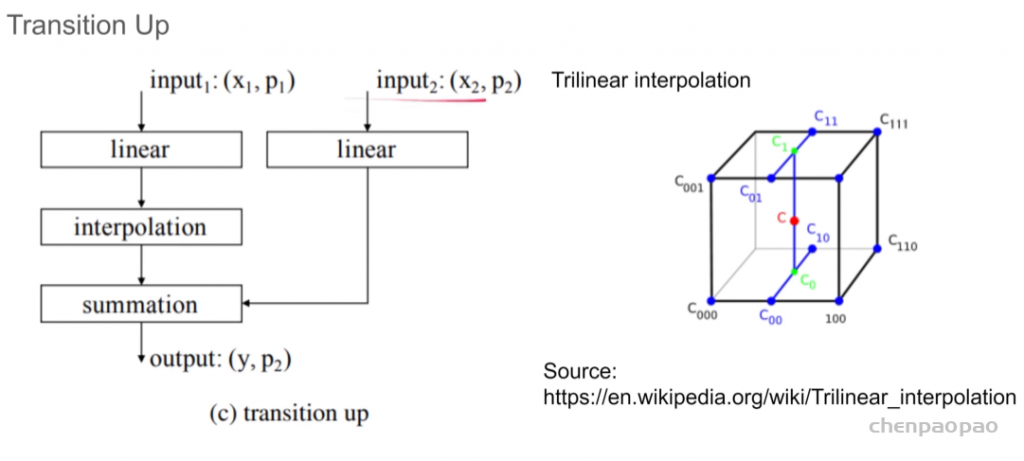
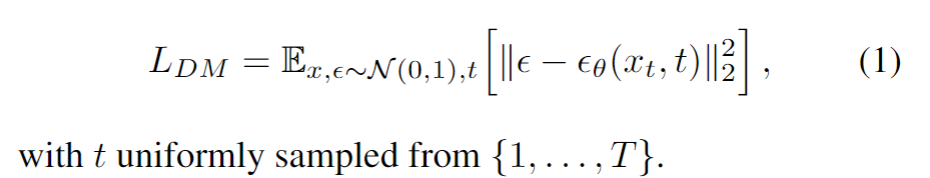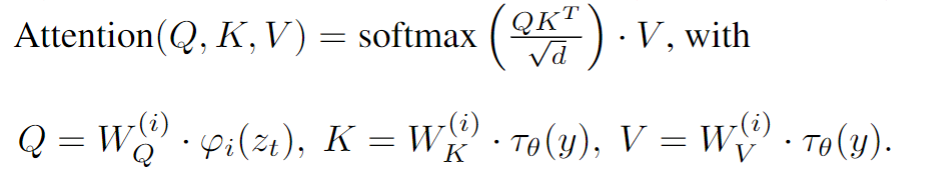迈克尔·布莱克(Michael J. Black)是出生在美国的计算机科学家,在德国图宾根工作。他是马克斯·普朗克智能系统研究所的创始理事,负责领导感知系统部门的计算机视觉,机器学习和计算机图形研究。他还是图宾根大学的名誉教授。
研究价值 = 新意度 x 有效性 x 问题大小 ,这篇博客的标题叫做科学中的新意度,来看看大佬是如何解释 论文新意度的(Novelty)。
审稿人对怎样才能使一篇论文被 CVPR 这样的顶级会议所接受有着强烈的想法。他们知道,要进入这样的会议是很难的,而且得到一篇论文是很有声望的。
因此,被录用的论文必须是非常特别的。这是事实,但什么使一篇论文特别呢?许多审稿人关注的一个重点是新颖性。但什么是科学中的新颖性?
我看到评审员经常把复杂性、难度和技术性误认为是新颖性。在科学评审中,新颖性似乎意味着这些东西。我们最好把 “新颖性 “这个词从审查说明中去掉,用美来代替。
美感消除了 “技术性 “和 “复杂性 “的概念,并更多地涉及到科学新颖性的核心。 一幅画可以是美丽的,即使它很简单,技术复杂度很低。一张纸也可以。毕加索的一个小插曲可以和伦勃朗的复杂画作一样美丽。考虑到美,让我们看看审查员对新颖性的一些常见误解。
Reviewers have strong ideas about what makes a paper acceptable in top conferences like CVPR. They know that getting into such conferences is hard and that getting a paper in is prestigious. So, the papers that get in must be really special. This is true, but what makes a paper special? A key focus of many reviewers is novelty. But what is novelty in science?

I see reviewers regularly mistake complexity, difficulty, and technicality for novelty. In science reviewing, novelty seems to imply these things. We might be better served by removing the word “novelty” from the review instructions and replacing it with beauty.
Beauty removes the notions of “technical” and “complex” and gets more to the heart of scientific novelty. A painting can be beautiful even if it is simple and the technical complexity is low. So can a paper. A little squiggle of paint by Picasso can be as beautiful as an intricate painting by Rembrandt.
Keeping beauty in mind, let’s look at some common reviewer misunderstandings about novelty.
Novelty as complexity
The simplicity of an idea is often confused with a lack of novelty when exactly the opposite is often true. A common review critique is
The idea is very simple. It just changes one term in the loss and everything else is the same as prior work.
If nobody thought to change that one term, then it is ipso facto novel. The inventive insight is to realize that a small change could have a big effect and to formulate the new loss.
Such reviews lead my students to say that we should make an idea appear more complex so that reviewers will find it of higher value. I value simplicity over unnecessary complexity; the simpler the better. Taking an existing network and replacing one thing is better science than concocting a whole new network just to make it look more complex.
Novelty as difficulty
It’s hard to get a paper into a top conference, therefore reviewers often feel that the ideas and technical details must be difficult. The authors have to shed blood, sweat, and tears to deserve a paper. Inexperienced reviewers, in particular, like to see that the authors have really worked hard.
Formulating a simple idea means stripping away the unnecessary to reveal the core of something. This is one of the most useful things that a scientist can do.
A simple idea can be important. But it can also be trivial. This is where reviewers struggle. A trivial idea is an unimportant idea. If a paper has a simple idea that works better than the state of the art, then it is most likely not trivial. The authors are onto something and the field will be interested.
Novelty as surprise
Novelty and surprise are closely related. A novel idea is a surprising one by definition — it’s one that nobody in the field thought of. But there is a flip side to this as surprise is a fleeting emotion. If you hear a good idea, there is a moment of surprise and then, the better it is, the more obvious it may seem. A common review:
The idea is obvious because the authors just combined two well known ideas.
Obvious is the opposite of novelty. So, if an idea is obvious after you’ve heard it, reviewers quickly assume it isn’t novel. The novelty, however, must be evaluated before the idea existed. The inventive novelty was to have the idea in the first place. If it is easy to explain and obvious in hindsight, this in no way diminishes the creativity (and novelty) of the idea.
Novelty as technical novelty
The most common misconception of reviewers is that novelty pertains to technical details. Novelty (and value) come in many forms in papers. A new dataset can be novel if it does something no other dataset has done, even if all the methods used to generate the dataset are well known. A new use of an old method can be novel if nobody ever thought to use it this way. Replacing a complex algorithm with a simple one provides insight.
Novelty reveals itself in as many ways as beauty. Before critiquing a paper for a lack to technical novelty ask yourself if the true novelty lies elsewhere.
Novelty as usefulness or value
Not all novel ideas are useful. Just the property of being new does not connote value. We want new ideas that lead us somewhere. Here, reviewers need to be very careful. It’s very hard to know where a new idea will take the field because any predictions that we make are based on the field as it is today.
A common review I get is
The authors describe a new method but I don’t know why anyone needs this.
Lack of utility is indeed an issue but it is very hard to assess with a new idea. Reviewers should be careful here and aware that we all have limited imagination.
A personal note
My early career was built on seeing and formalizing connections between two established fields: robust statistics and Markov random fields. The novelty arose from the fact that nobody had put these ideas together before. It turned out to be a fertile space with many surprising connections that led to new theory. Fortunately, these connections also turned out to be valuable, resulting in practical algorithms that were state of the art.
With hindsight, the connection between robust statistics and outliers in computer vision seems obvious. Today, the use of robust estimators in vision is the norm and seems no more novel than breathing air. But to see the connections for the first time, before others saw them, was like breathing for the first time.
There is little in life more exciting than that spark of realization in science when you glimpse a new way of seeing. You feel as if you were the first to stand on a mountain peak. You are seeing the world for a moment the way nobody before you has ever seen it. This is novelty and it happens in an instant but is enabled by all of one’s experience.
The resulting paper embodies the translation of the idea into code, experiments, and text. In this translation, the beauty of the spark may be only dimly glimpsed. My request of reviewers is to try to imagine the darkness before the spark.
总结:
1、新意度 !=复杂度、困难度、惊讶度、技术新意度、有效性
2、新意度 ~=优美 (要懂得欣赏)