MiDaS v3.1:https://github.com/isl-org/MiDaS(最近也在更新)

这篇文章提出了一种监督的深度估计方法,其中使用一些很有价值的策略使得最后深度估计的结果具有较大提升。具体来讲文章的策略可以归纳为:
1)数据集 : 现有的深度数据集的场景不够丰富, 不能训练出一个在任意场景下都健壮的模型. 因此作者选择结合这些数据集。使用多个深度数据集(各自拥有不同的scale和shift属性)加入进行训练,增大数据量与实现场景的互补
但是组合这些数据集有三个挑战:
- 深度表达不同, 有的是0表示最近, 有的是0表示最远
- 部分数据集没有提供缩放信息
- 部分数据集提供了单张图像的相对深度(disparity), 但是跨数据集的相对深度无法直接转换
2)提出了一种scale-shift invariable的loss(具有深度和偏移不变性的损失函数)用于去监督深度的回归过程,从而使得可以更加有效使用现有数据;
3)采用从3D电影中进行采样的方式扩充数据集,从而进一步增加数据量;
4)使用带有原则属性的多目标训练方法,从而得到一种更加行之有效的优化方法;
结合上述的优化策略与方法,文章的最后得到的模型具有较强的泛化能力,从而摆脱了之前一些公开数据集场景依赖严重的问题。
优势:
- 问题的转化
为了解决数据本身存在深度不一致的问题, 转化成设计一个对深度不敏感的loss - 预训练模型
可以直接得到任意单张图像的深度信息, 用于下游任务的训练,
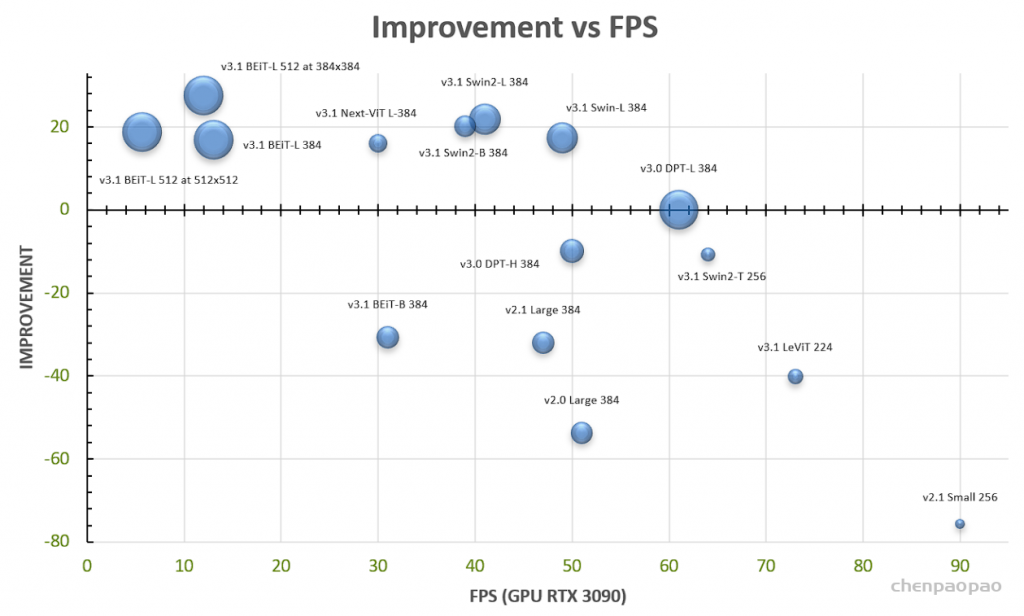
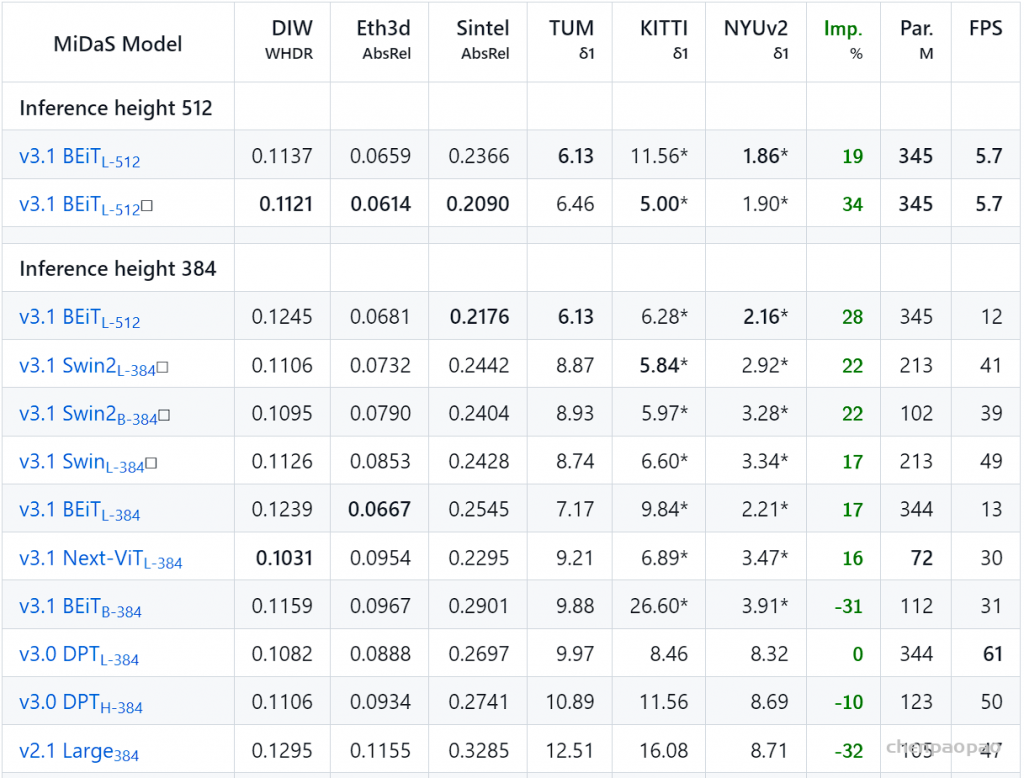
效果: