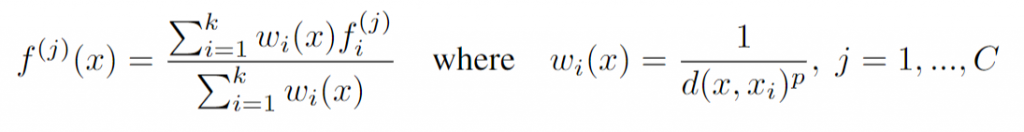High-Resolution Image Synthesis with Latent Diffusion Models
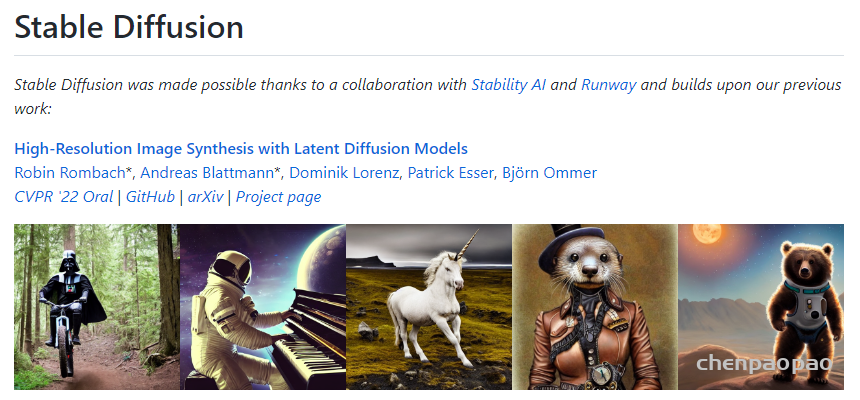
Stable Diffusion 是一个“文本到图像”的人工智能模型。近日,Stable AI 公司向公众开放了它的预训练模型权重。当输入一个文字描述时,Stable Diffusion 可以生成 512×512 像素的图像,这些图像如相片般真实,反映了文字描述的场景。
这个项目先是经历了早期的代码发布,而后又向研究界有限制地发布了模型权重,现在模型权重已经向公众开放。对于最新版本,任何人都可以在为普通消费者设计的硬件上下载和使用 Stable Diffusion。该模型不仅支持文本到图像的生成,而且还支持图像到图像的风格转换和放大。与之一同发布的还有 DreamStudio 测试版,这是一个用于该模型的 API 和 Web 用户界面。
Stable Diffusion 可以支持众多的操作。与 DALL-E 类似,它可以生成一个高质量的图像,并使其完全符合所需图像的文字描述。我们也可以使用一个直观的草图和所需图像的文字描述,从而创建一个看起来很真实的图像。类似的“图像到图像”的能力可以在 Meta AI 的 Make-A-Scene 模型中找到,该模型刚发布不久。
微软亚洲研究院的研究项目 3D 视频会议系统 VirtualCube,可以让在线会议的与会者建立自然的眼神交互,沉浸式的体验就像在同一个房间内面对面交流一样。该技术的相关论文被全球虚拟现实学术会议 IEEE Virtual Reality 2022 接收并获得了大会的最佳论文奖(Best Paper Award – Journal Papers Track)。
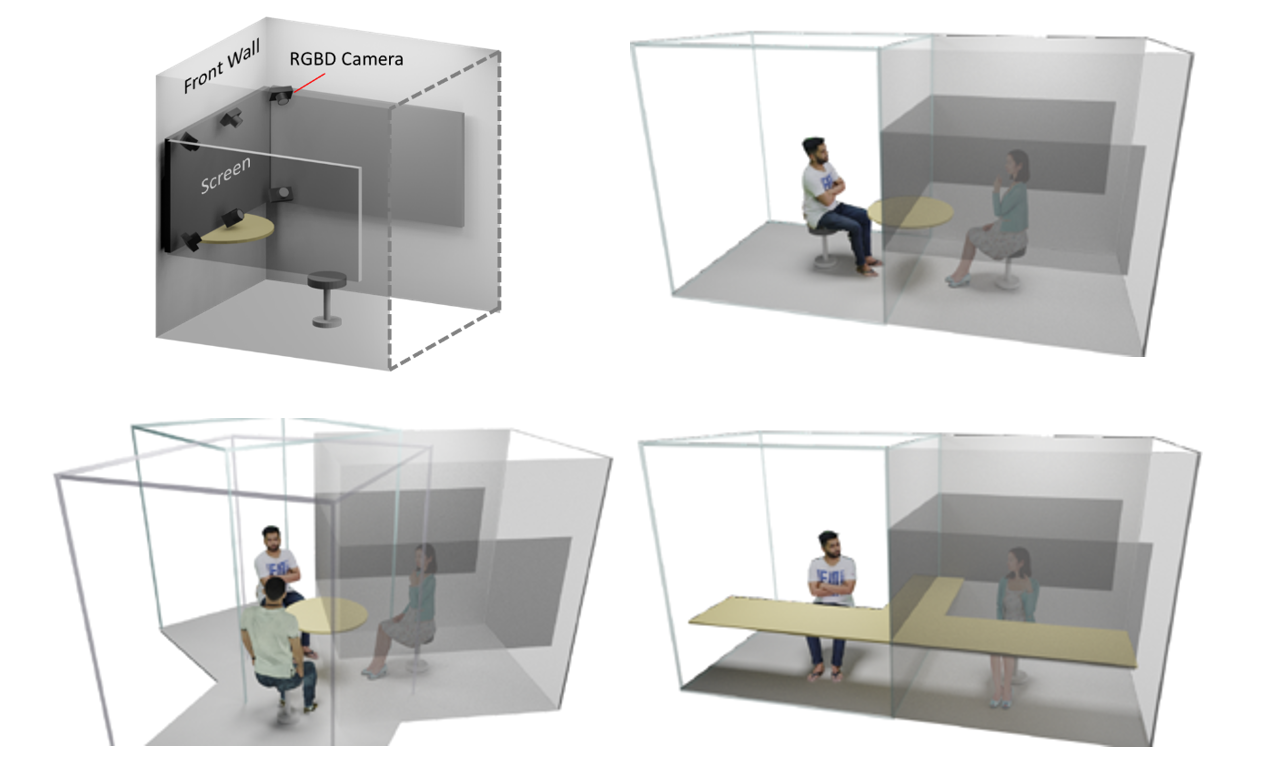
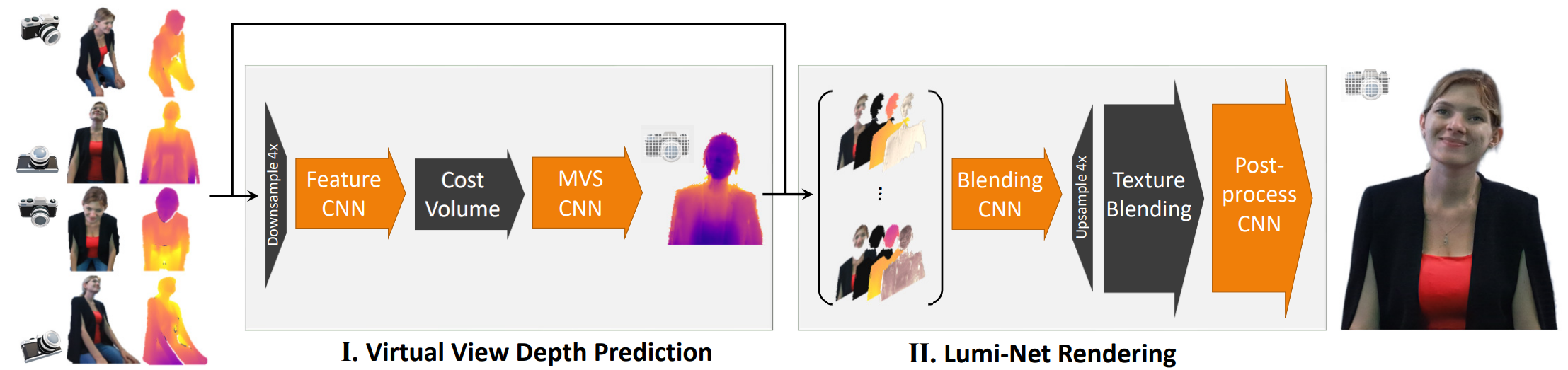
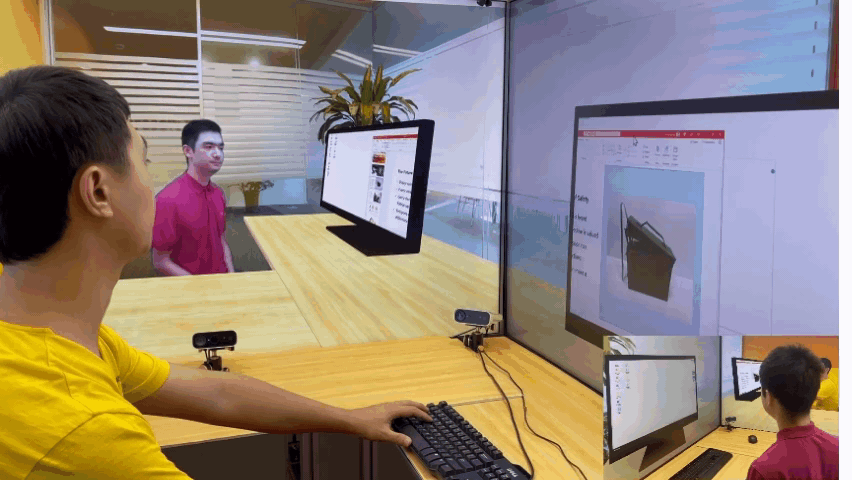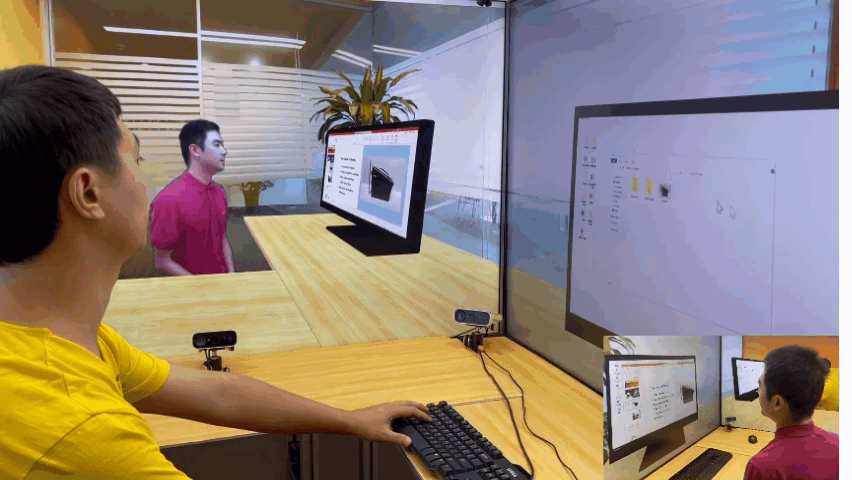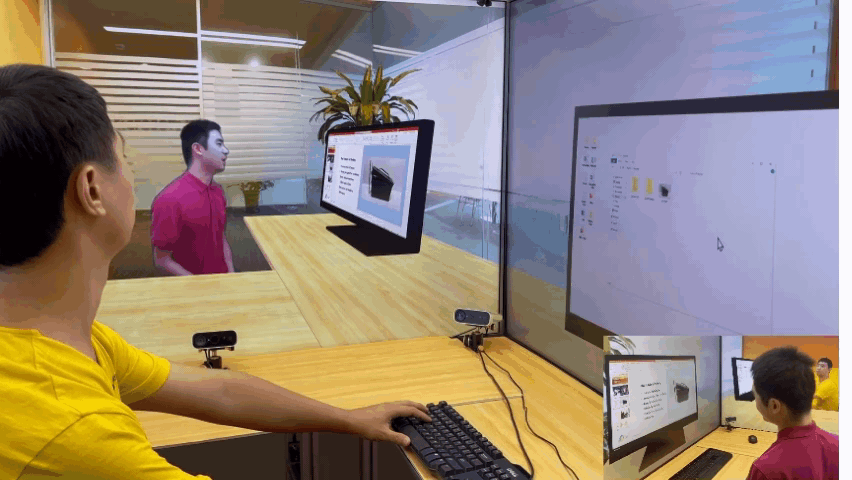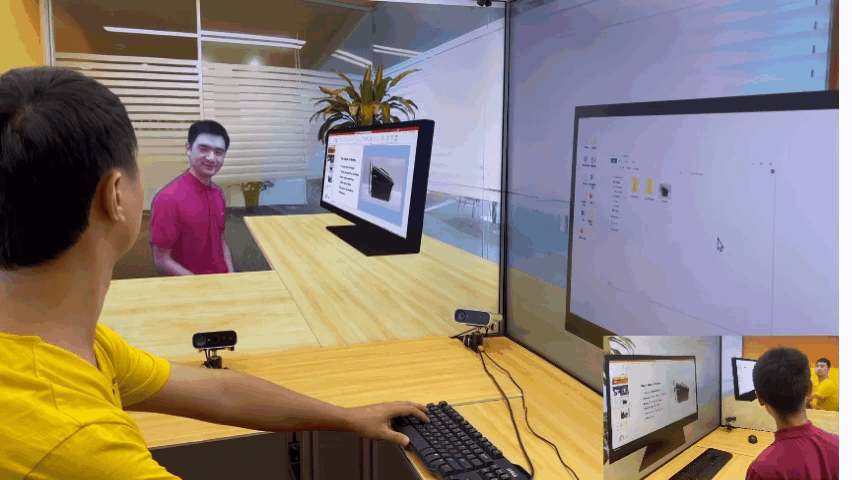
为了解决这些问题,微软亚洲研究院提出了创新的 3D 视频会议系统——VirtualCube,它可以在远程视频会议中建立起真人等大的 3D 形象,无论是正面沟通,还是侧方交流,系统都能够正确捕捉到与会者的眼神、动态,建立起眼神和肢体交流。相关论文被全球虚拟现实学术会议 IEEE Virtual Reality 2022 接收并获得了大会的最佳论文奖(Best Paper Award – Journal Papers Track)
VirtualCube 系统具有三大优势:
标准化、简单化,全部使用现有的普通硬件设备。与办公场所中常见的格子间(Cubicle)类似,每个 VirtualCube 都提供了一致的物理环境和设备配置:与会者正前方安装有6个 Azure Kinect RGBD 摄像头,以捕捉真人的图像和眼神等动作;在与会者的正面和左右两侧还各有一个大尺寸的显示屏,以创造出身临其境的参会感。使用现有的、标准化的硬件能够大大简化用户设备校准的工作量,从而实现 3D 视频系统的快速部署和应用。
感。使用现有的、标准化的硬件能够大大简化用户设备校准的工作量,从而实现 3D 视频系统的快速部署和应用。
实时、高质量渲染真人图像。VirtualCube 可以捕捉到参与者的各种细微变化,包括人的皮肤颜色、纹理,面部或衣服上的反射光泽等,并实时渲染生成真人大小的 3D 形象,显示在远程与会者的屏幕中。而且虚拟会议环境的背景也可以根据用户的需求自由选择。
任意变换会议场景,都能身临其境
V-Cube View和V-Cube Assembly算法双剑合璧,沉浸式会议体验不再是难题
其实业界对 3D 视频会议的研究从未间断过。早在2000年,就有人曾提出过与类似混合现实技术有关的畅想。基于这个设想,科研人员一直在探索如何将视频会议以更逼真、更自然的方式呈现,期间也出现了不同的技术路线和解决方案,但都没有达到理想的效果。对此,微软亚洲研究院主管研究员张译中和杨蛟龙表示,过往的研究仍然有很多没有解决的问题:首先,在真实环境下,无论放置怎样的单目摄像设备,即使图像质量再高,与会者也很难形成自然的眼神交流,特别是多人会议的情况;其次,很多研究针对特定的会议场景进行优化,如两个人面对面的会议或三人的圆桌会议,很难支持不同的会议设置;第三,虽然在影视界我们能够看到一些逼真的虚拟人,但那是需要专业的技术和影视团队长时间打磨和优化才能实现的,仍然需要一定的手工劳动,目前无法进行实时捕捉和实时渲染。
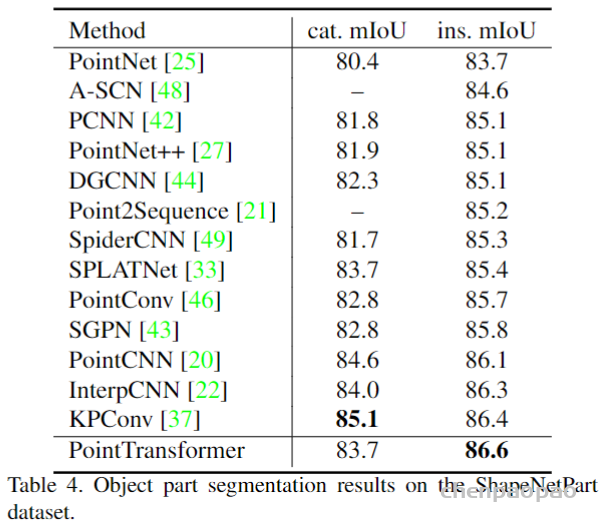
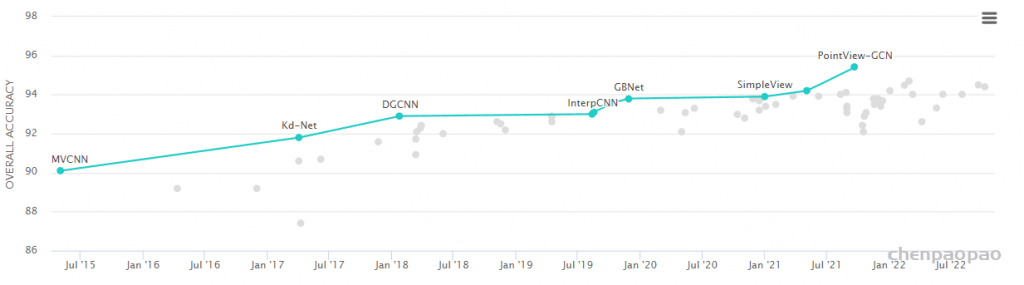
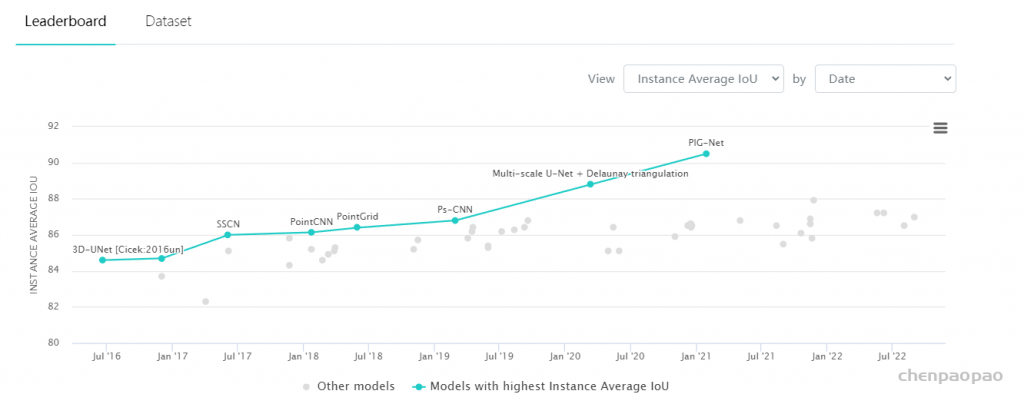
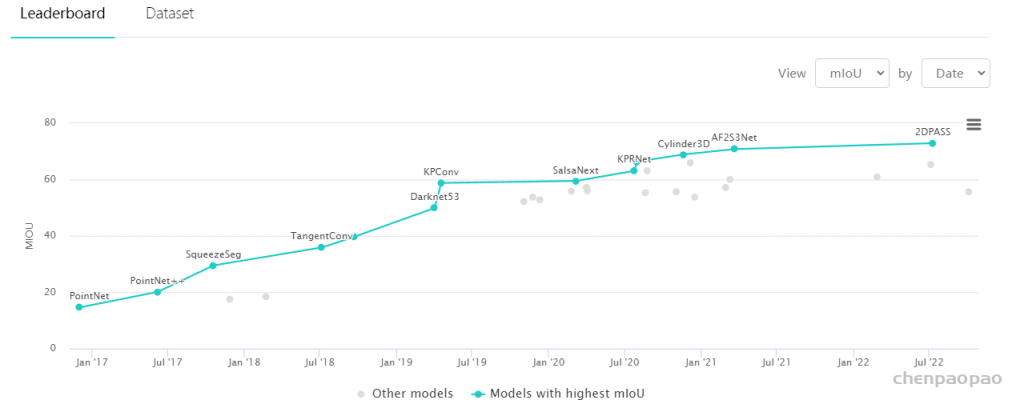
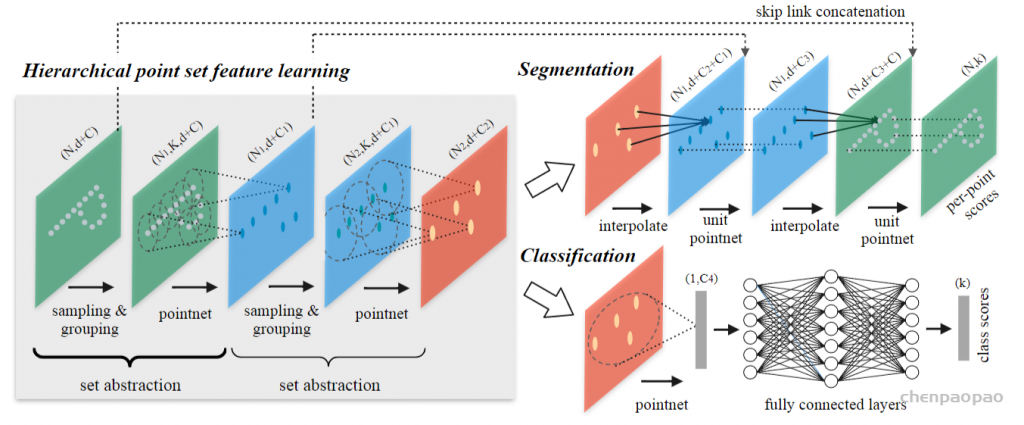
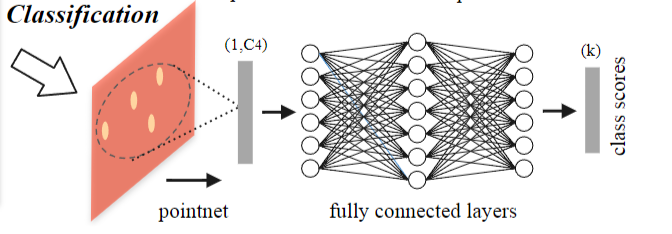
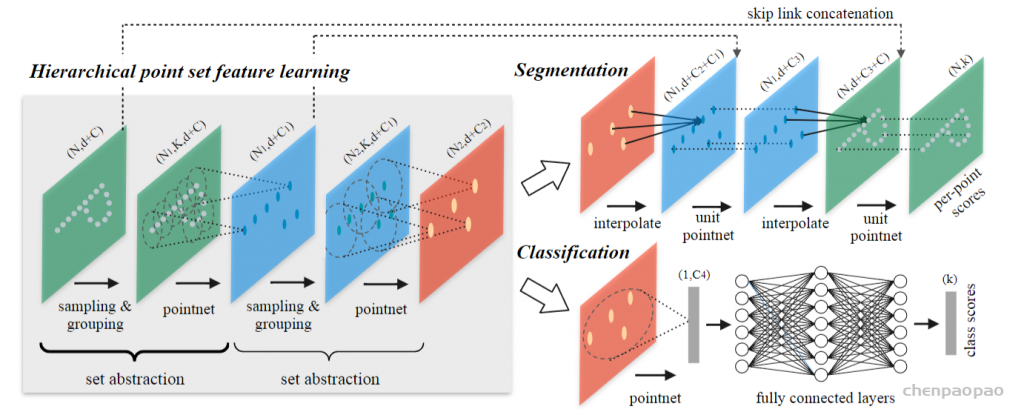
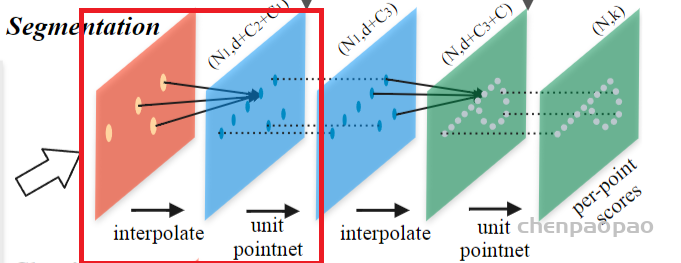
3D Point Cloud Classification on ModelNet40 3D Point Cloud Classification on ModelNet40 3D Part Segmentation on ShapeNet-Part3D Semantic Segmentation on SemanticKITTI
def pointnet_sa_module(xyz, points, npoint, radius, nsample, mlp, mlp2, group_all, is_training, bn_decay, scope, bn=True, pooling='max', knn=False, use_xyz=True, use_nchw=False):
''' PointNet Set Abstraction (SA) Module
Input:
xyz: (batch_size, ndataset, 3) TF tensor
points: (batch_size, ndataset, channel) TF tensor
npoint: int32 -- #points sampled in farthest point sampling
radius: float32 -- search radius in local region
nsample: int32 -- how many points in each local region
mlp: list of int32 -- output size for MLP on each point
mlp2: list of int32 -- output size for MLP on each region
group_all: bool -- group all points into one PC if set true, OVERRIDE
npoint, radius and nsample settings
use_xyz: bool, if True concat XYZ with local point features, otherwise just use point features
use_nchw: bool, if True, use NCHW data format for conv2d, which is usually faster than NHWC format
Return:
new_xyz: (batch_size, npoint, 3) TF tensor
new_points: (batch_size, npoint, mlp[-1] or mlp2[-1]) TF tensor
idx: (batch_size, npoint, nsample) int32 -- indices for local regions
'''
data_format = 'NCHW' if use_nchw else 'NHWC'
with tf.variable_scope(scope) as sc:
# Sample and Grouping
if group_all:
nsample = xyz.get_shape()[1].value
new_xyz, new_points, idx, grouped_xyz = sample_and_group_all(xyz, points, use_xyz)
else:
new_xyz, new_points, idx, grouped_xyz = sample_and_group(npoint, radius, nsample, xyz, points, knn, use_xyz)
# Point Feature Embedding
if use_nchw: new_points = tf.transpose(new_points, [0,3,1,2])
for i, num_out_channel in enumerate(mlp):
new_points = tf_util.conv2d(new_points, num_out_channel, [1,1],
padding='VALID', stride=[1,1],
bn=bn, is_training=is_training,
scope='conv%d'%(i), bn_decay=bn_decay,
data_format=data_format)
if use_nchw: new_points = tf.transpose(new_points, [0,2,3,1])
# Pooling in Local Regions
if pooling=='max':
new_points = tf.reduce_max(new_points, axis=[2], keep_dims=True, name='maxpool')
elif pooling=='avg':
new_points = tf.reduce_mean(new_points, axis=[2], keep_dims=True, name='avgpool')
elif pooling=='weighted_avg':
with tf.variable_scope('weighted_avg'):
dists = tf.norm(grouped_xyz,axis=-1,ord=2,keep_dims=True)
exp_dists = tf.exp(-dists * 5)
weights = exp_dists/tf.reduce_sum(exp_dists,axis=2,keep_dims=True) # (batch_size, npoint, nsample, 1)
new_points *= weights # (batch_size, npoint, nsample, mlp[-1])
new_points = tf.reduce_sum(new_points, axis=2, keep_dims=True)
elif pooling=='max_and_avg':
max_points = tf.reduce_max(new_points, axis=[2], keep_dims=True, name='maxpool')
avg_points = tf.reduce_mean(new_points, axis=[2], keep_dims=True, name='avgpool')
new_points = tf.concat([avg_points, max_points], axis=-1)
# [Optional] Further Processing
if mlp2 is not None:
if use_nchw: new_points = tf.transpose(new_points, [0,3,1,2])
for i, num_out_channel in enumerate(mlp2):
new_points = tf_util.conv2d(new_points, num_out_channel, [1,1],
padding='VALID', stride=[1,1],
bn=bn, is_training=is_training,
scope='conv_post_%d'%(i), bn_decay=bn_decay,
data_format=data_format)
if use_nchw: new_points = tf.transpose(new_points, [0,2,3,1])
new_points = tf.squeeze(new_points, [2]) # (batch_size, npoints, mlp2[-1])
return new_xyz, new_points, idx
还有个问题:query ball point如何保证对于每个局部邻域,采样点的数量都是一样的呢? 事实上,如果query ball的点数量大于规模 K ,那么直接取前 K 个作为局部邻域;如果小于,那么直接对某个点重采样,凑够规模 K
KNN和query ball的区别:(摘自原文)Compared with kNN, ball query’s local neighborhood guarantees a fixed region scale thus making local region feature more generalizable across space, which is preferred for tasks requiring local pattern recognition (e.g. semantic point labeling).也就是query ball更加适合于应用在局部/细节识别的应用上,比如局部分割。
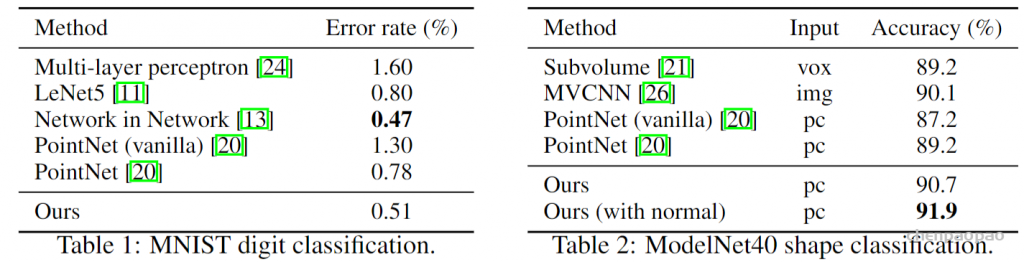
MNIST: Images of handwritten digits with 60k training and 10k testing samples.(用于分类)
ModelNet40: CAD models of 40 categories (mostly man-made). We use the official split with 9,843 shapes for training and 2,468 for testing. (用于分类)
SHREC15: 1200 shapes from 50 categories. Each category contains 24 shapes which are mostly organic ones with various poses such as horses, cats, etc. We use five fold cross validation to acquire classification accuracy on this dataset. (用于分类)
ScanNet: 1513 scanned and reconstructed indoor scenes. We follow the experiment setting in [5] and use 1201 scenes for training, 312 scenes for test. (用于分割)