
[📖 VITA-1.5 Paper] [🤖 Basic Demo] [🍎 VITA-1.0]
- Github:https://github.com/VITA-MLLM/VITA
- Paper:arxiv.org/pdf/2501.01957
- modelscope:https://modelscope.cn/models/modelscope/NJU_VITA-1.5/summary
[📽 VITA-1.5 Demo Show! Here We Go! 🔥]
引言
近年来,多模态大语言模型(MLLMs)在视觉和文本的结合上取得了显著进展。然而,随着人机交互需求的增加,语音在多模态对话系统中的作用变得愈发重要。语音不仅是信息传递的关键媒介,还能显著提升交互的自然性和便捷性。因此,如何将视觉和语音模态高效整合,实现高性能的多模态交互,成为了当前研究的重点。

VITA-1.5的提出正是为了解决这一挑战。通过精心设计的多阶段训练方法,VITA-1.5逐步训练大语言模型(LLM)理解视觉和语音信息,最终实现了流畅的视觉和语音交互。与现有模型相比,VITA-1.5不仅保留了强大的视觉-语言能力,还实现了高效的语音对话能力,显著加速了多模态端到端的响应速度。
VITA-1.5
模型架构
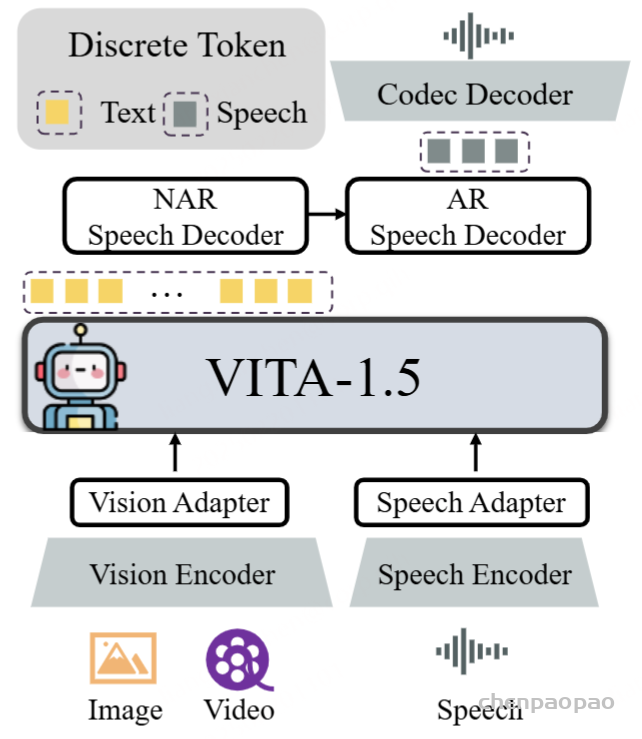
VITA-1.5的整体架构如图2所示。输入侧与VITA-1.0版本相同,采用“多模态编码器-适配器-LLM”的配置。它将视觉/音频Transformer和多层连接器与LLM结合进行联合训练,旨在增强对视觉、语言和音频的统一理解。在输出侧,VITA-1.5拥有自己的端到端语音模块,而不是像原始VITA-1.0版本那样使用外部TTS模型。
视觉模态
视觉编码器:VITA-1.5采用InternViT-300M作为视觉编码器,输入图像大小为448×448像素,每张图像生成256个视觉标记。对于高分辨率图像,VITA-1.5采用动态分块策略捕捉局部细节,提高图像理解的准确性。
视频处理:视频被视为一种特殊的多图像输入。如果视频长度短于4秒,则均匀采样4帧;对于4到16秒的视频,每秒采样一帧;对于超过16秒的视频,均匀采样16帧。视频帧不应用动态分块,以避免过多的视觉标记影响处理效率。
视觉适配器:使用两层MLP将视觉特征映射到适合LLM理解的视觉标记。
音频模态
语音编码器:类似于[56],我们的音频编码模块由多个下采样卷积层(4倍下采样)和24个Transformer块(隐藏大小为1024)组成。下采样层有助于降低音频特征的帧率,提高LLM的处理速度。音频编码器约有350M参数,输出帧率为12.5Hz。使用Mel滤波器组特征作为音频编码器的输入,窗口大小为25ms,偏移为10ms。
语音适配器:由多个2倍下采样的卷积层组成。
语音解码器:使用TiCodec作为我们的编解码模型,定制了一个大小为1024的单码本。这种单码本设计简化了推理阶段的解码过程。编解码模型负责将连续语音信号编码为离散语音标记,频率为40Hz,同时能够将这些标记解码回采样率为24,000Hz的语音信号。
当前的LLM只能输出文本标记,语音生成能力要求LLM能够输出语音标记。为此,我们在文本标记后添加了两个语音解码器:1)非自回归(NAR)语音解码器,全局处理文本标记并建模语义特征,旨在生成语音标记的初始分布;2)自回归(AR)语音解码器,基于NAR解码器生成的语音信息逐步生成更高质量的语音标记。最终的语音标记序列通过编解码模型的语音解码器解码为连续语音信号流(波形)。我们为NAR和AR语音解码器采用了4个LLaMA解码层,隐藏大小为896,参数大小约为120M。
训练数据

如表1所示,多模态指令微调的训练数据涵盖了广泛的类别,如描述数据和问答数据,包括中文和英文。在不同的训练阶段,从整体数据集中选择性地采样子集以服务于不同的目标。具体来说,数据集分类如下:
- 图像描述数据:使用ShareGPT4V、ALLaVA-Caption、SharedGPT4o-Image和合成数据等数据集训练模型生成图像的描述性语言。
- 图像问答数据:使用LLaVA-150K、LLaVA-Mixture-sample、LVIS-Instruct、ScienceQA、ChatQA和从LLaVA-OV采样的子集(如通用图像问答和数学推理数据集)等数据集训练模型回答基于图像的问题和执行视觉推理任务。
- OCR和图表数据:支持模型理解OCR和图表内容,使用Anyword-3M、ICDAR2019-LSVT、UReader、SynDOG、ICDAR2019-LSVT-QA和从LLaVA-OV采样的相应数据等数据集。
- 视频数据:使用ShareGemini和合成数据等数据集训练模型处理视频输入并执行诸如描述和基于视频的问答等任务。
- 纯文本数据:增强模型理解和生成语言的能力,促进基于文本的问答任务。
除了表1中列出的图像和视频数据外,还纳入了110,000小时的内部语音-转录配对ASR数据,涵盖中文和英文,用于训练音频编码器并将音频编码器与LLM对齐。此外,使用TTS系统生成的3,000小时文本-语音配对数据用于训练语音解码器。
三阶段训练策略
为了确保VITA-1.5在涉及视觉、语言和音频的任务中表现良好,我们必须面对一个关键挑战,即不同模态之间的训练冲突。例如,添加语音数据可能会对视觉数据的理解产生负面影响,因为语音的特征与视觉的特征显著不同,导致学习过程中的干扰。为了解决这一挑战,我们设计了一个三阶段训练策略,如图3所示。核心思想是逐步将不同模态引入模型,使其在增加新模态能力的同时保持现有模态的能力。
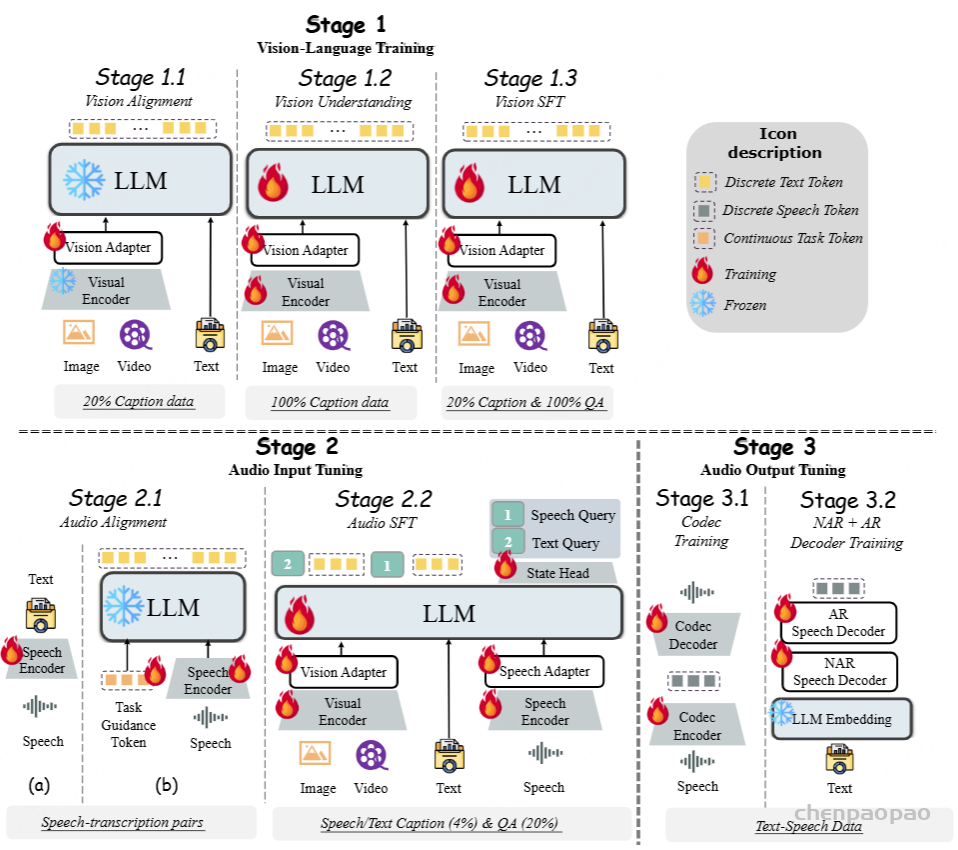
VITA-1.5的训练管道。训练过程分为三个阶段,以逐步将视觉和音频纳入LLM同时缓解了形态冲突。第一阶段的重点是视觉训练,包括视觉对齐(阶段1.1,使用表1中的20%字幕数据),视觉理解(阶段1.2,使用100%的字幕数据)以及用于Visual QA的指令调整(阶段1.3,使用20%字幕数据和100%QA数据)。阶段2引入音频输入调整,并具有音频对齐(阶段2.1,使用11,000小时的语音转录对)和语音质量检查的指令调整(阶段2.2,采样4%字幕数据和20%的QA数据)。最后,第3阶段的重点是音频输出调整,包括对编解码器模型的训练(使用3,000个小时的文本语音数据)和语音解码器培训(阶段3.2)。图像中显示的百分比对应于表1中指定的数据采样率。
阶段1:视觉训练
阶段1.1 视觉对齐:在此阶段,我们的目标是弥合视觉和语言之间的差距。前者的特征从预训练的视觉编码器InternViT-300M中提取,后者通过LLM引入。我们使用表1中20%的描述性描述数据进行训练,其中只有视觉适配器是可训练的,而其他模块是冻结的。这种方法允许LLM初步对齐视觉模态。
阶段1.2 视觉理解:在此阶段,我们的目标是教会LLM转录图像内容。为此,我们使用表1中所有的描述性描述数据。在此过程中,视觉模块的编码器和适配器以及LLM都是可训练的。重点是使模型通过学习关于图像的描述性文本,建立视觉和语言之间的强连接,使其能够通过生成自然语言描述来理解图像内容。
阶段1.3 视觉SFT:在阶段1.2之后,模型已经获得了对图像和视频的基本理解。然而,指令跟随能力仍然有限,难以应对视觉问答任务。为了实现这一点,我们使用表1中所有的问答数据,同时保留20%的描述性描述数据以增加数据集的多样性和任务的复杂性。
在训练过程中,视觉模块的编码器和适配器以及LLM都是可训练的。此阶段的关键目标是使模型不仅能够理解视觉内容,还能够根据指令回答问题。
阶段2:音频输入微调
阶段2.1 音频对齐:在完成阶段1的训练后,模型已经建立了强大的图像和视频理解基础。在此阶段,我们的目标是基于阶段1减少音频和语言之间的差异,使LLM能够理解音频输入。训练数据包括11,000小时的语音-转录对。我们采用两步方法:(a)语音编码器训练:我们采用常见语音识别系统中使用的训练框架,使用连接时序分类(CTC)损失函数[18]训练语音编码器。目的是使编码器从语音输入中预测转录文本。此步骤确保音频编码器能够提取语音特征并将其映射到文本表示空间。(b)语音适配器训练:在训练语音编码器后,我们将其与LLM集成,使用音频适配器将音频特征引入LLM的输入层。此阶段的训练目标是使LLM能够输出语音数据的转录文本。
此外,在步骤(b)中,我们引入了特殊的可训练输入标记来指导语音理解过程。这些标记提供了额外的上下文信息,指导用于问答任务的LLM执行ASR任务。
阶段2.2 音频SFT:此阶段的重点是引入语音问题和文本答案的问答功能。为此,我们从表1中采样4%的描述数据和20%的问答数据。在数据处理方面,大约一半的基于文本的问题被随机替换为其对应的语音版本,使用TTS系统生成。
在此阶段,视觉编码器和适配器、音频编码器和适配器以及LLM都是可训练的,旨在提高模型对多模态输入的适应性。此外,我们在LLM的输出中添加了一个分类头。该头用于区分输入是来自语音还是文本。结果,模型可以更准确地解释语音输入,并高效灵活地处理不同模态。
阶段3:音频输出微调
在前两个训练阶段,VITA-1.5模型已经有效地发展了其多模态理解能力。然而,一个关键的能力,即语音输出,仍然缺失,这对于其作为交互助手的角色至关重要。为了在不影响模型基本能力的情况下引入语音输出功能,我们借鉴了[56]的策略,使用3,000小时的文本-语音数据,并采用两步训练方法(见图3)。
阶段3.1 编解码训练:此步骤的目标是使用语音数据训练具有单码本的编解码模型。编解码模型的编码器能够将语音映射到离散标记,而解码器可以将离散标记映射回语音流。在VITA-1.5的推理阶段,仅使用解码器。
阶段3.2 NAR + AR解码器训练:此阶段的训练使用文本-语音配对数据,其中文本被输入到LLM的分词器和嵌入层以获得其嵌入向量,语音被输入到编解码模型的编码器以获得其语音标记。文本嵌入向量被发送到NAR语音解码器以获得全局语义特征,然后将这些特征发送到AR语音解码器,预测相应的语音标记。请注意,在此阶段LLM是冻结的,因此多模态性能不受影响。
评估
视觉-语言评估
基线:我们比较了一系列开源MLLMs,包括VILA-1.5、LLaVA-Next、CogVLM2、InternLM-XComposer2.5、Cambrian-1、MiniCPM-V-2.6、Ovis1.5、InternVL-Chat-1.5、InternVL-2、LLaVA-OV和Video-LLaVA、SilME和LongVA,以及5个闭源MLLMs,包括GPT-4V、GPT-4o、GPT-4o-mini、Gemini 1.5 Pro和Claude 3.5 Sonnet。
评估基准:为了评估VITA-1.5的图像感知和理解能力,我们使用了多个评估基准,包括MME、MMBench、MMStar、MMMU、MathVista、HallusionBench、AI2D、OCRBench和MMVet。这些基准涵盖了广泛的方面,包括通用多模态能力(如MME、MMBench和MMMU)、数学推理(MathVista)、幻觉检测(HallusionBench)、图表(AI2D)和OCR(OCRBench)理解,提供了全面的评估结果。对于视频理解,我们使用了代表性的评估基准,包括Video-MME、MVBench和TempCompass。
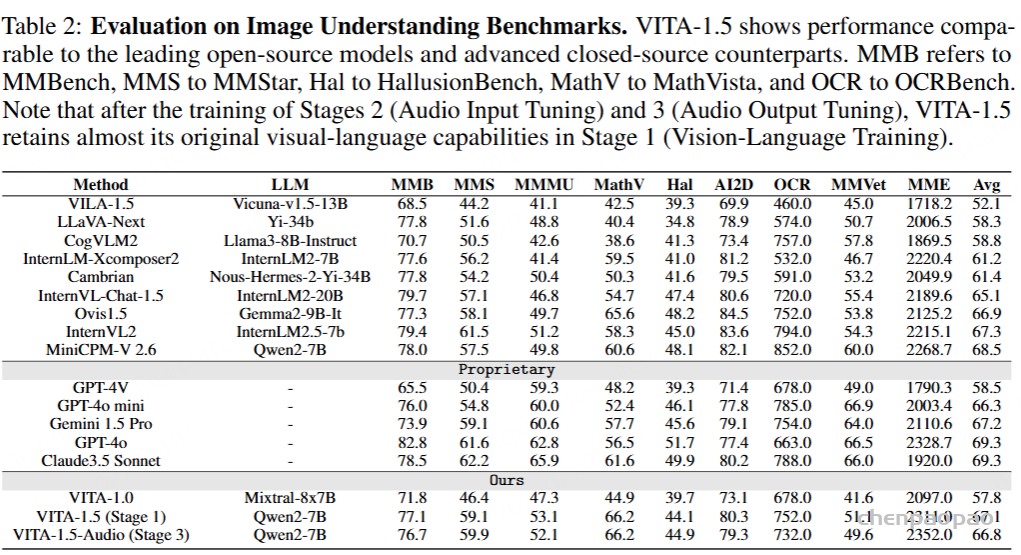
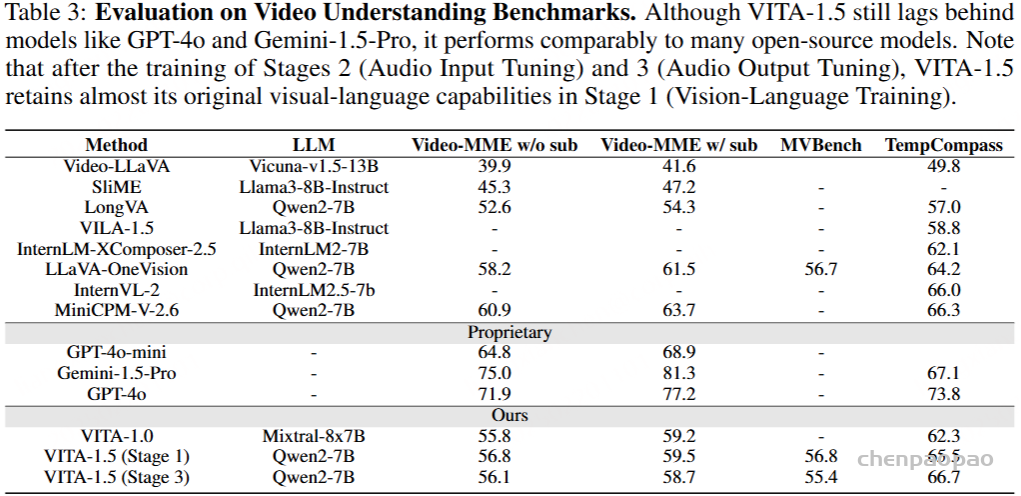
视觉-语言能力:表2展示了VITA-1.5的图像理解性能比较。在三个阶段的训练后,VITA-1.5的表现与最先进的开源模型相当,甚至超过了一些闭源模型,如GPT-4V和GPT-4o-mini。这一结果突显了VITA-1.5在图像-语言任务中的强大能力。如表3所示,VITA-1.5在视频理解评估中表现出与顶级开源模型相当的性能。与专有模型的显著差距表明,VITA-1.5在视频理解方面仍有显著的改进空间和潜力。请注意,在阶段2(音频输入微调)和阶段3(音频输出微调)的训练后,VITA-1.5几乎保留了其在阶段1(视觉-语言训练)中的原始视觉-语言能力。
语音评估
基线:以下三个基线模型用于比较:Wav2vec2-base、Mini-Omini2、Freeze-Omini和VITA-1.0。
评估基准:普通话评估集包括三个数据集:aishell-1、test net和test meeting。这些数据集用于评估模型在普通话语音上的表现。评估指标是字符错误率(CER)。英语评估集包括四个数据集:dev-clean、dev-other、test-clean和test-other,用于评估模型在英语语音上的表现。评估指标是词错误率(WER)。
ASR性能:表4中的评估结果表明,VITA-1.5在普通话和英语ASR任务中均取得了领先的准确性。这表明VITA-1.5已成功集成了先进的语音能力,以支持多模态交互。

结论
本文介绍了VITA-1.5,这是一个通过精心设计的三阶段训练策略整合视觉和语音的多模态LLM。通过缓解模态之间的固有冲突,VITA-1.5在视觉和语音理解方面实现了强大的能力,无需依赖单独的ASR或TTS模块即可实现高效的语音到语音交互。广泛的评估表明,VITA-1.5在多模态基准测试中表现出色。我们希望VITA-1.5能够接过VITA-1.0的旗帜,继续推动开源模型在实时多模态交互领域的进步。