https://github.com/QwenLM/Qwen-Audio
Qwen-Audio:通过统一的大规模音频语言模型推进通用音频理解
Qwen-Audio 🤖 | 🤗 | Qwen-Audio-Chat 🤖 | 🤗 | Demo 🤖 | 🤗
Homepage | Paper | WeChat | Discord
{kind=link}
本文提出了Qwen-Audio模型,旨在通过扩大音频语言预训练的范围,覆盖超过30个任务和多种音频类型,如人声、自然声音、音乐和歌曲,从而促进通用音频理解能力的提升。然而,直接联合训练所有任务和数据集可能导致干扰问题,因为不同数据集相关的文本标签由于任务焦点、语言、标注的细粒度和文本结构的差异而存在显著变化。为了解决一对多的干扰问题,我们精心设计了一个多任务训练框架,通过对解码器的分层标签序列进行条件化,促进知识共享并通过共享和特定标签分别避免干扰。值得注意的是,Qwen-Audio在多种基准任务中实现了卓越的性能,而无需任何任务特定的微调,超越了同类模型。在Qwen-Audio的基础上,我们进一步开发了Qwen-Audio-Chat,允许多种音频和文本输入,实现多轮对话并支持多种以音频为中心的场景。
Qwen-Audio 可以以多种音频 (包括说话人语音、自然音、音乐、歌声)和文本作为输入,并以文本作为输出。Qwen-Audio 系列模型的特点包括:
- 音频基石模型:Qwen-Audio是一个性能卓越的通用的音频理解模型,支持各种任务、语言和音频类型。在Qwen-Audio的基础上,我们通过指令微调开发了Qwen-Audio-Chat,支持多轮、多语言对话。Qwen-Audio和Qwen-Audio-Chat模型均已开源。
- 兼容多种复杂音频的多任务学习框架:为了避免由于数据收集来源不同以及任务类型不同,带来的音频到文本的一对多的干扰问题,我们提出了一种多任务训练框架,实现相似任务的知识共享,并尽可能减少不同任务之间的干扰。通过提出的框架,Qwen-Audio可以容纳训练超过30多种不同的音频任务;
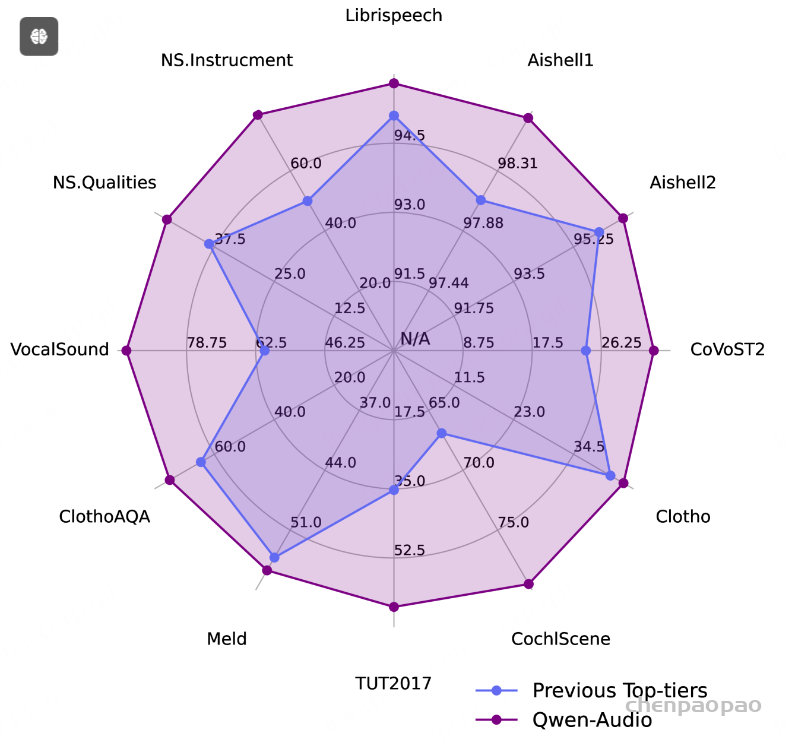
- 出色的性能:Qwen-Audio在不需要任何任务特定的微调的情况下,在各种基准任务上取得了领先的结果。具体得,Qwen-Audio在Aishell1、cochlscene、ClothoAQA和VocalSound的测试集上都达到了SOTA;
- 支持多轮音频和文本对话,支持各种语音场景:Qwen-Audio-Chat支持声音理解和推理、音乐欣赏、多音频分析、多轮音频-文本交错对话以及外部语音工具的使用。
Methodology
本节提供了Qwen-Audio和Qwen-Audio-Chat的详细信息,这些模型旨在实现通用音频理解和基于人类指令的灵活互动。首先,在第1节中介绍了Qwen-Audio和Qwen-Audio-Chat的模型结构。我们的模型训练过程分为两个阶段:多任务预训练和监督微调。我们在第2节中描述了通过多任务学习进行的Qwen-Audio训练。随后,在第3节中描述了Qwen-Audio-Chat的监督微调过程,使其能够实现灵活的人机互动。
模型架构
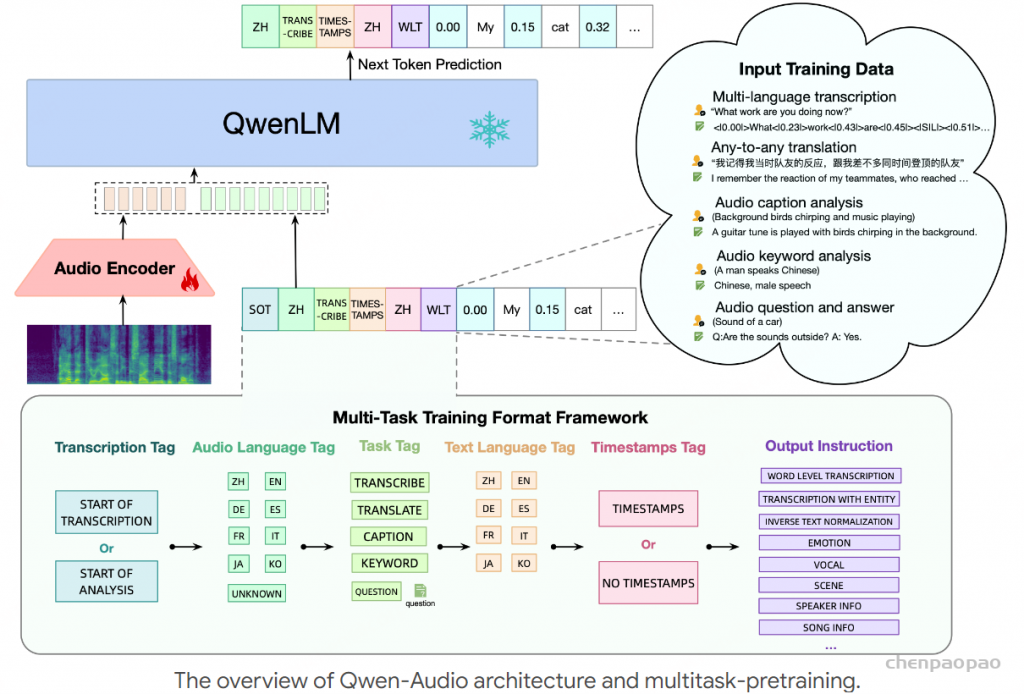
Qwen-Audio 模型的架构如图 3 所示。Qwen-Audio 包含一个音频编码器和一个大型语言模型。给定配对数据 (𝒂,𝒙) ,其中 𝒂 和 𝒙 表示音频序列和文本序列,训练目标是将下一个文本标记概率最大化为:

Audio Encoder 音频编码器
音频编码器Qwen-Audio采用单一音频编码器处理多种类型的音频。该音频编码器基于Whisper-large-v2模型初始化,该模型为32层Transformer结构,包含两个卷积下采样层作为前端。音频编码器由640M参数构成。尽管Whisper是针对语音识别和翻译进行监督训练的,其编码表示仍然包含丰富的信息,如背景噪声,甚至可以用于恢复原始语音。在音频数据预处理过程中,Whisper将其重采样至16kHz,并使用25ms的窗口大小和10ms的步长将原始波形转换为80通道梅尔谱图。此外,模型还包含一个步幅为2的池化层,以减少音频表示的长度。因此,编码器输出的每一帧大约对应于原始音频信号的40ms片段。在训练时,采用SpecAugment作为数据增强技术。
大型语言模型Qwen-Audio将大型语言模型作为其基础组件。该模型使用从Qwen-7B中获得的预训练权重进行初始化。Qwen-7B是一个32层的Transformer解码器模型,隐藏层大小为4096,总参数量为7.7B。
多任务预训练
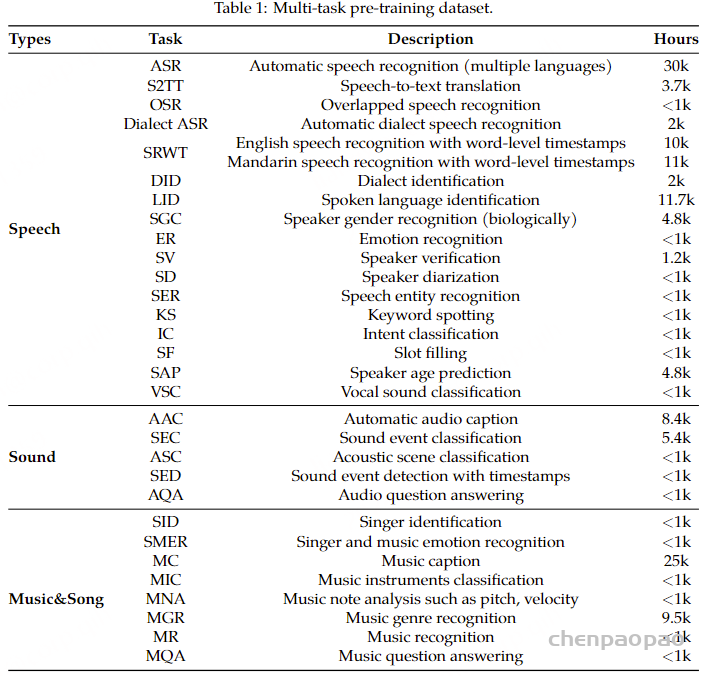
在音频处理领域,已开发出多样化的音频数据集以应对特定任务,如表1所示。Qwen-Audio旨在利用广泛的音频数据集进行联合训练,目标是训练一个统一的模型,能够支持所有音频任务,从而消除在处理不同任务时繁琐的模型切换需求。更重要的是,在联合训练过程中,各任务可以相互受益,原因在于:1)相似任务能够通过知识共享和协同学习而获益,因为它们关注音频信号中嵌入的基本信息;2)依赖于低层次感知能力的任务可以帮助需要高层次理解或推理能力的任务。
然而,由于任务聚焦、语言、标注的细粒度和文本结构等方面的差异,不同数据集在文本标签上存在显著变化(例如,有些数据是结构化的,而其他数据则是非结构化的)。为了训练适用于不同任务的网络,仅仅混合这些多样化的数据集无法实现相互增强;相反,它会引入干扰。目前大多数现有的多任务训练方法要么将相似任务分组(例如,音频描述、转录),要么为每个数据集分配一个数据集ID,以避免干扰。尽管这些方法取得了一定效果,但仍有很大的改进空间。Whisper提出了一种多任务训练格式,通过将任务和条件信息作为输入特定令牌的序列传递给语言解码器,如语音活动检测、语言识别和句子级时间戳标签。然而,Whisper主要集中于语音翻译和识别任务。
多任务训练格式框架
受到Whisper的启发,为了融合不同类型的音频,我们提出了一种多任务训练格式框架,具体如下:
- 转录标签:预测的启动由转录标签表示。使用<|startoftranscripts|>来指示涉及准确转录口语和捕捉语音录音语言内容的任务,如语音识别和语音翻译任务。对于其他任务,则使用<|startofanalysis|>标签。
- 音频语言标签:然后,我们引入一个语言标签,指示音频中所说的语言。该标签使用分配给训练集中每种语言的唯一令牌,共计八种语言。当音频片段不包含任何语音(例如自然声音和音乐)时,模型训练预测<|unknown|>令牌。
- 任务标签:后续令牌指定任务。我们将收集的音频任务分为五类:<|transcribe|>、<|translate|>、<|caption|>、<|analysis|>和<|question-answer|>任务。对于问答(QA)任务,我们在标签后附加相应的问题。
- 文本语言标签:标签令牌指定输出文本序列的语言。
- 时间戳标签:<|timestamps|>或<|notimestamps|>令牌的存在决定模型是否需要预测时间戳。与Whisper使用的句子级时间戳不同,包含<|timestamps|>标签要求模型进行细粒度的单词级时间戳预测,简称为SRWT(具有单词级时间戳的语音识别)。这些时间戳的预测与转录单词交错进行:开始时间令牌在每个转录令牌之前预测,而结束时间令牌在之后预测。根据我们的实验,SRWT提高了模型将音频信号与时间戳对齐的能力。这种改进的对齐有助于模型对语音信号的全面理解,从而在语音识别和音频问答任务等多个任务中取得显著进展。
- 输出指令:最后,我们提供输出指令,以进一步指定任务和不同子任务所需的格式,然后开始文本输出。
我们框架的指导原则是通过共享标签最大限度地提高相似任务之间的知识共享,从而提升它们的性能。同时,我们确保不同任务和输出格式可以区分,以避免模型的一对多映射问题。有关Qwen-Audio多任务格式的概述,请参见图3。
监督微调
多任务模型的广泛预训练赋予了它们对音频的广泛理解。在此基础上,我们采用基于指令的微调技术,以提高模型与人类意图的对齐能力,从而形成一个交互式聊天模型,称为Qwen-Audio-Chat。为实现这一目标,我们手动创建每个任务的示例。这些示例包括原始文本标签、问题和答案。随后,我们利用GPT-3.5基于提供的原始文本标签生成更多的问题和答案。此外,我们还通过手动标注、模型生成和策略串联创建了一套音频对话数据集。该数据集帮助我们将推理、故事生成和多图像理解能力融入模型中。
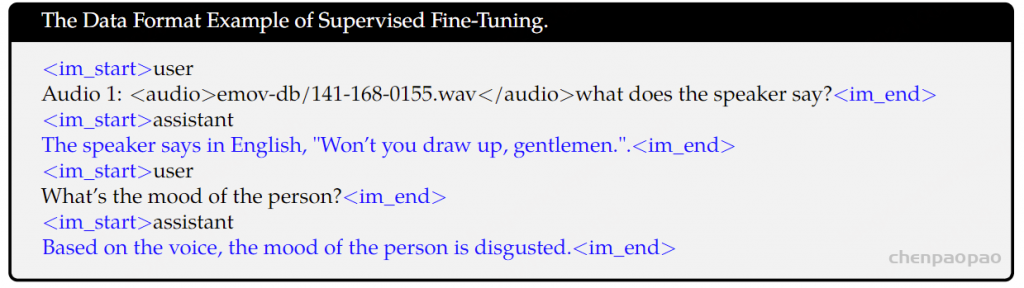
为了有效处理多音频对话和多个音频输入,我们引入了用“Audio id:”标记不同音频的约定,其中id对应于音频输入对话的顺序。在对话格式方面,我们使用ChatML(OpenAI)格式构建指令调优数据集。在这种格式中,每个交互的声明用两个特殊令牌(<im_start>和<im_end>)进行标记,以便于对话结束。
为了促进在多轮对话中来自音频和纯文本模态的多样化输入,我们在此训练过程中结合使用上述以音频为中心的指令数据和纯文本指令数据。这种方法使模型能够无缝处理多种输入形式。指令调优数据的总量为20k。
Experiments
设置
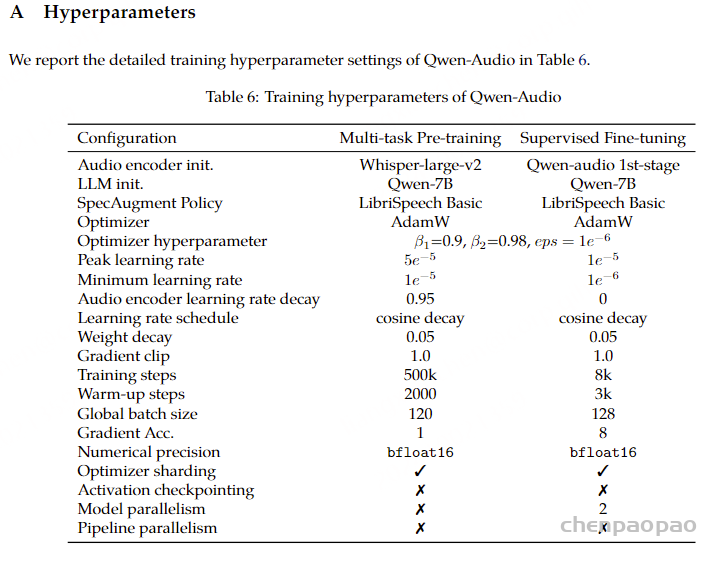
在多任务预训练阶段,我们冻结大型语言模型(LLM)的权重,仅优化音频编码器。该训练模型被称为Qwen-Audio。在随后的监督微调阶段,我们固定音频编码器的权重,仅优化LLM。最终模型被标记为Qwen-Audio-Chat。两个阶段的详细训练配置列在表6中。
评估
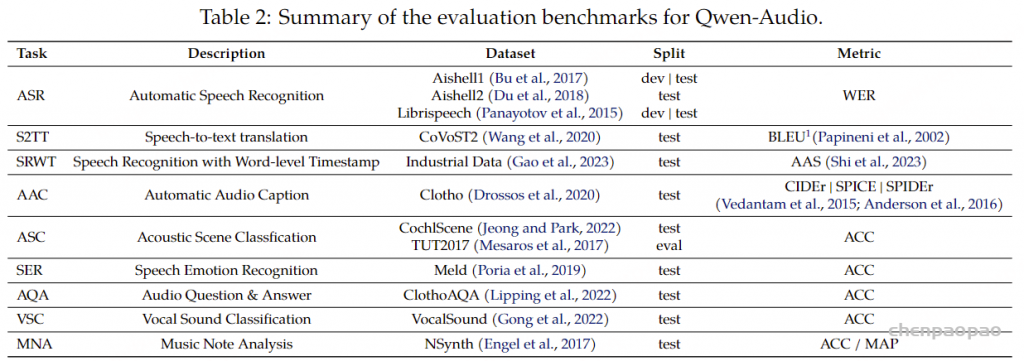
为了评估Qwen-Audio的通用理解能力,如表2所示,我们进行了全面的评估,涵盖多种任务,包括自动语音识别(ASR)、语音转文本翻译(S2TT)、自动音频描述(AAC)、声学场景分类(ASC)、语音情感识别(SER)、音频问答(AQA)、声乐声音分类(VSC)和音乐音符分析(MNA)。此次评估涉及12个数据集。评估数据集严格排除在训练数据之外,以避免数据泄露。两个阶段的详细训练配置列在表6中。
主要结果
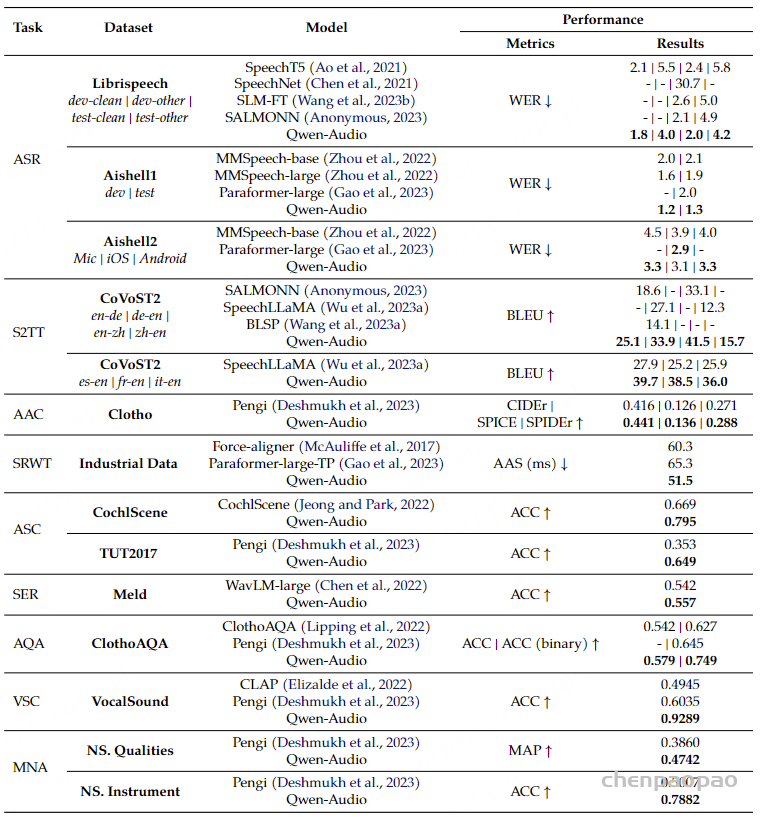
在本节中,我们对Qwen-Audio模型进行了全面评估,评估其在各种任务上的表现,而无需任何任务特定的微调。首先,我们检查其在英语自动语音识别(ASR)方面的结果,如表3所示,Qwen-Audio的表现优于以往的多任务学习模型。具体而言,它在librispeech的test-clean和test-other数据集上分别取得了2.0%和4.2%的词错误率(WER)。同样,中文普通话的ASR结果显示Qwen-Audio在与之前方法的对比中表现出竞争力。根据我们所知,Qwen-Audio在Aishell1的开发集和测试集上达到了最新的研究成果。此外,我们还评估了Qwen-Audio在CoVoST2数据集上的语音翻译性能。结果显示,Qwen-Audio在所有七个翻译方向上均显著超越基线模型。
最后,我们分析了Qwen-Audio在各种音频分析任务上的表现,包括AAC、SWRT、ASC、SER、AQA、VSC和MNA,结果汇总在表3中。在这些任务中,Qwen-Audio始终显著优于基线模型。特别地,它在CochlScene、ClothoAQA和VocalSound上取得了最新的研究成果,展示了模型强大的音频理解能力。
互动聊天结果
我们通过图2中的示例案例展示了Qwen-Audio-Chat的对话能力。此外,我们计划向公众开放训练好的模型,以便进行在线聊天互动。
词级时间戳预测分析
我们通过训练Qwen-Audio提出了带有词级时间戳的语音识别任务(SRWT),旨在不仅识别语音转录,还预测每个单词的时间戳。SRWT的目的有两个:首先,改善模型将音频信号与细粒度时间戳对齐的能力;其次,支持Qwen-Audio-Chat中的语音和音频的基础对接,以及基于对接的问答任务,例如找到提到某人姓名的音频片段的开始和结束时间,或识别给定音频中是否出现某种声音。
在本节中,我们在多任务预训练中排除了SRWT任务的训练,同时保持其他任务不变。值得注意的是,去除SRWT并不影响训练的音频数据集的覆盖范围,因为SRWT任务与自动语音识别(ASR)任务共享相同的音频数据集。结果如表4和表5所示,训练中包含SRWT的模型在自动语音识别和音频问答任务中表现优越,包括自然声音问答和音乐问答。这些结果突显了将细粒度词级时间戳纳入模型以增强通用音频信号对接能力,并进而提高声音和音乐信号问答任务性能的有效性。
结论
在本文中,我们提出了Qwen-Audio系列,这是一个具备通用音频理解能力的大规模音频语言模型集合。为了融合不同类型的音频进行共同训练,我们提出了一个统一的多任务学习框架,该框架促进了相似任务之间的知识共享,并避免了由于不同文本格式引起的一对多映射问题。在没有任何任务特定微调的情况下,所得到的Qwen-Audio模型在各种基准测试中超越了以往的工作,证明了其通用音频理解能力。通过监督指令微调,Qwen-Audio-Chat展示了与人类意图对齐的强大能力,支持来自音频和文本输入的多语言和多轮对话。