
- Github :https://github.com/InternLM/InternLM-XComposer/tree/main
- paper:https://arxiv.org/abs/2412.09596
随着人工智能的发展,构建能够实时感知环境、进行复杂推理并记忆的系统,已成为研究者们追求的目标。这不仅要求 AI 系统能处理音频、视频和文本等多模态数据,还需在动态环境中模拟人类感知、推理与记忆的协同能力。然而,现有多模态大语言模型(MLLMs)在这方面仍存在诸多限制,尤其是在同时处理任务时的效率和可扩展性。
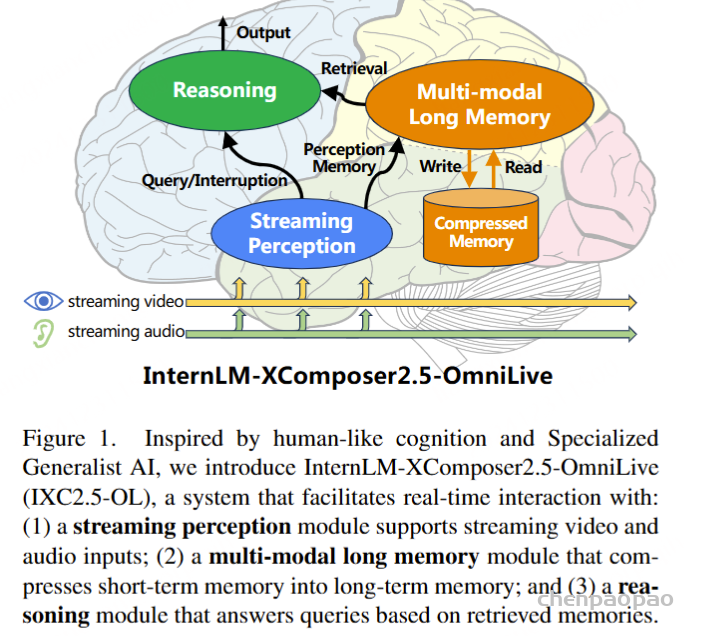
为解决这些问题,来自上海人工智能实验室、中国香港中文大学、复旦大学、中国科技大学、清华大学、北京航空航天大学和商汤集团的研究团队推出了一款创新框架——InternLM-XComposer2.5-OmniLive (IXC2.5-OL)。通过模块化设计,该系统将感知、记忆与推理功能解耦,实现了高效的实时多模态交互,为模拟人类认知提供了全新范式。
1.输入:流式的视频数据、流式的音频数据。
2.流式感知:感知模块对输入进行感知理解。
3.记忆:将感知到的数据作为记忆,写入到记忆池。
4.检索生成:从记忆池里检索到相关记忆,进行推理,得到输出。
现有系统的局限性
1) 感知与推理的割裂 大部分主流模型采用序列到序列的架构,这种设计导致系统在处理多模态数据时,需要在感知和推理间频繁切换。例如,模型在分析视频流时可能会停顿以处理文本任务,类似于“人在观察时无法思考”的状态。
2) 数据存储的低效 当前模型依赖扩展上下文窗口存储历史数据,但多模态数据(如视频流和音频流)会在短时间内生成海量信息,这种方法难以支撑长时间的数据积累。例如,一个小时的视频可能转化为数百万个标记,这对存储和检索都是巨大的挑战。
3) 模型架构的单一性 现有方法如 Mini-Omni 和 VideoLLM-Online,虽然尝试填补文本与视频理解之间的鸿沟,但因过度依赖顺序处理和有限的记忆整合能力,难以达到人类级别的认知效果。
InternLM-XComposer2.5-OmniLive 的创新设计
IXC2.5-OL 通过模块化架构模拟人脑,将感知、记忆和推理分解为三个独立但协同工作的模块:
- 流式感知模块(Streaming Perception Module)
- 多模态长时记忆模块(Multimodal Long Memory Module)
- 推理模块(Reasoning Module)
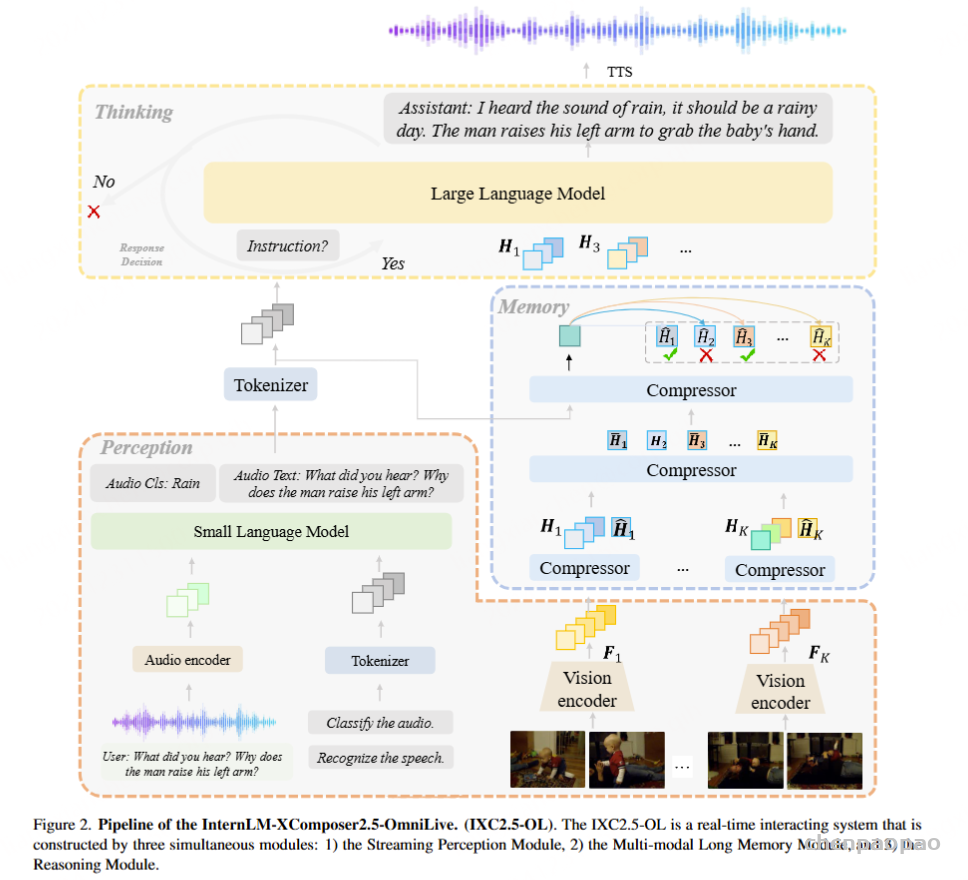
1) 流式感知模块:实时数据捕获与编码
该模块处理实时音频和视频流,使用先进模型如 Whisper(音频编码)和 OpenAI CLIP-L/14(视频感知)提取高维特征。负责处理视频和音频数据,因此包含了对应的视频感知模块和音频转换模块。
视频感知模块:使用的OpenAI的CLIP-L/14,用于将每一帧视频,也就是图片,编码为语义特征。向多模态长时记忆模块提供粗粒度的视觉信息。 它处理实时视频输入流,并将每一帧编码成语义特征。 为了提高效率,我们在实践中使用了 OpenAI CLIP-L/14
然后直接将语义特征送给记忆模块。
音频感知模块:万物都能token。类似VLM的处理,包含音频编码器(Whisper)、音频投影器、小型语言模型(Qwen2-1.8B)
语言模型的输出有两个:音频类别;音频转文本。
- 任务:捕获并编码关键信息,如语音内容、环境音等,直接存入记忆模块。
- 应用:音视频会议的实时字幕生成、智能监控中异常事件识别。
包含一个音频编码器、一个音频投影器和一个小语言模型 (SLM)。 音频编码器将输入音频样本编码成高维特征,音频投影器进一步将特征映射到 SLM 的输入空间。 SLM 输出音频的类别(例如,笑声、鼓掌声或雨声)以及音频中的自然语言(即自动语音识别结果)。 在实践中,我们使用 Whisper模型作为音频编码器,并使用 Qwen2-1.8B 作为 SLM。
2) 多模态长时记忆模块:高效存储与检索
多模态长时记忆模块是处理极长视频输入的核心设计,它帮助推理模块摆脱其上下文窗口中数百万个符元。 它与 VideoStreaming 的思想类似,即将视频片段编码成短期记忆,并将其整合到长期记忆中。 给定问题后,它会为推理模块检索最相关的视频片段。
此模块的核心功能是将短期记忆压缩为高效的长期表示。
- 方法:通过算法优化,能够将数百万帧视频浓缩成紧凑的记忆单元,有效减少存储成本并提升检索准确性。
- 优势:大幅降低计算资源的占用,为实时交互提供支持。
多模态推理所占用的token是非常多的,因为要对一张图片进行动态切分。所以必须考虑记忆的存储。依赖长上下文来存储历史信息对于长期使用而言是不切实际的。这里采用了类似Mem0的方法,压缩-检索方法。能够仅保留与查询相关的token,去掉冗余的token。
方法:将视频片段编码为短期记忆,整合为长期记忆。检索到最相关的视频片段作为上下文。
1.视频片段压缩:对视频片段做空间下采样编码为短期记忆和全局记忆。
2.记忆整合:短期记忆是视频片段的详细信息。为了得到长期记忆,对短期和全局记忆整合。
3.视频片段检索:接收到query后,将其编码到记忆的特征空间,具体编码过程是将长期记忆和query作为压缩器的输入,取最后的token的隐藏状态作为query特征。使用query特征计算与每个视频片段的全局特征的相似性,得到最相关的视频片段和记忆信息。
视频片段检索。 当用户提出问题时,多模态长期记忆模块检索与问题相关的视频片段,并将视频片段及其短期记忆提供给推理模块。 在实践中,我们首先将问题编码到记忆的特征空间。 我们将长期记忆与标记化的提问连接起来作为压缩器的输入,并将输出特征的最后一个符元视为与记忆空间对齐的问题特征。 然后,我们计算问题特征与每个视频的全局记忆之间的相似度,并为推理模块选择最相关的片段。
3) 推理模块:信息检索与复杂任务执行
推理模块通过检索记忆模块中的相关信息,快速完成复杂任务,如回答用户问题或执行指令。
- 特点:实现感知、推理与记忆的同步协作,避免传统系统中各模块割裂运行的效率低下问题。
- 应用:智能问答系统、实时决策支持。
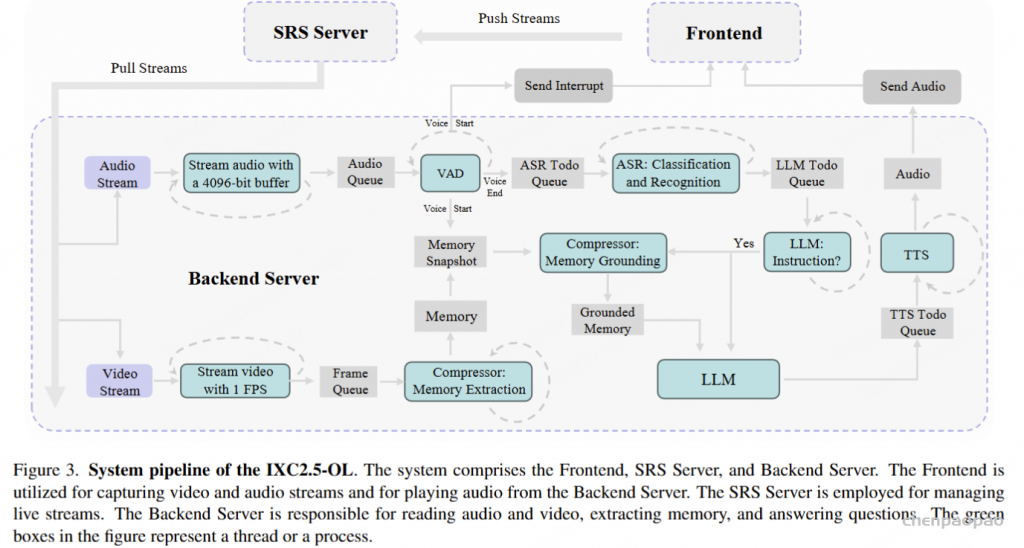
系统流程
系统包括前端、SRS服务器和后端服务器。
前端。 前端应用程序使用JavaScript开发,能够启用摄像头和麦克风来捕获视频和音频流输入,然后将其推送到SRS服务器。 同时,它与后端建立WebSocket连接,以监听音频输出和中断信号。 接收到音频数据后,前端会播放音频。 接收到中断信号后,前端会暂停音频播放并丢弃待处理的音频。
SRS 服务器。 SRS(Simple Realtime Server)是一个简单高效的实时视频服务器,能够支持多种实时流协议,例如RTMP、WebRTC、HLS、HTTP-FLV、SRT等。 它以其可靠接收和传输音频和视频流的能力而闻名。
后端服务器。 与前端建立WebSocket连接后,后端将从SRS服务器拉取流,并启动单独的线程来读取音频和视频。
音频读取线程将音频流分割成4096位的块,并将它们放入音频队列中。 语音活动检测(VAD)[40]线程持续从音频队列读取数据,并检测语音活动的开始和结束。 检测到语音活动开始时,后端会向前端发送中断信号以暂停当前正在播放的音频,同时向视频处理过程发送备份信号,指示其保存当前内存状态。 检测到语音活动结束时,整个语音片段将被放入ASR待处理队列中。 自动语音识别 (ASR) 线程持续从ASR 任务队列读取音频片段,对其进行背景噪声分类和语音识别,然后将结果入队到大语言模型 (LLM) 任务队列供 LLM 使用。
视频读取线程以每秒 1 帧的速度读取视频帧,并将它们入队到帧队列。 压缩器进程从队列中读取视频帧,识别它们,提取相关内存并存储。 接收到来自语音活动检测 (VAD) 线程的备份信号后,压缩器进程将保存当前内存状态以备将来检索。
LLM 进程从LLM 任务队列读取文本,并确定它是否是需要模型响应的指令。 对于识别为指令的文本,压缩器进程将使用当前指令和备份的内存执行内存接地,以检索与指令相关的内存。 然后,LLM 进程将根据检索到的内存和指令生成响应,并将生成的输出入队到文本转语音 (TTS) 任务队列。 一个额外的 TTS 线程(例如,F5-TTS [20],MeloTTS [154])将把来自TTS 任务队列的文本转换成音频并发送到前端。
未来的改进点:
1.编码器优化:选择垂直领域的编码器,提升视频和音频理解能力。
2.多模态的长期记忆模块:这方面是核心。可以参考mem0将视频和音频记忆存储到多模态知识图谱中,还有针对每个用户的键值数据库,向量数据库,图形数据库等。这样才能更为个性化,增强可用性。
性能测试与研究成果
1) 卓越的基准测试成绩IXC2.5-OL 在多项国际权威测试中表现出色:
- 音频处理
- 在 Wenetspeech 中文测试集上,语音识别的词错误率(WER)为 7.8%,远超 VITA 和 Mini-Omni。
- 在 LibriSpeech 英文基准上,“清晰”环境下的 WER 为 2.5%,而在噪声环境中也达到了 9.2% 的优秀成绩。
- 视频处理
- 在 MLVU 和 StreamingBench 的视频推理与异常识别测试中,分别取得了 66.2% 和 73.79% 的评分,创下行业新高。
2) 高效的多模态处理能力流式感知模块通过压缩和记忆机制,实现了对多模态数据的实时处理。系统能够同时处理数百万标记,检索速度快且数据损失率低,适合需要长期交互的动态环境。
3) 开放性与易用性研究团队已将全部代码、模型及推理框架公开,开发者可以快速集成并根据实际需求进行优化。
实际应用场景
1) 智能监控与异常检测 IXC2.5-OL 的实时视频处理能力,适用于智能监控系统中异常事件的自动识别,如公共场所的行为异常分析。
2) 智能会议助手 通过实时感知音频与视频流,该框架可为企业提供智能会议助手服务,包括实时记录、摘要生成以及任务提醒。
3) 教育与学习 在在线教育中,IXC2.5-OL 可作为虚拟导师,实时分析学习者的行为反馈并调整教学策略,同时记录学习数据以优化课程内容。
4) 医疗辅助诊断 长时记忆模块能够存储并快速检索患者的历史病历数据,结合实时感知与推理功能,辅助医生做出准确诊断。
结语
IXC2.5-OL 的模块化设计从本质上解决了传统系统的诸多局限:
- 感知、记忆与推理的分工协作:模拟人脑的处理方式,确保了系统的高效性与可扩展性。
- 实时多模态交互:实现了音频、视频和文本的同步处理,为动态环境中的复杂应用提供了解决方案。
- 高效存储与检索:通过记忆压缩机制,将长期多模态交互的计算与存储成本降至最低。
随着 AI 技术的进一步发展,IXC2.5-OL 不仅将继续推动人机交互的革新,还为构建更接近人类认知的 AI 系统提供了重要参考。