
Monocular Depth Estimation is the task of estimating the depth value (distance relative to the camera) of each pixel given a single (monocular) RGB image. This challenging task is a key prerequisite for determining scene understanding for applications such as 3D scene reconstruction, autonomous driving, and AR. State-of-the-art methods usually fall into one of two categories: designing a complex network that is powerful enough to directly regress the depth map, or splitting the input into bins or windows to reduce computational complexity. The most popular benchmarks are the KITTI and NYUv2 datasets. Models are typically evaluated using RMSE or absolute relative error. 这项具有挑战性的任务是确定 3D 场景重建、自动驾驶和 AR 等应用场景理解的关键先决条件。
任务介绍
深度估计是计算机视觉领域的一个基础性问题,其可以应用在机器人导航、增强现实、三维重建、自动驾驶等领域。而目前大部分深度估计都是基于二维RGB图像到RBG-D图像的转化估计,主要包括从图像明暗、不同视角、光度、纹理信息等获取场景深度形状的Shape from X方法,还有结合SFM(Structure from motion)和SLAM(Simultaneous Localization And Mapping)等方式预测相机位姿的算法。其中虽然有很多设备可以直接获取深度,但是设备造价昂贵。也可以利用双目进行深度估计,但是由于双目图像需要利用立体匹配进行像素点对应和视差计算,所以计算复杂度也较高,尤其是对于低纹理场景的匹配效果不好。而单目深度估计则相对成本更低,更容易普及。
那么对于单目深度估计,顾名思义,就是利用一张或者唯一视角下的RGB图像,估计图像中每个像素相对拍摄源的距离。对于人眼来说,由于存在大量的先验知识,所以可以从一只眼睛所获取的图像信息中提取出大量深度信息。那么单目深度估计不仅需要从二维图像中学会客观的深度信息,而且需要提取一些经验信息,后者则对于数据集中相机和场景会比较敏感。
通过阅读文献,可以将基于深度学习的单目深度估计算法大致分为以下几类:
- 监督算法
顾名思义,直接以2维图像作为输入,以深度图为输出进行训练::监督方法的监督信号基于深度图的地面真值,因此单目深度估计可以看作是一个回归问题。从单个深度图像设计神经网络来预测深度。利用预测深度图和实际深度图之间的差异来监督网络的训练 L2损失


上面给的例子是KITTI数据集中的一组例子,不过深度图可能看的不是很明显,我重新将深度图涂色之后:
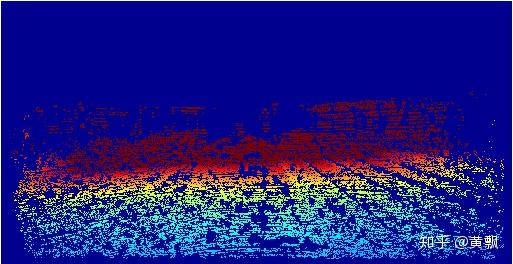
深度网络通过近似真值的方法来学习场景的深度。基于不同结构和损失函数的方法:据我们所知,Eigen等人首先用CNNs解决单目深度估计问题。该体系结构由两个组成部分组成(全局粗尺度网络和局部精细尺度网络),在文献中用于从单个图像进行端到端的深度图预测。
基于条件随机场的方法:Li等人提出了一种基于多层的条件随机场(CRFs)的细化方法,该方法也被广泛应用于语义分割。在深度的估计中,考虑到深度的连续特征,可以广泛地使用CRF的深度信息,因此可以广泛地应用于深度的估计中。
基于对抗性学习的方法:由于提出的对抗性学习在数据生成方面的突出表现,近年来成为一个研究热点。各种算法、理论和应用已得到广泛发展。对抗式学习深度估计的框架如图所示。
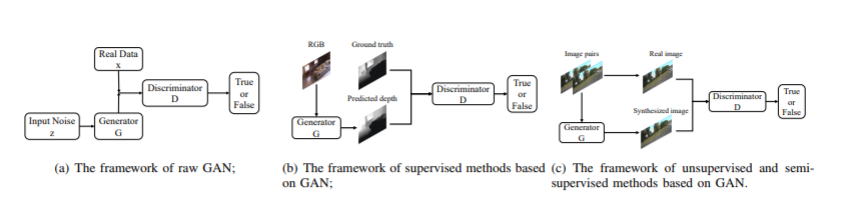
- 无监督算法
首先,所谓的“无监督”虽然不需要输入真实深度信息,但需要输入双目摄像头获取到的同一时刻不同角度的图像或者前后帧图像,只是这样就叫做无监督在我看来略显牵强。
有监督学习方法要求每幅RGB图像都有其对应的深度标签,而深度标签采集通常需要深度相机或激光雷达,前者范围受限后者成本昂贵。再者,采集的原始深度标签通常是一些稀疏的点,不能与原图很好的匹配。因此不用深度标签的无监督估计方法是近年的研究趋势,其基本思路是利用左右视图,结合对极几何与自动编码机的思想求解深度。
由于深度数据的获取难度较高,所以目前有大量算法都是基于无监督模型的。即仅仅使用两个摄像机采集的双目图像数据进行联合训练。其中双目数据可彼此预测对方,从而获得相应的视差数据,再根据视差与深度的关系进行演化。亦或是将双目图像中各个像素点的对应问题看作是立体匹配问题进行训练。左视图-右视图示例:


视差,以我们人眼为例,两只眼睛看到的图像分别位于不同的坐标系。将手指从较远地方慢慢移动到眼前,会发现,手指在左眼的坐标系中越来越靠右,而在右眼坐标系中越来越靠左,这种差异性就是视差。与此同时,可以说明,视差与深度成反比。除此之外,由于摄像机参数也比较容易获取,所以也可以以相机位姿作为标签进行训练。

同时同一水平线上的两个照相机拍摄到的照片是服从以下物理规律的:
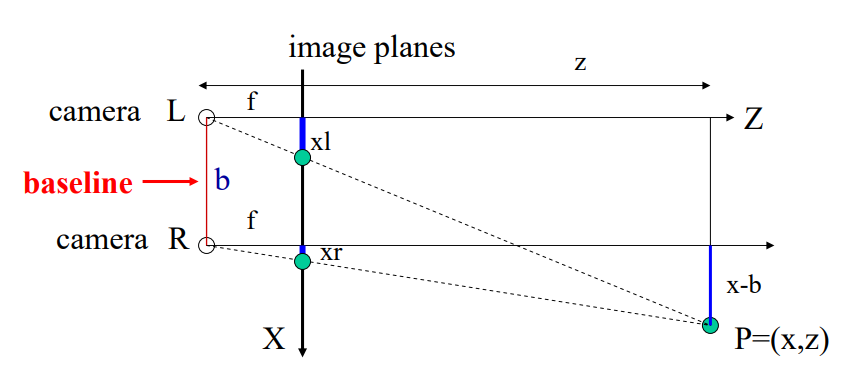
在图中, Z 为场景所距离我们的深度, X为三维场景映射到的二维图像平面,也就是最终我们得到的二维图像所在的平面。 f为相机的焦距。 b为两个相机之间的距离,Xl和 Xr 分别为相同物体在左右两个不同相机中成像的坐标。根据以上信息,和简单的三角形相似规律我们可以得到:


这种思路最先应用于使用单张图片生成新视角问题:DeepStereo 和 Deep3d之中, 在传统的视角生成问题之中,首先会利用两张图(或多张)求取图片之间的视差d,其次通过得到的视差(相当于三维场景)来生成新视角。
基于可解释性掩模的方法:基于投影函数的视图重建算法依赖于静态场景假设,即动态目标在相邻帧上的位置不满足投影函数,从而影响测光度误差和训练过程。
基于传统视觉里程计的方法:用传统的直接视觉里程计回归的位姿来辅助深度估计,而不是使用位姿网络估计的位姿。直接视觉里程计利用深度网络生成的深度图和一个三帧图像,通过最小化光度误差来估计帧间的姿态,然后将计算出的姿态发送回训练框架。因此,由于深度网络由更精确的姿态来监督,因此深度估计的精度显着提高。
基于多任务框架的方法:最近的方法在基本框架中引入了额外的多任务网络,如光流、物体运动和相机内参矩阵,作为一个附加的训练框架,加强了整个训练任务之间的关系
基于对抗学习的方法:将对抗学习框架引入到无监督的单目深度估计中。由于在无监督训练中没有真正的深度图。因此,将视图重建算法合成的图像和真实图像作为鉴别器的输入,而不是使用鉴别器来区分真实深度图和预测深度图。
- Structure from motion/基于视频的深度估计(无监督学习)
这一部分中既包含了单帧视频的单目深度估计,也包含了多帧间视频帧的像素的立体匹配,从而近似获取多视角图像,对相机位姿进行估计。
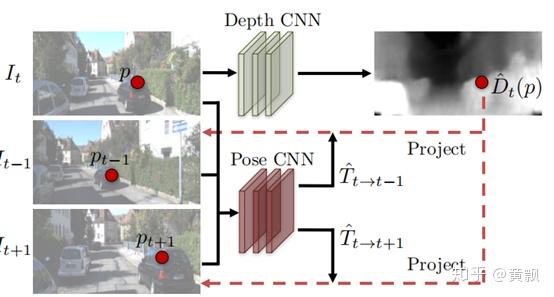
评估指标:
在单目深度估计问题中,常用的精度评估指标有相对误差(REL)、均方根误差(RMS)、对数误差(LG)及阈值误差(% correct)


深度估计相关数据集
在深度估计的研究中,由于室内外场景类型与深度范围具有较大的差异,对应不同的场景分别会构造不同的数据集。
- 真实场景数据集
- NYU depth v2(来自纽约大学)是常用的室内数据集之一,
- 选取了464个不同的场景,
- 利用RGB相机和微软的Kinect深度相机同时采集室内场景的RGB信息和深度信息,收集了407 024帧RGBD图像对构建数据集。
- 由于红外相机和摄像机之间的位置偏差,深度相机采集的原始深度图存在缺失部分或是噪点,
- 作者从中选取了1 449幅图像,利用着色算法对深度图进行填充得到稠密深度图,同时人工标注语义信息。
- Make3D(斯坦福大学)是常用的室外场景数据集之一,
- 使用激光扫描仪采集室外场景的深度信息,
- 选取的场景类型为白天的城市和自然风光,深度范围是5~81 m,大于该范围统一映射为81 m。
- 数据集共包含534幅RGBD图像对,其中400幅用于训练,134幅用于测试。
- KITTI(德国卡尔斯鲁厄理工学院和美国丰田技术研究院)自动驾驶领域常用的数据集之一,链接:http://www.cvlibs.net/datasets/kit
- 包含深度数据标签
- 通过一辆装配有2台高分辨率彩色摄像机、2台灰度摄像机、激光扫描仪和GPS定位系统的汽车采集数据,其中激光扫描仪的最大测量距离为120 m。
- 图像场景包括卡尔斯鲁厄市、野外地区以及高速公路。
- 数据集共包含93 000个RGBD训练样本。
- Depth in the Wild(DIW)(密歇根大学)以相对深度作为标签的数据集
- 从词典中随机选取单词作为搜索关键字,然后从互联网中收集得到原始的RGB图像。
- 标注工作外包给专门的工作人员,为了更加高效,每一幅图像选取了两个高亮的点,工作人员只需判定两个点的远近关系即可。
- 对于采样点对之间的位置关系,采用50%随机采样,另外50%对称采样的方法以使构建的数据集尽可能平衡。最终获得的有效标注图像约5×E11张。
- Cityscapes. Cityscapes的数据取自德国的50多个城市的户外场景,其中数据包含有左右视角图像、视差深度图、相机校准、车辆测距、行人标定、目标分割等,同时也包含有类似于vKITTI的虚拟渲染场景图像。其中简单的左视角图像、相机标定、目标分割等数据需要利用学生账号注册获取,其他数据需要联系管理员获取。链接:https://www.cityscapes-dataset.com/
- NYU depth v2(来自纽约大学)是常用的室内数据集之一,
- 虚拟场景数据集
- SceneNet RGB-D数据集
- SYNTHIA数据集
- 由于是通过虚拟场景生成,数据集中包括更多天气、环境及光照,场景类型多样。各数据集有各自的优缺点,在实际研究中,应根据具体研究问题来选择合适的数据集。
综上,可以看到基于深度学习的单目深度估计是本领域的发展方向。目前,该领域的发展主要集中在数据集和深度学习模型两方面。首先,数据集的质量在很大程度上决定了模型的鲁棒性与泛化能力,深度学习要求训练数据必须有更多的数量、更多的场景类型,如何构建满足深度学习的数据集成为一个重要的研究方向。目前,基于虚拟场景生成深度数据具有不需要昂贵的深度采集设备、场景类型多样、节省人力成本等优势,结合真实场景和虚拟场景的数据共同训练也是未来深度学习方法的趋势。其次,为了提高深度学习估计单幅图像深度的精度,要求更新的更复杂的深度框架。除了神经网络模型本身结构的优化,更新颖的算法设计也能有效地提升预测精度。研究工作大多采用有监督回归模型对连续的绝对深度值进行回归拟合。考虑到场景由远及近的特性,也有用分类模型进行绝对深度估计的方法。由深度信息和其他信息之间的互补性,部分工作结合表面法线等信息提升深度预测的精度。深度学习发展迅速,新的模型层出不穷,如何将这些模型应用于单幅图像深度估计问题中需要更加深入地研究。另外,探索神经网络在单目深度估计问题中学到的是何种特征也是一个重要的研究方向。
对于单目深度估计模型,目前主要分为基于回归/分类的监督模型,基于双目训练/视频序列的无监督模型,以及基于生成学习的图像风格迁移模型。大概从2017年起,即CVPR2018开始,单目深度估计的效果就已经达到了双目深度估计的效果,主要是监督模型。但是由于现有的数据集主要为KITTI、Cityscapes、NYU DepthV2等,其场景和相机都是固定的,从而导致监督学习下的模型无法适用于其他场景,尤其是多目标跟踪这类细节丰富的场景,可以从论文中看到,基本上每个数据集都会有一个单独的预训练模型。
对于GAN,其对于图像风格的迁移本身是一个很好的泛化点,既可以用于将场景变为晴天、雾天等情况,也可以用于图像分割场景。但是深度估计问题中,像素点存在相对大小,因此必定涉及到回归,因此其必定是监督学习模型,所以泛化性能也不好。对于无监督的算法,可能场景适应性会更好,但依旧不适用于对行人深度的估计。
参考文献
[1] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 3431-3440.
[2] Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation[C]//International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015: 234-241.
[3] Laina I, Rupprecht C, Belagiannis V, et al. Deeper depth prediction with fully convolutional residual networks[C]//2016 Fourth international conference on 3D vision (3DV). IEEE, 2016: 239-248.
[4] Fu H, Gong M, Wang C, et al. Deep ordinal regression network for monocular depth estimation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 2002-2011.
[5] Godard C, Mac Aodha O, Brostow G J. Unsupervised monocular depth estimation with left-right consistency[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 270-279.
[6] Dosovitskiy A, Fischer P, Ilg E, et al. Flownet: Learning optical flow with convolutional networks[C]//Proceedings of the IEEE international conference on computer vision. 2015: 2758-2766.
[7] Ilg E, Mayer N, Saikia T, et al. Flownet 2.0: Evolution of optical flow estimation with deep networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 2462-2470.
[8] Mayer N, Ilg E, Hausser P, et al. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 4040-4048.
[9] Xie J, Girshick R, Farhadi A. Deep3d: Fully automatic 2d-to-3d video conversion with deep convolutional neural networks[C]//European Conference on Computer Vision. Springer, Cham, 2016: 842-857.
[10] Luo Y, Ren J, Lin M, et al. Single View Stereo Matching[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
[11] Zhou T, Brown M, Snavely N, et al. Unsupervised learning of depth and ego-motion from video[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 1851-1858.
[12] Yin Z, Shi J. Geonet: Unsupervised learning of dense depth, optical flow and camera pose[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 1983-1992.
[13] Zhan H, Garg R, Saroj Weerasekera C, et al. Unsupervised learning of monocular depth estimation and visual odometry with deep feature reconstruction[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 340-349.
[14] Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[C]//Advances in neural information processing systems. 2014: 2672-2680.
[15] Radford A , Metz L , Chintala S . Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks[J]. Computer Science, 2015.
[16] Arjovsky M, Chintala S, Bottou L. Wasserstein gan[J]. arXiv preprint arXiv:1701.07875, 2017.
[17] Gulrajani I, Ahmed F, Arjovsky M, et al. Improved training of wasserstein gans[C]//Advances in Neural Information Processing Systems. 2017: 5767-5777.
[18] Mao X, Li Q, Xie H, et al. Least squares generative adversarial networks[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 2794-2802.
[19] Mirza M, Osindero S. Conditional generative adversarial nets[J]. arXiv preprint arXiv:1411.1784, 2014.
[20] Isola P, Zhu J Y, Zhou T, et al. Image-to-image translation with conditional adversarial networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1125-1134.
[21] Wang T C, Liu M Y, Zhu J Y, et al. High-resolution image synthesis and semantic manipulation with conditional gans[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 8798-8807.
[22] Zhu J Y, Park T, Isola P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2223-2232.
[23] Wang T C , Liu M Y , Zhu J Y , et al. Video-to-Video Synthesis[J]. arXiv preprint arXiv:1808.06601,2018.
[24] Zheng C, Cham T J, Cai J. T2net: Synthetic-to-realistic translation for solving single-image depth estimation tasks[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 767-783.
[25] Atapour-Abarghouei A, Breckon T P. Real-time monocular depth estimation using synthetic data with domain adaptation via image style transfer[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 2800-2810.
[26] Nekrasov V , Dharmasiri T , Spek A , et al. Real-Time Joint Semantic Segmentation and Depth Estimation Using Asymmetric Annotations[J]. arXiv preprint arXiv:1809.04766,2018.
[27] Nekrasov V , Shen C , Reid I . Light-Weight RefineNet for Real-Time Semantic Segmentation[J]. arXiv preprint arXiv:1810.03272, 2018.
[28] Lin G , Milan A , Shen C , et al. RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.,2017:1925-1934
[29] Zou Y , Luo Z , Huang J B . DF-Net: Unsupervised Joint Learning of Depth and Flow using Cross-Task Consistency[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018:36-53.
[30] Ranjan A, Jampani V, Balles L, et al. Competitive collaboration: Joint unsupervised learning of depth, camera motion, optical flow and motion segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 12240-12249.