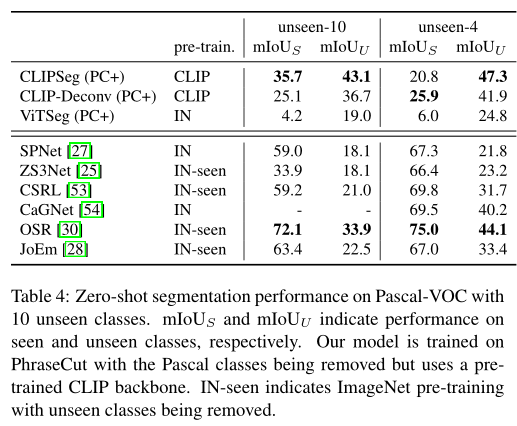
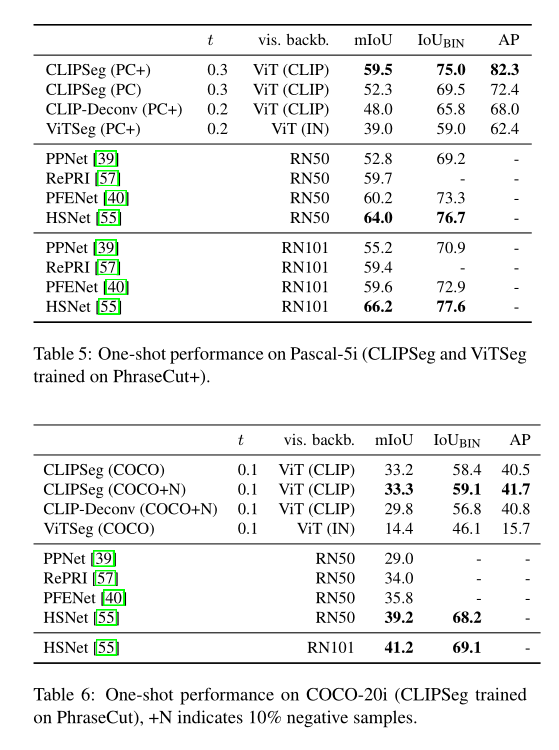
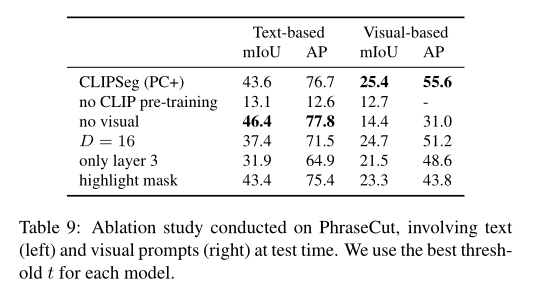
与现有的交互式模型不同,SEEM 是第一个不仅支持经典分割任务,还支持各种用户输入类型的通用接口,包括文本、点、涂鸦、框和图像,提供强大的组合功能。如下表 2 所示,通过添加可组合的 prompt,SEEM 在 cIoU,mIoU 等指标上有了显著的分割性能提升。

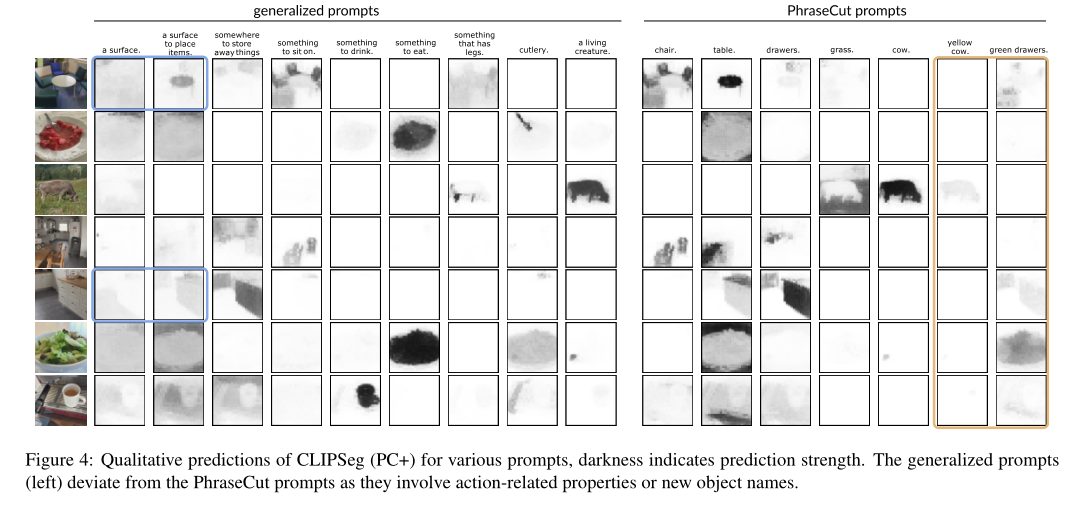
我们再来看一下交互式图像分割的可视化结果。用户只需要画出一个点或简单涂鸦,SEEM 就能提供非常好的分割结果

也可以输入文本,让 SEEM 进行图像分割

还能直接输入参考图像并指出参考区域,对其他图像进行分割,找出与参考区域一致的物体:

Zero-shot video object segmentation using the first frame plus one stroke:

总结
本文介绍了 SEEM,该模型可以同时对所有语义进行全局分割,并且可以与用户互动,接受来自用户的不同类型的视觉提示,包括点击、框选、多边形、涂鸦、文本和参考图像分割。这些提示 (prompt) 通过提示编码器映射到联合视觉-语义空间中,使我们的模型适用于各种提示,并可以灵活地组合不同的提示。通过大量实验证明,该模型在几个开放和交互分割基准测试上表现出竞争力。
当然,SEEM 并不是完美的,其存在的两个主要限制为:训练数据规模有限,SEEM 不支持基于部分的分割。我们通过利用更多的训练数据和监督,可以进一步提高模型性能,而基于部分的分割可以在不改变模型的情况下无缝地从中学习。最后,非常感谢 SAM 提出的分割数据集,这是是非常宝贵的资源,我们应该好好利用起来。