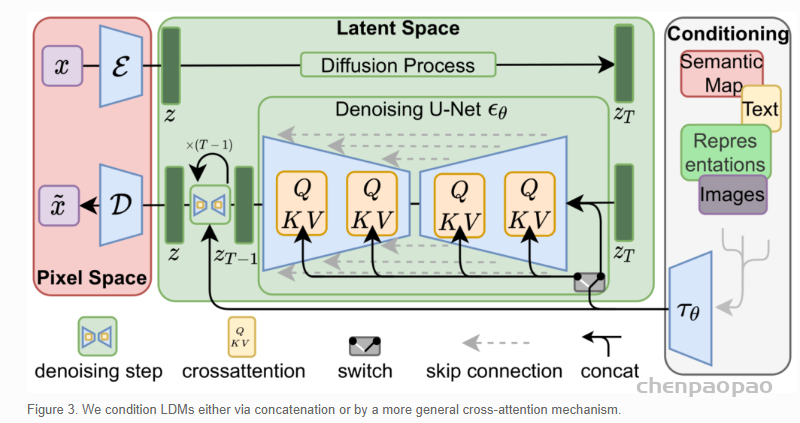
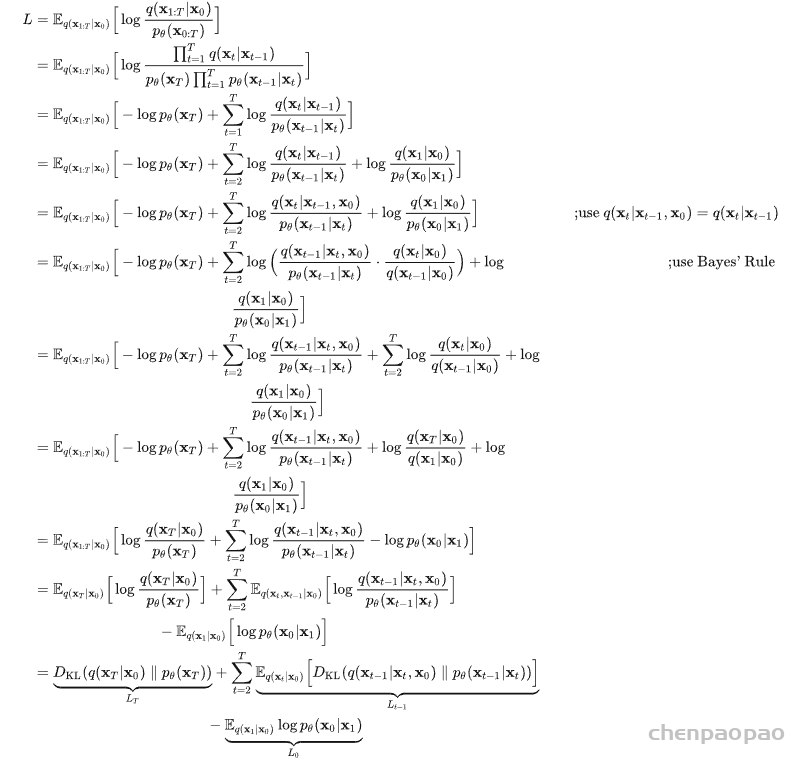
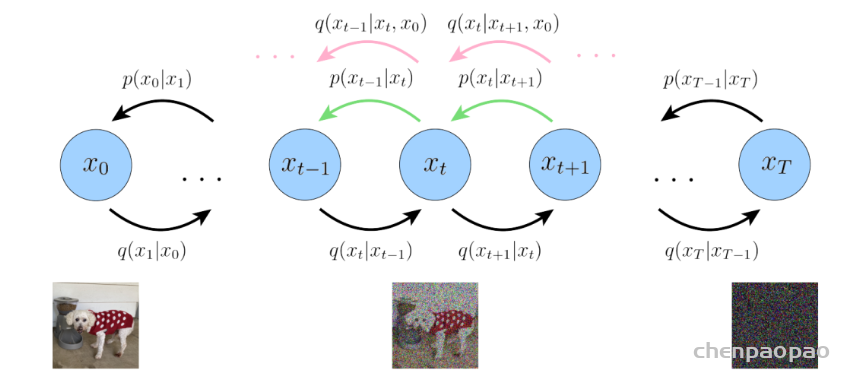
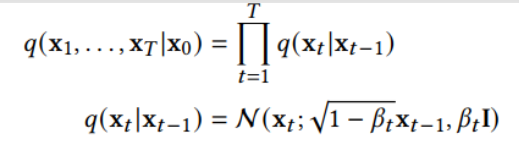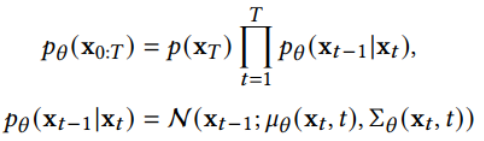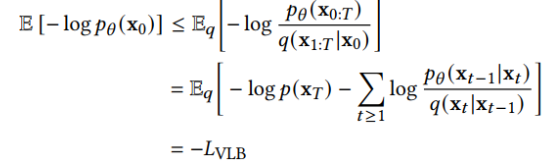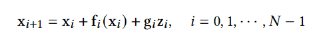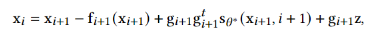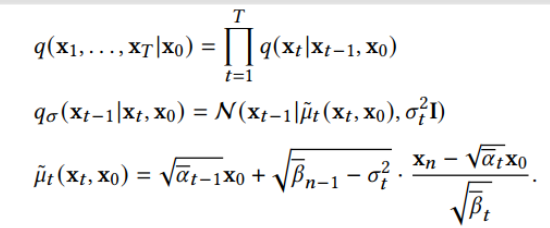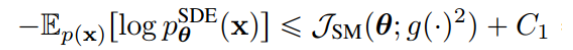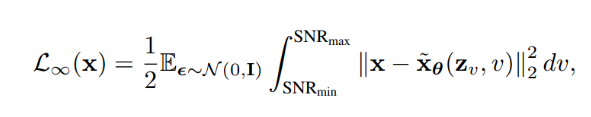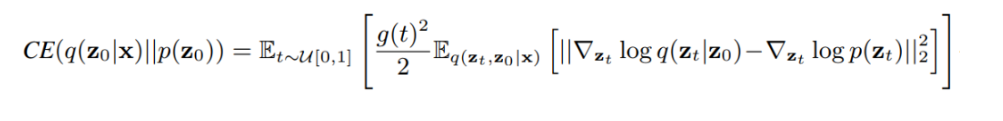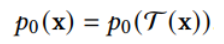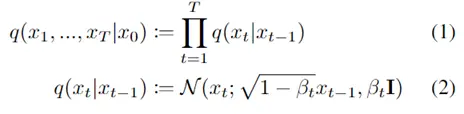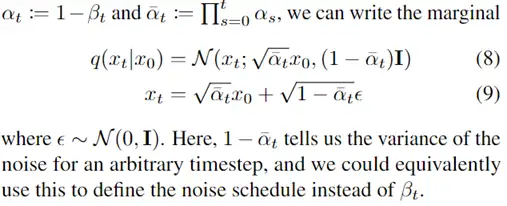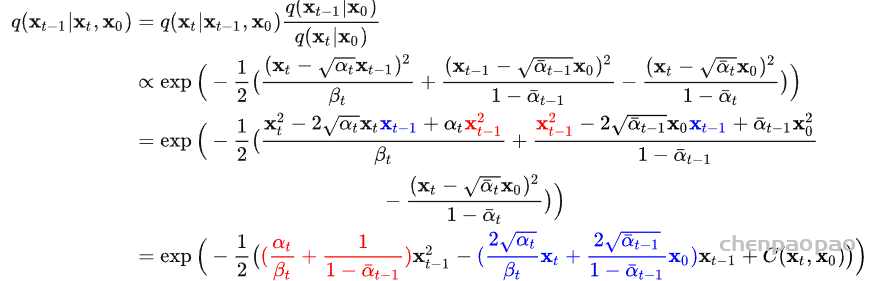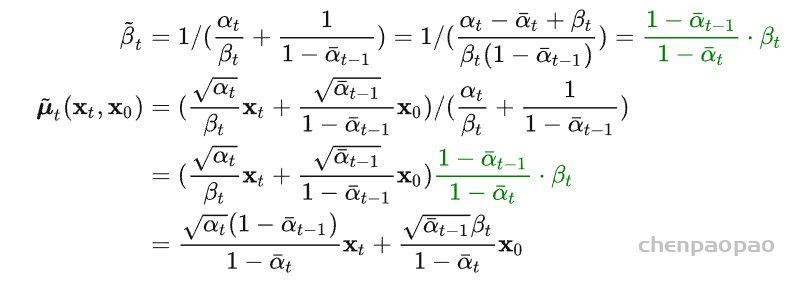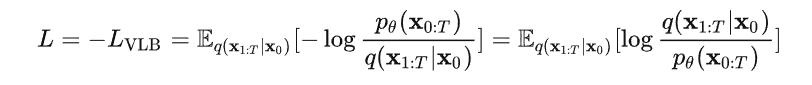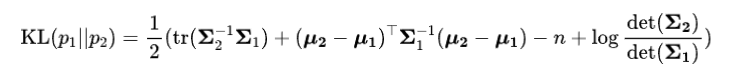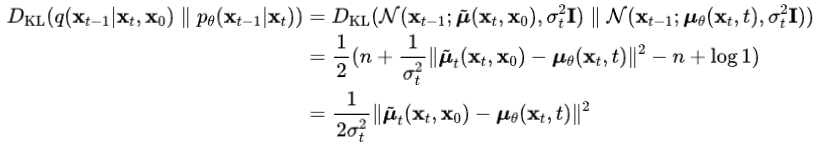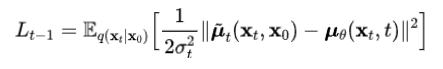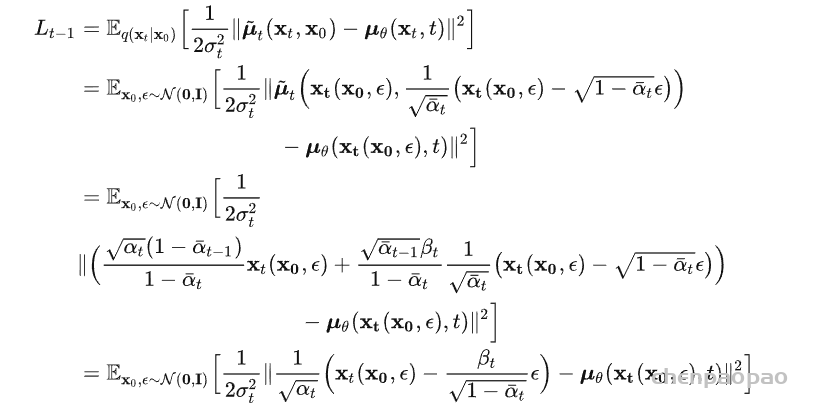High-Resolution Image Synthesis with Latent Diffusion Models
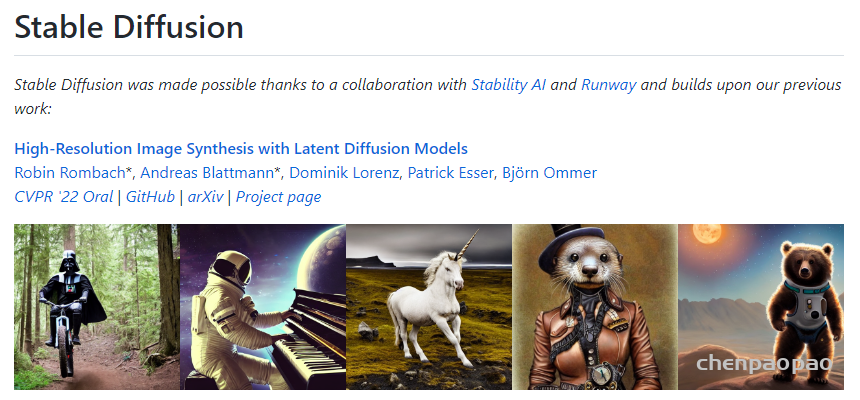
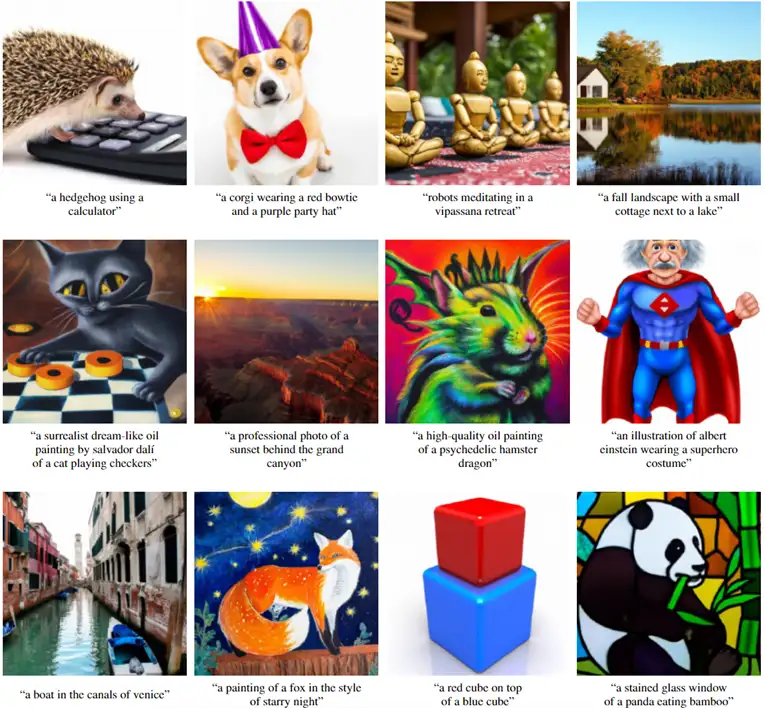
Stable Diffusion 是一个“文本到图像”的人工智能模型。近日,Stable AI 公司向公众开放了它的预训练模型权重。当输入一个文字描述时,Stable Diffusion 可以生成 512×512 像素的图像,这些图像如相片般真实,反映了文字描述的场景。
这个项目先是经历了早期的代码发布,而后又向研究界有限制地发布了模型权重,现在模型权重已经向公众开放。对于最新版本,任何人都可以在为普通消费者设计的硬件上下载和使用 Stable Diffusion。该模型不仅支持文本到图像的生成,而且还支持图像到图像的风格转换和放大。与之一同发布的还有 DreamStudio 测试版,这是一个用于该模型的 API 和 Web 用户界面。
Stable Diffusion 可以支持众多的操作。与 DALL-E 类似,它可以生成一个高质量的图像,并使其完全符合所需图像的文字描述。我们也可以使用一个直观的草图和所需图像的文字描述,从而创建一个看起来很真实的图像。类似的“图像到图像”的能力可以在 Meta AI 的 Make-A-Scene 模型中找到,该模型刚发布不久。
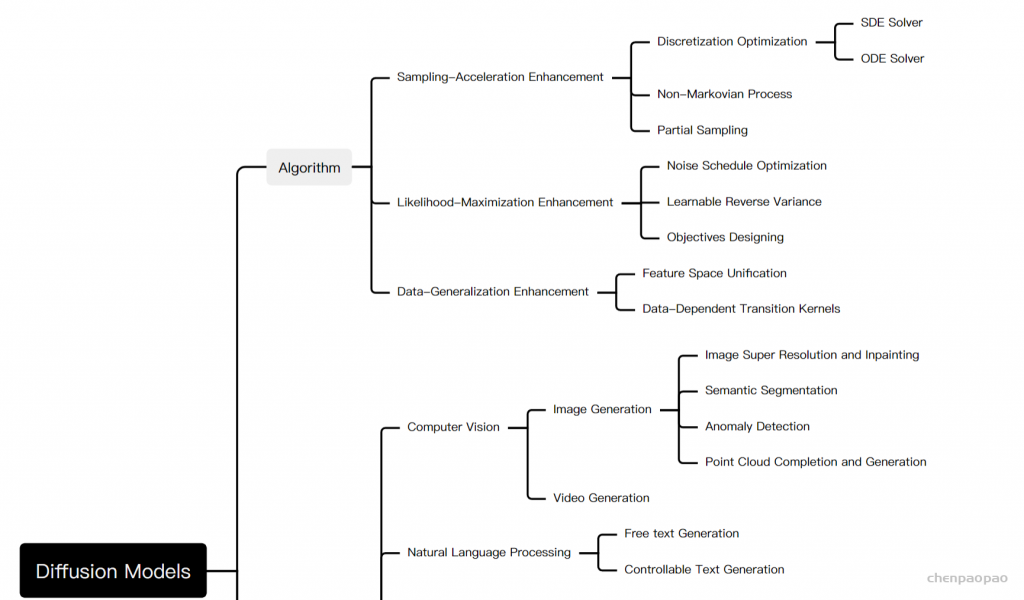
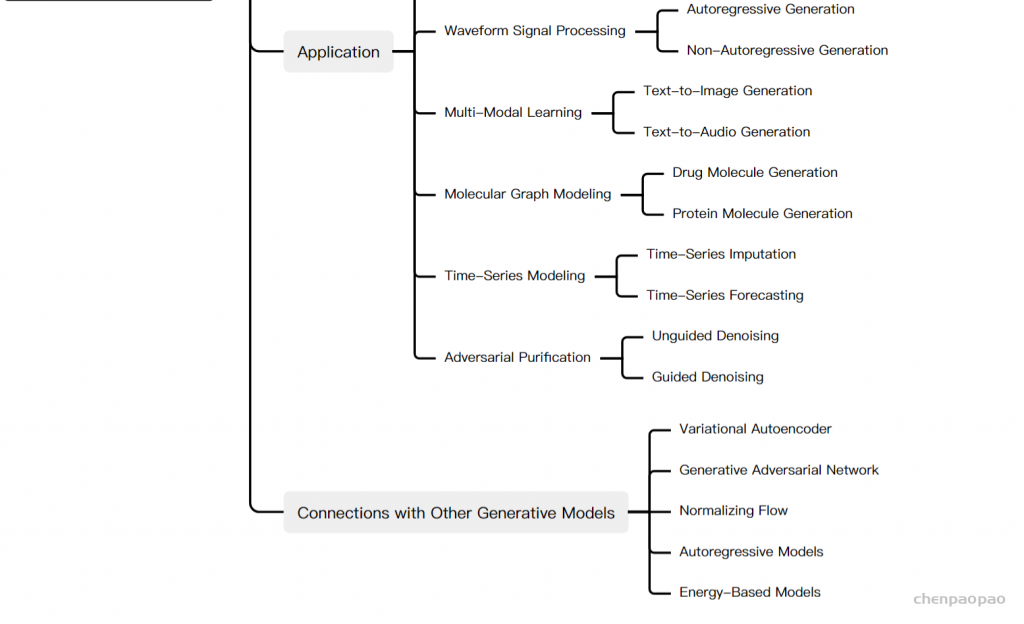
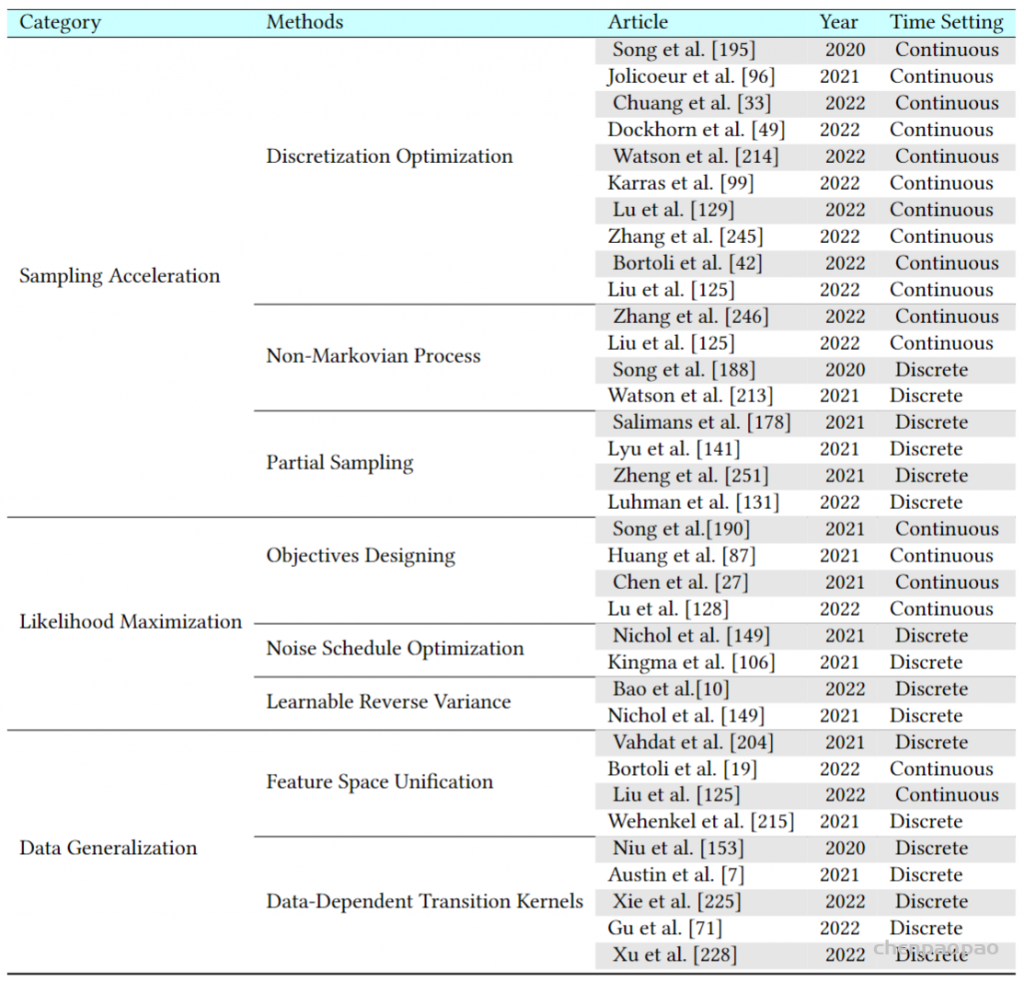
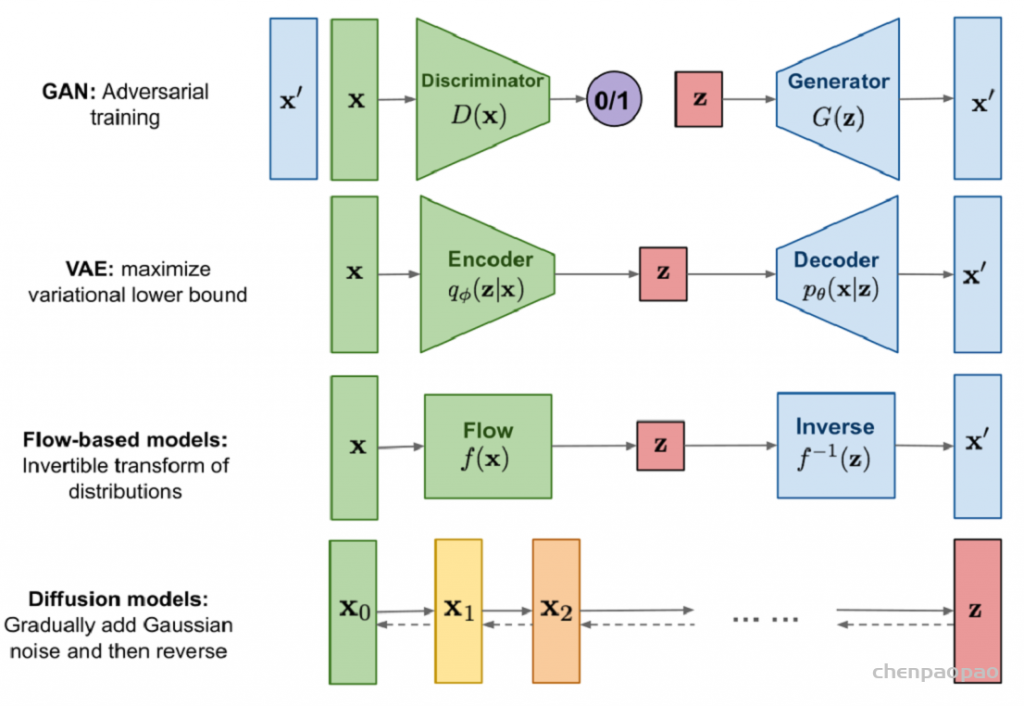
Diffusion Models: A Comprehensive Survey of Methods and Applications来自加州大学&Google Research的Ming-Hsuan Yang、北京大学崔斌实验室以及CMU、UCLA、蒙特利尔Mila研究院等众研究团队,首次对现有的扩散生成模型(diffusion model)进行了全面的总结分析,从diffusion model算法细化分类、和其他五大生成模型的关联以及在七大领域中的应用等方面展开,最后提出了diffusion model的现有limitation和未来的发展方向。
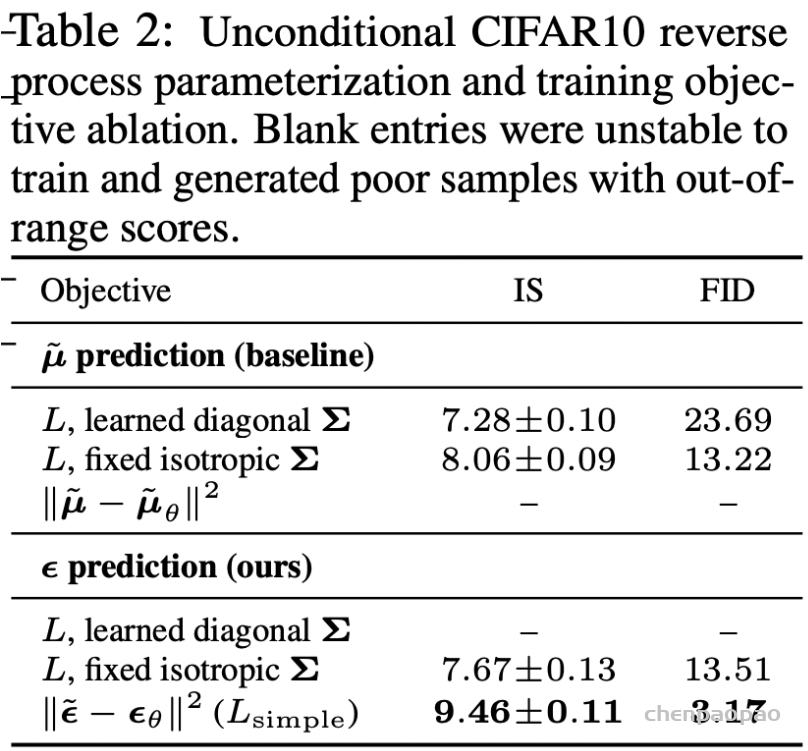
扩散模型假设数据存在于欧几里得空间,即具有平面几何形状的流形,并添加高斯噪声将不可避免地将数据转换为连续状态空间,所以扩散模型最初只能处理图片等连续性数据,直接应用离散数据或其他数据类型的效果较差。这限制了扩散模型的应用场景。数个研究工作将扩散模型推广到适用于其他数据类型的模型,我们对这些方法进行了详细地阐释。我们将其细化分类为两类方法:Feature Space Unification,Data-Dependent Transition Kernels。1.Feature Space Unification方法将数据转化到统一形式的latent space,然后再latent space上进行扩散。LSGM提出将数据通过VAE框架先转换到连续的latent space 上后再在其上进行扩散。这个方法的难点在于如何同时训练VAE和扩散模型。LSGM表明由于潜在先验是intractable的,分数匹配损失不再适用。LSGM直接使用VAE中传统的损失函数ELBO作为损失函数,并导出了ELBO和分数匹配的关系:
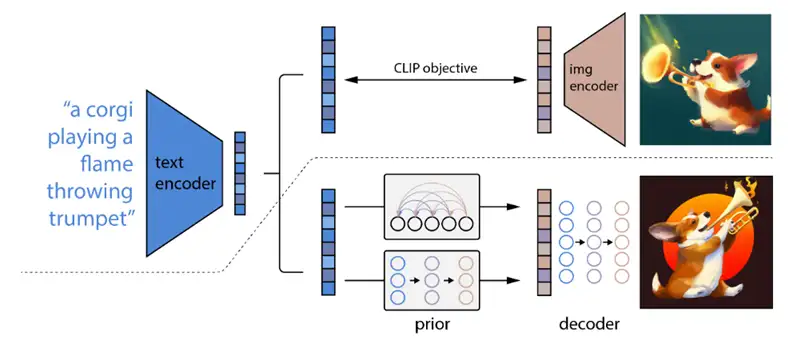
一种是auto-regressive model,将image embedding转换为一串离散的编码,并且基于condition caption y自回归地预测。(这里不一定要condition on caption(GLIDE的方法——额外用一个Transformer处理caption),也可以condition on CLIP text embedding)。此外,这里还用到了PCA来降维,降低运算复杂度。
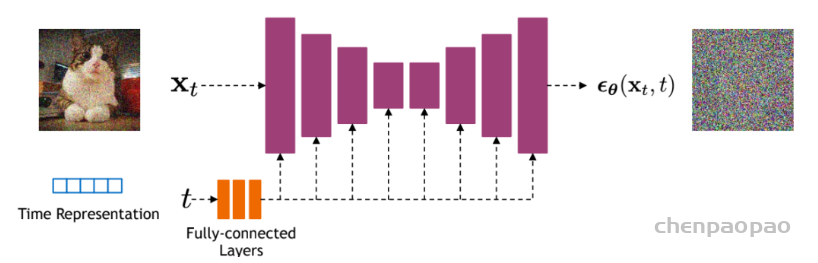
首先,是time embeding,这里是采用Attention Is All You Need中所设计的sinusoidal position embedding,只不过是用来编码timestep:
# use sinusoidal position embedding to encode time step (https://arxiv.org/abs/1706.03762)
def timestep_embedding(timesteps, dim, max_period=10000):
"""
Create sinusoidal timestep embeddings.
:param timesteps: a 1-D Tensor of N indices, one per batch element.
These may be fractional.
:param dim: the dimension of the output.
:param max_period: controls the minimum frequency of the embeddings.
:return: an [N x dim] Tensor of positional embeddings.
"""
half = dim // 2
freqs = torch.exp(
-math.log(max_period) * torch.arange(start=0, end=half, dtype=torch.float32) / half
).to(device=timesteps.device)
args = timesteps[:, None].float() * freqs[None]
embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)
if dim % 2:
embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1)
return embedding
# define TimestepEmbedSequential to support `time_emb` as extra input
class TimestepBlock(nn.Module):
"""
Any module where forward() takes timestep embeddings as a second argument.
"""
@abstractmethod
def forward(self, x, emb):
"""
Apply the module to `x` given `emb` timestep embeddings.
"""
class TimestepEmbedSequential(nn.Sequential, TimestepBlock):
"""
A sequential module that passes timestep embeddings to the children that
support it as an extra input.
"""
def forward(self, x, emb):
for layer in self:
if isinstance(layer, TimestepBlock):
x = layer(x, emb)
else:
x = layer(x)
return x
# upsample
class Upsample(nn.Module):
def __init__(self, channels, use_conv):
super().__init__()
self.use_conv = use_conv
if use_conv:
self.conv = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
def forward(self, x):
x = F.interpolate(x, scale_factor=2, mode="nearest")
if self.use_conv:
x = self.conv(x)
return x
# downsample
class Downsample(nn.Module):
def __init__(self, channels, use_conv):
super().__init__()
self.use_conv = use_conv
if use_conv:
self.op = nn.Conv2d(channels, channels, kernel_size=3, stride=2, padding=1)
else:
self.op = nn.AvgPool2d(stride=2)
def forward(self, x):
return self.op(x)
上面我们实现了U-Net的所有组件,就可以进行组合来实现U-Net了:
The full UNet model with attention and timestep embedding
class UNetModel(nn.Module):
def __init__(
self,
in_channels=3,
model_channels=128,
out_channels=3,
num_res_blocks=2,
attention_resolutions=(8, 16),
dropout=0,
channel_mult=(1, 2, 2, 2),
conv_resample=True,
num_heads=4
):
super().__init__()
self.in_channels = in_channels
self.model_channels = model_channels
self.out_channels = out_channels
self.num_res_blocks = num_res_blocks
self.attention_resolutions = attention_resolutions
self.dropout = dropout
self.channel_mult = channel_mult
self.conv_resample = conv_resample
self.num_heads = num_heads
# time embedding
time_embed_dim = model_channels * 4
self.time_embed = nn.Sequential(
nn.Linear(model_channels, time_embed_dim),
nn.SiLU(),
nn.Linear(time_embed_dim, time_embed_dim),
)
# down blocks
self.down_blocks = nn.ModuleList([
TimestepEmbedSequential(nn.Conv2d(in_channels, model_channels, kernel_size=3, padding=1))
])
down_block_chans = [model_channels]
ch = model_channels
ds = 1
for level, mult in enumerate(channel_mult):
for _ in range(num_res_blocks):
layers = [
ResidualBlock(ch, mult * model_channels, time_embed_dim, dropout)
]
ch = mult * model_channels
if ds in attention_resolutions:
layers.append(AttentionBlock(ch, num_heads=num_heads))
self.down_blocks.append(TimestepEmbedSequential(*layers))
down_block_chans.append(ch)
if level != len(channel_mult) - 1: # don't use downsample for the last stage
self.down_blocks.append(TimestepEmbedSequential(Downsample(ch, conv_resample)))
down_block_chans.append(ch)
ds *= 2
# middle block
self.middle_block = TimestepEmbedSequential(
ResidualBlock(ch, ch, time_embed_dim, dropout),
AttentionBlock(ch, num_heads=num_heads),
ResidualBlock(ch, ch, time_embed_dim, dropout)
)
# up blocks
self.up_blocks = nn.ModuleList([])
for level, mult in list(enumerate(channel_mult))[::-1]:
for i in range(num_res_blocks + 1):
layers = [
ResidualBlock(
ch + down_block_chans.pop(),
model_channels * mult,
time_embed_dim,
dropout
)
]
ch = model_channels * mult
if ds in attention_resolutions:
layers.append(AttentionBlock(ch, num_heads=num_heads))
if level and i == num_res_blocks:
layers.append(Upsample(ch, conv_resample))
ds //= 2
self.up_blocks.append(TimestepEmbedSequential(*layers))
self.out = nn.Sequential(
norm_layer(ch),
nn.SiLU(),
nn.Conv2d(model_channels, out_channels, kernel_size=3, padding=1),
)
def forward(self, x, timesteps):
"""
Apply the model to an input batch.
:param x: an [N x C x H x W] Tensor of inputs.
:param timesteps: a 1-D batch of timesteps.
:return: an [N x C x ...] Tensor of outputs.
"""
hs = []
# time step embedding
emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
# down stage
h = x
for module in self.down_blocks:
h = module(h, emb)
hs.append(h)
# middle stage
h = self.middle_block(h, emb)
# up stage
for module in self.up_blocks:
cat_in = torch.cat([h, hs.pop()], dim=1)
h = module(cat_in, emb)
return self.out(h)
# train
epochs = 10
for epoch in range(epochs):
for step, (images, labels) in enumerate(train_loader):
optimizer.zero_grad()
batch_size = images.shape[0]
images = images.to(device)
# sample t uniformally for every example in the batch
t = torch.randint(0, timesteps, (batch_size,), device=device).long()
loss = gaussian_diffusion.train_losses(model, images, t)
if step % 200 == 0:
print("Loss:", loss.item())
loss.backward()
optimizer.step()
这里我们以mnist数据简单实现了一个mnist-demo,下面是一些生成的样本: