
https://mp.weixin.qq.com/s/VazobOgY9QVaADpEur81ng https://bbs.huaweicloud.com/blogs/344188
分类: C++
Windows下使用VSCode配置OpenCV开发环境
Windows下使用VSCode配置OpenCV开发环境
通过使用 GitHub 上他人编译好的动态库,进行 OpenCV 环境的配置。
本博客对应 Bilibili 实操视频:https://www.bilibili.com/video/BV1BP4y1S7NX/目录
配置环境的前置知识非常多,在此一一罗列
- 环境变量的作用
- MinGW 不同版本的差异
- C/CPP 文件的编译与链接
- 动态链接与静态链接
- OpenCV 编译后的文件夹的结构
- g++ 编译命令中
-I, -L, -l三个参数的含义 - VS Code 开发 CPP 项目,生成的三个
.json文件的作用
MinGW 安装
选择 POSIX
这里涉及到环境变量相关的知识。
来到 https://sourceforge.net/projects/mingw-w64/files/#mingw-w64-gcc-8-1-0
看到
MinGW-W64 GCC-8.1.0
- x86_64-posix-sjlj
- x86_64-posix-seh (请选择这个版本下载)
- x86_64-win32-sjlj
- x86_64-win32-seh
- i686-posix-sjlj
- i686-posix-dwarf
- i686-win32-sjlj
- i686-win32-dwarf如果之前从未使用过 MinGW,那么请下载 posix 类别,并配置环境变量;
如果之前使用过 MinGW,那么你大概率下载的是 win32 类别,所以请重新安装并配置环境变量。
就算不编译 OpenCV 源码,要用它提供的动态链接库,也得老老实实使用 posix 那个。
保留两个 MinGW
我自己之前下载的是 win32 ,所以直接踩坑。
最后我通过修改文件夹名字的方法,把两个 MinGW 都留下来,等以后要换的时候,再改回来。
# 我自己使用的部分系统环境变量
GCC_WIN32_HOME: C:\Library\CPP\mingw64-posix
GCC_POSIX_HOME: C:\Library\CPP\mingw64-win32
Path:
...
%GCC_POSIX_HOME%\bin
...关于 win32 和 posix 的区别,请参考 【c/cpp 开发工具】MingGW 各版本区别及安装说明。
检验是否成功
g++ --version
C:\Users\User>g++ --versiong++ (x86_64-posix-seh-rev0, Built by MinGW-W64 project) 8.1.0Copyright (C) 2018 Free Software Foundation, Inc.This is free software; see the source for copying conditions. There is NOwarranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.看第二行,有 posix 字样。
C/CPP 文件的编译与链接
- 如果你是只会写单个
.c/.cpp文件的小白 - 如果你没有上过计算机组成、编译原理和操作系统这三门课
- 如果你没有听说过
readelf,objdump,.text/.data/.bss
我建议你先打好基础,再来配置 OpenCV,否则欲速则不达,就算手把手教会如何配置,
知其然而不知其所以然,下回配置环境还是得折腾一遍。
我先抛出一个问题:
一句简单的
printf("hello world");,在我的电脑上编译出了.exe文件,能直接在另一台电脑上运行?我为什么不用手动实现printf这个函数,别人也不用实现,这个函数到底定义在了哪里,实现在了哪里?
放两个视频:
OpenCV 文件夹结构
版本选择
使用别人编译好的 OpenCV dll 文件,保证编译后的文件能够运行。
这份文件在 GitHub 仓库 上可以下载,GitHub 下载的加速有很多办法,这里用最简单的一种:
来到 Gitee 上别人同步好的 镜像仓库,直接下载 zip 文件就行,20 MB 左右。
我使用的版本是 OpenCV 4.5.2-x64,OpenCV 4.5.5-x64 我试了不行。
4.5.5 的问题是能够生成 .exe 文件,但是无法运行。
所以为了保证成功,用 4.5.2。
文件结构
C:\LIBRARY\CPP\PACKAGES\OPENCV-MINGW-BUILD-OPENCV-4.1.0-X64├─etc # 不用管├─include # 头文件│ └─opencv2│ ├─calib3d│ ├─core│ ├─dnn│ ├─features2d│ ├─flann│ ├─... # 不一一罗列└─x64 └─mingw ├─bin │ └─ *.dll # 一堆 dll 文件 └─lib首先,include 文件夹,字面意思,用来 include 的。
我们知道 CPP 是定义和实现分离的,以函数为例,通常在 .h 文件中声明,在 .cpp 文件中实现。
如果 main.cpp 里使用了其他文件中定义的函数,而我们只是想要生成 .o 文件,只需要 include 对应的 .h 文件即可。
include/opencv2 下就是各种 .h 文件。
然后是 x64/mingw/bin,这里有一堆 *.dll,这就是动态链接库文件。
将动态链接库添加到系统环境变量
为了让第三方的动态链接库生效,我们需要将动态链接库添加到系统环境变量。
对于我来说,是将 C:\Library\CPP\Packages\OpenCV-MinGW-Build-OpenCV-4.1.0-x64\x64\mingw\bin 添加到环境变量中。
这一步的作用类似于告诉系统 prinf() 这个函数的二进制文件在哪儿。
g++ 命令的参数
介绍三个参数 -I、-L 和 -l。
-I 告诉编译器,头文件里的 include<package> 去哪儿找。
-L 告诉编译器,添加一个要动态链接的目录
-l 指定具体的动态链接库的名称
具体可以参考 gcc -L -l -I -i参数。
VS Code 项目配置
我们使用 VS Code 生成的三个 .json 文件来配置 OpenCV 项目,而不是使用 cmake。
这三个文件分别是:
c_cpp_properties.json,launch.json 和 tasks.json。
c_cpp_properties.json
这个文件删了,不影响编译与链接,但是 VS Code 的 C/C++ 插件依赖于这个文件做智能提示和代码分析。
{
"configurations": [
{
"name": "Win32", // 指示平台,如 Mac/Linux/Windows,实测乱填也行
"includePath": [
"${workspaceFolder}/**",
"C:/Library/CPP/Packages/OpenCV-MinGW-Build-OpenCV-4.5.2-x64/include"
],
"defines": [
"_DEBUG",
"UNICODE",
"_UNICODE"
],
"compilerPath": "C:/Library/CPP/mingw64-posix/bin/g++.exe"
}
],
"version": 4
}includePath:告诉插件,要用的依赖在哪儿。
compilerPath: 告诉插件,编译器的路径在哪儿。
tasks.json
{
"tasks": [
{
"type": "cppbuild",
"label": "build",
"command": "g++",
"args": [
"-fdiagnostics-color=always",
"-g",
"${file}",
"-I",
"C:/Library/CPP/Packages/OpenCV-MinGW-Build-OpenCV-4.5.2-x64/include",
"-L",
"C:/Library/CPP/Packages/OpenCV-MinGW-Build-OpenCV-4.5.2-x64/x64/mingw/bin",
"-l",
"libopencv_calib3d452",
"-l",
"libopencv_core452",
"-l",
"libopencv_dnn452",
"-l",
"libopencv_features2d452",
"-l",
"libopencv_flann452",
"-l",
"libopencv_gapi452",
"-l",
"libopencv_highgui452",
"-l",
"libopencv_imgcodecs452",
"-l",
"libopencv_imgproc452",
"-l",
"libopencv_ml452",
"-l",
"libopencv_objdetect452",
"-l",
"libopencv_photo452",
"-l",
"libopencv_stitching452",
"-l",
"libopencv_video452",
"-l",
"libopencv_videoio452",
"-l",
"opencv_videoio_ffmpeg452_64",
"-o",
"${fileDirname}\\${fileBasenameNoExtension}.exe"
],
"options": {
"cwd": "${fileDirname}"
},
"problemMatcher": [
"$gcc"
],
"group": {
"kind": "build",
"isDefault": true
},
"detail": "调试器生成的任务。"
}
],
"version": "2.0.0"
}这个文件想要看懂,就需要 g++ 命令那些参数的相关知识了,而那些参数相关的知识,就是编译和链接。
isDefault:表示这是默认的构建任务,可以发现,-l 后面跟着的参数,就是我们下载的 OpenCV的 bin 目录下的动态链接库的文件名。
launch.json
注意 gdb 文件路径即可。
{
"version": "0.2.0",
"configurations": [
{
"name": "(gdb) Launch", // 配置名称,将会在启动配置的下拉菜单中显示
"type": "cppdbg", // 配置类型,这里只能为cppdbg
"preLaunchTask": "build",
"request": "launch", //请求配置类型,可以为launch(启动)或attach(附加)
"program": "${fileDirname}\\${fileBasenameNoExtension}.exe",
// 将要进行调试的程序的路径
"args": [], // 程序调试时传递给程序的命令行参数,一般设为空即可
"stopAtEntry": false, // 设为true时程序将暂停在程序入口处,一般设置为false
"cwd": "${fileDirname}", // 调试程序时的工作目录,一般为${workspaceRoot}即代码所在目录workspaceRoot已被弃用,现改为workspaceFolder
"environment": [],
"externalConsole": false, // 调试时是否显示控制台窗口
"MIMode": "gdb",
"miDebuggerPath": "C:/Library/CPP/mingw64-posix/bin/gdb.exe", // miDebugger的路径,注意这里要与MinGw的路径对应
"setupCommands": [
{
"description": "Enable pretty-printing for gdb",
"text": "-enable-pretty-printing",
"ignoreFailures": false
}
]
}
]
}更新 VS Code 环境变量
VS Code 有一个特别的设置,就是在外面更新了环境变量以后,VS Code 内部的命令行是不知道的。
这个问题参考 vscode终端不能识别系统设置的环境变量? – 朝阳的回答 – 知乎
原因就是 VS Code 想要保存上一次关闭时候的命令行的历史记录,所以没有更新环境变量。
比如新建一个 Destop/print-hello.exe,并且添加到环境变量中,然后我们正常 Win + R, cmd,调出命令行,是可以直接运行 print-hello.exe。
但是,如果这个时候用 VS Code 打开一个项目,项目内部的命令行是不知道有这个环境变量的,它将不能 print-hello。
解决方法就是,使用一个“感知到”新的环境变量的命令行,使用指令 code <workspace> 重新打开项目,这个时候 VS Code 才会更新环境变量。
构建并运行
准备一个 test.cpp,内容如下,注意修改对应的图片地址。
#include <opencv2/opencv.hpp>
#include <opencv2/highgui.hpp>
#include <iostream>
using namespace cv;
int main()
{
Mat img = imread("./opencv.jpeg");
imshow("image", img);
waitKey();
return 0;
}现在文件目录是这样的:
.
├── .vscode
│ ├── c_cpp_properties.json
│ ├── launch.json
│ └── tasks.json
├── test.cpp
└── opencv.jpeg点击小三角就行。

总结
虽然是以配置 OpenCV 为引子,但是整个流程并不复杂:
- OpenCV 动态链接库添加到系统环境变量
tasks.json中填写编译参数- 更新 VS Code 环境变量
至于环境变量之类的,各位老手想必是轻车熟路了。
只要做好上面这三步,就能生成并调试 .exe 文件了。
如果您有任何关于文章的建议,欢迎评论或在 GitHub 提 PR
作者:ticlab本文为作者原创,转载请在 文章开头 注明出处:https://www.cnblogs.com/ticlab/p/16817542.html
TensorRT 7 动态输入和输出
教程文档:
【1】https://docs.nvidia.com/deeplearning/tensorrt/index.html
【2】https://developer.nvidia.com/zh-cn/tensorrt
【4】github: https://github.com/NVIDIA/TensorRT
[5] pytorch-onnx-tensorrt全链路简单教程(支持动态输入)
[6] Pytorch转onnx, TensorRT踩坑实录
流程:
(1)Torch模型转onnx
(2)Onnx转TensorRT engine文件
(3)TensorRT加载engine文件并实现推理
Torch模型转onnx:
def torch_2_onnx(model, MODEL_ONNX_PATH ):
OPERATOR_EXPORT_TYPE = torch._C._onnx.OperatorExportTypes.ONNX
"""
这里构建网络的输入,有几个就构建几个
和网络正常的inference时输入一致就可以
"""
org_dummy_input = (inputs_1, inputs_2, inputs_3, inputs_4)
#这是支持动态输入和输出的第一步
#每一个输入和输出中动态的维度都要在此注明,下标从0开始
dynamic_axes = {
'inputs_1': {0:'batch_size', 1:'text_length'},
'inputs_2': {0:'batch_size', 1:'text_length'},
'inputs_3': {0:'batch_size', 1:'text_length'},
'inputs_4': {0:'batch_size', 1:'text_length'},
'outputs': {0:'batch_size', 1:'text_length'},
}
output = torch.onnx.export( model,
org_dummy_input,
MODEL_ONNX_PATH,
verbose=True,
opset_version=11,
operator_export_type=OPERATOR_EXPORT_TYPE,
input_names=['inputs_1', 'inputs_2', 'inputs_3', 'inputs_4'],
output_names=['outputs'],
dynamic_axes=dynamic_axes
)
print("Export of model to {}".format(MODEL_ONNX_PATH))
使用onnxruntime进行验证
1. 安装onnxruntime
pip install onnxruntime
2. 使用onnxruntime验证
import onnxruntime as ort
ort_session = ort.InferenceSession('xxx.onnx')
img = cv2.imread('test.jpg')
net_input = preprocess(img) # 你的预处理函数
outputs = ort_session.run(None, {ort_session.get_inputs()[0].name: net_input})
print(outputs)
3. 上面的这段代码有一点需要注意,可以发现通过ort_session.get_inputs()[0].name可以得到输入的tensor名称,同理,也可以通过ort_session.get_outputs()[0].name来获得输出tensor的名称,如果你的网络有两个输出,则使用ort_session.get_outputs()[0].name和ort_session.get_outputs()[1].name来获得,这里得到的名称在后续tensorrt调用中会使用onnx转TensorRT的engine文件:
import tensorrt as trt
import sys
import os
def ONNX_build_engine(onnx_file_path, write_engine = False):
'''
通过加载onnx文件,构建engine
:param onnx_file_path: onnx文件路径
:return: engine
'''
G_LOGGER = trt.Logger(trt.Logger.WARNING)
# 1、动态输入第一点必须要写的
explicit_batch = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
batch_size = 10 # trt推理时最大支持的batchsize
with trt.Builder(G_LOGGER) as builder, builder.create_network(explicit_batch) as network, trt.OnnxParser(network, G_LOGGER) as parser:
builder.max_batch_size = batch_size
config = builder.create_builder_config()
config.max_workspace_size = common.GiB(2) #common文件可以自己去tensorrt官方例程下面找
config.set_flag(trt.BuilderFlag.FP16)
print('Loading ONNX file from path {}...'.format(onnx_file_path))
with open(onnx_file_path, 'rb') as model:
print('Beginning ONNX file parsing')
parser.parse(model.read())
print('Completed parsing of ONNX file')
print('Building an engine from file {}; this may take a while...'.format(onnx_file_path))
# 重点
profile = builder.create_optimization_profile() #动态输入时候需要 分别为最小输入、常规输入、最大输入
# 有几个输入就要写几个profile.set_shape 名字和转onnx的时候要对应
profile.set_shape("inputs_1", (1,3), (1,256), (10,512))
profile.set_shape("inputs_2", (1,3), (1,256), (10,512))
profile.set_shape("inputs_3", (1,3), (1,256), (10,512))
profile.set_shape("inputs_4", (1,3), (1,256), (10,512))
config.add_optimization_profile(profile)
engine = builder.build_engine(network, config)
print("Completed creating Engine")
# 保存engine文件
if write_engine:
engine_file_path = 'correction_fp16.trt'
with open(engine_file_path, "wb") as f:
f.write(engine.serialize())
return engineTensorRT 加载engine文件并进行推理:
def trt_inference(engine_file):
#此处的输入应当转成numpy的array,同时dtype一定要和原网络一致不然结果会不对
inputs_1= np.array(inputs_1, dtype=np.int32, order='C')
inputs_2= np.array(inputs_2, dtype=np.int32, order='C')
inputs_3= np.array(inputs_3, dtype=np.int32, order='C')
inputs_4= np.array(inputs_4, dtype=np.int32, order='C')
with get_engine(engine_file) as engine, engine.create_execution_context() as context:
#增加部分 动态输入需要
context.active_optimization_profile = 0
origin_inputshape=context.get_binding_shape(0)
origin_inputshape[0],origin_inputshape[1]=inputs_1.shape
context.set_binding_shape(0, (origin_inputshape)) #若每个输入的size不一样,可根据inputs_i的size更改对应的context中的size
context.set_binding_shape(1, (origin_inputshape))
context.set_binding_shape(2, (origin_inputshape))
context.set_binding_shape(3, (origin_inputshape))
#增加代码结束
inputs, outputs, bindings, stream = common.allocate_buffers(engine, context)
# Do inference
inputs[0].host = inputs_1
inputs[1].host = inputs_2
inputs[2].host = inputs_3
inputs[3].host = inputs_4
trt_outputs = common.do_inference_v2(context, bindings=bindings, inputs=inputs, outputs=outputs, stream=stream)
def get_engine(engine_path ):
logger = trt.Logger(trt.Logger.INFO)
trt.init_libnvinfer_plugins(logger, namespace="")
with open(engine_path, 'rb') as f, trt.Runtime(logger) as runtime:
return runtime.deserialize_cuda_engine(f.read())
common文件中的allcate_buffers()函数:
def allocate_buffers(engine, context):
inputs = []
outputs = []
bindings = []
stream = cuda.Stream()
for i, binding in enumerate(engine):
size = trt.volume(context.get_binding_shape(i))
dtype = trt.nptype(engine.get_binding_dtype(binding))
# Allocate host and device buffers
host_mem = cuda.pagelocked_empty(size, dtype)
device_mem = cuda.mem_alloc(host_mem.nbytes)
# Append the device buffer to device bindings.
bindings.append(int(device_mem))
# Append to the appropriate list.
if engine.binding_is_input(binding):
inputs.append(HostDeviceMem(host_mem, device_mem))
else:
outputs.append(HostDeviceMem(host_mem, device_mem))
return inputs, outputs, bindings, streampython 和 c++ 联合编译—ctypes库
Python 使用 ctypes 调用 C/C++ DLL 动态链接库
Python ctypes模块优点与适用场景
ctypes 有以下优点:
- Python内建,不需要单独安装
- 可以直接调用二进制的动态链接库,在Python一侧,不需要了解 c/c++ dll 内部的工作方式
- 对C/C++与Python基本类型的相互映射有良好的支持。
ctypes 在下列场景可以发挥较大作用
- 运算量大的操作可以写成 C/C++ dll, python 通过 ctypes 来调用, 大幅提升Python代码性能。
- python可以直接使用 C/C++各类资源,如boost库等。
- 第3方软件或硬件提供的SDK库,通过ctypes来实现调用对接。 理论上C/C++的库都可以对接,这比其它语言方便得多。
Python本身开发效率高,还具备丰富的生态资源,有了 ctypes 加持,还可以使用C/C++的优秀资源,因此,掌握了这个工具,相信我,在大部分项目上将给你带来惊喜。
ctypes 官方文档,更着重是一份产品说明书,而不是教程,阅读官方文档来学习比较耗精力。 本人旨在给提供一份优秀教程,尽可能有条理地讲清楚原理、通过实例代码演示如何使用,同时也涉及一些更复杂的使用场景,如回调函数等。
除了ctypes 外,还可以通过 python C API、Cython来编写C/C++代码模块,或者利用第3方工具包来完成融合,如
Swig
pybind11
1、Visual Studio 2022 把项目打包成DLL
在示例讲解之前,我们先用Visual Studio2022创建并编译1个DLL项目
1) 创建新项目, 选择dll项目
至此创建完成,包含源文件dllmain.cpp、pch.cpp,头文件framework.h、pch.h。 ![在这里插入图片描述]
2) 定义头文件 boFirst.h
#define IMPORT_DLL __declspec(dllimport) 定义了IMPORT_DLL 宏, __declspec(dllimport)表示函数将被编译为dll
extern "C" IMPORT_DLL ==》 指定该函数可被外部调用。
#pragma once
#ifdef DLL_EXPORT
#define IMPORT_DLL __declspec(dllexport)
#else
#define IMPORT_DLL __declspec(dllimport)
#endif
//自定义结构体
struct boShape
{
char shape[20];
float width;
float height;
float depth;
};
// 自定义函数
extern "C" IMPORT_DLL int bo_add(int a, int b);
//自定义函数,参数为结构体 boStruct
extern "C" IMPORT_DLL float bo_shape_vol(boShape bs);
这里分别添加bo_add, bo_shape_vol 两个可供外部调用函数声明, 也可以更简化,只要函数前面有extern “C” __declspec(dllexport) 即可。
#ifndef _PY_LIST_2_C_ARRAY_H_
#define _PY_LIST_2_C_ARRAY_H_
#include <stdio.h>
typedef struct {
int value;
wchar_t* name;
} Item;
extern "C" __declspec(dllexport)
int sum_diagonal(Item** field, size_t size);
#endif
3)实现函数代码
// boFirst.cpp : Defines the exported functions for the DLL.
#include "pch.h" // use stdafx.h in Visual Studio 2017 and earlier
#include <utility>
#include <limits.h>
#include "boFirst.h"
# include <iostream>
int bo_add(int a, int b)
{
int c;
c = a + b;
return c;
}
float bo_shape_vol(boShape bs)
{
float volume = bs.width * bs.height * bs.depth;
std::cout << bs.shape << "volume is " << volume << std::endl;
return volume;
}
4) 编译生成dll
选择build solution , 输出窗口可以看到,在x64\Debug\ 目录下生成了DLL_Test.dll 文件
Rebuild started...
1>------ Rebuild All started: Project: DLL_Test, Configuration: Debug x64 ------
1>pch.cpp
1>dllmain.cpp
1>boFirst.cpp
1>D:\workplace\temp\C++\DLL_Test\DLL_Test\boFirst.cpp(8,5): warning C4273: 'bo_add': inconsistent dll linkage
1>D:\workplace\temp\C++\DLL_Test\DLL_Test\boFirst.h(20,27): message : see previous definition of 'bo_add'
1>D:\workplace\temp\C++\DLL_Test\DLL_Test\boFirst.cpp(15,7): warning C4273: 'bo_shape_vol': inconsistent dll linkage
1>D:\workplace\temp\C++\DLL_Test\DLL_Test\boFirst.h(22,29): message : see previous definition of 'bo_shape_vol'
1>Generating Code...
1> Creating library D:\workplace\temp\C++\DLL_Test\x64\Debug\DLL_Test.lib and object D:\workplace\temp\C++\DLL_Test\x64\Debug\DLL_Test.exp
1>DLL_Test.vcxproj -> D:\workplace\temp\C++\DLL_Test\x64\Debug\DLL_Test.dll
1>Done building project "DLL_Test.vcxproj".
========== Rebuild All: 1 succeeded, 0 failed, 0 skipped ==========
2、通过 ctypes 调用DLL的简单示例
在上一节中的dll有两个方法,其中1个输入参数使用了C++ Struct 结构体, python没有对应的数据结构。
第1种调用方式 (标准方式):
Step-1:
将DLL_Test.dll 文件拷贝至python文件所在目录, 该dll中包含如下可供调用的函数
int bo_add(int a, int b)
float bo_shape_vol(boShape bs); 其中boShape为自定义structStep-2:
编写代码,调用 bo_add()方法
from ctypes import *
dll = cdll.LoadLibrary("./DLL_Test.dll")
print("bo_add ", dll.bo_add(20, 80))运行,即可以得到输出 100
cdll.LoadLibrary() 方法返回 cdll 对象,cdll 调用C/C++函数的方法遵从 cdecl 方式(C/C++函数调用的标准方式)。
上例是直接调用 dll中的函数.
第2种调用方式( 函数签名方式)
函数签名方式,相当于在python内重新申明1个C++函数的别名,申明内容包括用ctype指定函数形参与返回值的数据类型。
import ctypes
clibrary = ctypes.CDLL('clibrary.so')
# 定义1个python函数名,指向 C++ 函数
addTwoNumbers = clibrary.add
# 用ctypes 数据类型,定义函数的参数类与返回值类型,
addTwoNumbers.argtypes = [ctypes.c_int, ctypes.c_int]
addTwoNumbers.restype = ctypes.c_int
# 使用签名函数
print("Sum of two numbers is :", addTwoNumbers(20, 10))Output: Sum of two numbers is : 30
ctypes 数据类型 –> Python 数据类型的转换是程序在后台自动完成的。
3、ctypes 数据类型
C/C++的数据类型与 Python数据类型及使用方式都有较多差异,因此python调用C++函数,必须需要对DLL函数形参以及返回值类型进行转换,才能把数据传入DLL,以及解析DLL的返回值。ctypes 模块提供了中间数据类型,来帮助Python完成数据转换,这些类型在python中都是以对象方式出现。
Python 调用DLL函数分3步:
1) 在Python中重新申明 DLL 函数: 除了函数名之外,还要用ctypes的数据类型将 DLL 函数的形参与返回值重新申明一遍。
2) 实参准备:当实际调用该函数时,将数据赋值给ctypes参数后,调用该函数。
3) 解析返回值:如果有返回值,从 ctypes 类型中解析出数据。
其中,第1步,用ctypes 类型申明 DLL函数形参最为关键,可以认为这一步目的是将 C++的数据类型转换为Python数据类型,ctypes 起到桥梁作用。
下面介绍一下 ctypes 提供了哪些数据类型,以及如何使用。
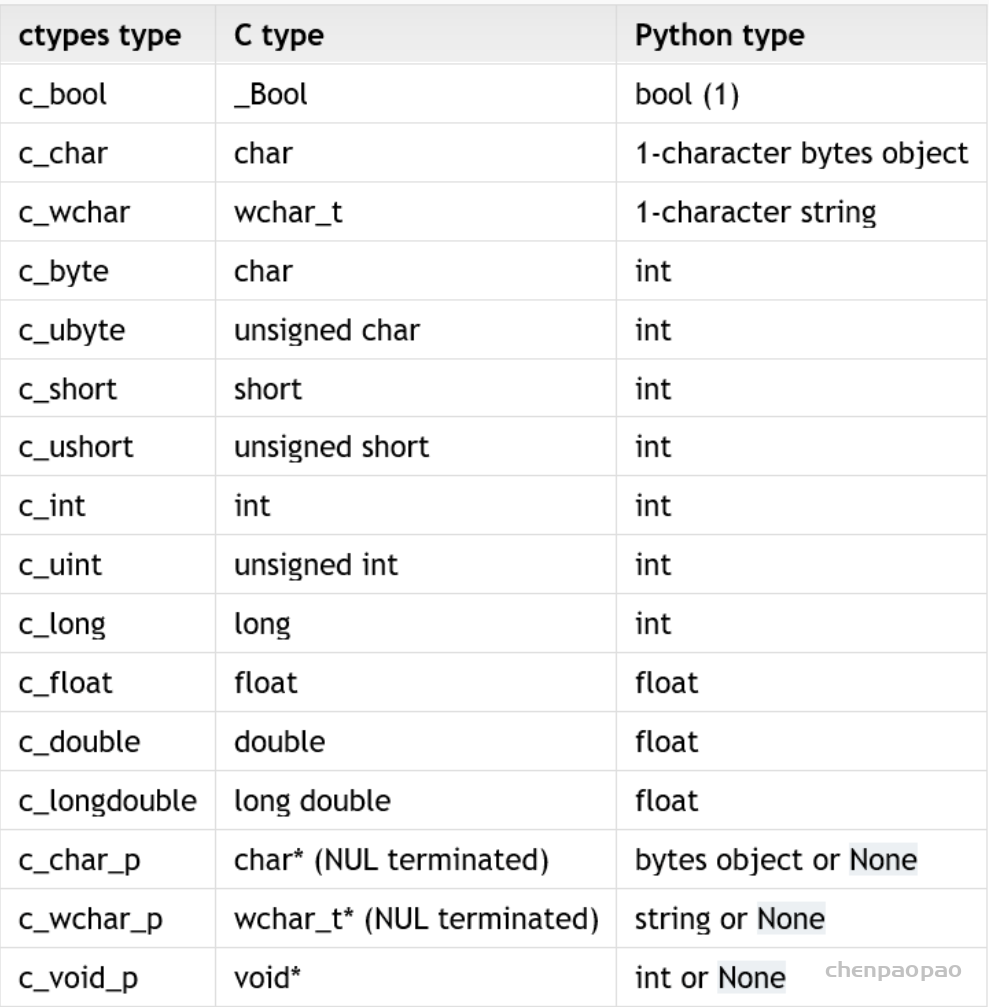
1) ctypes 与c、python数据类型的对应关系
2) 整数型参数变量定义
i = c_int()
赋值 :
i = c_int(99)
i.value=99
print(i)
c_long(99)3) 浮点数值参数
d1 = c_float()
d1.value=10.3
d1
c_float(10.300000190734863)
>>> d1.value
10.3000001907348634) 字符串参数
用 char * 32 定义1个32个字符的字符串,赋值用 value属性
>>> str1 = c_char * 32
>>> str1
<class '__main__.c_char_Array_32'>
>>> str1.value = b"hello"
>>> str1
<class '__main__.c_char_Array_32'>
>>> str1.value
b'hello'C/C++中字符串是用char* 指针或数组来代替,ctypes 提供对应的字符串指针类型 c_char_p,给c_char_p赋值通常有两种方式: – 把 python 字符串转为 bytes 类型, 使用endcode()方法。 – 直接使用bytes 类型字节串。
将字符串转换为 bytes 对象后,用c_char_p的value属性赋值, 用法示例 str2.value = x 赋值。
>>> x = b"abcdef"
>>> str2 = c_char_p()
>>> str2.value = x
>>> str2
c_char_p(140250436808304)
>>> str2.value
b'abcdef'
>>> str2 = str1
>>> str2
<class '__main__.c_char_Array_32'>
>>> str2.value
b'hello'c_char_p 指向的数据类型必须是二进制编码,即Bytes类型,如果是中文,可以用utf-8编码,显示时再解码.
>>> y=bytes("hello, 小王","utf-8")
>>> str2.value=y
>>> str2.value
b'hello, \xe5\xb0\x8f\xe7\x8e\x8b'
>>> str2.value.decode(encoding="utf-8")
'hello, 小王'ctypes 还提供了 create_string_buffer() 方法用于生成字符串。 格式: ctypes.create_string_buffer(init_or_size, size=None)
str3 = create_string_buffer(b’world’,32)
print(str3)
<main.c_char_Array_32 object at 0x7f8e9826eac0>
print(str3.value)
b’world’
print(str3.raw)
b’\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00′ repr(str3.raw)
create a 3 byte buffer, initialized to NUL bytes
p = create_string_buffer(3)create a buffer containing a NUL terminated string
p = create_string_buffer(b'Hello')
print(sizeof(p)
repr(p.raw))create a 10 byte buffer
p = create_string_buffer(b'Hello', 10) print(sizeof(p), repr(p.raw))5) 数组类型变量
数组的创建和C/C++语言的类似,给定数据类型和长度即可
如定义 c_int 类型数组, 长度为10. 先定义1个 INT_ARRAY 类型,再创建1个数组变量,其类型为 c_long_Array_10, 示例代码:
>>> INT_ARRAY = c_int * 10
>>> array1 = INT_ARRAY(10,20,30,40,50,60,70,80,90,100)
>>> array1
<__main__.c_long_Array_10 object at 0x00000283665D7040>
>>> array1[5]
60
>>> array1[7:]
[80, 90, 100]创建数据变量过程可以将两步并为1步,
>>> array2 = (c_int * 10)(10,20,30,40,50,60,70,80,90,100)
>>> array2
<__main__.c_long_Array_10 object at 0x0000028366558B40>
>>> array2[7:]
[80, 90, 100]6) Structure 变量
Python的dict类型虽然与C/C++ struct 结构体类型很相似,但不能直接拿来用。ctypes模块提供了 Structure 类来进行 C/C++ struct结构体类型转换。 示例,定义1个POINT 像素点结构体
class POINT(Structure):
... _fields_ = [("x", c_int),
... ("y", c_int)]
>>> point = POINT(10, 20)
>>> print(point.x, point.y)
10 20定义1个RECT 结构体,其字段为POINT结构体
>>> class RECT(Structure):
... _fields_ = [("upperleft", POINT),
... ("lowerright", POINT)]
...
>>> rc = RECT(point)
>>> print(rc.upperleft.x, rc.upperleft.y)
0 5
>>> print(rc.lowerright.x, rc.lowerright.y)
0 0
>>>r = RECT(POINT(1, 2), POINT(3, 4))1个更复杂的结构体, 字段 b , 为浮点数, “point_arrary” 为1个包含POINT结构体类型的Array
>>> class MyStruct(Structure):
... _fields_ = [("a", c_int),
... ("b", c_float),
... ("point_array", POINT * 4)]说明: python3 新增了struct 模块,基于序列化的原理,可将不同类型的数据打包进 ctypes bytes buffer变量,用于向c/c++ struct 变量传值, 但直观度不如 Structure变量,有兴趣者可以深入了解一下 python struct 模块的使用
7) 指针变量
ctypes提供了pointer()和POINTER()两种方法创建指针
pointer( object )用于将某个类型的对象转化为指针
其参数必须是ctypes的变量对象,不能是类型. 如下例,int_p 指向1个c_int 对象的指针,当前值为99
int_obj = c_int(99)
int_p = pointer(int_obj)
print(int_p)
使用contents方法访问指针
print(int_p.contents)
# 获取指针指向的值
print(int_p[0])output 如下
<ctypes.wintypes.LP_c_long object at 0x00000217897102C0>
c_long(99)
99POINTER()用于定义指针变量类型
POINTER() 的参数必须是类型名称,相当于定义了新的1个指针变量类型,但指向值的类型必须是指定的类型名称。然后再用这个新类型实例化1个指针变量。 而 pointer() 方法隐式地完成了POINTER()的工作。
# 指针类型
INT_P = POINTER(c_int) # 定义了1个新的指针变量类型
# 实例化
int_obj = c_int(4)
int_p_obj = INT_P(int_obj) # 实例化1个指针变量
print(int_p_obj)
print(int_p_obj.contents)
print(int_p_obj[0])output :
<__main__.LP_c_int object at 0x7f47df7f79e0>
c_int(4)
4指针类型的转换
ctypes提供 cast() 方法将一个ctypes实例转换为指向另一个ctypes数据类型的指针,cast()接受两个参数,一个是ctypes对象,它是或可以转换成某种类型的指针,另一个是ctypes指针类型。它返回第二个参数的一个实例,该实例引用与第一个参数相同的内存块。
# 初始化 1个 c_int的指针,当前值为4
int_p = pointer(c_int(99))
print(int_p)
# 定义1个 c_char类型的指针类型
char_p_type = POINTER(c_char)
print(char_p_type)
# 转 c_int变量转换为c_char类型指针
cast_type = cast(int_p, char_p_type)
print(cast_type)output:
<ctypes.wintypes.LP_c_long object at 0x0000021789710140>
<class 'ctypes.LP_c_char'>
<ctypes.LP_c_char object at 0x0000021789710E40>8) enum 枚举类型
在 C/C++中还有1个经常用到的类型是 enum,ctypes 没有相关类型,但python有1个enum类. 下面介绍如何 将 python enum 类用于 dll 函数参数。 如 C++程序中定义了1个枚举类型
enum Priority {
CRITICAL = 0x1,
IMPORTANT= 0x2,
NORMAL = 0x3,
MINOR = 0x4,
INFO = 0x5
};有1个函数: long set_priority(Priority n) 在python中,也定义1个enum类
import enum
class EnumPriority(enum.IntEnum):
CRITICAL = 0x1
IMPORTANT= 0x2
NORMAL = 0x3
MINOR = 0x4
INFO = 0x5
#注意必须将添加这个方法,ctyps 要求,将obj转为 init型
@classmethod
def from_param(cls, obj):
return int(obj)注意,必须要添加1个 from_param()方法., 将上面的枚举元素转为int型 下面将 python enum 做为参数传入dll
dll = cdll.LoadLibrary(dll_name)
set_priority=dll.set_priority
set_priority.restype = c_init
set_priority.argtypes = [EnumPriority]
# 调用该函数
print("call back result is ",set_priority(EnumPriority.INFO))4. 加载DLL库
Ctypes 提供有2种动态链接库的调用方式
ctypes.cdll. LoadLibrary(‘xxx.dll’) 加载 cdel调用方式的dll, 默认c++, vc++生成的dll库都是cdel方式。
ctypes.windll.LoadLibrary(‘xxx.dll’) 加载 win32调用方式(stdcall)的dll,所以很少使用此种调用方式
示例
def find_example_ctypes(required):
'''
Finds and loads example shared object of the required major
'''
# Importing ``ctypes`` should be in scope of this function to prevent failure
from ctypes import util, cdll
so_name = util.find_library('example.dll')
if so_name is None:
raise ExampleImportError('EXAMPLE shared object not found.')
example = cdll.LoadLibrary(so_name)
require_version(example.example_version(), required)
return example5. ctypes 向DLL函数传入参数
指定dll函数参数类型 通过argtypes属性来设置参数类型,
>>> strchr.restype = c_char_p
>>> strchr.argtypes = [c_char_p, c_char]例2:
myadd = dll.bo_add
myadd.restype = c_int
myadd.argtypes = [c_int, c_int]
print("call bo_add() with function signature approach \n", myadd(20, 80))传入指针参数 c++ 函数addx()的形参为两个指针, int addx( int p1, int p2), python 实例两个c_int型的指针传入
int_obj1 = c_int(20)
ptr1 = pointer(int_obj1)
int_obj2 = c_int(80)
ptr2 = pointer(int_obj2)
print("pass pointer to function addx(), ", dll.addx(ptr1, ptr2))传入结构体参数
步骤: – 在python定义1个Ctypes.Structure 类, 字段也C++ Struct类型保持一致。 – 用此类构建参数值 – 传入dll函数,前面要加byref 示例 :
from ctypes import *
class MyStruct(Structure):
_fields_ = [('shape', c_char*20),
('w', c_double),
('h', c_double),
('d', c_double),
]第2种调用方式
myadd = dll.bo_add
myadd.restype = c_int
myadd.argtypes = [c_int, c_int]
print("another call method to bo_add() : ", myadd(20, 80))传入结构体参数
dw, dh, dd = 4.0, 7.0, 3.0
dstr = b"cuboid "
s1 = MyStruct(dstr, dw, dh, dd)
print(s1.w, s1.h, s1.d)
print(s1.shape)
print(dll.bo_shape_vol(byref(s1)))Output 4.0 7.0 3.0 b’cuboid ‘ cuboid volume is 84 233390192
问题: print(dll.bo_shape_vol(byref(s1))) 打印出的是地址,不是结果 84 解决办法:用类的调用方式,定义dll函数返回值类型
print("第2种调用方法")
myVol = dll.bo_shape_vol
myVol.restype = c_double #定义dll函数返回值类型
myVol.argtypes = [POINTER(MyStruct)] #结构体参数是以地址方式传入,因此要转为指针
dx = myVol(byref(s1))
print(dx)Output
第2种调用方法
cuboid volume is 84
84.0下面是另1个例 子
from ctypes import *
class Passport(Structure):
_fields_ = [("name", c_char_p),
("surname", c_char_p),
("var", c_int)]
lib_dll = cdll.LoadLibrary("DLL_example.dll")
lib_dll.SetPassport.argtypes = [POINTER(Passport)]
lib_dll.GetPassport()
lib_dll.SetName(c_char_p(b"Yury"))
lib_dll.SetSurname(c_char_p(b"Wang"))
lib_dll.GetPassport()
name = str.encode(("Feng"))
surname = c_char_p((b'Li'))
passport = Passport(name, surname, 34)
lib_dll.SetPassport(pointer(passport))
lib_dll.GetPassport()Output:
Load DLL in Python
SetName
SetSurname
GetPassport: Default | Passport | 17
SetName
SetSurname
GetPassport: Yury | Orlov | 17
SetPassport
GetPassport: Vasiliy | Pupkin | 34
DETACH DLL6. 对回调函数的支持
C++中,用函数指针非常容易地实现回调函数,python也可以实现。 第1步: 用 CFUNCTYPE() 定义1个函数指针,windows 使用 WINFUNCTYPE() 。 CFUNCTYPE()第1个参数是回调函数返回值类型,后面是函数形参。 第2步:将回调函数名赋给CFUNCTYPE变量,相当于将函数地址赋给函数指针。 第3步:将该回调函数指针做为另1个函数的形参使用。
示例如下:
from ctypes import *
import sys
# 回调函数类型定义
if 'linux' in sys.platform:
fun_ctype = CFUNCTYPE
else:
fun_ctype = WINFUNCTYPE
def add(int a,int b):
return a+b
ADDFUNC = fun_ctype(c_int, c_int, c_int)
add_callback = ADDFUNC(add)
#将CFUNCTYPE变量做为函数形参
def test(x,y,ADDFUNC):
print(f"data is {x} and {y}
return add_callback(x,y)
#实际测试时,把回调函数做为参数传入
test(10,20,add_callback)总结:
1) ctypes 对c/c++ dll/so中的函数与形参,需要先申明才能使用
2)ctypes 提供了一套数据类型,用于C 数据类型与 python 数据类型的转换, 注意数组,指针类型的转换。
3) ctypes 调用 c/c++ dll/so 动态链接库函数的方法有两种
- 函数名直接调用
- 签名函数的方式调用
静态库(静态链接库lib/a)和动态库(动态链接库dll/so)
方法库大体上可以分为两类:静态库和动态库(共享库)。
1. windows中静态库是以 .lib 为后缀的文件,动态库是以 .dll 为后缀的文件。
2. linux中静态库是以 .a 为后缀的文件,动态库是以 .so为后缀的文件。
静态链接:
- 静态库 在链接阶段,会将汇编生成的目标文件.o与引用到的库一起链接打包到可执行文件中。因此对应的链接方式称为静态链接。
- 静态库可以简单看成是一组目标文件(.o .obj文件)的集合, 将若干个.o文件转换为静态库的过程,称之为打包. Linux下是使用ar工具, Windows下是使用lib.exe。
- Linux下静态链接库的后缀是.lib;Windows下静态链接库的后缀是.a。
动态链接:
- 动态库在程序编译时并不会被连接到目标代码中,而是在程序运行时才被载入。不同的应用程序如果调用相同的库,那么在内存里只需要有一份该共享库的实例,规避了空间浪费问题。动态库在程序运行是才被载入,也解决了静态库对程序的更新、部署和发布页会带来麻烦。用户只需要更新动态库即可,增量更新。
- 在Windows系统下的执行文件格式是PE(Portable Executable)格式,动态库需要一个DllMain函数做出初始化的入口,通常在导出函数的声明时需要有_declspec(dllexport)关键字。 跟exe有个main或者WinMain入口函数一样,DLL也有一个入口函数,就是DllMain。根据编写规范,Windows必须查找并执行DLL里的DllMain函数作为加载DLL的依据,它使得DLL得以保留在内存里。这个函数并不属于导出函数,而是DLL的内部函数。这意味着不能直接在应用工程中引用DllMain函数,DllMain是自动被调用的。
对于动态链接库,DllMain是一个可选的入口函数。一个动态链接库不一定要有DllMain函数,比如仅仅包含资源信息的DLL是没有DllMain函数的。
- Linux下gcc编译的执行文件默认是ELF格式,不需要初始化入口,亦不需要函数做特别的声明,编写比较方便。
无需打包工具,直接使用编译器即可创建动态库。 - Linux下动态链接库的后缀是.so;Windows下动态链接库的后缀是.dll
一、动态链接库创建和使用
1.创建hello.so动态库
#include <stdio.h>void hello(){ printf("hello world\n");}编译:gcc -fPIC -shared hello.c -o libhello.so2.hello.h头文件
void hello();3.链接动态库
#include <stdio.h>#include "hello.h" int main(){ printf("call hello()"); hello();}编译:gcc main.c -L. -lhello -o main这里-L的选项是指定编译器在搜索动态库时搜索的路径,告诉编译器hello库的位置。”.”意思是当前路径.
3.编译成够后执行./main,会提示:
In function `main':
main.c:(.text+0x1d): undefined reference to `hello'
collect2: ld returned 1 exit status这是因为在链接hello动态库时,编译器没有找到。
解决方法:
sudo cp libhello.so /usr/lib/这样,再次执行就成功输入:
call hello()
二、静态库 创建和使用
文件有:main.c、hello.c、hello.h
1.编译静态库hello.o:
gcc hello.c -o hello.o #这里没有使用-shared2.把目标文档归档
ar -r libhello.a hello.o #这里的ar相当于tar的作用,将多个目标打包。程序ar配合参数-r创建一个新库libhello.a,并将命令行中列出的文件打包入其中。这种方法,如果libhello.a已经存在,将会覆盖现在文件,否则将新创建。
3.链接静态库
gcc main.c -lhello -L. -static -o main这里的-static选项是告诉编译器,hello是静态库。
或者:
gcc main.c libhello.a -L. -o main这样就可以不用加-static
4.执行./main
输出:call hello()
区别:
可执行文件大小不一样
从前面也可以观察到,静态链接的可执行文件要比动态链接的可执行文件要大得多,因为它将需要用到的代码从二进制文件中“拷贝”了一份,而动态库仅仅是复制了一些重定位和符号表信息。
占用磁盘大小不一样
如果有多个可执行文件,那么静态库中的同一个函数的代码就会被复制多份,而动态库只有一份,因此使用静态库占用的磁盘空间相对比动态库要大。
扩展性与兼容性不一样
如果静态库中某个函数的实现变了,那么可执行文件必须重新编译,而对于动态链接生成的可执行文件,只需要更新动态库本身即可,不需要重新编译可执行文件。正因如此,使用动态库的程序方便升级和部署。
依赖不一样
静态链接的可执行文件不需要依赖其他的内容即可运行,而动态链接的可执行文件必须依赖动态库的存在。所以如果你在安装一些软件的时候,提示某个动态库不存在的时候也就不奇怪了。
即便如此,系统中一般存在一些大量公用的库,所以使用动态库并不会有什么问题。
复杂性不一样
相对来讲,动态库的处理要比静态库要复杂,例如,如何在运行时确定地址?多个进程如何共享一个动态库?当然,作为调用者我们不需要关注。另外动态库版本的管理也是一项技术活。这也不在本文的讨论范围。
加载速度不一样
由于静态库在链接时就和可执行文件在一块了,而动态库在加载或者运行时才链接,因此,对于同样的程序,静态链接的要比动态链接加载更快。所以选择静态库还是动态库是空间和时间的考量。但是通常来说,牺牲这点性能来换取程序在空间上的节省和部署的灵活性时值得的。再加上局部性原理,牺牲的性能并不多。
如何运行 c++ 代码/编译过程
运行cpp文件:
如何运行cpp文件:
方法1、vscode runcode
方法2、使用g++命令简单编译,在终端输入 g++ -o test test.cpp # -L. -l动态库名 (如果需要导入动态库)
方法3、对于复杂的程序,需要编写makefile or 使用cmake ,然后执行 make命令
CMake说明: 一般把CMakeLists.txt文件放在工程目录下,使用时,先创建一个叫build的文件夹(这个并非必须,因为cmake命令指向CMakeLists.txt所在的目录,例如cmake .. 表示CMakeLists.txt在当前目录的上一级目录。cmake后会生成很多编译的中间文件以及makefile文件,所以一般建议新建一个新的目录,专门用来编译),然后执行下列操作:
cd build
cmake ..
make
其中cmake .. 在build里生成Makefile,make根据生成makefile文件,编译程序,make应当在有Makefile的目录下,根据Makefile生成可执行文件。
C++编译过程主要分为,预处理、编译、汇编、链接四个过程。如下图所示:
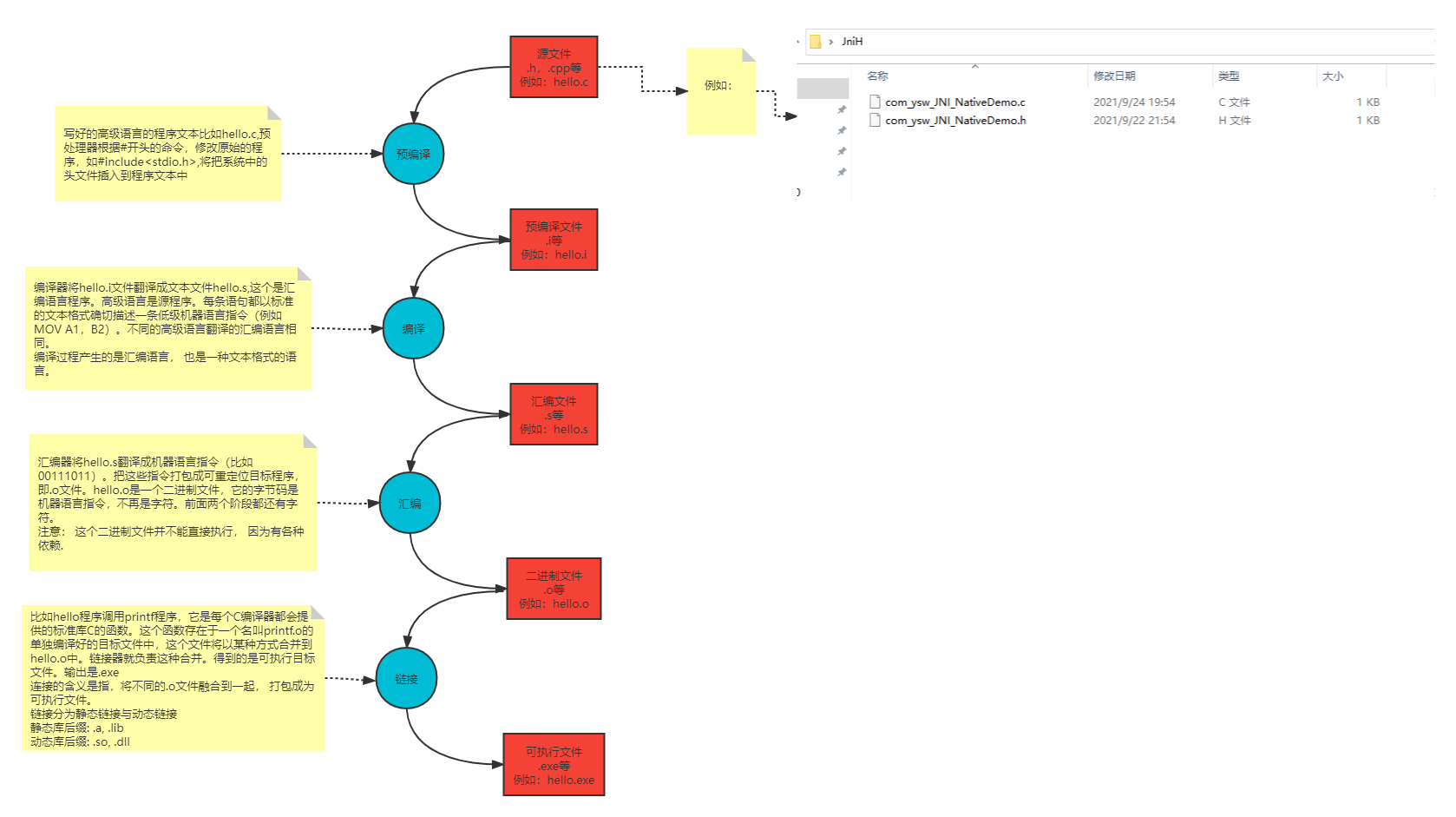
第一步:预处理 将源代码的.c 、.cpp 、.h 等文件包含到一个文件中。在这个过程中会使用一些预处理指令要求编译器使用什么样的方式包含这些文件。预处理结束之后对于c语言编译器会生成一个.i 文件。C++会生成.ii文件。
预编译过程主要处理那些源代码中以#开始的预编译指令,主要处理规则如下:
·将所有的#define删除,并且展开所有的宏定义;
·处理所有条件编译指令,如#if,#ifdef等;
·处理#include预编译指令,将被包含的文件插入到该预编译指令的位置。该过程递归进行,及被包含的文件可能还包含其他文件。
·删除所有的注释//和 /**/;
·添加行号和文件标识,如#2 “hello.c” 2,以便于编译时编译器产生调试用的行号信息及用于编译时产生编译错误或警告时能够显示行号信息;
·保留所有的#pragma编译器指令,因为编译器须要使用它们;
第二步:编译 编译过程就是把预处理完的文件进行一系列词法分析,语法分析,语义分析及优化后生成相应的汇编代码文件.
第三步:汇编 汇编器是将汇编代码转变成机器可以执行的命令,每一个汇编语句几乎都对应一条机器指令。汇编相对于编译过程比较简单,根据汇编指令和机器指令的对照表一一翻译即可。
第四步:链接 链接器ld将各个目标文件组装在一起,解决符号依赖,库依赖关系,并生成可执行文件。
动态链接和静态链接
方法库大体上可以分为两类:静态库和动态库(共享库)。
1. windows中静态库是以 .lib 为后缀的文件,动态库是以 .dll 为后缀的文件。
2. linux中静态库是以 .a 为后缀的文件,动态库是以 .so为后缀的文件。
静态链接:
- 静态库 在链接阶段,会将汇编生成的目标文件.o与引用到的库一起链接打包到可执行文件中。因此对应的链接方式称为静态链接。
- 静态库可以简单看成是一组目标文件(.o .obj文件)的集合, 将若干个.o文件转换为静态库的过程,称之为打包. Linux下是使用ar工具, Windows下是使用lib.exe。
- Linux下静态链接库的后缀是.lib;Windows下静态链接库的后缀是.a。
动态链接:
- 动态库在程序编译时并不会被连接到目标代码中,而是在程序运行时才被载入。不同的应用程序如果调用相同的库,那么在内存里只需要有一份该共享库的实例,规避了空间浪费问题。动态库在程序运行是才被载入,也解决了静态库对程序的更新、部署和发布页会带来麻烦。用户只需要更新动态库即可,增量更新。
- 在Windows系统下的执行文件格式是PE(Portable Executable)格式,动态库需要一个DllMain函数做出初始化的入口,通常在导出函数的声明时需要有_declspec(dllexport)关键字。 跟exe有个main或者WinMain入口函数一样,DLL也有一个入口函数,就是DllMain。根据编写规范,Windows必须查找并执行DLL里的DllMain函数作为加载DLL的依据,它使得DLL得以保留在内存里。这个函数并不属于导出函数,而是DLL的内部函数。这意味着不能直接在应用工程中引用DllMain函数,DllMain是自动被调用的。
对于动态链接库,DllMain是一个可选的入口函数。一个动态链接库不一定要有DllMain函数,比如仅仅包含资源信息的DLL是没有DllMain函数的。
- Linux下gcc编译的执行文件默认是ELF格式,不需要初始化入口,亦不需要函数做特别的声明,编写比较方便。
无需打包工具,直接使用编译器即可创建动态库。 - Linux下动态链接库的后缀是.so;Windows下动态链接库的后缀是.dll
区别:
当程序与静态库链接时,静态库中所包含的所有函数方法都会被copy到最终的可执行文件中去。这就会导致最终生成的可执行代码量相对变多,相当于编译器将代码补充完整了。这种方式会让程序运行起来相对快一些,不过也会有个缺点: 占用磁盘和内存空间,导致可执行exe程序过大。另外,静态库会被添加到和它链接的每个程序中去, 而且这些程序运行时, 都会被加载到内存中,无形中又多消耗了更多的内存空间。
与动态库链接的可执行文件只包含它需要的函数方法的引用表,而不是所有的函数代码,只有在程序执行时, 那些需要的函数代码才会被拷贝到内存中。这样就使可执行文件比较小, 节省磁盘空间,更进一步,操作系统使用虚拟内存,使得一份动态库驻留在内存中被多个程序使用,也同时节约了内存。不过由于运行时要去链接库会花费一定的时间,执行速度相对会慢一些。
总的来说,静态库是牺牲了空间效率,换取了时间效率,动态库是牺牲了时间效率换取了空间效率,没有好与坏的区别,只看具体需要了。
另外,一个程序编好后,有时需要做一些修改和优化,如果我们要修改的刚好是库函数的话,在接口不变的前提下,使用动态库的程序只需要将动态库重新编译就可以了,而使用静态库的程序则需要将静态库重新编译好后,将程序再重新编译一遍。
Elasticsearch
ES既是搜索引擎又是数据库:ElasticSearch究竟是不是数据库?历来存在争议.它是搜索引擎,千真万确,而它是数据库,需要看数据库的界定范围.广义上讲,关系型数据库,对象型数据库,搜索引擎,文件,都可以算作是数据库.数据库是用来存储数据的,为服务应用提供了数据的读写功能,即数据的添加,修改,删除,查询四种基本功能.
1.关系型数据库,诸如:transact-sql,plsql,mysql,firebird,maria等,具备了增删改查四种基本功能.
2.对象型数据库,诸如:redis,mongo等,也具备了增删改查四种基本功能.
3.搜索引擎,就是提到的elasticsearch,也具备了增删改查四种基本功能.
4.文件,比如:sqlite,也具备了增删改查四种基本功能.
ES: 基于Lucene框架的搜索引擎产品。you know for search. 提供了restful风格的操作接口。
ELK,日志检索
Lucene:是一个非常高效的全文检索引擎框架。Java开发的,只提供单机功能。
ES的一些核心概念:
1、索引index:关系型数据库中的table
2、文档document:行
3、字段 field text/keyword/byte:列
4、映射Mapping: Schema
5、查询方式 DSL:SQL ES新版本也支持SQL
6、分片sharding和副本replicas:index都是由sharding组成的。每个sharding都有一个或多个备份。ES集群健康状态。
1)Elasticsearch是搜索引擎
Elasticsearch在搜索引擎数据库领域排名绝对第一,内核基于Lucene构建,支持全文搜索是职责所在,提供了丰富友好的API。个人早期基于Lucene构建搜索应用,需要考虑的因素太多,自接触到Elasticsearch就再无自主开发搜索应用。普通工程师要想掌控Lucene需要一些代价,且很多机制并不完善,需要做大量的周边辅助程序,而Elasticsearch几乎都已经帮你做完了。
2)Elasticsearch不是搜索引擎
说它不是搜索引擎,估计很多从业者不认可,在个人涉及到的项目中,传统意义上用Elasticsearch来做全文检索的项目占比越来越少,多数时候是用来做精确查询加速,查询条件很多,可以任意组合,查询速度很快,替代其它很多数据库复杂条件查询的场景需求;甚至有的数据库产品直接使用Elasticsearch做二级索引,如HBase、Redis等。Elasticsearch由于自身的一些特性,更像一个多模数据库。
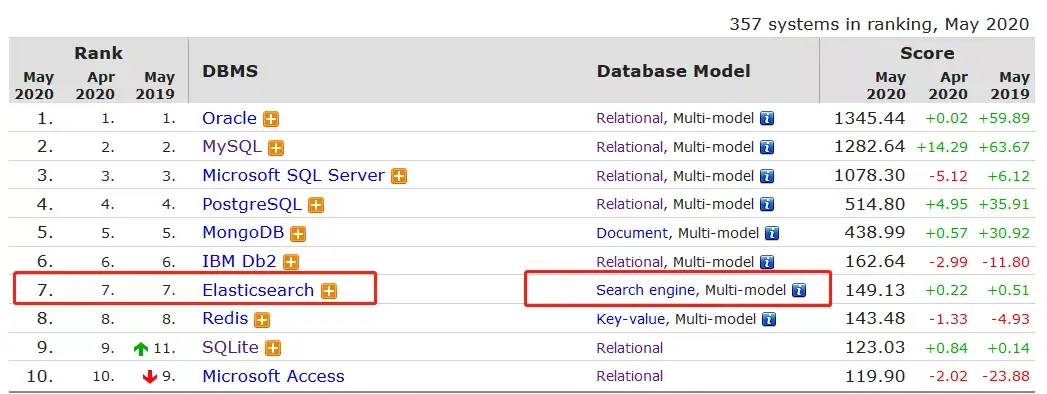
图示:Elasticsearch综合数据库排名热度已经到第7
3)Elasticsearch是数据库
Elasticsearch使用Json格式来承载数据模型,已经成为事实上的文档型数据库,虽然底层存储不是Json格式,同类型产品有大名鼎鼎的MongoDB,不过二者在产品定位上有差别,Elasticsearch更加擅长的基于查询搜索的分析型数据库,倾向OLAP;MongoDB定位于事务型应用层面OLTP,虽然也支持数据分析,笔者简单应用过之后再无使用,谁用谁知道。
4)Elasticsearch不是数据库
Elasticsearch不是关系型数据库,内部数据更新采用乐观锁,无严格的ACID事务特性,任何企图将它用在关系型数据库场景的应用都会有很多问题,很多其它领域的从业者喜欢拿这个来作为它的缺陷,重申这不是Elasticsearch的本质缺陷,是产品设计定位如此。

图示:Elastic擅长的应用场景
2、ES做什么
Elasticsearch虽然是基于Lucene构建,但应用领域确实非常宽泛。
1)全文检索
Elasticsearch靠全文检索起步,将Lucene开发包做成一个数据产品,屏蔽了Lucene各种复杂的设置,为开发人员提供了很友好的便利。很多传统的关系型数据库也提供全文检索,有的是基于Lucene内嵌,有的是基于自研,与Elasticsearch比较起来,功能单一,性能也表现不是很好,扩展性几乎没有。
如果,你的应用有全文检索需求,建议你优先迁移到Elasticsearch平台上来,其提供丰富的Full text queries会让你惊讶,一次用爽,一直用爽。
图示:Elasticsearch官方搜索文档
2)应用查询
Elasticsearch最擅长的就是查询,基于倒排索引核心算法,查询性能强于B-Tree类型所有数据产品,尤其是关系型数据库方面。当数据量超过千万或者上亿时,数据检索的效率非常明显。
个人更看中的是Elasticsearch在通用查询应用场景,关系型数据库由于索引的左侧原则限制,索引执行必须有严格的顺序,如果查询字段很少,可以通过创建少量索引提高查询性能,如果查询字段很多且字段无序,那索引就失去了意义;相反Elasticsearch是默认全部字段都会创建索引,且全部字段查询无需保证顺序,所以我们在业务应用系统中,大量用Elasticsearch替代关系型数据库做通用查询,自此之后对于关系型数据库的查询就很排斥,除了最简单的查询,其余的复杂条件查询全部走Elasticsearch。
3)大数据领域
Elasticserach已经成为大数据平台对外提供查询的重要组成部分之一。大数据平台将原始数据经过迭代计算,之后结果输出到一个数据库提供查询,特别是大批量的明细数据。
这里会面临几个问题,一个问题是大批量明细数据的输出,如何能在极短的时间内写到数据库,传统上很多数据平台选择关系型数据库提供查询,比如MySQL,之前在这方面吃过不少亏,瞬间写入性能极差,根本无法满足要求。另一个问题是对外查询,如何能像应用系统一样提供性能极好的查询,不限制查询条件,不限制字段顺序,支持较高的并发,支持海量数据快速检索,也只有Elasticsearch能够做到比较均衡的检索。
从官方的发布版本新特性来看,Elasticseacrch志在大数据分析领域,提供了基于列示存储的数据聚合,支持的聚合功能非常多,性能表现也不错,笔者有幸之前大规模深度使用过,颇有感受。
Elasticsearch为了深入数据分析领域,产品又提供了数据Rollup与数据Transform功能,让检索分析更上一层楼。在数据Rollup领域,Apache Druid的竞争能力很强,笔者之前做过一些对比,单纯的比较确实不如Druid,但自Elasticsearch增加了Transfrom功能,且单独创建了一个Transfrom的节点角色,个人更加看好Elasticseach,跳出了Rollup基于时间序列的限制。

图示:Rollup执行过程数据转换示意图
4)日志检索
著名的ELK三件套,讲的就是Elasticsearch,Logstash,Kibana,专门针对日志采集、存储、查询设计的产品组合。很多第一次接触到Elasticsearch的朋友,都会以为Elasticsearch是专门做日志的,其实这些都是误解,只是说它很擅长这个领域,在此领域大有作为,名气很大。
日志自身特点没有什么通用的规范性,人为的随意性很大,日志内容也是任意的,更加需求全文检索能力,传统技术手段本身做全文检索很是吃力。而Elasticsearch本身起步就是靠全文检索,再加上其分布式架构的特性,非常符合海量日志快速检索的场景。今天如果还发现有IT从业人员用传统的技术手段做日志检索,应该要打屁股了。
如今已经从ELK三件套发展到Elastic Stack了,新增加了很多非常有用的产品,大大增强了日志检索领域。
5)监控领域
指标监控,Elasticsearch进入此领域比较晚,却赶上了好时代,Elasticsearch由于其倒排索引核心算法,也是支持时序数据场景的,性能也是相当不错的,在功能性上完全压住时序数据库。
Elasticsearch搞监控得益于其提供的Elastic Stack产品生态,丰富完善,很多时候监控需要立体化,除了指标之外,还需要有各种日志的采集分析,如果用其它纯指标监控产品,如Promethues,遇到有日志分析的需求,还必须使用Elasticsearch,这对于技术栈来说,又扩增了,相应的掌控能力会下降,个人精力有限,无法同时掌握很多种数据产品,如此选择一个更加通用的产品才符合现实。
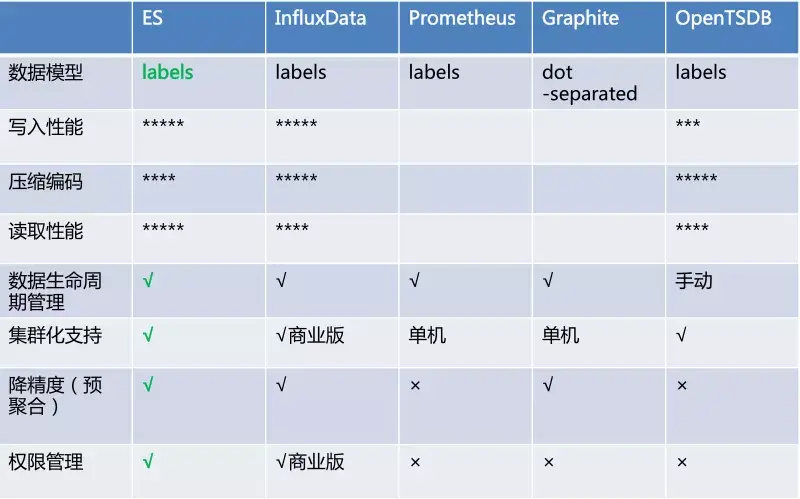
图示 :Elastic性能对比时序数据库(来自腾讯云分享)
6)机器学习
机器学习最近几年风吹的很大,很多数据产品都集成了,Elasticsearch也必须有,而且做的更好,真正将机器学习落地成为一个产品 ,简化使用,所见所得;而不像其它数据产品,仅仅集成算法包,使用者还必须开发很多应用支持。
Elasticsearch机器学习提供了两种方式,一种是异常检测类型,属于无监督学习,采用聚类模型,通常应用在安全分析领域,检测异常访问等;一种是数据帧分析,属于分类与回归,属于监督学习,可用于在业务模型领域,如电商行业,价格模型分析。
Elasticsearch本身是数据平台,集成了部分机器学习算法,同时又集成了Kibana可视化操作,使得从数据采集、到模型训练、到模型预测应用都可以一键式完成。
Elasticserach提供的机器学习套件,个人认为最应该应用在数据质量这个领域,帮助大数据平台自动检测数据质量,从而降低人力提供效率。
图示 :机器学习应用示意图(截图)
需求等级
Elasticsearch整个的技术栈非常复杂,涉及到的理论与技术点非常多,完全掌握并不现实,作为一个IT从业者,首先是定位好自己的角色,依据角色需求去学习掌握必备的知识点。以下是笔者对于一个技术产品的划分模型:
1、概念
Elasticsearch涉及到的概念很多,核心概念其实就那么几个,对于一个新手来说,掌握概念目的是为了建立起自己的知识思维模型,将之后学习到的知识点做一个很好的归纳划分;对于一个其它数据产品的老手来说 ,掌握概念的目的是为了与其它数据产品划分比较,深入的了解各自的优劣,在之后工作中若有遇到新的业务场景,可以迅速做出抉择。
IT从业者普遍都有个感受,IT技术发展太快了,各种技术框架产品层出不穷,学习掌握太难了,跟不上节奏。其实个人反倒觉得变化不大,基础理论核心概念并没有什么本质的发展变化,无非是工程技术实操变了很多,但这些是需要深入实践才需要的,对于概念上无需要。
作为一个技术总监,前端工程师工作1~2年的问题都可以问倒他,这是大家对于概念认知需求不一样。

图示:Elasticsearch核心概念
2、开发
开发工程师的职责是将需求变成可以落地运行的代码。Elasticsearch的应用开发工作总结起来就是增删改查,掌握必备的ES REST API,熟练运用足以。笔者之前任职某物流速运公司,负责Elasticsearch相关的工作,公司Elasticsearch的需求很多,尤其是查询方面,ES最厉害的查询是DSL,这个查询语法需要经常练习使用,否则很容易忘记,当每次有人询问时,都安排一个工程师专门负责各种解答,他在编写DSL方面非常熟练,帮助了很多的工程师新手使用Elasticsearch,屏蔽了很多细节,若有一些难搞定的问题,会由我来解决,另外一方面作为负责人的我偶然还要请他帮忙编写DSL。
Elasticsearch后面提供了SQL查询的功能,但比较局限,复杂的查询聚合必须回到DSL。

图示:DSL语法复杂度较高
3、架构
Elasticsearch集群架构总体比较复杂,首先得深入了解Elasticseach背后实现的原理,包括集群原理、索引原理、数据写入过程、数据查询过程等;其次要有很多案例实战的机会,遇到很多挑战问题 ,逐一排除解决,增加自己的经验。
对于开发工程师来说,满足日常需求开发无需掌握这些,但对于Elasticsearch技术负责人,就非常有必要了,面对各种应用需求,要能从架构思维去平衡,比如日志场景集群需求、大数据分析场景需求、应用系统复杂查询场景需求等,从实际情况设计集群架构以及资源分配等。
4、运维
Elasticsearch本质是一个数据库,也需要有专门的DBA运维,只是更偏重应用层面,所以运维职责相对传统DBA没有那么严苛。对于集群层面必须掌握集群搭建,集群扩容、集群升级、集群安全、集群监控告警等;另外对于数据层面运维,必须掌握数据备份与还原、数据的生命周期管理,还有一些日常问题诊断等。
5、源码
Elasticsearch本身是开源,阅读源码是个很好的学习手段,很多独特的特性官方操作文档并没有写出来,需要从源码中提炼,如集群节点之间的连接数是多少,但对于多数Elasticsearch从业者来说,却非必要。了解到国内主要是头部大厂需要深入源码定制化改造,更多的是集中在应用的便捷性改造,而非结构性的改造,Elastic原厂公司有几百人的团队做产品研发,而国内多数公司就极少的人,所以从产量上来说,根本不是一个等级的。
如果把Elasticsearch比喻为一件军事武器,对于士兵来说 ,熟练运用才是最重要的,至于改造应该是武器制造商的职责,一个士兵可以使用很多武器装备,用最佳的组合才能打赢一场战争,而不是去深入原理然后造轮子,容易本末倒置。
6、算法
算法应该算是数据产品本质的区别,关系型数据库索引算法主要是基于B-Tree, Elasticserach索引算法主要是倒排索引,算法的本质决定了它们的应用边界,擅长的应用领域。
通常掌握一个新的数据产品时,个人的做法是看它的关键算法。早期做过一个地理位置搜索相关的项目,基于某个坐标搜索周边的坐标信息,开始的时候采用的是三角函数动态计算的方式,数据量大一点,扫描一张数据表要很久;后面接触到Geohash算法,按照算法将坐标编码,存储在数据库中,基于前缀匹配查询,性能高效几个数量级,感叹算法的伟大;再后面发现有专门的数据库产品集成了Geohash算法,使用起来就更简单了。
Elasticsearch集成很多算法,每种算法实现都有它的应用场景。
拥抱ES的方法
1、官方文档
Elasticsearch早期出过一本参考手册《Elastic权威指南》,是一本很好的入门手册,从概念到实战都有涉及,缺点是版本针对的2.0,过于陈旧,除去核心概念,其余的皆不适用,当前最新版本已经是7.7了,跨度太大,Elasticsearch在跨度大的版本之间升级稍微比较麻烦,索引数据几乎是不兼容的,升级之后需要重建数据才可。
Elasticsearch当前最好的参考资料是官方文档,资料最全,同步发布版本,且同时可以参考多个版本。Elasticsearch官方参考文档也是最乱的,什么资料都有,系统的看完之后感觉仍在此山中,有点类似一本字典,看完了字典,依然写不好作文;而且资料还是英文的,至此就阻挡了国内大部分程序进入。
但想要学习Elasticsearch,官方文档至少要看过几遍,便于迅速查询定位。
图示:官方文档截图说明
2、系统学习
Elasticsearch成名很早,国内也有很多视频课程,多数比较碎片,或是纸上谈兵,缺乏实战经验。Elasticsearch有一些专门的书籍,建议购买阅读,国内深度一些的推荐《Elasticsearch源码解析与优化实战》,国外推荐《Elasticsearch实战》,而且看书还有助于培养系统思维。
Elasticsearch技术栈功能特性很多,系统学习要保持好的心态,持之以恒,需要很长时间,也需要参考很多资料。
3、背后原理
Elasticsearch是站在巨人肩膀上产品,背后借鉴了很多设计思想,集成了很多算法,官方的参考文档在技术原理探讨这块并没有深入,仅仅点到为止。想要深入了解,必须得另辟蹊径。
Elastic官方的博客有很多优质的文章,很多人因为英文的缘故会忽视掉,里面有很多关键的实现原理,图文并茂,写得非常不错;另外国内一些云厂商由于提供了Elasticsearch云产品,需要深度定制开发,也会有一些深入原理系列的文章,可以去阅读参考,加深理解。对于已经有比较好的编程思维的人,也可以直接去下载官方源码,设置断点调试阅读。
4、项目实战
项目实战是非常有效的学习途径,考过驾照的朋友都深有体会,教练一上来就直接让你操练车,通过很多次的练习就掌握了。Elasticsearch擅长的领域很多,总结一句话就是“非强事务ACID场景皆可适用”,所以可以做的事情也很多。
日志领域的需求会让你对于数据写入量非常的关心,不断的调整优化策略,提高吞吐量,降低资源消耗;业务系统的需求会让你对数据一致性与时效性特别关心,从其它数据库同步到ES,关注数据同步的速度,关注数据的准确性,不断的调整你的技术方案与策略;大数据领域的需求会让你对于查询与聚合特别关注,海量的数据需要快速的检索,也需要快速的聚合结果。
项目实战的过程,就是一个挖坑填坑的过程,实战场景多了,解决的问题多了,自然就掌握得很好了。
CPU怎么识别我们写的代码?
文章来源 图灵人工智能 转自STM32嵌入式开发,版权属于原作者,仅学术分享
先说一下半导体,啥叫半导体?就是介于导体和绝缘体中间的一种东西,比如二极管。相关文章:关于二极管的基础知识。
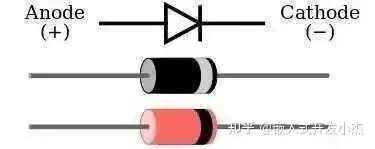
电流可以从A端流向C端,但反过来则不行。你可以把它理解成一种防止电流逆流的东西。
当C端10V,A端0V,二极管可以视为断开。
当C端0V,A端10V,二极管可以视为导线,结果就是A端的电流源源不断的流向C端,导致最后的结果就是A端=C端=10V。
等等,不是说好的C端0V,A端10V么?咋就变成结果是A端=C端=10V了?你可以把这个理解成初始状态,当最后稳定下来之后就会变成A端=C端=10V。
文科的童鞋们对不住了,实在不懂问高中物理老师吧。反正你不能理解的话就记住这种情况下它相当于导线就行了。
利用半导体的这个特性,我们可以制作一些有趣的电路,比如【与门】。
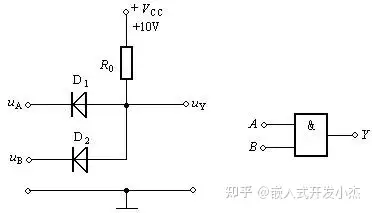
我们把这个装置成为【与门】,把有电压的地方计为1,0电压的地方计为0。至于具体几V电压,那不重要。也就是AB必须同时输入1,输出端Y才是1;AB有一个是0,输出端Y就是0。
其他还有【或门】【非门】和【异或门】,跟这个都差不多,或门就是输入有一个是1输出就是1,输入00则输入0。
非门也好理解,就是输入1输出0,输入0输出1。
异或门难理解一些,不过也就那么回事,输入01或者10则输出1,输入00或者11则输出0。(即输入两个一样的值则输出0,输入两个不一样的值则输出1)。
这几种门都可以用二极管或者三极管做出来,具体怎么做就不演示了,有兴趣的童鞋可以自己试试。当然实际并不是用二极管三极管做的,因为它们太费电了。实际是用场效应管(也叫MOS管)做的。
然后我们就可以用门电路来做CPU了。当然做CPU还是挺难的,我们先从简单的开始:加法器。相关文章:CPU如何进行数字加法。加法器顾名思义,就是一种用来算加法的电路,最简单的就是下面这种。
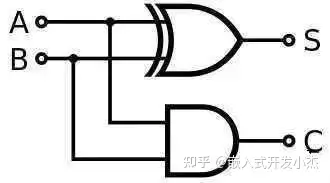
AB只能输入0或者1,也就是这个加法器能算0+0,1+0或者1+1。
输出端S是结果,而C则代表是不是发生进位了,二进制1+1=10嘛。这个时候C=1,S=0。
费了大半天的力气,算个1+1是不是特别有成就感?
那再进一步算个1+2吧(二进制01+10),然后我们就发现了一个新的问题:第二位需要处理第一位有可能进位的问题,所以我们还得设计一个全加法器。
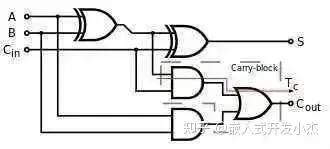
每次都这么画实在太麻烦了,我们简化一下。
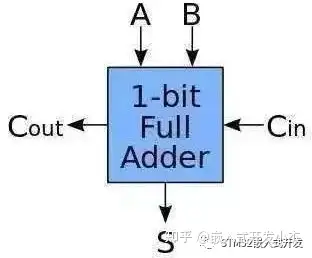
也就是有3个输入2个输出,分别输入要相加的两个数和上一位的进位,然后输入结果和是否进位。然后我们把这个全加法器串起来:
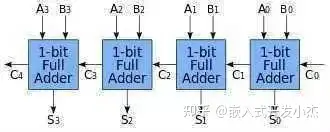
我们就有了一个4位加法器,可以计算4位数的加法也就是15+15,已经达到了幼儿园中班水平,是不是特别给力?
做完加法器我们再做个乘法器吧,当然乘任意10进制数是有点麻烦的,我们先做个乘2的吧。
乘2就很简单了,对于一个2进制数数我们在后面加个0就算是乘2了。比如:
5=101(2)
10=1010(2)
以我们只要把输入都往前移动一位,再在最低位上补个零就算是乘2了。具体逻辑电路图我就不画,你们知道咋回事就行了。
那乘3呢?简单,先位移一次(乘2)再加一次。乘5呢?先位移两次(乘4)再加一次。
所以一般简单的CPU是没有乘法的,而乘法则是通过位移和加算的组合来通过软件来实现的。这说的有点远了,我们还是继续做CPU吧。
现在假设你有8位加法器了,也有一个位移1位的模块了。串起来你就能算(A+B)×2了!激动人心,已经差不多到了准小学生水平。
那我要是想算A×2+B呢?简单,你把加法器模块和位移模块的接线改一下就行了,改成输入A先过位移模块,再进加法器就可以了。
你的意思是我改个程序还得重新接线?
所以你以为呢?
实际上,编程就是把线来回插啊。惊喜不惊喜?意外不意外?

早期的计算机就是这样编程的,几分钟就算完了但插线好几天。关于插线编程的相关文章推荐看着篇:国内大神手工焊接,制作了一个CPU。而且插线是个细致且需要耐心的工作,所以那个时候的程序员都是清一色的漂亮女孩子,穿制服的那种,就像照片上这样。是不是有种生不逢时的感觉?
插线也是个累死人的工作。所以我们需要改进一下,让CPU可以根据指令来相加或者乘2。这里再引入两个模块,一个叫flip-flop,简称FF,中文好像叫触发器,如下图这样。
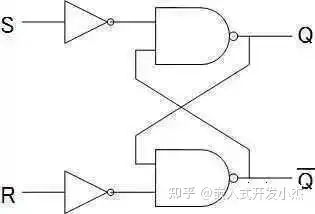
这个模块的作用是存储1bit数据。比如上面这个RS型的FF,R是Reset,输入1则清零。S是Set,输入1则保存1。RS都输入0的时候,会一直输出刚才保存的内容。
我们用FF来保存计算的中间数据(也可以是中间状态或者别的什么),1bit肯定是不够的,不过我们可以并联嘛,用4个或者8个来保存4位或者8位数据。这种我们称之为寄存器(Register)。另外一个叫MUX,中文叫选择器,如下图就是一个选择器。
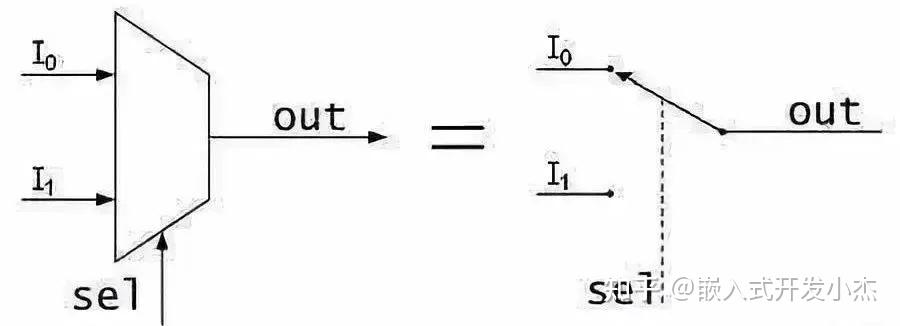
这个就简单了,sel输入0则输出i0的数据,i0是什么就输出什么,01皆可。同理sel如果输入1则输出i1的数据。当然选择器可以做的很长,比如这种四进一出的具体原理不细说了,其实看看逻辑图琢磨一下就懂了,知道有这个东西就行了。下图是一个四进一出-选择器。

有这个东西我们就可以给加法器和乘2模块(位移)设计一个激活针脚。
这个激活针脚输入1则激活这个模块,输入0则不激活。这样我们就可以控制数据是流入加法器还是位移模块了。
于是我们给CPU先设计8个输入针脚,4位指令,4位数据。
我们再设计3个指令:
- 0100,数据读入寄存器
- 0001,数据与寄存器相加,结果保存到寄存器
- 0010,寄存器数据向左位移一位(乘2)
为什么这么设计呢,刚才也说了,我们可以为每个模块设计一个激活针脚。然后我们可以分别用指令输入的第二第三第四个针脚连接寄存器,加法器和位移器的激活针脚。
这样我们输入0100这个指令的时候,寄存器输入被激活,其他模块都是0没有激活,数据就存入寄存器了。同理,如果我们输入0001这个指令,则加法器开始工作,我们就可以执行相加这个操作了。
这里就可以简单回答这个问题的第一个小问题了:CPU是为什么能看懂这些二级制的数呢?
为什么CPU能看懂,因为CPU里面的线就是这么接的呗。你输入一个二进制数,就像开关一样激活CPU里面若干个指定的模块以及改变这些模块的连同方式,最终得出结果。
几个可能会被问的问题
Q:CPU里面可能有成千上万个小模块,一个32位/64位的指令能控制那么多吗?
A:我们举例子的CPU里面只有3个模块,就直接接了。真正的CPU里会有一个解码器(decoder),把指令翻译成需要的形式。
Q:你举例子的简单CPU,如果我输入指令0011会怎么样?
A:当然是同时激活了加法器和位移器从而产生不可预料的后果,简单的说因为你使用了没有设计的指令,所以后果自负呗。在真正的CPU上这么干大概率就是崩溃呗,不过肯定会有各种保护性的设计。
细心的小伙伴可能发现一个问题:你设计的指令【0001,数据与寄存器相加,结果保存到寄存器】这个一步做不出来吧?
毕竟还有一个回写的过程,实际上确实是这样。我们设计的简易CPU执行一个指令差不多得三步,读取指令,执行指令,写寄存器。
经典的RISC设计则是分5步:读取指令(IF),解码指令(ID),执行指令(EX),内存操作(MEM),写寄存器(WB)。我们平常用的x86的CPU有的指令可能要分将近20个步骤。
你可以理解有这么一个开关,我们啪的按一下,CPU就走一步,你按的越快CPU就走的越快。咦?听说你有个想法?少年,你这个想法很危险啊,姑且不说你能不能按那么快。拿现代的CPU来说,也就2GHz多吧,大概一秒也就按个20亿下吧。
就算你能按那么快,虽然速度是上去了,但功耗会大大增加,发热上升稳定性下降。江湖上确实有这种玩法,名曰超频,不过新手不推荐你尝试哈。
那CPU怎么知道自己走到哪一步了呢?前面不是介绍了FF么,这个不光可以用来存中间数据,也可以用来存中间状态,也就是走到哪了。
具体的设计涉及到FSM(finite-state machine),也就是有限状态机理论,以及怎么用FF实装。这个也是很重要的一块,考试必考哈,只不过跟题目关系不大,这里就不展开讲了。
我们再继续刚才的讲,现在我们有3个指令了。我们来试试算个(1+4)X2+3吧。
0100 0001 ;寄存器存入1
0001 0100 ;寄存器的数字加4
0010 0000 ;乘2
0001 0011 ;再加三
太棒了,靠这台计算机我们应该可以打败所有的幼儿园小朋友,称霸大班了。而且现在我们用的是4位的,如果换成8位的CPU完全可以吊打低年级小学生了!
实际上用程序控制CPU是个挺高级的想法,再此之前计算机(器)的CPU都是单独设计的。
1969年一家日本公司BUSICOM想搞程控的计算器,而负责设计CPU的美国公司也觉得每次都重新设计CPU是个挺傻X的事,于是双方一拍即合,于1970年推出一种划时代的产品,世界上第一款微处理器4004。
这个架构改变了世界,那家负责设计CPU的美国公司也一步一步成为了业界巨头。哦对了,它叫Intel,对,就是噔噔噔噔的那个。
我们把刚才的程序整理一下:
“01000001000101000010000000010011”
你来把它输入CPU,我去准备一下去幼儿园大班踢馆的工作。
什么!?等我们输完了人家小朋友掰手指都能算出来了?
没办法机器语言就是这么反人类。哦,忘记说了,这种只有01组成的语言被称之为机器语言(机器码),是CPU唯一可以理解的语言。不过你把机器语言让人读,绝对一秒变典韦,这谁也受不了。
所以我们还是改进一下吧。不过话虽这么讲,也就往前个30年,直接输入01也是个挺普遍的事情。
于是我们把我们机器语言写成的程序:
0100 0001 ;寄存器存入1
0001 0100 ;寄存器的数字加4
0010 0000 ;乘2
0001 0011 ;再加三
改写成:
MOV 1 ;寄存器存入1
ADD 4 ;寄存器的数字加4
SHL 0 ;乘2(介于我们设计的乘法器暂时只能乘2,这个0是占位的)
ADD 3 ;再加三
是不是容易读多了?这就叫汇编语言。
汇编语言的好处在于它和机器语言一一对应。
也就是我们写的汇编可以完美的改写成机器语言,直接指挥cpu,进行底层开发;我们也可以把内存中的数据dump出来,以汇编语言的形式展示出来,方便调试和debug。
汇编语言极大的增强了机器语言的可读性和开发效率,但对于人类来说也依然是太晦涩了,于是我们又发明了高级语言,以近似于人类的语法来表现数据结构和算法。
比如很多语言都可以这么写:
a=(1+4)*2+3;
当然这样计算机是不认识的,我们要把它翻译成计算机认识的形式,这个过程叫编译,用来做这个事的东西叫编译器。
具体怎么把高级语言弄成汇编语言/机器语言的,一本书都写不完,我们就举个简单的例子。
我们把:
(1+4)*2+3
转换成:
1,4,+,2,*,3,+
这种写法叫后缀表示法,也成为逆波兰表示法。相对的,我们平常用的表示法叫中缀表示法,也就是符号方中间,比如1+4。而后缀表示法则写成1,4,+。
转换成这种写法的好处是没有先乘除后加减的影响,也没有括号了,直接算就行了。
具体怎么转换的可以找本讲编译原理的书看看,这里不展开讲了。
转换成这种形式之后我们就可以把它改成成汇编语言了。
从头开始处理,最开始是1,一个数字,那就存入寄存器:
MOV 1
之后是4,+,那就加一下:
ADD 4
然后是2,*,那就乘一下(介于我们设计的乘法器暂时只能乘2,这个0是占位的):
SHL 0
最后是3,+,那再加一下:
ADD 3
最后我们把翻译好的汇编整理一下:
MOV 1
ADD 4
SHL 0
ADD 3
再简单的转换成机器语言,就可以拿到我们设计的简单CPU上运行了。
其实到了这一步,应该把这个问题都讲清楚了:C语言写出来的东西是怎么翻译成二进制的,电脑又是怎么运行这个二进制的。
只不过题主最后还提到栈和硬件的关系,这里就再多说几句。
其实栈是一种数据结构,跟CPU无关。只不过栈这个数据结构实在太常用了,以至于CPU会针对性的进行优化。为了能让我们的CPU也能用栈,我们给它增加几个组件。
第一,增加一组寄存器。现在有两组寄存器了,我们分别成为A和B。
第二,增加两个指令,RDA/RDB和WRA/WRB,分别为把指定内存地址的数据读到寄存器A/B,和把寄存器A/B的内容写到指定地址。
顺便再说下内存,内存有个地址总线,有个数据总线。比如你要把1100这个数字存到0011这个地址,就把1100接到数据总线,0011接到地址总线,都准备好了啪嚓一按开关(对,就是我们前面提到的那个开关),就算是存进去了。
什么叫DDR内存呢,就是你按这个开关的时候存进去一个数字,抬起来之前你把地址和数据都更新一下,然后一松手,啪!又进去一个。也就是正常的内存你按一下进去1个数据,现在你按一下进去俩数据,这就叫双倍速率(Double Data Rate,简称DDR)
加了这几个命令之后我们发现按原来的设计,CPU每个指令针脚控制一个模块的方式的话针脚不够用了。所以我们就需要加一个解码器了(decoder)。
于是我们选择用第二个位作为是否选择寄存器的针脚。如果为0,则第三第四位可以正常激活位移器和加法器;如果为1则只激活寄存器而不激活位移和加法器,然后用第四位来决定是寄存器A还是B。这样变成了:
- 0100,数据读入寄存器A
- 0101,数据读入寄存器B (我们把汇编指令定义为MOVB)
- 0001,数据与寄存器A相加,结果保存到寄存器A
- 0011,数据与寄存器B相加,结果保存到寄存器B(我们把汇编指令定义为ADDB)
- 0010,寄存器A数据向左位移一位(乘2)
最后我们可以用第一位来控制是不是进行内存操作。如果第一位为1则也不激活位移和加法器模块,然后用第三个针脚来控制是读还是写。这样就有了:
- 1100,把寄存器B的地址数据读入寄存器A(我们把汇编指令定义为RD)
- 1110,寄存器A的数据写到寄存器B指定的地址(我们把汇编指令定义为WR)
我们加了个解码器之后,加法器的激活条件从p4变成了(NOT (p1 OR p2)) AND p4。
加法器的输入则由第三个针脚判断,0则为寄存器A,1为寄存器B。这就是简单的指令解码啦。
当然我们也可以选择不向下兼容,另外设计一套指令。不过放到现实世界恐怕就要出大乱子了,所以你也可以想象我们平常用的x86背了个多大的历史包袱。
这个时候我们用栈的话,先栈地址初始化:
0101 1000 ; MOVB 16; 把栈底地址定义为1000
之后入栈的话,比如把数字3,4入栈:
1111 0011 ; WR 03; 把3写到内存,地址为1000
0011 0001 ; ADDB 01; 栈地址+1
1111 0100 ; WR 04; 把3写到内存,地址为1001
0011 0001 ; ADDB 01; 栈地址+1
这样就把3,4都保存到栈里了。
出栈的话反过来:
0011 1111 ; ADDB -1; 栈地址-1
1101 0000 ; RD 00; 把内容读入寄存器A,00是占位
0011 1111 ; ADDB -1; 栈地址-1
1101 0000 ; RD 00; 把内容读入寄存器A,00是占位
这样就依次得到4,3两个值。
所以,入栈出栈其实就是把数据写道指定的内存位置,CPU其实不知道你是在干啥。相关文章:关于C语言堆栈的经典讲解。当然我们也可以让CPU知道。
接下来我们再改进一下,给CPU再加一个寄存器SP,并定义两个指令:一个PUSH,一个POP。动作分别是把数据写入SP的地址,然后SP=SP+1,POP的话反过来。
这样有什么好处呢?好处在于PUSH/POP这样的指令消耗特别少,速度特别快。而栈这种数据结构在各种程序里用的又特别频繁,设计成专用的指令则可以很大程度上提升效率。
当然前提是编译器知道这个指令,并且做了优化,所以同样的程序(c语言写的),编译参数不一样(打开/关闭某些特性),编译出来的东西也就不一样,在不同硬件上的运行的效率也就会不一样。
比如上古时代的mmx,今天的SSE4.2,AVX-512,给力不给力?特别给力,但你平常用的程序支不支持是另一码事,要支持怎么办?重新编译呗。
这个时候开源的优势就显示出来了,重新编译很方便。闭源的话你就要指望作者开恩啦。
对于大多数人来说,电脑就是个黑箱,我们很难理解它到底是怎用工作的。这个问题又很难一句两句解释清楚,因为它是一环扣一环的,每一环都很抽象,每一环都是基础值俩个学分,展开了讲没上限的那种。
这就导致了即使是系统学过计算机的人也不见得就有一个明确而清晰的思路。想用尽量短的篇幅和尽量简单的语言把这个事从头到位解释了一下,希望能给大家解答一些疑惑。关于软硬件结合,另外也推荐下这篇文章:代码是如何控制硬件的?
C++ 教程(持续更新)
1、视频
https://www.bilibili.com/video/BV1et411b73Z?p=2&spm_id_from=pageDriver&vd_source=dab57cea5e1b38b49ad994543c0c61bf
2、github笔记
c++ 类
代码实例:
#include <iostream>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
using namespace std;
class Stack
{
public:
Stack(int size=1024);
~Stack();
void init();
bool isEmpty();
bool isFull();
void push(int data);
int pop();
private:
int* space;
int top;
};
Stack::Stack(int size)
{
space = new int[size];
top = 0;
}
Stack::~Stack()
{
delete []space;
}
//void Stack::init()
//{
// memset(space,0,sizeof(space));
// top = 0;
//}
bool Stack::isEmpty()
{
return top == 0;
}
bool Stack::isFull()
{
return top == 1024;
}
void Stack::push(int data)
{
space[top++] = data;
}
int Stack::pop()
{
return space[--top];
}
int main()
{
// Stack s;
Stack s(100);
// s.init();
if(!s.isFull())
s.push(10);
if(!s.isFull())
s.push(20);
if(!s.isFull())
s.push(30);
if(!s.isFull())
s.push(40);
if(!s.isFull())
s.push(50);
while(!s.isEmpty())
cout<<s.pop()<<endl;
return 0;
}
1、构造器(Constructor):
在类对象创建时,自动调用,完成类对象的初始化。尤其是动态堆内存的申请。
规则:
1 在对象创建时自动调用,完成初始化相关工作。
2 无返回值,与类名同,
3 可以重载,可默认参数。
4 默认无参空体,一经实现,默认不复存在。
class 类名
{
类名(形式参数)
构造体
}
class A
{
A(形参)
{}
}比如:
Stack::Stack(int size)
{
space = new int[size];
top = 0;
}private和public,类对象可以直接访问公有成员,但只有公有成员函数内部来访问对象的私有成员
析造器(Destructor):析构函数的作用,并不是删除对象,而在对象销毁前完成的一些清理工作。
对象销毁时期
1、栈对象离开其作用域。
2、堆对象被手动 delete.
定义:
class 类名
{
~类名()
析造体
}
class A
{
~A()
{}
}
在类对像销毁时,自动调用,完成对象的销毁。尤其是类中己申请的堆内存的释放.
规则:
1 对象销毁时,自动调用。完成销毁的善后工作。
2 无返值,与类名同,无参。不可以重载与默认参数。
3 系统提供默认空析构器,一经实现,不复存在。
Stack::~Stack()
{
delete []space;
}
this 指针
系统在创建对象时,默认生成的指向当前对象的指针。这样作的目的,就是为了带来方
便
1,避免构造器的入参与成员名相同。
2,基于 this 指针的自身引用还被广泛地应用于那些支持多重串联调用的函数中。
比如连续赋值
#include <iostream>
using namespace std;
class Stu
{
public:
Stu(string name, int age) // :name(name),age(age)
{
this->name = name;
this->age = age;
}
Stu & growUp()
{
this->age++;
return *this; // return this; ??
}
void display()
{
cout<<name<<" : "<<age<<endl;
}
private:
string name;
int age;
};
int main()
{
Stu s("wangguilin",30);
s.display();
s.growUp().growUp().growUp().growUp().growUp();
s.display();
return 0;
}类继承
在 C++中可重用性(software reusability)是通过继承(inheritance)这一机制来实现的。如果没有掌握继承性,就没有掌握类与对象的精华
#include <iostream>
using namespace std;
class Person
{
public:
void eat(string food)
{
cout<<"i am eating "<<food<<endl;
}
};
class Student:public Person
{
public:
void study(string course)
{
cout<<"i am a student i study "<<course<<endl;
}
};
class Teacher:public Person
{
public:
void teach(string course)
{
cout<<"i am a teacher i teach "<<course<<endl;
}
};
int main()
{
Student s;
s.study("C++");
s.eat("黄焖鸡");
Teacher t;
t.teach("Java");
t.eat("驴肉火烧");
return 0;
}
类的继承,是新的类从已有类那里得到已有的特性。或从已有类产生新类的过程就是类的派生。原有的类称为基类或父类,产生的新类称为派生类或子类。派生与继承,是同一种意义两种称谓。
派生类的声明:
class 派生类名:[继承方式] 基类名
{
派生类成员声明;
};
一个派生类可以同时有多个基类,这种情况称为多重继承,派生类只有一个基类,称为单继承。下面从单继承讲起
继承方式规定了如何访问基类继承的成员。继承方式有 public, private, protected。继承方式不影响派生类的访问权限,影响了从基类继承来的成员的访问权限,包括派生类内的访问权限和派生类对象。
简单讲:
公有继承:基类的公有成员和保护成员在派生类中保持原有访问属性,其私有成员仍为基类的私有成员。
私有继承:基类的公有成员和保护成员在派生类中成了私有成员,其私有成员仍为基类的私有成员。
保护继承:基类的公有成员和保护成员在派生类中成了保护成员,其私有成员仍为基类的私有成员
pretected 对于外界访问属性来说,等同于私有,但可以派生类中可见。
#include <iostream>
using namespace std;
class Base
{
public:
int pub;
protected:
int pro;
private:
int pri;
};
class Drive:public Base
{
public:
void func()
{
pub = 10;
pro = 100;
// pri = 1000;
public;
int a;
protected:
int b;
private:
int c
};
//
int main()
{
Base b;
b.pub = 10;
// b.pro = 100;
// b.pri = 1000;
return 0;
}
派生类中的成员,包含两大部分,一类是从基类继承过来的,一类是自己增加的成员。从基类继承过过来的表现其共性,而新增的成员体现了其个性。
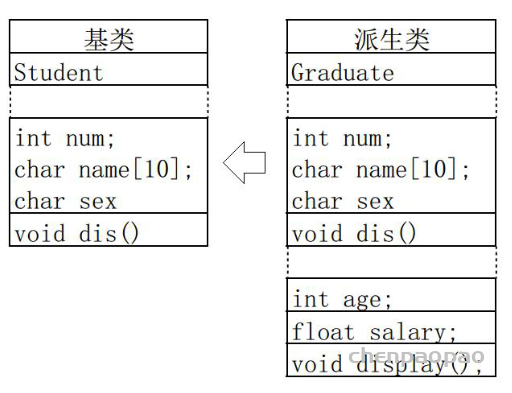
几点说明:
1,全盘接收,除了构造器与析构器。基类有可能会造成派生类的成员冗余,所以说基
类是需设计的。
2,派生类有了自己的个性,使派生类有了意义
派生类中由基类继承而来的成员的初始化工作还是由基类的构造函数完成,然后派生类
中新增的成员在派生类的构造函数中初始化。
派生类构造函数的语法:
派生类名::派生类名(参数总表):基类名(参数表),内嵌子对象(参数表)
{
派生类新增成员的初始化语句; //也可出现地参数列表中
}
构造函数的初始化顺序并不以上面的顺序进行,而是根据声明的顺序初始化。
如果基类中没有默认构造函数(无参),那么在派生类的构造函数中必须显示调用基类构
造函数,以初始化基类成员。
代码实现
祖父类
student.h
class Student
{
public:
Student(string sn,int n,char s);
~Student();
void dis();
private:
string name;
int num;
char sex;
};
student.cpp
Student::Student(string sn, int n, char s)
:name(sn),num(n),sex(s)
{
}
Student::~Student()
{
}
void Student:: dis()
{
cout<<name<<endl;
cout<<num<<endl;
cout<<sex<<endl;
}
父类
graduate.h
class Graduate:public Student
{
public:
Graduate(string sn,int in,char cs,float fs);
~Graduate();
void dump()
{
dis();
cout<<salary<<endl;
}
private:
float salary;
};
graduate.cpp
Graduate::Graduate(string sn, int in, char cs, float fs)
:Student(sn,in,cs),salary(fs)
{
}
Graduate::~Graduate()
{
}
类成员
birthday.h
class Birthday
{
public:
Birthday(int y,int m,int d);
~Birthday();
void print();
private:
int year;
int month;
int day;
};
birthday.cpp
Birthday::Birthday(int y, int m, int d)
:year(y),month(m),day(d)
{
}
Birthday::~Birthday()
{
}
void Birthday::print()
{
cout<<year<<month<<day<<endl;
}
子类
doctor.h
class Doctor:public Graduate
{
public:
Doctor(string sn,int in,char cs,float fs,string st,int iy,int im,in
t id);
~Doctor();
void disdump();
private:
string title; //调用的默认构造器,初始化为””
Birthday birth; //类中声明的类对象
};
doctor.cpp
Doctor::Doctor(string sn, int in, char cs, float fs, string st, int iy,
int im, int id)
:Graduate(sn,in,cs,fs),birth(iy,im,id),title(st)
{
}
Doctor::~Doctor()
{
}
void Doctor::disdump()
{
dump();
cout<<title<<endl;
birth.print();
}
测试代码
int main()
{
Student s("zhaosi",2001,'m');
s.dis();
cout<<"----------------"<<endl;
Graduate g("liuneng",2001,'x',2000);
g.dump();
cout<<"----------------"<<endl;
Doctor d("qiuxiang",2001,'y',3000,"doctor",2001,8,16);
d.disdump();
return 0;