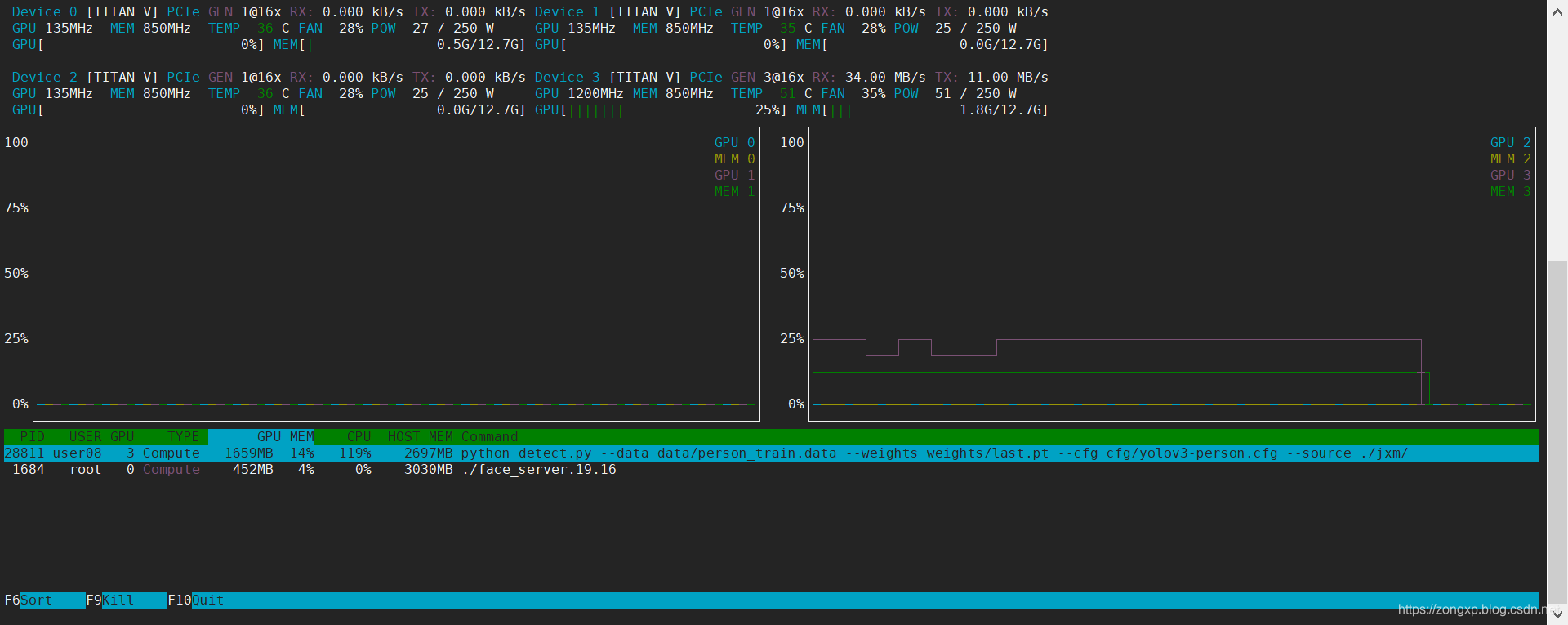
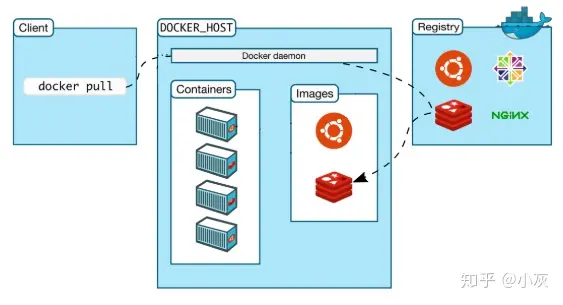
文章来源于一个知乎问题:如何判断候选人有没有千卡GPU集群的训练经验?确实对于普通开发者来说,大概率从未尝试过使用数千张GPU训练一个模型,这方面确实是一个很好的研究方向,也是成为顶尖算法工程师所必需的必经之路,因此记录下知乎的一些回答,用于学习和记录。虽然目前还没有机会能够调用数千张GPU用于模型训练,但对于目前几十张GPU进行并行训练也有帮助。
高赞回答1:如何用千卡进行训练
最近看到知乎一个回答,把千卡训练的难度吹上天了。但其实真正用过千卡就会发现也就那么几个点。于是想写一篇文章简单讲讲。
本文将包括三个部分:
- 首先我们将讨论千卡训练的难题,以及应该在什么时候使用千卡训练;
- 接着,我们将讨论如何在一千张卡上开始训练,如何让他达到近乎线性的性能提升;
- 最后我们将展开讨论一些千卡训练当中仍然悬而未决(至少对于开源社区来说)的问题。
为什么千卡训练是困难的?
其实那篇回答在这部分说的没错。千卡训练和八卡训练的区别是—显卡多了一百多倍。
这意味着什么呢?
- 通信时间增加
- 故障概率增加
这俩问题都很好理解。
时间上,PyTorch 内部支持 NCCL / Gloo / MPI 三个通信后端(请务必使用 NCCL。)其中训网络最常用的 AllReduce 操作【从多个sender那里接收数据,最终combine到一个节点上】会根据具体硬件配置走 Ring AllReduce 和 Tree AllReduce【ring allreduce和tree allreduce的具体区别是什么?】。Ring 的时间复杂度是 O(pn),Tree 的时间复杂度是 O(logpn)。就算是理论上 128 节点也比单节点慢至少七倍,实践当中跨节点通信要远比单节点慢得多。
故障上,一个节点出问题的概率是 p,128 个节点就是 1−(1−p128)。也就是说如果一个操作在一个训练当中的出错概率是 1%,那么在 128 节点当中的出错概率就是 72.37%。
此外,随着规模的增大,许多问题都会变得难以忍受。比如数据增强要花 0.1s,一亿条数据就是 278 个小时(当然这只是胡拆的一个数字,实际有各种机制所以不会有这么大影响。
因此,钱多烧手并不是使用千卡训练的理由。闲得蛋疼可能是,但你得多蛋疼才能想出这么折磨自己的 idea?
因此,千卡训练解决的问题是大模型&大数据问题。如果你的训练时间没有超过 8192 GPU 日,那么你绝对不需要一千张显卡。
看到这里,绝大多数人已经可以关掉这篇文章了。除非你的模型和数据都以 B(十亿)来作为计量单位。当然如果你正在厕所里手机没电想看点儿东西解闷儿的话(虽然我很怀疑是否会有人把他打出来……那么可以继续往下看
如何使用一千张卡训练?
如何提高计算效率?
这件事情其实是一个 case by case 的事情。因为通信、计算速度啥的受硬件影响更多。同样是 A100 集群,我全 DGX 节点,每一张 A100 都是 SXM 接口并配一块儿专属的 IB 网卡。你一个小破普惠服务器插 8 张 PCI-E A100,IB 卡一个节点只给一张。那咱俩遇到的问题就完全不是一个问题。
因此,要讨论如何提高训练效率、减少训练耗时,我们首先要了解训练耗时在哪里。那么,一个训练步的耗时在哪里呢?需要谨记,没有 profile 的优化是没有意义的。
你可能会说,forward backward sync。很好,这说明你了解 PyTorch 的基本流程。不过现实当中要复杂得多。
- dataset 读取数据,构建输出
- dataloader collate 数据,进行数据预处理
- 模型 forward 计算输出
- loss compute
- 模型 backward 计算梯度
- 模型 sync 梯度
- 优化器 step 更新权重
- 打印 log
当然这是可以无限细分下去的,但一般这些就够了。需要注意的是,除了 4-7 的耗时是真耗时,其他都需要通过异步操作来盖掉。这也是我们的优化目标。
异步执行在 PyTorch 的 dataloader、CUDA 和分布式当中都存在。前者可以通过设置 num_workers 和 prefetch_count 为 0 来关闭,后两者可以通过 cuda.synchornize 和 dist.barrier 来执行手动同步。在 profile 时,我们需要首先需要测整个 step 的时长。然后再在每次测量前执行手动同步来计算每个部分的时长。如果前者的总耗时等于后者 4-7 的耗时之和,那么通常不需要执行任何操作。但这种情况在千卡操作中几乎不可能发生。
第 6 步通信往往需要耗费大量时间。因此,我们还需要进一步优化通信。
以下内容是对PyTorch Distributed的概括,有感兴趣的同学建议通读并背诵全文。
计算-通信重叠
在 PyTorch 当中,梯度的通信和反向传播是交叠进行的。也就是说,每完成一层的梯度计算,都会立即触发当前层的同步。实现起来也很简单,每个进程在完成自己第 k 层的梯度计算后都会触发一个钩子来给计数器+1s。当计数器达到进程数时开火进行梯度通信。有很多同学在计算梯度过程中遇到过 RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one. 错误,这就是因为有的模块没有参与计算 loss,导致梯度同步卡住了。需要注意,当 find_unused_parameters=True 时,PyTorch 分布式使用 nn.Module.__init__ 当中定义子模块的反向顺序来作为梯度桶的构建顺序。因此,确保模块定义和调用的顺序一致是一个良好的实践。
梯度合桶
尽管理论上来说,同步发生的越及时,重合度越高,性能越好。但实际上每次发起通信都是有上头的。因此,现实当中梯度同步并不是越多越好越快越好。为此,PyTorch 引入了梯度合桶机制,通过把多个 Tensor 装在一个桶里再通信桶来减少通信次数从而减少总耗时。合桶的 bucket_cap_mb 默认是 25MiB,这对于绝大多数模型来说都是太小的。目前已经有提升这个默认值的特性需求,但是这个还是调一下更好。
梯度累加
当你做完所有操作之后,惊喜的发现 TMD 怎么同步时间还是单节点的好几倍。这其实是正常情况……实际上超过 256 卡的训练想要把通信盖掉就是一件不可能的事情。你说老师我看 FB 论文说他们 256 卡就是线性提升啊…那这里不得不提的一个策略就是梯度累加了。梯度累加会执行 k 次 forward+backward 之后再执行优化器步进。这有很多好处,首先对于大模型 batch size 通常不能开多大,梯度累加可以提升等效 batch size。其次累加期间的 backward 不需要通信梯度,加快了训练速度。
少即是快
Python 是一种很慢的语言。当然你说 JIT trace+torch.compile 有提升我也不反对,但对于最高效率来说,只有必须要存在的代码和不存在的代码两种。
抱抱脸的 Transformers 就是一个反例。两个子模块就能写完的 TransformerLayer 他们硬是能写出来一堆…偏偏他们还信奉 Single Model File Policy……我寻思你这完全不考虑继承的封这么多层是要搞鸡毛啊?正例反而是 PyTorch……(笑死,我竟然会夸脸书代码写得好。具体来说就是 nn.functional 当中的各种实现。你会发现他们第一行往往是 handle_torch_func。熟悉 Python 装饰器的小伙汁通常要问了,为啥这里不用个装饰器统一一下?因为装饰器会引入额外的函数调用,额外的函数调用就是额外的上头。
因此,如果你想确保最高的效率,写一个简单的训练代码和模型代码非常重要。毕竟,1%的效率提升,节省的可能是数百个 GPU 日。
如何平稳训练
这一段当中中咱们只讨论你能控制的问题。
捕捉不致命的异常
故障率高的问题其实很好解决。在训练当中,大部分异常都是非致命异常,接住他们就好了。我之前写过一个装饰器,catch,它的作用就是接住异常,然后调回调函数(默认当然就是把错误打印到 log 里)。所有你需要做的只是使用它来装饰所有非 fatal 的操作。
在实际应用当中,我们遇到的最常见的问题是存 ckpt 写满了磁盘(不准笑,从商汤到上海 AI Lab,这个问题在哪儿都日常出现。咱也不知道为啥肯买那么多显卡但不肯多插点儿硬盘,咱也不敢问)。接住所有保存操作,如果你有闲心可以在回调里删一下之前的 ckpt。没闲心的话…大不了重训一次嘛(逃。)第二常见的问题,你猜对了……存 log 写满了硬盘……所以所有 logging 操作也都是要 catch 的。这就是为啥我都用 tmux 然后开很长的缓存窗口,总是能抢救一些 log 出来的。
咳咳,说点儿正经的。任何联网操作都是需要 catch 的,常见的联网操作主要包括从 ceph 读取数据和…写 log 到远程(逃。其他就没啥了吧,我见过有大哥尝试恢复 OOM 的,但效果似乎不是很好,至少我自己没用过。简单来说,唯一不应捕捉的错误是集群炸了。
那有的大兄弟就说了,集群没爆炸,但是有两张卡突然掉了咋办。这个咱第三部分再讨论。
管好模型的输出
模型训着训着发散了几乎是每个训大模型的人都会遇到的问题。输出和 loss 只要有 nan 果断丢掉。梯度先 clip by value 再 clip by norm 都是常规操作。哦对了,还有初始化……关于大模型收敛性的论文有一堆,此处不再赘述。
比更大,还更大,再更大
弹性训练
实际上当你的训练超过 2048 个 GPU 日时,在整个训练过程当中发生单个 GPU 甚至单个节点下线是再正常不过的事情了。
PyTorch 在 1.10 就引入了 torchelastic 弹性训练机制。这个东西,用过的都骂娘。等下,让我先骂一遍。呸。ok 咱们继续吧。
我印象当中在微软的最后一轮面试当中被问到了这个问题:如何设计一个弹性分布式系统。
我的回答很教科书。每 k 分钟,系统会做一次 AllGather 来统计存活进程数,然后选举出一个主进程。主进程会计算好每个进程的 rank 和 local rank 然后广播给各个进程。所有进程每次前向传播开始时向主进程发送一个心跳包来汇报状态。主进程会根据心跳包来确定这一个 step 参与同步的机器有多少。
但很可惜,2024 年了。还是没人去写。他妈的。
层次化梯度同步
我一直认为梯度同步不应该以 GPU/进程为单位。而应该分为大同步(节点间同步)和小同步(节点内同步)。小同步可以更高频的进行,大同步则可以更慢的执行。这样不仅能提高实际的梯度同步频率,降低同步总耗时,并且还能天然的去结合小 batch 和大 batch 训练的优点—节点内小 batch 关注个体,节点间大 batch 关注整体。
有没有发现所有东西都很简单?
是这样的,千卡训练是任何一个普通CS本科生花三个月就能学会的东西。没有任何复杂的地方。
延伸阅读
Understanding the difficulty of training deep feedforward neural networks
高赞回答2:关于千卡训练的难度分析
千卡,其实是个相对模糊的概念,对于多数人而言,这就跟你告诉你,我有1兆资产和10兆资产一样,你只知道很多很多,但是完全傻傻分不清楚,这到底是多少,能买多少东西。千卡,也是一样。按照常见的一机8卡GPU的类型来看,用过125台机器训练的,就算得上是千卡了。从这个角度上说,其实门槛也没有那么那么的高。可事实呢?真正的大模型要用多少机器训练?答案是远超千卡 —— 看看下面的GPT-4信息,这是千卡吗?比万卡还要多!!!
How much compute was used to train GPT-4?
2.15e25 floatingSome key facts about how this enormous model was trained: Used 25,000 Nvidia A100 GPUs simultaneously. Trained continuously for 90–100 days. Total compute required was 2.15e25 floating point operations.Sep 27, 2023
另外,从根本上说,千卡训练是一个复合体。很多时候,大家就知道一件事,“牛逼”,除了知道喊666之外,就少有了解到底牛逼在哪里。以至于说,觉得非常的高大上。我可以这么说一句,千卡及其以上的训练对于绝大多数人和企业而言,这就是个屠龙术 —— 除了某些个,用手指头数的出来的地方,别的地方完全没有这样的需求,也没有这样的资源来进行千卡训练。这是什么意思?意思就是。如果真有这样经验的人,流了出来,大概率很难对口的找工作,因为他在千卡集训中的训练经验和工程实践,大概率根本别的地方用不上。另一层意思是,如果你只是个一般人,那你想想就得了,就跟你可以意淫下某个自己喜欢的明星,但别真去追求,真要去了,你大概是连榜一大哥的待遇都不会有,注定了人财两空。我当然知道有人会说,那难道流出来的人,不能去那几个指头数的出来的地方吗?可以的,但是别着急,你们往后面看就知道了 —— 去还是能去的,但是如果他不是跟着大佬一起跑,到了新地方他们真不见的能继续干。
再来说说,千卡训练是个什么复合体 —— 至少是,科学,工程和人情世故。先看大模型训练中的任务怎么从“量变到质变”的 —— 任何一个小规模训练上的问题,放大几百几千倍之后,都有可能成为不可忽视的问题。比如,数据预处理,小的时候,你也许完全不在意,这到底是多少个毫秒搞定的。但是,如果你现在有上百T的数据要处理,手一抖,写个不那么高效的算法,多处理个几天,甚至几周都有可能。当然,更可怕的就不是慢,而是坏了 —— 一个小bug可以坏了整条pipeline。有的时候,你甚至都不能说是bug,但是反正不爽就是了。比如,两个人写预处理,一个人把图片弄成了BGR,一个弄成了RGB —— 又不是不能用,但是就是膈应人;又比如,数据原图太大了,要统一缩放,然后有人做的时候直接就缩成了方形,然后呢?我们之后需要的模型要正常长宽比的数据又该怎么办呢?再来一次嘛?再搞两个礼拜?你说这是个什么问题?可以看成是科学,当然也可以看成是工程的一部分,这两个就是紧密结合在一起的,单单你会调模型,在这个千卡训练的事情上,你是玩不转的。因为很多问题卡脖子的问题,根本就是,或者大概率是工程问题 —— 什么网络通信,什么磁盘空间,什么读取速度,什么数值稳定,小规模的时候,你都可以不用管,想怎么搞怎么搞,怎么搞可以怎么有。可是上了规模之后,很多东西都被限定死了,根本不是你想怎么干就能怎么干的。我说的这个话,大概很多用pytorch+cuda的朋友也不见的认同,毕竟这套组合下,没有太多技术支持的团队也干成了这样的事情。但是,这背后是因为,使用能支持这样训练的云服务本身就意味着,付了更多的钱,在已经白嫖了nvidia一波的前提下,外加meta(pytorch),外加微软(deepspeed),外加……,又变相雇佣了一个专门的支持团队。但是,这些都不改变一个事实 —— 那就是,这都是你跟着前人的脚步前进,有人替你已经把这条路上的坑,踩的差不多了。可是,如果你要做些原创性的工作呢?必然是会遇到很多前人都不会有的问题。
多说一句,也许有人会说,“我不关心别的,我就只关心pytorch+cuda下,做训练的经验”。那我告诉你,这本质上这跟你单机单卡训练就不应该有什么不一样,跟是不是pytorch,用不用cuda都没什么大关系 —— 你想想最理想情况下,这是不是就应该跟单机单卡训练一样么,无非就是现在的这个“单机”的GPU内存是所有的机器GPU内存的总和,能让你用一个更大的batch size和学习率。至于,GPU内部怎么通信,数据怎么通信,各个机器怎么通信,gradient传播怎么实现,需要你这个训模师知道吗?你在单机单卡的时候都不用知道,在单机多卡的时候不用知道,在小规模分布式训练的时候不用知道,那为什么到了千卡的时候,你就应该知道了?理想情况下,就算到了百万卡,也不用做建模的你去知道这里的各种工程实践。
那千卡训练到底难在哪里了?首先,就是难在之前提及的工程上面了 —— 简单假设一个卡在一天内不挂掉的概率是p,那么现在现在千卡同时一天内不挂掉的概率是多少?算算你就知道,对于p^1000,其实有机器挂掉才是正常的。如果是万卡呢?你可见的是,机器N越多,p^N就越小,这个事情就是越难。有人要说“我单机训练的时候,几年都遇不到问题,老黄的GPU稳定的一塌糊涂。”对此,我也只有呵呵,没人告诉你训练不下去都是GPU的问题。你大概是选择性忘记了各种自己训练中遇到的事情 —— 比如,上次实验中断,GPU进程没杀干净,还占着内存;和人共享的服务器上,有个卧龙觉得你训练的时候CPU占用率低了点,给你加了点任务;好巧不巧,默认的缓存地址没地方了,包装不上了,预训练模型下不来了…… 说这么多看似和训练无关的事情是因为,所有这些都要能自动化,因为里面有一个地方翻车了,你训练就进行不下去了。通信连不上,磁盘满了,遇上了奇葩的GPU,IO巨慢 …… 不管什么原因挂掉了,关键的是之后应该怎么办?有没有可能对这个出问题的机器进行热替换?怎么办才能最大程度不影响训练进程?怎么样才能在下次避免同样的问题。当然,实际情况可以更加复杂,GPU不见的是同批次的,模型也可以大到,哪怕在A100上也只能这个机器放一部分,那个机器放一部分……
但是也别误解,以为千卡训练,就对训模师而言,其实没什么挑战。这样的理解显然是错的。这对训模师的实操来说,肯定是一个巨大的挑战。完全是拿着卖白菜钱(想想你年薪才多少,算你年薪百万好了),操着卖白粉的心(这千卡训练要花多少钱?你年薪都不够它的一个零头)。因为这机器一开,实在是太烧金了。而且可见的是,你必然是要去debug的 —— 为什么小模型的时候,训练的挺好的,一变大就翻车了?或者说,虽然没翻车,但是为什么性能就涨了一丢丢?或者为什么前面训练挺稳定的,到了后面的loss curve就会有很大的spike?有经验的训模师能更早,更快的发现问题。也能更快和更好的解决问题。很多时候,也真不见的看log就能看出来点啥的,看数据,看gradient的大小分布,和其他模型的训练进行记录做比对,甚至做可视化,都是很有必要的。而这所有的一切,都需要你很有经验 —— 同样的log,有人就能一眼看出来问题在哪里,有人就只能对着发呆,或者机械性的说“换一组参数再试一下”。同样觉得可能哪里有问题,有人就能知道应该来验证这个猜想是对是错,有人就只能天马行空的给出一堆,谁也不知道对不对的原因。所以,一旦这条路线被摸索出来之后,其实也就没什么难度了 —— 数据,脚本,机器都在那里了,我就问你,我在服务器上run那条千卡训练命令,跟你run的能有什么不同?所以,真正的关键不是在于有没有用过千卡GPU训练过模型,而是有没有从头至尾,一路披荆斩棘的自己淌出来一条可重复的模型技术路线!!
当然,如果你要以为,这事情就只是技术,那也是太年轻了点。机器一开,要多少钱,这账真要算准从训模师的角度说是很难的,毕竟具体价格都是大公司之间协议的,属于商业机密,但是估算个大概的数目不难。按照aws的p4d算(8卡A100,见下图),便宜的算法,千卡训练一个月,需要花费 $11.57/每台小时*24小时/天*125台*30天 = $1,041,340;按照阿里云的算法,单卡年费¥170533.8,也就是¥19.47每小时,但是算上多卡的费用,这实际上比上面aws的价格更贵。当然,你也许能用更便宜的价格拿到机器,比如别找这么大的云服务平台,找个小的,但是再少还能少多少,算打5折,这都是50多万美刀,350多万人民币一个月。要知道,这可是训练一次的价格哦。一个能用的模型背后,可是5x,甚至10x更多的不能用模型哦,所以烧个几千万,真跟玩一样。
正是因为这么贵,所以也同样表明了,为什么一定要找有经验的训模师 —— 你要知道,你自己的每个实验决定,都是变相的花出去十几,几十甚至上百万的美金。早发现问题,早停下来;早解决问题,早开始;知道怎么偷懒,什么样的ablation study可以跳什么必须做,什么时候可以用小模型替代,什么时候可以用一个老的checkpoint来个jump start,什么时候直接白嫖论文上的结论就行……,所有这些都和花多少钱才能把这个事情办了,输出一个达标的模型,直接相关 。相反的,万一你要找个拉垮的训模师,前面不知道怎么计划,代码不知道怎么验证,训练起来了不懂怎么有效监控,有了异常不知道如何排除,……,最后都要靠着模型训练全完了之后做evaluation才知道行不行的那种。那么就算预算全花完了,什么都没有训练出来,我也没有什么好奇怪的。
铺垫这么多,终于可以来谈谈最后一个层面 —— 人情世故了。你看,千卡训练这个事情,有这么大的风险翻车,要花这么多的预算,那么现在问题来了,你要是部门领导,你让谁来干这个事情?哦,你想放权给下面的经理,让他来找人?又或者找个刚来的博士?找个顶校+顶会的博士?不管你怎么找,可问题是,你就这么信得过他吗?你怎么保证他,能干这个,能干好这个,不会中途跑路,不会磨洋工…… 要知道,这样大的项目和预算,如果要真干塌了,不说整个部门要一起完蛋,至少这一条线的人员必然是要担责的,哪怕是主要领导也跑不掉。所以喽,关键的关键是,你必须找自己信的过的人,还要找确实有能力可以担当重任的人 —— 真正最后来干这个千卡训练的人,不但自己技术要过硬,更是团队的中坚力量,至少也要得到一两个大头目的支持,而且还要得到小头目支持。你再牛逼,没信任没大佬支持,这事情不说完全不可能,也是基本没可能。你再牛逼,要是真的小头目给你上眼药,比如,跟上面吹风,“好像看见你在看招聘网站”,你想大头目心里会不会有阴影?所以,别给我扯什么,老子有多少顶会顶刊,老子导师是谁谁谁,这在绝大多数情况,都不好使。所以,刚毕业的,或者做实习的,或者刚工作的,如果宣称自己有这个经验,就是一眼丁真。因为上面是绝对不会找不信任的人来这样重要的工作,这跟你有没有相关的工作经验无关。这同样意味着,真正干这些事情的人也很难流出来 —— 因为对于嫡系来说,加薪升职,在干好了的前提下,那还不都是so easy吗?所以,是你,你愿意出来吗?出来了,就算你牛逼,但是获取信任,成为嫡系也要一个时间,不是吗?