MLP-Mixer的增强版,带gating的MLP。有两个版本,分别是gMLP和aMLP。Pay-Attention-to-MLPs是gMLP版本,同时也提出了gMLP的增强版aMLP。
paper: https://arxiv.org/abs/2105.08050
github: https://github.com/antonyvigouret/Pay-Attention-to-MLPs
此文和最近刊出MLP文章相同,旨在探究self-attention对于Transformer来说是否至关重要。并在CV和NLP上的相关任务进行实验。
Transformer结构具有可并行化汇聚所有token间的空间信息的优点。众所周知self-attention是通过计算输入间的空间关系动态的引入归纳偏置,同时被静态参数化的MLP能表达任意的函数,所以self-attention对于Transformer在CV和NLP等领域的成功是否是至关重要的呢?
- 此文提出了一个基于MLP的没有self-attention结构名为gMLP,仅仅存在静态参数化的通道映射(channel projections)和空间映射(spatial projections)。同时作者通过实验发现当对空间映射的线性结果进行门机制乘法得到的效果最好。
- 此文使用gMLP做图片分类并在ImageNet上取得了与DeiT、ViT等Transformer模型相当的效果。与先前的MLP模型MLP-Mixer相比,gMLP做到了参数更少(参数减少66%)效果更强(效果提升3%)。
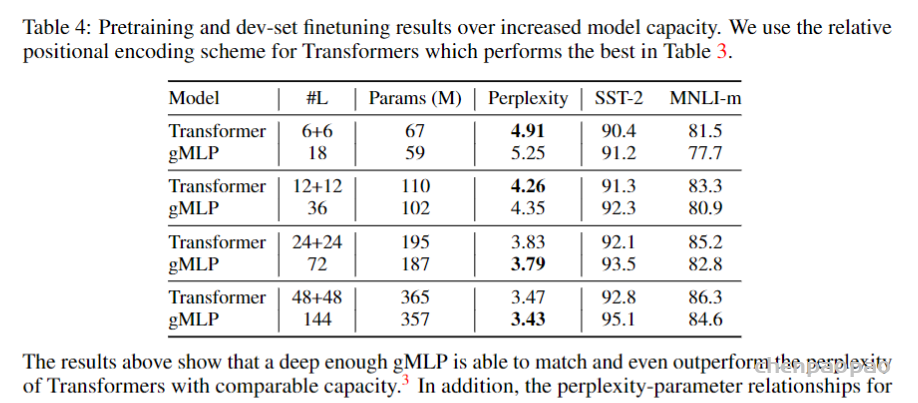
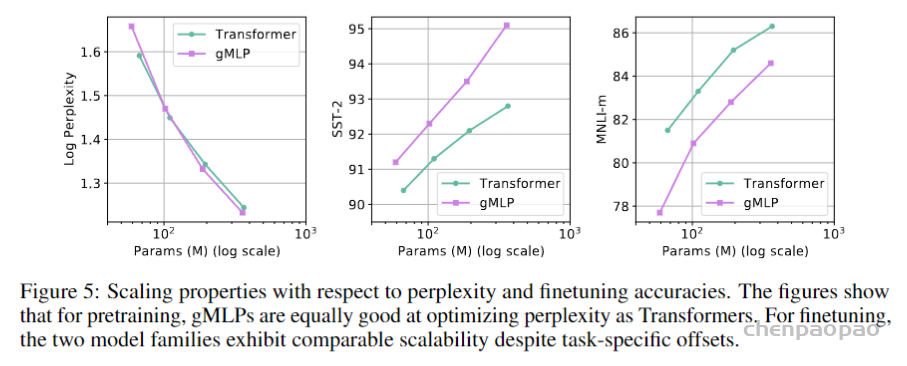
- 此文使用gMLP做masked language modeling,gMLP采用和Bert一样的设置最小化perplexity取得了和Transformer模型预训练一样好的效果。通过pretraining和finetuning实验发现随着模型容量的增加,gMLP比Transformer提升更大,表明模型相较于self-attention可能对于模型容量的大小更为敏感。
- 对于需要跨句对齐的微调任务MNLI,gMLP与Transformer相比逊色一筹。对此作者发现加上一个128特征大小的单头注意力足以使得gMLP在任何NLP任务上取得比Transformer更好的效果。
gMLP由L个如下图所示的模块堆叠而成
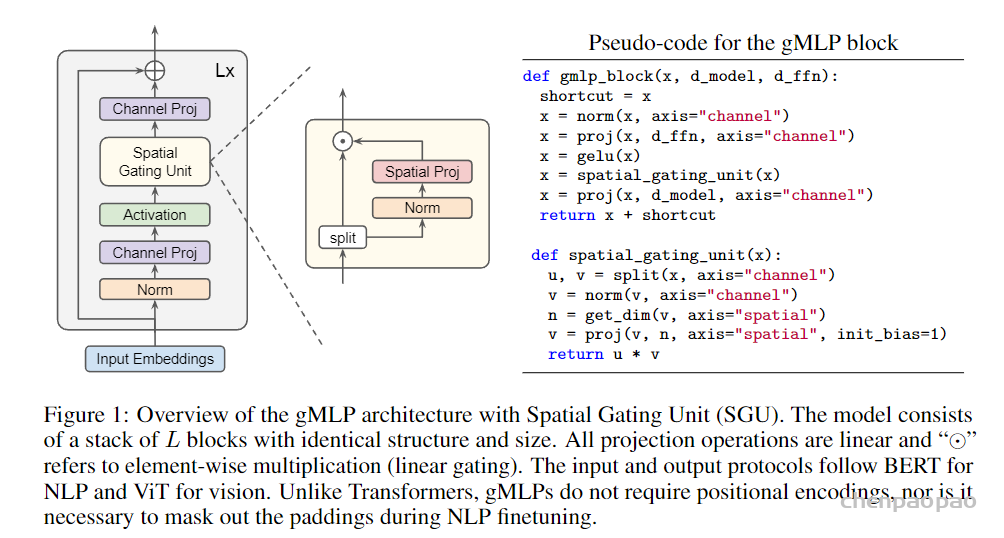
设每个模块的输入 \(X \in \mathbb{R}^{n \times d}\), n为序列长度, d为特征维度。每个模块表达如下:
\(Z=\sigma(X U), \quad \tilde{Z}=s(Z), \quad Y=\tilde{Z} V\)
\(\sigma\) 是GELU等激活函数, U 和 V 和Transformer中的FFN类似都是线性映射。为了简洁表达上式中 省略了shortcuts, normalizations 和 biases。
上式中最重要的是能捕捉空间交互的 \(s(\cdot)\) 。如果上式去掉 \(s(\cdot)\) 那么将不再能进行空间交互和FFN 并无区别。文中作者选择名为 Spatial Gating Unit (SGU) 的模块作为 \(s(\cdot)\) 捕捉空间依赖。另外,gMLP在NLP、CV任务中遵循与BERT、ViT一样的输入输出规则。
Spatial Gating Unit:
为了能有跨token的交互, \(s(\cdot)\) 操作须在空间维度。可以简单的使用线性映射表示:
\(f_{W, b}(Z)=W Z+b\)
其中 \(W \in \mathbb{R}^{n \times n}\) 表示空间交互的映射参数。在self-attention中 W 是通过 Z 动态计算得到的。 此文对上式使用gating操作以便更好的训练,如下所示:
\(s(Z)=Z \odot f_{W, b}(Z)\)
为了训练更稳定,作者将 W 和 b 分别初始化为接近 0 与 1 来保证在开始训练时 \(f_{W, b} \approx 1\) 、 \(s(Z z) \approx Z\) 使得在开始阶段gMLP近似于FFN并在训练中逐渐学习到跨token的空间信息。
作者进一步发现将 Z 从通道维度分割成两部分 \(\left(Z_1, Z_2\right)\) 进行gating操作更有用,如下所示:
\(
s(Z)=Z_1 \odot f_{W, b}\left(Z_2\right)
\)
另外函数 \(f_{W, b}\)的输入通常需要normalizel以此提升模型的稳定性。
一些思考:这里的SpatialGatingUnit里面用到了一个通道split,然后再将分割后的两部分做乘法,让我想到了NAFnet中的simplegate,这个的作用一是减少计算量(相比于GELU)、另外引入门控机制,在通道维度进行通道交织,对于模型的效果表现很好。
作者进一步分析了SGU与现有的一些操作的相似之处:首先是Gated Linear Units (GLU) 与 SGU的区别在于SGU对spatial dimension而GLU对channel dimension; 其次SGU和
Squeeze-and-Excite (SE) 一样使用hadamard-product,只是SGU并没有跨通道的映射来保 证排列不变性;SGU的空间映射可以看作depthwise convolution不过SGU只学习跨通道只是, 并没有跨通道过滤器;SGU学习的是二阶空间交互 \(z_i z_j\) , self-attention学习的是三阶交互 \(q_i k_j v_k\) , SGU的复杂度为 \(n^2 e / 2\) 而self-attention的复杂度为 \(2 n^2 d_{\text {。 }}\)
实验:
1、Image Classification
此文首先将gMLP应用于图片分类,使用ImageNet数据集而且不使用额外数据。下表首先展示了gMLP用于图片分类的参数,gMLP和ViT/B16一样使用 16×16 个patch,同时采用和DeiT相似的正则化方法防止过拟合。
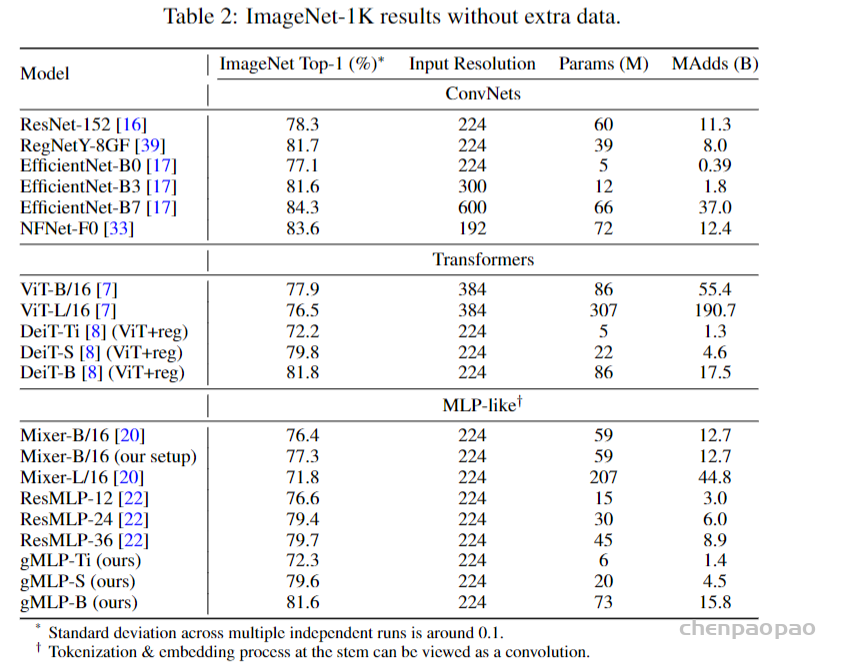
下表中gMLP与baselines在ImageNet上的结果表示gMLP取得了与视觉Transformer相当的结果,同时与其它MLP视觉模型相比,gMLP取得了准确率、速度权衡下最好的结果。
Masked Language Modeling with BERT:
此文同时将gMLP应用于masked language modeling(MLM)任务,对于预训练和微调任务,模型的输入输出规则都保持与BERT一致。
作者观察到在MLM任务最后学习到的空间映射矩阵总是Toeplitz-like matrics,如下图所示。所以作者认为gMLP是能从数据中学习到平移不变性的概念的,这使得gMLP实质起到了卷积核是整个序列长度的1-d卷积的作用。在接下来的MLM实验中,作者初始 W 为Toeplitz matrix。
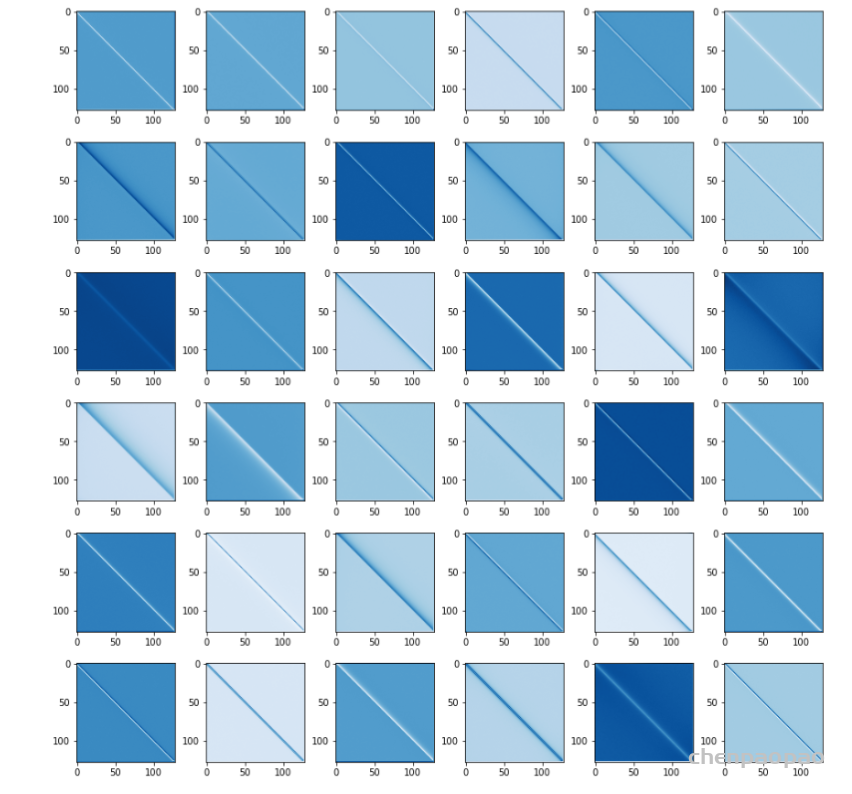
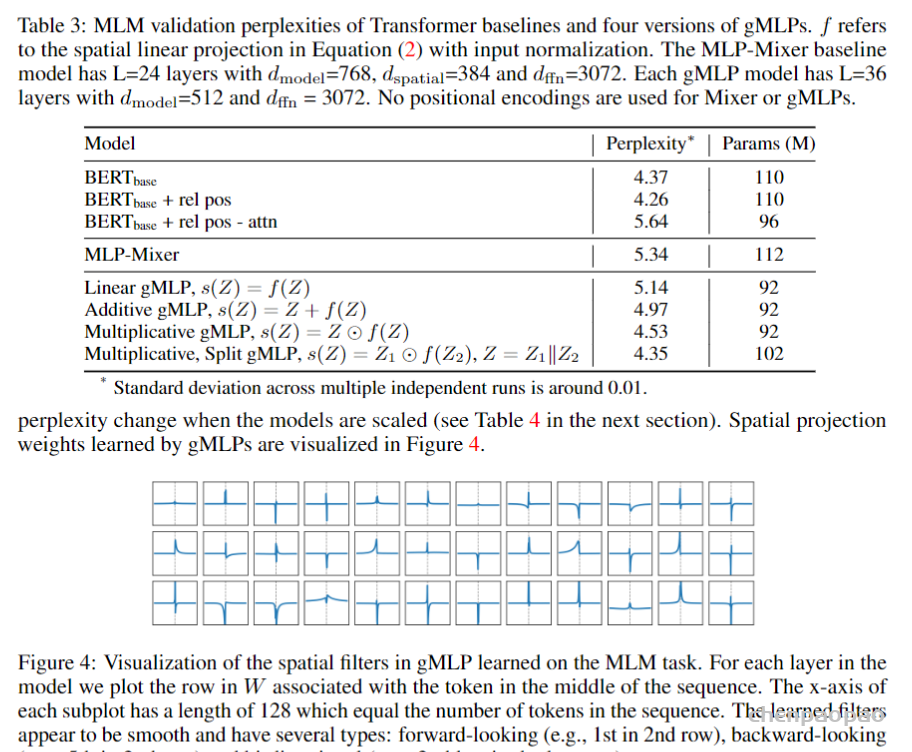
Ablation: The Importance of Gating in gMLP for BERT’s Pretraining:下表展示了gMLP的各种变体与Transoformer模型、MLP-Mixer的比较,可以看到gMLP在与Transformer相同模型大小的情况下能达到与Transformer相当的效果。同时gating操作对于空间映射十分有用。同时下图还可视化了模型学习到的空间映射参数。
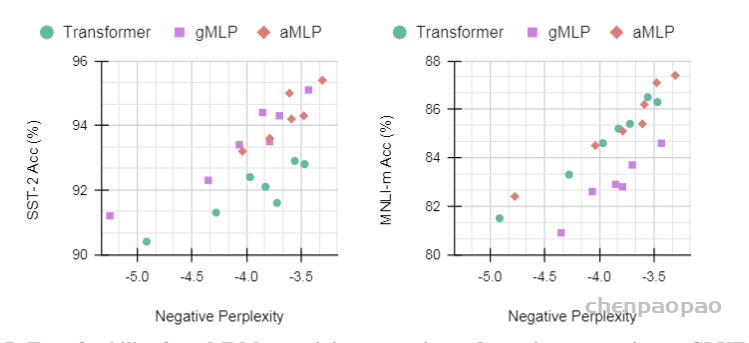
Case Study: The Behavior of gMLP as Model Size Increases:下表与下图展示了gMLP随着模型增大逐渐能有与Transformer相当的效果,可见Transformer的效果应该主要是依赖于模型尺寸而非self-attention。
- Ablation: The Usefulness of Tiny Attention in BERT’s Finetuning:从上面的Case Study可以发现gMLP对于需要跨句子连接的finetuing任务可能不及Transformer,所以作者提出了gMLP的增强版aMLP。aMLP相较于gMLP仅增加了一个单头64的self-attention如下图所示:

从下图结果可以发现aMLP相较于gMLP极大提升了效果并在所有task超过了Transformer。