代码实例:
#include <iostream>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
using namespace std;
class Stack
{
public:
Stack(int size=1024);
~Stack();
void init();
bool isEmpty();
bool isFull();
void push(int data);
int pop();
private:
int* space;
int top;
};
Stack::Stack(int size)
{
space = new int[size];
top = 0;
}
Stack::~Stack()
{
delete []space;
}
//void Stack::init()
//{
// memset(space,0,sizeof(space));
// top = 0;
//}
bool Stack::isEmpty()
{
return top == 0;
}
bool Stack::isFull()
{
return top == 1024;
}
void Stack::push(int data)
{
space[top++] = data;
}
int Stack::pop()
{
return space[--top];
}
int main()
{
// Stack s;
Stack s(100);
// s.init();
if(!s.isFull())
s.push(10);
if(!s.isFull())
s.push(20);
if(!s.isFull())
s.push(30);
if(!s.isFull())
s.push(40);
if(!s.isFull())
s.push(50);
while(!s.isEmpty())
cout<<s.pop()<<endl;
return 0;
}
1、构造器(Constructor):
在类对象创建时,自动调用,完成类对象的初始化。尤其是动态堆内存的申请。
规则:
1 在对象创建时自动调用,完成初始化相关工作。
2 无返回值,与类名同,
3 可以重载,可默认参数。
4 默认无参空体,一经实现,默认不复存在。
class 类名
{
类名(形式参数)
构造体
}
class A
{
A(形参)
{}
}
比如:
Stack::Stack(int size)
{
space = new int[size];
top = 0;
}
private和public,类对象可以直接访问公有成员,但只有公有成员函数内部来访问对象的私有成员
析造器(Destructor):析构函数的作用,并不是删除对象,而在对象销毁前完成的一些清理工作。
对象销毁时期
1、栈对象离开其作用域。
2、堆对象被手动 delete.
定义:
class 类名
{
~类名()
析造体
}
class A
{
~A()
{}
}
在类对像销毁时,自动调用,完成对象的销毁。尤其是类中己申请的堆内存的释放.
规则:
1 对象销毁时,自动调用。完成销毁的善后工作。
2 无返值,与类名同,无参。不可以重载与默认参数。
3 系统提供默认空析构器,一经实现,不复存在。
Stack::~Stack()
{
delete []space;
}
this 指针
系统在创建对象时,默认生成的指向当前对象的指针。这样作的目的,就是为了带来方
便
1,避免构造器的入参与成员名相同。
2,基于 this 指针的自身引用还被广泛地应用于那些支持多重串联调用的函数中。
比如连续赋值
#include <iostream>
using namespace std;
class Stu
{
public:
Stu(string name, int age) // :name(name),age(age)
{
this->name = name;
this->age = age;
}
Stu & growUp()
{
this->age++;
return *this; // return this; ??
}
void display()
{
cout<<name<<" : "<<age<<endl;
}
private:
string name;
int age;
};
int main()
{
Stu s("wangguilin",30);
s.display();
s.growUp().growUp().growUp().growUp().growUp();
s.display();
return 0;
}
类继承
在 C++中可重用性(software reusability)是通过继承(inheritance)这一机制来实现的。如果没有掌握继承性,就没有掌握类与对象的精华
#include <iostream>
using namespace std;
class Person
{
public:
void eat(string food)
{
cout<<"i am eating "<<food<<endl;
}
};
class Student:public Person
{
public:
void study(string course)
{
cout<<"i am a student i study "<<course<<endl;
}
};
class Teacher:public Person
{
public:
void teach(string course)
{
cout<<"i am a teacher i teach "<<course<<endl;
}
};
int main()
{
Student s;
s.study("C++");
s.eat("黄焖鸡");
Teacher t;
t.teach("Java");
t.eat("驴肉火烧");
return 0;
}
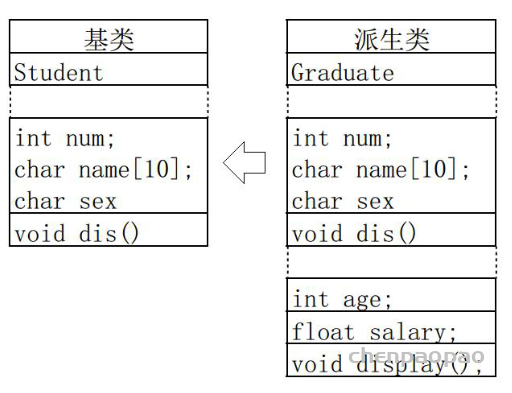
类的继承,是新的类从已有类那里得到已有的特性。或从已有类产生新类的过程就是类的派生。原有的类称为基类或父类,产生的新类称为派生类或子类。派生与继承,是同一种意义两种称谓。
派生类的声明:
class 派生类名:[继承方式] 基类名
{
派生类成员声明;
};
一个派生类可以同时有多个基类,这种情况称为多重继承,派生类只有一个基类,称为单继承。下面从单继承讲起
继承方式规定了如何访问基类继承的成员。继承方式有 public, private, protected。继承方式不影响派生类的访问权限,影响了从基类继承来的成员的访问权限,包括派生类内的访问权限和派生类对象。
简单讲:
公有继承:基类的公有成员和保护成员在派生类中保持原有访问属性,其私有成员仍为基类的私有成员。
私有继承:基类的公有成员和保护成员在派生类中成了私有成员,其私有成员仍为基类的私有成员。
保护继承:基类的公有成员和保护成员在派生类中成了保护成员,其私有成员仍为基类的私有成员
pretected 对于外界访问属性来说,等同于私有,但可以派生类中可见。
#include <iostream>
using namespace std;
class Base
{
public:
int pub;
protected:
int pro;
private:
int pri;
};
class Drive:public Base
{
public:
void func()
{
pub = 10;
pro = 100;
// pri = 1000;
public;
int a;
protected:
int b;
private:
int c
};
//
int main()
{
Base b;
b.pub = 10;
// b.pro = 100;
// b.pri = 1000;
return 0;
}
派生类中的成员,包含两大部分,一类是从基类继承过来的,一类是自己增加的成员。从基类继承过过来的表现其共性,而新增的成员体现了其个性。
几点说明:
1,全盘接收,除了构造器与析构器。基类有可能会造成派生类的成员冗余,所以说基
类是需设计的。
2,派生类有了自己的个性,使派生类有了意义
派生类中由基类继承而来的成员的初始化工作还是由基类的构造函数完成,然后派生类
中新增的成员在派生类的构造函数中初始化。
派生类构造函数的语法:
派生类名::派生类名(参数总表):基类名(参数表),内嵌子对象(参数表)
{
派生类新增成员的初始化语句; //也可出现地参数列表中
}
构造函数的初始化顺序并不以上面的顺序进行,而是根据声明的顺序初始化。
如果基类中没有默认构造函数(无参),那么在派生类的构造函数中必须显示调用基类构
造函数,以初始化基类成员。
代码实现
祖父类
student.h
class Student
{
public:
Student(string sn,int n,char s);
~Student();
void dis();
private:
string name;
int num;
char sex;
};
student.cpp
Student::Student(string sn, int n, char s)
:name(sn),num(n),sex(s)
{
}
Student::~Student()
{
}
void Student:: dis()
{
cout<<name<<endl;
cout<<num<<endl;
cout<<sex<<endl;
}
父类
graduate.h
class Graduate:public Student
{
public:
Graduate(string sn,int in,char cs,float fs);
~Graduate();
void dump()
{
dis();
cout<<salary<<endl;
}
private:
float salary;
};
graduate.cpp
Graduate::Graduate(string sn, int in, char cs, float fs)
:Student(sn,in,cs),salary(fs)
{
}
Graduate::~Graduate()
{
}
类成员
birthday.h
class Birthday
{
public:
Birthday(int y,int m,int d);
~Birthday();
void print();
private:
int year;
int month;
int day;
};
birthday.cpp
Birthday::Birthday(int y, int m, int d)
:year(y),month(m),day(d)
{
}
Birthday::~Birthday()
{
}
void Birthday::print()
{
cout<<year<<month<<day<<endl;
}
子类
doctor.h
class Doctor:public Graduate
{
public:
Doctor(string sn,int in,char cs,float fs,string st,int iy,int im,in
t id);
~Doctor();
void disdump();
private:
string title; //调用的默认构造器,初始化为””
Birthday birth; //类中声明的类对象
};
doctor.cpp
Doctor::Doctor(string sn, int in, char cs, float fs, string st, int iy,
int im, int id)
:Graduate(sn,in,cs,fs),birth(iy,im,id),title(st)
{
}
Doctor::~Doctor()
{
}
void Doctor::disdump()
{
dump();
cout<<title<<endl;
birth.print();
}
测试代码
int main()
{
Student s("zhaosi",2001,'m');
s.dis();
cout<<"----------------"<<endl;
Graduate g("liuneng",2001,'x',2000);
g.dump();
cout<<"----------------"<<endl;
Doctor d("qiuxiang",2001,'y',3000,"doctor",2001,8,16);
d.disdump();
return 0;