
https://mp.weixin.qq.com/s/VazobOgY9QVaADpEur81ng https://bbs.huaweicloud.com/blogs/344188
分类: 计算机网络
Elasticsearch
ES既是搜索引擎又是数据库:ElasticSearch究竟是不是数据库?历来存在争议.它是搜索引擎,千真万确,而它是数据库,需要看数据库的界定范围.广义上讲,关系型数据库,对象型数据库,搜索引擎,文件,都可以算作是数据库.数据库是用来存储数据的,为服务应用提供了数据的读写功能,即数据的添加,修改,删除,查询四种基本功能.
1.关系型数据库,诸如:transact-sql,plsql,mysql,firebird,maria等,具备了增删改查四种基本功能.
2.对象型数据库,诸如:redis,mongo等,也具备了增删改查四种基本功能.
3.搜索引擎,就是提到的elasticsearch,也具备了增删改查四种基本功能.
4.文件,比如:sqlite,也具备了增删改查四种基本功能.
ES: 基于Lucene框架的搜索引擎产品。you know for search. 提供了restful风格的操作接口。
ELK,日志检索
Lucene:是一个非常高效的全文检索引擎框架。Java开发的,只提供单机功能。
ES的一些核心概念:
1、索引index:关系型数据库中的table
2、文档document:行
3、字段 field text/keyword/byte:列
4、映射Mapping: Schema
5、查询方式 DSL:SQL ES新版本也支持SQL
6、分片sharding和副本replicas:index都是由sharding组成的。每个sharding都有一个或多个备份。ES集群健康状态。
1)Elasticsearch是搜索引擎
Elasticsearch在搜索引擎数据库领域排名绝对第一,内核基于Lucene构建,支持全文搜索是职责所在,提供了丰富友好的API。个人早期基于Lucene构建搜索应用,需要考虑的因素太多,自接触到Elasticsearch就再无自主开发搜索应用。普通工程师要想掌控Lucene需要一些代价,且很多机制并不完善,需要做大量的周边辅助程序,而Elasticsearch几乎都已经帮你做完了。
2)Elasticsearch不是搜索引擎
说它不是搜索引擎,估计很多从业者不认可,在个人涉及到的项目中,传统意义上用Elasticsearch来做全文检索的项目占比越来越少,多数时候是用来做精确查询加速,查询条件很多,可以任意组合,查询速度很快,替代其它很多数据库复杂条件查询的场景需求;甚至有的数据库产品直接使用Elasticsearch做二级索引,如HBase、Redis等。Elasticsearch由于自身的一些特性,更像一个多模数据库。
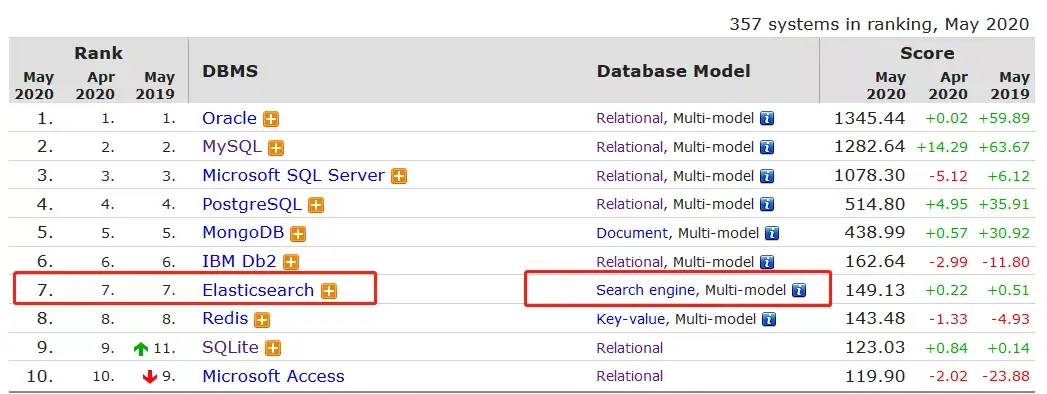
图示:Elasticsearch综合数据库排名热度已经到第7
3)Elasticsearch是数据库
Elasticsearch使用Json格式来承载数据模型,已经成为事实上的文档型数据库,虽然底层存储不是Json格式,同类型产品有大名鼎鼎的MongoDB,不过二者在产品定位上有差别,Elasticsearch更加擅长的基于查询搜索的分析型数据库,倾向OLAP;MongoDB定位于事务型应用层面OLTP,虽然也支持数据分析,笔者简单应用过之后再无使用,谁用谁知道。
4)Elasticsearch不是数据库
Elasticsearch不是关系型数据库,内部数据更新采用乐观锁,无严格的ACID事务特性,任何企图将它用在关系型数据库场景的应用都会有很多问题,很多其它领域的从业者喜欢拿这个来作为它的缺陷,重申这不是Elasticsearch的本质缺陷,是产品设计定位如此。

图示:Elastic擅长的应用场景
2、ES做什么
Elasticsearch虽然是基于Lucene构建,但应用领域确实非常宽泛。
1)全文检索
Elasticsearch靠全文检索起步,将Lucene开发包做成一个数据产品,屏蔽了Lucene各种复杂的设置,为开发人员提供了很友好的便利。很多传统的关系型数据库也提供全文检索,有的是基于Lucene内嵌,有的是基于自研,与Elasticsearch比较起来,功能单一,性能也表现不是很好,扩展性几乎没有。
如果,你的应用有全文检索需求,建议你优先迁移到Elasticsearch平台上来,其提供丰富的Full text queries会让你惊讶,一次用爽,一直用爽。
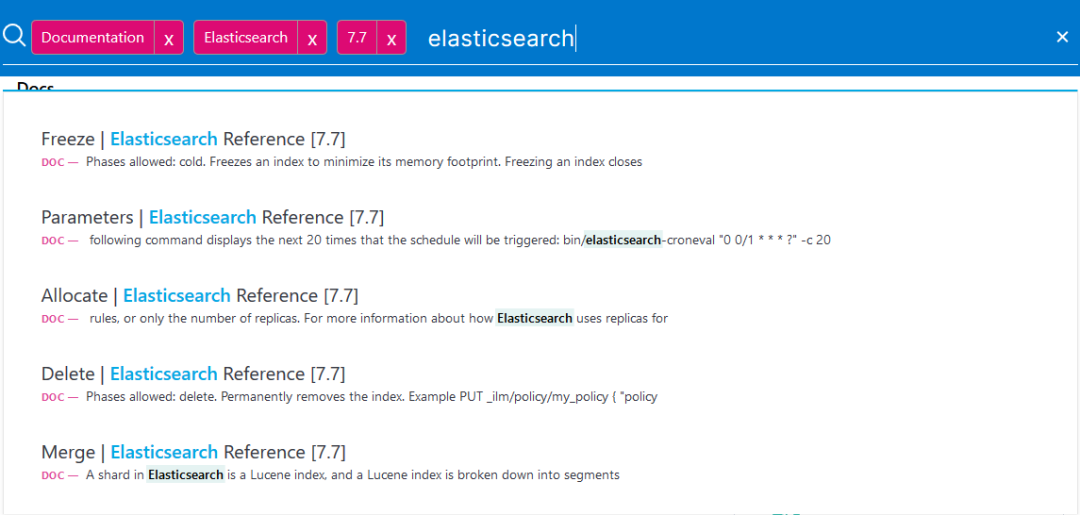
图示:Elasticsearch官方搜索文档
2)应用查询
Elasticsearch最擅长的就是查询,基于倒排索引核心算法,查询性能强于B-Tree类型所有数据产品,尤其是关系型数据库方面。当数据量超过千万或者上亿时,数据检索的效率非常明显。
个人更看中的是Elasticsearch在通用查询应用场景,关系型数据库由于索引的左侧原则限制,索引执行必须有严格的顺序,如果查询字段很少,可以通过创建少量索引提高查询性能,如果查询字段很多且字段无序,那索引就失去了意义;相反Elasticsearch是默认全部字段都会创建索引,且全部字段查询无需保证顺序,所以我们在业务应用系统中,大量用Elasticsearch替代关系型数据库做通用查询,自此之后对于关系型数据库的查询就很排斥,除了最简单的查询,其余的复杂条件查询全部走Elasticsearch。
3)大数据领域
Elasticserach已经成为大数据平台对外提供查询的重要组成部分之一。大数据平台将原始数据经过迭代计算,之后结果输出到一个数据库提供查询,特别是大批量的明细数据。
这里会面临几个问题,一个问题是大批量明细数据的输出,如何能在极短的时间内写到数据库,传统上很多数据平台选择关系型数据库提供查询,比如MySQL,之前在这方面吃过不少亏,瞬间写入性能极差,根本无法满足要求。另一个问题是对外查询,如何能像应用系统一样提供性能极好的查询,不限制查询条件,不限制字段顺序,支持较高的并发,支持海量数据快速检索,也只有Elasticsearch能够做到比较均衡的检索。
从官方的发布版本新特性来看,Elasticseacrch志在大数据分析领域,提供了基于列示存储的数据聚合,支持的聚合功能非常多,性能表现也不错,笔者有幸之前大规模深度使用过,颇有感受。
Elasticsearch为了深入数据分析领域,产品又提供了数据Rollup与数据Transform功能,让检索分析更上一层楼。在数据Rollup领域,Apache Druid的竞争能力很强,笔者之前做过一些对比,单纯的比较确实不如Druid,但自Elasticsearch增加了Transfrom功能,且单独创建了一个Transfrom的节点角色,个人更加看好Elasticseach,跳出了Rollup基于时间序列的限制。

图示:Rollup执行过程数据转换示意图
4)日志检索
著名的ELK三件套,讲的就是Elasticsearch,Logstash,Kibana,专门针对日志采集、存储、查询设计的产品组合。很多第一次接触到Elasticsearch的朋友,都会以为Elasticsearch是专门做日志的,其实这些都是误解,只是说它很擅长这个领域,在此领域大有作为,名气很大。
日志自身特点没有什么通用的规范性,人为的随意性很大,日志内容也是任意的,更加需求全文检索能力,传统技术手段本身做全文检索很是吃力。而Elasticsearch本身起步就是靠全文检索,再加上其分布式架构的特性,非常符合海量日志快速检索的场景。今天如果还发现有IT从业人员用传统的技术手段做日志检索,应该要打屁股了。
如今已经从ELK三件套发展到Elastic Stack了,新增加了很多非常有用的产品,大大增强了日志检索领域。
5)监控领域
指标监控,Elasticsearch进入此领域比较晚,却赶上了好时代,Elasticsearch由于其倒排索引核心算法,也是支持时序数据场景的,性能也是相当不错的,在功能性上完全压住时序数据库。
Elasticsearch搞监控得益于其提供的Elastic Stack产品生态,丰富完善,很多时候监控需要立体化,除了指标之外,还需要有各种日志的采集分析,如果用其它纯指标监控产品,如Promethues,遇到有日志分析的需求,还必须使用Elasticsearch,这对于技术栈来说,又扩增了,相应的掌控能力会下降,个人精力有限,无法同时掌握很多种数据产品,如此选择一个更加通用的产品才符合现实。
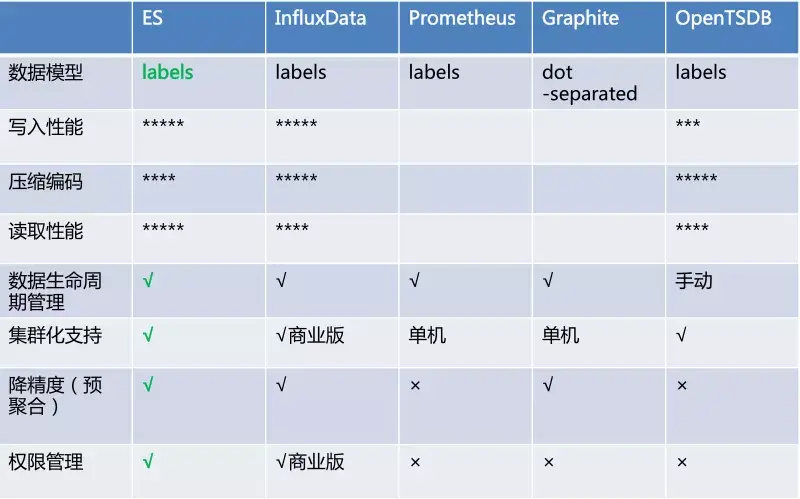
图示 :Elastic性能对比时序数据库(来自腾讯云分享)
6)机器学习
机器学习最近几年风吹的很大,很多数据产品都集成了,Elasticsearch也必须有,而且做的更好,真正将机器学习落地成为一个产品 ,简化使用,所见所得;而不像其它数据产品,仅仅集成算法包,使用者还必须开发很多应用支持。
Elasticsearch机器学习提供了两种方式,一种是异常检测类型,属于无监督学习,采用聚类模型,通常应用在安全分析领域,检测异常访问等;一种是数据帧分析,属于分类与回归,属于监督学习,可用于在业务模型领域,如电商行业,价格模型分析。
Elasticsearch本身是数据平台,集成了部分机器学习算法,同时又集成了Kibana可视化操作,使得从数据采集、到模型训练、到模型预测应用都可以一键式完成。
Elasticserach提供的机器学习套件,个人认为最应该应用在数据质量这个领域,帮助大数据平台自动检测数据质量,从而降低人力提供效率。
图示 :机器学习应用示意图(截图)
需求等级
Elasticsearch整个的技术栈非常复杂,涉及到的理论与技术点非常多,完全掌握并不现实,作为一个IT从业者,首先是定位好自己的角色,依据角色需求去学习掌握必备的知识点。以下是笔者对于一个技术产品的划分模型:
1、概念
Elasticsearch涉及到的概念很多,核心概念其实就那么几个,对于一个新手来说,掌握概念目的是为了建立起自己的知识思维模型,将之后学习到的知识点做一个很好的归纳划分;对于一个其它数据产品的老手来说 ,掌握概念的目的是为了与其它数据产品划分比较,深入的了解各自的优劣,在之后工作中若有遇到新的业务场景,可以迅速做出抉择。
IT从业者普遍都有个感受,IT技术发展太快了,各种技术框架产品层出不穷,学习掌握太难了,跟不上节奏。其实个人反倒觉得变化不大,基础理论核心概念并没有什么本质的发展变化,无非是工程技术实操变了很多,但这些是需要深入实践才需要的,对于概念上无需要。
作为一个技术总监,前端工程师工作1~2年的问题都可以问倒他,这是大家对于概念认知需求不一样。

图示:Elasticsearch核心概念
2、开发
开发工程师的职责是将需求变成可以落地运行的代码。Elasticsearch的应用开发工作总结起来就是增删改查,掌握必备的ES REST API,熟练运用足以。笔者之前任职某物流速运公司,负责Elasticsearch相关的工作,公司Elasticsearch的需求很多,尤其是查询方面,ES最厉害的查询是DSL,这个查询语法需要经常练习使用,否则很容易忘记,当每次有人询问时,都安排一个工程师专门负责各种解答,他在编写DSL方面非常熟练,帮助了很多的工程师新手使用Elasticsearch,屏蔽了很多细节,若有一些难搞定的问题,会由我来解决,另外一方面作为负责人的我偶然还要请他帮忙编写DSL。
Elasticsearch后面提供了SQL查询的功能,但比较局限,复杂的查询聚合必须回到DSL。

图示:DSL语法复杂度较高
3、架构
Elasticsearch集群架构总体比较复杂,首先得深入了解Elasticseach背后实现的原理,包括集群原理、索引原理、数据写入过程、数据查询过程等;其次要有很多案例实战的机会,遇到很多挑战问题 ,逐一排除解决,增加自己的经验。
对于开发工程师来说,满足日常需求开发无需掌握这些,但对于Elasticsearch技术负责人,就非常有必要了,面对各种应用需求,要能从架构思维去平衡,比如日志场景集群需求、大数据分析场景需求、应用系统复杂查询场景需求等,从实际情况设计集群架构以及资源分配等。
4、运维
Elasticsearch本质是一个数据库,也需要有专门的DBA运维,只是更偏重应用层面,所以运维职责相对传统DBA没有那么严苛。对于集群层面必须掌握集群搭建,集群扩容、集群升级、集群安全、集群监控告警等;另外对于数据层面运维,必须掌握数据备份与还原、数据的生命周期管理,还有一些日常问题诊断等。
5、源码
Elasticsearch本身是开源,阅读源码是个很好的学习手段,很多独特的特性官方操作文档并没有写出来,需要从源码中提炼,如集群节点之间的连接数是多少,但对于多数Elasticsearch从业者来说,却非必要。了解到国内主要是头部大厂需要深入源码定制化改造,更多的是集中在应用的便捷性改造,而非结构性的改造,Elastic原厂公司有几百人的团队做产品研发,而国内多数公司就极少的人,所以从产量上来说,根本不是一个等级的。
如果把Elasticsearch比喻为一件军事武器,对于士兵来说 ,熟练运用才是最重要的,至于改造应该是武器制造商的职责,一个士兵可以使用很多武器装备,用最佳的组合才能打赢一场战争,而不是去深入原理然后造轮子,容易本末倒置。
6、算法
算法应该算是数据产品本质的区别,关系型数据库索引算法主要是基于B-Tree, Elasticserach索引算法主要是倒排索引,算法的本质决定了它们的应用边界,擅长的应用领域。
通常掌握一个新的数据产品时,个人的做法是看它的关键算法。早期做过一个地理位置搜索相关的项目,基于某个坐标搜索周边的坐标信息,开始的时候采用的是三角函数动态计算的方式,数据量大一点,扫描一张数据表要很久;后面接触到Geohash算法,按照算法将坐标编码,存储在数据库中,基于前缀匹配查询,性能高效几个数量级,感叹算法的伟大;再后面发现有专门的数据库产品集成了Geohash算法,使用起来就更简单了。
Elasticsearch集成很多算法,每种算法实现都有它的应用场景。
拥抱ES的方法
1、官方文档
Elasticsearch早期出过一本参考手册《Elastic权威指南》,是一本很好的入门手册,从概念到实战都有涉及,缺点是版本针对的2.0,过于陈旧,除去核心概念,其余的皆不适用,当前最新版本已经是7.7了,跨度太大,Elasticsearch在跨度大的版本之间升级稍微比较麻烦,索引数据几乎是不兼容的,升级之后需要重建数据才可。
Elasticsearch当前最好的参考资料是官方文档,资料最全,同步发布版本,且同时可以参考多个版本。Elasticsearch官方参考文档也是最乱的,什么资料都有,系统的看完之后感觉仍在此山中,有点类似一本字典,看完了字典,依然写不好作文;而且资料还是英文的,至此就阻挡了国内大部分程序进入。
但想要学习Elasticsearch,官方文档至少要看过几遍,便于迅速查询定位。
图示:官方文档截图说明
2、系统学习
Elasticsearch成名很早,国内也有很多视频课程,多数比较碎片,或是纸上谈兵,缺乏实战经验。Elasticsearch有一些专门的书籍,建议购买阅读,国内深度一些的推荐《Elasticsearch源码解析与优化实战》,国外推荐《Elasticsearch实战》,而且看书还有助于培养系统思维。
Elasticsearch技术栈功能特性很多,系统学习要保持好的心态,持之以恒,需要很长时间,也需要参考很多资料。
3、背后原理
Elasticsearch是站在巨人肩膀上产品,背后借鉴了很多设计思想,集成了很多算法,官方的参考文档在技术原理探讨这块并没有深入,仅仅点到为止。想要深入了解,必须得另辟蹊径。
Elastic官方的博客有很多优质的文章,很多人因为英文的缘故会忽视掉,里面有很多关键的实现原理,图文并茂,写得非常不错;另外国内一些云厂商由于提供了Elasticsearch云产品,需要深度定制开发,也会有一些深入原理系列的文章,可以去阅读参考,加深理解。对于已经有比较好的编程思维的人,也可以直接去下载官方源码,设置断点调试阅读。
4、项目实战
项目实战是非常有效的学习途径,考过驾照的朋友都深有体会,教练一上来就直接让你操练车,通过很多次的练习就掌握了。Elasticsearch擅长的领域很多,总结一句话就是“非强事务ACID场景皆可适用”,所以可以做的事情也很多。
日志领域的需求会让你对于数据写入量非常的关心,不断的调整优化策略,提高吞吐量,降低资源消耗;业务系统的需求会让你对数据一致性与时效性特别关心,从其它数据库同步到ES,关注数据同步的速度,关注数据的准确性,不断的调整你的技术方案与策略;大数据领域的需求会让你对于查询与聚合特别关注,海量的数据需要快速的检索,也需要快速的聚合结果。
项目实战的过程,就是一个挖坑填坑的过程,实战场景多了,解决的问题多了,自然就掌握得很好了。
数据存储方案 –NAS
NAS(Network Attached Storage:网络附属存储),简单来说,就是个人或中小型企业私用的网络存储服务器。区别于百度云,坚果云等公有云存储,由于NAS的硬件是在本地放置,所以可以称为私有云。
简单解释NAS就是私人的7*24小时在线的存储服务器,1996年美国硅谷首先提出NAS概念,把存储设备和网络接口集成在一起,直接通过网络存取数据。网络附属存储(NAS)是一种专业的网络文件存储及文件备份设备。它通过自带的网络接口把存储设备直接连入到网络中,实现海量数据的网络共享,把应用程序服务器从繁重的I/O负载中解脱出来,从而把存储功能从通用文件服务器中分离出来,获得更高的存取效率,更低的存储成本。硬件层面上NAS就是一台电脑,但是跟普通电脑的技能点分配还是略有区别的。
1、 Network Attached Storage
NAS 的全称是 Network Attached Storage,翻译成中文就是网络附加存储。我们来拆解一下就是网络、附加、存储。存不需要过多的解释,就是来存储东西的。附加的意思就是这块存储可以轻松的附加上,或者取下而不影响系统使用。对比我们电脑上的硬盘,就不能说是附加的。因为电脑硬盘不能随便的取下,而且硬盘取下来之后你的电脑就没法用了。网络的意思是想要访问存储里面的内容,需要有网络才行,不管是公网还是局域网反正得有网。
简单来说,NAS 提供存储服务,可用通过网络来访问存储里面的内容。
2、超大容量
NAS 作为一台存储服务器,它的主要功能是存储,相比于我们普通的硬盘,NAS 最大的特点是存储空间共享,也就是网络访问。基于网络访问就可以实现其他很多功能如数据同步,照片备份,重要资料备份等等。NAS 的容量是很大的,一般都是以 T 为单位(1TB = 1024GB)。NAS 存储本身也是可以扩展的,通过累计叠加多个硬盘容量,可以扩大存储空间。NAS 系统一天 24 小时待命,没有用一会关机一会儿这种说法。因此 NAS 对磁盘的稳定性要求很高。
3、数据共享
任何设备,只要你能连上 NAS 并且赋予了访问权限,你就可以访问 NAS 中存储的数据。我们可以在手机、笔记本、iPad、智能电视上访问 NAS 中的数据。就像使用本地存储一样,非常的方便。NAS 的一个使用场景是办公共享,在一个局域网内可以实现办公的连续性。当文件在电脑被编辑保存之后,可以用 iPad 接着编辑。
4、安全存储
企业最看重这一点。安全对于企业来说,主要从两方面来讲,一是数据不能丢,而是数据不能泄露给别人。NAS 都具备强大的数据备份功能,可以提供安全不丢失的数据存储,这解决了上面的第一个问题;而解决第二个问题的方式也很简单,自己保存数据,不要用第三方的服务就行。
NAS 的使用场景:视频下载\备份手机上的照片,文件。
NAS有一个重要的功能,异地访问,现在的家庭用户基本都没有自己的公网IP,就算是有路由器,内网穿透,端口映射等等的设置也是相当繁琐的。当然成品NAS一般都有自己的中转服务器可以实现异地访问的功能,但是传输速度相当感人。
上网限制和翻墙的基本原理
相关文章:翻墙与科学上网全面解析 翻墙与科学上网
本文转载自:http://blog.021xt.cc/archives/85
目前在国内基本访问不了google站点和android的站点,下载个gradle都要等很久。所以如果不翻墙很多工作都没办法正常做。所以在学习翻墙的同时也顺便了解了下目前限制网络访问的一些基本知识。
网络限制和监控应该说大家都有体会。比如很多公司都会限制一些网站的访问,比如网盘、视屏网站。有时也会对你访问的内容进行监控。还有一些公共WIFI,可能限制你只能访问80端口。在比如在国内无法访问google,facebook,android等网站。要想绕过这些限制,必须先知道他们是如何限制的。
本文主要是从技术角度来了解的网络限制方式和应对方式。并不做任何翻墙方式的推荐和指导。对于网络的知识,还是停留在上过网络课 的水平,文章内容也都是自己了解后总结的。可能会有错误和遗漏。会定期更新。
DNS污染和劫持
以下解释来之百度百科:
某些网络运营商为了某些目的,对DNS进行了某些操作,导致使用ISP的正常上网设置无法通过域名取得正确的IP地址。
某些国家或地区出于某些目的为了防止某网站被访问,而且其又掌握部分国际DNS根目录服务器或镜像,也会利用此方法进行屏蔽。
目前我们访问网站主要都是通过域名进行访问,而真正访问这个网站前需要通过DNS服务器把域名解析为IP地址。而普通的DNS服务使用UDP协议,没有任何的认证机制。DNS劫持是指返回给你一个伪造页面的IP地址,DNS污染是返回给你一个不存在的页面的IP地址。
比如你使用电信、联通、移动的宽带,默认你是不需要设置任何DNS服务器的。这些DNS服务器由他们提供。一旦检测到你访问的网页是不允许的访问的,就会返回一个不存在的网页。而很多运营商也会使用DNS劫持来投放一些广告。
解决办法:
- 使用OpenDNS(208.67.222.222)或GoogleDNS(8.8.8.8)(现在不太好用,被封锁,速度慢)
- 使用一些第三方的DNS服务器
- 自己用VPS搭建DNS服务器
- 修改机器host文件,直接IP访问
封锁IP
通过上面一些方式,可以绕过DNS污染,通过IP地址访问无法访问的网页。但是目前针对IP进行大范围的封锁。虽然google这种大公司有很多镜像IP地址,但是目前基本全部被封锁掉,有漏网的可能也坚持不了多久。而且很多小公司的服务是部署在一些第三方的主机上,所以封锁IP有时会误伤,封锁一个IP导致主机上本来可以使用的页面也无法访问了。
不过目前不可能把所有国外的IP全部封锁掉,所以我们采用机会从国内连接到国外的VPS,进行翻墙。
解决办法:
- 使用VPS搭建代理
- 使用IPV6 (IPV6地址巨大,采用封地址不现实,但是目前国内只有部分高校部署了IPV6)
封锁HTTP代理
对于没有办法搭建VPS的人来说,最好的办法就是使用HTTP代理。客户端不在直接请求目标服务器,而是请求代理服务器,代理服务器在去请求目标服务器。然后返回结果。关于HTTP代理可以参考
| 1 | 《HTTP权威指南》第六章:代理 |
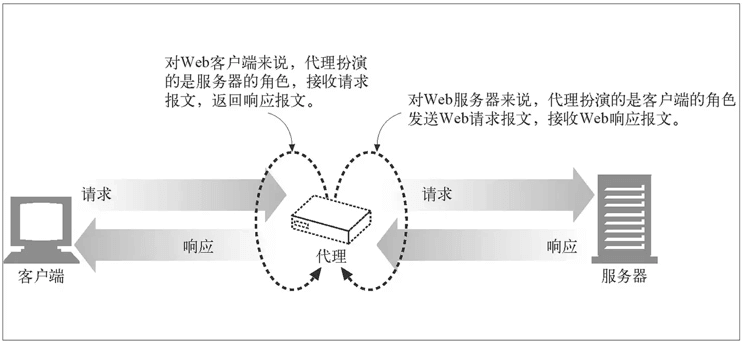
对于HTTP代理来说,封锁起来非常简单。因为HTTP协议是明文,Request Message中就带有要请求的URL或IP地址,这样很容易就被检测到。对于HTTPS来说,虽然通信是进行加密了,但是在建连之前会给代理服务器发送CONNECT方法,这里也会带上要访问的远端服务器地址。如果代理服务器在国外,在出去前就会被检测到。 如果代理服务器在国内,呵呵,你也出不去啊。
对于HTTP代理,因为是明文,所以很容易被服务器了解你的一些数据。所以不要随便使用第三方的HTTP代理访问HTTP网站,而HTTPS虽然不知道你的数据,但是可以知道你去了那里。
解决办法:
- 使用VPS搭建VPN
- 使用第三方VPN
封锁VPN
虚拟专用网(英语:Virtual Private Network,简称VPN),是一种常用于连接中、大型企业或团体与团体间的私人网络的通讯方法。虚拟私人网络的讯息透过公用的网络架构(例如:互联网)来传送内联网的网络讯息。它利用已加密的通道协议(Tunneling Protocol)来达到保密、发送端认证、消息准确性等私人消息安全效果。
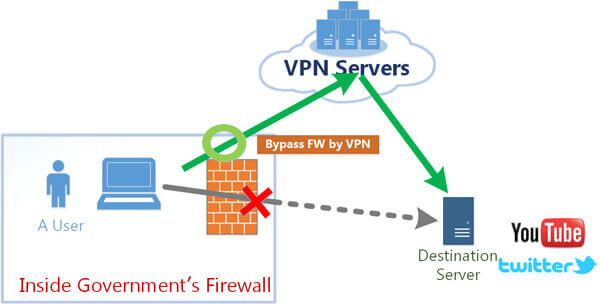
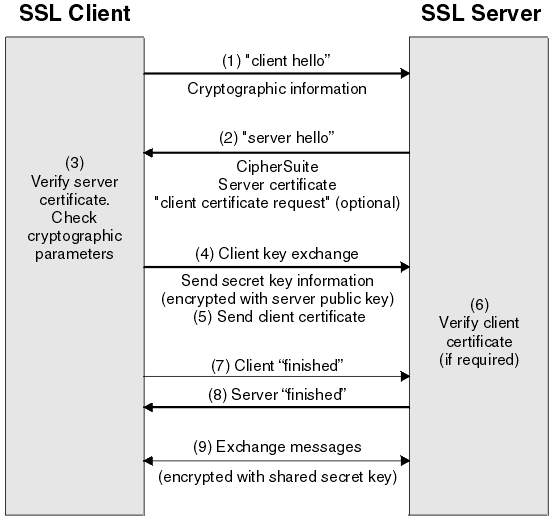
正常网络通信时,所有网络请求都是通过我们的物理网卡直接发送出去。而VPN是客户端使用相应的VPN协议先与VPN服务器进行通信,成功连接后就在操作系统内建立一个虚拟网卡,一般来说默认PC上所有网络通信都从这虚拟网卡上进出,经过VPN服务器中转之后再到达目的地。
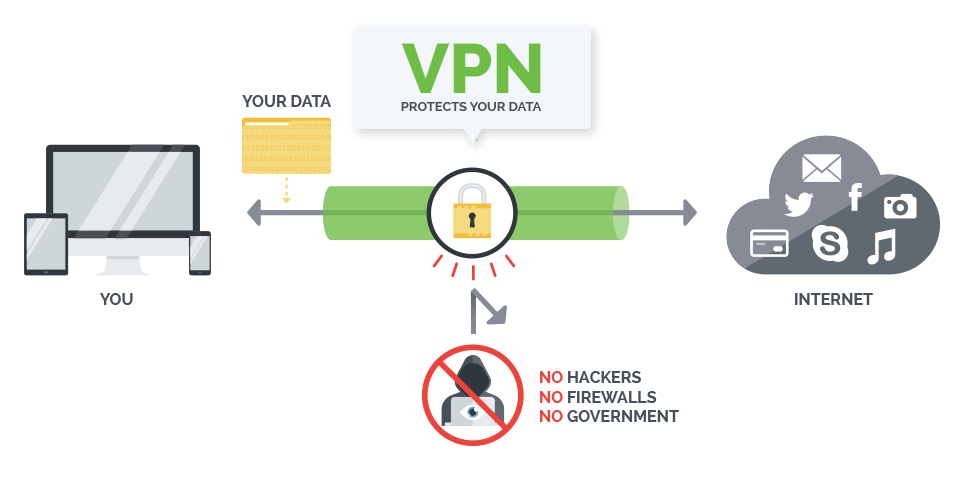
通常VPN协议都会对数据流进行强加密处理,从而使得第三方无法知道数据内容,这样就实现了翻墙。翻墙时VPN服务器知道你干的所有事情(HTTP,对于HTTPS,它知道你去了哪)。
VPN有多种协议:OPENVPN、PPTP、L2TP/IPSec、SSLVPN、IKEv2 VPN,Cisco VPN等。其中的PPTP和L2TP是明文传输协议。只负责传输,不负责加密。分别利用了MPPE和IPSec进行加密。
| 背景 | PPTP 是一个基于 PPP 的很基本的协议。PPTP 是微软 Windows 平台第一个支持的 VPN 协议。PPTP 标准并没有实际描述加密和授权特性,并且依赖于 PPP 协议的隧道来实现安全功能。 | L2TP 是一个在 IETF RFC 3193 中被正式标准化的高级协议。推荐在需要安全加密的地方用来替代 PPTP。 | OpenVPN 是一个高级的开源 VPN 解决方案,由 “OpenVPN technologies” 支持,并且已经成为开源网络领域里的事实标准。OpenVPN 使用成熟的 SSL/TLS 加密协议。 |
| 数据加密 | PPP 负载是使用微软点对点协议(Microsoft’s Point-to-Point Encryption protocol,MPPE)加密。MPPE 实现了 RSA RC4 加密算法,并使用最长 128 位密钥。 | L2TP 负载使用标准的 IPSec 协议加密。在 RFC 4835 中指定了使用 3DES 或 AES 加密算法作为保密方式。 | OpenVPN 使用 OpenSSL 库来提供加密。OpenSSL 支持好几种不同的加密算法,如:3DES,AES,RC5 等。 |
| 安装/配置 | Windows 所有版本和大多数其他操作系统包括移动平台都内建了对 PPTP 的支持。PPTP 只需要一个用户名和密码,以及一个服务器地址,所以安装和配置相当简单。 | 从 2000/XP 起的所有 Windows 平台和 Mac OS X 10.3+ 都内建了 L2TP/IPSec 的支持。大多数现代的移动平台比如 iPhone 和 Android 也有内建的客户端。 | OpenVPN 不包含在任何操作系统中,需要安装客户端软件,但安装也是相当简单,基本上 5 分钟可以完成。 |
| 速度 | 由于使用 128 位密钥,加密开销相比 OpenVPN 使用 256位密钥要小,所以速度感觉稍快一点,但这个差异微不足道。 | L2TP/IPSec 将数据封装两次,所以相比其他竞争者效率稍低,速度也慢一些。 | 当使用默认的 UDP 模式,OpenVPN 的表现是最佳的。 |
| 端口 | PPTP 使用 TCP 1723 端口和 GRE(协议 47)。通过限制 GRE 协议,PPTP 可以轻易地被封锁。 | L2TP/IPSec 使用 UDP 500 端口用来初始化密钥交换,使用协议 50 用来传输 IPSec 加密的数据( ESP ),使用 UDP 1701 端口用来初始化 L2TP 的配置,还使用 UDP 4500 端口来穿过 NAT。L2TP/IPSec 相比 OpenVPN 容易封锁,因为它依赖于固定的协议和端口。 | OpenVPN 可以很容易的配置为使用任何端口运行,也可以使用 UDP 或 TCP 协议。为了顺利穿越限制性的防火墙,可以将 OpenVPN 配置成使用 TCP 443 端口,因为这样就无法和标准的 HTTPS 无法区分,从而极难被封锁。 |
| 稳定性/兼容性 | PPTP 不如 OpenVPN 可靠,也不能像 OpenVPN 那样在不稳定网络中快速恢复。另外还有部分同 GRE 协议和一些路由器的兼容性问题。 | L2TP/IPSec 比 OpenVPN 更复杂,为了使在 NAT 路由器下的设备可靠地使用,配置可以会更加困难。但是,只要服务器和客户端都支持 NAT 穿越,那么就没什么问题了。 | 无论是无线网络、蜂窝网络,还是丢包和拥塞经常发生的不可靠网络,OpenVPN 都非常稳定、快速。对于那些相当不可以的连接,OpenVPN 有一个 TCP 模式可以使用,但是要牺牲一点速度,因为将 TCP 封装在 TCP 时效率不高。 |
| 安全弱点 | 微软实现的 PPTP 有一个严重的安全问题(serious security vulnerabilities)。对于词典攻击来说 MSCHAP-v2 是很脆弱的,并且 RC4 算法也会遭到“位翻转攻击( bit-flipping attack )”。如果保密是重要的,微软也强烈建议升级到 IPSec。 | IPSec 没有明显的漏洞,当和安全加密算法如 AES 一起使用时,被认为是很安全的。 | OpenVPN 也没有明显漏洞,当和安全加密算法如 AES 一起使用时,也被认为是相当安全的。 |
| 客户端的兼容性 | Windows、Mac OS X、Linux、Apple iOS、Android、DD-WRT | Windows、Mac OS X、Linux、Apple iOS、Android | Windows、Mac OS X、Linux |
| 结论 | 由于主要的安全漏洞,除了兼容性以外没有好的理由选择使用 PPTP。如果你的设备既不支持 L2TP/IPSec 又不支持 OpenVPN,那么 PPTP 是一个合理的选择。如果关心快速安装和简易配置,那么 L2TP/IPSec 值得考虑。 | L2TP/IPSec 是优秀的,但相比 OpenVPN 的高效和杰出的稳定性要落后一点。如果你使用运行 iOS 或 Android 的移动设备,那么这就是最佳的选择,因为 OpenVPN 目前还不支持这些平台。另外,如果需要快速安装,L2TP/IPSec 也是一个较佳的选择。 | 对于所有的 Windows, Mac OS X 以及 Linux 桌面用户来说,OpenVPN 是最好的选择。OpenVPN 速度快,并且安全可信。但劣势是缺乏对移动设备的支持,另外还需要安装第三方客户端。 |
| 等级 |
{kind=link}
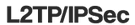{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
对于VPN和其他一些加密的传输的协议来说,没有办法直接获取明文的请求信息,所以没有办法直接封锁,而是使用了监控的方式:
暴力破解
对于一些使用弱加密方式的协议来说,直接使用暴力破解检查传输内容。比如PPTP使用MPPE加密,但是MPPE是基于RC4,对于强大的防火墙背后的超级计算机集群,破解就是几秒钟的事情。
破解后明文中一旦包含了违禁内容,请求就会被封。而对应的IP可能会进入重点关怀列表。
特征检测
要想成功翻墙都必须与对应的远程服务器建立连接,然后再用对应的协议进行数据处理并传输。
而问题就出在这里:翻墙工具和远程服务器建立连接时,如果表现的很独特,在一大堆流量里很显眼,就会轻易被GFW识别出从而直接阻断连接,而VPN(尤其是OPENVPN)和SSH这方面的问题尤其严重。
流量监控
当一个VPN地址被大量人请求,并保持长时间连接时,就很容易引起关注。SSH接口有大量数据请求。一般会结合其他特征。
深度包检测
深度数据包检测(英语:Deep packet inspection,缩写为 DPI),又称完全数据包探测(complete packet inspection)或信息萃取(Information eXtraction,IX),是一种电脑网络数据包过滤技术,用来检查通过检测点之数据包的数据部分(亦可能包含其标头),以搜索不匹配规范之协议、病毒、垃圾邮件、入侵,或以预定之准则来决定数据包是否可通过或需被路由至其他不同目的地,亦或是为了收集统计数据之目的。
比如我们用HTTPS来访问一个网站,TLS/SSL协议在建连过程如下:
很明显的会发送“client hello”和“server hello” 这种特诊很明显的信息。(当然不会根据这个就封掉,否则https没法用了)。而后续会有服务端证书发送,验证,客户端密钥协商等过程。有明显的协议特征。
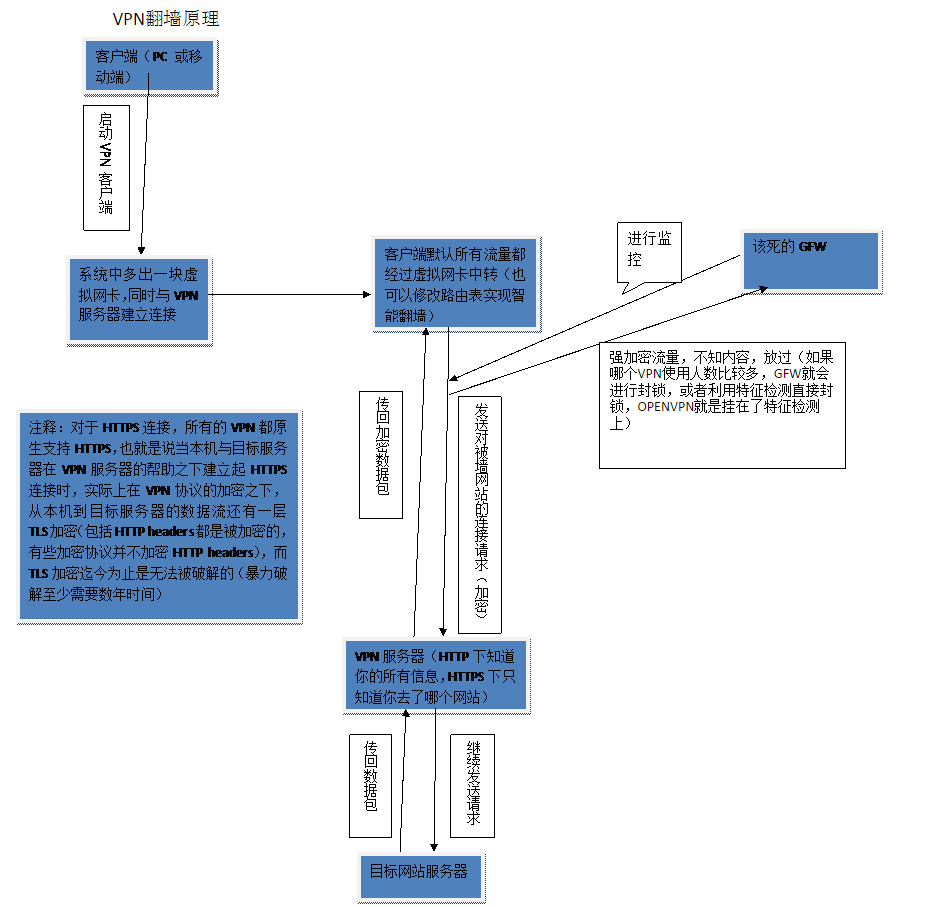
下面是网上找的两张图:提醒大家最好不要随便用不安全的VPN来访问不合适的网页,开开android没啥问题。
Socks代理/SSH Socks
SOCKS是一种网络传输协议,主要用于客户端与外网服务器之间通讯的中间传递。SOCKS是”SOCKetS”的缩写[1]。
当防火墙后的客户端要访问外部的服务器时,就跟SOCKS代理服务器连接。这个代理服务器控制客户端访问外网的资格,允许的话,就将客户端的请求发往外部的服务器。
这个协议最初由David Koblas开发,而后由NEC的Ying-Da Lee将其扩展到版本4。最新协议是版本5,与前一版本相比,增加支持UDP、验证,以及IPv6。
根据OSI模型,SOCKS是会话层的协议,位于表示层与传输层之间
与HTTP代理的对比
SOCKS工作在比HTTP代理更低的层次:SOCKS使用握手协议来通知代理软件其客户端试图进行的连接SOCKS,然后尽可能透明地进行操作,而常规代理可能会解释和重写报头(例如,使用另一种底层协议,例如FTP;然而,HTTP代理只是将HTTP请求转发到所需的HTTP服务器)。虽然HTTP代理有不同的使用模式,CONNECT方法允许转发TCP连接;然而,SOCKS代理还可以转发UDP流量和反向代理,而HTTP代理不能。HTTP代理通常更了解HTTP协议,执行更高层次的过滤(虽然通常只用于GET和POST方法,而不用于CONNECT方法)
Socks代理本身协议是明文传输,虽然相对HTTP有一些优势,但是明文也导致Socks代理很容易被封。所以可以考虑对Socks进行加密。所以出现了SSH Socks,对于MAC和Linux来说,不需要Client就可以进行访问。详细可以看:SSH隧道技术简介:端口转发&SOCKS代理
但是网上看有些地区好像会对一些VPS的SSH进行端口干扰。我在武汉好像SSH到我的VPS一会就会断。在上海一直没这问题。而且SSH一般是小流量数据,如果数据量特别大,也会被认为是翻墙,进入特别关怀列表。
Shadowsocks
认准官网:https://shadowsocks.org/en/index.html (.com那个是卖账号的)
| 1 2 | A secure socks5 proxy, designed to protect your Internet traffic. |
Shadowsocks 目前不容易被封杀主要是因为:
- 建立在socks5协议之上,socks5是运用很广泛的协议,所以没办法直接封杀socks5协议
- 使用socks5协议建立连接,而没有使用VPN中的服务端身份验证和密钥协商过程。而是在服务端和客户端直接写死密钥和加密算法。所以防火墙很难找到明显的特征,因为这就是个普通的socks5协议。
- Shadowsock搭建也比较简单,所以很多人自己架设VPS搭建,个人使用流量也很小,没法通过流量监控方式封杀。
- 自定义加密方式和密钥。因为加密主要主要是防止被检测,所以要选择安全系数高的加密方式。之前RC4会很容易被破解,而导致被封杀。所以现在推荐使用AES加密。而在客户端和服务端自定义密钥,泄露的风险相对较小。
所以如果是自己搭建的Shadosocks被封的概率很小,但是如果是第三方的Shadeowsocks,密码是server定的,你的数据很可能遭受到中间人攻击。
顺便说一下,Shadowssocks是天朝的clowwindy大神写的。不过Shadowsocks项目源码已经从github上删除了并停止维护了,但是release中还有源码可以下载。https://github.com/shadowsocks/shadowsocks
Shadowsocks-rss
前面认为Shadowssocks特征并不是很明细,但是了解协议工作原理后会发现,SS协议本身还有有漏洞,可以被利用来检测特征,具体讨论看:ShadowSocks协议的弱点分析和改进。 里面中间那些撕逼就不用看了,我总结了下大致意思是:
协议过于简单,并且格式固定,很容易被发起中间人攻击。先看看协议结构
| 1 2 3 4 5 | +————–+———————+——————+———-+ | Address Type | Destination Address | Destination Port | Data | +————–+———————+——————+———-+ | 1 | Variable | 2 | Variable | +————–+———————+——————+———-+ |
Possible values of address type are 1 (IPv4), 4 (IPv6), 3 (hostname). For IPv4 address, it’s packed as a 32-bit (4-byte) big-endian integer. For IPv6 address, a compact representation (16-byte array) is used. For hostname, the first byte of destination address indicates the length, which limits the length of hostname to 255. The destination port is also a big-endian integer.
The request is encrypted using the specified cipher with a random IV and the pre-shared key, it then becomes so-called payload.
结构很简单,上面解释也很清楚。Client每一个请求都是这种格式,然后进行加密。Server端解密然后解析。看起来没什么问题,没有密钥你无法模拟中间人攻击,也没什么明显特征。但是看看Server处理逻辑会发现存在一些问题:
Client数据在加密目前用的最多的是AES系列,加密后在协议数据前会有16位的IV。而Server段解析后,首先判断请求是否有效,而这个判断很简单:
| 1 | 判断的依据就是Address Type的那个字节,看它是不是在那三个可能取值,如果不是,立即断开连接,如果是,就尝试解析后面的地址和端口进行连接。 |
如果能发起中间人攻击,模拟Client请求,这个就是一个很明显的特征,如果把Address Type穷举各种情况,其中只有3种情况会连接成功。那么很可能就是一个Shadowsocks 服务器。
所以只需要先劫持一条socks5的请求,因为AES加密后Address Type位置是固定的(第17位),篡改这一位,穷举256种情况(AES-256),然后发送给服务器。如果服务器在3种情况没有关闭连接,就说明这个很可能是Shadowsock服务。你这个IP很快就进入关怀列表了。
这里的关键就是AES加密明文和密文对应关系。密码学不是太懂,贴帖子里面一个回复:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | 举个例子,现在有一个协议包,共7个字节 0x01, 0x08, 0x08, 0x08, 0x08, 0x00, 0x50 对照socks5协议,很明显这是一个IPv4包(第一个字节是0x01),目的地是8.8.8.8的80端口 被shadowsocks加密了以后(密码abc,加密方式aes-256-cfb),数据包就变成了这样 0xbb, 0x59, 0x1c, 0x4a, 0xb9, 0x0a, 0x91, 0xdc, 0x07, 0xef, 0x72, 0x05, 0x90, 0x42, 0xca, 0x0d, 0x4c, 0x3b, 0x87, 0x8e, 0xca, 0xab, 0x32 前16个字节,从0xbb到0x0d,都是iv,根据issue中提到的弱点和之前的总结,只需要修改0x4c,即真正密文中的第一个字节,就可要起到修改明文中的第一个字节的效果。 那就把0x4c修改成0x4d吧,解密以后的结果是 0x00, 0x08, 0x08, 0x08, 0x08, 0x00, 0x50 的确只有第一个字节被改掉了,根据breakwa11的理论,不难推出其他情况,其中合法的是 0x4e => 0x03 (Domain Name) 0x49 => 0x04 (IPv6) |
所以目前Shadowsocks应该是比较容易被检测出来。但是为什么没有被封掉,呵呵,就不知道了。所以这个项目目的就是在SS基础上进行一些混淆。因为原有实现确实有漏洞。 不过目前这个项目好像也停止更新了。并且木有开源。
当然如果是自己用完全可以自己修改一个私有协议,这样就没法被检测到了。但是需要同时修改Server段,MAC Client,Windows Client, Android Client。 – -!
GoAgent和GoProxy
Google App Engine是一个开发、托管网络应用程序的平台,使用Google管理的数据中心
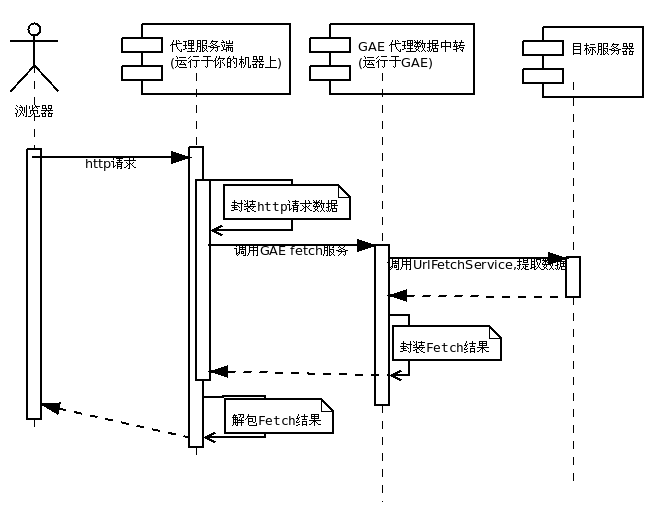
GoAgent的运行原理与其他代理工具基本相同,使用特定的中转服务器完成数据传输。它使用Google App Engine的服务器作为中传,将数据包后发送至Google服务器,再由Google服务器转发至目的服务器,接收数据时方法也类似。由于服务器端软件基本相同,该中转服务器既可以是用户自行架设的服务器,也可以是由其他人架设的开放服务器。
GoAgent其实也是利用GAE作为代理,但是因为他是连接到google的服务器,因为在国内现在google大量被封,所以GoAgent也基本很难使用。目前github上源码也已经删除。
但是GoAgent本身不依赖于GAE,而且使用Python编写,完全可以部署到VPS上进行代理。GoProxy是GoAgent的后续项目https://github.com/phuslu/goproxy
还有一个XX-NET:https://github.com/XX-net/XX-Net 有兴趣都可以去了解下。
Tor
Tor(The Onion Router,洋葱路由器)是实现匿名通信的自由软件。Tor是第二代洋葱路由的一种实现,用户通过Tor可以在因特网上进行匿名交流。
| 1 | The Tor network is a group of volunteer-operated servers that allows people to improve their privacy and security on the Internet. Tor’s users employ this network by connecting through a series of virtual tunnels rather than making a direct connection, thus allowing both organizations and individuals to share information over public networks without compromising their privacy. Along the same line, Tor is an effective censorship circumvention tool, allowing its users to reach otherwise blocked destinations or content. Tor can also be used as a building block for software developers to create new communication tools with built-in privacy features. |
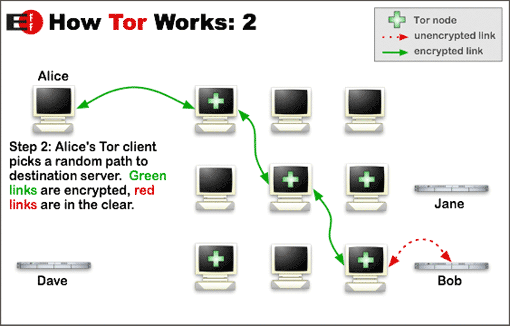
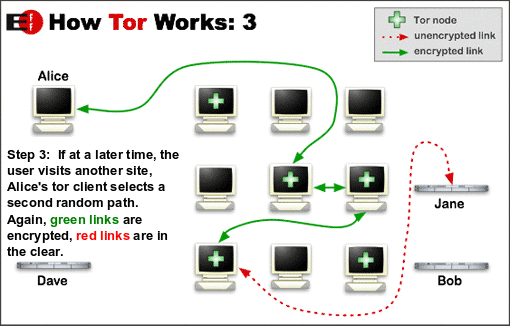
下面的图来自官网的介绍。具体内容大家可以自己看,简单说和其他翻墙方式不同,简单可以理解为Tor有一群代理服务器,然后要访问远端站点,是通过随机的代理路径来完成的,数据经历了多个代理服务器的传递。它主要作用是隐藏访问者信息,而翻墙只是顺带的功能。
要访问远程站点,Client需要知道Tor nodes,这些nodes就是普通加入的用户,就好像P2P下载一样。获取nodes信息后,会随机选择一条路径访问。 因为这个原因,Tor的速度可能不会很好。

而关于Tor的漏洞和检测看这里:Tor真的十分安全么 其原理以及漏洞详解!
目前有结合Tor+Shadowsocks前置代理使用的。
Reference
VPN翻墙,不安全的加密,不要相信墙内公司
GFW的工作原理(1) ————GFW是如何识别并封锁翻墙工具的
关于翻墙和匿名与网络安全类科普文大集合
为什么不应该用 SSL 翻墙
科学上网的一些原理
本地回环地址
本地回环地址(Loopback Address)通常是指127.0.0.1,不属于任何一个有类别地址类。一般都会用来检查本地网络协议、基本数据接口等是否正常的。
在开发或者调试时,我们经常需要和本地的服务器进行通信,例如启动nginx之后,在浏览器输入lcoalhost或者127.0.0.1就可以访问到本机上面的http服务。
Linux是如何访问本机IP的?
大多数操作系统都在网络层实现了环回能力,通常是使用一个虚拟的环回网络接口来实现。这个虚拟的环回网络接口看着像是一个真实的网卡,实际上是操作系统用软件模拟的,它可以通过TCP/IP与同一台主机上的其他服务进行通信,以127开头的IPv4地址就是为它保留的,主流Linux操作系统为环回网卡分配的地址都是127.0.0.1,主机名是localhost。
环回网络接口之所以被称之为环回网络接口,是因为从本机发送到本机任意一个IP的数据报文都会在网络层交给环回网络接口,不再下发到数据链路层进行处理,环回网络接口直接发送回网络层,最终交由应用层软件程序进行处理。这种方式对于性能测试非常有用,因为省去了硬件的开销,可以直接测试协议栈软件所需要的时间。
那环回网络接口是如何判断目的IP是否为本机地址的呢?
答案就是网络层在进行路由转发的时候会先查本地的路由表,发现是本机IP后交给环回网络接口。查看本地路由表的命令如下:
ip route show table local
输出内容如下:
broadcast 10.141.128.0 dev eth0 proto kernel scope link src 10.141.155.131
local 10.141.155.131 dev eth0 proto kernel scope host src 10.141.155.131
broadcast 10.141.191.255 dev eth0 proto kernel scope link src 10.141.155.131
broadcast 127.0.0.0 dev lo proto kernel scope link src 127.0.0.1
local 127.0.0.0/8 dev lo proto kernel scope host src 127.0.0.1
local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1
其中local开头的便是本地IP,dev后面是网卡名称。
查完了本地路由表之后会再查主路由表,也就是我们经常操作的路由表。
ip route show table main
输出内容如下
default via 10.141.128.1 dev eth0 proto static metric 100
10.141.128.0/18 dev eth0 proto kernel scope link src 10.141.155.131 metric 100
环回网络接口
现在我们再来看下环回网络接口
ifconfig lo
输出
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 1554227 bytes 123327716 (117.6 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1554227 bytes 123327716 (117.6 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
可以看到本地环回接口的IPv4地址是127.0.0.1,子网掩码是255.0.0.0,对应A类网络号127,有趣的是当我们访问 127.0.0.1-127.255.255.254之间的任意一个地址都会访问到本机。
IPv6地址::1,前缀是128位,表示只有一个地址。
环回网络接口的当前MTU是64KB,不过最高可以设置到2GB,真是恐怖如斯。
下面几条RX,TX开头的分别代表收发到的数据报文个数和大小以及错包、丢包、溢出次数和无效帧。
排查网卡
排查网卡硬件问题的简便办法,在软件方面都检查不到问题而且物理层外部设备也工作正常的情况下可以采用,或许就是你的救命稻草!windows+R键打开“运行”窗口,输入cmd回车打开“命令提示符窗口”,然后输入ping 127.0.0.1 回车,如果返回值正常说明网卡硬件没有问题,反之就可以考虑网卡硬件的修复了!原理很简单,利用ping命令以及本地回环地址(127.0.0.1),通俗的说就是127.0.0.1这个地址会给自己的物理地址发送信息,即使在断网的条件下正常的网卡也应该ping的通,所以如果不通,就只能说明是网卡硬件问题了!