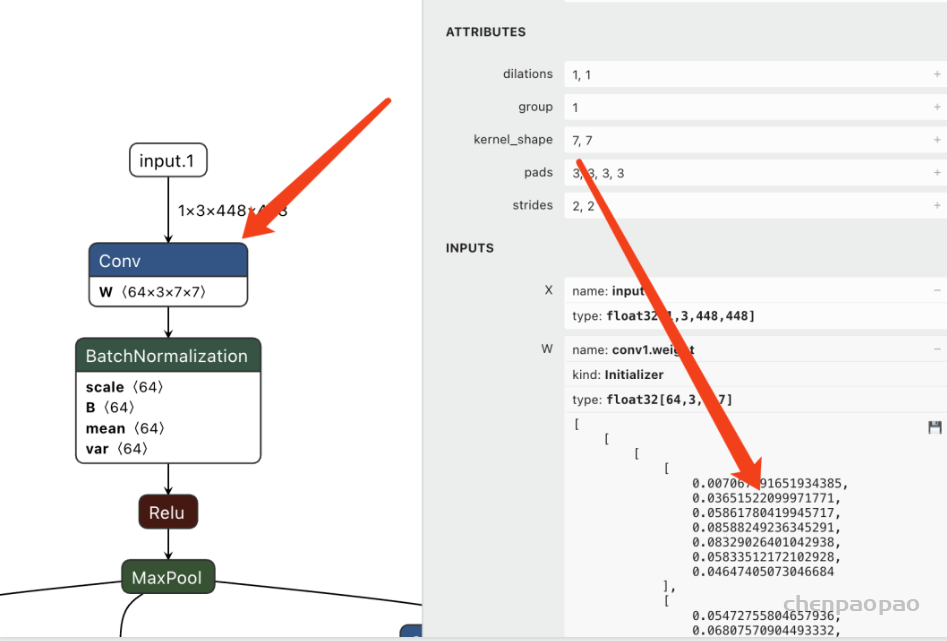
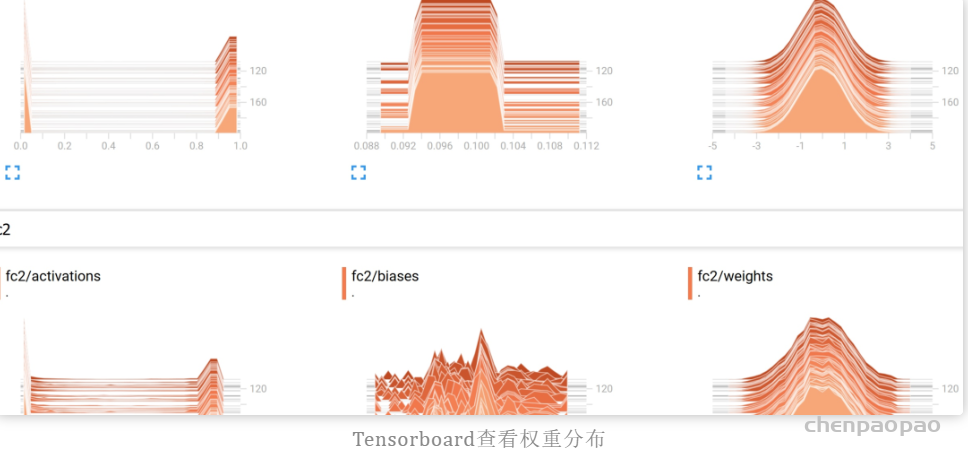
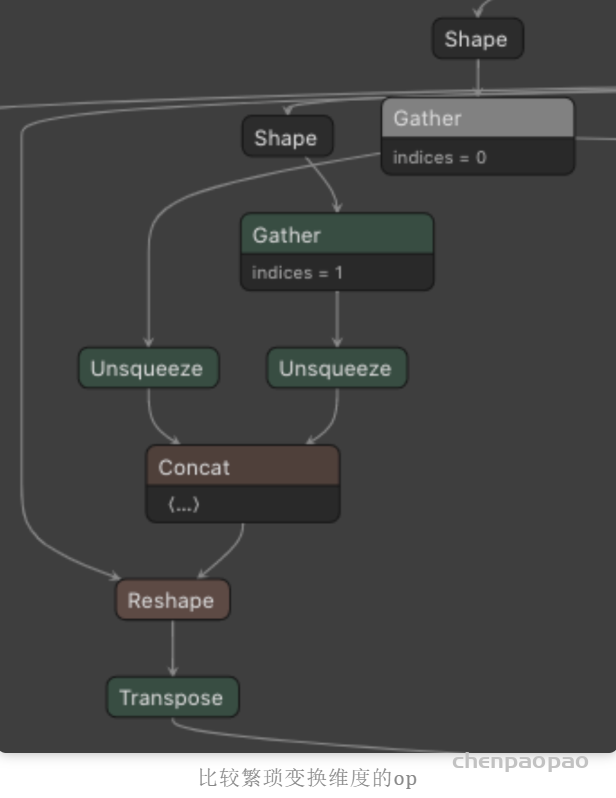
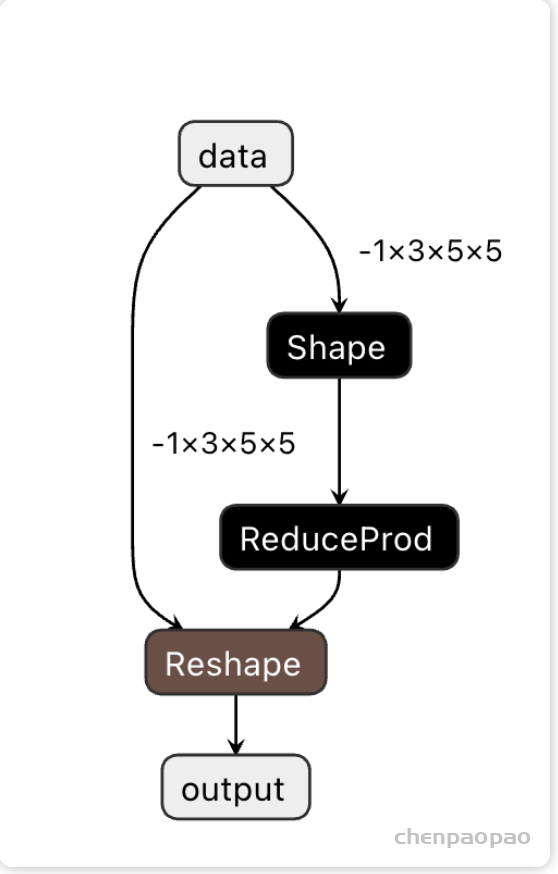
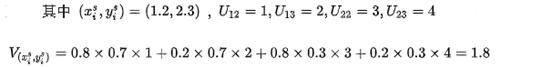摘自知乎:
bookname 嵌入式AI算法研究
中文文本清洗
中文文本清洗:
– 去除指定无用的符号
– 让文本只保留汉字
– 文本中的表情符号去除
– 繁体中文与简体中文转换
中文文本清洗类
import re
from opencc import OpenCC
from bs4 import BeautifulSoup
import jieba
from glob import glob
import torch
from tqdm.auto import tqdm
import sys
!ls ../package/
sys.path.insert(0, "../package/")
from ltp import LTP
nlp = LTP(path="base")
class TextCleaner:
'''
批量清洗数据
'''
def __init__(self,
remove_space=True, # 去除空格
remove_suspension=True, # 转换省略号
only_zh=False, # 只保留汉子
remove_sentiment_character=True, # 去除表情符号
to_simple=True, # 转化为简体中文
remove_html_label=True,
remove_stop_words=False,
stop_words_dir="./停用词/",
with_space=False,
batch_size=256):
self._remove_space = remove_space
self._remove_suspension = remove_suspension
self._remove_sentiment_character = remove_sentiment_character
self._only_zh = only_zh
self._to_simple = to_simple
self._remove_html_label = remove_html_label
self._remove_stop_words = remove_stop_words
self._stop_words_dir = stop_words_dir
self._with_space = with_space
self._batch_size = batch_size
def clean_single_text(self, text):
if self._remove_space:
text = self.remove_space(text)
if self._remove_suspension:
text = self.remove_suspension(text)
if self._remove_sentiment_character:
text = self.remove_sentiment_character(text)
if self._to_simple:
text = self.to_simple(text)
if self._only_zh:
text = self.get_zh_only(text)
if self._remove_html_label:
text = self.remove_html(text)
return text
def clean_text(self, text_list):
text_list = [self.clean_single_text(text) for text in tqdm(text_list)]
tokenized_words_list = self.tokenizer_batch_text(text_list)
if self._remove_stop_words:
text_list = [self.remove_stop_words(words_list, self._stop_words_dir, self._with_space) for words_list in tokenized_words_list]
return text_list
def remove_space(self, text): #定义函数
return text.replace(' ','') # 去掉文本中的空格
def remove_suspension(self, text):
return text.replace('...', '。')
def get_zh_only(self, text):
def is_chinese(uchar):
if uchar >= u'\u4e00' and uchar <= u'\u9fa5': # 判断一个uchar是否是汉字 中文字符的编码范围 \u4e00 - \u9fff,只要在这个范围就可以
return True
else:
return False
content = ''
for i in text:
if is_chinese(i):
content = content+i
return content
def remove_sentiment_character(self, sentence):
pattern = re.compile("[^\u4e00-\u9fa5^,^.^!^,^。^?^?^!^a-z^A-Z^0-9]") #只保留中英文、数字和符号,去掉其他东西
#若只保留中英文和数字,则替换为[^\u4e00-\u9fa5^a-z^A-Z^0-9]
line = re.sub(pattern,'',sentence) #把文本中匹配到的字符替换成空字符
new_sentence=''.join(line.split()) #去除空白
return new_sentence
def to_simple(self, sentence):
new_sentence = OpenCC('t2s').convert(sentence) # 繁体转为简体
return new_sentence
def to_tradition(self, sentence):
new_sentence = OpenCC('s2t').convert(sentence) # 简体转为繁体
return new_sentence
def remove_html(self, text):
return BeautifulSoup(text, 'html.parser').get_text() #去掉html标签
def tokenizer_batch_text(self, text_list):
tokenized_text = []
len_text = len(text_list)
with torch.no_grad():
steps = self._batch_size
for start_idx in tqdm(range(0, len_text, steps)):
if start_idx + steps > len_text:
tokenized_text += nlp.seg(text_list[start_idx:])[0]
else:
tokenized_text += nlp.seg(text_list[start_idx:start_idx+steps])[0]
return tokenized_text
def remove_stop_words(self, words_list, stop_words_dir, with_space=False):
"""
中文数据清洗 stopwords_chineses.txt存放在博客园文件中
:param text:
:return:
"""
stop_word_filepath_list = glob(stop_words_dir + "/*.txt")
for stop_word_filepath in stop_word_filepath_list:
with open(stop_word_filepath) as fp:
stopwords = {}.fromkeys([line.rstrip() for line in fp]) #加载停用词(中文)
eng_stopwords = set(stopwords) #去掉重复的词
words = [w for w in words_list if w not in eng_stopwords] #去除文本中的停用词
if with_space:
return ' '.join(words)
else:
return ''.join(words)
ltp
file /root/.cache/torch/ltp/8909177e47aa4daf900c569b86053ac68838d09da28c7bbeb42b8efcb08f56aa-edb9303f86310d4bcfd1ac0fa20a744c9a7e13ee515fe3cf88ad31921ed616b2-extracted/config.json not found
file /root/.cache/torch/ltp/8909177e47aa4daf900c569b86053ac68838d09da28c7bbeb42b8efcb08f56aa-edb9303f86310d4bcfd1ac0fa20a744c9a7e13ee515fe3cf88ad31921ed616b2-extracted/config.json not found
cleaner = TextCleaner(remove_stop_words=True, with_space=True)
contents = [' 大家好, 欢迎一起来学习文本的空格 去除 !', ' 大家好,文本的空格 去除 !']
results = cleaner.clean_text(contents)
print(results)
0%| | 0/2 [00:00<?, ?it/s]
0%| | 0/1 [00:00<?, ?it/s]
['好 , 学习 文本 空格 去除 !', '好 , 文本 空格 去除 !']去除空格
# 去除空格
contents = ' 大家好, 欢迎一起来学习文本的空格 去除 !'
print('处理前文本:'+contents)
def process(our_data): #定义函数
content = our_data.replace(' ','') # 去掉文本中的空格
print('处理后文本:'+content)
process(contents)
处理前文本: 大家好, 欢迎一起来学习文本的空格 去除 !
处理后文本:大家好,欢迎一起来学习文本的空格去除!去除空格的同时把省略号转换为句号
# 去除空格的同时把省略号转换为句号
contents = ' 大家好, 这里还有 很多的知识...一起拉学习吧 !'
print('处理前文本:'+contents)
def process(data): #定义函数
content1 = data.replace(' ','') # 去掉文本中的空格
content2 = content1.replace('...','。') # 去掉文本中的空格
print('处理后文本:'+ content2)
process(contents)
处理前文本: 大家好, 这里还有 很多的知识...一起拉学习吧 !
处理后文本:大家好,这里还有很多的知识。一起拉学习吧!让文本只保留汉字
def is_chinese(uchar):
if uchar >= u'\u4e00' and uchar <= u'\u9fa5': # 判断一个uchar是否是汉字
return True
else:
return False
def allcontents(contents):
content = ''
for i in contents:
if is_chinese(i):
content = content+i
print('\n处理后的句子为:\n'+content)
centents = '1,2,3...我们开始吧, 加油!'
print('原句子为:\n'+centents)
allcontents(centents)
原句子为:
1,2,3...我们开始吧, 加油!
处理后的句子为:
我们开始吧加油文本中的表情符号去除
import re
sentence='现在听着音乐,duo rui mi,很开心*_*'
print('原句子为:\n'+sentence)
def clear_character(sentence):
pattern = re.compile("[^\u4e00-\u9fa5^,^.^!^a-z^A-Z^0-9]") #只保留中英文、数字和符号,去掉其他东西
#若只保留中英文和数字,则替换为[^\u4e00-\u9fa5^a-z^A-Z^0-9]
line=re.sub(pattern,'',sentence) #把文本中匹配到的字符替换成空字符
new_sentence=''.join(line.split()) #去除空白
print('\n处理后的句子为:\n'+new_sentence)
clear_character(sentence)
原句子为:
现在听着音乐,duo rui mi,很开心*_*
处理后的句子为:
现在听着音乐,duoruimi,很开心繁体中文与简体中文转换
from opencc import OpenCC
sentence = '你现在读的这里是简体,这里是繁体,能看懂吗?'
print('原句子为:\n'+sentence)
def Simplified(sentence):
new_sentence = OpenCC('t2s').convert(sentence) # 繁体转为简体
print('\n处理后的句子为:\n'+new_sentence)
def Traditional(sentence):
new_sentence = OpenCC('s2t').convert(sentence) # 简体转为繁体
print('\n处理后的句子为:\n'+new_sentence)
Simplified(sentence)
Traditional(sentence)
原句子为:
你现在读的这里是简体,这里是繁体,能看懂吗?
处理后的句子为:
你现在读的这里是简体,这里是繁体,能看懂吗?
处理后的句子为:
你现在读的这里是简体,这里是繁体,能看懂吗?OpenCC的参数设置:
- hk2s: Traditional Chinese (Hong Kong standard) to Simplified Chinese
- s2hk: Simplified Chinese to Traditional Chinese (Hong Kong standard)
- s2t: Simplified Chinese to Traditional Chinese
- s2tw: Simplified Chinese to Traditional Chinese (Taiwan standard)
- s2twp: Simplified Chinese to Traditional Chinese (Taiwan standard, with phrases)
- t2hk: Traditional Chinese to Traditional Chinese (Hong Kong standard)
- t2s: Traditional Chinese to Simplified Chinese
- t2tw: Traditional Chinese to Traditional Chinese (Taiwan standard)
- tw2s: Traditional Chinese (Taiwan standard) to Simplified Chinese
- tw2sp: Traditional Chinese (Taiwan standard) to Simplified Chinese (with phrases)去除html标签和停用词
from bs4 import BeautifulSoup
import jieba
from glob import glob
def clean_chineses_text(text, with_space=False):
"""
中文数据清洗 stopwords_chineses.txt存放在博客园文件中
:param text:
:return:
"""
text = BeautifulSoup(text, 'html.parser').get_text() #去掉html标签
text = jieba.lcut(text)
stop_word_filepath_list = glob("./停用词/*.txt")
# print(stop_word_filepath_list)
for stop_word_filepath in stop_word_filepath_list:
with open(stop_word_filepath) as fp:
stopwords = {}.fromkeys([line.rstrip() for line in fp]) #加载停用词(中文)
eng_stopwords = set(stopwords) #去掉重复的词
words = [w for w in text if w not in eng_stopwords] #去除文本中的停用词
if with_space:
return ' '.join(words)
else:
return ''.join(words)
clean_chineses_text("你现在读的这里是简体,这里是繁体,能看懂吗?", with_space=True)
Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
Loading model cost 0.703 seconds.
Prefix dict has been built successfully.
'读 简体 , 这里 繁体 , 能看懂 吗 ?'
ENGLISH_STOP_WORDS = frozenset([
"about", "above", "across", "after", "afterwards", "again", "against",
"all", "almost", "alone", "along", "already", "also", "although", "always",
"am", "among", "amongst", "amoungst", "amount", "an", "and", "another",
"any", "anyhow", "anyone", "anything", "anyway", "anywhere", "are",
"around", "as", "at", "back", "be", "became", "because", "become",
"becomes", "becoming", "been", "before", "beforehand", "behind", "being",
"below", "beside", "besides", "between", "beyond", "bill", "both",
"bottom", "but", "by", "call", "can", "cannot", "cant", "co", "con",
"could", "couldnt", "cry", "de", "describe", "detail", "do", "done",
"down", "due", "during", "each", "eg", "eight", "either", "eleven", "else",
"elsewhere", "empty", "enough", "etc", "even", "ever", "every", "everyone",
"everything", "everywhere", "except", "few", "fifteen", "fifty", "fill",
"find", "fire", "first", "five", "for", "former", "formerly", "forty",
"found", "four", "from", "front", "full", "further", "get", "give", "go",
"had", "has", "hasnt", "have", "he", "hence", "her", "here", "hereafter",
"hereby", "herein", "hereupon", "hers", "herself", "him", "himself", "his",
"how", "however", "hundred", "ie", "if", "in", "inc", "indeed",
"interest", "into", "is", "it", "its", "itself", "keep", "last", "latter",
"latterly", "least", "less", "ltd", "made", "many", "may", "me",
"meanwhile", "might", "mill", "mine", "more", "moreover", "most", "mostly",
"move", "much", "must", "my", "myself", "name", "namely", "neither",
"never", "nevertheless", "next", "nine", "no", "nobody", "none", "noone",
"nor", "not", "nothing", "now", "nowhere", "of", "off", "often", "on",
"once", "one", "only", "onto", "or", "other", "others", "otherwise", "our",
"ours", "ourselves", "out", "over", "own", "part", "per", "perhaps",
"please", "put", "rather", "re", "same", "see", "seem", "seemed",
"seeming", "seems", "serious", "several", "she", "should", "show", "side",
"since", "sincere", "six", "sixty", "so", "some", "somehow", "someone",
"something", "sometime", "sometimes", "somewhere", "still", "such",
"system", "take", "ten", "than", "that", "the", "their", "them",
"themselves", "then", "thence", "there", "thereafter", "thereby",
"therefore", "therein", "thereupon", "these", "they", "thick", "thin",
"third", "this", "those", "though", "three", "through", "throughout",
"thru", "thus", "to", "together", "too", "top", "toward", "towards",
"twelve", "twenty", "two", "un", "under", "until", "up", "upon", "us",
"very", "via", "was", "we", "well", "were", "what", "whatever", "when",
"whence", "whenever", "where", "whereafter", "whereas", "whereby",
"wherein", "whereupon", "wherever", "whether", "which", "while", "whither",
"who", "whoever", "whole", "whom", "whose", "why", "will", "with",
"within", "without", "would", "yet", "you", "your", "yours", "yourself",
"yourselves", "a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l",
"m", "n", "o", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z"])特征抽取
文本特征提取类
import numpy as np
import pandas as pd
from tqdm.auto import tqdm
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer, HashingVectorizer
import sys
!ls ../package/
sys.path.insert(0, "../package/")
from ltp import LTP
nlp = LTP(path="base")
from gensim.models import Word2Vec
class TextFeatures:
def __init__(self, ngram_range=(1, 2)):
self.cvt = CountVectorizer(tokenizer=self.tokenizer, ngram_range=ngram_range)
self.tvt = TfidfVectorizer(tokenizer=self.tokenizer, ngram_range=ngram_range)
self.hvt = HashingVectorizer(tokenizer=self.tokenizer, ngram_range=ngram_range)
self.cleaner = TextCleaner(remove_html_label=True, remove_stop_words=True, with_space=True)
def clean_text(self, text_list):
return self.cleaner.clean_text(text_list)
def tokenizer(self, text):
return text.split(" ")
def get_bow(self, text_list):
return self.cvt.fit_transform(text_list)
def get_tfidf(self, text_list):
return self.tvt.fit_transform(text_list)
def get_hashing(self, text_list):
return self.hvt.fit_transform(text_list)
ltp
file /root/.cache/torch/ltp/8909177e47aa4daf900c569b86053ac68838d09da28c7bbeb42b8efcb08f56aa-edb9303f86310d4bcfd1ac0fa20a744c9a7e13ee515fe3cf88ad31921ed616b2-extracted/config.json not found
file /root/.cache/torch/ltp/8909177e47aa4daf900c569b86053ac68838d09da28c7bbeb42b8efcb08f56aa-edb9303f86310d4bcfd1ac0fa20a744c9a7e13ee515fe3cf88ad31921ed616b2-extracted/config.json not found
train_df = pd.read_csv("../0.数据/1.情感分析/NLPCC14-SC/train.tsv", sep="\t", error_bad_lines=False)
train_df.head()set(train_df["label"]), train_df.shape
({0, 1}, (10000, 2))
cleaner = TextCleaner(remove_html_label=True, remove_stop_words=True, with_space=True)
contents = [' 大家好, 欢迎一起来学习文本的空格 去除 !']
results = cleaner.clean_text(contents)
print(results)
0%| | 0/1 [00:00<?, ?it/s]
0%| | 0/1 [00:00<?, ?it/s]
['好 , 学习 文本 空格 去除 !']
tqdm.pandas(desc="clean data")
train_df["cleaned_text"] = cleaner.clean_text(train_df["text_a"].values)
0%| | 0/10000 [00:00<?, ?it/s]
0%| | 0/40 [00:00<?, ?it/s]
train_df.to_csv("cleaned_train.csv", index=None)
# import torch
# from tqdm.auto import tqdm
# tokenized_text = []
# text_list = list(train_df["cleaned_text"].values)
# with torch.no_grad():
# steps = 256
# for start_idx in tqdm(range(0, train_df.shape[0], steps)):
# # print(start_idx)
# if start_idx + steps > train_df.shape[0]:
# tokenized_text += nlp.seg(text_list[start_idx:])[0]
# else:
# tokenized_text += nlp.seg(text_list[start_idx:start_idx+steps])[0]
# from joblib import dump, load
# 关掉显存占用
# from numba import cuda
# cuda.select_device(0)
# cuda.close() BOW
!ls ../1.基础/停用词/
中文停用词库.txt 哈工大停用词表.txt 四川大学停用词表.txt 百度停用词表.txt
from glob import glob
# 停用词列表
stop_words = []
txt_list = glob("../1.基础/停用词/*.txt")
for txt_path in txt_list:
with open(txt_path, "r") as fp:
lines = fp.readlines()
stop_words += [line.strip() for line in lines]
len(stop_words)
3893
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer, HashingVectorizer
from sklearn.linear_model import Ridge, Lasso, LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, roc_auc_score
def tokenizer(text):
return text.split(" ")
# corpus = [" ".join(text_list) for text_list in tokenized_text]
# corpus[:2]
corpus = train_df["cleaned_text"].values
cvt = CountVectorizer(stop_words=stop_words, tokenizer=tokenizer, ngram_range=(1, 2))
x_cvt = cvt.fit_transform(corpus)
len(cvt.vocabulary_)
137525
y = train_df["label"].values
X_train, X_val, y_train, y_val = train_test_split(x_cvt, y, test_size=0.1)
clf = Ridge(alpha=500.)
clf.fit(X_train, y_train)
print("train score: ")
y_pred = clf.predict(X_train)
print(roc_auc_score(y_train, y_pred), accuracy_score(y_train, y_pred>0.5))
print()
print("valid score: ")
y_pred = clf.predict(X_val)
print(roc_auc_score(y_val, y_pred), accuracy_score(y_val, y_pred>0.5))
train score:
0.8657380740314067 0.798
valid score:
0.8009079767378523 0.733TFIDF
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer, HashingVectorizer
tvt = TfidfVectorizer(stop_words=stop_words, tokenizer=tokenizer, ngram_range=(1, 2))
x_tvt = tvt.fit_transform(corpus)
len(tvt.vocabulary_)
137525
y = train_df["label"].values
X_train, X_val, y_train, y_val = train_test_split(x_tvt, y, test_size=0.1)
clf = Ridge(alpha=10.)
clf.fit(X_train, y_train)
print("train score: ")
y_pred = clf.predict(X_train)
print(roc_auc_score(y_train, y_pred), accuracy_score(y_train, y_pred>0.5))
print()
print("valid score: ")
y_pred = clf.predict(X_val)
print(roc_auc_score(y_val, y_pred), accuracy_score(y_val, y_pred>0.5))
train score:
0.9349220324539836 0.8745555555555555
valid score:
0.7963706773775423 0.728HashingVectorizer
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer, HashingVectorizer
hvt = HashingVectorizer(stop_words=stop_words, tokenizer=tokenizer, ngram_range=(1, 2))
x_hvt = hvt.fit_transform(corpus)
y = train_df["label"].values
X_train, X_val, y_train, y_val = train_test_split(x_hvt, y, test_size=0.1)
clf = Ridge(alpha=1.)
clf.fit(X_train, y_train)
print("train score: ")
y_pred = clf.predict(X_train)
print(roc_auc_score(y_train, y_pred), accuracy_score(y_train, y_pred>0.5))
print()
print("valid score: ")
y_pred = clf.predict(X_val)
print(roc_auc_score(y_val, y_pred), accuracy_score(y_val, y_pred>0.5))
train score:
0.99204728016389 0.969
valid score:
0.8349841394447204 0.749LDA
train_df = pd.read_csv("./cleaned_train.csv")
train_df.head()from glob import glob
# 停用词列表
stop_words = []
txt_list = glob("../1.基础/停用词/*.txt")
for txt_path in txt_list:
with open(txt_path, "r") as fp:
lines = fp.readlines()
stop_words += [line.strip() for line in lines]
len(stop_words)
3893
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer, HashingVectorizer
from sklearn.decomposition import LatentDirichletAllocation
from sklearn.linear_model import Ridge, Lasso, LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, roc_auc_score
def tokenizer(text):
return text.split(" ")
corpus = train_df["cleaned_text"].values
corpus = [string if string is not np.nan else "" for string in corpus]
cvt = CountVectorizer(tokenizer=tokenizer, ngram_range=(1, 2))
x_cvt = cvt.fit_transform(corpus)
lda = LatentDirichletAllocation(n_components=32, doc_topic_prior=None, topic_word_prior=None, learning_method='batch',
learning_decay=0.7, learning_offset=50.0, max_iter=10, batch_size=128, evaluate_every=-1,
total_samples=1000000.0, perp_tol=0.1, mean_change_tol=0.001, max_doc_update_iter=100,
n_jobs=None, verbose=0, random_state=402)
docres = lda.fit_transform(x_cvt)
docres.shape
(10000, 32)
y = train_df["label"].values
X_train, X_val, y_train, y_val = train_test_split(docres, y, test_size=0.1)
clf = Ridge(alpha=500.)
clf.fit(X_train, y_train)
print("train score: ")
y_pred = clf.predict(X_train)
print(roc_auc_score(y_train, y_pred), accuracy_score(y_train, y_pred>0.5))
print()
print("valid score: ")
y_pred = clf.predict(X_val)
print(roc_auc_score(y_val, y_pred), accuracy_score(y_val, y_pred>0.5))
train score:
0.5984059229289742 0.5741111111111111
valid score:
0.5797141495568878 0.57gensim
corpus = [string.split(" ") for string in corpus]
from gensim import corpora
dictionary = corpora.Dictionary(corpus)
dictionary.save('qzone.dict')
dictionary.filter_extremes(no_below=20, no_above=0.5)
dictionary.compactify()
corpus = [dictionary.doc2bow(s) for s in corpus]
corpora.MmCorpus.serialize('corpus_bow.mm', corpus) # 存储语料库
from gensim.models import LdaModel
num_topics = 100
chunksize = 2000
passes = 20
iterations = 400
eval_every = None
temp = dictionary[0]
id2word = dictionary.id2token
model = LdaModel(
corpus=corpus,
id2word=id2word,
chunksize=chunksize,
alpha='auto',
eta='auto',
iterations=iterations,
num_topics=num_topics,
passes=passes,
eval_every=eval_every
)
model.save('qzone.model')
top_topics = model.top_topics(corpus)
avg_topic_coherence = sum([t[1] for t in top_topics]) / num_topics
print('Average topic coherence: %.4f.' % avg_topic_coherence)
Average topic coherence: -5.7200.
len(top_topics), len(corpus)
(100, 10000)LTP特征提取
import sys
!ls ../package/
sys.path.insert(0, "../package/")
from ltp import LTP
nlp = LTP(path="base")
ltp
file /root/.cache/torch/ltp/8909177e47aa4daf900c569b86053ac68838d09da28c7bbeb42b8efcb08f56aa-edb9303f86310d4bcfd1ac0fa20a744c9a7e13ee515fe3cf88ad31921ed616b2-extracted/config.json not found
file /root/.cache/torch/ltp/8909177e47aa4daf900c569b86053ac68838d09da28c7bbeb42b8efcb08f56aa-edb9303f86310d4bcfd1ac0fa20a744c9a7e13ee515fe3cf88ad31921ed616b2-extracted/config.json not found
seg, hidden = nlp.seg(["他叫汤姆去拿外衣。"])
pos = nlp.pos(hidden)
ner = nlp.ner(hidden)
srl = nlp.srl(hidden)
dep = nlp.dep(hidden)
sdp = nlp.sdp(hidden)对于LTP提取的特征,可以参考LTP的文档