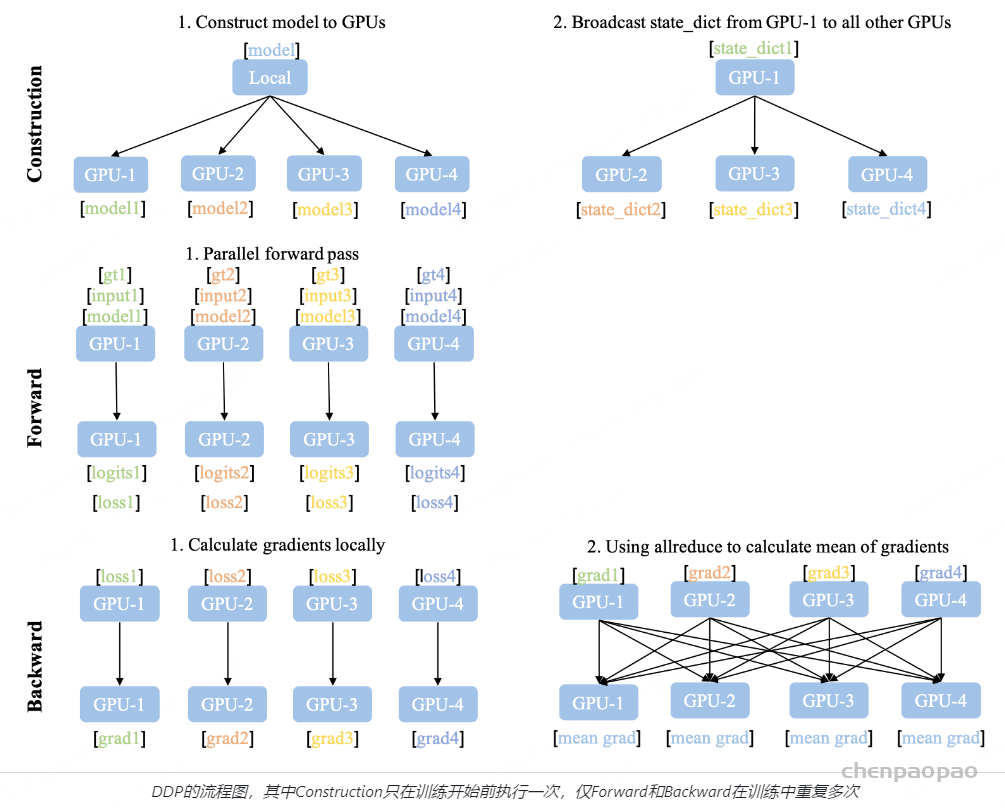
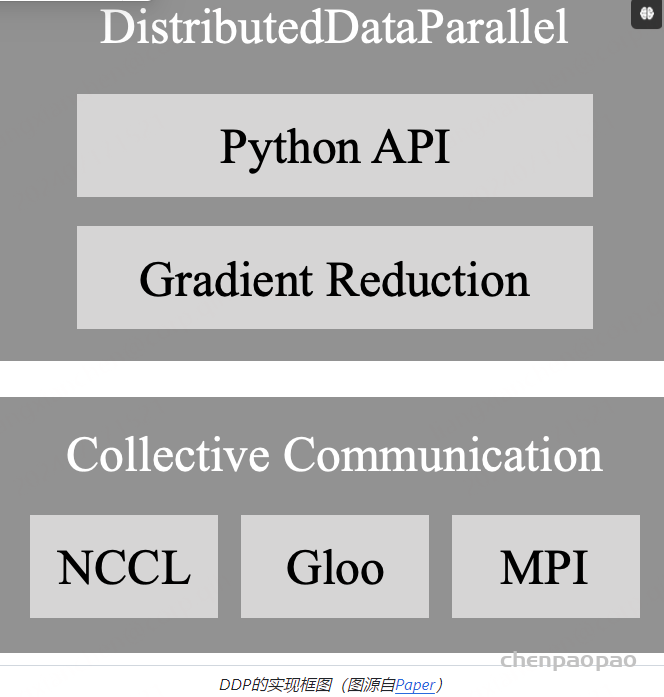
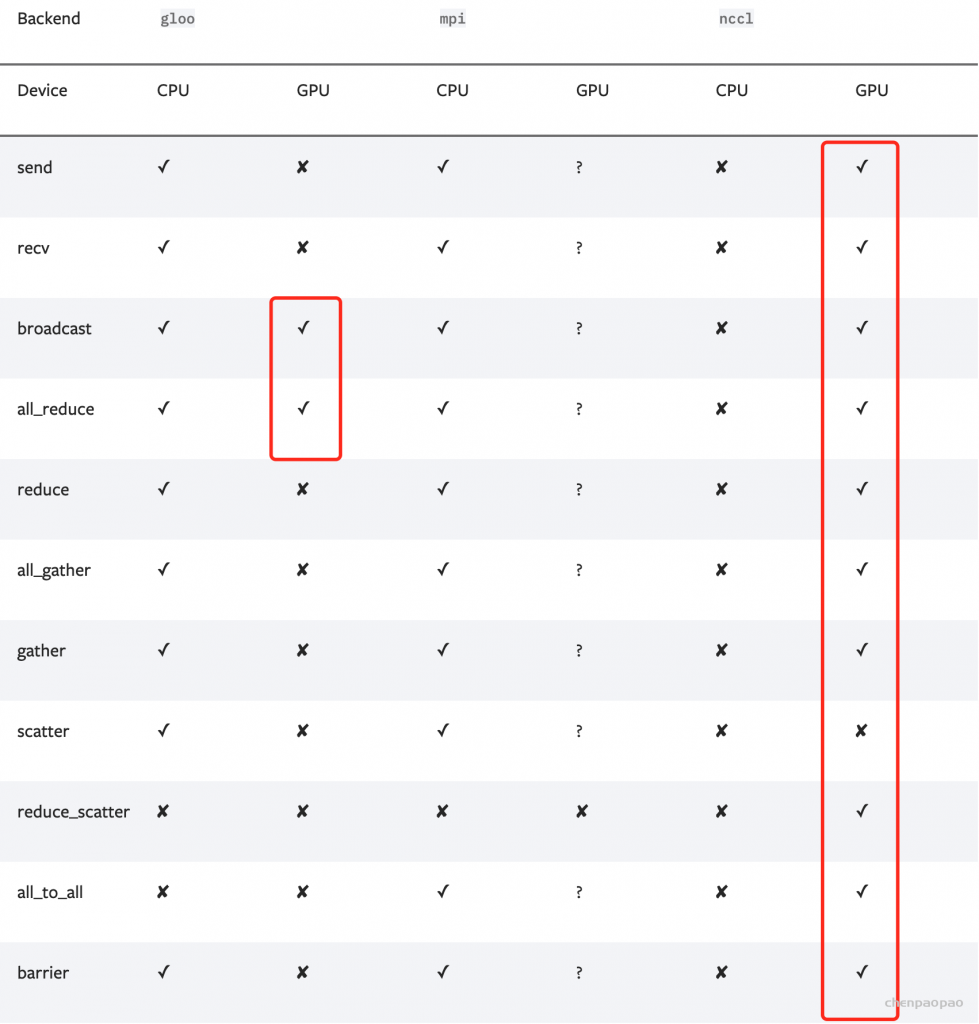
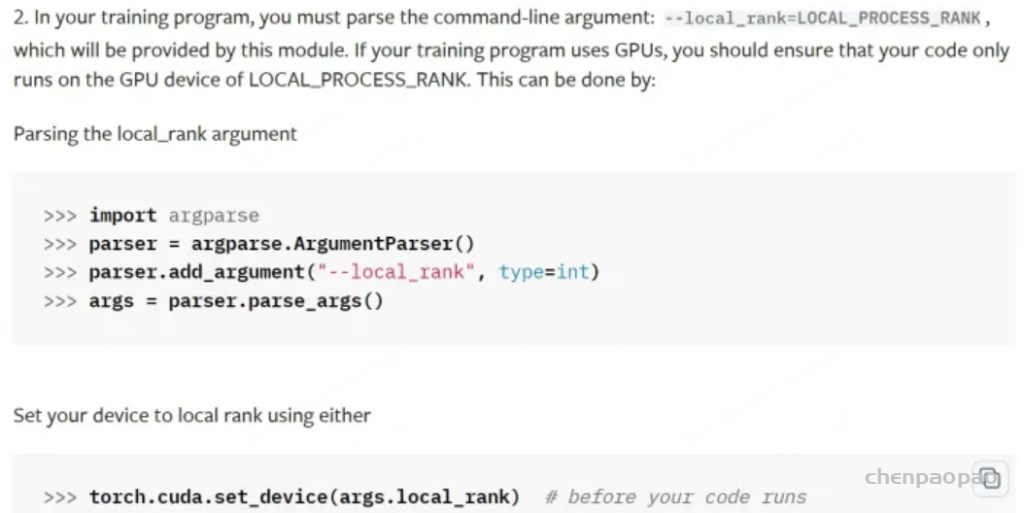
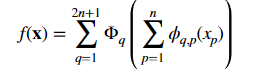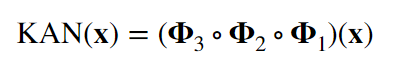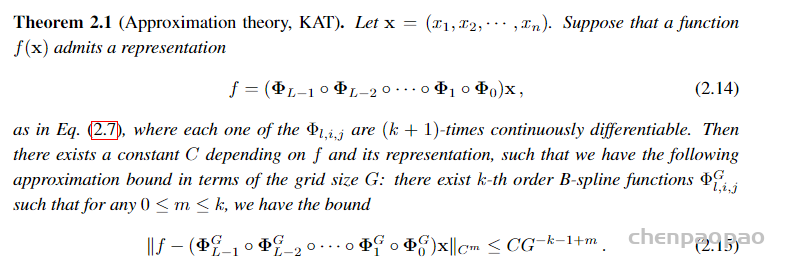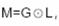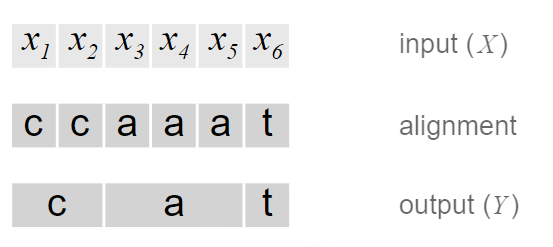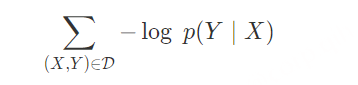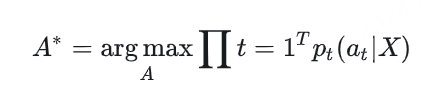from datetime import datetime
import argparse
import torchvision
import torchvision.transforms as transforms
import torch
import torch.nn as nn
import torch.distributed as dist
from tqdm import tqdm
定义一个简单的卷积神经网络模型。
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7*7*32, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
定义主函数,添加一些启动脚本的可选参数。
def main():
parser = argparse.ArgumentParser()
parser.add_argument('-g', '--gpuid', default=0, type=int,
help="which gpu to use")
parser.add_argument('-e', '--epochs', default=2, type=int,
metavar='N',
help='number of total epochs to run')
parser.add_argument('-b', '--batch_size', default=4, type=int,
metavar='N',
help='number of batchsize')
args = parser.parse_args()
train(args.gpuid, args)
然后给出训练函数的详细内容。
def train(gpu, args):
model = ConvNet()
model.cuda(gpu)
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().to(gpu)
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
# Data loading code
train_dataset = torchvision.datasets.MNIST(root='./data',
train=True,
transform=transforms.ToTensor(),
download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=args.batch_size,
shuffle=True,
num_workers=0,
pin_memory=True,
sampler=None)
start = datetime.now()
total_step = len(train_loader)
for epoch in range(args.epochs):
model.train()
for i, (images, labels) in enumerate(tqdm(train_loader)):
images = images.to(gpu)
labels = labels.to(gpu)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch + 1, args.epochs, i + 1, total_step,
loss.item()))
print("Training complete in: " + str(datetime.now() - start))
System:
You are a translator proficient in English and {language}. Your task is to translate the following English text into {language}, focusing on a natural and fluent result that avoids “translationese.” Please consider these points:
1. Keep proper nouns, brands, and geographical names in English.
2. Retain technical terms or jargon in English, but feel free to explain in {language} if necessary.
3. Use {language} idiomatic expressions for English idioms or proverbs to ensure cultural relevance.
4. Ensure quotes or direct speech sound natural in {language}, maintaining the original’s tone.
5. For acronyms, provide the full form in {language} with the English acronym in parentheses.
User:
Text for translation: {text}
Assistant:
{translation results}
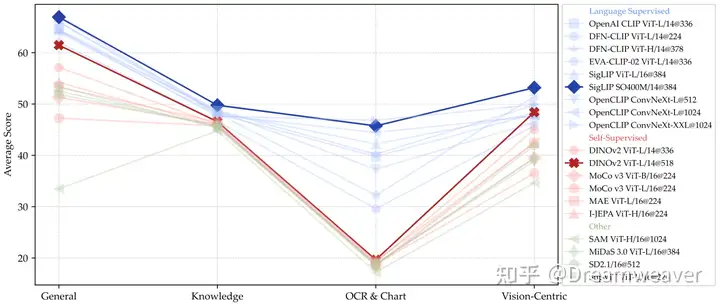
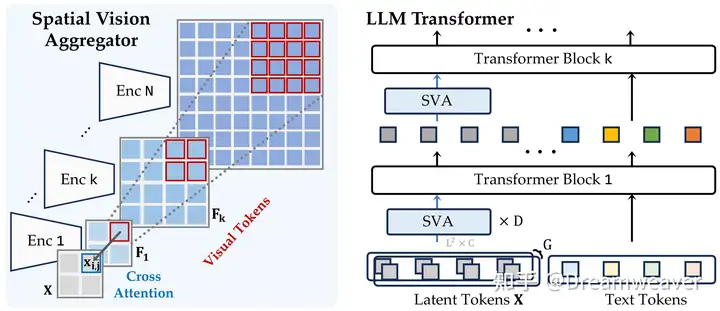
24年6月,LeCun&谢赛宁团队发布Cambrian-1,关注以视觉为中心的多模态LLM,开源了8B/13B/34B的模型。当前多模态LLM仍存在较大的视觉缺陷,需要增强视觉表征以更好地和语言模态交互,赋予模型在真实场景更强的感知定位能力。这项研究的一大意义在于影响多模态LLM的工作开始重视视觉表征质量的提升,而非一直scale up LLM。
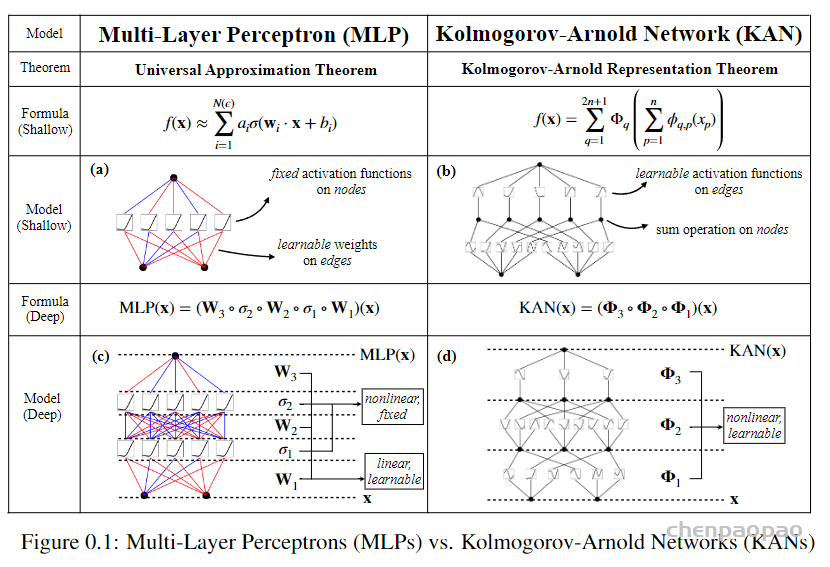
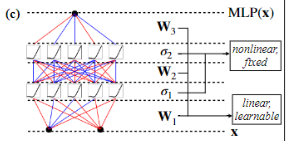
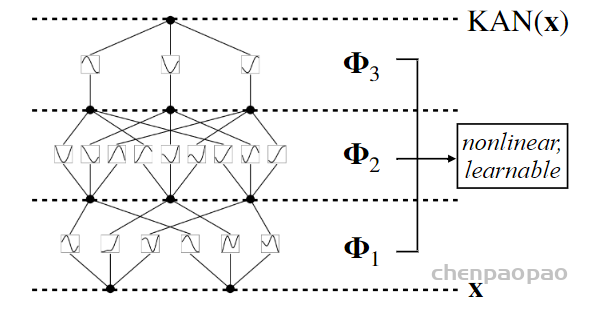
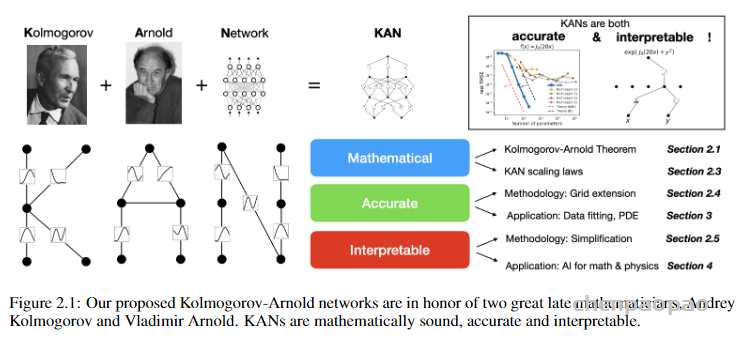
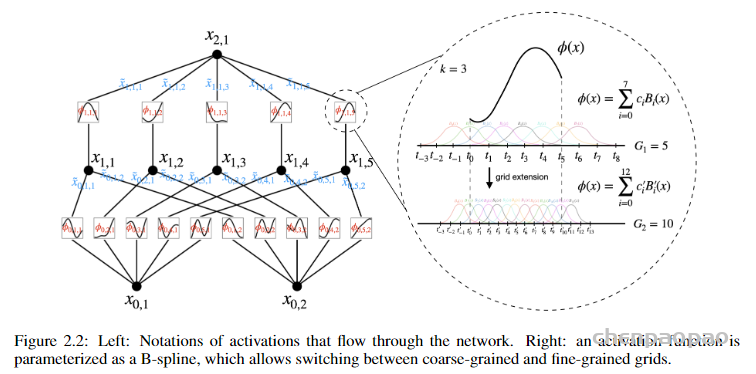
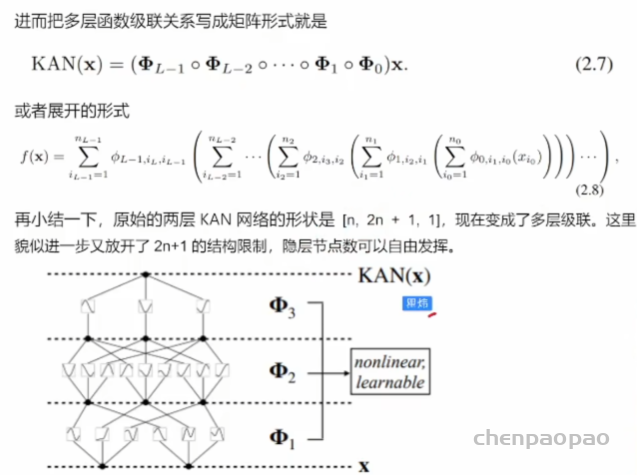
MLPs通过增加模型的宽度和深度可以提高性能,但这种方法效率低下,因为需要独立地训练不同大小的模型。KANS:开始可以用较少的参数训练,然后通过简单地细化其样条网格来增加参数,无需重新训练整个模型。 基本原理就是通过将样条函数(splines)旧的粗网格转换为更细的网格,并对应地调整参数,无需从头开始训练就能扩展现有的 KAN 模型。这种技术称为“网格扩展”(grid extension)
文章用了一个小例子来证明这一点。用 KAN 网络逼近一个函数。上图中横轴的每个grid-x“标签代表了在特定训练步骤时进行网格细化的时点。每次这样的标记出现,都意味着网格点数量在这个步骤有所增加,从而使模型能够更细致地逼近目标函数,这通常会导致误差的下降。表明网格点的增加直接影响了模型的学习效果,提高了逼近目标函数的精度。左右图表示了两种不同结构的网络。
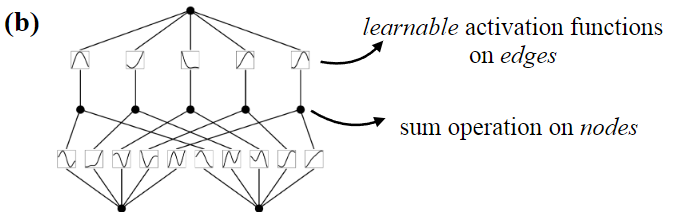
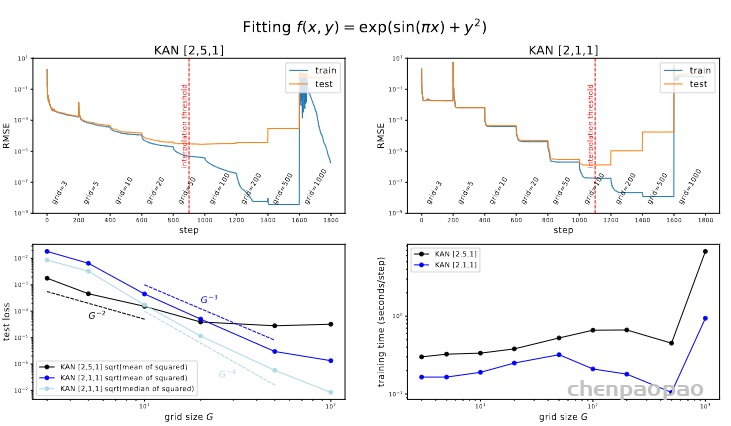
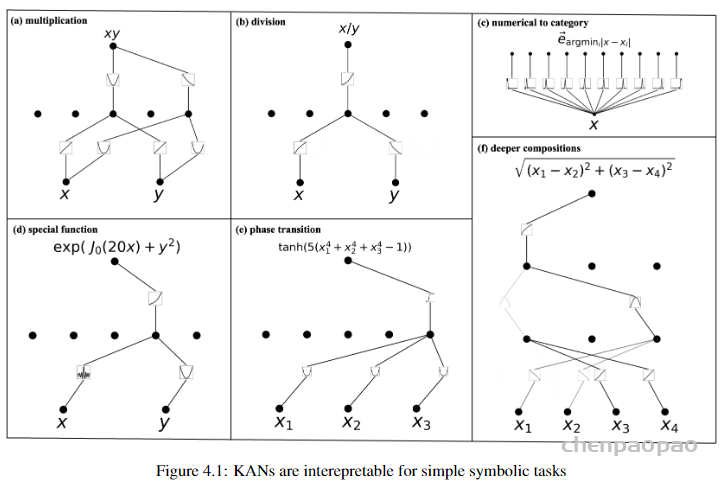
尽管上面介绍了 KAN 的不少好处,但遇到实际问题时该怎么设计网络结构依然是个玄学。因此需要有种方法能自动发现这种结构。本文提出的方法是使用稀疏正则化和剪枝技术从较大的 KAN 开始训练,剪枝后的 KAN 比未剪枝的 KAN 更易解释。为了使 KAN 达到最大的可解释性,本文提出了几种简化技术,并提供了一个示例,说明用户如何与KAN 进行交互以增强可解释性。
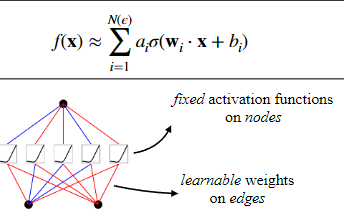
1.稀疏化:使用数据集训练一个 KAN 模型,使其能够尽可能地拟合目标函数。MLP通常使用 L1 正则化来促进权重的稀疏性,L1正则化倾向于推动权重值向零收缩特别是那些对模型输出影响不大的权重。权重短阵的“稀疏化“可以降低模型的复杂性,减少模型的存储需求和计算负担,因为只需要处理非零权重;还能提高模型的泛化能力,减少过拟合的风险。
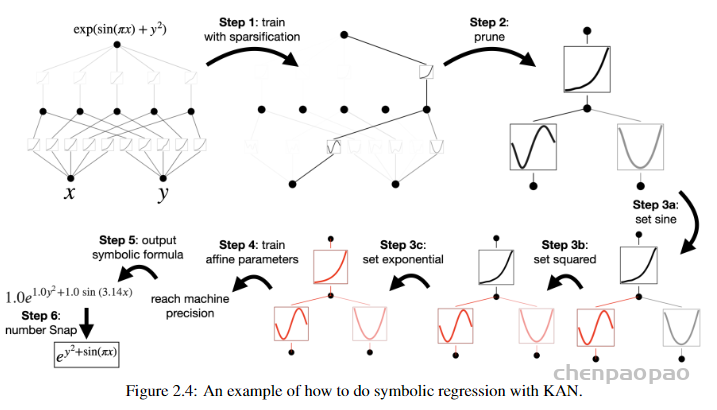
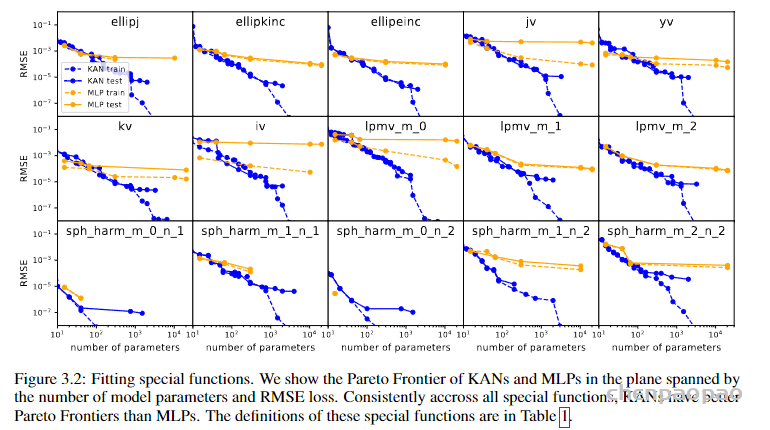
接着对比了 KAN 和 MLP 在高难度的特殊函数拟合任务上的性能,结论类似。随参数量增多KAN(蓝色)表现稳定,越来越好,而MLP(黄色)出现平台期。KANS在维持低误差的同时,表现出更好的参数效率和泛化能力。这一点对于设计高效目精确的机器学习模型来说是极其重要的,特别是在资源受限或对精度要求极高的应用中。
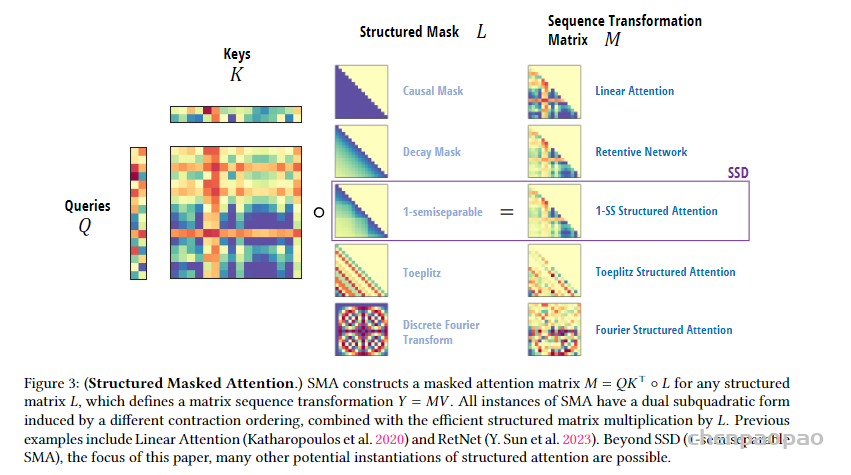
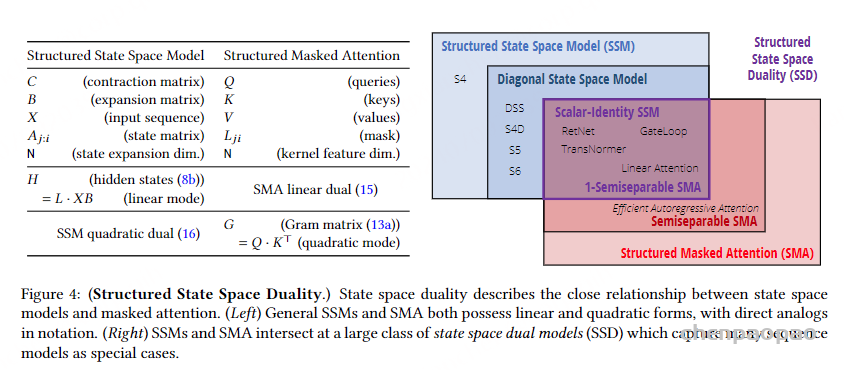
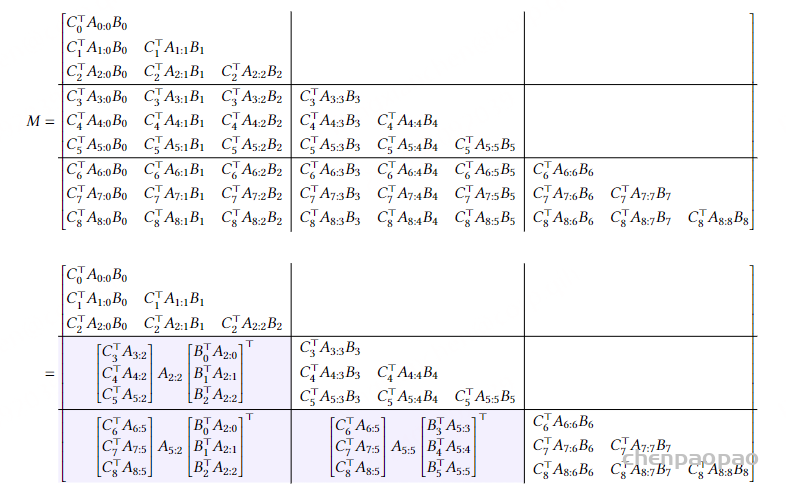
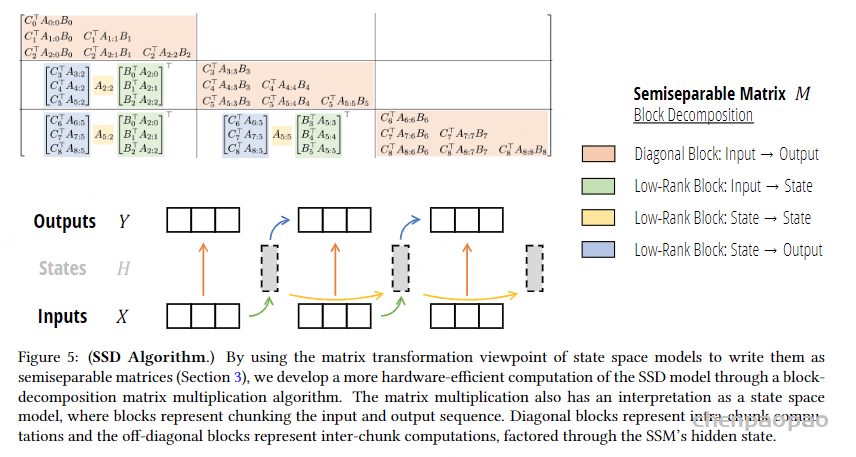
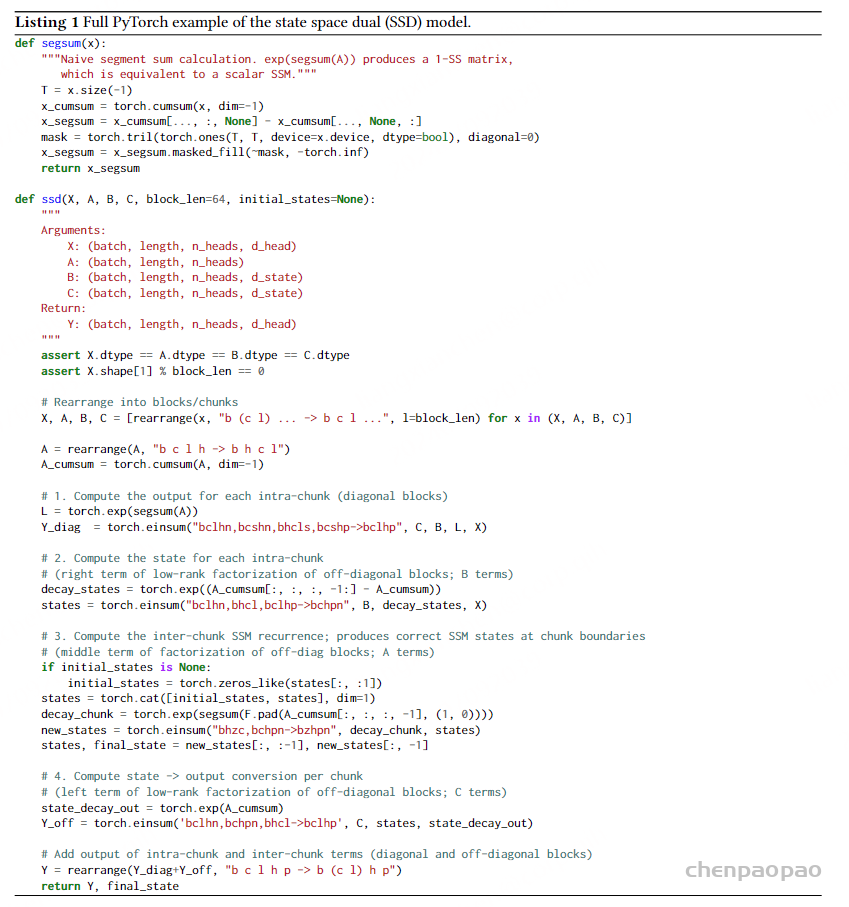
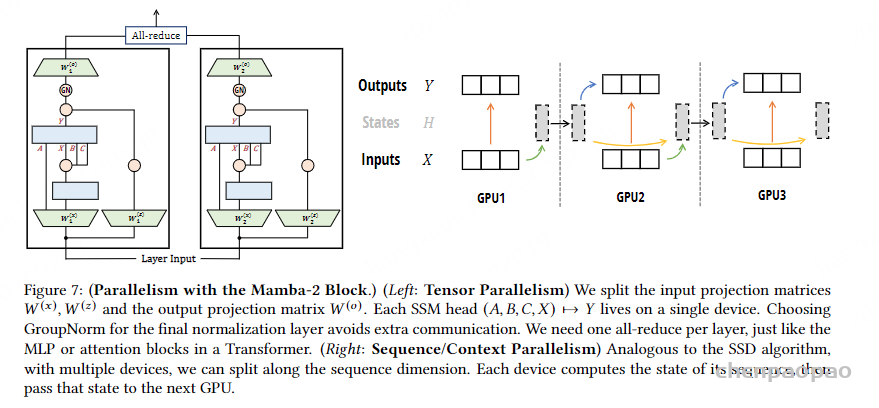
图的下半部分展示了通过这种块分解方法进行计算的流程。输入序列 X 被分解成多个块,每个块对应图中的一个黑色虚线框。输入块通过低秩块(绿色箭头)和对角块(色箭头)进行计算,得到中间的状态块 H。状态块之间通过低秩块(黄色箭头)进行计算,表示状态间的传递。最终,状态块通过对角块(蓝色箭头)计算得到输出块Y。
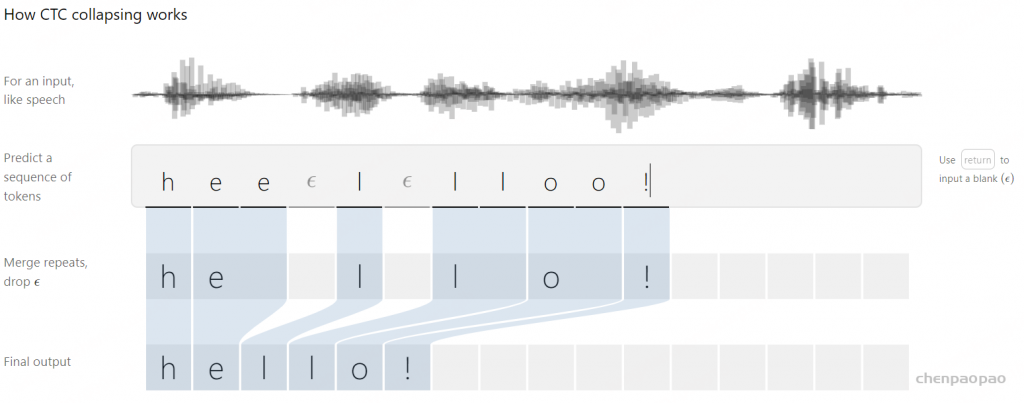
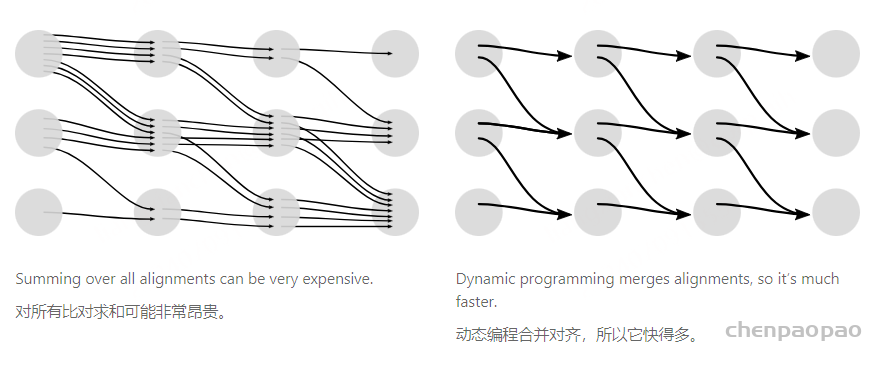
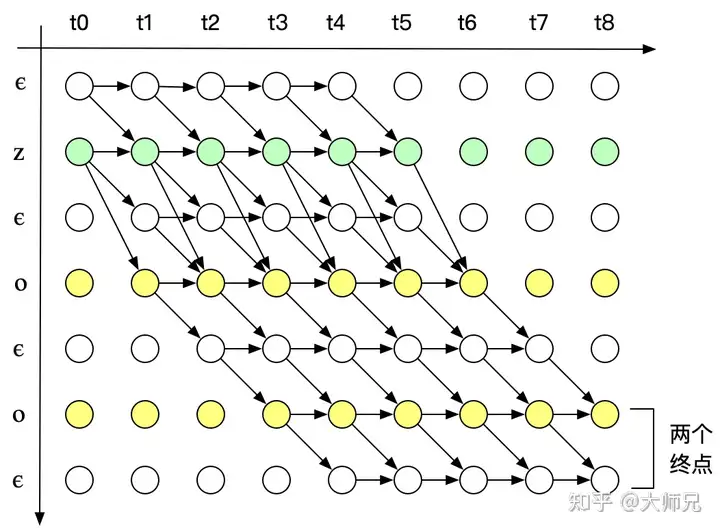
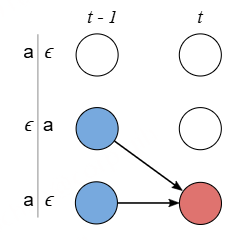
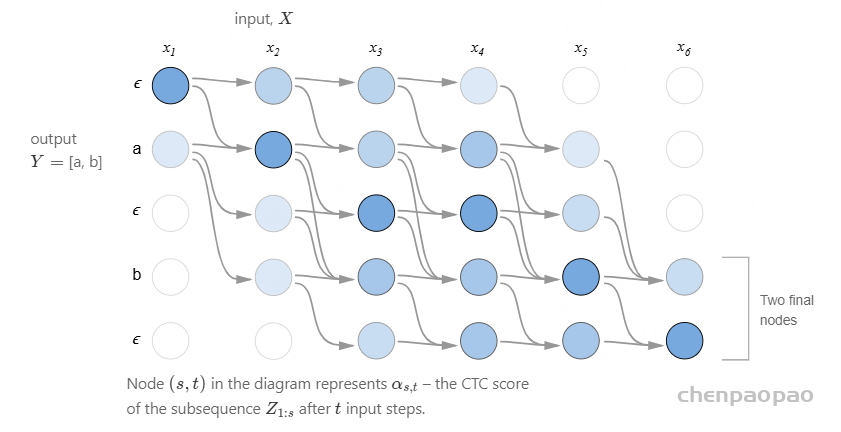
在语音识别中,我们的数据集是音频文件和其对应的文本,不幸的是,音频文件和文本很难在单词的单位上对齐。除了语言识别,在OCR,机器翻译中,都存在类似的Sequence to Sequence结构,同样也需要在预处理操作时进行对齐,但是这种对齐有时候是非常困难的。如果不使用对齐而直接训练模型时,由于人的语速的不同,或者字符间距离的不同,导致模型很难收敛。