
训练时候可以进行 左pad 或者 右pad,或者对 prompt 进行左pad,对 label 进行右pad。现在其实一般预训练或者微调的时候都不pad,否则会影响训练效率,大概的思路:假设 batch size = 2,max_seq_len = 16,sequence 1、2、3、4 分别有 7、9、6、10 个 token,那么就可以组成[[s1+s2], [s3+s4]] 进行训练,这个时候需要构造一个正确的 casual attention mask。flash_attn_varlen_qkvpacked_func 接口,就可以实现这样的计算而无需 padding。
batch 推理的时候一般只用 左pad。推理时也只有batch推理会有影响,另外左对齐方便所有行同时产生next token。在强化学习训练PPO/DPO/GRPO 的时候需要用到推理,所以也需要做左pad!!
padding_side 的影响
谈到 padding,我们自然要考虑 attention_mask,借助 attention_mask 可以在计算 attention weight 时将 padding 带来的影响屏蔽掉。下面是设置不同的 padding_side,tokenizer 的输出:
没有设置 padding_side 或者 padding_side=’right’:
>>> from transformers import LlamaForCausalLM, LlamaTokenizer
>>> tokenizer = LlamaTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
>>> tokenizer.pad_token = tokenizer.eos_token
>>> prompts = ["hello llama", "who are you?"]
>>> tokenizer(prompts, return_tensors="pt", padding=True)
{
'input_ids': tensor([[ 1, 22172, 11148, 3304, 2], │············
[ 1, 1058, 526, 366, 29973]]),
'attention_mask': tensor([[1, 1, 1, 1, 0], [1, 1, 1, 1, 1]])
}设置 padding_side=’left’:
>>> from transformers import LlamaForCausalLM, LlamaTokenizer
>>> tokenizer = LlamaTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf", padding_side="left")
>>> tokenizer.pad_token = tokenizer.eos_token
>>> prompts = ["hello llama", "who are you?"]
>>> tokenizer(prompts, return_tensors="pt", padding=True)
{
'input_ids': tensor([[ 2, 1, 22172, 11148, 3304], │············
[ 1, 1058, 526, 366, 29973]]),
'attention_mask': tensor([[0, 1, 1, 1, 1], [1, 1, 1, 1, 1]])
}要理解 padding_side=’right’ 为什么会导致结果不正确,关键的点是 next token 的预测是使用句子的最后一个 token 经过 transformer 层之后输出的 logit 来得到 next token 的。下面是 model.generate通过多次跳转后来到 next token 的处理逻辑:
# https://github.com/huggingface/transformers/blob/a7cab3c283312b8d4de5df3bbe719971e24f4281/src/transformers/generation/utils.py#L2411
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
# forward pass to get next token
outputs = self(
**model_inputs,
return_dict=True,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
)
next_token_logits = outputs.logits[:, -1, :]
# argmax
next_tokens = torch.argmax(next_tokens_scores, dim=-1)从上面的代码可以看到,句子最后一个 token 所对应的 logit 会被用来计算 next token,因此,最后一个 token logit 的计算是否正确决定了推理的结果是否正确。
接下来,我们来看一下 padding_side=’left’ 和 padding_side=’right’,最后一个 token 所对应的 logit 是否是正确计算的。
我们先来看 padding_side=’left’ 的最后一个 logit 的计算过程,省略中间的具体细节,只给出关键的过程),这里只关注句子 “hello llama”:
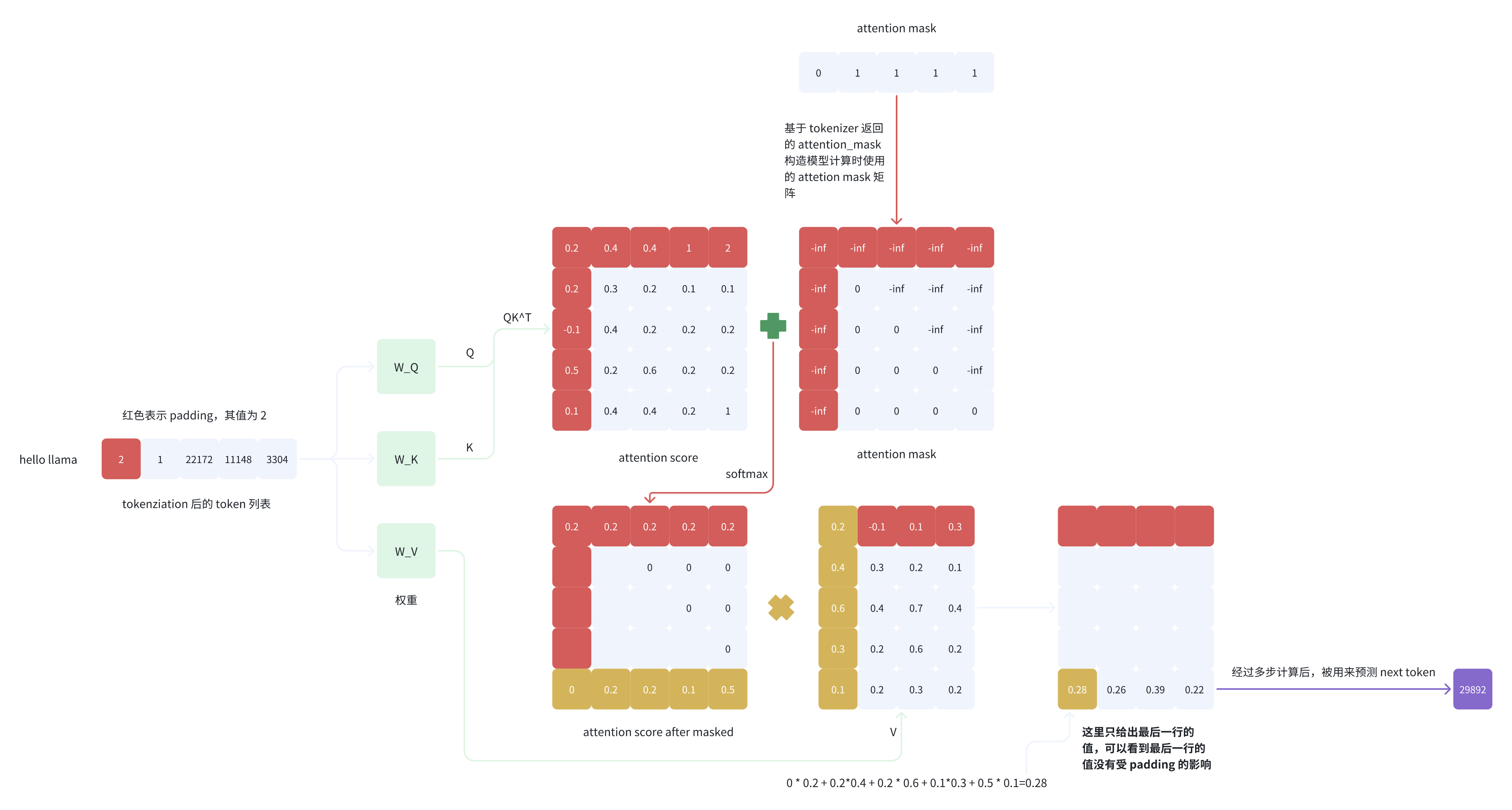
从图 4 的计算过程可以看到,使用 padding_side=’left’ 的方式,attention score after masked 矩阵的最后一行和 V 的第一列进行内积后得到的值为正确且符合期望的值,即最后一个 token 所对应的 logit 的计算没有受 padding 的影响,该 logit 的计算过程正确。
因为最后一列计算得分时候,V第一行:pad token 的权重【 attention score】都是 0,且attention score 左下角权重为0,那么计算结果最后一列的结果 只跟非pad的V有关
我们接下来看一下 padding_side=’right’ 的最后一个 logit 的计算过程:
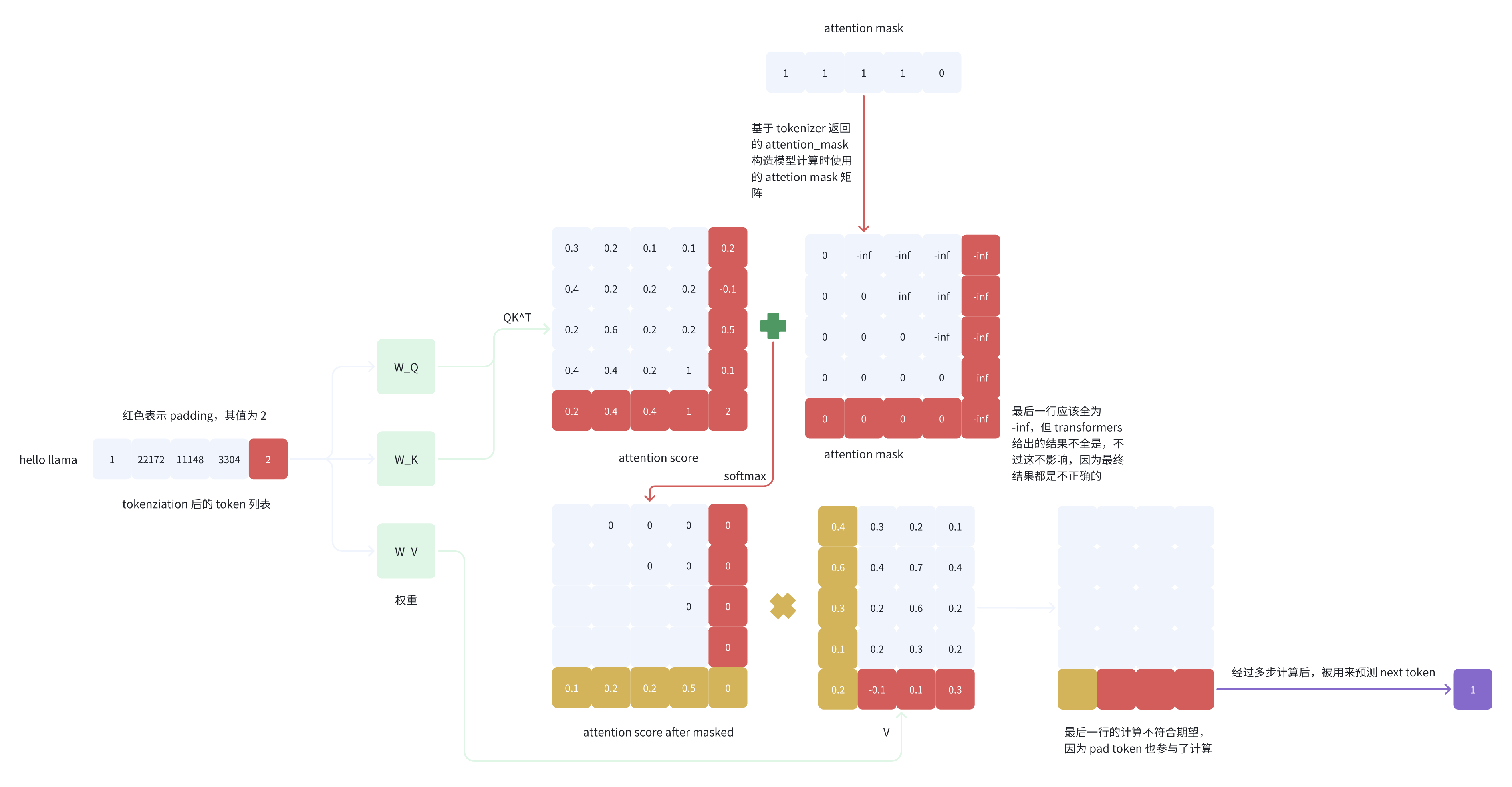
从图 5 的计算过程可以看到,attention score after masked 矩阵的最后一行和 V 的第一列进行内积后得到的值是不符合期望的,即最后一个 token(pad token)所对应的 logit 的计算不正确,因为 pad token 也参与了计算,而正确预测 next token 的时候 pad token 是不应该参与计算的。
因为最后一列计算得分时候,V最后一行:pad token对应的的权重【 attention score 最后一行】不都是0,,那么计算结果最后一列的结果 跟非pad的V有关。
至此,我们弄清楚了为什么 padding_side=’right’ 会产生不正确的结果。
Prepacking-消除attention padding冗余计算
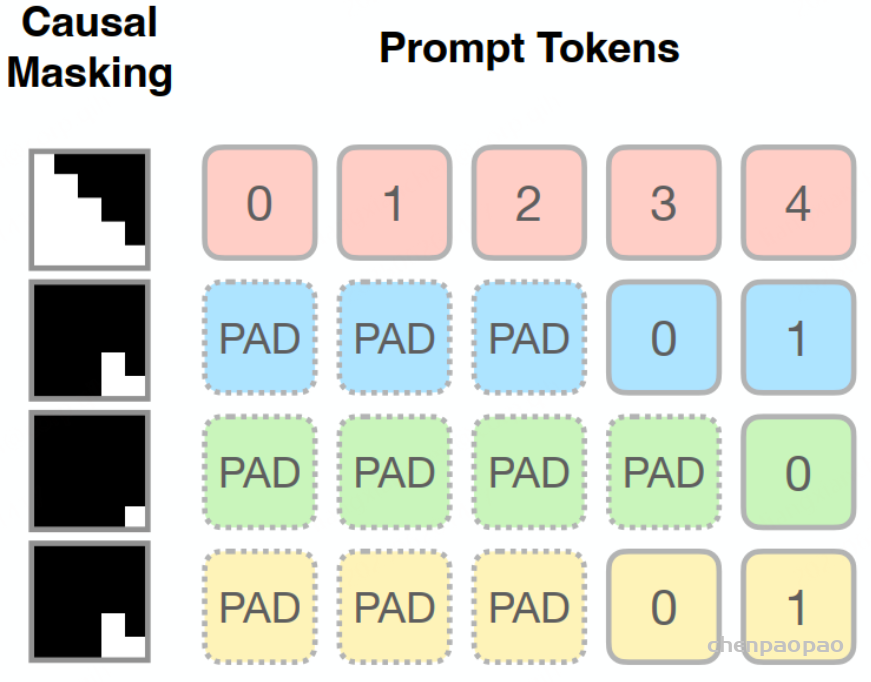
一个batch里,不同的request,其prompt长度不一样,这样计算attention时会做padding,确保所有的request长度相同。如下图所示,1个batch总共4个句子,后面3个句子做了padding,这样做的一个问题就是,会浪费计算。
,一个解决方法是去除padding,把这些句子放在一个句子里计算。如下图所示,去除了padding之后,所有的request放在一个句子里。但是带来的问题是,attention计算只有句子之内的不同token需要进行attention计算(红色计算attention、蓝色计算attention等等),句子之间是独立的。所以这种做法必须要进行适当的数据组织,让我们的attention算子能知道自己该把哪些token放在一个句子里计算。如下图所示,虽然输入到attention算子的是一个句子,包含10个token,但是需要一些额外数据,让attention算子去把红色部分当一个request计算attention、蓝色部分当一个request计算attention、绿色部分当一个request计算attention、黄色部分当一个request计算attention。
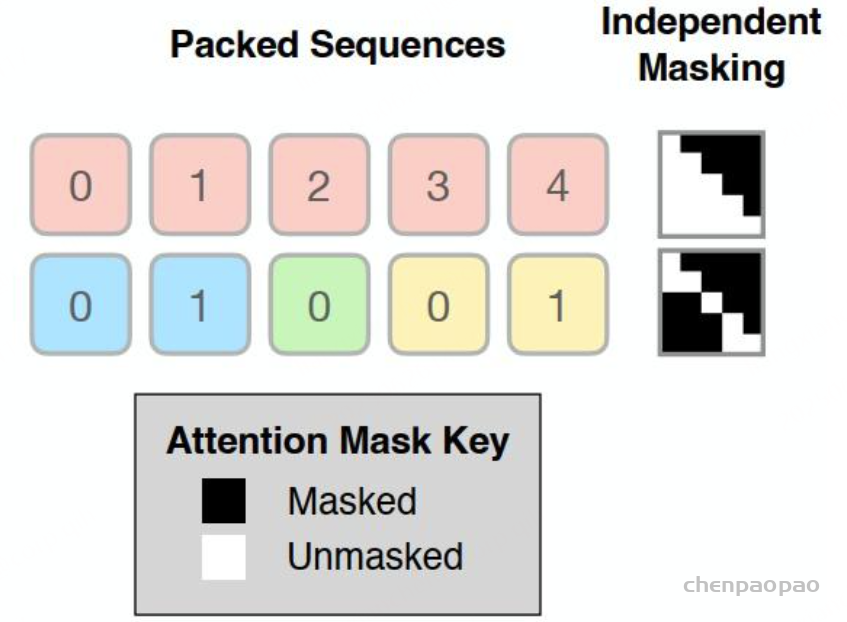
预打包在概念上很简单;我们不是将每个序列填充到相同的长度,而是使用现成的装箱算法将多个提示打包在一起,以代替填充标记。