https://seisman.github.io/how-to-write-makefile
https://cmake.org/
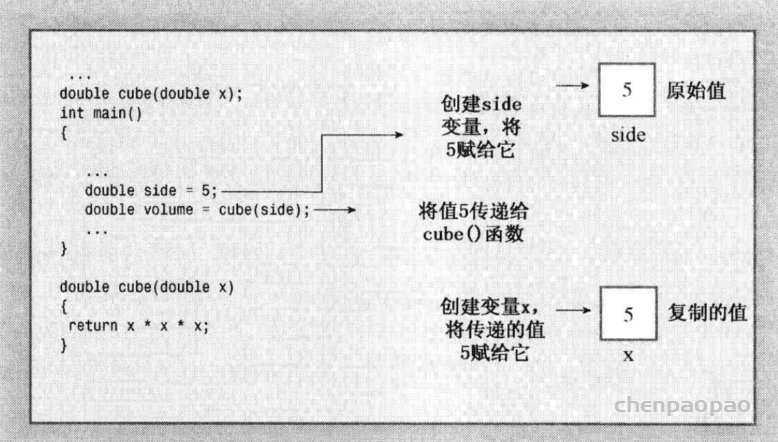
Makefile:规定编译的顺序规则 make就是一个gcc/g++的调度器
代码变成可执行文件,叫做编译(compile);先编译这个,还是先编译那个(即编译的安排),叫做构建(build)。
Make是最常用的构建工具,诞生于1977年,主要用于C语言的项目。但是实际上 ,任何只要某个文件有变化,就要重新构建的项目,都可以用Make构建。
make命令执行时,需要一个名为makefile的 文件,以告诉make命令需要怎么样的去编译和链接程序。
CMake是一种跨平台编译工具,比make更为高级,使用起来要方便得多。CMake主要是编写CMakeLists.txt文件,然后用cmake命令将CMakeLists.txt文件转化为make所需要的makefile文件,最后用make命令编译源码生成可执行程序或共享库(so(shared object)).它的作用和qt的qmake是相似的。
CMake 有什么用:
GNU Make ,QT 的 qmake ,微软的 MS nmake,BSD Make(pmake),Makepp,等等。这些 Make 工具遵循着不同的规范和标准,所执行的 Makefile 格式也千差万别。这样就带来了一个严峻的问题:如果软件想跨平台,必须要保证能够在不同平台编译。而如果使用上面的 Make 工具,就得为每一种标准写一次 Makefile ,这将是一件让人抓狂的工作。CMake 就是针对上面问题所设计的工具:它首先允许开发者编写一种平台无关的 CMakeList.txt 文件来定制整个编译流程,然后再根据目标用户的平台进一步生成所需的本地化 Makefile 和工程文件
写 CMake 配置文件 CMakeLists.txt 。 执行命令 cmake PATH 或者 ccmake PATH 生成 Makefile(ccmake 和 cmake 的区别在于前者提供了一个交互式的界面)。其中, PATH 是 CMakeLists.txt 所在的目录。 使用 make 命令进行编译。 重点:gcc和make区别
gcc是编译器 而make不是 make是依赖于Makefile来编译多个源文件的工具 在Makefile里同样是用gcc(或者别的编译器)来编译程序.
gcc是编译一个文件,make是编译多个源文件的工程文件的工具。
make就是一个gcc/g++的调度器,通过读入一个文件(默认文件名为Makefile或者makefile),执行一组以gcc/g++为主的shell命令序列。输入文件主要用来记录文件之间的依赖关系和命令执行顺序。gcc是编译工具; make是定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译; 也就是说make是调用gcc的。
Makefile的编写规则
commmond每行命令之前必须有一个tab键。如果想用其他键,可以用内置变量.RECIPEPREFIX声明。
makefile教程
makefile教程
编写 Makefile的文件:
target ... : prerequisites ...
[tab]
command
…
…
或者:
targets : prerequisites ; command
command
…
执行:make 目标target名
target
可以是一个object file(目标文件),也可以是一个执行文件,还可以是一个标签(label)。对于标签这种特性,在后续的“伪目标”章节中会有叙述。
prerequisites
生成该target所依赖的文件和/或target
command(任意的命令)每行命令之前必须有一个tab键。如果想用其他键,可以用内置变量.RECIPEPREFIX声明。
该target要执行的命令(任意的shell命令)
command是命令行,如果其不与“target:prerequisites”在一行,那么,必须以 Tab 键开头,如果和prerequisites在一行,那么可以用分号做为分隔。(见上)
prerequisites也就是目标所依赖的文件(或依赖目标)。如果其中的某个文件要比目标文件要新,那么,目标就被认为是“过时的”,被认为是需要重生成的。这个在前面已经讲过了。
如果命令太长,你可以使用反斜杠( \ )作为换行符。make对一行上有多少个字符没有限制。规则告诉make两件事,文件的依赖关系和如何生成目标文件。
一般来说,make会以UNIX的标准Shell,也就是 /bin/sh 来执行命令。
例如:
Makefile的文件:
a.txt: b.txt c.txt
[tab]
cat b.txt c.txt > a.txt
构建命令:
$ make a.txt
一个目标(target)就构成一条规则。目标通常是文件名,指明Make命令所要构建的对象,比如上文的 a.txt 。目标可以是一个文件名,也可以是多个文件名,之间用空格分隔。
除了文件名,目标还可以是某个操作的名字,这称为”伪目标”(phony target)。
clean:
rm *.o
上面代码的目标是clean,它不是文件名,而是一个操作的名字,属于"伪目标 ",作用是删除对象文件。
$ make clean井号(#)在Makefile中表示注释
make命令
执行时,需要一个makefile文件,以告诉make命令需要怎么样的去编译和链接程序。
首先,我们用一个示例来说明makefile的书写规则,以便给大家一个感性认识。这个示例来源于gnu 的make使用手册,在这个示例中,我们的工程有8个c文件,和3个头文件,我们要写一个makefile来告诉make命令如何编译和链接这几个文件。我们的规则是:
如果这个工程没有编译过,那么我们的所有c文件都要编译并被链接。
edit : main.o kbd.o command.o display.o \
insert.o search.o files.o utils.o
cc -o edit main.o kbd.o command.o display.o \
insert.o search.o files.o utils.o
main.o : main.c defs.h
cc -c main.c
kbd.o : kbd.c defs.h command.h
cc -c kbd.c
command.o : command.c defs.h command.h
cc -c command.c
display.o : display.c defs.h buffer.h
cc -c display.c
insert.o : insert.c defs.h buffer.h
cc -c insert.c
search.o : search.c defs.h buffer.h
cc -c search.c
files.o : files.c defs.h buffer.h command.h
cc -c files.c
utils.o : utils.c defs.h
cc -c utils.c
clean :
rm edit main.o kbd.o command.o display.o \
insert.o search.o files.o utils.o反斜杠( \ )是换行符的意思。这样比较便于makefile的阅读。我们可以把这个内容保存在名字为“makefile”或“Makefile”的文件中,然后在该目录下直接输入命令 make 就可以生成执行文件edit。如果要删除执行文件和所有的中间目标文件,那么,只要简单地执行一下 make clean 就可以了。
在这个makefile中,目标文件(target)包含:执行文件edit和中间目标文件( *.o ),依赖文件(prerequisites)就是冒号后面的那些 .c 文件和 .h 文件。每一个 .o 文件都有一组依赖文件,而这些 .o 文件又是执行文件 edit 的依赖文件。依赖关系的实质就是说明了目标文件是由哪些文件生成的,换言之,目标文件是哪些文件更新的。
在定义好依赖关系后,后续的那一行定义了如何生成目标文件的操作系统命令,一定要以一个 Tab 键作为开头。记住,make并不管命令是怎么工作的,他只管执行所定义的命令。make会比较targets文件和prerequisites文件的修改日期,如果prerequisites文件的日期要比targets文件的日期要新,或者target不存在的话,那么,make就会执行后续定义的命令。
这里要说明一点的是, clean 不是一个文件,它只不过是一个动作名字,有点像c语言中的label一样,其冒号后什么也没有,那么,make就不会自动去找它的依赖性,也就不会自动执行其后所定义的命令。要执行其后的命令,就要在make命令后明显得指出这个label的名字。这样的方法非常有用,我们可以在一个makefile中定义不用的编译或是和编译无关的命令,比如程序的打包,程序的备份,等等。
回声
正常情况下,make会打印每条命令,然后再执行,这就叫做回声(echoing)。
test:
# 这是测试
执行上面的规则,会得到下面的结果。
$ make test
# 这是测试模式匹配 通配符%
Make命令允许对文件名,进行类似正则运算的匹配,主要用到的匹配符是 %。比如,假定当前目录下有 f1.c 和 f2.c 两个源码文件,需要将它们编译为对应的对象文件。
%.o: %.c等同于下面的写法。
f1.o: f1.c
f2.o: f2.c使用匹配符%,可以将大量同类型的文件,只用一条规则就完成构建。
通配符
通配符(wildcard)用来指定一组符合条件的文件名。Makefile 的通配符与 Bash 一致,主要有星号(*)、问号(?)和 […] 。比如, *.o 表示所有后缀名为o的文件。
clean:
rm -f *.o变量 变量需要放在 $( )
Makefile 允许使用等号自定义变量。
txt = Hello World
test:
@echo $(txt)上面代码中,变量 txt 等于 Hello World。调用时,变量需要放在 $( ) 之中。
调用Shell变量,需要在美元符号前,再加一个美元符号,这是因为Make命令会对美元符号转义。
有时,变量的值可能指向另一个变量。
v1 = $(v2)
上面代码中,变量 v1 的值是另一个变量 v2。这时会产生一个问题,v1 的值到底在定义时扩展(静态扩展),还是在运行时扩展(动态扩展)?如果 v2 的值是动态的,这两种扩展方式的结果可能会差异很大。为了解决类似问题,Makefile一共提供了四个赋值运算符 (=、:=、?=、+=),它们的区别请看StackOverflow
VARIABLE = value
# 在执行时扩展,允许递归扩展。
VARIABLE := value
# 在定义时扩展。
VARIABLE ?= value
# 只有在该变量为空时才设置值。
VARIABLE += value
# 将值追加到变量的尾端。内置变量(Implicit Variables)
Make命令提供一系列内置变量,比如,$(CC) 指向当前使用的编译器,$(MAKE) 指向当前使用的Make工具。这主要是为了跨平台的兼容性,详细的内置变量清单见手册。
output:
$(CC) -o output input.c自动变量(Automatic Variables)
Make命令还提供一些自动变量,它们的值与当前规则有关。主要有以下几个。
(1)$@
$@指代当前目标,就是Make命令当前构建的那个目标。比如,make foo的 $@ 就指代foo。
.txt b.txt:
touch $@
等同于下面的写法。
a.txt:
touch a.txt
b.txt:
touch b.txt
(2)$<
$< 指代第一个前置条件。比如,规则为 t: p1 p2,那么$< 就指代p1。
a.txt: b.txt c.txt
cp $< $@
等同于下面的写法。
a.txt: b.txt c.txt
cp b.txt a.txt
(3)$?
$? 指代比目标更新的所有前置条件,之间以空格分隔。比如,规则为 t: p1 p2,其中 p2 的时间戳比 t 新,$?就指代p2。
(4)$^
$^ 指代所有前置条件,之间以空格分隔。比如,规则为 t: p1 p2,那么 $^ 就指代 p1 p2 。
(5)$*
$* 指代匹配符 % 匹配的部分, 比如% 匹配 f1.txt 中的f1 ,$* 就表示 f1。
(6)$(@D) 和 $(@F)
$(@D) 和 $(@F) 分别指向 $@ 的目录名和文件名。比如,$@是 src/input.c,那么$(@D) 的值为 src ,$(@F) 的值为 input.c。
(7)$(<D) 和 $(<F)
$(<D) 和 $(<F) 分别指向 $< 的目录名和文件名。
所有的自动变量清单,请看手册。下面是自动变量的一个例子。
dest/%.txt: src/%.txt
@[ -d dest ] || mkdir dest
cp $< $@
上面代码将 src 目录下的 txt 文件,拷贝到 dest 目录下。首先判断 dest 目录是否存在,如果不存在就新建,然后,$< 指代前置文件(src/%.txt), $@ 指代目标文件(dest/%.txt)。判断和循环
Makefile使用 Bash 语法,完成判断和循环。
ifeq ($(CC),gcc)
libs=$(libs_for_gcc)
else
libs=$(normal_libs)
endif
上面代码判断当前编译器是否 gcc ,然后指定不同的库文件。
(1)shell 函数
shell 函数用来执行 shell 命令
srcfiles := $(shell echo src/{00..99}.txt)
(2)wildcard 函数
wildcard 函数用来在 Makefile 中,替换 Bash 的通配符。
srcfiles := $(wildcard src/*.txt)
(3)subst 函数
subst 函数用来文本替换,格式如下。
$(subst from,to,text)
下面的例子将字符串"feet on the street"替换成"fEEt on the strEEt"。
$(subst ee,EE,feet on the street)
下面是一个稍微复杂的例子。
comma:= ,
empty:=
# space变量用两个空变量作为标识符,当中是一个空格
space:= $(empty) $(empty)
foo:= a b c
bar:= $(subst $(space),$(comma),$(foo))
# bar is now `a,b,c'.
(4)patsubst函数
patsubst 函数用于模式匹配的替换,格式如下。
$(patsubst pattern,replacement,text)
下面的例子将文件名"x.c.c bar.c",替换成"x.c.o bar.o"。
$(patsubst %.c,%.o,x.c.c bar.c)
(5)替换后缀名
替换后缀名函数的写法是:变量名 + 冒号 + 后缀名替换规则。它实际上patsubst函数的一种简写形式。
min: $(OUTPUT:.js=.min.js)
上面代码的意思是,将变量OUTPUT中的后缀名 .js 全部替换成 .min.js 。函数
Makefile 还可以使用函数,格式如下。
$(function arguments)
# 或者
${function arguments}
Makefile提供了许多内置函数,可供调用。下面是几个常用的内置函数。多个文件目录下Makefile的写法:!有用的实例
1.有用的网址:
https://seisman.github.io/how-to-write-makefile/conditionals.html
2.对于多个文件都在同一目录下:
测试程序在同一个文件中,共有func.h、func.c、main.c三个文件,Makefile写法如下所示:
makefile文件:
##-wall 使gcc对源文件的代码有问题的地方发出警告
CC = gcc
CFLAGS = -g -Wall
main:main.o func.o
$(CC) main.o func.o -o main
main.o:main.c
$(CC) $(CFLAGS) -c main.c -o main.o
func.o:func.c
$(CC) $(CFLAGS) -c func.c -o func.o
clean:
rm -rf *.o执行:
make 目标3、通用模板
实际当中程序文件比较大,这时候对文件进行分类,分为头文件、源文件、目标文件、可执行文件。也就是说通常将文件按照文件类型放在不同的目录当中,这个时候的Makefile需要统一管理这些文件,将生产的目标文件放在目标目录下,可执行文件放到可执行目录下。测试程序如下图所示:
# innclude目录:.h头文件
# src: .c源文件
# obj: 生成的可执行文件main
# bin: .o文件(编译过程的中间文件)
DIR_INC = ./include
DIR_SRC = ./src
DIR_OBJ = ./obj
DIR_BIN = ./bin
SRC = $(wildcard ${DIR_SRC}/*.c)
OBJ = $(patsubst %.c,${DIR_OBJ}/%.o,$(notdir ${SRC}))
TARGET = main
BIN_TARGET = ${DIR_BIN}/${TARGET}
CC = gcc
CFLAGS = -g -Wall -I${DIR_INC}
${BIN_TARGET}:${OBJ}
$(CC) $(OBJ) -o $@
${DIR_OBJ}/%.o:${DIR_SRC}/%.c
$(CC) $(CFLAGS) -c $< -o $@
.PHONY:clean
clean:
find ${DIR_OBJ} -name *.o -exec rm -rf {}解释如下:
(1)Makefile中的 符号 $@, $^, $< 的意思:
(2)wildcard、notdir、patsubst的意思:
wildcard : 扩展通配符
SRC = $(wildcard *.c)
等于指定编译当前目录下所有.c文件,如果还有子目录,比如子目录为inc,则再增加一个wildcard函数,象这样:
SRC = $(wildcard .c) $(wildcard inc/ .c)
(3)gcc -I -L -l的区别:
gcc -o hello hello.c -I /home/hello/include -L /home/hello/lib -lworld
上面这句表示在编译hello.c时-I /home/hello/include表示将/home/hello/include目录作为第一个寻找头文件的目录, 寻找的顺序是:/home/hello/include–>/usr/include–>/usr/local/include
-L /home/hello/lib表示将/home/hello/lib目录作为第一个寻找库文件的目录,
寻找的顺序是:/home/hello/lib–>/lib–>/usr/lib–>/usr/local/lib
-lworld表示在上面的lib的路径中寻找libworld.so动态库文件(如果gcc编译选项中加入了“-static”表示寻找libworld.a静态库文件)autoconf和automake工具
autoconf和automake两个工具来帮助我们自动地生成符合自由软件惯例的Makefile
https://thebigdoc.readthedocs.io/en/latest/auto-make-conf.html
步骤:
create project
touch NEWS README ChangeLog AUTHORS
autoscan
configure.scan ==> configure.in/configure.ac
aclocal
autoheader(可选,生成config.h.in)
Makefile.am(根据源码目录可能需要多个)
libtoolize –automake –copy –force(如果configure.ac中使用了libtool)
automake –add-missing
autoconf
./configure && make && make install安装:
sudo apt-get install autoconf例子:
https://www.laruence.com/2009/11/18/1154.html
打印当前工作目录 pwd 命令
Linux中用 pwd 命令来查看”当前工作目录“的完整路径。 简单得说,每当你在终端进行操作时,你都会有一个当前工作目录。
在不太确定当前位置时,就会使用pwd来判定当前目录在文件系统内的确切位置。
pwd
如果目录是链接时:
格式:pwd -P 显示出实际路径,而非使用连接(link)路径。今天这个部分有点难🚹