
1、2D卷积
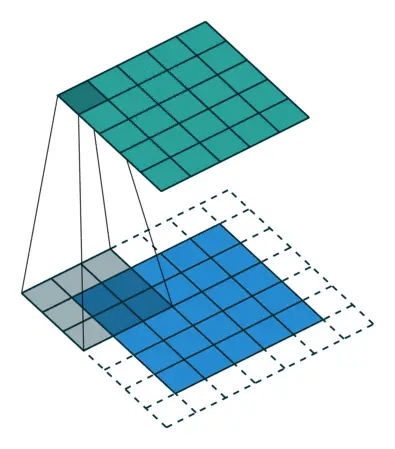
2、3D卷积
3D卷积相比2D卷积来说,多了一个(时间)维度。卷积核和map都是3维的。三维卷积常用于医学领域(CT影响),视频处理领域(检测动作及人物行为)
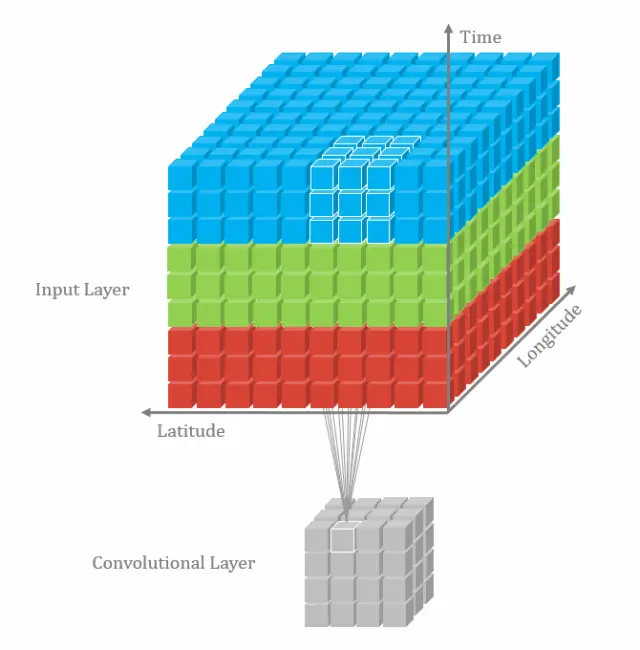
1、2D卷积
2、3D卷积
3D卷积相比2D卷积来说,多了一个(时间)维度。卷积核和map都是3维的。三维卷积常用于医学领域(CT影响),视频处理领域(检测动作及人物行为)
Depthwise(DW)卷积与Pointwise(PW)卷积,合起来被称作Depthwise Separable Convolution(参见Google的Xception),该结构和常规卷积操作类似,可用来提取特征,但相比于常规卷积操作,其参数量和运算成本较低。所以在一些轻量级网络中会碰到这种结构如MobileNet。
摘自:https://zhuanlan.zhihu.com/p/80041030
对于一张5×5像素、三通道彩色输入图片(shape为5×5×3)。经过3×3卷积核的卷积层(假设输出通道数为4,则卷积核shape为3×3×3×4),最终输出4个Feature Map,如果有same padding则尺寸与输入层相同(5×5),如果没有则为尺寸变为3×3。

此时,卷积层共4个Filter,每个Filter包含了3个Kernel,每个Kernel的大小为3×3。因此卷积层的参数数量可以用如下公式来计算:
N_std = 4 × 3 × 3 × 3 = 108
Depthwise Separable Convolution是将一个完整的卷积运算分解为两步进行,即Depthwise Convolution与Pointwise Convolution。
Depthwise Convolution is a type of convolution where we apply a single convolutional filter for each input channel. In the regular 2D convolution performed over multiple input channels, the filter is as deep as the input and lets us freely mix channels to generate each element in the output. In contrast, depthwise convolutions keep each channel separate. To summarize the steps, we:
同于常规卷积操作,Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积。上面所提到的常规卷积每个卷积核是同时操作输入图片的每个通道。
同样是对于一张5×5像素、三通道彩色输入图片(shape为5×5×3),Depthwise Convolution首先经过第一次卷积运算,不同于上面的常规卷积,DW完全是在二维平面内进行。卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。所以一个三通道的图像经过运算后生成了3个Feature map(如果有same padding则尺寸与输入层相同为5×5),如下图所示。
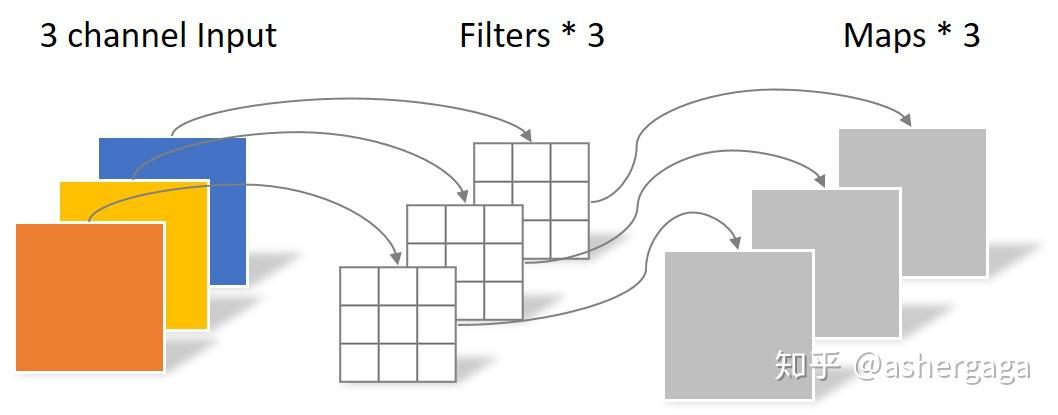
其中一个Filter只包含一个大小为3×3的Kernel,卷积部分的参数个数计算如下:
N_depthwise = 3 × 3 × 3 = 27
Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。如下图所示。
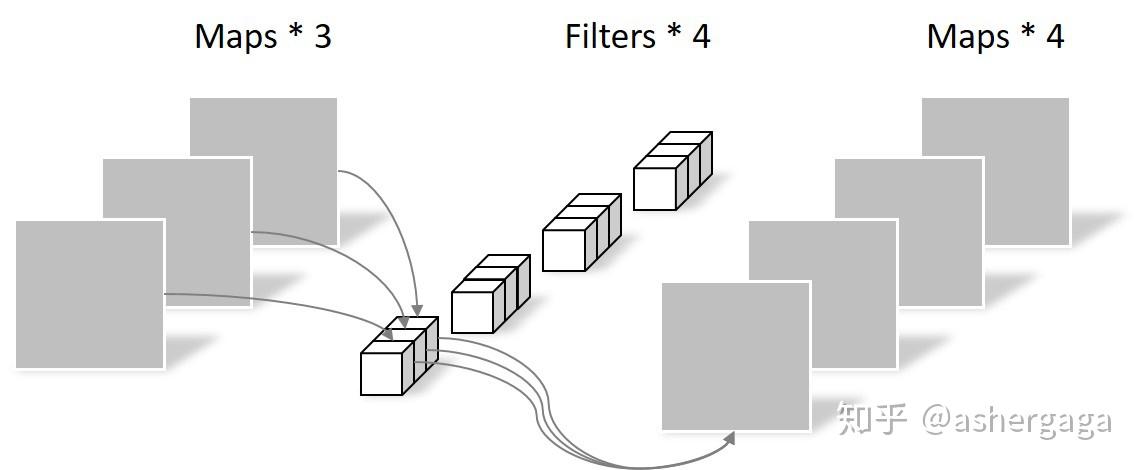
由于采用的是1×1卷积的方式,此步中卷积涉及到的参数个数可以计算为:
N_pointwise = 1 × 1 × 3 × 4 = 12
经过Pointwise Convolution之后,同样输出了4张Feature map,与常规卷积的输出维度相同。
回顾一下,常规卷积的参数个数为:
N_std = 4 × 3 × 3 × 3 = 108
Separable Convolution的参数由两部分相加得到:
N_depthwise = 3 × 3 × 3 = 27
N_pointwise = 1 × 1 × 3 × 4 = 12
N_separable = N_depthwise + N_pointwise = 39
相同的输入,同样是得到4张Feature map,Separable Convolution的参数个数是常规卷积的约1/3。因此,在参数量相同的前提下,采用Separable Convolution的神经网络层数可以做的更深。
数据集下载地址:http://m6z.cn/5MjlYkAI-TOD 在 28,036 张航拍图像中包含 8 个类别的 700,621 个对象实例。与现有航拍图像中的目标检测数据集相比,AI-TOD 中目标的平均大小约为 12.8 像素,远小于其他数据集。

数据集下载地址:http://m6z.cn/6nUrYe现有的 Earth Vision 数据集要么适用于语义分割,要么适用于对象检测。iSAID 是第一个用于航空图像实例分割的基准数据集。这个大规模和密集注释的数据集包含 2,806 张高分辨率图像的 15 个类别的 655,451 个对象实例。iSAID 的显着特征如下:(a) 大量具有高空间分辨率的图像,(b) 十五个重要且常见的类别,(c) 每个类别的大量实例,(d) 每个类别的大量标记实例图像,这可能有助于学习上下文信息,(e) 巨大的对象尺度变化,通常在同一图像内包含小、中和大对象,(f) 图像内具有不同方向的对象的不平衡和不均匀分布,描绘真实-生活空中条件,(g)几个小尺寸物体,外观模糊,只能通过上下文推理来解决,(h)由专业注释者执行的精确实例级注释,由符合良好规范的专家注释者交叉检查和验证定义的指导方针。

数据集下载地址:http://m6z.cn/6vqF3T在 TinyPerson 中有 1610 个标记图像和 759 个未标记图像(两者主要来自同一视频集),总共有 72651 个注释。

数据集下载地址:http://m6z.cn/5xgYdYDeepScores 数据集的目标是推进小物体识别的最新技术,并将物体识别问题置于场景理解的背景下。DeepScores 包含高质量的乐谱图像,分为 300 0 000 张书面音乐,其中包含不同形状和大小的符号。拥有近一亿个小对象,这使得我们的数据集不仅独一无二,而且是最大的公共数据集。DeepScores 带有用于对象分类、检测和语义分割的基本事实。因此,DeepScores 总体上对计算机视觉提出了相关挑战,超出了光学音乐识别 (OMR) 研究的范围。

数据集下载地址:http://m6z.cn/6nUs1CWiderPerson 数据集是野外行人检测基准数据集,其图像选自广泛的场景,不再局限于交通场景。我们选择了 13,382 张图像并标记了大约 400K 带有各种遮挡的注释。我们随机选择 8000/1000/4382 图像作为训练、验证和测试子集。与 CityPersons 和 WIDER FACE 数据集类似,我们不发布测试图像的边界框基本事实。用户需要提交最终的预测文件,我们将进行评估。

数据集下载地址:http://m6z.cn/5N3Yk7加州理工学院行人数据集由大约 10 小时的 640×480 30Hz 视频组成,该视频取自在城市环境中通过常规交通行驶的车辆。注释了大约 250,000 帧(在 137 个大约分钟长的片段中),总共 350,000 个边界框和 2300 个独特的行人。注释包括边界框和详细的遮挡标签之间的时间对应关系。

数据集下载地址:http://m6z.cn/5UAbEWNWPU VHR-10 Dataset 是一个用于空间物体检测的 10 级地理遥感数据集,其拥有 650 张包含目标的图像和 150 张背景图像,共计 800 张,目标种类包括飞机、舰船、油罐、棒球场、网球场、篮球场、田径场、港口、桥梁和汽车共计 10 个类别。该数据集由西北工业大学于 2014 年发布,相关论文有《Multi-class geospatial object detection and geographic imageclassification based on collection of part detectors》、《A survey on objectdetection in optical remote sensing images》和《Learningrotation-invariant convolutional neural networks for object detection in VHRoptical remote sensing images》。

数据集下载地址:http://m6z.cn/6nUs6sInria 航空影像标注解决了遥感中的一个核心主题:航空影像的自动像素级标注(论文链接)。数据集特点:

数据集下载地址:http://m6z.cn/5EN96H它是一个开放的遥感图像目标检测数据集。数据集包括飞机、油箱、游乐场和立交桥。此数据集的格式为PASCAL VOC。数据集包括4个文件,每个文件用于一种对象。
数据集下载地址:http://m6z.cn/616t6R从Internet(例如YouTube或Google)上的图像/视频收集的四个小物体数据集,包括4种类型的图像,可用于小物体目标检测的研究。数据集包含四类:

COCO2017是2017年发布的COCO数据集的一个版本,主要用于COCO在2017年后持有的物体检测任务、关键点检测任务和全景分割任务。

数据集链接:http://m6z.cn/6fzn0f该数据集由早期火灾和烟雾的图像数据集组成。数据集由在真实场景中使用手机拍摄的早期火灾和烟雾图像组成。大约有7000张图像数据。图像是在各种照明条件(室内和室外场景)、天气等条件下拍摄的。该数据集非常适合早期火灾和烟雾探测。数据集可用于火灾和烟雾识别、检测、早期火灾和烟雾、异常检测等。数据集还包括典型的家庭场景,如垃圾焚烧、纸塑焚烧、田间作物焚烧、家庭烹饪等。本文仅含100张左右。
数据集链接:http://m6z.cn/6vIKlJDOTA是用于航空图像中目标检测的大型数据集。它可以用于开发和评估航空图像中的目标探测器。这些图像是从不同的传感器和平台收集的。每个图像的大小在800×800到20000×20000像素之间,包含显示各种比例、方向和形状的对象。DOTA图像中的实例由航空图像解释专家通过任意(8 d.o.f.)四边形进行注释。
数据集链接:http://m6z.cn/5DdJL1该数据库由七个不同织物结构的245张4096 x 256像素图像组成。数据库中有140个无缺陷图像,每种类型的织物20个,除此之外,有105幅纺织行业中常见的不同类型的织物缺陷(12种缺陷)图像。图像的大尺寸允许用户使用不同的窗口尺寸,从而增加了样本数量。

数据集链接:http://m6z.cn/5wnucm该数据集采集的目标为工业应用、纹理很少的目标,同时缺乏区别性的颜色,且目标具有对称性和互相关性,数据集由三个同步的传感器获得,一个结构光传感器,一个RGBD sensor,一个高分辨率RGBsensor,从每个传感器分别获得了3.9w训练集和1w测试集,此外为每个目标创建了2个3D model,一个是CAD手工制作的另一个是半自动重建的。训练集图片的背景大多是黑色的,而测试集的图片背景很多变,会包含不同光照、遮挡等等变换(之所以这么做作者说是为了使任务更具有挑战性)。同时作者解释了本数据集的优势在于:1.大量跟工业相关的目标;2.训练集都是在可控的环境下抓取的;3.测试集有大量变换的视角;4.图片是由同步和校准的sensor抓取的;5.准确的6D pose标签;6.每个目标有两种3D模型;

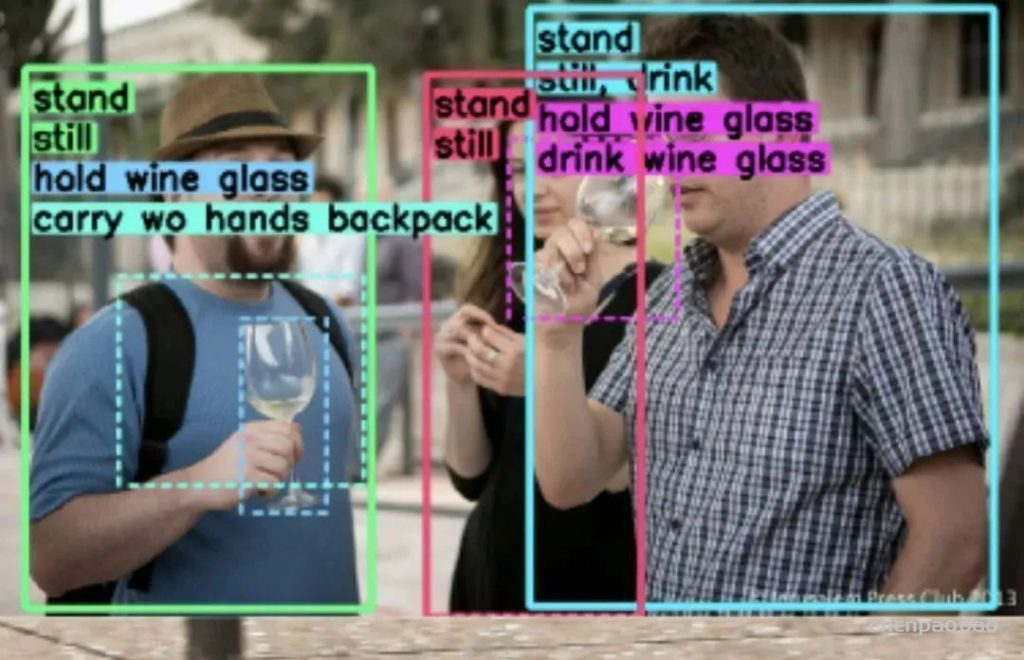
数据集链接:http://m6z.cn/6fzmQfH²O由V-COCO数据集中的10301张图像组成,其中添加了3635张图像,这些图像主要包含人与人之间的互动。所有的H²O图像都用一种新的动词分类法进行了注释,包括人与物和人与人之间的互动。该分类法由51个动词组成,分为5类:
数据集链接:http://m6z.cn/5ZMmRG图像中的垃圾(GINI)数据集是SpotGarbage引入的一个数据集,包含2561张图像,956张图像包含垃圾,其余的是在各种视觉属性方面与垃圾非常相似的非垃圾图像。

数据集链接:http://m6z.cn/5KJWJANAO包含7934张图像和9943个对象,这些图像未经修改,代表了真实世界的场景,但会导致最先进的检测模型以高置信度错误分类。与标准MSCOCO验证集相比,在NAO上评估时,EfficientDet-D7的平均精度(mAP)下降了74.5%。

数据集链接:http://m6z.cn/5Sg9NXLabelme Dataset 是用于目标识别的图像数据集,涵盖 1000 多个完全注释和 2000 个部分注释的图像,其中部分注释图像可以被用于训练标记算法 ,测试集拥有来自于世界不同地方拍摄的图像,这可以保证图片在续联和测试之间会有较大的差异。该数据集由麻省理工学院 –计算机科学和人工智能实验室于 2007 年发布,相关论文有《LabelMe: a database and web-based tool for image annotation》。

数据集链接:http://m6z.cn/6uxAIx该数据集包括小众印度车辆的图像,如Autorikshaw、Tempo、卡车等。该数据集由用于分类和目标检测的小众印度车辆图像组成。据观察,这些小众车辆(如autorickshaw、tempo、trucks等)上几乎没有可用的数据集。这些图像是在白天、晚上和晚上的不同天气条件下拍摄的。该数据集具有各种各样的照明、距离、视点等变化。该数据集代表了一组非常具有挑战性的利基类车辆图像。该数据集可用于驾驶员辅助系统、自动驾驶等的图像识别和目标检测。

数据集链接:http://m6z.cn/5DdK0v椅子数据集包含大约1000个不同三维椅子模型的渲染图像。

数据集链接:http://m6z.cn/60wX8rSUN09数据集包含12000个带注释的图像,其中包含200多个对象类别。它由自然、室内和室外图像组成。每个图像平均包含7个不同的注释对象,每个对象的平均占用率为图像大小的5%。对象类别的频率遵循幂律分布。发布者使用 397 个采样良好的类别进行场景识别,并以此搭配最先进的算法建立新的性能界限。该数据集由普林斯顿视觉与机器人实验室于 2014 年发布,相关论文有《SUN Database: Large-scale Scene Recognition from Abbey to Zoo》、《SUN Database: Exploring a Large Collection of Scene Categories》。
数据集链接:http://m6z.cn/5wnuoM使用迄今为止公开共享的全球最大的开放检索信息数据集。Unsplash数据集由250000多名贡献摄影师创建,并包含了数十亿次照片搜索的信息和对应的照片信息。由于Unsplash数据集中包含广泛的意图和语义,它为研究和学习提供了新的机会。

数据集链接:http://m6z.cn/5DdK6DHICO-DET是一个用于检测图像中人-物交互(HOI)的数据集。它包含47776幅图像(列车组38118幅,测试组9658幅),600个HOI类别,由80个宾语类别和117个动词类别构成。HICO-DET提供了超过150k个带注释的人类对象对。V-COCO提供了10346张图像(2533张用于培训,2867张用于验证,4946张用于测试)和16199人的实例。

数据集链接:http://m6z.cn/5Sgafn上海科技数据集是一个大规模的人群统计数据集。它由1198张带注释的群组图像组成。数据集分为两部分,A部分包含482张图像,B部分包含716张图像。A部分分为训练和测试子集,分别由300和182张图像组成。B部分分为400和316张图像组成的序列和测试子集。群组图像中的每个人都有一个靠近头部中心的点进行注释。总的来说,该数据集由33065名带注释的人组成。A部分的图像是从互联网上收集的,而B部分的图像是在上海繁忙的街道上收集的。

数据集链接:http://m6z.cn/6n5Adu大约9000多张独特的图片。该数据集由印度国内常见垃圾对象的图像组成。图像是在各种照明条件、天气、室内和室外条件下拍摄的。该数据集可用于制作垃圾/垃圾检测模型、环保替代建议、碳足迹生成等。

数据集下载地址:http://m6z.cn/61z9Fv当前大多数高级人脸识别方法都是基于深度学习而设计的,深度学习取决于大量人脸样本。但是,目前尚没有公开可用的口罩遮挡人脸识别数据集。为此,这项工作提出了三种类型的口罩遮挡人脸数据集,包括口罩遮挡人脸检测数据集(MFDD),真实口罩遮挡人脸识别数据集(RMFRD)和模拟口罩遮挡人脸识别数据集(SMFRD)。基于这些数据集,可以开发口罩遮挡人脸的各种应用。本项目开发的多粒度口罩遮挡人脸识别模型可达到95%的准确性,超过了行业报告的结果。

数据集下载地址:http://m6z.cn/5wJJLA德国交通标志基准测试是在 2011 年国际神经网络联合会议 (IJCNN) 上举办的多类单图像分类挑战赛。我们诚邀相关领域的研究人员参与:该比赛旨在参与者无需特殊领域知识。我们的基准测试具有以下属性:

数据集下载地址:http://m6z.cn/5U2X4u该数据集中含有自行车、摩托车、汽车、货车的图像数据,可用于CNN模型以实现车辆识别和车辆分类,其中自行车、摩托车、汽车数据来自2005 PASCAL视觉类挑战赛(VOC2005)所使用的数据的筛选处理结果,货车图片来自网络收集,后期通过筛选处理得到。在本数据中,训练数据集与测试数据集占比约为5:1。

数据集下载地址:http://m6z.cn/5TikF9WGISD(Wine Grape Instance Segmentation Dataset)是为了提供图像和注释来研究对象检测和实例分割,用于葡萄栽培中基于图像的监测和现场机器人技术。它提供了来自五种不同葡萄品种的实地实例。这些实例显示了葡萄姿势、光照和焦点的变化,包括遗传和物候变化,如形状、颜色和紧实度。可能的用途包括放宽实例分割问题:分类(图像中是否有葡萄?)、语义分割(图像中的“葡萄像素”是什么?)、对象检测(图像中的葡萄在哪里?)、和计数(每个簇有多少浆果?)。
数据集下载地址:http://m6z.cn/5wJK64检测小麦穗是一项重要任务,可以估计相关性状,包括穗种群密度和穗特征,如卫生状况、大小、成熟阶段和芒的存在。本数据集包含 4,700 张高分辨率 RGB 图像和 190,000 个标记的小麦头,这些小麦头采集自世界各地不同生长阶段的不同基因型的多个国家。

数据集下载地址:http://m6z.cn/68ldS0通过记录超过 350 公里的瑞典高速公路和城市道路的序列,创建了一个数据集。一个 1.3 兆像素的彩色摄像机,一个点灰色变色龙,被放置在一辆汽车的仪表板上,从前窗向外看。摄像头略微指向右侧,以便尽可能多地覆盖相关标志。该镜头的焦距为 6.5 毫米,视野约为 41 度。高速公路上的典型速度标志大约为 90 cm 宽,如果要在大约 30 m 的距离处检测到它们,则对应于大约 50 像素的大小。总共记录了超过 20 000 帧,其中每五帧被手动标记。每个标志的标签包含标志类型(人行横道、指定车道右侧、禁止站立或停车、优先道路、让路、50 公里/小时或 30 公里/小时)、能见度状态(遮挡、模糊或可见)和道路状态(是否标志是在正在行驶的道路上或在小路上)。
数据集下载地址:http://m6z.cn/61zarT包含 774 个众包图像和 698 个网络挖掘图像。众包和网络挖掘的图像分别包含 2,496 和 2,230 个工人实例。

数据集链接:https://beerys.github.io/CaltechCameraTraps/该数据集包含来自美国西南部 140 个摄像头位置的 243,100 张图像,带有 21 个动物类别的标签(加上空白),主要是在物种级别(例如,最常见的标签是负鼠、浣熊和土狼),以及 大约 66,000 个边界框注释。大约 70% 的图像被标记为空。
数据集下载地址:http://m6z.cn/6nnDQK该数据来自 J-EDI 海洋垃圾数据集。构成该数据集的视频在质量、深度、场景中的对象和使用的相机方面差异很大。它们包含许多不同类型的海洋垃圾的图像,这些图像是从现实世界环境中捕获的,提供了处于不同衰减、遮挡和过度生长状态的各种物体。此外,水的清晰度和光的质量因视频而异。这些视频经过处理以提取 5,700 张图像,这些图像构成了该数据集,所有图像都在垃圾实例、植物和动物等生物对象以及 ROV 上标有边界框。

数据集下载地址:http://m6z.cn/5wJJTa本数据集汇总了700个在坑洼处带有3K +注释的图像,用于从道路图像中检测坑洼,检测道路地形和坑洼。
数据集下载地址:http://m6z.cn/61EksR大赛数据集里有1万份来自实际生产中有瑕疵的铝型材监测影像数据,每个影像包含一个或多种瑕疵。供机器学习的样图会明确标识影像中所包含的瑕疵类型。

数据集下载地址:http://m6z.cn/61Ekw5在布匹的实际生产过程中,由于各方面因素的影响,会产生污渍、破洞、毛粒等瑕疵,为保证产品质量,需要对布匹进行瑕疵检测。布匹疵点检验是纺织行业生产和质量管理的重要环节,目前人工检测易受主观因素影响,缺乏一致性;并且检测人员在强光下长时间工作对视力影响极大。由于布匹疵点种类繁多、形态变化多样、观察识别难道大,导致布匹疵点智能检测是困扰行业多年的技术瓶颈。本数据涵盖了纺织业中布匹的各类重要瑕疵,每张图片含一个或多种瑕疵。数据包括包括素色布和花色布两类,其中,素色布数据约8000张;花色布数据约12000张。
数据集下载地址:http://m6z.cn/5U87us数据集收集了夹杂、划痕、压入氧化皮、裂纹、麻点和斑块6种缺陷,每种缺陷300张,图像尺寸为200×200。数据集包括分类和目标检测两部分,不过目标检测的标注中有少量错误,需要注意。

数据集下载地址:http://m6z.cn/61EkBp该数据集中提供了四种类型的带钢表面缺陷。训练集共有12568张,测试集5506张。图像尺寸为1600×256。
数据集下载地址:http://m6z.cn/61EkUh该数据集包含了7种带钢缺陷类型。这个数据集不是图像数据,而是带钢缺陷的28种特征数据,可用于机器学习项目。钢板故障的7种类型:装饰、Z_划痕、K_划痕、污渍、肮脏、颠簸、其他故障。
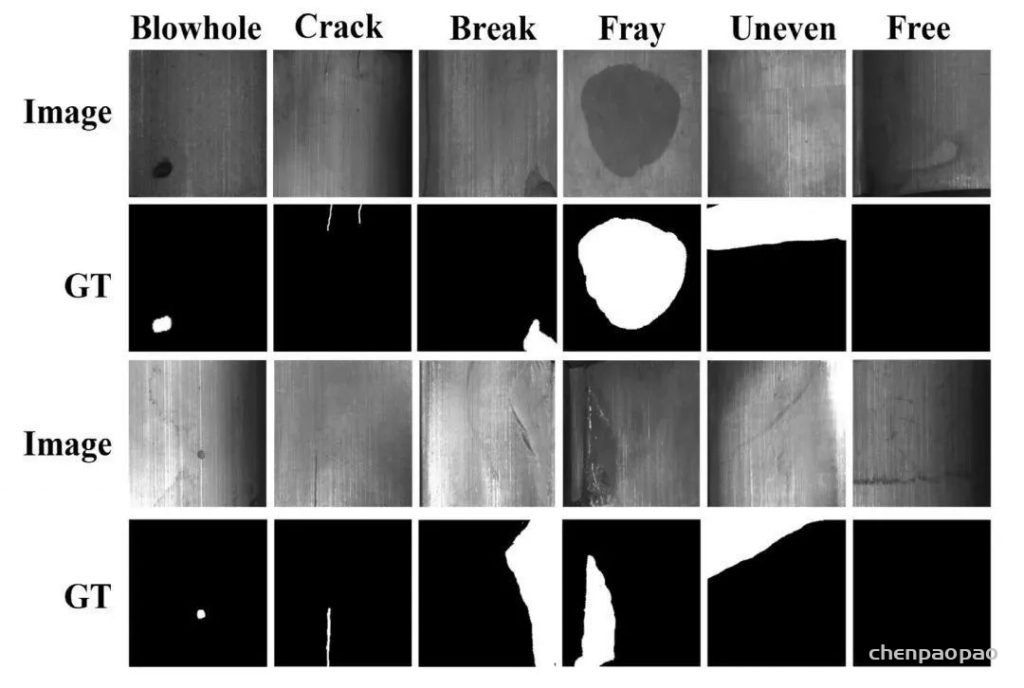
数据集下载地址:http://m6z.cn/5F5eQV该数据集主要针对纹理背景上的杂项缺陷,为较弱监督的训练数据。包含十个数据集,前六个为训练数据集,后四个为测试数据集。每个数据集均包含以灰度8位PNG格式保存的1000个“无缺陷”图像和150个“有缺陷”图像,每个数据集由不同的纹理模型和缺陷模型生成。“无缺陷”图像显示的背景纹理没有缺陷,“无缺陷”图像的背景纹理上恰好有一个标记的缺陷。所有数据集已随机分为大小相等的训练和测试子数据集。弱标签以椭圆形表示,大致表示缺陷区域。
数据集下载地址:http://m6z.cn/5F5eSd中国科学院自动所一个课题组收集的数据集,是“Saliency of magnetic tile surface defects”这篇论文的数据集。收集了6种常见磁瓦缺陷的图像,并做了语义分割的标注。
数据集下载地址:http://m6z.cn/61EkKLRSDDs数据集包含两种类型的数据集:第一种是从快车道捕获的I型RSDDs数据集,其中包含67个具有挑战性的图像。第二个是从普通/重型运输轨道捕获的II型RSDDs数据集,其中包含128个具有挑战性的图像。两个数据集的每幅图像至少包含一个缺陷,并且背景复杂且噪声很大。RSDDs数据集中的这些缺陷已由一些专业的人类观察员在轨道表面检查领域进行了标记。
数据集下载地址:http://m6z.cn/61EkMHKTH-TIPS 是一个纹理图像数据集,在不同的光照、角度和尺度下拍摄的不同材质表面纹理图片。类型包括砂纸、铝箔、发泡胶、海绵、灯芯绒、亚麻、棉、黑面包、橙皮和饼干共10类。

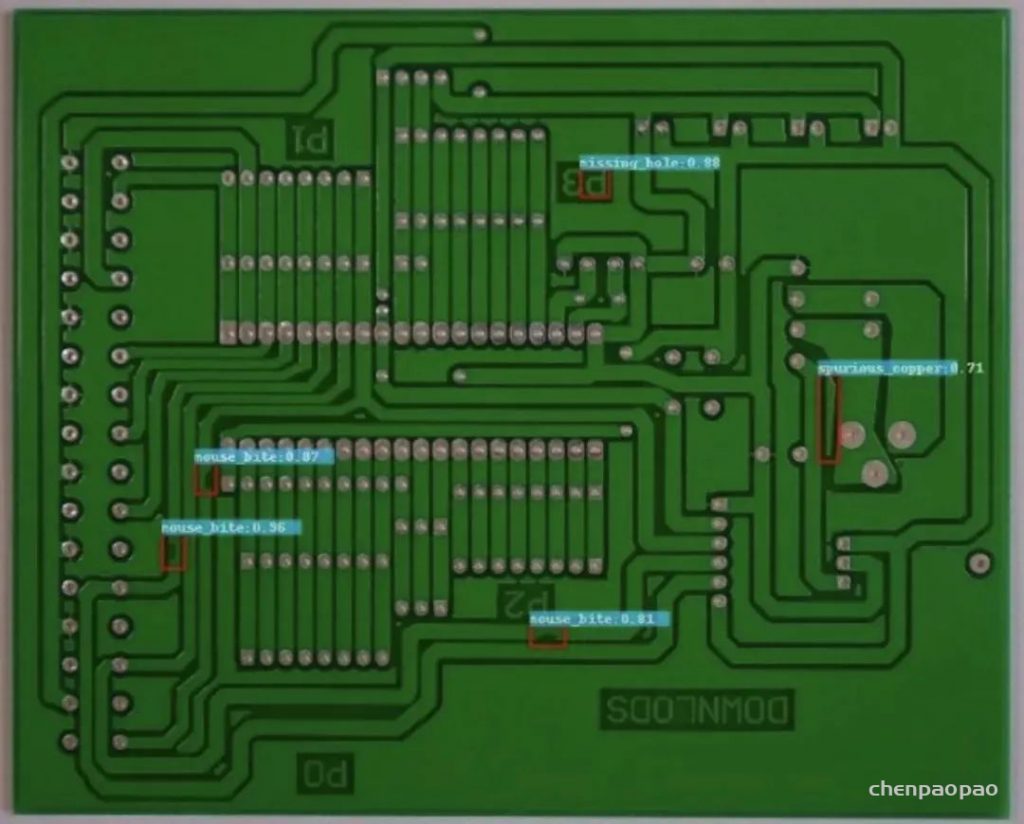
数据集下载地址:http://m6z.cn/5U87Ji这是一个公共的合成PCB数据集,由北京大学发布,其中包含1386张图像以及6种缺陷(缺失孔,鼠咬坏,开路,短路,杂散,伪铜),用于检测,分类和配准任务。
数据集下载地址:http://m6z.cn/6gGnTdIMDB-WIKI 500k+ 是一个包含名人人脸图像、年龄、性别的数据集,图像和年龄、性别信息从 IMDB 和 WiKi 网站抓取,总计 524230 张名人人脸图像及对应的年龄和性别。其中,获取自 IMDB 的 460723 张,获取自 WiKi 的 62328 张。

数据集下载地址:http://m6z.cn/5Nm7gpWIDER FACE数据集是人脸检测的一个benchmark数据集,包含32203图像,以及393,703个标注人脸,其中,158,989个标注人脸位于训练集,39,,496个位于验证集。每一个子集都包含3个级别的检测难度:Easy,Medium,Hard。这些人脸在尺度,姿态,光照、表情、遮挡方面都有很大的变化范围。WIDER FACE选择的图像主要来源于公开数据集WIDER。制作者来自于香港中文大学,他们选择了WIDER的61个事件类别,对于每个类别,随机选择40%10%50%作为训练、验证、测试集。
数据集下载地址:http://m6z.cn/61EnzL该数据集是用于研究无约束面部识别问题的面部照片数据库。数据集包含从网络收集的13000多张图像。每张脸都贴上了所画的人的名字,图片中的1680人在数据集中有两个或更多不同的照片。

数据集下载地址:http://m6z.cn/5F5hLpGENKI数据集是由加利福尼亚大学的机器概念实验室收集。该数据集包含GENKI-R2009a,GENKI-4K,GENKI-SZSL三个部分。GENKI-R2009a包含11159个图像,GENKI-4K包含4000个图像,分为“笑”和“不笑”两种,每个图片的人脸的尺度大小,姿势,光照变化,头的转动等都不一样,专门用于做笑脸识别。GENKI-SZSL包含3500个图像,这些图像包括广泛的背景,光照条件,地理位置,个人身份和种族等。
数据集链接:http://m6z.cn/5DlIR9PubFig Dataset 是一个大型人脸数据集,主要用于人脸识别和身份鉴定,其涵盖互联网上 200 人的 58,797 张图像,不同于大多数现有面部数据集,这些图像是在主体完全不受控制的情况下拍摄的,因此不同图像中姿势、光照、表情、场景、相机、成像条件和参数存在较大差异,该数据集类似于 UMass-Amherst 创建的 LFW 数据集。该数据集由哥伦比亚大学于 2009 年发布,相关论文有《Attribute and Simile Classifiers for Face Verification》。

数据集链接:http://m6z.cn/60EW0nCelebFaces Attributes Dataset (CelebA) 是一个大规模的人脸属性数据集,包含超过 20 万张名人图像,每张都有 40 个属性注释。该数据集中的图像涵盖了较大的姿势变化和杂乱的背景。CelebA 种类多、数量多、注释丰富,包括10,177 个身份,202,599 张人脸图像,以及5 个地标位置,每张图像 40 个二进制属性注释。该数据集可用作以下计算机视觉任务的训练和测试集:人脸属性识别、人脸识别、人脸检测、地标(或人脸部分)定位以及人脸编辑与合成。
数据集链接:http://m6z.cn/5So6DB为促进人脸识别算法的研究和实用化,美国国防部的Counterdrug Technology Transfer Program(CTTP)发起了一个人脸识别技术(Face Recognition Technology 简称FERET)工程,它包括了一个通用人脸库以及通用测试标准。到1997年,它已经包含了1000多人的10000多张照片,每个人包括了不同表情,光照,姿态和年龄的照片。
数据集链接:http://m6z.cn/6fHmaT该数据集包含 12,995 张人脸图像,这些图像用 (1) 五个面部标志,(2) 性别、微笑、戴眼镜和头部姿势的属性进行了注释。

数据集链接:http://m6z.cn/5ZUjyC这个数据集包含了1521幅分辨率为384×286像素的灰度图像。每一幅图像来自于23个不同的测试人员的正面角度的人脸。为了便于做比较,这个数据集也包含了对人脸图像对应的手工标注的人眼位置文件。图像以 “BioID_xxxx.pgm”的格式命名,其中xxxx代表当前图像的索引(从0开始)。类似的,形如”BioID_xxxx.eye”的文件包含了对应图像中眼睛的位置。

数据集链接:http://m6z.cn/5So6vR该数据集所选用的人脸照片均来自于两部比较知名的电视剧,《吸血鬼猎人巴菲》和《生活大爆炸》。
数据集链接:http://m6z.cn/5vPwfOCMU PIE人脸库建立于2000年11月,它包括来自68个人的40000张照片,其中包括了每个人的13种姿态条件,43种光照条件和4种表情下的照片,现有的多姿态人脸识别的文献基本上都是在CMU PIE人脸库上测试的。

数据集链接:http://m6z.cn/6u3P2V该数据集包含 1,595 个不同人的 3,425 个视频。所有视频都是从 YouTube 下载的。每个主题平均有 2.15 个视频可用。最短剪辑时长为 48 帧,最长剪辑为 6070 帧,视频剪辑的平均长度为 181.3 帧。在这个数据集下,算法需要判断两段视频里面是不是同一个人。有不少在照片上有效的方法,在视频上未必有效/高效。

数据集链接:http://m6z.cn/5vPwioCASIA 人脸图像数据库版本 5.0(或 CASIA-FaceV5)包含 500 个对象的 2,500 个彩色人脸图像。CASIA-FaceV5 的面部图像是使用罗技 USB 摄像头在一个会话中捕获的。CASIA-FaceV5的志愿者包括研究生、工人、服务员等。所有人脸图像均为16位彩色BMP文件,图像分辨率为640*480。典型的类内变化包括照明、姿势、表情、眼镜、成像距离等。

数据集链接:http://m6z.cn/5So6VP该数据集包含通过在谷歌图片搜索中输入常见的名字从网络上收集的人的图像。每个正面的眼睛、鼻子和嘴巴中心的坐标在地面实况文件中提供。此信息可用于对齐和裁剪人脸或作为人脸检测算法的基本事实。该数据集有 10,524 个不同分辨率和不同设置的人脸,例如 肖像图像、人群等。侧面或非常低分辨率的面孔未标记。

数据集链接:http://m6z.cn/69aaIeMPII Human Shape 人体模型数据是一系列人体轮廓和形状的3D模型及工具。模型是从平面扫描数据库 CAESAR 学习得到。

数据集链接:http://m6z.cn/6gGnPbMPII 人体姿态数据集是用于评估人体关节姿势估计的最先进基准。该数据集包括大约 25,000 张图像,其中包含超过 40,000 个带有注释身体关节的人。这些图像是使用已建立的人类日常活动分类法系统收集的。总的来说,数据集涵盖了 410 项人类活动,每个图像都提供了一个活动标签。每张图像都是从 YouTube 视频中提取的,并提供前后未注释的帧。此外,测试集有更丰富的注释,包括身体部位遮挡和 3D 躯干和头部方向。

数据集链接:http://m6z.cn/692agI作者收集了一个带有注释关节的足球运动员数据集,可用于多视图重建。数据集包括:

数据集链接:http://m6z.cn/692akKPenn Action Dataset(宾夕法尼亚大学)包含 15 个不同动作的 2326 个视频序列以及每个序列的人类联合注释。

数据集链接:http://m6z.cn/5xr6XqBBC Pose 包含 20 个视频(每个视频长度为 0.5 小时至 1.5 小时),由 BBC 录制,并配有手语翻译。这 20 个视频分为 10 个用于训练的视频、5 个用于验证的视频和 5 个用于测试的视频。

数据集链接:http://m6z.cn/6gynqzPoser 数据集是用于姿态估计的数据集,由 1927 个训练图像和 418 个测试图像组成。这些图像是综合生成的,并调整为单峰预测。这些图像是使用 Poser 软件包生成的。
数据集链接:http://m6z.cn/5xr6Z2“野外 3D 姿势数据集”是野外第一个具有准确 3D 姿势用于评估的数据集。虽然存在户外其他数据集,但它们都仅限于较小的记录量。3DPW 是第一个包含从移动电话摄像头拍摄的视频片段的技术。数据集包括:

数据集链接:http://m6z.cn/5UGaiiV-COCO是一个基于 COCO 的数据集,用于人机交互检测。V-COCO 提供 10,346 张图像(2,533 张用于训练,2,867 张用于验证,4,946 张用于测试)和 16,199 个人物实例。每个人都有 29 个动作类别的注释,并且没有包括对象在内的交互标签。

数据集链接:http://m6z.cn/692aos宜家 ASM 数据集是装配任务的多模式和多视图视频数据集,可对人类活动进行丰富的分析和理解。它包含 371 个家具组件样本及其真实注释。每个样本包括 3 个 RGB 视图、一个深度流、原子动作、人体姿势、对象片段、对象跟踪和外部相机校准。

数据集链接:http://m6z.cn/62cnp5这是一个立体图像对数据集,适用于上身人的立体人体姿态估计。SHPED 由 630 个立体图像对(即 1260 个图像)组成,分为 42 个视频片段,每个片段 15 帧。这些剪辑是从 26 个立体视频中提取的,这些视频是从 YouTube 获得的,标签为 yt3d:enable = true。此外,SHPED 包含 1470 条火柴人上身注释,对应于 49 个人根据这些条件:直立位置、所有上身部分几乎可见以及身体的非侧面视点。

数据集链接:http://m6z.cn/5xr6M8AIST++ 舞蹈动作数据集是从 AIST 舞蹈视频数据库构建的。对于多视图视频,设计了一个精心设计的管道来估计相机参数、3D 人体关键点和 3D 人体舞蹈动作序列:它为 1010 万张图像提供 3D 人体关键点注释和相机参数,涵盖 9 个视图中的 30 个不同主题。这些属性使其成为具有 3D 人体关键点注释的最大和最丰富的现有数据集。它还包含 1,408 个 3D 人类舞蹈动作序列,表示为关节旋转以及根轨迹。舞蹈动作平均分布在 10 种舞蹈流派中,有数百种编舞。运动持续时间从 7.4 秒不等。至 48.0 秒。所有的舞蹈动作都有相应的音乐。

数据集链接:http://m6z.cn/6o4AAg该数据集专注于在各种人群和复杂事件中进行非常具有挑战性和现实性的以人为中心的分析任务,包括地铁上下车、碰撞、战斗和地震逃生。并且具有大规模和密集注释的标签,涵盖了以人为中心的分析中的广泛任务。

数据集链接:http://m6z.cn/5xz4OW道路和车道估计基准包括289次培训和290幅测试图像。我们在鸟瞰空间中评估道路和车道的估计性能。它包含不同类别的道路场景:城市无标记、城市标记、 城市多条标记车道以及以上三者的结合。

数据集链接:http://m6z.cn/5xz4QoCrackForest数据集是一个带注释的道路裂缝图像数据库,可以大致反映城市路面状况。

数据集链接:http://m6z.cn/6gGlltstero 2015 基准测试包含 200 个训练场景和 200 个测试场景(每个场景 4 幅彩色图像,以无损 png 格式保存)。与stereo 2012 和flow 2012 基准测试相比,它包含动态场景,在半自动过程中为其建立了真值。该数据集是通过在卡尔斯鲁厄中等规模城市、农村地区和高速公路上行驶而捕获的。每张图像最多可以看到 15 辆汽车和 30 名行人。

数据集下载地址:http://www.cvlibs.net/datasets/kitti/eval_scene_flow.php?benchmark=flowFlow 2015 基准测试包含 200 个训练场景和 200 个测试场景(每个场景 4 幅彩色图像,以无损 png 格式保存)。与stereo 2012 和flow 2012 基准测试相比,它包含动态场景,在半自动过程中为其建立了真值。该数据集是通过在卡尔斯鲁厄中等规模城市、农村地区和高速公路上行驶而捕获的。每张图像最多可以看到 15 辆汽车和 30 名行人。
数据集下载地址:http://www.cvlibs.net/datasets/kitti/eval_scene_flow.phpSceneflow 2015 基准测试包含 200 个训练场景和 200 个测试场景(每个场景 4 幅彩色图像,以无损 png 格式保存)。与stereo 2012 和flow 2012 基准测试相比,它包含动态场景,在半自动过程中为其建立了真值。该数据集是通过在卡尔斯鲁厄中等规模城市、农村地区和高速公路上行驶而捕获的。每张图像最多可以看到 15 辆汽车和 30 名行人。
数据集下载地址:http://www.cvlibs.net/datasets/kitti/eval_depth_all.phpKITTI-depth 包含超过 93,000 个深度图以及相应的原始 LiDaR 扫描和 RGB 图像。鉴于大量的训练数据,该数据集应允许训练复杂的深度学习模型,以完成深度补全和单幅图像深度预测的任务。此外,该数据集提供了带有未发布深度图的手动选择图像,作为这两个具有挑战性的任务的基准。

数据集下载地址:http://m6z.cn/61EogvALOV++,Amsterdam Library of Ordinary Videos for tracking 是一个物体追踪视频数据,旨在对不同的光线、通透度、泛着条件、背景杂乱程度、焦距下的相似物体的追踪。

数据集下载地址:http://m6z.cn/6gGlzF由布朗大学发布的人类动作视频数据集,该数据集视频多数来源于电影,还有一部分来自公共数据库以及YouTube等网络视频库。数据库包含有6849段样本,分为51类,每类至少包含有101段样本。

数据集下载地址:http://m6z.cn/69a8xyUCF50 是一个由中佛罗里达大学发布的动作识别数据集,由来自 youtube 的真实视频组成,包含 50 个动作类别,如棒球投球、篮球投篮、卧推、骑自行车、骑自行车、台球、蛙泳、挺举、跳水、击鼓等。对于所有 50 个类别,视频分为 25 组,其中每组由超过 4 个动作剪辑。同一组中的视频片段可能具有一些共同的特征,例如同一个人、相似背景、相似视点等。

数据集下载地址:http://m6z.cn/6vILNpSBU Kinect Interaction是一个复杂的人类活动数据集,描述了两个人的交互,包括同步视频、深度和运动捕捉数据。
数据集下载地址:http://m6z.cn/5TAgdC一个包含 37 个类别的宠物数据集,每个类别大约有 200 张图像。这些图像在比例、姿势和照明方面有很大的变化。所有图像都有相关的品种、头部 ROI 和像素级三元图分割的地面实况注释。

数据集下载地址:http://m6z.cn/5TAgbwCAT 数据集包括超过 9,000 张猫图像。对于每张图像,猫的头部都有九个点的注释,眼睛两个,嘴巴一个,耳朵六个。

数据集下载地址:http://m6z.cn/6nF6kM斯坦福狗数据集包含来自世界各地的 120 种狗的图像。该数据集是使用 ImageNet 中的图像和注释构建的,用于细粒度图像分类任务。该数据集的内容:

数据集下载地址:http://m6z.cn/5TAgeAStreetScenes Challenge Framework 是用于对象检测的图像、注释、软件和性能测量的集合。每张图像都是从马萨诸塞州波士顿及其周边地区的 DSC-F717 相机拍摄的。然后用围绕 9 个对象类别的每个示例的多边形手动标记每个图像,包括 [汽车、行人、自行车、建筑物、树木、天空、道路、人行道和商店]。这些图像的标记是在仔细检查下完成的,以确保对象总是以相同的方式标记,关于遮挡和其他常见的图像变换。

数据集下载地址:http://m6z.cn/616wopCars 数据集包含 196 类汽车的 16,185 张图像。数据分为 8,144 个训练图像和 8,041 个测试图像,其中每个类别大致按 50-50 分割。课程通常在品牌、型号、年份级别,例如 2012 Tesla Model S 或 2012 BMW M3 coupe。
MNIST数据集是一个手写阿拉伯数字图像识别数据集,图片分辨率为 20×20 灰度图图片,包含‘0 – 9’ 十组手写手写阿拉伯数字的图片。其中,训练样本 60000 ,测试样本 10000,数据为图片的像素点值,作者已经对数据集进行了压缩。
该数据集是图片数据,分为训练集85%(Train)和测试集15%(Test)。其中O代表Organic(有机垃圾),R代表Recycle(可回收)
数据集下载地址:http://m6z.cn/5ExMWbSVHN 是一个真实世界的图像数据集,用于开发机器学习和对象识别算法,对数据预处理和格式化的要求最低。它可以被视为与MNIST风格相似(例如,图像是经过裁剪的小数字),但包含一个数量级的更多标记数据(超过 600,000 个数字图像),并且来自一个更难、未解决的现实世界问题(识别自然场景图像中的数字和数字)。SVHN 是从谷歌街景图像中的门牌号获得的。

数据集下载地址:http://m6z.cn/5SUfEd该数据集的目的是提供一种简单的方法来开始处理 3D 计算机视觉问题,例如 3D 形状识别。

LVIS是一个大规模细粒度词汇集标记数据集,该数据集针对超过 1000 类物体进行了约 200 万个高质量的实例分割标注,包含 164k 张图像。
Crowd Segmentation Dataset 是一个高密度人群和移动物体视频数据,视频来自BBC Motion Gallery 和 Getty Images 网站。
Densely Annotated Video Segmentation 是一个高清视频中的物体分割数据集,包括 50个 视频序列,3455个 帧标注,视频采集自高清 1080p 格式。、
数据集下载地址:http://m6z.cn/6nF67SMediaTeam Oulu Document 数据集是一个文档扫描图像和文档内容数据集,包含 500篇 1975年之前的文档信息。
作者 | 算法进阶
摘自: 算法进阶微信公众号
数据、算法、算力是人工智能发展的三要素。数据决定了Ai模型学习的上限,数据规模越大、质量越高,模型就能够拥有更好的泛化能力。然而在实际工程中,经常有数据量太少(相对模型而言)、样本不均衡、很难覆盖全部的场景等问题,解决这类问题的一个有效途径是通过数据增强(Data Augmentation),使模型学习获得较好的泛化性能。

数据增强(Data Augmentation)是在不实质性的增加数据的情况下,从原始数据加工出更多的表示,提高原数据的数量及质量,以接近于更多数据量产生的价值。其原理是,通过对原始数据融入先验知识,加工出更多数据的表示,有助于模型判别数据中统计噪声,加强本体特征的学习,减少模型过拟合,提升泛化能力。
如经典的机器学习例子–哈士奇误分类为狼:通过可解释性方法,可发现错误分类是由于图像上的雪造成的。通常狗对比狼的图像里面雪地背景比较少,分类器学会使用雪作为一个特征来将图像分类为狼还是狗,而忽略了动物本体的特征。此时,可以通过数据增强的方法,增加变换后的数据(如背景换色、加入噪声等方式)来训练模型,帮助模型学习到本体的特征,提高泛化能力。

需要关注的是,数据增强样本也有可能是引入片面噪声,导致过拟合。此时需要考虑的是调整数据增强方法,或者通过算法(可借鉴Pu-Learning思路)选择增强数据的最佳子集,以提高模型的泛化能力。
常用数据增强方法可分为:基于样本变换的数据增强及基于深度学习的数据增强。
样本变换数据增强即采用预设的数据变换规则进行已有数据的扩增,包含单样本数据增强和多样本数据增强。
单(图像)样本增强主要有几何操作、颜色变换、随机擦除、添加噪声等方法,可参见imgaug开源库。

多样本增强是通过先验知识组合及转换多个样本,主要有Smote、SamplePairing、Mixup等方法在特征空间内构造已知样本的邻域值。
Smote(Synthetic Minority Over-sampling Technique)方法较常用于样本均衡学习,核心思想是从训练集随机同类的两近邻样本合成一个新的样本,其方法可以分为三步:
1、 对于各样本X_i,计算与同类样本的欧式距离,确定其同类的K个(如图3个)近邻样本;
2、从该样本k近邻中随机选择一个样本如近邻X_ik,生成新的样本:
Xsmote_ik = Xi + rand(0,1) ∗ ∣X_i − X_ik∣ 3、重复2步骤迭代N次,可以合成N个新的样本。

# SMOTE
from imblearn.over_sampling import SMOTE
print("Before OverSampling, counts of label\n{}".format(y_train.value_counts()))
smote = SMOTE()
x_train_res, y_train_res = smote.fit_resample(x_train, y_train)
print("After OverSampling, counts of label\n{}".format(y_train_res.value_counts())) SamplePairing算法的核心思想是从训练集随机抽取的两幅图像叠加合成一个新的样本(像素取平均值),使用第一幅图像的label作为合成图像的正确label。

Mixup算法的核心思想是按一定的比例随机混合两个训练样本及其标签,这种混合方式不仅能够增加样本的多样性,且能够使决策边界更加平滑,增强了难例样本的识别,模型的鲁棒性得到提升。其方法可以分为两步:
1、从原始训练数据中随机选取的两个样本(xi, yi) and (xj, yj)。其中y(原始label)用one-hot 编码。
2、对两个样本按比例组合,形成新的样本和带权重的标签
x˜ = λxi + (1 − λ)xj
y˜ = λyi + (1 − λ)yj 最终的loss为各标签上分别计算cross-entropy loss,加权求和。其中 λ ∈ [0, 1], λ是mixup的超参数,控制两个样本插值的强度。

# Mixup
def mixup_batch(x, y, step, batch_size, alpha=0.2):
"""
get batch data
:param x: training data
:param y: one-hot label
:param step: step
:param batch_size: batch size
:param alpha: hyper-parameter α, default as 0.2
:return: x y
"""
candidates_data, candidates_label = x, y
offset = (step * batch_size) % (candidates_data.shape[0] - batch_size)
# get batch data
train_features_batch = candidates_data[offset:(offset + batch_size)]
train_labels_batch = candidates_label[offset:(offset + batch_size)]
if alpha == 0:
return train_features_batch, train_labels_batch
if alpha > 0:
weight = np.random.beta(alpha, alpha, batch_size)
x_weight = weight.reshape(batch_size, 1)
y_weight = weight.reshape(batch_size, 1)
index = np.random.permutation(batch_size)
x1, x2 = train_features_batch, train_features_batch[index]
x = x1 * x_weight + x2 * (1 - x_weight)
y1, y2 = train_labels_batch, train_labels_batch[index]
y = y1 * y_weight + y2 * (1 - y_weight)
return x, y 不同于传统在输入空间变换的数据增强方法,神经网络可将输入样本映射为网络层的低维向量(表征学习),从而直接在学习的特征空间进行组合变换等进行数据增强,如MoEx方法等。

生成模型如变分自编码网络(Variational Auto-Encoding network, VAE)和生成对抗网络(Generative Adversarial Network, GAN),其生成样本的方法也可以用于数据增强。这种基于网络合成的方法相比于传统的数据增强技术虽然过程更加复杂, 但是生成的样本更加多样。

# VAE模型
class VAE(keras.Model):
...
def train_step(self, data):
with tf.GradientTape() as tape:
z_mean, z_log_var, z = self.encoder(data)
reconstruction = self.decoder(z)
reconstruction_loss = tf.reduce_mean(
tf.reduce_sum(
keras.losses.binary_crossentropy(data, reconstruction), axis=(1, 2)
)
)
kl_loss = -0.5 * (1 + z_log_var - tf.square(z_mean) - tf.exp(z_log_var))
kl_loss = tf.reduce_mean(tf.reduce_sum(kl_loss, axis=1))
total_loss = reconstruction_loss + kl_loss
grads = tape.gradient(total_loss, self.trainable_weights)
self.optimizer.apply_gradients(zip(grads, self.trainable_weights))
self.total_loss_tracker.update_state(total_loss)
self.reconstruction_loss_tracker.update_state(reconstruction_loss)
self.kl_loss_tracker.update_state(kl_loss)
return {
"loss": self.total_loss_tracker.result(),
"reconstruction_loss": self.reconstruction_loss_tracker.result(),
"kl_loss": self.kl_loss_tracker.result(),
} 
# DCGAN模型
class GAN(keras.Model):
...
def train_step(self, real_images):
batch_size = tf.shape(real_images)[0]
random_latent_vectors = tf.random.normal(shape=(batch_size, self.latent_dim))
# G: Z→X(输入噪声z, 输出生成的图像数据x)
generated_images = self.generator(random_latent_vectors)
# 合并生成及真实的样本并赋判定的标签
combined_images = tf.concat([generated_images, real_images], axis=0)
labels = tf.concat(
[tf.ones((batch_size, 1)), tf.zeros((batch_size, 1))], axis=0
)
# 标签加入随机噪声
labels += 0.05 * tf.random.uniform(tf.shape(labels))
# 训练判定网络
with tf.GradientTape() as tape:
predictions = self.discriminator(combined_images)
d_loss = self.loss_fn(labels, predictions)
grads = tape.gradient(d_loss, self.discriminator.trainable_weights)
self.d_optimizer.apply_gradients(
zip(grads, self.discriminator.trainable_weights)
)
random_latent_vectors = tf.random.normal(shape=(batch_size, self.latent_dim))
# 赋生成网络样本的标签(都赋为真实样本)
misleading_labels = tf.zeros((batch_size, 1))
# 训练生成网络
with tf.GradientTape() as tape:
predictions = self.discriminator(self.generator(random_latent_vectors))
g_loss = self.loss_fn(misleading_labels, predictions)
grads = tape.gradient(g_loss, self.generator.trainable_weights)
self.g_optimizer.apply_gradients(zip(grads, self.generator.trainable_weights))
# 更新损失
self.d_loss_metric.update_state(d_loss)
self.g_loss_metric.update_state(g_loss)
return {
"d_loss": self.d_loss_metric.result(),
"g_loss": self.g_loss_metric.result(),
}神经风格迁移(Neural Style Transfer)可以在保留原始内容的同时,将一个图像的样式转移到另一个图像上。除了实现类似色彩空间照明转换,还可以生成不同的纹理和艺术风格。

神经风格迁移是通过优化三类的损失来实现的:
style_loss:使生成的图像接近样式参考图像的局部纹理;
content_loss:使生成的图像的内容表示接近于基本图像的表示;
total_variation_loss:是一个正则化损失,它使生成的图像保持局部一致。
# 样式损失
def style_loss(style, combination):
S = gram_matrix(style)
C = gram_matrix(combination)
channels = 3
size = img_nrows * img_ncols
return tf.reduce_sum(tf.square(S - C)) / (4.0 * (channels ** 2) * (size ** 2))
# 内容损失
def content_loss(base, combination):
return tf.reduce_sum(tf.square(combination - base))
# 正则损失
def total_variation_loss(x):
a = tf.square(
x[:, : img_nrows - 1, : img_ncols - 1, :] - x[:, 1:, : img_ncols - 1, :]
)
b = tf.square(
x[:, : img_nrows - 1, : img_ncols - 1, :] - x[:, : img_nrows - 1, 1:, :]
)
return tf.reduce_sum(tf.pow(a + b, 1.25))深度学习研究中的元学习(Meta learning)通常是指使用神经网络优化神经网络,元学习的数据增强有神经增强(Neural augmentation)等方法。
神经增强(Neural augmentation)是通过神经网络组的学习以获得较优的数据增强并改善分类效果的一种方法。其方法步骤如下:
1、获取与target图像同一类别的一对随机图像,前置的增强网络通过CNN将它们映射为合成图像,合成图像与target图像对比计算损失;
2、将合成图像与target图像神经风格转换后输入到分类网络中,并输出该图像分类损失;
3、将增强与分类的loss加权平均后,反向传播以更新分类网络及增强网络权重。使得其输出图像的同类内差距减小且分类准确。

摘自 Jack Cui
马赛克,克星,真来了!
何恺明大神的新作 论文:https://arxiv.org/abs/2111.06377
项目地址:https://github.com/facebookresearch/mae
简单讲:将图片随机遮挡,然后复原。并且遮挡的比例,非常大!超过整张图的 80% ,我们直接看效果:

第一列是遮挡图,第二列是修复结果,第三列是原图。图片太多,可能看不清,我们单看一个:

看这个遮挡的程度,表针、表盘几乎都看不见了。但是 MAE 依然能够修复出来:

这个效果真的很惊艳!甚至对于遮挡 95% 的面积的图片依然 work。

看左图,你能看出来被遮挡的是蘑菇吗??MAE 却能轻松修复出来。接下来,跟大家聊聊 MAE。
讲解 MAE 之前不得不先说下 Vit。红遍大江南北的 Vision Transformer,ViT。领域内的小伙伴,或多或少都应该听说过。它将 Transformer 应用到了 CV 上面,将整个图分为 16 * 16 的小方块,每个方块做成一个词,然后放进 Transformer 进行训练。视觉transformer 和自然语言处理 中的transformer可以进行类比,可以把一个图像块理解成一个单词。
MAE 结构设计的非常简单:

将一张图随机打 Mask,未 Mask 部分输入给 Encoder 进行编码学习,这个 Encoder 就是 Vit,然后得到每个块的特征。再将未 Mask 部分以及 Mask 部分全部输入给 Decoder 进行解码学习,最终目标是修复图片。而 Decoder 就是一个轻量化的 Transformer。它的损失函数就是普通的 MSE。所以说, MAE 的 Encoder 和 Decoder 结构不同,是非对称式的。Encoder 将输入编码为 latent representation,而 Decoder 将从 latent representation 重建原始信号。
项目提供了 Colab,如果你能登陆,那么可以直接体验:https://colab.research.google.com/github/facebookresearch/mae/blob/main/demo/mae_visualize.ipynb
如果不能登陆,可以直接本地部署,作者提供了预训练模型。
MAE 可以用来生成不存在的内容,就像 GAN 一样。
Transformer 最初主要应用于一些自然语言处理场景,比如翻译、文本分类、写小说、写歌等。随着技术的发展,Transformer 开始征战视觉领域,分类、检测等任务均不在话下,逐渐走上了多模态的道路。
Transformer 是 Google 在 2017 年提出的用于机器翻译的模型。

Transformer 的内部,在本质上是一个 Encoder-Decoder 的结构,即 编码器-解码器。
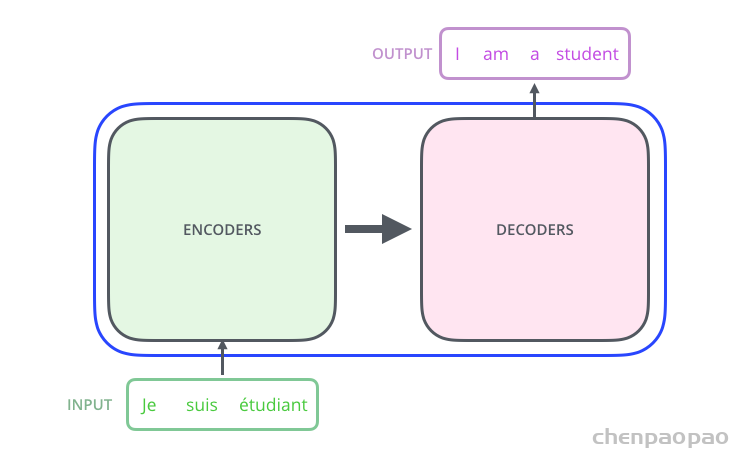
Transformer 中抛弃了传统的 CNN 和 RNN,整个网络结构完全由 Attention 机制组成,并且采用了 6 层 Encoder-Decoder 结构。
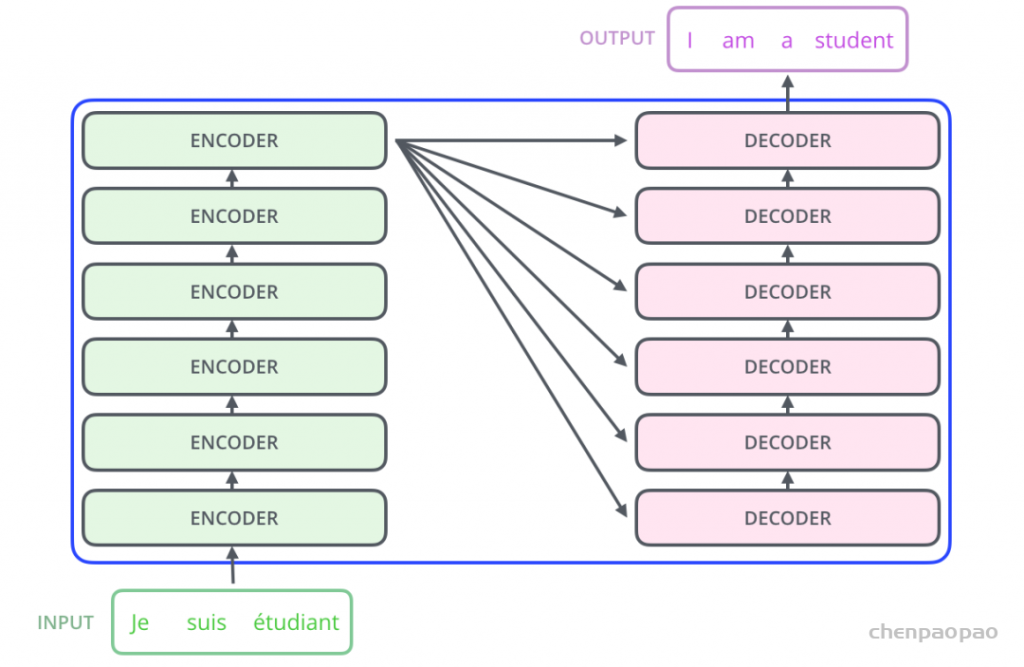
显然,Transformer 主要分为两大部分,分别是编码器和解码器。整个 Transformer 是由 6 个这样的结构组成,为了方便理解,我们只看其中一个Encoder-Decoder 结构。
以一个简单的例子进行说明:
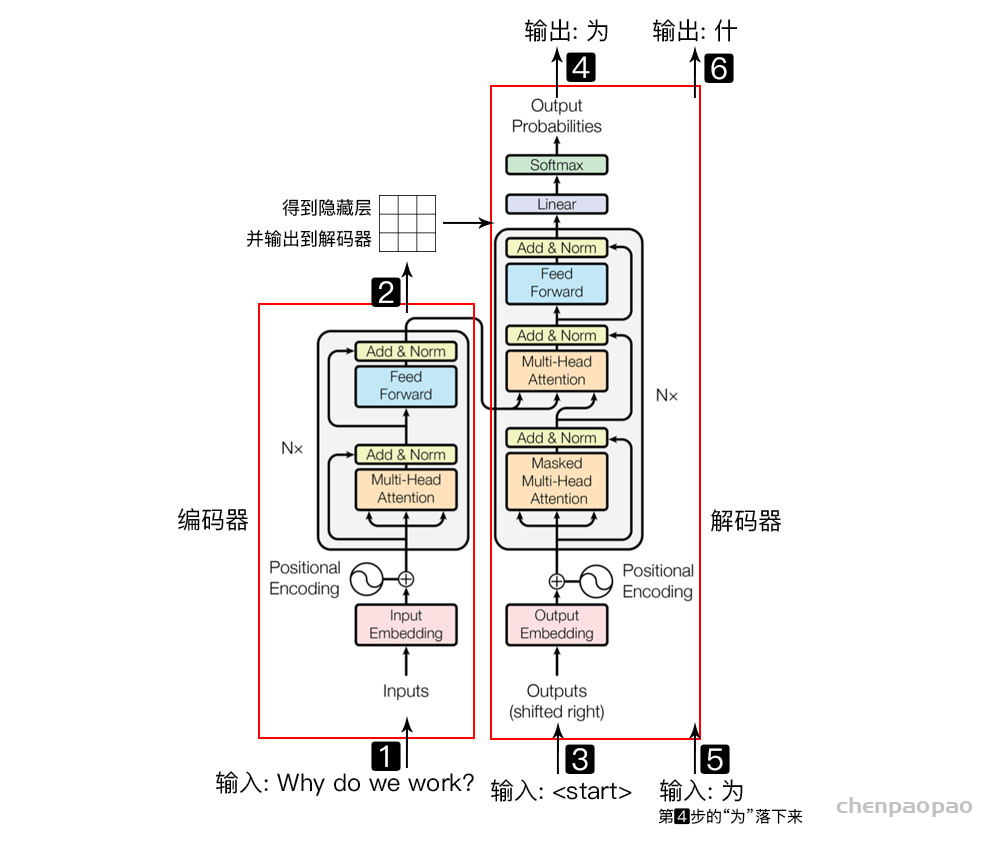
Why do we work?,我们为什么工作?左侧红框是编码器,右侧红框是解码器,编码器负责把自然语言序列映射成为隐藏层(上图第2步),即含有自然语言序列的数学表达。解码器把隐藏层再映射为自然语言序列,从而使我们可以解决各种问题,如情感分析、机器翻译、摘要生成、语义关系抽取等。简单说下,上图每一步都做了什么:
解码器和编码器的结构类似,本文以编码器部分进行讲解。即把自然语言序列映射为隐藏层的数学表达的过程,因为理解了编码器中的结构,理解解码器就非常简单了。为了方便学习,我将编码器分为 4 个部分,依次讲解。
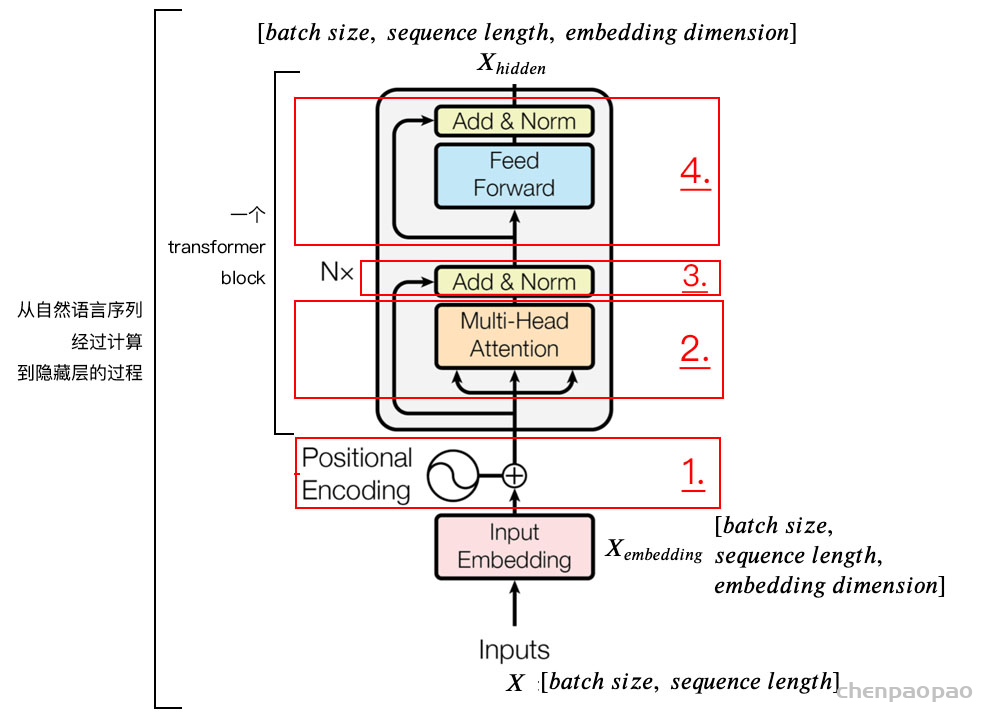
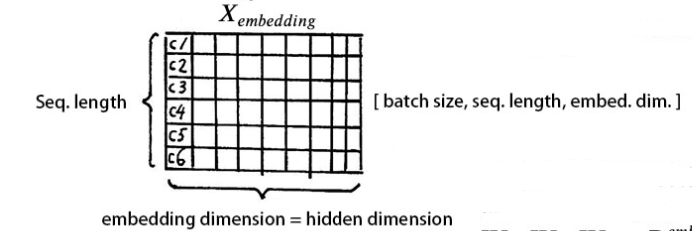
我们输入数据 X 维度为[batch size, sequence length]的数据,比如我们为什么工作。batch size 就是 batch 的大小,这里只有一句话,所以 batch size 为 1,sequence length 是句子的长度,一共 7 个字,所以输入的数据维度是 [1, 7]。我们不能直接将这句话输入到编码器中,因为 Tranformer 不认识,我们需要先进行字嵌入,即得到图中的 。简单点说,就是文字->字向量的转换,这种转换是将文字转换为计算机认识的数学表示,用到的方法就是 Word2Vec,Word2Vec 的具体细节,对于初学者暂且不用了解,这个是可以直接使用的。得到维度是 [batch size, sequence length, embedding dimension],embedding dimension 的大小由 Word2Vec 算法决定,Tranformer 采用 512 长度的字向量。所以 的维度是 [1, 7, 512]。至此,输入的我们为什么工作,可以用一个矩阵来简化表示。
我们知道,文字的先后顺序,很重要。比如吃饭没、没吃饭、没饭吃、饭吃没、饭没吃,同样三个字,顺序颠倒,所表达的含义就不同了。文字的位置信息很重要,Tranformer 没有类似 RNN 的循环结构,没有捕捉顺序序列的能力。为了保留这种位置信息交给 Tranformer 学习,我们需要用到位置嵌入。加入位置信息的方式非常多,最简单的可以是直接将绝对坐标 0,1,2 编码。Tranformer 采用的是 sin-cos 规则,使用了 sin 和 cos 函数的线性变换来提供给模型位置信息:
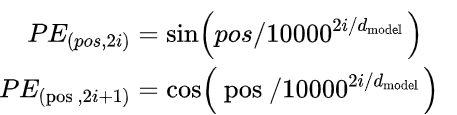
上式中 pos 指的是句中字的位置,取值范围是 [0, 𝑚𝑎𝑥 𝑠𝑒𝑞𝑢𝑒𝑛𝑐𝑒 𝑙𝑒𝑛𝑔𝑡ℎ),i 指的是字嵌入的维度, 取值范围是 [0, 𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛)。 就是 𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛 的大小。上面有 sin 和 cos 一组公式,也就是对应着 𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛 维度的一组奇数和偶数的序号的维度,从而产生不同的周期性变化。
# 导入依赖库
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import math
def get_positional_encoding(max_seq_len, embed_dim):
# 初始化一个positional encoding
# embed_dim: 字嵌入的维度
# max_seq_len: 最大的序列长度
positional_encoding = np.array([
[pos / np.power(10000, 2 * i / embed_dim) for i in range(embed_dim)]
if pos != 0 else np.zeros(embed_dim) for pos in range(max_seq_len)])
positional_encoding[1:, 0::2] = np.sin(positional_encoding[1:, 0::2]) # dim 2i 偶数
positional_encoding[1:, 1::2] = np.cos(positional_encoding[1:, 1::2]) # dim 2i+1 奇数
# 归一化, 用位置嵌入的每一行除以它的模长
# denominator = np.sqrt(np.sum(position_enc**2, axis=1, keepdims=True))
# position_enc = position_enc / (denominator + 1e-8)
return positional_encoding
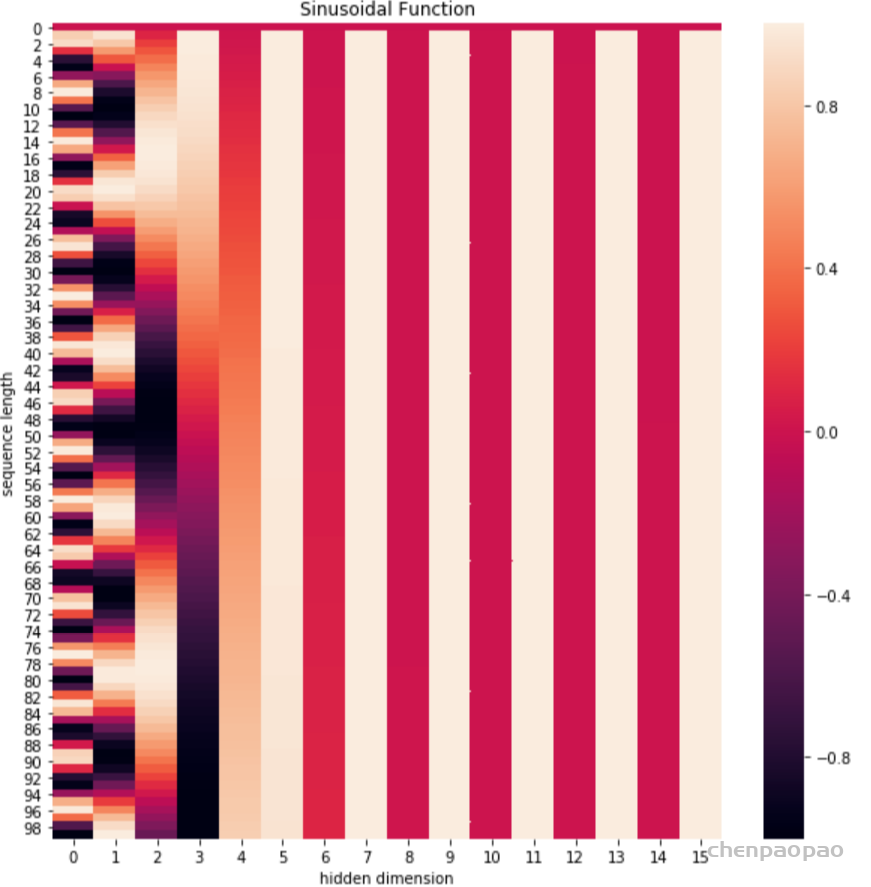
positional_encoding = get_positional_encoding(max_seq_len=100, embed_dim=16)
plt.figure(figsize=(10,10))
sns.heatmap(positional_encoding)
plt.title("Sinusoidal Function")
plt.xlabel("hidden dimension")
plt.ylabel("sequence length")可以看到,位置嵌入在 𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛 (也是hidden dimension )维度上随着维度序号增大,周期变化会越来越慢,而产生一种包含位置信息的纹理。
就这样,产生独一的纹理位置信息,模型从而学到位置之间的依赖关系和自然语言的时序特性。
最后,将Xembedding 和 位置嵌入 相加,送给下一层。
直接看下图笔记,讲解的非常详细。
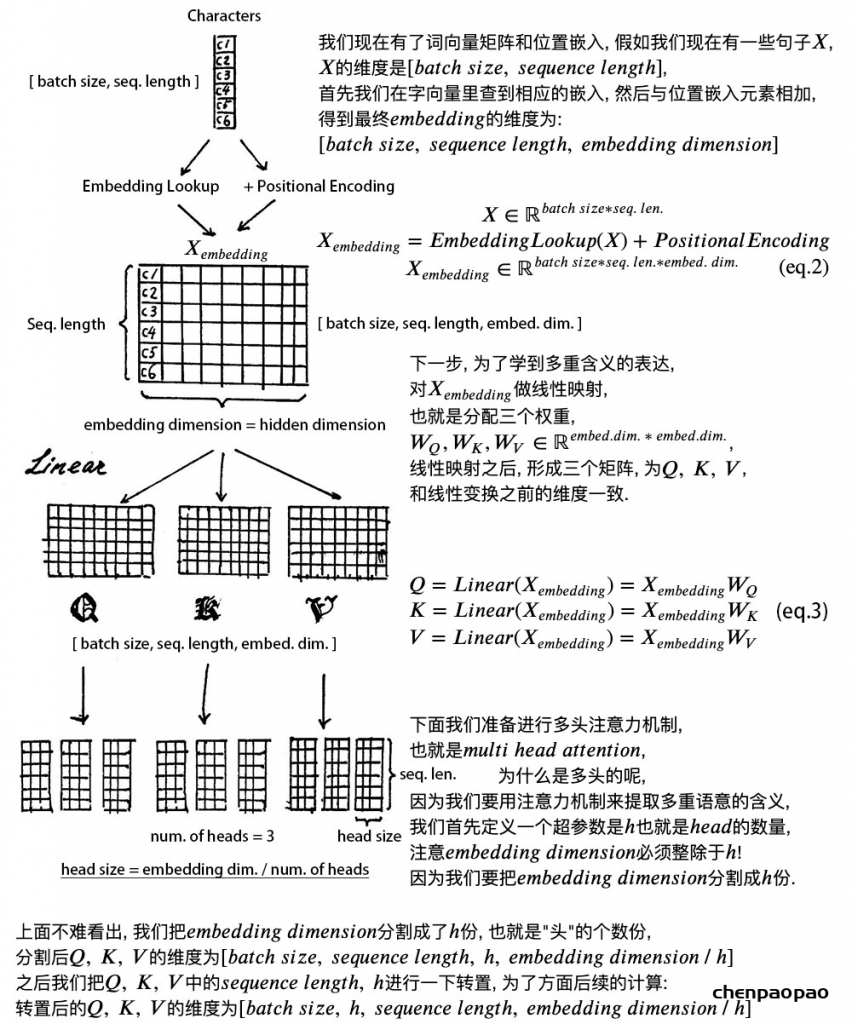
多头的意义在于,\(QK^{T}\) 得到的矩阵就叫注意力矩阵,它可以表示每个字与其他字的相似程度。因为,向量的点积值越大,说明两个向量越接近。
我们的目的是,让每个字都含有当前这个句子中的所有字的信息,用注意力层,我们做到了。
需要注意的是,在上面 𝑠𝑒𝑙𝑓 𝑎𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛 的计算过程中,我们通常使用 𝑚𝑖𝑛𝑖 𝑏𝑎𝑡𝑐ℎ,也就是一次计算多句话,上文举例只用了一个句子。
每个句子的长度是不一样的,需要按照最长的句子的长度统一处理。对于短的句子,进行 Padding 操作,一般我们用 0 来进行填充。
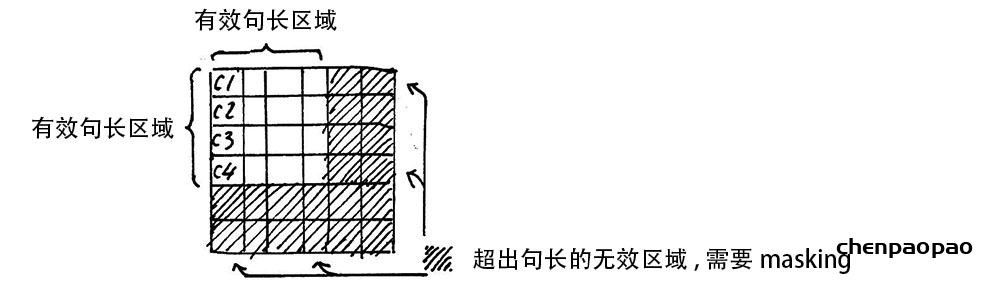
加入了残差设计和层归一化操作,目的是为了防止梯度消失,加快收敛。
我们在上一步得到了经过注意力矩阵加权之后的 𝑉, 也就是 𝐴𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛(𝑄, 𝐾, 𝑉),我们对它进行一下转置,使其和 𝑋𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 的维度一致, 也就是 [𝑏𝑎𝑡𝑐ℎ 𝑠𝑖𝑧𝑒, 𝑠𝑒𝑞𝑢𝑒𝑛𝑐𝑒 𝑙𝑒𝑛𝑔𝑡ℎ, 𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛] ,然后把他们加起来做残差连接,直接进行元素相加,因为他们的维度一致:
$$
X_{\text {embedding }}+\text { Attention }(Q, K, V)
$$
在之后的运算里,每经过一个模块的运算,都要把运算之前的值和运算之后的值相加,从而得到残差连接,训练的时候可以使梯度直接走捷径反传到最初始层:
$$
X+\text { SubLayer }(X)
$$
作用是把神经网络中隐藏层归一为标准正态分布,也就是 𝑖.𝑖.𝑑 独立同分布, 以起到加快训练速度, 加速收敛的作用。
$$
\mu_{i}=\frac{1}{m} \sum_{i=1}^{m} x_{i j}
$$
上式中以矩阵的行 (𝑟𝑜𝑤) 为单位求均值:
$$
\sigma_{j}^{2}=\frac{1}{m} \sum_{i=1}^{m}\left(x_{i j}-\mu_{j}\right)^{2}
$$
上式中以矩阵的行 (𝑟𝑜𝑤) 为单位求方差:
$$
\operatorname{LayerNorm}(x)=\alpha \odot \frac{x_{i j}-\mu_{i}}{\sqrt{\sigma_{i}^{2}+\epsilon}}+\beta
$$
然后用每一行的每一个元素减去这行的均值,再除以这行的标准差,从而得到归 一化后的数值, \(\epsilon\) 是为了防止除 0 ;之后引入两个可训练参数 \(\alpha, \beta\) 来弥补归一化的过程中损失掉的信息,注意 \(\odot\) 表示 元素相乘而不是点积,我们一般初始化 \(\alpha\) 为全 1 ,而\(\beta\) 为全 0 。
代码层面非常简单,单头 attention 操作如下:
class ScaledDotProductAttention(nn.Module):
''' Scaled Dot-Product Attention '''
def __init__(self, temperature, attn_dropout=0.1):
super().__init__()
self.temperature = temperature
self.dropout = nn.Dropout(attn_dropout)
def forward(self, q, k, v, mask=None):
# self.temperature是论文中的d_k ** 0.5,防止梯度过大
# QxK/sqrt(dk)
attn = torch.matmul(q / self.temperature, k.transpose(2, 3))
if mask is not None:
# 屏蔽不想要的输出
attn = attn.masked_fill(mask == 0, -1e9)
# softmax+dropout
attn = self.dropout(F.softmax(attn, dim=-1))
# 概率分布xV
output = torch.matmul(attn, v)
return output, attnMulti-Head Attention 实现在 ScaledDotProductAttention 基础上构建:
class MultiHeadAttention(nn.Module):
''' Multi-Head Attention module '''
# n_head头的个数,默认是8
# d_model编码向量长度,例如本文说的512
# d_k, d_v的值一般会设置为 n_head * d_k=d_model,
# 此时concat后正好和原始输入一样,当然不相同也可以,因为后面有fc层
# 相当于将可学习矩阵分成独立的n_head份
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):
super().__init__()
# 假设n_head=8,d_k=64
self.n_head = n_head
self.d_k = d_k
self.d_v = d_v
# d_model输入向量,n_head * d_k输出向量
# 可学习W^Q,W^K,W^V矩阵参数初始化
self.w_qs = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_ks = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_vs = nn.Linear(d_model, n_head * d_v, bias=False)
# 最后的输出维度变换操作
self.fc = nn.Linear(n_head * d_v, d_model, bias=False)
# 单头自注意力
self.attention = ScaledDotProductAttention(temperature=d_k ** 0.5)
self.dropout = nn.Dropout(dropout)
# 层归一化
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
def forward(self, q, k, v, mask=None):
# 假设qkv输入是(b,100,512),100是训练每个样本最大单词个数
# 一般qkv相等,即自注意力
residual = q
# 将输入x和可学习矩阵相乘,得到(b,100,512)输出
# 其中512的含义其实是8x64,8个head,每个head的可学习矩阵为64维度
# q的输出是(b,100,8,64),kv也是一样
q = self.w_qs(q).view(sz_b, len_q, n_head, d_k)
k = self.w_ks(k).view(sz_b, len_k, n_head, d_k)
v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)
# 变成(b,8,100,64),方便后面计算,也就是8个头单独计算
q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)
if mask is not None:
mask = mask.unsqueeze(1) # For head axis broadcasting.
# 输出q是(b,8,100,64),维持不变,内部计算流程是:
# q*k转置,除以d_k ** 0.5,输出维度是b,8,100,100即单词和单词直接的相似性
# 对最后一个维度进行softmax操作得到b,8,100,100
# 最后乘上V,得到b,8,100,64输出
q, attn = self.attention(q, k, v, mask=mask)
# b,100,8,64-->b,100,512
q = q.transpose(1, 2).contiguous().view(sz_b, len_q, -1)
q = self.dropout(self.fc(q))
# 残差计算
q += residual
# 层归一化,在512维度计算均值和方差,进行层归一化
q = self.layer_norm(q)
return q, attn这个层就没啥说的了,非常简单,直接看代码吧:
class PositionwiseFeedForward(nn.Module):
''' A two-feed-forward-layer module '''
def __init__(self, d_in, d_hid, dropout=0.1):
super().__init__()
# 两个fc层,对最后的512维度进行变换
self.w_1 = nn.Linear(d_in, d_hid) # position-wise
self.w_2 = nn.Linear(d_hid, d_in) # position-wise
self.layer_norm = nn.LayerNorm(d_in, eps=1e-6)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
residual = x
x = self.w_2(F.relu(self.w_1(x)))
x = self.dropout(x)
x += residual
x = self.layer_norm(x)
return xTransformer 最初主要应用于一些自然语言处理场景,比如翻译、文本分类、写小说、写歌等。随着技术的发展,Transformer 开始征战视觉领域,分类、检测等任务均不在话下,逐渐走上了多模态的道路。
Transformer 是 Google 在 2017 年提出的用于机器翻译的模型。
Transformer 的内部,在本质上是一个 Encoder-Decoder 的结构,即 编码器-解码器。
Transformer 中抛弃了传统的 CNN 和 RNN,整个网络结构完全由 Attention 机制组成,并且采用了 6 层 Encoder-Decoder 结构。
显然,Transformer 主要分为两大部分,分别是编码器和解码器。整个 Transformer 是由 6 个这样的结构组成,为了方便理解,我们只看其中一个Encoder-Decoder 结构。
以一个简单的例子进行说明:
Why do we work?,我们为什么工作?左侧红框是编码器,右侧红框是解码器,编码器负责把自然语言序列映射成为隐藏层(上图第2步),即含有自然语言序列的数学表达。解码器把隐藏层再映射为自然语言序列,从而使我们可以解决各种问题,如情感分析、机器翻译、摘要生成、语义关系抽取等。简单说下,上图每一步都做了什么:
解码器和编码器的结构类似,本文以编码器部分进行讲解。即把自然语言序列映射为隐藏层的数学表达的过程,因为理解了编码器中的结构,理解解码器就非常简单了。为了方便学习,我将编码器分为 4 个部分,依次讲解。
我们输入数据 X 维度为[batch size, sequence length]的数据,比如我们为什么工作。batch size 就是 batch 的大小,这里只有一句话,所以 batch size 为 1,sequence length 是句子的长度,一共 7 个字,所以输入的数据维度是 [1, 7]。我们不能直接将这句话输入到编码器中,因为 Tranformer 不认识,我们需要先进行字嵌入,即得到图中的 。简单点说,就是文字->字向量的转换,这种转换是将文字转换为计算机认识的数学表示,用到的方法就是 Word2Vec,Word2Vec 的具体细节,对于初学者暂且不用了解,这个是可以直接使用的。得到维度是 [batch size, sequence length, embedding dimension],embedding dimension 的大小由 Word2Vec 算法决定,Tranformer 采用 512 长度的字向量。所以 的维度是 [1, 7, 512]。至此,输入的我们为什么工作,可以用一个矩阵来简化表示。
我们知道,文字的先后顺序,很重要。比如吃饭没、没吃饭、没饭吃、饭吃没、饭没吃,同样三个字,顺序颠倒,所表达的含义就不同了。文字的位置信息很重要,Tranformer 没有类似 RNN 的循环结构,没有捕捉顺序序列的能力。为了保留这种位置信息交给 Tranformer 学习,我们需要用到位置嵌入。加入位置信息的方式非常多,最简单的可以是直接将绝对坐标 0,1,2 编码。Tranformer 采用的是 sin-cos 规则,使用了 sin 和 cos 函数的线性变换来提供给模型位置信息:
上式中 pos 指的是句中字的位置,取值范围是 [0, 𝑚𝑎𝑥 𝑠𝑒𝑞𝑢𝑒𝑛𝑐𝑒 𝑙𝑒𝑛𝑔𝑡ℎ),i 指的是字嵌入的维度, 取值范围是 [0, 𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛)。 就是 𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛 的大小。上面有 sin 和 cos 一组公式,也就是对应着 𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛 维度的一组奇数和偶数的序号的维度,从而产生不同的周期性变化。
# 导入依赖库
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import math
def get_positional_encoding(max_seq_len, embed_dim):
# 初始化一个positional encoding
# embed_dim: 字嵌入的维度
# max_seq_len: 最大的序列长度
positional_encoding = np.array([
[pos / np.power(10000, 2 * i / embed_dim) for i in range(embed_dim)]
if pos != 0 else np.zeros(embed_dim) for pos in range(max_seq_len)])
positional_encoding[1:, 0::2] = np.sin(positional_encoding[1:, 0::2]) # dim 2i 偶数
positional_encoding[1:, 1::2] = np.cos(positional_encoding[1:, 1::2]) # dim 2i+1 奇数
# 归一化, 用位置嵌入的每一行除以它的模长
# denominator = np.sqrt(np.sum(position_enc**2, axis=1, keepdims=True))
# position_enc = position_enc / (denominator + 1e-8)
return positional_encoding
positional_encoding = get_positional_encoding(max_seq_len=100, embed_dim=16)
plt.figure(figsize=(10,10))
sns.heatmap(positional_encoding)
plt.title("Sinusoidal Function")
plt.xlabel("hidden dimension")
plt.ylabel("sequence length")可以看到,位置嵌入在 𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛 (也是hidden dimension )维度上随着维度序号增大,周期变化会越来越慢,而产生一种包含位置信息的纹理。
就这样,产生独一的纹理位置信息,模型从而学到位置之间的依赖关系和自然语言的时序特性。
最后,将Xembedding 和 位置嵌入 相加,送给下一层。
直接看下图笔记,讲解的非常详细。
多头的意义在于,\(QK^{T}\) 得到的矩阵就叫注意力矩阵,它可以表示每个字与其他字的相似程度。因为,向量的点积值越大,说明两个向量越接近。
我们的目的是,让每个字都含有当前这个句子中的所有字的信息,用注意力层,我们做到了。
需要注意的是,在上面 𝑠𝑒𝑙𝑓 𝑎𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛 的计算过程中,我们通常使用 𝑚𝑖𝑛𝑖 𝑏𝑎𝑡𝑐ℎ,也就是一次计算多句话,上文举例只用了一个句子。
每个句子的长度是不一样的,需要按照最长的句子的长度统一处理。对于短的句子,进行 Padding 操作,一般我们用 0 来进行填充。
加入了残差设计和层归一化操作,目的是为了防止梯度消失,加快收敛。
我们在上一步得到了经过注意力矩阵加权之后的 𝑉, 也就是 𝐴𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛(𝑄, 𝐾, 𝑉),我们对它进行一下转置,使其和 𝑋𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 的维度一致, 也就是 [𝑏𝑎𝑡𝑐ℎ 𝑠𝑖𝑧𝑒, 𝑠𝑒𝑞𝑢𝑒𝑛𝑐𝑒 𝑙𝑒𝑛𝑔𝑡ℎ, 𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛] ,然后把他们加起来做残差连接,直接进行元素相加,因为他们的维度一致:
$$
X_{\text {embedding }}+\text { Attention }(Q, K, V)
$$
在之后的运算里,每经过一个模块的运算,都要把运算之前的值和运算之后的值相加,从而得到残差连接,训练的时候可以使梯度直接走捷径反传到最初始层:
$$
X+\text { SubLayer }(X)
$$
作用是把神经网络中隐藏层归一为标准正态分布,也就是 𝑖.𝑖.𝑑 独立同分布, 以起到加快训练速度, 加速收敛的作用。
$$
\mu_{i}=\frac{1}{m} \sum_{i=1}^{m} x_{i j}
$$
上式中以矩阵的行 (𝑟𝑜𝑤) 为单位求均值:
$$
\sigma_{j}^{2}=\frac{1}{m} \sum_{i=1}^{m}\left(x_{i j}-\mu_{j}\right)^{2}
$$
上式中以矩阵的行 (𝑟𝑜𝑤) 为单位求方差:
$$
\operatorname{LayerNorm}(x)=\alpha \odot \frac{x_{i j}-\mu_{i}}{\sqrt{\sigma_{i}^{2}+\epsilon}}+\beta
$$
然后用每一行的每一个元素减去这行的均值,再除以这行的标准差,从而得到归 一化后的数值, \(\epsilon\) 是为了防止除 0 ;之后引入两个可训练参数 \(\alpha, \beta\) 来弥补归一化的过程中损失掉的信息,注意 \(\odot\) 表示 元素相乘而不是点积,我们一般初始化 \(\alpha\) 为全 1 ,而\(\beta\) 为全 0 。
代码层面非常简单,单头 attention 操作如下:
class ScaledDotProductAttention(nn.Module):
''' Scaled Dot-Product Attention '''
def __init__(self, temperature, attn_dropout=0.1):
super().__init__()
self.temperature = temperature
self.dropout = nn.Dropout(attn_dropout)
def forward(self, q, k, v, mask=None):
# self.temperature是论文中的d_k ** 0.5,防止梯度过大
# QxK/sqrt(dk)
attn = torch.matmul(q / self.temperature, k.transpose(2, 3))
if mask is not None:
# 屏蔽不想要的输出
attn = attn.masked_fill(mask == 0, -1e9)
# softmax+dropout
attn = self.dropout(F.softmax(attn, dim=-1))
# 概率分布xV
output = torch.matmul(attn, v)
return output, attnMulti-Head Attention 实现在 ScaledDotProductAttention 基础上构建:
class MultiHeadAttention(nn.Module):
''' Multi-Head Attention module '''
# n_head头的个数,默认是8
# d_model编码向量长度,例如本文说的512
# d_k, d_v的值一般会设置为 n_head * d_k=d_model,
# 此时concat后正好和原始输入一样,当然不相同也可以,因为后面有fc层
# 相当于将可学习矩阵分成独立的n_head份
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):
super().__init__()
# 假设n_head=8,d_k=64
self.n_head = n_head
self.d_k = d_k
self.d_v = d_v
# d_model输入向量,n_head * d_k输出向量
# 可学习W^Q,W^K,W^V矩阵参数初始化
self.w_qs = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_ks = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_vs = nn.Linear(d_model, n_head * d_v, bias=False)
# 最后的输出维度变换操作
self.fc = nn.Linear(n_head * d_v, d_model, bias=False)
# 单头自注意力
self.attention = ScaledDotProductAttention(temperature=d_k ** 0.5)
self.dropout = nn.Dropout(dropout)
# 层归一化
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
def forward(self, q, k, v, mask=None):
# 假设qkv输入是(b,100,512),100是训练每个样本最大单词个数
# 一般qkv相等,即自注意力
residual = q
# 将输入x和可学习矩阵相乘,得到(b,100,512)输出
# 其中512的含义其实是8x64,8个head,每个head的可学习矩阵为64维度
# q的输出是(b,100,8,64),kv也是一样
q = self.w_qs(q).view(sz_b, len_q, n_head, d_k)
k = self.w_ks(k).view(sz_b, len_k, n_head, d_k)
v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)
# 变成(b,8,100,64),方便后面计算,也就是8个头单独计算
q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)
if mask is not None:
mask = mask.unsqueeze(1) # For head axis broadcasting.
# 输出q是(b,8,100,64),维持不变,内部计算流程是:
# q*k转置,除以d_k ** 0.5,输出维度是b,8,100,100即单词和单词直接的相似性
# 对最后一个维度进行softmax操作得到b,8,100,100
# 最后乘上V,得到b,8,100,64输出
q, attn = self.attention(q, k, v, mask=mask)
# b,100,8,64-->b,100,512
q = q.transpose(1, 2).contiguous().view(sz_b, len_q, -1)
q = self.dropout(self.fc(q))
# 残差计算
q += residual
# 层归一化,在512维度计算均值和方差,进行层归一化
q = self.layer_norm(q)
return q, attn这个层就没啥说的了,非常简单,直接看代码吧:
class PositionwiseFeedForward(nn.Module):
''' A two-feed-forward-layer module '''
def __init__(self, d_in, d_hid, dropout=0.1):
super().__init__()
# 两个fc层,对最后的512维度进行变换
self.w_1 = nn.Linear(d_in, d_hid) # position-wise
self.w_2 = nn.Linear(d_hid, d_in) # position-wise
self.layer_norm = nn.LayerNorm(d_in, eps=1e-6)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
residual = x
x = self.w_2(F.relu(self.w_1(x)))
x = self.dropout(x)
x += residual
x = self.layer_norm(x)
return x最后,回顾下 𝑡𝑟𝑎𝑛𝑠𝑓𝑜𝑟𝑚𝑒𝑟 𝑒𝑛𝑐𝑜𝑑𝑒𝑟 的整体结构。
经过上文的梳理,我们已经基本了解了 𝑡𝑟𝑎𝑛𝑠𝑓𝑜𝑟𝑚𝑒𝑟 编码器的主要构成部分,我们下面用公式把一个 𝑡𝑟𝑎𝑛𝑠𝑓𝑜𝑟𝑚𝑒𝑟 𝑏𝑙𝑜𝑐𝑘 的计算过程整理一下:
1) 字向量与位置编码
$$X= EmbeddingLookup (X)+ PositionalEncoding$$
$$X \in \mathbb{R}^{\text {batch size } * \text { seq. len. * embed.dim. }}$$
2) 自注意力机制
$$
Q=\operatorname{Linear}(X)=X W_{Q}
$$
$$
K=\operatorname{Linear}(X)=X W_{K}
$$
$$
V=\operatorname{Linear}(X)=X W_{V}
$$
$$
X_{\text {attention }}=\text { SelfAttention }(Q, K, V)
$$
3) 残差连接与层归一化
$$
X_{\text {attention }}=X+X_{\text {attention }}
$$
$$
X_{\text {attention }}=\text { Layer Norm }\left(X_{\text {attention }}\right)
$$
4) 前向网络
其实就是两层线性映射并用激活函数激活,比如说 ReLU :
$$
X_{\text {hidden }}=\operatorname{Activate}\left(\text { Linear }\left(\text { Linear }\left(X_{\text {attention }}\right)\right)\right)
$$
5) 重复3)
$$
X_{\text {hidden }}=X_{\text {attention }}+X_{\text {hidden }}
$$
$$
X_{\text {hidden }}=\text { Layer } N \text { orm }\left(X_{\text {hidden }}\right)
$$
$$
X_{\text {hidden }} \in \mathbb{R}^{\text {batch size } * \text { seq. len. } * \text { embed. dim. }}
$$
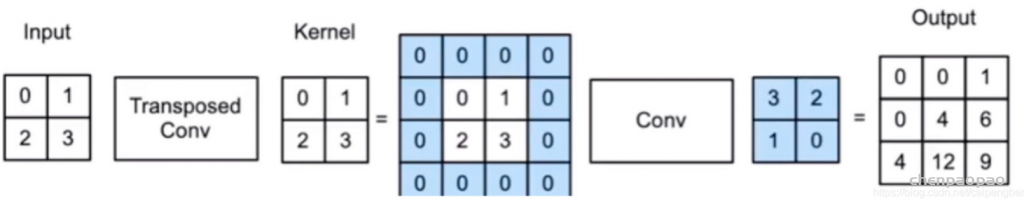
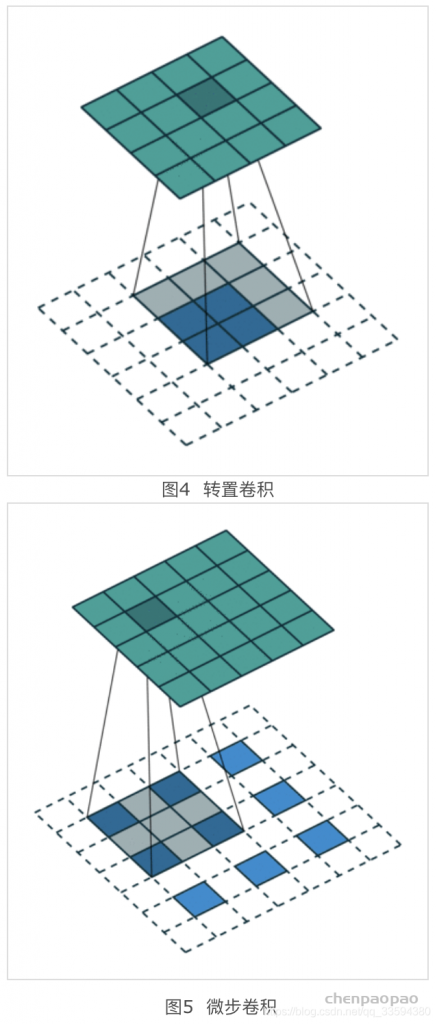
1、转置卷积 又可以称为 反卷积(数据从低维到高维)
转置卷积是一个将低维特征转换到高维特征。为什么叫做转置卷积呢?其实就是引入了转置的思想。
X= W.T · X 其中W.T的维度是(d,p),但是这两个W并不是同一个值,而是具有转置的形式而已。上面的例子是一维向量的情况,在卷积操作中,也可以借用这个思想,从低维到高维的转变可以在形式上看成是转置操作。
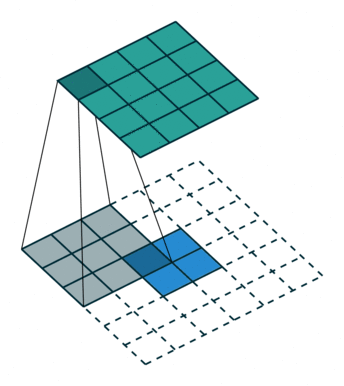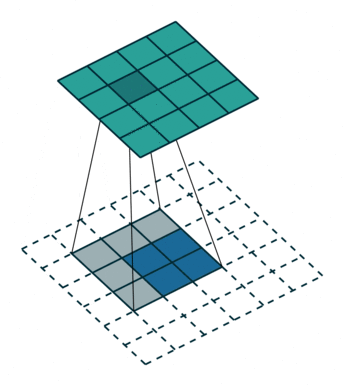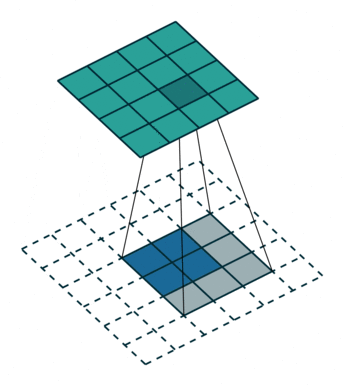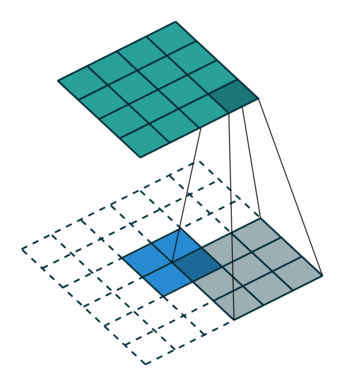
如上图所示,对2 * 2的特征映射先做(m-1) padding得到6 * 6的输入,然后对其进行3*3的卷积操作,从而得到4 * 4的特征映射。 同样,这个两个3 * 3的卷积参数不是一致的,都是可学习的。
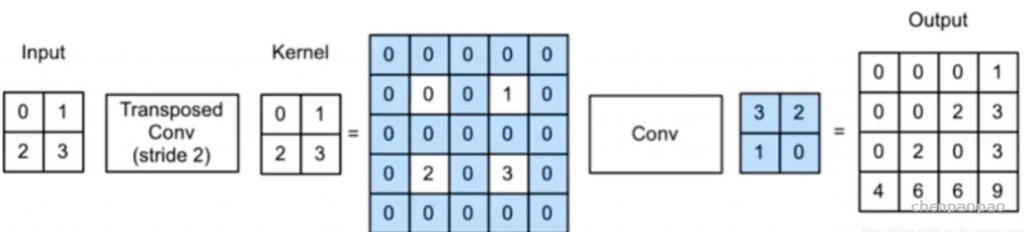
2、微步卷积(步长不为1的转置卷积(反卷积))
微步卷积其实是一个转置卷积的一个特殊情况,就是卷积操作的stride ≠ 1。因为在现实中,为了大幅度降低特征维数,卷积的步长会大于1。同样,为了大幅度提高特征维度,我们也可以用通过卷积来实现,这种卷积stride < 1 ,所以叫做微步卷积。
stride=2),从而我得到的特征输出为2 * 2.
跟转置卷积一样,先对2 * 2的输入做(m-1)padding ,然后再在特征之间插入stride -1个0,从而得到一个7 * 7的特征输入,然后对其做3 * 3 的卷积操作,得到5 * 5的特征输出。
如何计算反卷积:
当输入的矩阵高宽为n,核大小为k,padding为p,stride为s
1、当填充为0步长为1时
将输入填充 k − 1 。(k是 卷积核大小)
将核矩阵上下,左右翻转。
之后正常做填充为0(无填充),步幅为1的卷积。
2 当填充为 p 步幅为1时
将输入填充 k − p − 1 。
将核矩阵上下,左右翻转。
之后正常做填充为0,步幅为1的卷积。

3 当填充为 p pp 步幅为s ss时
在行和列之间插入s − 1 行和列。
将输入填充 k − p − 1。
将核矩阵上下,左右翻转。
之后正常做填充为0,步幅为1的卷积。
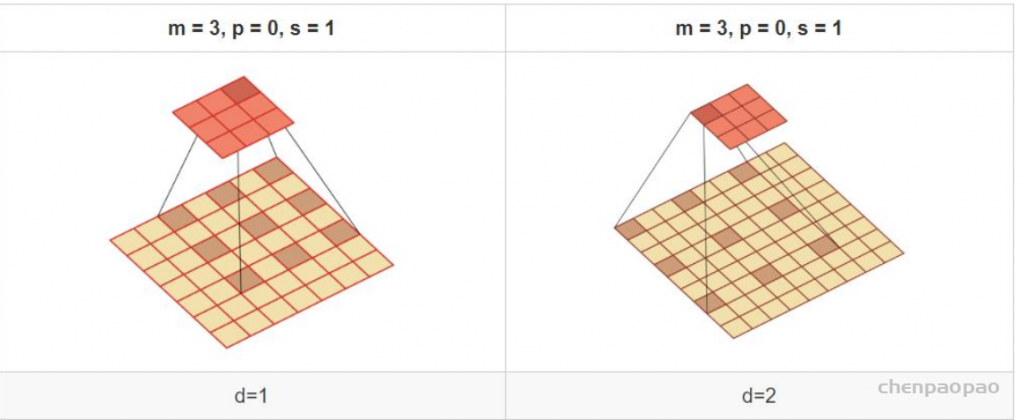
3、空洞卷积(膨胀卷积)
通常来说,对于一个卷积层,如果希望增加输出单元的感受野,一般由三个方式:
其中1和2都会增加参数量,而3会丢失特征信息。这样我们就可以引入‘空洞卷积’的概念,它不增加参数量,同时它也可以增加输出的感受野。
它主要是通过给卷积核插入空洞来增加其感受野大小,如果卷积核每两个元素之间插入d-1个空洞,那么卷积核的有效大小为:M = m + (m-1)*(d-1)


DCGAN 的判别器和生成器都使用了卷积神经网络(CNN)来替代GAN 中的多层感知机,同时为了使整个网络可微,拿掉了CNN 中的池化层,另外将全连接层以全局池化层替代以减轻计算量。
从上图中可以看到,生成器G 将一个100 维的噪音向量扩展成64 * 64 * 3 的矩阵输出,整个过程采用的是微步卷积的方式。作者在文中将其称为fractionally-strided convolutions,并特意强调不是deconvolutions。
去卷积(链接:反卷积)又包含转置卷积和微步卷积,两者的区别在于padding 的方式不同,看看下面这张图片就可以明白了:
DCGAN 的训练方法跟GAN 是一样的,分为以下三步:
(1)for k steps:训练D 让式子【logD(x) + log(1 – D(G(Z)) (G keeps still)】的值达到最大
(2)保持D 不变,训练G 使式子【logD(G(z))】的值达到最大
(3)重复step(1)和step(2)直到G 与D 达到纳什均衡
DCGAN 相比于GAN 或者是普通CNN 的改进包含以下几个方面:
(1)使用卷积和去卷积代替池化层
(2)在生成器和判别器中都添加了批量归一化操作
(3)去掉了全连接层,使用全局池化层替代
(4)生成器的输出层使用Tanh 激活函数,其他层使用RELU
(5)判别器的所有层都是用LeakyReLU 激活函数
通过使用插值微调噪音输入z 的方式可以导致隐空间结构发生变化从而引导生成图像发生语义上的平滑过度,比如说从有窗户到没窗户,从有电视到没电视等等。

通过标注窗口,并判断激活神经元是否在窗口内的方式来找出影响窗户形成的神经元,将这些神经元的权重设置为0,那么就可以导致生成的图像中没有窗户。从下图可以看到,上面一行图片都是有窗户的,下面一行通过语义遮罩的方式拿掉了窗户,但是空缺的位置依然是平滑连续的,使整幅图像的语义没有发生太大的变化。

在向量算法中有一个很经典的例子就是【vector(“King”) – vector(“Man”) + vector(“Woman”) = vector(“Queue”)】,作者将该思想引入到图像生成当中并得到了以下实验结果:【smiling woman – neutral woman + neutral man = smiling man】

| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 | |||||
CycleGAN、pix2pix、iGAN的主要贡献者最近在NIPS 2017上又推出了一篇文章Toward Multimodal Image-to-Image Translation(见https://junyanz.github.io/BicycleGAN/,https://arxiv.org/pdf/1711.11586.pdf),讨论如何从一张图像同时转换为多张风格不一成对的图像。
Pix2pix 和 CycleGAN 是非常的流行GAN,不仅在学术界有许多变体,同时也有许多基于此的应用。但是,它们都有一个缺点——图像的输出看起来几乎总是相同的。例如,如果我们要执行斑马到马的转换,被转换的同一马的照片将始终具有相同的外观和色调。这是由于GAN固有的特性,它学会过滤了噪声的随机性。
像pix2pix这样的图像转换(一对一)的方式是存在歧义的,因为不可能只对应一个输出。因此作者提出了一种一对多的输出,即将可能输出的图像是存在一定的分布特性的。

论文的主要方法如下图所示:

下图是 BicycleGAN 相关的模型和配置。图(a)是推理的配置,图像A与噪声相结合以生成图像B ^ ,可以将此看作是 cGAN 。在BicyleGAN中,形状为(256, 256, 3)的图像A是条件,而从潜在编码 z采样的噪声为大小为8的一维向量。图(b)是 pix2pix + 噪声 的训练配置。而图(c) 和 图(d) 的两个配置由 BicycleGAN 训练时使用:

简而言之,BicycleGAN 可以找到潜在编码z与目标图像B之间的关系,因此生成器可以在给定不同的z时学会生成不同的图像B ^ 。如上图所示,BicycleGAN 通过组合 cVAE-GAN 和 cLR-GAN 这两种模型来做到这一点。
cVAE-GAN
VAE-GAN 的作者认为,L1 损失并不是衡量图像视觉质量的良好指标。例如,如果图像向右移动几个像素,则人眼看起来可能没有什么不同,但会导致较大的L1损失。因此使用 GAN 的鉴别器来学习目标函数,以判断伪造的图像是否真实,并使用 VAE 作为生成器,生成的图像更清晰。如果忽略上图(c)中的图像 A ,那就是 VAE-GAN ,由于以 A 为条件,其成为条件 cVAE-GAN 。训练步骤如下:
训练中的数据流为 B − > z − > B ^ ( 图(c) 中的实线箭头),总的损失函数由三个损失组成:
对抗损失 \(L_{GAN}^{VAE}\)
L1重建损失 \(L_{1}^{VAE}(G)\)
KL散度损失 \(L_{KL}(E)\)
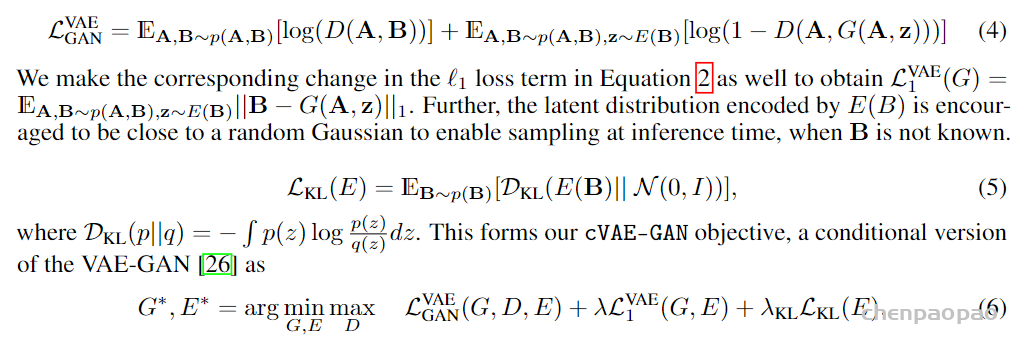
cLR-GAN(Conditional Latent Regressor GAN)
在 cVAE-GAN 中,对真实图像B进行编码,以提供潜在矢量的真实样本并从中进行采样。但是,cLR-GAN 的处理方式有所不同,其首先使用生成器从随机噪声中生成伪图像 B^,然后对伪图像 B^ 进行编码,最后计算其与输入随机噪声差异。
前向计算步骤如下:
首先,类似于 cGAN ,随机产生一些噪声,然后串联图像A以生成伪图像 B ^ ,之后,使用来自 VAE-GAN 的同一编码器将伪图像 B ^ 编码为潜矢量。
最后,从编码的潜矢量中采样 z ^ ,并用输入噪声 z 计算损失。数据流为 z −> B ^ −> z ^ ( 图(d) 中的实线箭头),有两个损失:
对抗损失 \(L_{GAN}\)
噪声 N(z) 与潜在编码之间的 L1损失 \(L_{1}^{latent}\)
通过组合这两个数据流,在输出和潜在空间之间得到了一个双映射循环。 BicycleGAN 中的 bi 来自双映射(双向单射),这是一个数学术语,简单来说其表示一对一映射,并且是可逆的。在这种情况下,BicycleGAN 将输出映射到潜在空间,并且类似地从潜在空间映射到输出。总损失如下:
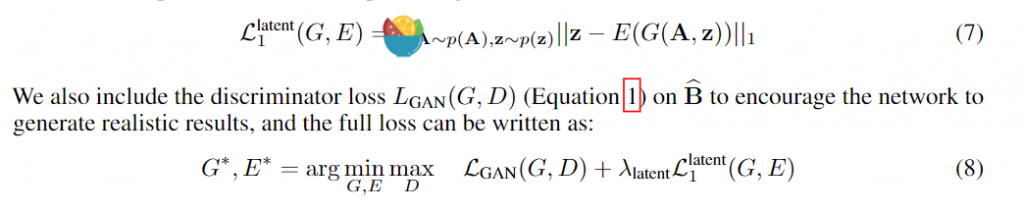
最总的损失:

可以分为两块来理解,第一块就是cVAE-GAN的训练,我们分析的基础就是鞋子纹理风格生成为例。
鞋子纹理图片经过编码器得到编码后的latent z通过KL距离将其拉向我们事先定义好的分布N(z)上,将服从分布的z与鞋子草图A结合后送入生成器G中得到重构的鞋子纹理图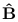 。 此时为了衡量重构和真实的误差,这里用了L1损失和GAN的对抗思想实现,我们在后面损失函数分析部分再说。这样cVAE-GAN部分就可以训练了,cVAE GAN的重点还是在得到的embedding z。
。 此时为了衡量重构和真实的误差,这里用了L1损失和GAN的对抗思想实现,我们在后面损失函数分析部分再说。这样cVAE-GAN部分就可以训练了,cVAE GAN的重点还是在得到的embedding z。
另一块就是cLR-GAN的训练,将鞋子草图A和分布N(z)结合经过生成器G得到鞋子纹理图, 再通过对生成的纹理图编码后得到的z去趋近分布N(z)来反向矫正生成图,达到一个变相的循环。
当这两部分训练的很好时,这个就是我们需要的BicycleGAN了,在检验训练效果时我们只需要,输入A加上N(z)就可以生成鞋子的纹理图了, 这个N(z)具体为什么怎么取将决定生成为纹理的风格了。
一些细节

pytorch代码:https://github.com/junyanz/BicycleGAN
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 | |||||
来源:磐创AI分享
https://ezyang.github.io/convolution-visualizer/index.html
这种交互式可视化演示了各种卷积参数如何影响输入、权重和输出矩阵之间的形状和数据依赖性。将鼠标悬停在输入/输出上将突出显示相应的输出/输入,而将鼠标悬停在权重上将突出显示哪些输入与该权重相乘以计算输出。(严格来说,这里可视化的操作是相关性,而不是卷积,因为真正的卷积在执行相关性之前会翻转其权重。但是,大多数深度学习框架仍然称这些卷积,最终与梯度下降相同.)
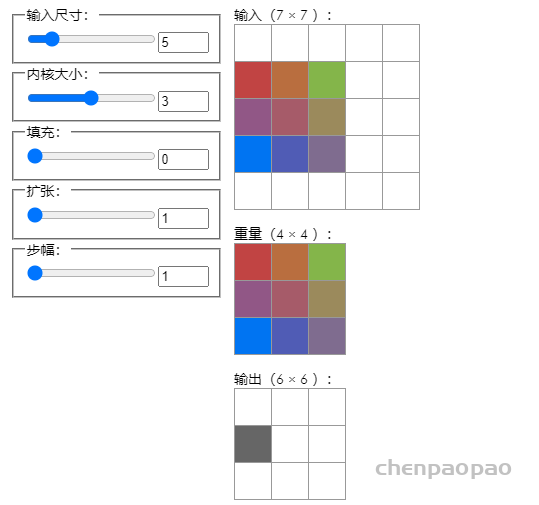
https://docs.wandb.ai/v/zh-hans/
Weights & Biases 可以帮助跟踪你的机器学习项目。使用我们的工具记录运行中的超参数和输出指标(Metric),然后对结果进行可视化和比较,并快速与同事分享你的发现。
通过wandb,能够给你的机器学习项目带来强大的交互式可视化调试体验,能够自动化记录Python脚本中的图标,并且实时在网页仪表盘展示它的结果,例如,损失函数、准确率、召回率,它能够让你在最短的时间内完成机器学习项目可视化图片的制作。
总结而言,wandb有4项核心功能:
看板:跟踪训练过程,给出可视化结果
报告:保存和共享训练过程中一些细节、有价值的信息
调优:使用超参数调优来优化你训练的模型
工具:数据集和模型版本化
也就是说,wandb并不单纯的是一款数据可视化工具。它具有更为强大的模型和数据版本管理。此外,还可以对你训练的模型进行调优。
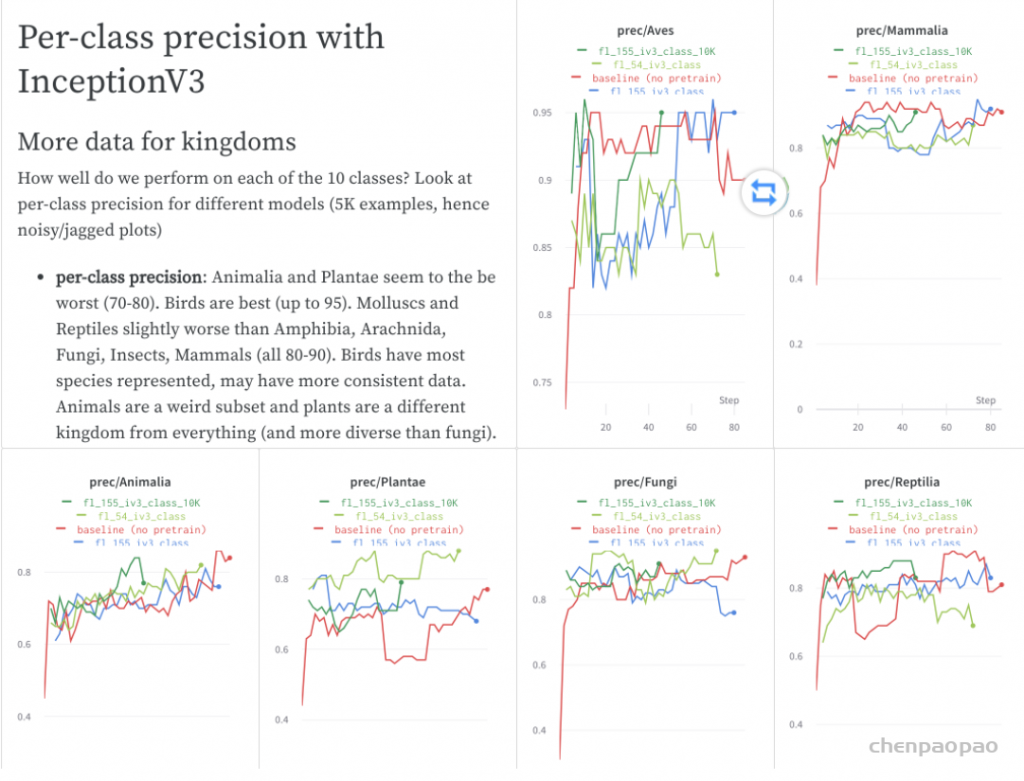
一个用于画卷积神经网络的Python脚本
https://github.com/gwding/draw_convnet
http://alexlenail.me/NN-SVG/LeNet.html
https://github.com/HarisIqbal88/PlotNeuralNet
https://www.tensorflow.org/tensorboard/graphs
https://github.com/BVLC/caffe/blob/master/python/caffe/draw.py
http://www.mathworks.com/help/nnet/ref/view.html
https://transcranial.github.io/keras-js/#/inception-v3
https://github.com/martisak/dotnets
http://www.graphviz.org/
https://conx.readthedocs.io/en/latest/index.html
https://wagenaartje.github.io/neataptic/
在PyTorch深度学习中,最常用的模型可视化工具是Facebook(中文为脸书,目前已改名为Meta)公司开源的Visdom
Visdom可以直接接受来自PyTorch的张量,而不用转化成NumPy中的数组,从而运行效率很高。此外,Visdom可以直接在内存中获取数据,毫秒级刷新,速度很快。
Visdom的安装很简单,直接执行以下命令即可:
pip install visdom
开启服务,因为visdom本质上是一个类似于Jupyter Notebook 的Web服务器,在使用之前需要在终端打开服务,代码如下:
python -m visdom.server
正常执行后,根据提示在浏览器中输入相应地址即可,默认地址为:
http://localhost:8097/
本例通过使用PyTorch的可视化工具Visdom对手写数字数据集进行建模。
步骤1:先导入模型需要的包,代码如下。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from visdom import Visdom
步骤2:定义训练参数,代码如下。
batch_size=200
learning_rate=0.01
epochs=10
… …
执行成功后,在visdom网页可以看到实时更新的训练过程的数据变化,每一个epoch测试数据更新一次,如图9-15所示。
Visdom是由Plotly 提供的可视化支持,所以提供一下可视化的接口:
更新损失函数
在训练的时候我们每一批次都会打印一下训练的损失和测试的准确率,这样展示的图表是需要动态增加数据的,下面我们来模拟一下这种情况:
x,y=0,0
env2 = Visdom()
pane1= env2.line(
X=np.array([x]),
Y=np.array([y]),
opts=dict(title='dynamic data'))Setting up a new session…
for i in range(10):
time.sleep(1) #每隔一秒钟打印一次数据
x+=i
y=(y+i)*1.5
print(x,y)
env2.line(
X=np.array([x]),
Y=np.array([y]),
win=pane1,#win参数确认使用哪一个pane
update='append') #我们做的动作是追加pytorch也支持tensorboard的使用:
Tensorboard的工作流程简单来说是
这一步由代码中的writer完成这一步通过在命令行运行tensorboard完成。官方:
https://pytorch.org/docs/stable/tensorboard.html?highlight=tensorboard
其中可视化的主要功能如下:
(1)Scalars:展示训练过程中的准确率、损失值、权重/偏置的变化情况。
(2)Images:展示训练过程中记录的图像。
(3)Audio:展示训练过程中记录的音频。
(4)Graphs:展示模型的数据流图,以及训练在各个设备上消耗的内存和时间。
(5)Distributions:展示训练过程中记录的数据的分部图。
(6)Histograms:展示训练过程中记录的数据的柱状图。
(7)Embeddings:展示词向量后的投影分部。
步骤1:首先导入相关的第三方包,代码如下。
import numpy as np
from torch.utils.tensorboard import SummaryWriter
步骤2:将loss写到Loss_Accuracy路径下面,代码如下。
np.random.seed(10)
writer = SummaryWriter(‘runs/Loss_Accuracy’)
步骤3:然后将loss写到writer中,其中add_scalars()函数可以将不同的变量添加到同一个图,代码如下。
for n_iter in range(100):
writer.add_scalar(‘Loss/train’, np.random.random(), n_iter)
writer.add_scalar(‘Loss/test’, np.random.random(), n_iter)
writer.add_scalar(‘Accuracy/train’, np.random.random(), n_iter)
writer.add_scalar(‘Accuracy/test’, np.random.random(), n_iter)
首先导入tensorboard
from torch.utils.tensorboard import SummaryWriter 这里的SummaryWriter的作用就是,将数据以特定的格式存储到刚刚提到的那个文件夹中。
首先我们将其实例化
writer = SummaryWriter('./path/to/log')这里传入的参数就是指向文件夹的路径,之后我们使用这个writer对象“拿出来”的任何数据都保存在这个路径之下。
这个对象包含多个方法,比如针对数值,我们可以调用
writer.add_scalar(tag, scalar_value, global_step=None, walltime=None)这里的tag指定可视化时这个变量的名字,scalar_value是你要存的值,global_step可以理解为x轴坐标。
举一个简单的例子:
for epoch in range(100)
mAP = eval(model)
writer.add_scalar('mAP', mAP, epoch)这样就会生成一个x轴跨度为100的折线图,y轴坐标代表着每一个epoch的mAP。这个折线图会保存在指定的路径下(但是现在还看不到)
同理,除了数值,我们可能还会想看到模型训练过程中的图像。
writer.add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')
writer.add_images(tag, img_tensor, global_step=None, walltime=None, dataformats='NCHW')我们已经将关心的数据拿出来了,接下来我们只需要在命令行运行:
tensorboard --logdir=./path/to/the/folder --port 8123然后打开浏览器,访问地址http://localhost:8123/即可。这里的8123只是随便一个例子,用其他的未被占用端口也没有任何问题,注意命令行的端口与浏览器访问的地址同步。
如果发现不显示数据,注意检查一下路径是否正确,命令行这里注意是
--logdir=./path/to/the/folder 而不是
--logdir= './path/to/the/folder '另一点要注意的是tensorboard并不是实时显示(visdom是完全实时的),而是默认30秒刷新一次。
命名变量的时候可以使用形如
writer.add_scalar('loss/loss1', loss1, epoch)
writer.add_scalar('loss/loss2', loss2, epoch)
writer.add_scalar('loss/loss3', loss3, epoch)的格式,这样3个loss就会被显示在同一个section。
假如使用了两种学习率去训练同一个网络,想要比较它们训练过程中的loss曲线,只需要将两个日志文件夹放到同一目录下,并在命令行运行
tensorboard --logdir=./path/to/the/root --port 8123